bnl computing environment eic detector r&d simulation workshop october 8-9 th, 2012 maxim...
TRANSCRIPT

BNL Computing EnvironmentBNL Computing Environment
EIC Detector R&D Simulation WorkshopOctober 8-9th, 2012
Maxim PotekhinYuri Fisyak
[email protected]@bnl.gov

2
DisclaimerDisclaimer
BNL is a large and diverse organization.
In this presentation, we will only consider the computing environment of some of its larger communities of users, namely experiments at RHIC and ATLAS at the LHC. The focus will be on ATLAS, with a brief overview of STAR.
And it’s a vast topic – we’ll only be able to cover the basics.
The physics at LHC and RHIC is beyond the scope of this talk, we’ll only discuss computing.

3
OverviewOverview
Goals of this presentation:
• To overview the RHIC and ATLAS Computing Facility at BNL – a modern, state of the art platform supporting thousands of users working for a few major experiments
• To touch upon basic building blocks of Monte Carlo simulation in STAR
• To review experience in managing large-scale simulation workflow in ATLAS
• To present specific features of the PanDA system, the basis of the computing model of the ATLAS experiment at the LHC, and its future potential
Acknowledgements:
• A number of people contributed to this presentation.
• Special thanks to V.Fine, A.Klimentov and M.Ernst of Brookhaven National Lab, and A.Vaniachine of Argonne National Lab for their contributions.

4
RHIC and ATLAS Computing Facility at BNLRHIC and ATLAS Computing Facility at BNL(credits: M.Ernst)(credits: M.Ernst)
History:
• RACF was Formed in the mid-1990’s to provide centralized computing resources for the four RHIC experiments (BRAHMS, PHOBOS, STAR, PHENIX)
• Role was expanded in the late 1990’s to act as the US Tier-1 computing center for the ATLAS experiment at the LHC (i.e. the flagship of the US computing resources supporting ATLAS)
• Currently, staffed by 35 FTEs providing a full range of scientific computing services for more than 4000 users
• In addition:
Small but growing utilization by astrophysics groups
Occasional opportunistic utilization of resources by life sciences and neutrino physics research groups
Important R&D platform for Grid Technology and Cloud Computing, VM cluster technology etc

5
RACF: scale of RHICH and ATLAS computing RACF: scale of RHICH and ATLAS computing facilitiesfacilities
(credits: M.Ernst) (credits: M.Ernst)
RHIC:• 1200 Compute Servers (130 kHS06, 16k job slots)
• 7 PB of Distributed Storage on Compute Nodes, up to 16 GB/s between compute servers and distributed storage servers
• 4 Robotic Tape Libraries w/ 40 tape drives and 38k cartridge slots, 20 PB of active data
ATLAS:• 1150 Compute Servers (115 kHS06, 12k job slots)
• 90 Storage Servers driving 8500 disk drives (10 PB), up to 18 GB/s observed in production between compute and storage farm
• 3 Robotic Tape Libraries w/ 30 tape drives and 26k cartridge slots, 7 PB of active data

6
RACF: the infrastructureRACF: the infrastructure (credits: M.Ernst) (credits: M.Ernst)
Magnetic Tape Archive:• Data inventory of currently 27 PB managed by High Performance Storage System
(HPSS), archive layer below dCache or xrootd
• Up to 4GB/s tape/HPSS dCache/xrootd throughput
Network:• LAN – 13 enterprise switches w/ 5800 active ports (750 10GE ports), 160 Gbps
inter-switch Bandwidth
• WAN – 60 Gbps in production (20 Gbps to CERN and other ATLAS T1s) + 20 Gbps for ATLAS T1/T2 traffic and up to 20 Gbps serving domestic and international data transfer needs

7
RACF and Open Science GridRACF and Open Science Grid (credits: M.Ernst) (credits: M.Ernst)
The Open Science Grid Consortium• http://www.opensciencegrid.org
• The Open Science Grid (OSG) advances science through open distributed computing. The OSG is a multi-disciplinary partnership to federate local, regional, community and national cyber infrastructures to meet the needs of research and academic communities at all scales.
• The OSG provides provide common service and support for resource providers and scientific institutions using a distributed fabric of high throughput computational services. The OSG does not own resources but provides software and services to users and resource providers alike to enable the opportunistic usage and sharing of resources. The OSG is jointly funded by the Department of Energy and the National Science Foundation.
• RACF Staff is heavily engaged in the OSG Major contributor to Technology Investigation area and the architectural development of
OSG’s Fabric of Services
Member of the Management Team and represents BNL on the OSG Council
ATLAS Tier-1 center fully integrated with OSG
Provides opportunistic cycles to other OSG VOs

