bioinformatics and data warehousing 1)introduction to bioinformatics 2)fasta file format 3)searching...
Post on 21-Dec-2015
217 views
TRANSCRIPT

Bioinformatics and Data Warehousing
1) Introduction to Bioinformatics
2) FASTA File Format
3) Searching Gene Sequences (BLAST)
4) Data Management in Biomedical Informatics
Michael Kane, Ph.D.Computer & Information Technology
Bindley Bioscience CenterPurdue University
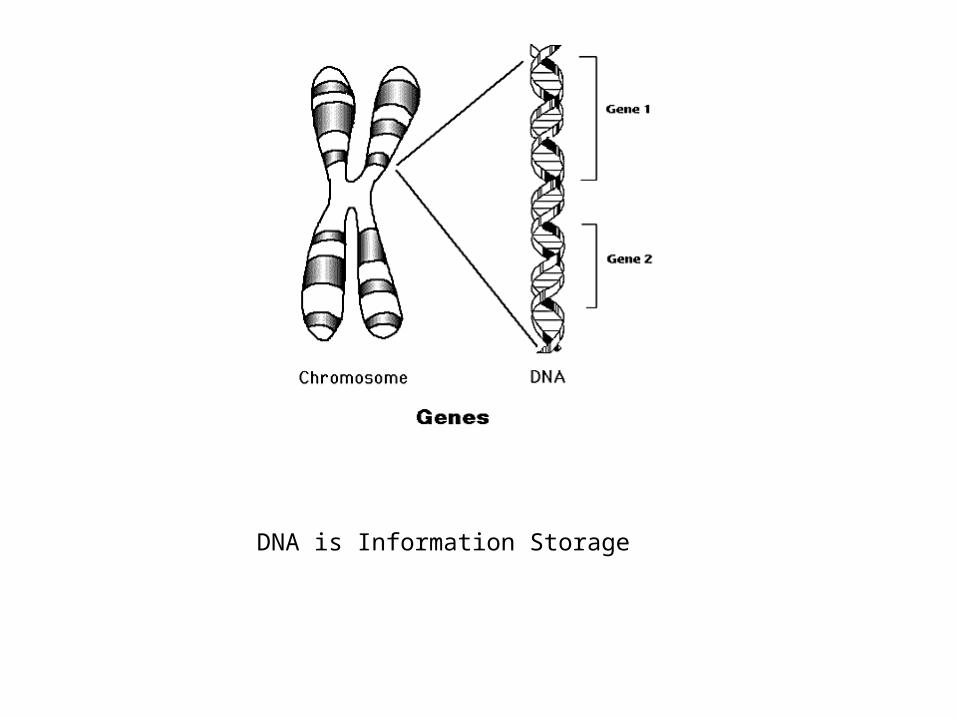
DNA is Information Storage

“Zipped Files”
Decompression
“Executable Files”

DNA is Double Stranded – One strand is the “coding strand” and the other strand is there to stabilize the DNA sequence when not in use. Double-stranded DNA is very durable in our environment.

