biological databases nicky mulder: [email protected]
TRANSCRIPT


What is a database
• an organized body of related infomation www.cogsci.princeton.edu/cgi-bin/webwn
• Data collection that is:– Structured (computer readable)– Searchable– Updatable– Cross-linked– Publicly available

Biological Databases
• Make data available to public• So much data available, needs ordering• Turn data into computer-readable form• Ability to retrieve data from various sources• Can have primary (archival) or secondary databases
(curated)
Most commonly used are sequence databases
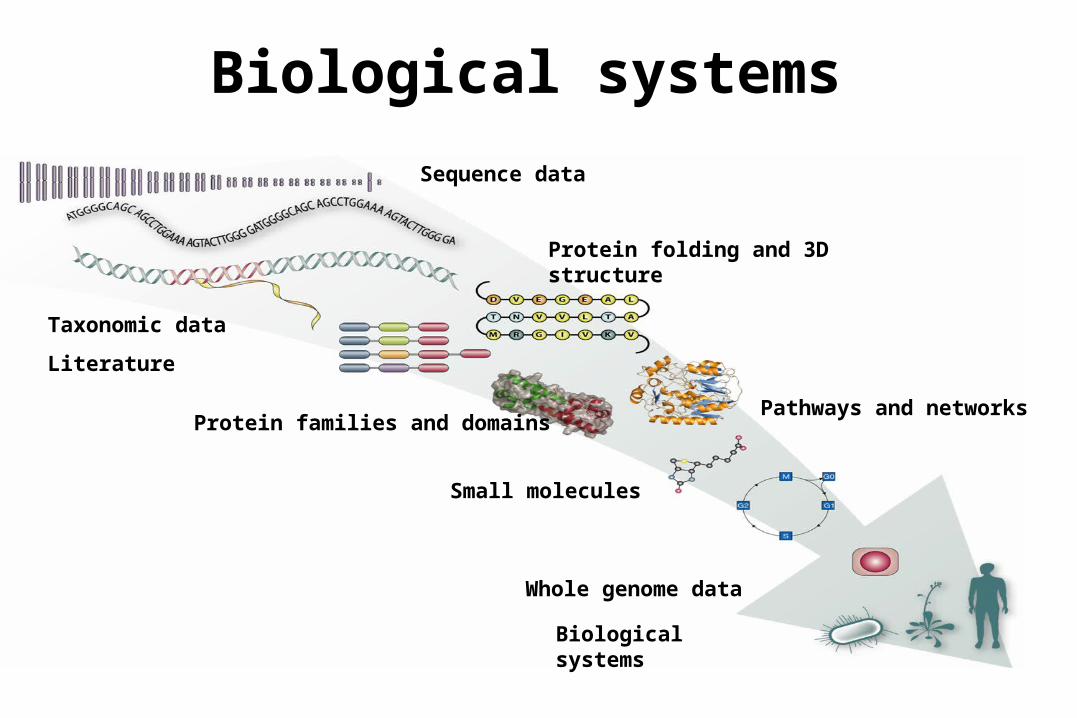
Biological systems
Taxonomic data
Literature
Protein folding and 3D structure
Small molecules
Pathways and networks
Biological systems
Protein families and domains
Whole genome data
Sequence data

Biological systems
Taxonomic data
Literature
Protein folding and 3D structure
Small molecules
Pathways and networks
Biological systems
Protein families and domains
Whole genome data
Sequence data

Biological systems
Taxonomic data
Literature
Protein folding and 3D structure
Small molecules
Pathways and networks
Biological systems
Protein families and domains
Whole genome data
Sequence data
Ontologies -GO

Sequence databases
• Used for retrieving a known gene/protein sequence• Useful for finding information on a gene/protein• Can find out how many genes are available for a given
organism• Can comparing your sequence to the others in the
database• Can submit your sequence to store with the rest• Main databases: nucleotide and protein sequence DBs

Requirements for good sequence database
• It must be complete with minimal redundancy
• It must contain as much up-to-date information (annotation) as possible on each sequence
• All the information items must be retrievable by computer programs in a consistent manner
• It must be highly interoperable with other databases

Nucleotide sequence databases
• EMBL, DDBJ, GenBank
• Data submitted by sequence owner
• Must provide certain information and CDS if applicable
• No additional annotation added
• Entries never merged –some redundancy
PromoterExons
CDS (coding sequence)

