bi-weekly btp presentation bhargava reddy 110050078 14-10-2014, tuesday
TRANSCRIPT

Bi-Weekly BTP presentation
Bhargava Reddy110050078
14-10-2014, Tuesday

Contents
• Defining Entropy of a Language• Calculating entropy of a language• Letter and word frequencies• Entropy of various World Languages• Entropy of Telugu• Indus Script• Entropy of Word Ordering

Motivation for Entropy in English
• Aoccdrnig to rseearchat at Elingsh uinervtisy, it deosn't mttaer in waht odrer the ltteers ina wrod are, the olny iprmoatnt tihng is taht the frist and lsat ltteer is at the rghit pclae. The rset canbe a toatl mses and youcansitll raed it wouthit a porbelm. Tihs is bcuseae we do not raed ervey lteter by it slef but the wrod as a wlohe.

The actual sentence
• According to research at English university, it doesn't matter in what order the letters in a word are, the only important thing is that the first and last letter is at the right place. The rest can be a total mess and you can still read it with out a problem. This is because we do not read every letter by it self but the word as a whole.

Letters removed in words
• Acc__ding t_ res_a_ch a_ En_l_sh _ni_ersity, it do__n’t ma_t_r in wh__ or_er t_e l_tt_rs in _ wo__ are, t_e onl_ im_or_an_ thi__ is tha_ th_ fi_st an_ l_st le__er is a_ the ri__t pl__e. T_e re_t can b_ _ tot_l mes_ a_d yo_ can st__l re_d i_ with_ut _ pro__em. Thi_ i_ beca__e we do_’t read ev_r_ let__r by i_sel_ but the w__d as _ who__
• 25% of the letters have been removed from the actual sentence

The Formula for Entropy
Where K is a positive constant
It is a statistical parameter which measures in a certain sense, how much information is produced from the source
Based on Shannon's: A Mathematical Theory of Communication

Entropy of Language
• If the language is translated into binary digits (0 or 1) in the most efficient way, the entropy H is the average number or binary digits required per letter of the original language.• The redundancy measures the amount of constraint imposed on a
text in the language due to its statistical structure• Ex: In english: The frequency of letter E, Strong tendency that H
follows T or U to follow Q
Based on Shannon's: Prediction and Entropy of Printed English

Entropy calculation from the statistics of English• Entropy H can be calculated by a series of approximations , ,…, • Each values above successively takes more and more of the statistics
of the language into account and approach H as a limit• FN is called the N-gram entropy: It measures the amount of
information or entropy due to statistics extending over N adjacent letters of text.
Based on Shannon's: Prediction and Entropy of Printed English

Entropy of English
Here: bi is a block of N-1 letters
j is an arbitrary letter following bi
is the probability of the N-gram bi ,j
is the conditional probability of the letter j after the block bi , which is given by
Based on Shannon's: Prediction and Entropy of Printed English

Interpretation of the equation
• It is the average uncertainty (conditional entropy) of the next letter j when the preceding N-1 letter are known• As N is increased, FN includes longer and longer range statistics and
the entropy, H, is given by the limiting value of FN as
Based on Shannon's: Prediction and Entropy of Printed English

