banco de dados i 1. introdução -...
TRANSCRIPT

1Curso: Sistema de Informação Disciplina: Banco de dados I Fase: 3 Professor: Edson Thizon ([email protected]) Nº de créditos: 04 Carga Horária: 68 horas/aula
BANCO DE DADOS I 1. Introdução
Bancos de dados e tecnologia de banco de dados tem estado presente no dia-a-dia do uso de computadores. Banco de dados desempenha um papel crítico em muitas áreas onde computadores são utilizados, incluindo negócios, engenharia, medicina, educação, etc. O termo ‘banco de dados’ foi definido por diversos autores:
WIEDERHOLD Um banco de dados é uma coleção de dados mutuamente relacionados. CHU Um banco de dados é um conjunto de dados relacionados entre si. DATE Um banco de dados é uma coleção de dados operacionais armazenados usados pelos
sistemas de uma determinada aplicação. KORTH Um banco de dados é uma coleção de dados que contém informação de um particular
empreendimento. ELMASRI & NAVATHE Um banco de dados é uma coleção de dados relacionados. ENGLES Um banco de dados é uma coleção de dados operacionais usados pelo sistema de
aplicações de uma empresa. O termo ‘dado’ denota um fato que pode ser registrado e que possui significado implícito.
Por exemplo, considere os nomes, telefones e endereços de todas as pessoas que você conhece. A definição de banco de dados como ‘uma coleção de dados relacionados’ é geral; por
exemplo, considere a coleção de palavras deste texto como sendo dados relacionados e, portanto, constitui um banco de dados. Entretanto, o uso comum do termo ‘banco de dados’ é usualmente mais restrito. Um banco de dados possui as seguintes propriedades implícitas:
• Um banco de dados é uma coleção logicamente coerente de dados com algum significado inerente; um arranjo aleatório de dados não pode ser considerado um banco de dados.
• Um banco de dados é projetado e construído com dados para um propósito específico. Ele possui um grupo de usuários e algumas aplicações pré-concebidas, as quais esses usuários estão interessados.
• Um banco de dados representa algum aspecto do mundo real; alteração neste mundo real são refletidas no banco de dados.
Em outras palavras: um banco de dados tem alguma fonte na qual os dados são derivados,
alguma taxa de interação com eventos do mundo real, e uma audiência que está ativamente interessada em seu conteúdo.
Um banco de dados pode ser de qualquer tamanho e variar de complexidade. Por
exemplo, a lista de nomes, endereços e telefones de uso pessoal pode ter dezenas de registros e possui

2uma estrutura simples. Por outro lado, o catálogo de livros de uma grande biblioteca pública pode ter milhares (ou milhões) de registros, classificados e caracterizados com dados de autor (primeiro e último nomes), título, editora, data de publicação, edição, etc.
Um banco de dados pode ser gerado e mantido manualmente ou por máquina. O fichário
de uma biblioteca é um exemplo de banco de dados criado e mantido manualmente. Um banco de dados computadorizado pode ser criado e mantido por:
• um grupo de programas especialmente escrito para essa tarefa; ou • um sistema de gerenciador de banco de dados.
Um Sistema Gerenciador de Banco de Dados (SGBD) é uma coleção de programas que
habilitam usuários para criar e manter um banco de dados. O SGBD é um software de propósito geral que facilita o processo de definição, construção e manipulação de bancos de dados.
Definição de banco de dados envolve especificar tipos de dados para serem gravados no
banco de dados, com uma descrição detalhada de cada tipo de dado. Construção de um banco de dados é o processo de gravar inicialmente dados no banco de dados. Manipulação de um banco de dados inclui funções como consulta por dados específicos e atualização para refletir alterações no mundo real.
A figura 1 denota o conceito de sistema de banco de dados, que consiste na composição de banco de dados e software.
Figura 1 – Um simplificado ambiente de sistema de banco de dados.
Programas
SGBD
• BD gravado • Definição do BD gravada
(Meta-dados)
Usuários
ORACLE, SQL SERVER, INFORMIX, SYBASE, ...
Sistema de Banco de Dados