Example EMBL entry 1: general info
ID AB083336 standard; genomic DNA; MAM; 6116 BP.
AC AB083336; XX SV AB083336.1
DT 06-JAN-2005 (Rel. 82, Created) DT 06-JAN-2005 (Rel. 82, Last updated, Version 1)
DE Sus scrofa p27Kip1 gene for p27Kip1, p27Kip1R, complete cds, alternative DE splicing.
OS Sus scrofa (pig) OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; OC Eutheria; Cetartiodactyla; Suina; Suidae; Sus.
RN [1] RP 1-6116 RA Hirano K., Shintani Y., Hirano M., Kanaide H.;
RT ;
RL Submitted (08-APR-2002) to the EMBL/GenBank/DDBJ databases. RL Katsuya Hirano, Graduate School of Medical Sciences, Kyushu University, RL Division of Molecular Cardiology, Research Institute of Angiocardiology;
RL 3-1-1 Maidashi, Higashi-ku, Fukuoka, Fukuoka, 812-8582, Japan
RL (E-mail:[email protected], Tel:81-92-642-5550, RL Fax:81-92-642-5552)
RN [2] RA Shintani Y., Hirano K., Hirano M., Nishimura J., Nakano H., Kanaide H.;
RT "Cloning and Charaterization of full sequence of porcine p27Kip1 gene and RT expression of splice isoform p27Kip1R";
RL Unpublished.
References
Description of gene
Accession number

Example EMBL entry 2:
features on the sequence -CDS
FH Key Location/Qualifiers
FT source 1..6116
FT /db_xref="taxon:9823"
FT /mol_type="genomic DNA"
FT /organism="Sus scrofa"
FT /cell_type="liver"
FT /clone_lib="lambda Fix II porcine genomic DNA"
FT exon 784..1714
FT /evidence=NOT_EXPERIMENTAL
FT /note="The residue 2591 corresponds to the transcription
FT initiation site determined in human gene"
FT CDS join(1240..1714,2261..2271,5104..5160)
FT /codon_start=1
FT /gene="p27Kip1"
FT /product="p27Kip1R"
FT /protein_id="BAD83612.1"
FT /translation="MSNVRVSNGSPSLERMDARQAEYPKPSACRNLFGPVNHEELTRDL
FT EKHCRDMEEASQRKWNFDFQNHKPLEGKYEWQEVEKGSLPEFYYRPPRPPKGACKVPAQ
FT EGQGVSGTRQAVPLIGSQANSEDTHLVDQKTDAPDSQTGLAEQCTGIRKRPATDDSSPP
FT SVSLKIGMYQLNYSSVW"
Corresponding protein sequence
Feature type and location
Feature name and information

FT intron 1715..2260
FT /cons_splice=(5'site:NO,3'site:NO)
FT exon 2261..2390
FT /number=2
FT intron 2391..4494
FT /cons_splice=(5'site:NO,3'site:NO)
FT exon 4495..5824 FT /note="ending at a putative poly A site following a polyA
FT signal"
FT /number=3
FT polyA_signal 5802..5807 XX SQ Sequence 6116 BP; 1583 A; 1392 C; 1438 G; 1703 T; 0 other;
gcggccgcga gctcaattaa ccctcactaa agggagtcga ctcgatctcg aagccctttt 60
cttgttttta ttgagggaga gcttgggttc agaatacatt acaaatgcag catctattcc 120
agtctactta tagaaagacg tcctcctggg cttcccccct aagccccctg cctcccctag 180
aacagcacag acttctaggt taagggtgag ctaaccactg ctcaccccca gctaaggcac 240
ccaggctcag gggctccccg cctcccccgc tgagcgagcg gtgggggccc ccccgggaga 300
gagcccagct gggggccgag cgcccagcgg cgagcccagc tgcccgcccc tacccgctcg 360
gcgagcgagg ggaaaataag atcgccctcg gcgaggagag ggaggtcggg gctccggagc 420
Example EMBL entry 3: features on the sequence –
introns and exons
DNA sequence

Summary of information in EMBL entries
• Describes sequence type, e.g. genomic DNA, RNA, EST
• Provides taxonomy from which sequence came• Provides information on submitters and references• Describes features on a sequence NB for function,
replication, recombination, structure etc.• Shows if the DNA encodes a protein (CDS) and
provides protein sequence • Provides actual nucleotide sequence

Protein sequences
DNA
RNA
Protein
SS
Ac
Protein cleavage Protein modification
Transported to organelle or membrane
Folded into secondary or
tertiary structure
Performs a specific function
All this info needs to be captured in a database

Protein Sequence Databases• UniProt:
– Swiss-Prot –manually curated, distinguishes between experimental and computationally derived annotation
– TrEMBL - Automatic translation of EMBL, no manual curation, some automatic annotation
• GenPept -GenBank translations• RefSeq - Non-redundant sequences for certain
organisms• IPI –International protein Index –combination of
many protein sequence databases

Example of a Swiss-Prot entry 1
References
General information

Example of a Swiss-Prot entry 2
Cross-references
Functional information

Example of a Swiss-Prot entry 3Keywords
Features
Sequence

Swiss-Prot annotation mainly found in:
• Description (DE) lines – Protein name/function
• Comment (CC) lines – e.g. function, subcellular location, pathway, cofactor, disease,
etc.
• Feature table (FT) – features on the sequence, e.g. domain, active site, modifications,
variations, etc.
• Keyword (KW) lines – Set of a few hundred controlled vocabulary terms