8
ATLAS: experiment at the LHCATLAS: experiment at the LHC

9
ATLAS: scale and complexity of workloadATLAS: scale and complexity of workload
Main job types in ATLAS, ordered by resource consumption
• Monte Carlo production• User Analysis• Group Production• Validation• Data processing and re-processing• Testing
What’s the scale of the workload?
• ATLAS generates and processes ~106 jobs per day• ~105 jobs running at any given time• Monte Carlo: 5×109 events in 2011 alone
How to manage complexity?
• Given the sheer number of jobs processed in ATLAS , individual job definition is out of question, in particular due to the fact that the large number of parameters makes it error-prone
• Instead, the main unit of computation is a TASK, i.e. a set of jobs with similar parameters
• Tasks are created and managed by a purpose-built ATLAS Task Request application, which encapsulates the expert knowledge of the great variety and number of job parameters and makes this complexity manageable for the end user, the physicist
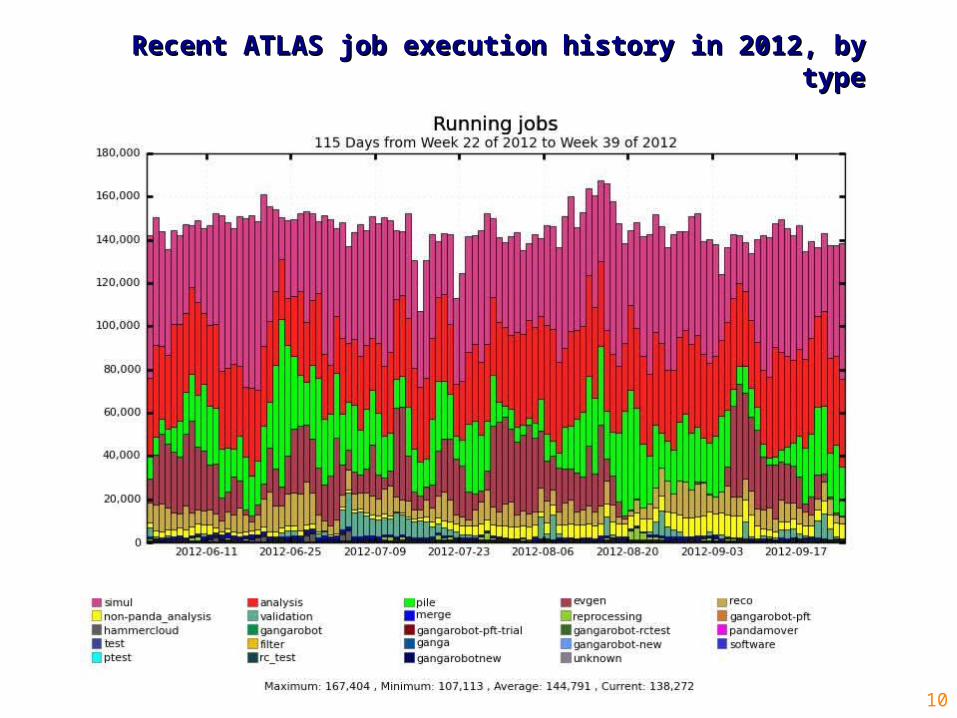
10
Recent ATLAS job execution history in 2012, by Recent ATLAS job execution history in 2012, by typetype

11
ATLAS: note on tasks and task requestsATLAS: note on tasks and task requests
The original concept of tasks was based on the assumptions
• Small to moderate number of tasks in the system• Large number of jobs included in the task
But as ATLAS workflow matured, the situation has changed
• Larger tasks split into smaller ones to facilitate the optimize the throughput, i.e. be able to start using a subset of the final sample before all of it becomes 100% available
• Less jobs per task• Important implication for the ATLAS production system evolution
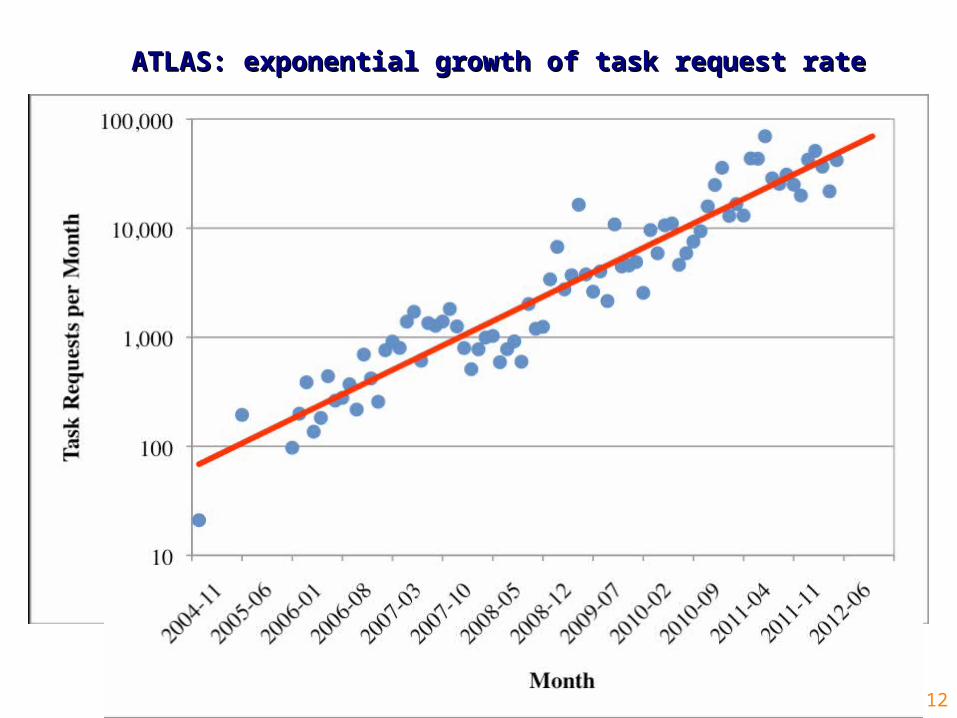
12
ATLAS: exponential growth of task request rateATLAS: exponential growth of task request rate