Calculations of the FN
• If we ignore the spaces and punctuation then we can give a definition to it as : bits per letter• This involves just the letter frequencies can thus be calculated as:
bits per letter• Di-gram assumption is taken here
bits per letter
Based on Shannon's: Prediction and Entropy of Printed English
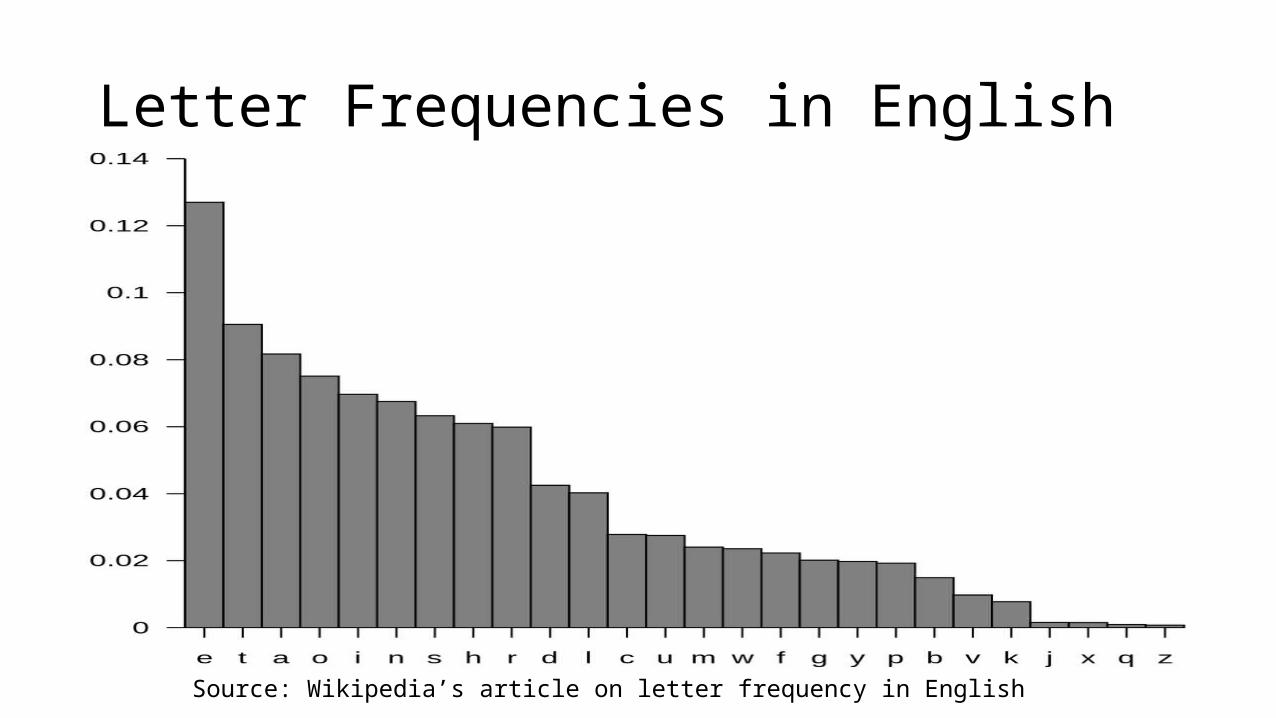
Letter Frequencies in English
Source: Wikipedia’s article on letter frequency in English

Calculation of higher FN
• Similar calculations for F3 gives the value as 3.3 bits• The tables of N-gram frequencies are not available for N>3 as a result
F4,F5,F6 cannot be calculated the same way• Word frequencies are used to calculate to assist in such situations• Let us look at the log-log paper of the probabilities of words against
frequency rank
Based on Shannon's: Prediction and Entropy of Printed English

Word Frequencies• The most frequent word in english “the” has
a probability .071 and this is plotted against 1
• The next one is “of” with .034 and is plotted against 2 and so on
• If we used log scales for both the x,y axes we have observed that we have a straight line
• Thus if pn is the frequency of the nth most frequent word we have roughly
The above equation is termed as Ziff’s law
Based on Shannon's: Prediction and Entropy of Printed English