3
2. Abordagem Tradicional de Arquivos e Abordagem de BD
Várias características distingue a abordagem de banco de dados da abordagem tradicional de arquivos. Na abordagem tradicional de arquivos (ou processamento tradicional de arquivos) cada usuário define e implementa os arquivos necessários para uma específica aplicação. Por exemplo, em uma universidade um usuário precisa manter arquivos de alunos e seu controle acadêmico; programas são utilizados para imprimir histórico acadêmico e fazer registro de novas notas. Um segundo usuário do departamento financeiro mantém arquivos de alunos e seus registros de pagamento. Embora ambos os usuários esteja interessados em dados sobre estudantes, cada usuário mantém seus próprios arquivos e programas que acessam tais arquivos. Essa redundância na definição e armazenamento de dados resulta em espaço de armazenamento perdido e esforço adicional para manter dados comuns atualizados.
Na abordagem de banco de dados, um único repositório de dados é mantido, o qual é
definido uma vez e então acessado por vários usuários.
2.1 Natureza Auto-contida de um Sistema de BD A característica fundamental da abordagem de banco de dados é que o sistema de banco
de dados contém não somente a banco de dados propriamente dito, mas também uma completa definição ou descrição do banco de dados. Essa definição é gravada no catálogo do sistema, que contém informação como estrutura de cada arquivo, o tipo e formato de armazenamento de item de dado, e várias restrições dos dados. A informação gravada no catálogo é chamada de meta-dados, conforme apresentado na figura 1.
O catálogo é usado pelo SGBD e ocasionalmente pelos usuários do banco de dados que
necessitam de informação sobre a estrutura do banco de dados. O software SGBD não é escrito para qualquer aplicação de banco de dados específica e, portanto, deve utilizar o catálogo para conhecer a estrutura de arquivos em um banco de dados particular, como tipo e formato dos dados que ele irá acessar. O software SGBD deve trabalhar uniformemente com qualquer número de aplicações de banco de dados – por exemplo, banco de dados de universidade, instituição bancária, etc – sempre utilizando a definição banco de dados gravada no catálogo.
No processamento tradicional de arquivos, a definição de dados é tipicamente parte
integrante dos programas de aplicação. Portanto, esses programas são restritos para trabalhar com somente um banco de dados específico, cuja estrutura é declarada nos programas de aplicação. Por exemplo, um programa PASCAL possui variáveis de arquivo declaradas nele; um programa PL/I possui estruturas de arquivo especificadas através de instruções DCL; um programa COBOL possui instruções na Data Division que define seus arquivos. Enquanto o software de processamento de arquivos pode acessar somente um banco de dados específico, o software SGBD pode acessar muitos bancos de dados distintos, extraindo do catálogo as definições do banco de dados e usando tais definições para corretamente acessar qualquer banco de dados.
Em um banco de dados de uma universidade, uma solicitação pelo ‘endereço do aluno
cuja matrícula é 123’ resulta no acesso ao arquivo de alunos. O SGBD necessita saber a estrutura do arquivo de alunos, bem como a posição do endereço dentro de cada registro do arquivo; com base na descrição de dados presente do banco de dados, o SGBD poderá acessar dados para consultar ou atualizar endereço de aluno. Por outro lado, na abordagem tradicional de arquivos a estrutura de arquivo com os dados descritivos de ‘endereço de aluno’ estão codificados dentro dos programas que acessam o arquivo.

4
2.2 Isolamento entre Programas e Dados Na abordagem tradicional de arquivos, a estrutura de arquivos de dados está embutida nos
programas, de modo que alterações na estrutura de um arquivo poderá requerer a modificação de todos os programas que acessam tal arquivo. Por outro lado, programas que interagem com o SGBD são escritos independentemente de qualquer arquivo. A estrutura dos arquivos de dados é gravada no catálogo de dados separadamente dos programas de acesso. Esta propriedade é tipicamente chamada de independência programa-dados. Se um novo dado é necessário para a descrição de um aluno, por exemplo data de nascimento, tal dado deve ser incluído em cada registro do arquivo de alunos, o que resulta na alteração do registro. Neste caso, o catálogo de dados será modificado para refletir a nova estrutura de registro. Na abordagem de banco de dados, os programas referenciam os dados através de seus nomes, sendo desnecessário alterar os programas que acessam o arquivo de alunos, visto que o nome de cada um dos demais dados permanece inalterado.
2.3 Suporte a Múltiplas Visões dos Dados
Um banco de dados tipicamente tem muitos usuários, onde cada qual pode requerer um
diferente perspectiva ou visão dos dados. Uma visão pode ser um subconjunto de um banco de dados ou pode conter dados virtuais que são derivados do banco de dados, mas não estão explicitamente gravados. Um SGBD deve fornecer facilidades para a definição de múltiplas visões. Por exemplo, um usuário pode estar interessado no histórico de notas de alunos; um outro usuário é responsável pelo controle de pagamentos efetuados pelos alunos.
3. Pessoas Envolvidas no Dia-a-dia de um Grande Banco de Dados Em um pequeno banco de dados de uso pessoal, uma única pessoa tipicamente irá definir,
construir e manipular o banco de dados. Por outro lado, em um grande banco de dados com milhares (ou milhões) de usuários e com restrições no tempo de acesso podem-se identificar alguns papéis para pessoas que interagem com banco de dados.
3.1 Administrador de Banco de Dados (DBA)
Em uma organização onde muitas pessoas utilizam os mesmos recursos, existe a
necessidade de um administrador para gerenciar esses recursos. Em ambiente de banco de dados, o recurso primário é o banco de dados propriamente dito e recurso secundário é o SGBD, ambos sobre a supervisão do administrador de banco de dados (DBA). O DBA é responsável pela autorização de acesso ao banco de dados e pela monitoração e coordenação de seu uso, e está estando envolvido com aspectos físicos do banco de dados (estruturas de armazenamento, métodos de acesso, etc).
3.2 Projetistas de Banco de Dados
Projetistas de banco de dados são responsáveis pela identificação dos dados para o banco
de dados e pela escolha de estruturas apropriadas para representar e gravar tais dados. Essas tarefas são executadas antes da implementação do banco de dados. É necessária uma comunicação com os usuários do banco de dados para entender seus requisitos, de modo que o projeto possa atendê-los. A visão de cada grupo de usuários deve ser entendida e o projeto final deverá suportar os requisitos de todos os grupos de usuários.
3.3 Usuário Final
Usuário final é a pessoa cujo trabalho requer acessar o banco de dados para consulta e
atualização de dados; um banco de dados existe primariamente para seu uso.