13
PanDA: Production and Distributed Analysis System
HistoryThe PanDA system has been developed by US ATLAS (BNL and UTA) since 2005 to
meet ATLAS requirements for a data-driven workload management system for production and distributed analysis processing capable of operating at LHC data processing scale. ATLAS processing and analysis places challenging requirements on throughput, scalability, robustness, efficient resource utilization, minimal operations manpower, and tight integration of data management with processing workflow.
In October 2007 PanDA was adopted by the ATLAS Collaboration as the sole system for distributed processing production across the Collaboration.
Pilot Job FrameworkUse of pilot jobs for acquisition of processing resources: payload jobs are assigned to
successfully activated and validated “pilots” based on PanDA-managed brokerage criteria.
This “late binding” of payload jobs to processing slots prevents latencies and failure modes in slot acquisition from impacting the jobs, and maximizes the flexibility of job allocation to resources based on the dynamic status of processing facilities and job priorities. Payloads are defined as scripts (termed “transformations”) which the pilot job obtains from a URL specified by the PanDA server, in the course of communication between the two.
The pilot is also a principal 'insulation layer' for PanDA, encapsulating the complex heterogeneous environments and interfaces of the grids and facilities on which PanDA operates.
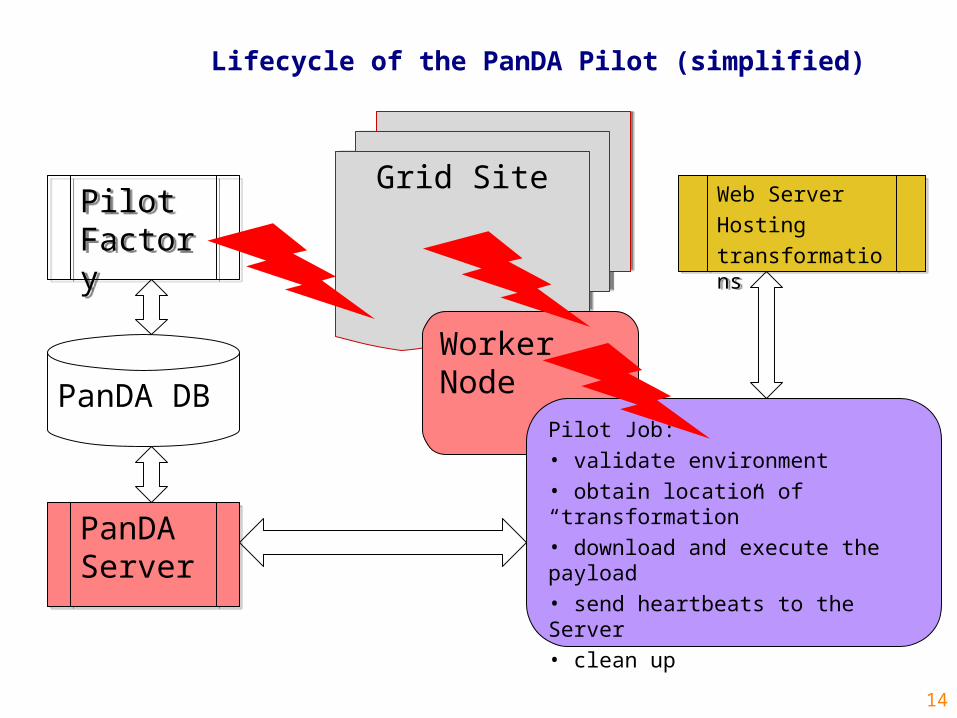
14
Lifecycle of the PanDA Pilot (simplified)
Grid SiteGrid Site
PanDA ServerPanDA Server
Worker Node
Pilot FactoryPilot Factory
Pilot Job:• validate environment• obtain location of “transformation”• download and execute the payload• send heartbeats to the Server• clean up
PanDA DB
Web Server
Hosting
transformations
Web Server
Hosting
transformations
15
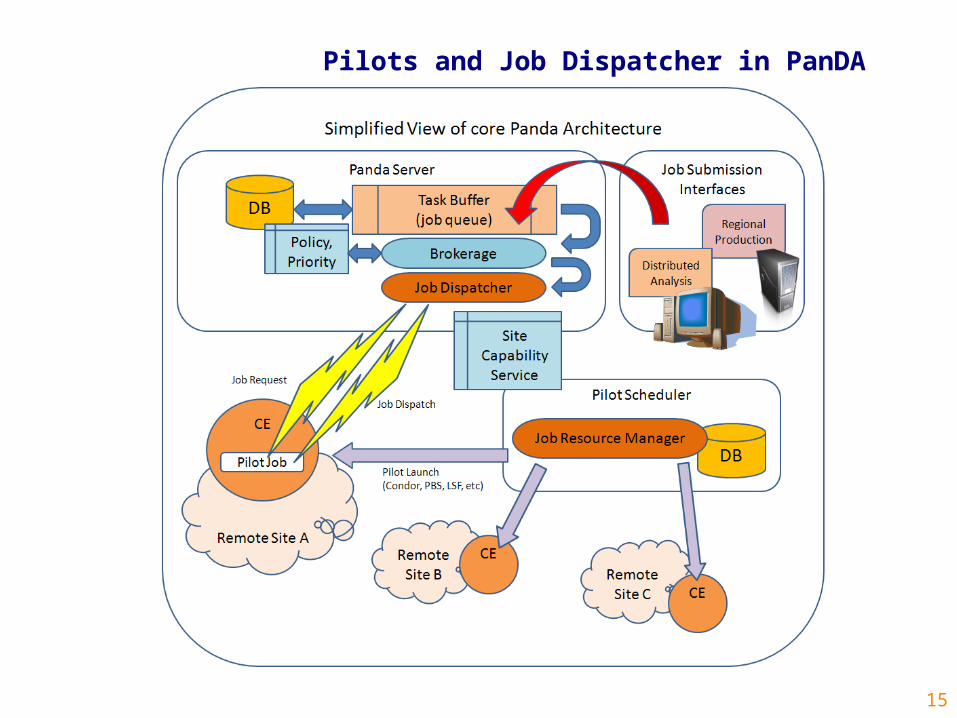
Pilots and Job Dispatcher in PanDA

