bioinformatics lecture xxi
TRANSCRIPT

H.E.J. Research Institute of Chemistry,International Center for Chemical and Biological Sciences,
University of Karachi,Karachi
Chem-727 (Bioinformatics)Lecture-21
Patterns and Profiles in Bioinformatics
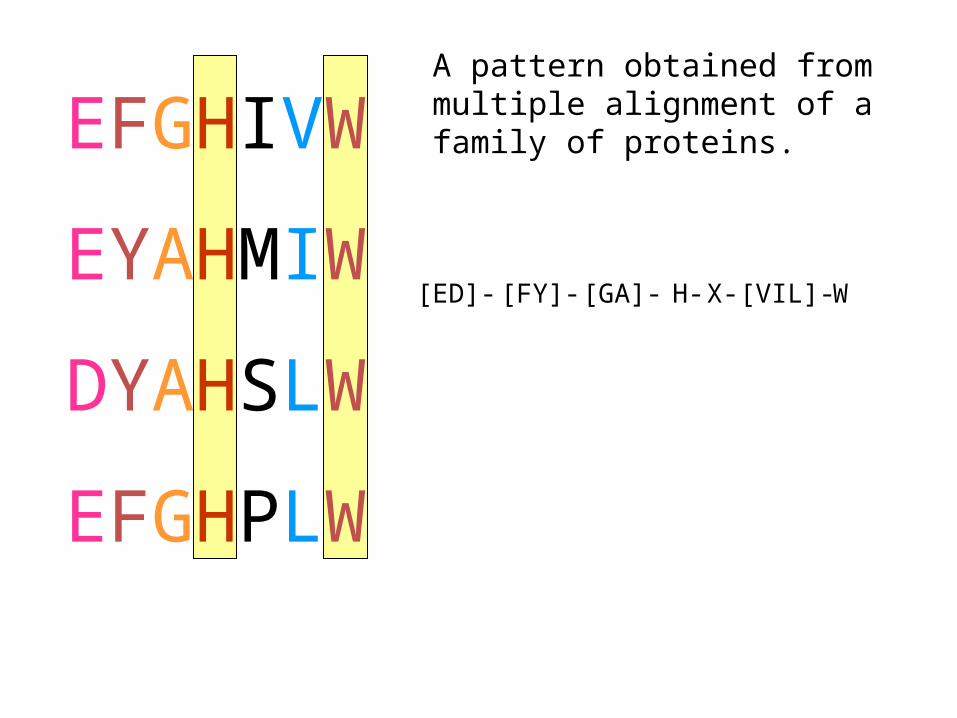
EFGHIVW
EYAHMIW
DYAHSLW
EFGHPLW
[ED]- [FY]- H-[GA]- X- [VIL]- W
A pattern obtained from multiple alignment of a family of proteins.
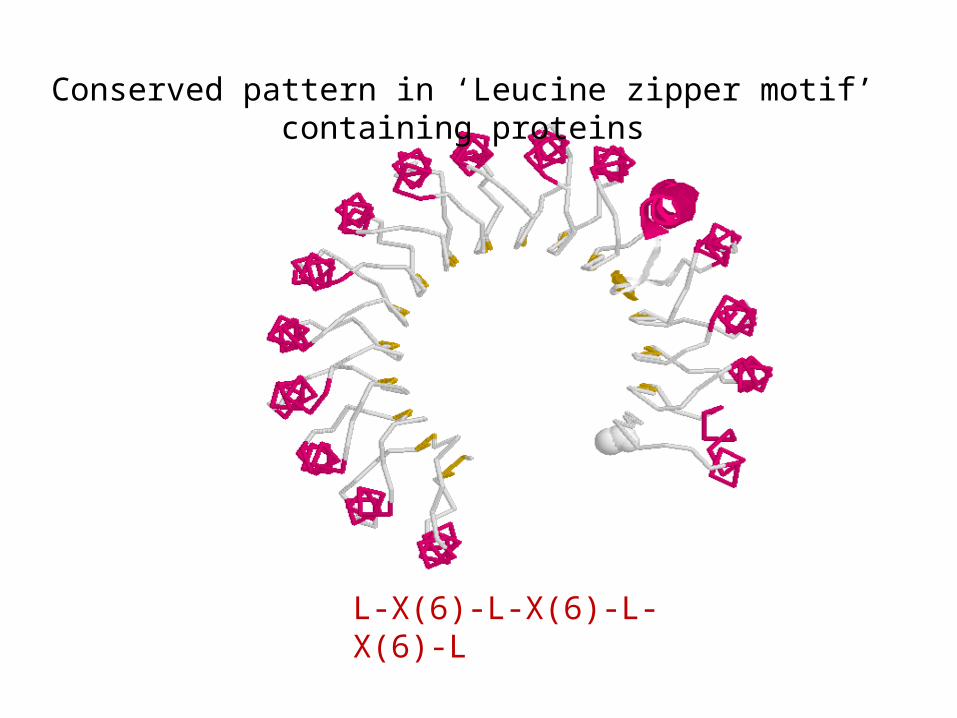
