best practices for implementing arm cortex -a12 processor ... · pdf filebest practices for...
TRANSCRIPT

Best Practices for Implementing ARM Cortex® -A12 Processor and MaliTM-T6XX GPUs for Mid-Range Mobile SoCs.

2 © 2012 Cadence Design Systems, Inc. All rights reserved.
Joint team working on ARM® Cortex® -A12 iRM flow
iRM content: • Design constraints
• Floorplan files
• CPF files for low power flows.
• Cadence flow scripts, e.g. RC & EDI, based on Foundation flow scripts.
• Makefile to run the whole flow.
• iRM User Guide document
Cortex-A12: ARM-Cadence collaboration
Optimized
EDA Flow
Evaluate
Cortex-A12
RTL Support
CPF
EDA Tool
Releases
Optimized
Physical IP
iRM
Cadence ARM Experienced
support at EAC
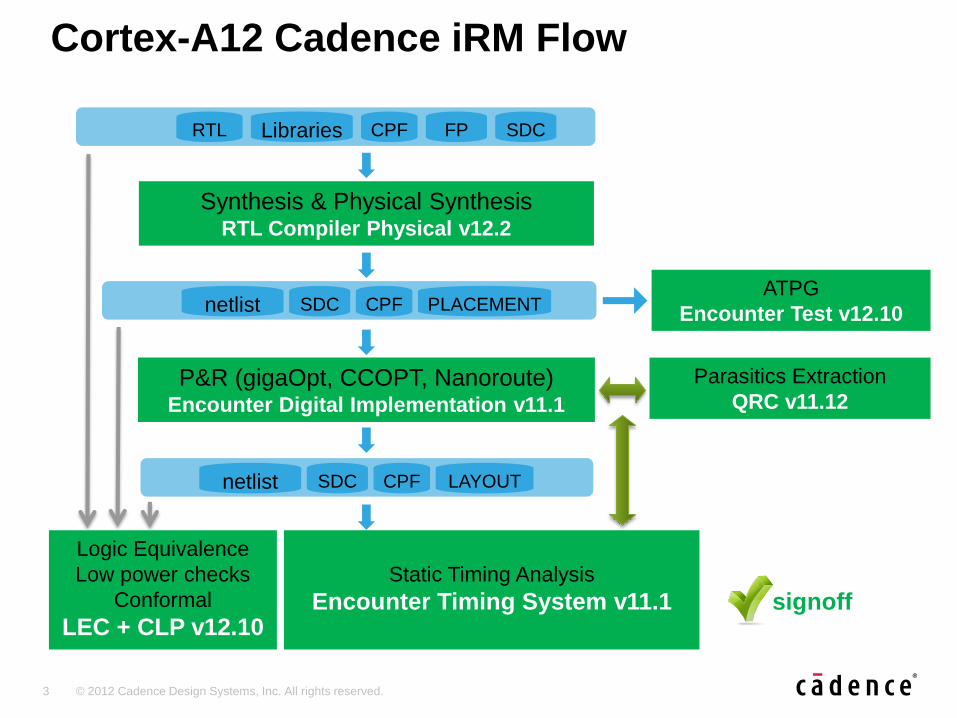
3 © 2012 Cadence Design Systems, Inc. All rights reserved.
Synthesis & Physical Synthesis RTL Compiler Physical v12.2
P&R (gigaOpt, CCOPT, Nanoroute) Encounter Digital Implementation v11.1
ATPG
Encounter Test v12.10
Parasitics Extraction
QRC v11.12
RTL Libraries CPF FP SDC
netlist CPF LAYOUT SDC
netlist CPF PLACEMENT SDC
Static Timing Analysis
Encounter Timing System v11.1
Logic Equivalence
Low power checks
Conformal
LEC + CLP v12.10 signoff
Cortex-A12 Cadence iRM Flow