5 A maioria dos usuários finais utilizam programas voltados ao desempenho de suas
funções profissionais, interagindo com tais programas em seu dia-a-dia; nesta classe, pode-se citar caixa bancário, caixa de supermercado, agente de turismo, vendedores de varejo, etc. Alguns usuários mais sofisticados, como engenheiros e cientistas, estão mais familiarizados com as facilidades de um SGBD e são capazes de utilizar ferramentas para elaborar suas consultas.
3.4 Analista de Sistemas e Programador de Aplicações Analistas de sistemas determinam os requisitos dos usuários, e desenvolve especificações
que atendam tais requisitos. Programadores de aplicações implementam essas especificações na forma de programas, efetuando teste, depuração e manutenção, bem como elaborando documentação.

6
Sistema Gerenciador de Banco de Dados SGBD Um SGBD é uma coleção de programas que habilitam os usuários a criar e manter um banco de dados. 1. Características de um SGBD Diversos elementos caracterizam um SGBD; alguns SGBDs incorporam parte desses elementos e bom SGBD deveria incluir todos os elementos. 1.1 Controle de Redundância Na abordagem tradicional de arquivos, cada grupo de usuários mantém seus próprios arquivos. Por exemplo, em uma universidade dois grupos de usuários estão interessados no controle acadêmico e no controle financeiro, respectivamente. Cada grupo mantém independentemente arquivos de alunos: o primeiro com dados de grade curricular e histórico de disciplinas cursadas; o segundo com registros de ocorrências de pagamentos efetuados. Vários dados estarão gravados duas vezes, visto que ambos os grupos de usuários necessitam de informações comuns. Outros grupos de usuários podem também necessitar de dados de alunos, o que potencialmente resultará em nova redundância. A redundância no armazenamento do mesmo dado diversas vezes conduz a vários problemas. Primeiro, existe uma necessidade de realizar uma única atualização lógica – como inserir um novo aluno – várias vezes: uma vez para cada arquivo onde existem alunos registrados. Isto conduz à duplicação de esforço. Segundo, espaço de armazenamento é perdido devido à gravação do mesmo dado repetidamente, que pode ser um sério problema em grandes banco de dados. Um terceiro e mais sério problema é que arquivos que representam os mesmos dados podem tornar-se inconsistentes. Isto pode acontecer quando uma atualização é aplicada para alguns dos arquivos, mas não todos; atualizações são aplicadas independentemente por cada grupo de usuários. Na abordagem de banco de dados, integram-se as visões de diferentes grupos de usuários durante o projeto de banco de dados. Para favorecer a consistência de dados, poderia se ter um projeto de banco de dados onde cada item de dado lógico – como nome de aluno ou data de nascimento – estaria em um único local no banco de dados. Tal situação evita inconsistência e economiza espaço de armazenamento. Em alguns casos, redundância controlada pode ser útil. Por exemplo, pode ser mais conveniente que o nome de aluno esteja no arquivo de histórico de disciplinas cursadas, além de já estar no arquivo de alunos. Esta decisão pode ter sido motivada devido um grande volume de consultas sobre histórico acadêmico; se todos os dados solicitados estiverem em um único arquivo, a operação torna-se mais rápida, pois não é necessário buscar dados em diversos arquivos. Alguns SGBDs possuem a capacidade de controlar essa redundância, proibindo inconsistências associadas aos arquivos. No exemplo, caso seja necessário alterar o nome de aluno no arquivo de alunos, o SGBD terá a responsabilidade de atualizar as demais cópias deste item de dado lógico. 1.2 Compartilhamento de Dados Um SGBD pode permitir que diversos usuários acessem um banco de dados simultaneamente; isto é essencial se dados de diversas aplicações são integrados e mantidos em um único banco de dados. Um SGBD deve incluir software de controle de concorrência para garantir uma atualização controlada quando diversos usuários tentam atualizar o mesmo dado, resultando em atualizações corretas. Um exemplo ocorre em um sistema de reservas de passagens aéreas; o SGBD deve garantir que um assento seja reservado para um único passageiro. Outro mecanismo que suporta a noção de dados