CAGGACCATGGAACTCAGCGTCCTCCTCTTCCTTGCACTCCTCACAGGACTCTTGCTACTCCTGGTTCAGCGCCACCCTAACACCCATGACCGCCTCCCACCAGGGCCCCGCCCTCTGCCCCTTTTGGGAAACCTTCTGCAGATGGATAGAAGAGGCCTACTCAAATCCTTTCTGAGGTTCCGAGAGAAATATGGGGACGTCTTCACGGTACACCTGGGACCGAGGCCCGTGGTCATGCTGTGTGGAGTAGAGGCCATACGGGAGGCCCTTGTGGACAAGGCTGAGGCCTTCTCTGGCCGGGGAAAAATCGCCATGGTCGACCCATTCTTCCGGGGATATGGTGTGATCTTTGCCAATGGAAACCGCTGGAAGGTGCTTCGGCGATTCTCTGTGACCACTATGAGGGACTTCGGGATGGGAAAGCGGAGTGTGGAGGAGCGGATTCAGGAGGAGGCTCAGTGTCTGATAGAGGAGCTTCGGAAATCCAAGGGGGCCCTCATGGACCCCACCTTCCTCTTCCAGTCCATTACCGCCAACATCATCTGCTCCATCGTCTTTGGAAAACGATTCCACTACCAAGATCAAGAGTTCCTGAAGATGCTGAACTTGTTCTACCAGACTTTTTCACTCATCAGCTCTGTATTCGGCCAGCTGTTTGAGCTCTTCTCTGGCTTCTTGAAATACTTTCCTGGGGCACACAGGCAAGTTTACAAAAACCTGCAGGAAATCAATGCTTACATTGGCCACAGTGTGGAGAAGCACCGTGAAACCCTGGACCCCAGCGCCCCCAAGGACCTCATCGACACCTACCTGCTCCACATGGAAAAAGAGAAATCCAACGCACACAGTGAATTCAGCCACCAGAACCTCAACCTCAACACGCTCTCGCTCTTCTTTGCTGGCACTGAGACCACCAGCACCACTCTCCGCTACGGCTTCCTGCTCATGCTCAAATACCCTCATGTTGCAGAGAGAGTCTACAGGGAGATTGAACAGGTGATTGGCCCACATCGCCCTCCAGAGCTTCATGACCGAGCCAAAATGCCATACACAGAGGCAGTCATCTATGAGATTCAGAGATTTTCCGACCTTCTCCCCATGGGTGTGCCCCACATTGTCACCCAACACACCAGCTTCCGAGGGTACATCATCCCCAAGGACACAGAAGTATTTCTCATCCTGAGCACTGCTCTCCATGACCCACACTA

THEREDCAT_HSDKLSD_WASNOTHOTBUT_WKKNASDNKSAOJ.ASDNALKS_WASWET_ASDFLKSDOFIJEIJKNAWDFN_ANDMAD_WERN.JSNDFJN_YETSAD_MNSFDGPOIJD_BUTTHEFOX_SDKMFIDSJIR.JER_GOTWET_JSN.DFOIAMNJNER_ANDATEHIM.

Start with a thin 2 x 4 lego block…
Add a 2 x 2 lego block…
Add a 2 x 3 lego block…
Add a 2 x 4 lego block…

What are the comparative genome sizes of humans and other organisms being studied?
organism estimated sizeestimated
gene number
average gene densitychromo-some
number
Homo sapiens(human)
2900 million bases ~30,000 1 gene per 100,000 bases 46
Rattus norvegicus(rat)
2750 million bases ~30,000 1 gene per 100,000 bases 42
Mus musculus (mouse)
2500 million bases ~30,000 1 gene per 100,000 bases 40
Drosophila melanogaster(fruit fly)
180 million bases 13,600 1 gene per 9,000 bases 8
Arabidopsis thaliana(plant)
125 million bases 25,500 1 gene per 4000 bases 5
Caenorhabditis elegans(roundworm)
97 million bases 19,100 1 gene per 5000 bases 6
Saccharomyces cerevisiae(yeast)
12 million bases 6300 1 gene per 2000 bases 16
Escherichia coli(bacteria)
4.7 million bases 3200 1 gene per 1400 bases 1
H. influenzae (bacteria)
1.8 million bases 1700 1 gene per 1000 bases 1
Genome size does not correlate with evolutionary status, nor is the number of genes proportionate with genome size.