4 © 2012 Cadence Design Systems, Inc. All rights reserved.
• Extend collaboration started on ARM® Mali™-T604 back in 2011
• Technology used: – TSMC 28nm HPM
– Base C35 LVT, Base C35 SVT
– PMK C35 HVT, PMK C35 SVT, PMK C35 LVT
• Goals – Develop the optimal methodology to achieve PPA targets
– Deliver a set of customer ready deployable scripts
– Deliver a methodology that can be used to implement the Mali-T678-MP4 being developed for the ARM Reference Platform
– Demonstrate Cadence methodology for future Mali GPU’s.
Mali T678: ARM-Cadence collaboration
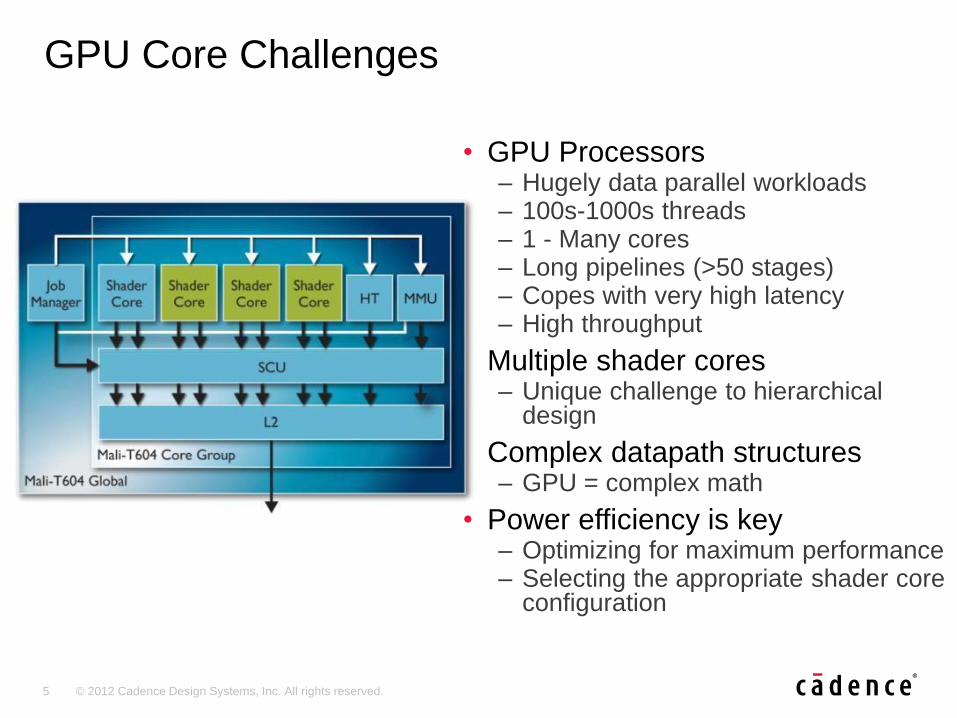
5 © 2012 Cadence Design Systems, Inc. All rights reserved.
• GPU Processors – Hugely data parallel workloads – 100s-1000s threads – 1 - Many cores – Long pipelines (>50 stages) – Copes with very high latency – High throughput
• Multiple shader cores – Unique challenge to hierarchical
design
• Complex datapath structures – GPU = complex math
• Power efficiency is key – Optimizing for maximum performance – Selecting the appropriate shader core
configuration
GPU Core Challenges

6 © 2012 Cadence Design Systems, Inc. All rights reserved.
Mali-T678 iRM floorplan
Core group 0
Core group 1 • 9 power domains
• 8 switchable power domains
• Bottom up flow with 6 share core macros
I/O
pins

7 © 2012 Cadence Design Systems, Inc. All rights reserved.
Flexible Hierarchical Implementation Flow
Top Level Creation
Shader Core Creation
• ARM Mali GPU supports multiple numbers of shader cores – Each shader core is 2.6M
instances – 2-8 shader cores in a
configuration
• Flow must support separate shader core / top level – Supporting parallel runs – Goal is to minimize iterations
regardless of configuration
• Developed hierarchical RTL synthesis strategy – Complementary to proven
hierarchical implementation flow
Shader Core
Synthesis
Shader Core
P&R
ILM
Creation
Lib/lef
Creation
Top Level
Synthesis
Top
P&R and
Assembly
Top
Only
Netlist

8 © 2012 Cadence Design Systems, Inc. All rights reserved.
• MBCI Flow – Merge single-bit flops into multi-bit
version of flops – dual or quad flop versions (requires MB cells in library)
– QOR driven multi-bit mapping
– Clean verification flow with LEC
• Benefit – Sharing clock enables reduces power
• Impact on Mali-T678 – Did MBCI on the Shader
– 88% conversion rate (swap ratio) – Using 2x only flops
– No loss in performance
Multi-Bit Cell Inferencing (MBCI) Memory
18%
IO 23%
Random Logic 18%
Clock tree 27%
Datapath 14%
CK
0
20
40
60
80
100
Customer Design Swap Ratios
CK

9 © 2012 Cadence Design Systems, Inc. All rights reserved.
Base Logical
MBCI
WNS -0.121ns -0.129ns
TNS -104.69ns -140.84ns
Utilization 77.04% 73.39%
Seq Power 97.55 47.18
Total Power 450.67 277.60
Reduce Power up to 10% while meeting Timing Physical Aware Multi-Bit Cell Inferencing (PA-MBCI)
Physical
MBCI
-0.123ns
-104.49ns
74.59%
65.04
345.77
No QoS loss
Same frequency
Good Balance
between Timing
and Power
Only cells placed within
a given threshold
distance are merged