7compartilhado é a facilidade para definição de visão do usuário, que é usada para especificar a porção de um banco de dados que é de interesse para um particular grupo de usuários. 1.3 Restrição de Acesso não Autorizado Quando múltiplos usuários compartilham um banco de dados, é provável que alguns usuários não estejam autorizados para acessar toda informação em um banco de dados. Por exemplo, dados financeiros são freqüentemente considerados confidenciais, e portanto somente pessoas autorizadas podem ter permissão de acesso a tais dados. Em adição, alguns usuários possuem permissão apenas para consultar dados, enquanto outros possuem permissão para consultar e atualizar dados. Portanto, o tipo de operação de acesso – consulta ou atualização – também pode ser controlado. Tipicamente, usuários ou grupos de usuários possuem contas de acesso protegidas por senha, as quais são utilizadas para se obter acesso para o banco de dados. Um SGBD deveria fornecer um subsistema de segurança e autorização, que poderia ser utilizado pelo DBA para criar contas e especificar restrições de acesso; o SGBD forçaria essas restrições automaticamente. Controle similar pode ser aplicado ao próprio SGBD; por exemplo, somente usuários do tipo DBA poderiam ter privilégios para criar novas contas de usuário. 1.4 Fornecimento de Múltiplas Interfaces Muitos tipos de usuários, com diversos níveis de conhecimento técnico, usam um banco de dados; um SGBD poderia fornecer uma variedade de interfaces de usuário. Os tipos de interface incluem linguagens de consulta para usuários casuais, interfaces de linguagem de programação para programadores de aplicação, formulários e interfaces dirigidas por menu para outros tipos de usuários. 1.5 Forçar Restrições de Integridade Muitas aplicações possuem restrições de integridade (regras) associadas aos dados. O mais simples tipo de restrição de integridade para um item de dado é o tipo de dado. Por exemplo, a matricula de aluno deve ser um valor inteiro de 6 posições; o nome de aluno deve ser uma cadeia de caracteres com no máximo 30 caracteres. Muitos SGBDs possuem a facilidade para definir tipos de dado em adição aos tipos de dado básicos. Existem muitos tipos de restrições. Um tipo de restrição que ocorre freqüentemente é especificar que um registro de um arquivo deve estar relacionado a registros de outros arquivos; por exemplo, todo registro do arquivo de histórico de disciplinas cursadas deve estar relacionado com um registro do arquivo de aluno. Outro tipo de restrição especifica a unicidade de dados, como cada aludo deve ter uma matrícula distinta. Essas restrições são resultado da semântica dos dados associado ao mundo real que ele representa. É de responsabilidade do projetista do banco de dados especificar restrições de integridade durante o projeto de banco de dados. Vale ressaltar que um item de dados pode ser entrado erroneamente, mas ainda satisfazer as restrições especificadas. Por exemplo, em dados errados do tipo ‘o telefone de um aluno possui valor incorreto’ (provavelmente devido a erro de digitação) não pode ser detectado pelo SGBD. 1.6 Backup e Recovery Um SGBD deve fornecer facilidades para recuperação em caso de falhas de hardware e software. Por exemplo, se o computador falha no meio de um complexa transação de atualização, o SGBD deve garantir que o banco de dados será restaurado ao seu estado antes do início da transação.