Inferences
• The above equation can definitely not be true if we take it indefinitely since we know that is infinite• We will assume that the equation is true up to the value such that the
sum is equal to 1 and the other probabilities are 0• Calculations have determined that it occurs at the value occurs at the
word rank 8727• Thus the entropy is then:
• Which is 11.82/4.5 = 2.62 bits per letter since the average word in English is 4.5 letters
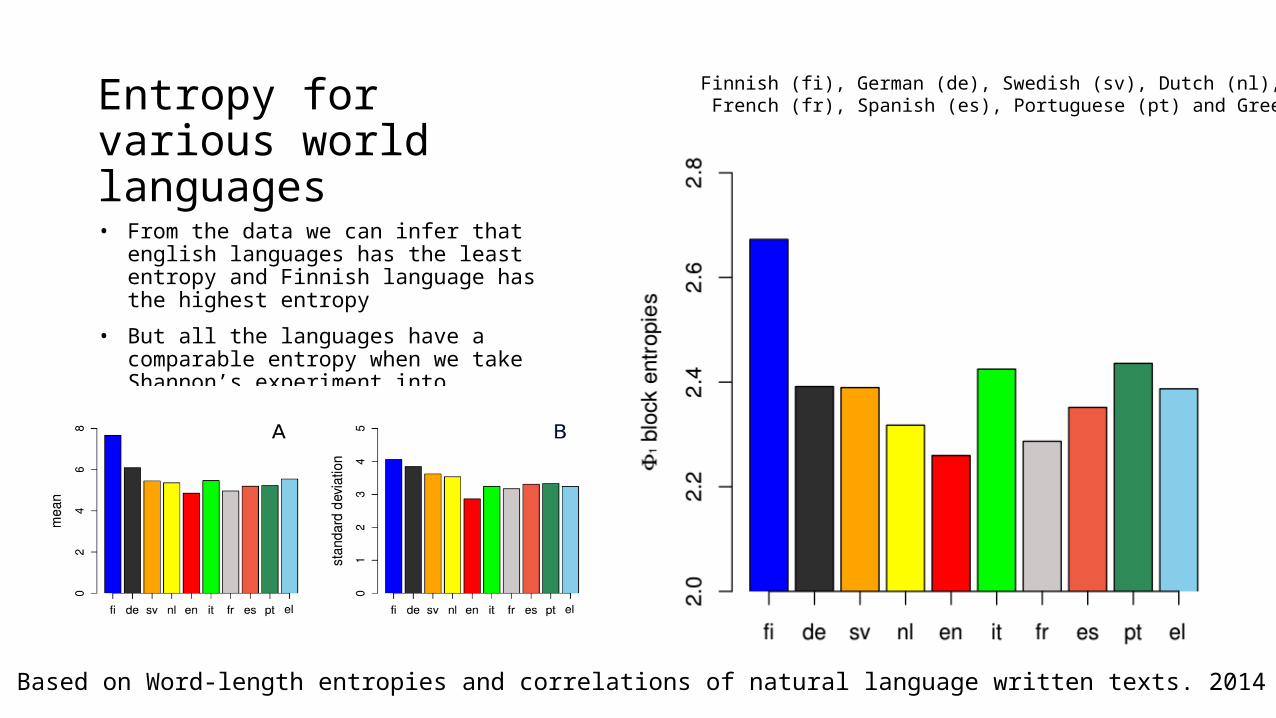
Entropy for various world languages• From the data we can infer that english languages
has the least entropy and Finnish language has the highest entropy
• But all the languages have a comparable entropy when we take Shannon’s experiment into consideration
Finnish (fi), German (de), Swedish (sv), Dutch (nl), English (en), Italian (it), French (fr), Spanish (es), Portuguese (pt) and Greek (el)
Based on Word-length entropies and correlations of natural language written texts. 2014

Ziff like plots for various world languages
Based on Word-length entropies and correlations of natural language written texts. 2014

Entropy of Telugu Language
• Indian languages are highly phonetic which makes the computation of the entropy to be a rather difficult task• Thus entropy for Telugu has been calculated by converting it into
english language and using Shannon’s experiment. The entropy is calculated in 2 ways:
1. Converting into English and then considering them as English letters2. Converting into English and then considering them as Telugu letters
Based on Entropy of Telugu. Venkata Ravinder Paruchuri. 2011