10 © 2012 Cadence Design Systems, Inc. All rights reserved.
Key Shader Core Challenges and Solutions
• Clock SI − Challenge: much higher SI at 28nm, too much
congestion to fix traditionally
− Solution: use CCOpt to shield nets higher in the clock tree − No impact to congestion
• Data SI − Challenge: predictable closure flow
− Solution: tighten pre-SI timing to enable more pre-IPO transforms − Cuts down on updates post-route
− Fewer jumps in closure
• Hold Fixing − Challenge: lots more hold fixes needed at
28nm − Shader core had regions of high density
− Solution: used cell padding on registers to allow room for hold buffer insertion

11 © 2012 Cadence Design Systems, Inc. All rights reserved.
Key technologies for implementing high-performance GHz + ARM processors and Mali GPU's

12 © 2012 Cadence Design Systems, Inc. All rights reserved.
• Multi-objective low-power and physical aware global synthesis
• Better WNS and total power
• Tighter correlation to EDI System
• Multi-bit cell inference (MBCI)
• Improved TAT
RC/RCP
• Fine grained, multi-threaded logic transformations + TNS driven optimization
• Dynamic/leakage power minimization
• Route-driven/layer-aware opt
• Much improved WNS/TNS/TAT*
GigaOpt
• CCOpt improves even fine-tuned ARM processor timing
• Useful skew based time borrowing across entire pipeline chain
• Improved MMMC/OCV/setup/hold
• Improved PPA than std. CTS solution
CCOpt *WNS = worst negative slack
TNS = total negative slack
TAT = turn-around-time
CCOpt=Clock Concurrent
Optimization
Key improvements to Encounter digital tools In
-Desig
n S
ign
off
(RC
X, T
imin
g, P
ow
er, D
FM
)

13 © 2012 Cadence Design Systems, Inc. All rights reserved.
Next-Gen Physical Aware RTL Synthesis

14 © 2012 Cadence Design Systems, Inc. All rights reserved.
Next-Gen Physical Aware RTL Synthesis Faster Synthesis, Better QoR and Convergence
GigaHertz Performance Up to 50+% TNS,
10% WNS,
10% total power savings
Congestion Optimization Structure and map generic logic
with physical placement
knowledge at the RTL stage
Tight Correlation to EDIS Generate predictive netlist for P&R
Faster full-flow TAT by reducing
Synthesis to P&R iterations
Place
&
Route
Reduce
Iterations
New RTL-Level Physical Aware Engines:
QoR/PPA:
Structuring, Mapping
& Restructuring
(PAS/PAM/PAR)
Full flow Support:
Multi-Bit, ECO,
DFT, Low Power,
Hierarchical/ILMs
RTL Compiler + Advanced Physical Option
Available in RTL Compiler 13.1 (Nov’13):
PAS/PAM/PAR, PA-MBCI, PA-ECO, PA-DFT
Early access software in use by 9 of the top
10 Semiconductor Design Companies

15 © 2012 Cadence Design Systems, Inc. All rights reserved. Data lines
Select
lines
reg array 1st stage muxes
Unique Placement Technology
Bit 14 Registers
Bit 14 MUXes
Other registers
Other MUXes
Select registers
Select signal
Data signal
Reg array 1st stage muxes 2nd, 3rd … stage muxes Read ports
Traditional
Placement
Desired
Placement

16 © 2012 Cadence Design Systems, Inc. All rights reserved.
Unique Placement Technology
Traditional
Placement
New
Encounter Placement Engine –
streamlines data line and select lines

17 © 2012 Cadence Design Systems, Inc. All rights reserved.
GigaOpt: Next generation optimization technology pervasive through the EDI System flow

18 © 2012 Cadence Design Systems, Inc. All rights reserved.
Design database
Threaded extraction
Threaded current source model base+SI delay calc
Threaded routing
Threaded MMMC timing
Threaded “sub-network” transform engine
GigaOpt technology
Logic
Transforms
Routing
Transforms
Placement
Transforms
ROI-Driven Optimization Power vs. Performance vs. Area
Score = gain
pain

19 © 2012 Cadence Design Systems, Inc. All rights reserved.
GigaOpt
Size a Gate
Buffer a Net
Gate composition
e.g. NAND/NOR AOI
Gate decomposition
e.g. AOI NAND/NOR
Bubble push
Route-driven optimization
Buffer a net
on a high metal layer
M9/M10
M7/M8
M5/M6
13.1 default
(data normalized to 1.0 at
90nm)