16
Highlights of PanDA principal design features
• Support for both managed production and individual users (analysis) so as to benefit from a common WMS infrastructure and to allow analysis to leverage production operations support, thereby minimizing overall operations workload.
• A coherent, homogeneous processing system layered over diverse and heterogeneous processing resources, which may simultaneously include local resources such as a farm located at the site, and any number of Grid Sites distributed worldwide. This helps insulate production operators and analysis users from the complexity of the underlying processing infrastructure. It also maximizes the amount of PanDA systems code that is independent of the underlying middleware and facilities actually used for processing in any given environment.
• Extensive direct use of Condor (particularly Condor-G), as a pilot job submission infrastructure of proven capability and reliability. This functionality is currently contained in the recently developed “AutoPyFactory”.
• Coherent and comprehensible system view afforded to users, and to PanDA's own job brokerage system, through a system-wide job database that records comprehensive static and dynamic information on all jobs in the system. To users and to PanDA itself, the job database appears essentially as a single attribute-rich queue feeding a worldwide processing resource.

17
PanDA in a nutshell
• The users never have to deal with specific details of highly heterogeneous computing sites, their batch systems and storage facilities. They don’t have to know anything about the sites’ gatekeepers or other information that would normally be necessary to submit a job in the Grid environment
• Despite the description of the pilot job framework used in PanDA, as presented in these slides, its users don’t have to know much or anything about pilots
• Grid sites become an abstraction know by their mnemonic names, such UTA_SWT2, and are often thought of as queues for job execution
• Stage-in and stage-out of ATLAS data is fully automatic and handled by the Dynamic Data Management System, description of which is well outside the scope of this presentation
• Due to intelligence built into the brokerage mechanism in the PanDA server, jobs utilizing a particular dataset are guided to sites that already have these data
• Jobs are fed into PanDA either by individual users, via a suite of command line utilities, or by an automated process (a robot) which processes tasks created by the Task Request system and stored in the database.