Conserved pattern in ‘Leucine zipper motif’ containing proteins
L-X(6)-L-X(6)-L-X(6)-L
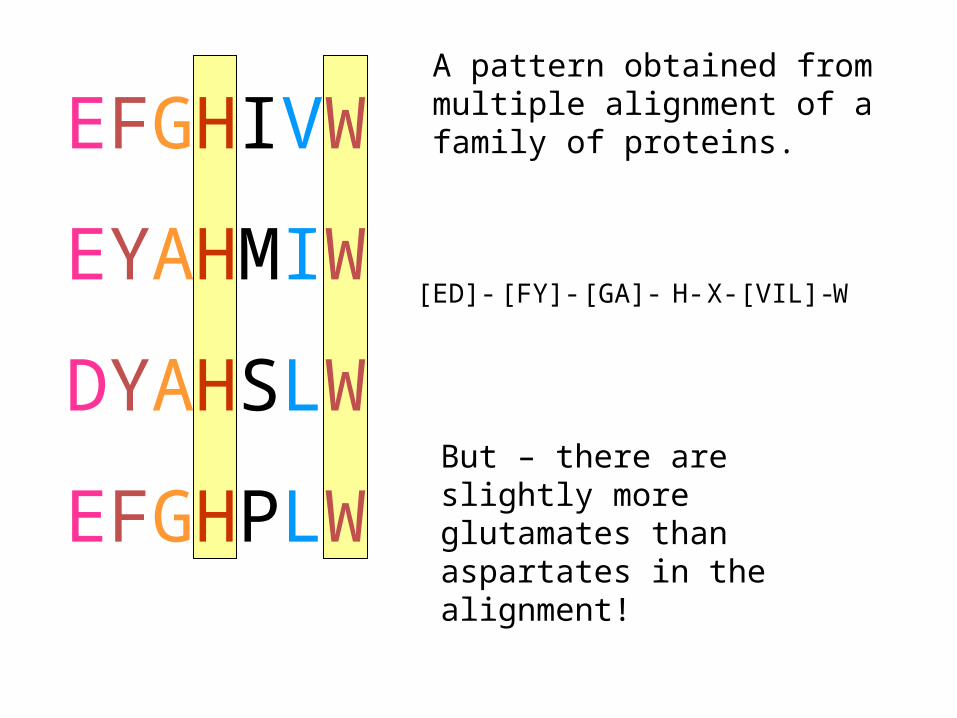
EFGHIVW
EYAHMIW
DYAHSLW
EFGHPLW
[ED]- [FY]- H-[GA]- X- [VIL]- W
A pattern obtained from multiple alignment of a family of proteins.
But – there are slightly more glutamates than aspartates in the alignment!
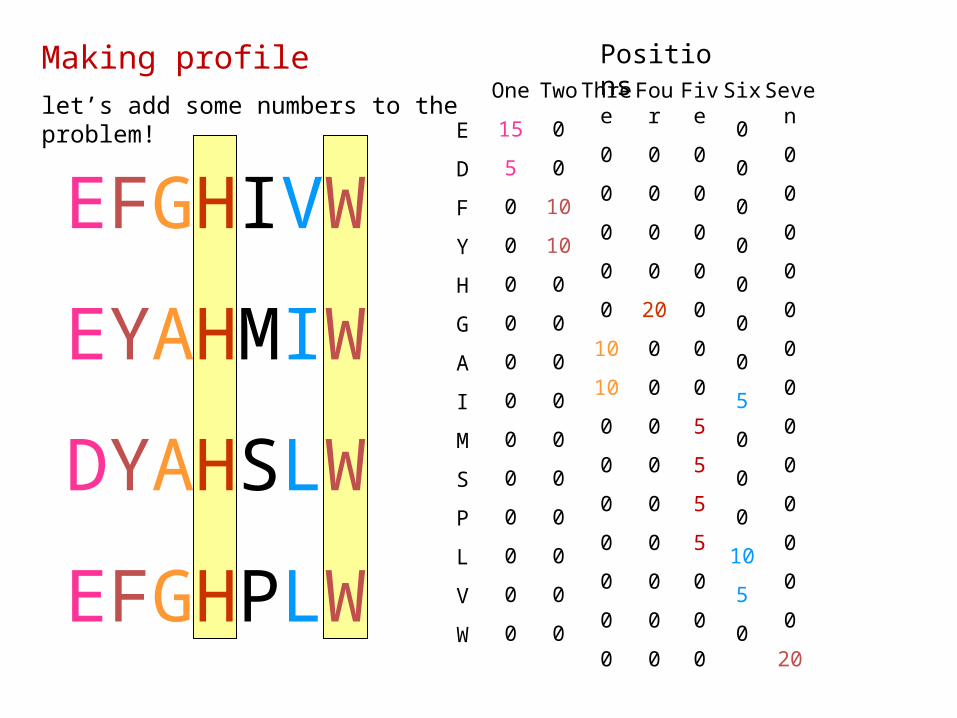
Making profilelet’s add some numbers to the problem!