Other parts to UniProt
• UniParc –archive of all sequences
• UniProt –Swiss-Prot + TrEMBL
• UniProt NREF100 (100% seqs merged)
• UniProt NREF90 (90% seqs merged)
• UniProt NREF50 (50% seqs merged)

Submitting sequences to EMBL or UniProt
WEB-IN -web-based submission tool for submitting DNA sequences to EMBL database.
Protein sequences submitted when the peptides have been directly sequenced. Submit through SPIN

Sequence formats
• Not MSWord, but text!• Most include an ID/name/annotation of some sort• FASTA, E.g.
>xyz some other comment ttcctctttctcgactccatcttcgcggtagctgggaccgccgttcagtcgccaatatgcgctctttgtccgcgcccaggagctacacaccttcgaggtgaccggccaggaaacggtcgccagatcaaggctcatgtagcctcactgg
Others specific to programs, e.g. GCG, abi, clustal, etc.

Literature database: PubMed/Medline
• Source of Medical-related & scientific literature• PubMed has articles published after 1965• Can search by many different means, e.g. author,
title, date, journal etc., or keywords for each• Can save queries and results• Can usually retrieve abstracts and full papers• PubMed has list of tags to search specific fields,
e.g. [AU], [TI], [DP] etc.

Search fields in PubMed
• Title Words [TI] MeSH Terms [MH] • Title/Abstract Words [TIAB] Language [LA]• Text Words [TW] Journal Title [TA]• Substance Name [NM] Issue [IP]• Subset [SB] Filter [FILTER]• Secondary Source ID [SI] Entrez Date [EDAT]• Subheadings [SH] EC/RN Number [RN]• Publication Type [PT] Author Name [AU]• Publication Date [DP] All Fields [ALL]• Personal Name as Subject [PS] Affiliation [AD]• Page Number [PG] Unique Identifiers [UID]• Title Words [TI] MeSH Major Topic [MAJR]• MeSH Date [MHDA]

Taxonomy Databases
• Most used is NCBI’s taxonomy database: http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=Taxonomy
• Provides entries for all known organisms• Provides taxonomic lineage and translation table for
organisms• Sequence entries for organism• UniProt-specific taxonomy database is Newt: • http://www.ebi.ac.uk/newt
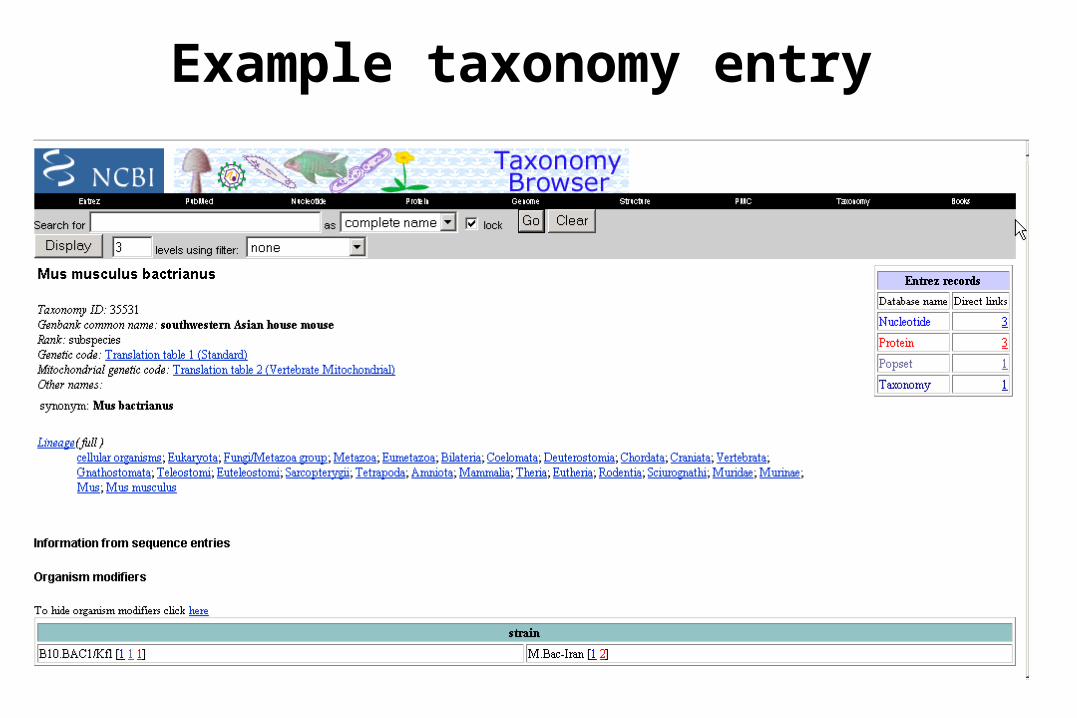
Example taxonomy entry

Where to find the databases
• Table of addresses for major databases and tools
• Nucleic Acids Research Database issue January each year
• Nucleic Acids Research Software issue –new
• Amos’s list of tools: http://www.expasy.ch/alinks.html