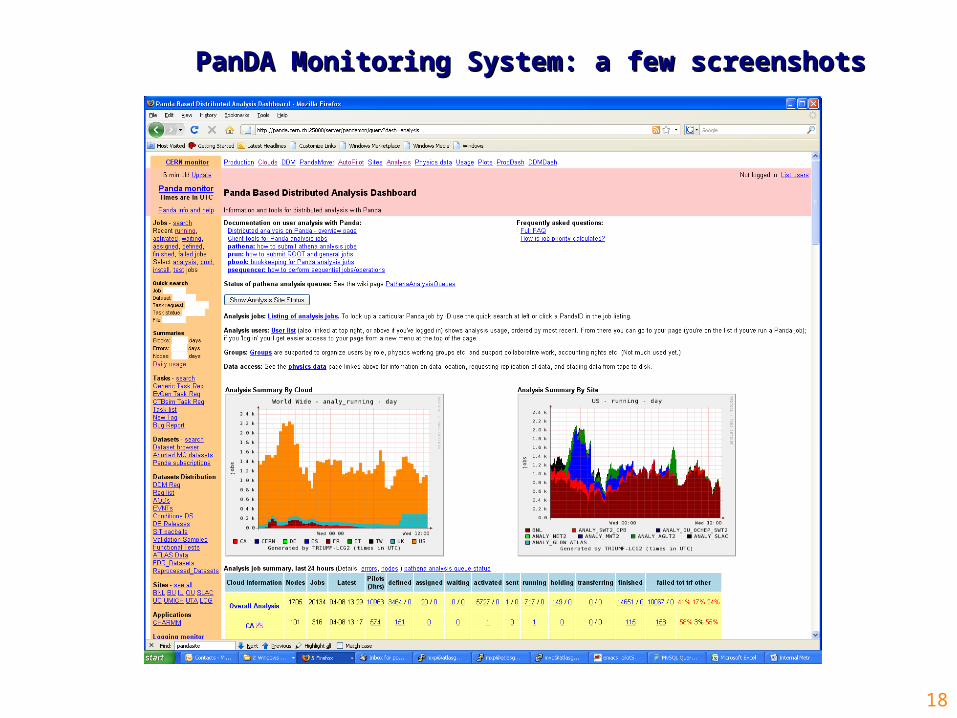
• At any given point in time, the users have access to comprehensive information regarding their task, job and data status, aggregated data characterizing operation of sites and clouds, and individual details of the pilot and payload job execution. All of this is delivered to the user via the PanDA Monitor – see the following next slides.
• One way to look at PanDA is this: it effectively creates a virtual supercomputer with ~1.4×105 cores, which is on par with 25 largest machines in the top-500 list
18
PanDA Monitoring System: a few screenshotsPanDA Monitoring System: a few screenshots
19
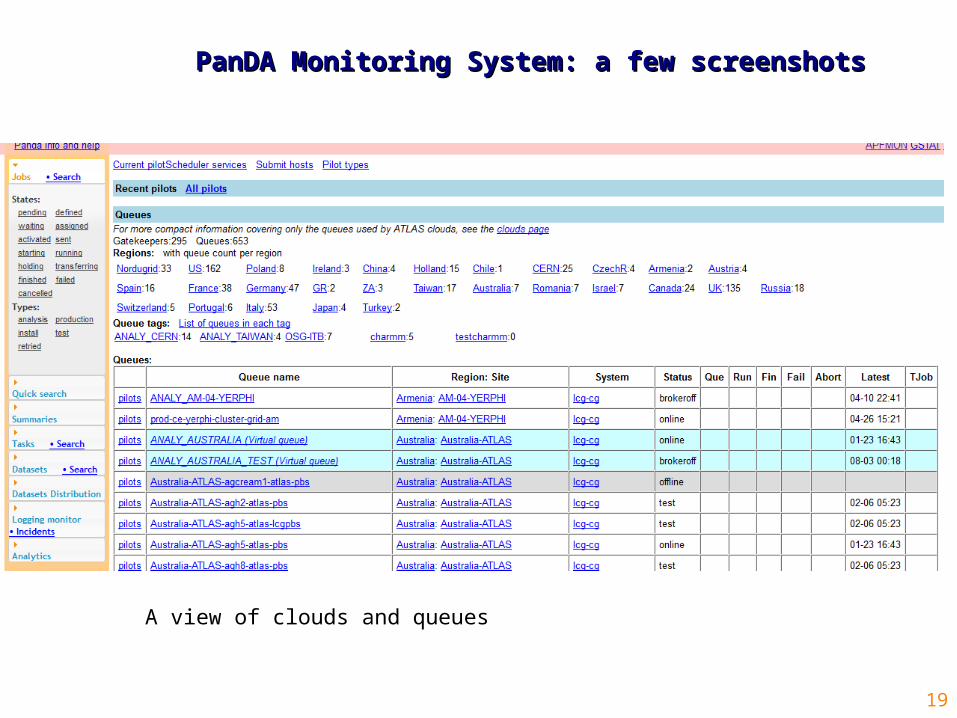
PanDA Monitoring System: a few screenshotsPanDA Monitoring System: a few screenshots
A view of clouds and queues
20
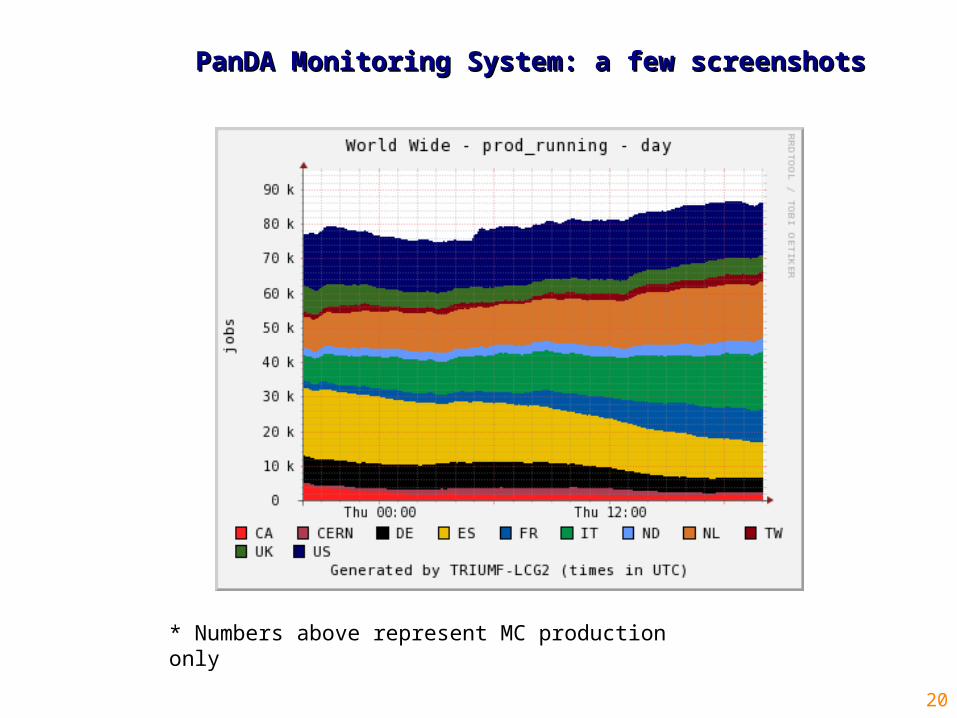
PanDA Monitoring System: a few screenshotsPanDA Monitoring System: a few screenshots
* Numbers above represent MC production only
21
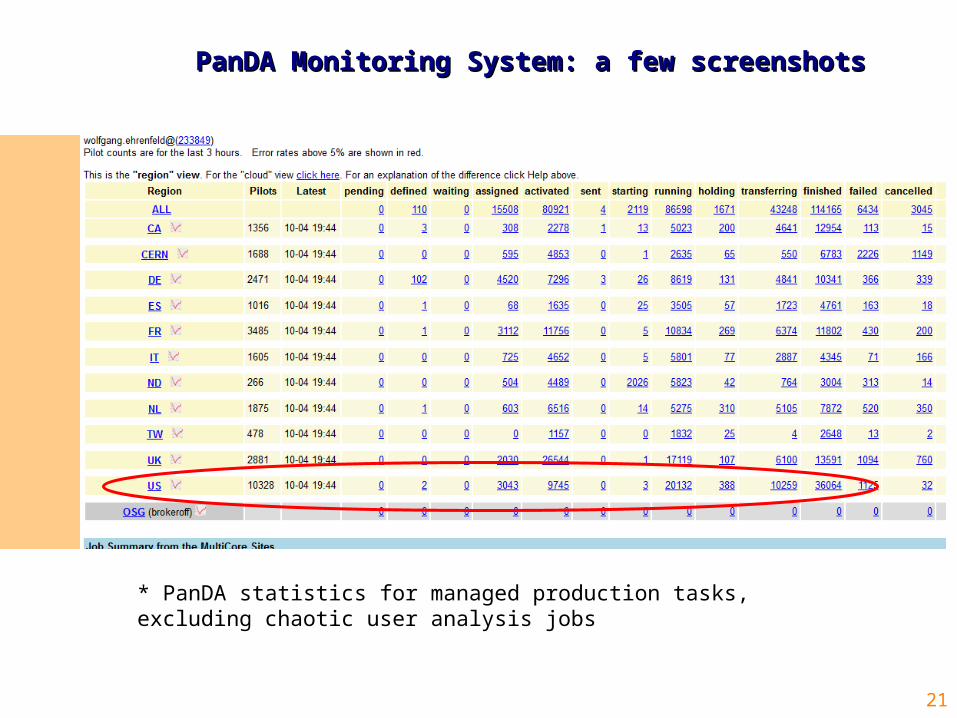
PanDA Monitoring System: a few screenshotsPanDA Monitoring System: a few screenshots
* PanDA statistics for managed production tasks, excluding chaotic user analysis jobs