8
1.7 Vantagens Adicionais da Abordagem de Banco de Dados DESENVOLVIMENTO DE PADRÕES A abordagem de banco de dados permite o DBA definir e forçar padrões, como nomes e formatos de elementos de dados, terminologia, etc. Isso facilita a comunicação e cooperação entre departamentos, projetos e usuários dentro de uma organização. FLEXIBILIDADE Pode ser necessário alterar a estrutura de um banco de dados através da adição de informação que não está correntemente no banco de dados. Um SGBD deve permitir tais alterações sem afetar muitos dos programas de aplicação existentes. TEMPO DE DESENVOLVIMENTO REDUZIDO Projetar e implementar uma nova aplicação a partir de um banco de dados existente é uma tarefa que leva menos tempo que se um banco de dados ainda não existisse. A abordagem de banco de dados permite a criação de novas aplicações em um tempo inferior que na abordagem tradicional de arquivos. DISPONIBILIDADE DE INFORMAÇÃO ATUALIZADA Um SGBD torna o banco de dados disponível para todos os usuários. Essa disponibilidade é essencial para muitas aplicações, como reservas de passagens aéreas e instituições bancárias. Isto é possível devido ao controle de concorrência e recuperação do SGBD. 1.8 Quando não Usar um SGBD Existem situações onde o uso de um SGBD pode ser um custo desnecessário comparado com o processamento tradicional de arquivos: • Alto investimento inicial com software e, possivelmente, com hardware. • Overhead de segurança, controle de concorrências, recuperação e funções de integridade
(aplicações em tempo-real). • O banco de dados e aplicações são simples e bem definidas, não se esperando muitas alterações. • Múltiplos acessos não são necessários. 2. Modelos de Dados, Esquemas e Instâncias Uma característica fundamental da abordagem de banco de dados é a abstração de dados. O conceito de abstração está associado à característica de se observar somente os aspectos de interesse, sem se preocupar com maiores detalhes envolvidos. No contexto de abstração de dados, por exemplo, um banco de dados pode ser visto sem se considerar a forma como os dados estão armazenados fisicamente.
Exemplos de Abstração em um Banco de Dados Um usuário que deseja consultar um banco de dados não necessita se importar com dados que não estão associados ao seu dia-a-dia (se ele é do departamento de engenharia, não deve ter acesso aos dados de folha de pagamento); um programador de aplicação não precisa se importar com aspectos físicos de armazenamento (quais os arquivos que armazenam o banco de dados); um administrador de banco de dados deve saber detalhes físicos do banco de dados para realizar ajustes que poderão resultar em melhoria de performance. A finalidade de um sistema de banco de dados é simplificar e facilitar o acessos aos dados. Visões do usuário de alto-nível ajuda-nos a atingir isto. Os usuários do sistema não devem preocupar-se desnecessariamente com os detalhes físicos de implementação do sistema. Contudo, o fator principal da satisfação de um usuário com um sistema de banco de dados é o seu desempenho. Se o tempo de resposta a uma solicitação é muito longo, o valor do sistema é diminuído. O desempenho de um sistema depende da eficiência das estruturas de dados usadas para representar os dados no banco de dados, e quão eficientemente o sistema é capaz de operar essas estruturas de dados.

9 Um modelo de dados é a principal ferramenta no fornecimento dessa abstração. Um modelo de dados é um conjunto de conceitos que podem ser usados para descrever a estrutura de um banco de dados. Estrutura de banco de dados denota tipos de dados, relacionamentos e restrições associadas aos dados. Alguns modelos de banco de dados incluem um conjunto de operações para consultas e atualizações no banco de dados. 2.1 Categorias de Modelos de Dados Pode-se caracterizar um modelo de dados baseado nos tipos de conceitos que eles fornecem para descrever a estrutura de banco de dados. Modelo de dados conceitual ou de alto-nível fornece conceitos que são próximos da percepção dos usuários a respeito dos dados. Modelo de dados de baixo-nível ou físico fornece conceitos que descrevem os detalhes de como os dados são armazenados. Conceitos fornecidos por modelos de baixo-nível são geralmente significantes para profissionais de informática, não sendo úteis aos usuários finais. Entre estes dois extremos está uma classe de modelo de dados de implementação, que fornece conceitos que podem ser entendidos pelos usuários finais, mas não está longe da forma como os dados poderiam ser organizados. Modelo de dados de alto-nível usa conceitos como entidades, atributos e relacionamentos. Uma entidade é um objeto que pode ser representado no banco de dados. Um atributo é uma propriedade que descreve algum aspecto de um objeto. Relacionamentos entre objetos podem ser facilmente representados. O mais popular modelo de dados de alto-nível é o modelo Entidade Relacionamento. Modelo de dados de implementação é freqüentemente utilizado em SGBDs comerciais, sendo o mais popular denominado modelo Relacional. Modelo de dados físico descreve como os dados são armazenados; por exemplo, formato de registro, ordenação de registro, caminho de acesso, etc. Um caminho de acesso busca agilizar pesquisas particulares por registros. 2.2 Esquemas e Instâncias Em qualquer modelo de dados é importante distinguir entre descrição do banco de dados e o banco de dados propriamente dito. A descrição de um banco de dados é chamada de esquema de banco de dados. Um esquema de banco de dados é especificado durante o projeto do banco de dados e não é freqüentemente modificado. Alguns modelos de dados possuem certa notação gráfica para representar esquemas de banco de dados; tal notação é chamada diagrama de esquema. A figura 1 exemplifica um diagrama de esquema, especificando a estrutura de cada arquivo; os registros correntes não são representados. ALUNO Matrícula Nome Sexo DataNascDISCIPLINA NumDisc NomeDisc Créditos PRÉ-REQUISITO NumDisc NumDisc PreReq TURMA CodTurma NumDisc Semestre Ano Professor HISTÓRICO Matrícula CodTurma Nota
Figura 1 – Exemplo de diagrama de esquema. Um diagrama de esquema apresenta somente alguns aspectos de um esquema, como nome de arquivo, itens de dados e alguns tipos de restrição. Outros aspectos não são especificados no diagrama de esquema; por exemplo, a figura 1 não exibe o tipo de dado de cada item de dado, nem os relacionamentos associando os vários arquivos. Muitos tipos de restrição não são representadas em