EFGHIVW
EYAHMIW
DYAHSLW
EFGHPLW
E
D
F
Y
H
G
A
I
M
S
P
L
V
W
One
15
5
0
0
0
0
0
0
0
0
0
0
0
0
Two
0
0
10
10
0
0
0
0
0
0
0
0
0
0
Three
0
0
0
0
0
10
10
0
0
0
0
0
0
0
Four
0
0
0
0
20
0
0
0
0
0
0
0
0
0
Five
0
0
0
0
0
0
0
5
5
5
5
0
0
0
Six
0
0
0
0
0
0
0
5
0
0
0
10
5
0
Seven
0
0
0
0
0
0
0
0
0
0
0
0
0
20
Positions

Significance of Patterns and Profiles• Profiles express the patterns inherent in multiple alignment of a set
of homologous sequences.• They permit greater accuracy in alignments of distantly-related
sequences.• Highly conserved residues are likely to be part of the active site• Conservation patterns facilitate identification of other homologous
sequences.• Patterns help in classifying subfamilies within a set of homologues.• Residues with little conservation and are subject to indels, are likely
to be in the surface loops of protein structures.• Reliability of protein-structure prediction methods (in particular
homology modeling) increase due to information obtained from multiple alignments

PROSITE; premier bioinformatics service for identification of patterns and profiles