22
PanDA Monitoring SystemPanDA Monitoring System
• PanDA Monitoring System is its distinguishing and powerful feature It intuitively models relationships between queues, pilots and jobs, as well as I/O datasets,
in the its Web interface Provides central access point to the job’s stdout, stderr and pilot submission log, via the
Web interface – extremely useful for troubleshooting Provides plethora of other information:
Status of Pilot Factories Statistics on site usage and activity Software releases etc
Has dataset browser functionality Links to Dynamic Data Management Operations and Atlas Dashboard Provides helpful links to documentation, help and problem reporting
• Current Monitor technology platform and status: Written in Python cx_Oracle is used for database connectivity Web service based on Apache server instrumented with mod_python/mod_wsgi The existing Panda monitoring system represents a significant investment of manpower
and expertise. Its evolution was guided by user requirements, and that is reflected in the feature set.
• Current Development: The Monitor is being upgraded with better and reorganized code base, which takes
advantage of JSON/AJAX technology
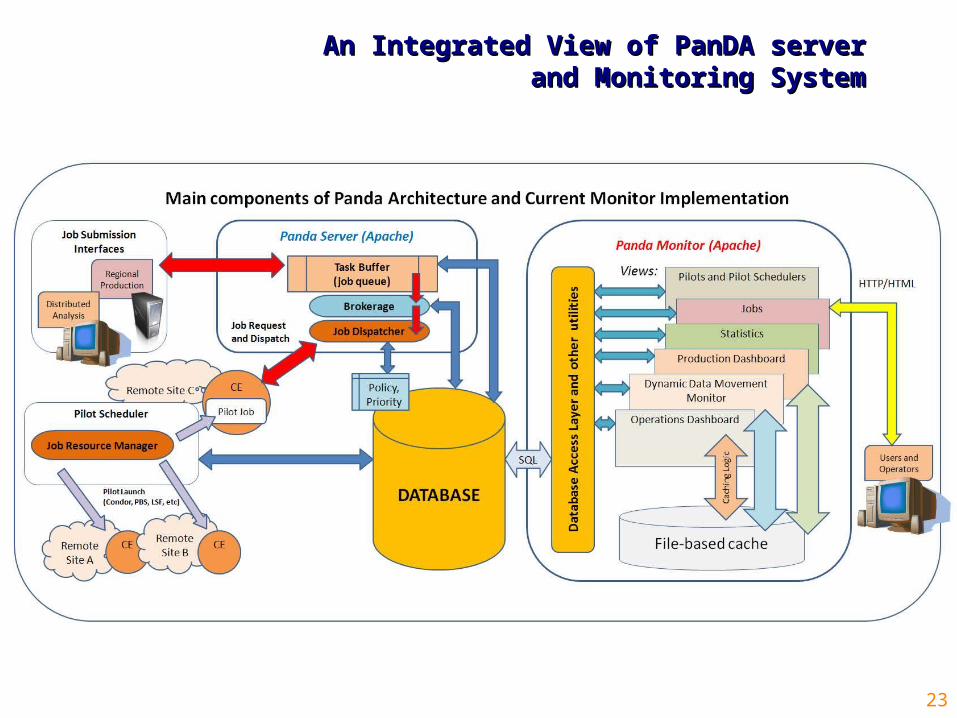
23
An Integrated View of PanDA serverAn Integrated View of PanDA serverand Monitoring Systemand Monitoring System