>gi|1924940|emb|CAA67058.1| myosin-IF [Homo sapiens] QEKLTSRKMDSRWGGRSESINVTLNVEQAAYTRDALAKGLYARLFDFLVEAINRAMQKPQEEYSIGVLDI YGFEIFQKNGFEQFCINFVNEKLQQIFIELTLKAEQEEYVQEGIRWTPIQYFNNKVVCDLIENKLSPPGI MSVLDDVCATMHATGGGADQTLLQKLQAAVGTHEHFNSWSAGFVIHHYAGKVSYDVSGFCERNRDVLFSD LIELMQSSDQAFLRMLFPEKLDGDKKGRPSTAGSKIKKQANDLVATLMRCTPHYIRCIKPNETKHARDWE ENRVQHQVEYLGLKENIRVRRAGFAYRRQFAKFLQRYAILTPETWPRWRGDERQGVQHLLRAVNMEPDQY QMGSTKVFVKNPESLFLLEEVRERKFDGFARTIQKAWRRHVAVRKYEEMREEASNILLNKKERRRNSINR NFVGDYLGLEERPELRQFLGKKERVDFADSVTKYDRRFKPIKRDLILTPKCVYVIGREKMKKGPEKGPVC EILKKKLDIQALRGVSLSTRQDDFFILQEDAADSFLESVFKTEFVSLLCKRFEEATRRPLPLTFSDTLQF RVKKEGWGGGGTRSVTFSRGFGDLAVLKVGGRTLTVSVGDGLPKNSKPTGKGLAKGKPRRSSQAPTRAAP GAPQGMDRNGAPLCPQGGAPCPLEKFIWPRGHPQASPALRPHPWDASRRPRARPPSEHNTEFLNVPDQGM AGMQRKRSVGQRPVPVGRPKPQPRTHGPRCRALYQYVGQDVDELSFNVNEVIEILMEDPSGWWKGRLHGQ EGLFPGNYVEKI
FASTAFileFormat
TinySeqXML
<?xml version="1.0"?><!DOCTYPE TSeq PUBLIC "-//NCBI//NCBI TSeq/EN" "http://www.ncbi.nlm.nih.gov/dtd/NCBI_TSeq.dtd"><TSeq> <TSeq_seqtype value="nucleotide"/> <TSeq_gi>1924939</TSeq_gi> <TSeq_accver>X98411.1</TSeq_accver> <TSeq_taxid>9606</TSeq_taxid> <TSeq_orgname>Homo sapiens</TSeq_orgname> <TSeq_defline>Homo sapiens partial mRNA for myosin-IF</TSeq_defline> <TSeq_length>2711</TSeq_length> <TSeq_sequence>CAGGAGAAGCTGACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGT……</TSeq>

>GENE NUMBER ONEAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER TWOAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER THREEAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER FOURAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER FIVEAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER SIXAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........>GENE NUMBER SEVENAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC.............>GENE NUMBER TWENTY MILLIONAGCTGCTAGTAGAGTCGCTCGGATAGGACTGCTAGCTGC........
FASTA File Format DATABASE (DATA WAREHOUSE)

DYNAMIC PROGRAMMING and SEQUENCE SEARCHES
'Dynamic programming' is an efficient programming technique for solving certain combinatorial problems. It is particularly important in bioinformatics as it is the basis of sequence alignment algorithms for comparing protein and DNA sequences.
In the bioinformatics application Dynamic Programming gives a spectacular efficiency gain over a purely recursive algorithm.
Don't expect much enlightenment from the etymology of the term 'dynamic programming,' though. Dynamic programming was formalized in the early 1950s by mathematician Richard Bellman, who was working at RAND Corporation on optimal decision processes. He wanted to concoct an impressive name that would shield his work from US Secretary of Defense Charles Wilson, a man known to be hostile to mathematics research. His work involved time series and planning—thus 'dynamic' and 'programming' (note, nothing particularly to do with computer programming). Bellman especially liked 'dynamic' because "it's impossible to use the word dynamic in a derogatory sense"; he figured dynamic programming was "something not even a Congressman could object to.”

The following is an example of global sequence alignment using Needleman/Wunsch techniques. For this example, the two sequences to be globally aligned are:
G A A T T C A G T T A (sequence #1) G G A T C G A (sequence #2)
Initialization Step
Since this example assumes there is no gap opening or gap extension penalty, the first row and first column of the matrix can be initially filled with 0.
DYNAMIC PROGRAMMING and SEQUENCE SEARCHES

Matrix Fill Step
DYNAMIC PROGRAMMING and SEQUENCE SEARCHES

Traceback Step
(Seq #1) A |(Seq #2) A
(Seq #1) T A |(Seq #2) _ A
(Seq #1)T T A |(Seq #2)_ _ A
G A A T T C A G T T A| | | | | | G G A _ T C _ G _ _ A
_ G A A T T C A G T T A | | | | | |G G A _ _ T C _ G _ _ A
There are multiple solutions to this alignment, and most dynamic programming algorithms print out only a single solution.
DYNAMIC PROGRAMMING and SEQUENCE SEARCHES

BLAST (Basic Local Alignment Search Tool)
Why is BLAST so fast?
By preindexing all the possible 11-letter words into the database records (411 = 4,194,304).
.
.GTCGTAGTCGATCGTAGTCGCTCGTAGTCG..
Steps: 1) Find all the 11-letter words in your query sequence, plus a few variations. 2) Look these up in the 11-letter-word index. 3) Retrieve all sequences containing those words. 4) Use a rigorous algorithm (e.g. Smith-Waterman) to extend the match in both directions