• PROSITE is a database of protein families and domains. It consists of entries describing the domains, families and functional sites as well as amino acid patterns, signatures, and profiles in them.
• Applications include (a) identifying possible functions of newly discovered proteins and (b) analysis of known proteins for previously undetermined activity.
• Prosite outputs contain information about biologically meaningful residues, like active sites, substrate- or co-factor-binding sites, posttranslational modification sites or disulfide bonds, to help function determination.
• E.g. prediction of phosphorylation/glycosylation sites in protein sequences.
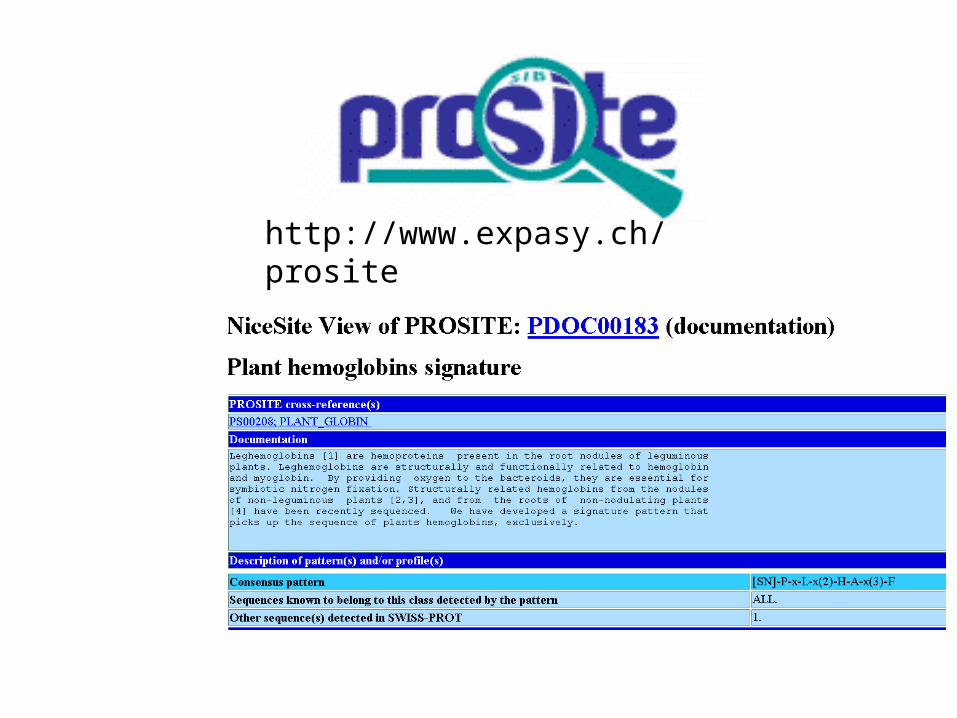
http://www.expasy.ch/prosite

http://protein.toulouse.inra.fr/prodomCG.html
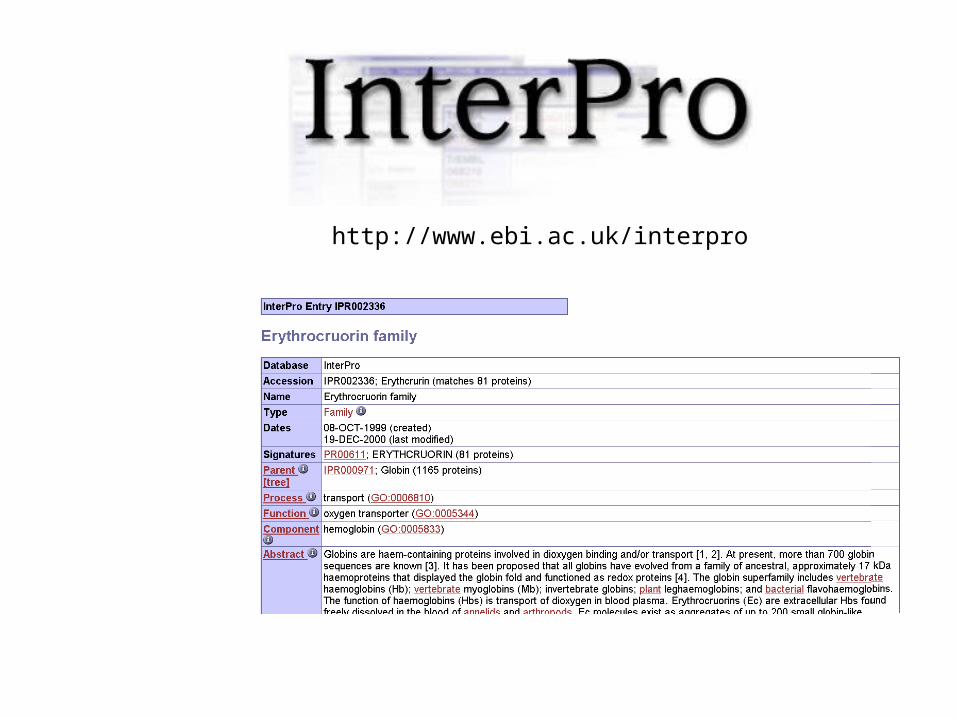
http://www.ebi.ac.uk/interpro
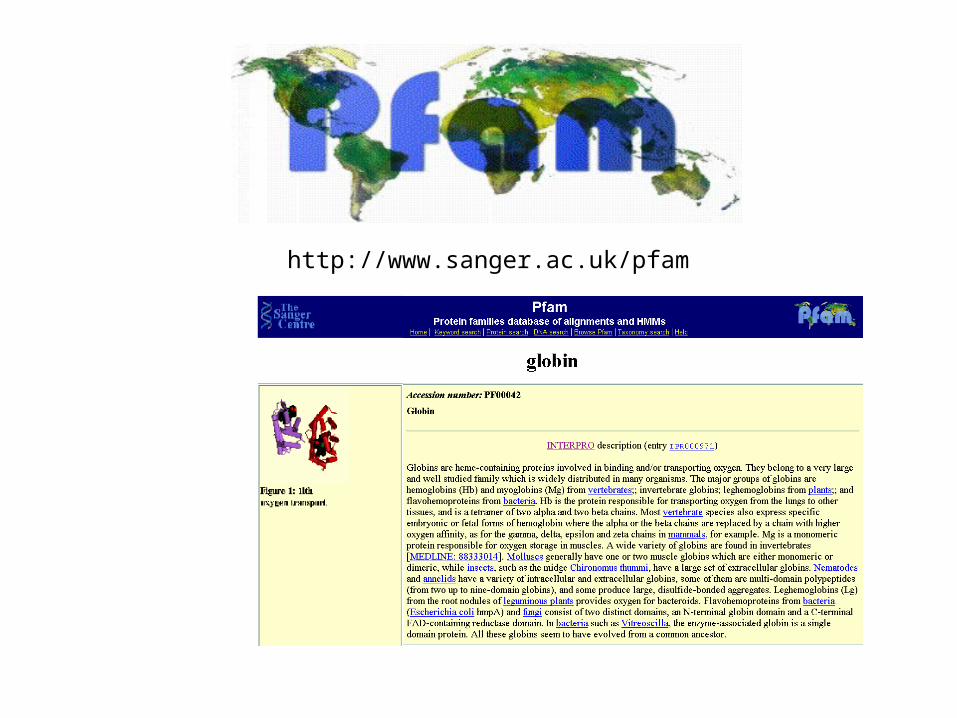
http://www.sanger.ac.uk/pfam

• Pfam-A– 7,255 Curated families with
annotation.• Pfam-B
– 365,172 families derived from Prodom.

http://smart.embl-heidelberg.de/