10diagramas de esquema; uma restrição como ‘um aluno reprovado por mais de uma vez na disciplina INF352 deverá obrigatoriamente cursar a disciplina INF001’ é difícil de representar. Os dados reais no banco de dados podem alterar com freqüência; por exemplo, o banco de dados da figura 1 altera cada vez que um novo aluno é adicionado ou cada disciplina cursada. Os dados em um banco de dados em um particular momento é denominado instância do banco de dados (ou estado do banco de dados). Muitas instâncias de banco de dados podem corresponder a um particular esquema de banco de dados. Cada vez que um registro é inserido ou excluído, ou se altera o valor de um item de dados, uma instância do banco de dados é alterada, tornando-se uma nova instância. A distinção entre esquema do banco de dados e instância do banco de dados é muito importante. Quando se define um novo banco de dados, somente o seu esquema de banco de dados é especificado para o SGBD. Nesse ponto, a instância correspondente do banco de dados é a ‘instância vazia’, sem dados. A instância inicial do banco de dados é alcançada quando os dados são inicialmente carregados. A partir desse ponto, cada vez que uma operação de atualização é aplicada no banco de dados, uma nova instância do banco de dados é caracterizada. O SGBD é parcialmente responsável pela garantia de que cada instância do banco de dados satisfaça a estrutura e as restrições especificadas no esquema. Portanto, especificar um correto esquema para o banco de dados é extremamente importante, devendo ser projetado com muito cuidado. O esquema do banco de dados é gravado pelo SGBD, de modo que possa ser referenciado sempre que necessário. 3. Arquitetura de SGBD Três características importantes da abordagem de banco de dados são: isolamento entre dados e programas, suporte a múltiplas visões do usuário e uso de um catálogo para gravar a descrição do banco de dados (esquema). A figura 2 ilustra uma arquitetura em níveis:
Figura 2 – Arquitetura de SGBD em níveis.
VISÃO EXTERNA
VISÃO EXTERNA
ESQUEMA CONCEITUAL
ESQUEMA INTERNO
BANCO DE DADOS ARMAZENADO
Nível Externo
Nível
Nível Interno
USUÁRIOS FINAIS

11 O nível interno tem um esquema interno, que descreve a estrutura de armazenamento físico, do banco de dados. O esquema interno usa um modelo de dados físico e descreve detalhes de armazenamento de dados e caminhos de acesso para o banco de dados. O nível conceitual tem um esquema conceitual, que descreve o banco de dados para a comunidade de usuários. O esquema conceitual é a descrição global do banco de dados que esconde os detalhes da estrutura física de armazenamento e concentra-se em descrever entidades, tipos de dados, relacionamentos e restrições. Um modelo de dados de alto-nível ou um modelo de dados de implementação podem ser usados neste nível. O nível externo ou visão inclui um número de esquemas externos ou visões do usuário. Cada esquema externo envolve a visão do banco de dados de um grupo de usuários do banco de dados. Cada visão tipicamente descreve a parte do banco de dados que um particular grupo de usuários está interessada e esconde o resto do banco de dados daquele grupo. Um modelo de dados de alto nível ou um modelo de dados de implementação podem ser usados neste nível. 4. Independência de Dados A arquitetura em 3 níveis pode ser usada para esclarecer o conceito de independência de dados, que pode ser definida como a capacidade de alterar o esquema em um nível sem alterar o esquema do nível imediatamente superior. Apresentam-se 2 níveis de independ6encia de dados: 4.1 Independência de Dados Lógica É a capacidade de alterar o esquema conceitual sem alterar o esquema externo ou programas de aplicação. Pode-se alterar o esquema conceitual pela adição de um novo tipo de registro ou item de dado, pela remoção de um tipo de registro ou item de dado. No último caso, esquemas externos que referem-se aos dados restantes não seriam afetados. 4.2 Independência de Dados Física É a capacidade de alterar o esquema interno sem alterar os esquema conceitual. Alterações no esquema interno podem ser necessárias pois alguns arquivos físicos são reorganizados – por exemplo, pela criação de estruturas de acesso adicionais – para melhorar a performance de consulta ou atualização.

12
Modelagem de Dados Conceitual (Modelo ER) Modelagem de Dados Conceitual é o primeiro passo para o desenvolvimento de um sistema em ambiente de banco de dados. Este processo se desenvolve no fase denominada de analise no ciclo de desenvolvimento.
MODELAGEMDE DADOS
Estratégia
Análise
Modelo de dados Entidade relacionamentoDefinições de entidade
Definiçoes de tabelas, indexes
Projeto
Construção
CONCEITUAL
PROJETODO BANCODE DADOS
CONSTRUÇÃODO BANCODE DADOS
Informações requeridas do negócio
Banco de Dados Operacional
A meta da Modelagem de Dados Conceitual é desenvolver um modelo entidade-relacionamento que representa as informações requeridas dos negócios. Exemplo A seguinte modelo entidade-relacionamento representa a informação requerida do Departamento de Recursos Humanos.
Componentes do Modelo Entidade-Relacionamento
• Entidades - os objetos de significância sobre os quais as informações necessitam ser mantidas.
• Relacionamentos - como os objetos de significância são relacionados. • Atributos - a informação específica a qual necessita ser mantida.