20 © 2012 Cadence Design Systems, Inc. All rights reserved.
Design 11.1
Freq
13.1
Freq
11.1
TNS (ns)
13.1
TNS (ns)
Design A 360 MHz 723 MHz -3,400 0
Design B 347 MHz 725 MHz -5,153 0
Design C 420 MHz 645 MHz -2,080 -27
Design D 435 MHz 631 MHz -5,694 -77
Design E 435 MHz 684 MHz -13,624 -32
57% Average
Improvement
Route-driven optimization results

21 © 2012 Cadence Design Systems, Inc. All rights reserved.
CCOpt: Native integration in EDI System

22 © 2012 Cadence Design Systems, Inc. All rights reserved.
Clock Concurrent Optimization Technology
CCOpt is natively integrated in the EDI System, delivering
Excellent PPA and TAT improvements
clock
variable
G
G < T - skew
fixed
T
Traditional CTS and Post-CTS Opt
CTS
Post-CTS opt
variable
Clock Concurrent Optimization
clock
G
G < T – (L – C)
T
CCOpt L C
variable variable

23 © 2012 Cadence Design Systems, Inc. All rights reserved.
Native CCOpt integration
Next-generation
multi-threaded
GigaOpt engine
Native code
migration
Merg
e
placeDesign
routeDesign
optDesign -preCTS
optDesign -postCTS
ccoptDesign
optDesign -postRoute
placeDesign
routeDesign
optDesign -preCTS
ccoptDesign
optDesign -postRoute
Native CCOpt is a limited-access feature in release 13.1

24 © 2012 Cadence Design Systems, Inc. All rights reserved.
Native CCOpt results (28nm node)
Tool WNS TNS Runtime Density
Low-power mobile
32-bit CPU
Scripted -57ps -12ns 34hr 15min 51.65%
Native -15ps -0ns 3hr 56min 52.56%
32-bit CPU for tablets and
smartphones
Scripted -85ps -297ns 101hr 17min 74.64%
Native -12ps -0ns 25hr 35min 69.88%
Complex 64-bit CPU for
datacenters
Scripted -99ps -26ns 34hr 36min 52.61%
Native -76ps -3ns 23hr 25min 52.15%
Quad-core 32-bit CPU hard-macro
Scripted -77ps -553ns 62hr 45min 78.16%
Native -15ps -1ns 21hr 57min 71.65%

25 © 2012 Cadence Design Systems, Inc. All rights reserved.
Design signoff with Tempus

26 © 2012 Cadence Design Systems, Inc. All rights reserved.
Introducing Tempus Timing Signoff Solution New technology accelerates timing analysis and closure by weeks
100 200 300 400 500
Performance Massively parallelized
Scalable to 100s of CPUs
Optimized data structures
Accuracy 10X faster path-based analysis
Advanced process modeling
Closure 10X reduction in closure time
Unlimited MMMC capacity
Path or graph-based optimization
Place
and
route
Physical View
(DEF)
Hierarchical or
flat, physically
aware ECO
2-3
Iteration
Distributed,
multi-mode,
multi-corner
(MMMC) delay
calculation and STA
Physically-aware
optimization
Hold, DRV,
setup, leakage
Tempus™
Timing
closed
-0.1
-0.08
-0.06
-0.04
-0.02
0
Pat
h S
lack
Path Number
AOCV PBA Slack
AOCV Graph Based
Pessimism
reduction
PBA reduces pessimism
Path Number
Certified by TSMC for 20nm designs Endorsed by Texas Instruments for
advanced giga-scale, giga-performance ICs

27 © 2012 Cadence Design Systems, Inc. All rights reserved.
Cortex A12
• ARM and Cadence are working with lead partners on the implementation of the Cortex-A12
– Cadence Cortex-A12 iRM is available today from ARM.
• Next version of the Cortex-A12 iRM will use upcoming Cadence releases for EDI, RC/RCP, Tempus.
Mali T600 Series GPU
• ARM’s Mali GPU is a significant advancement in mobile graphics – Advanced scalable architecture
– Optimal power/performance balancing
• Cadence’s implementation technology is perfectly suited to efficient Mali GPU implementation
– Multi-objective global synthesis
– Physically aware convergent flow throughout
– Advanced clock tree optimization for power and performance
– Power efficient multi-bit register merging
– Efficient hierarchical flows
• The Cadence flow for the Mali-T678 is available from ARM
Summary