Telugu Language Entropy
Based on Entropy of Telugu. Venkata Ravinder Paruchuri. 2011

Inferences
• The entropy of Telugu is higher than that of English, which means that Telugu is more succinct than English and each syllable in Telugu(as in other Indian languages) contains more information compared to English
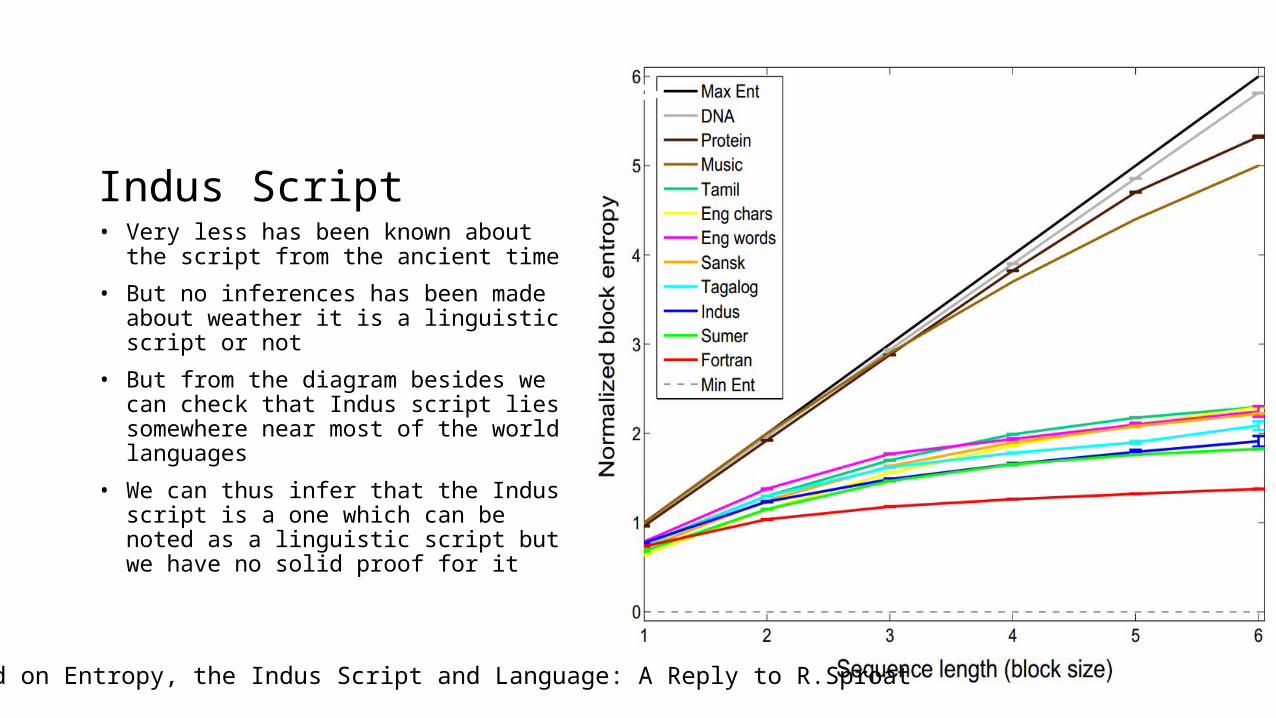
Indus Script• Very less has been known about the script
from the ancient time
• But no inferences has been made about weather it is a linguistic script or not
• But from the diagram besides we can check that Indus script lies somewhere near most of the world languages
• We can thus infer that the Indus script is a one which can be noted as a linguistic script but we have no solid proof for it
Based on Entropy, the Indus Script and Language: A Reply to R.Sproat
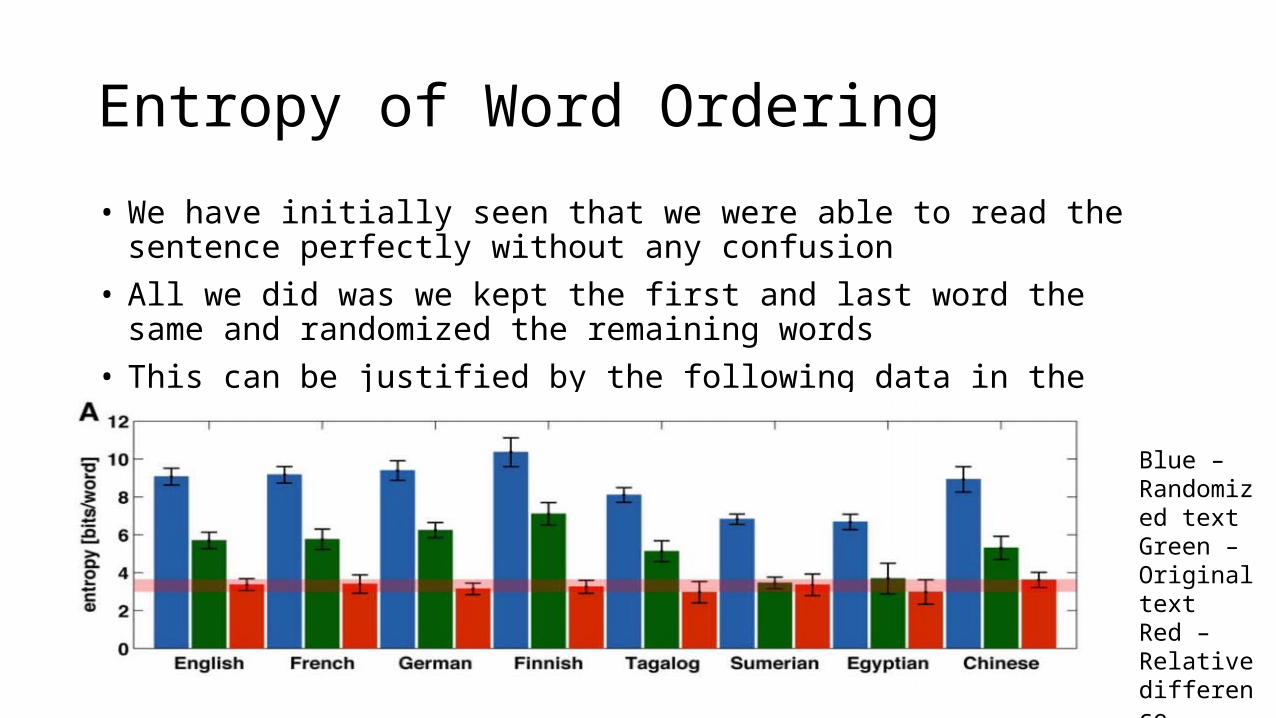
Entropy of Word Ordering
• We have initially seen that we were able to read the sentence perfectly without any confusion
• All we did was we kept the first and last word the same and randomized the remaining words
• This can be justified by the following data in the figure
Blue – Randomized textGreen – Original textRed – Relative difference

References
• Prediction and Entropy of Printed English. C.E.Shannon. The Bell System Technical Journal. January 1951• Word-length entropies and correlations of natural language written texts.
Maria Kalimeri, Vassilios Constantoudis, Constantinos Papadimitrious. ArXiV conference 2014• Entropy of Telugu. Venkata Ravinder Paruchuri. 2011• Entropy, the Indus Script and Language: A Reply to R.Sproat. Rajesh PN Rao,
Nisha Yadav, Mayank Vahia, Hrishikesh. Computational Linguistics 36(4). 2010• Universal Entropy of Word Ordering Across Linguistic Families. Marcelo A.
Montemurro, Zanette DH. PLoS ONE 6(5): e19875. doi:10.1371/journal.pone.0019875. 2011