13O Modelo Entidade-Relacionamento é um meio efetivo para coleta e documentação das informações requeridas de uma organização. • Com o documento modelo E-R os requisitos de informação organizacionais são claros e com formato
preciso. • Usuários podem facilmente entender a forma gráfica do modelo E-R. • Modelo E-R pode ser facilmente desenvolvido e refinado. • Modelo E-R fornece uma clara figura do escopo dos requisitos de informação. • Modelo E-R fornece uma estrutura para integração de múltiplas aplicações, projetos de desenvolvimento, ou
pacotes de aplicação. Nota Rápida • Tenha certeza do completo estabelecimento dos requisitos de informações organizacionais durante o estágio de modelagem de dados conceitual. Mudanças nos requisitos durante estágios posteriores do ciclo de vida, pode ser extremamente caro. A Modelagem de Dados Conceitual é independente do hardware ou software a ser usado na implementação. O Modelo E-R pode mapear um banco de dados hierárquico, de rede ou relacional.
MODELO ENTI DADE RELAÇÃOI TEM DOCONTRATO
CONTRATO
PRODUTOPARA
MOSTRAR NO
JUNTO
FEI TO EMCI MA
CONTRATO
I TEM 2
PRODUTO Y
I TEM 1
PRODUTO X
PRODUTO X
PRODUTO Y
I TEM 2I TEM 1
CONTRATO
HI ERÁRQUI COBANCO DE DADOS
DE REDEBANCO DE DADOS
RELACI ONALBANCO DE DADOS
QUANT.NÚM.CONTRAT. PRODUTO
I TEM
PRODUTOCONTRATOCÓD. DATA CÓD. DESCRI ÇÃOCLI ENTE

14
ENTIDADES Entidade é alguma coisa (objeto significante) sobre a qual a informação precisa ser conhecida ou mantida. Outras definições de Entidade: • Um objeto de interesse de negócios. • Uma entidade é uma classe ou categoria de alguma coisa • Uma entidade é a nomeação de algo. Exemplos Os seguintes podem ser objetos de significância sobre o qual a companhia (empresa) precisa manter a informações: EMPREGADO DEPARTAMENTO PROJETO - Atributos descrevem entidades e são as partes específicas da informação as quais precisam ser conhecidas. Exemplos Os possíveis atributos para entidade EMPREGADO são: número, nome, data de nascimento e salário. Os possíveis atributos para entidade departamento são: nome, número e localização. Nota Rápida • Uma entidade deve ter atributos que necessitam ser conhecidos do ponto de vista dos negócios ou então não é
uma entidade no escopo dos requisitos do negócio.
Convenções da Diagramação de Entidades • Box arredondado (soft box) de qualquer tamanho • O nome da entidade deve ser singular e único • Nome da entidade no topo • Opcional: nome sinônimo que deve ser representado entre parênteses • Os nomes dos atributos logo abaixo Exemplos

15Notas rápidas • O sinônimo é um nome alternativo para a entidade. • Os sinônimos são muito utilizados quando dois grupos de usuários têm diferentes nomes para o mesmo
objeto significante. - Cada entidade deve ter vários instâncias ou ocorrências. Exemplos A entidade EMPREGADO tem uma instância para cada empregado no negócio: João Alves, Maria do Carmo e Egberto da Silva são todos os instâncias da entidade EMPREGADO. A entidade DEPARTAMENTO tem um instância para cada departamento na companhia:
Departamento Financeiro, Departamento de vendas e o Departamento de Desenvolvimento são todos os instâncias da entidade DEPARTAMENTO.
Cada instância da entidade tem específicos valores para seus atributos. Exemplo A entidade EMPREGADO tem atributos de nome, número, data de nascimento e salário. A instância João Alves tem os seguintes valores: nome João Alves, número: 1322, data de nascimento 15-mar-50 e o salário de R$1000. Notas Rápidas • Instâncias são as vezes confundidos com entidades. • A entidade é uma classe ou categoria da coisa. ex.: EMPREGADO. • A instância é uma coisa específica. ex.: o empregado João Alves. - Cada instância deve ser unicamente identificável em relação aos outros instâncias de mesma entidade. Um atributo ou um grupo de atributos que unicamente identificam uma entidade é chamado Identificador Único (Unique Identifier - UID). Exemplo Cada empregado tem um único número. Número é um candidato para único identificador para a entidade EMPREGADO. Procurar atributos que unicamente identificam uma entidade. Exemplo Que atributos poderiam unicamente identificar as seguintes entidades?