24
A few tools and platforms used in ATLAS and A few tools and platforms used in ATLAS and PanDAPanDA
• Monte Carlo simulation While Geant3 saw some use in early days of ATLAS, nowadays it’s exclusively G4 C++ and ROOT based geometry model
• Web services based on Apache server instrumented with mod_python, and other plug-ins as necessary Increasing use of JSON/AJAX and jQuery to serve and render content Oracle RDBMS is used as backend storage for most components of PanDA Recent migration to noSQL technology for some of the more demanding components:
Hadoop, HDFS and HBase. A Cassandra-based prototype built and tested.
• Language platform for most tools and services Python is overwhelmingly preferred as the language platform for infrastructure
development. Java used where necessary
• Additional tools and components The software stack provided by the Open Science Grid, formerly known as Virtual Data
Toolkit, forms the basis of the US ATLAS Grid Infrastructure Condor system is widely used both by itself, or as a basis for building software
components. Grid job submission (in case of PanDA limited to the Pilot Job submission) is primarily
done via Condor-G Message Queue technology is used in a few components in ATLAS

25
PanDA use outside of ATLASPanDA use outside of ATLAS
• Prior Experience Life Sciences: protein folding code (CHARMM) was run opportunistically on OSG sites
using PanDA, resulting in publications Daya Bay neutrino experiment group did a few Monte Carlo test runs (production level
statistics) on RACF utilizing PanDA, again using some of RHIC owned resources in opportunistic mode
• Current developments The Alpha Magnetic Spectrometer (AMS) collaboration has started using PanDA to run
Monte Carlo Simulation According to a recent initiative, both CMS and ATLAS experiments at the LHC are
exploring the possibility of creating shared components of their computing infrastructure, and as a part of this project, CMS is working on adapting its workflow to run on PanDA, with initial success reported
There has been a successful effort aimed at utilization of Cloud-based resources under PanDA management
• What’s needed to use PanDA to its full potential? All software components need to be Grid-ready, i.e. site-agnostic and easily configurable
to adapt to the local file system layout, software location etc Translated into English: no hardcoded paths, in particular pointing to the user’s home
directory PanDA will handle loading the correct environment provided there is configuration
capability in the payload There is little to no software that needs to be installed by prospective PanDA users,
outside of a few simple job submission scripts.

26
Project participants at BNLProject participants at BNL
• RACF and PAS Core PanDA components have been developed by the members of the Physics
Application Software (PAS) Group at BNL a few PAS personnel have prior STAR experience PAS Group has 10 members whose activities are not limited to PanDA and ATLAS A few important parts of PanDA infrastructure created by RACF experts. The is a close ongoing collaboration between PAS and RACF which allows us to make
continuous improvements to PanDA and conduct R&D on promising new technologies and their integration into ATLAS software systems (e.g. web service frameworks, noSQL databases).

27
SummarySummary
• BNL RACF is a large, state of the art and sophisticated facility, a flagship of computing for particle physics and heavy ion research in the US and a part of the vibrant ecosystem of the Open Science Grid
• STAR experiment at RHIC is using a combination of Geant3-based simulation and C++/ROOT reconstruction software, having created data and geometry adapters as necessary
• PanDA is a proven large-scale Workload Management system: Handling petabytes of data Processing a million jobs daily on hundreds of sites worldwide Supporting automated production as well as individual user and group tasks Offering extensive monitoring facilities leading to a more transparent and efficient
environment Undeniable track record in supporting cutting-edge physics research and discovery Upgrade program under way to improve scalability of the system, its robustness and ease of
use for the researchers

28
Backup SlidesBackup Slides

29
ATLAS: event data modelATLAS: event data model
Multiple data models supported and used in ATLAS• RDO: Raw Data Object
• ESD: Event Summary Data (intended for calibration)
• DPD: Derived Physics Data (for interactive analysis)
• AOD: Analysis Object Data
• TAG: Event Selection Data
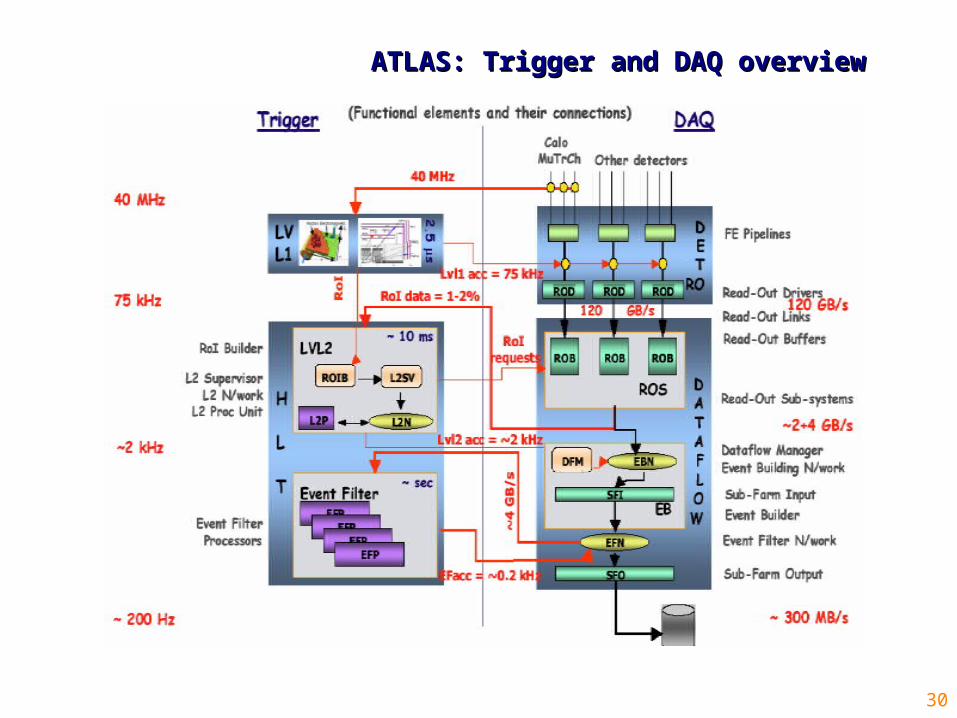
30
ATLAS: Trigger and DAQ overviewATLAS: Trigger and DAQ overview