>UNKNOWN GENE SEQUENCEAGGACCATGGAACTCAGCGTCCTCCTCTTCCTTGCACTCCTCACAGGACTCTTGCTACTCCTGGTTCAGCGCCACCCTAACACCCATGACCGCCTCCCACCAGGGCCCCGCCCTCTGCCCCTTTTGGGAAACCTTCTGCAGATGGATAGAAGAGGCCTACTCAAATCCTTTCTGAGGTTCCGAGAGAAATATGGGGACGTCTTCACGGTACACCTGGGACCGAGGCCCGTGGTCATGCTGTGTGGAGTAGAGGCCATACGGGAGGCCCTTGTGGACAAGGCTGAGGCCTTCTCTGGCCGGGGAAAAATCGCCATGGTCGACCCATTCTTCCGGGGATATGGTGTGATCTTTGCCAATGGAAACCGCTGGAAGGTGCTTCGGCGATTCTCTGTGACCACTATGAGGGACTTCGGGATGGGAAAGCGGAGTGTGGAGGAGCGGATTCAGGAGGAGGCTCAGTGTCTGATAGAGGAGCTTCGGAAATCCAAGGGGGCCCTCATGGACCCCACCTTCCTCTTCCAGTCCATTACCGCCAACATCATCTGCTCCATCGTCTTTGGAAAACGATTCCACTACCAAGATCAAGAGTTCCTGAAGATGCTGAACTTGTTCTACCAGACTTTTTCACTCATCAGCTCTGTATTCGGCCAGCTGTTTGAGCTCTTCTCTGGCTTCTTGAAATA
http://www.ncbi.nlm.nih.gov/

Genomic Database(DATA WAREHOUSE)
>GENEAgtgctcgatagatcgctcgcata…
RESULTS
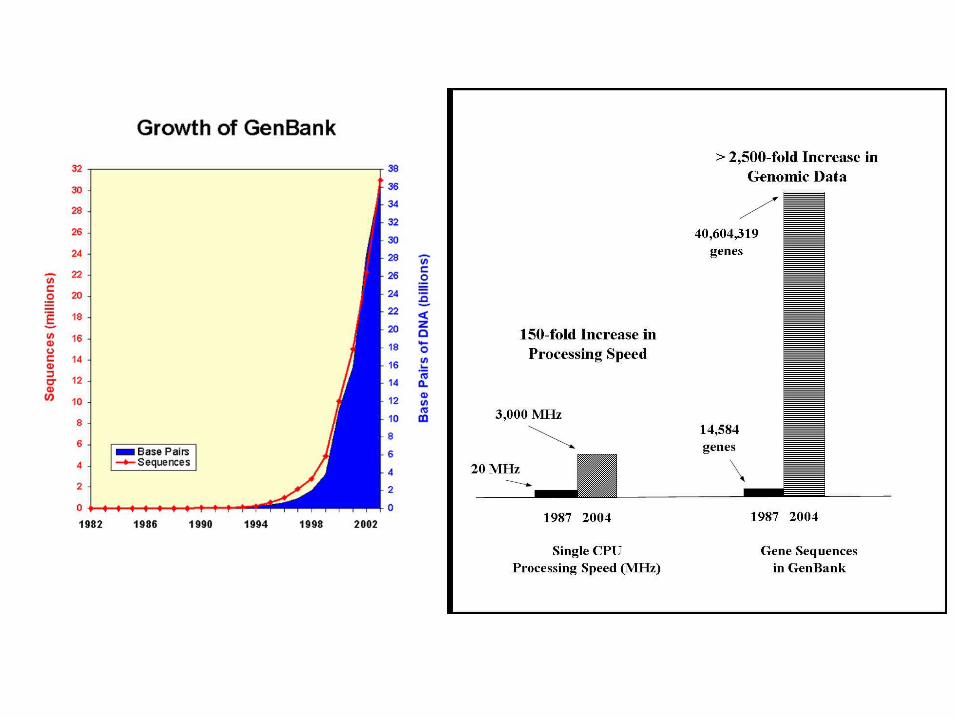
New Gene Sequences (1 per second!)
Results DB
Gene Cloning DB