16Notas Rápidas • Se uma entidade não pode ser unicamente identificada, isso não poderia ser uma entidade. • Atributos que unicamente identificam uma entidade e são parte do único identificador (UID) da entidade são
marcados com #. IDENTIFICAR E MODELAR ENTIDADES Siga os passos abaixo para identificar e modelar entidades a partir de um conjunto de notas de uma entrevista. 1. Examine os substantivos. Eles são objetos significantes? 2. Nomeie cada entidade. 3. Existe alguma informação ou interesse sobre a entidade que o negócio (empresa) precisa manter? 4. Cada instância da entidade é unicamente identificável? Qual atributo ou atributos poderiam servir como um
UID? 5. Faça uma descrição disso: “Um empregado tem a importância de um assalariado da companhia. Por
exemplo, Egberto da Silva e Maria do Carmo são EMPREGADOS.” 6. Diagrame cada entidade e alguns de seus atributos. Nota Rápida • Não se precipite desqualificando um candidato entidade. Atributos adicionais de interesse da companhia
poderiam ser expostos mais tarde. EXERCÍCIOS 1) Identificar e modelar as entidades a partir das seguintes informações:
“Eu sou gerente de uma companhia de treinamento que oferece cursos de caráter técnico. Lecionamos vários cursos, cada qual tem um código, um nome, e preço. Introdução ao Unix e Programação C são dois de nossos mais populares cursos. Os cursos variam, em termos de duração, de um a quatro dias. Um professor (instrutor) pode lecionar vários cursos. Egberto Silva e Maria do Carmo são dois de nossos melhores instrutores, nós mantemos o nome e o telefone de cada um deles. Cada curso é lecionado por somente um instrutor. Nós criamos um curso e então nomeamos o professor. Os estudantes podem frequentar vários cursos ao mesmo tempo. João fez todos os cursos que fornecemos. Nós também mantemos nome, fone e endereço dos estudantes. Alguns estudantes e instrutores não têm telefone.”
Descrições da Entidade • CURSO tem a importância de um serviço de treinamento oferecido pela companhia. Por exemplo,
Introdução ao Unix e Programção em C . • ALUNO tem a importância de um participante em um ou mais CURSOs. Por exemplo João Alves. • O PROFESSOR tem a importância de instrutor em um ou mais CURSOs. Por exemplo, Rita Poks e Laertes
Ferreira. 2) Identificar e modelar a entidades para o seguinte conjunto de informações. Escreva uma rápida descrição de dada entidade, mostrando pelo menos dois atributos para cada uma delas: “Sou proprietário de um a pequena loja de vídeo. Temos mais de 3000 fitas aqui e queremos um sistema para controla-las. Cada fita contem um número. Para cada filme precisamos saber seu título e

17categoria(comédia, suspense, terror, etc.). Muitos de nosso filmes tem mais de uma cópia. A cada filme fornecemos um ID e então controlamos qual o filme que uma fita contem. O formato de uma fita pode ser BETA ou VHS. Sempre temo uma fita para dado filme, e cada fita tem apenas um filme. Não temos aqui nenhum filme que requeira mais de uma fita. Freqüentemente as pessoas alugam filmes pelos atores. Queremos manter informações sobre os astros que atuam em nosso filmes. Nem todos os filmes são estrelados por astros e só mantemos aqui astros que atuam em filmes do nosso catalogo. Os clientes gostam de saber a data de nascimento de um astro, bem como o seu verdadeiro nome. Temos muitos clientes. Apenas alugamos filmes para pessoas inscritas em nosso vídeo clube. Para cada membro mantemos seu primeiro e ultimo nome telefone e endereço. Claro que cada membro possui um numero de titulo. Alem disso mantemos o status de credito de cada um. Queremos controlar os alugueis de filmes. Um cliente pode alugar vários filmes ao mesmo tempo. Apenas mantemos os alugueis correntes(pendentes). Não controlamos o histórico de locações.”

18
RELACIONAMENTOS O relacionamento é a associação bi-direcional, significante entre duas entidades, ou entre a entidade e ela mesma. Syntax Cada entidade1 { deve ser} NOME DO RELACIONAMENTO {um ou mais} entidade2 {ou pode ser } {ou um único} Exemplo O relacionamento entre o instrutor e o curso é: Cada CURSO pode ser lecionado por um e somente um PROFESSOR. Cada PROFESSOR pode ser alocado para lecionar um ou mais CURSOs. Cada direção da conexão tem: • um nome --- lecionado por ou alocado para. • uma opção --- deve ser ou pode ser ,um ou outro. • um grau --- um e somente um ou um ou mais . Diagramando Convenções • Uma linha entre duas entidades • Nome das conexões localizados abaixo dos soft box • Opcional opcional (pode ser) obrigatório(deve ser) • Grau
um ou mais um e somente um
muitos
obr igatór ioopcional
um(pé de galinha)

19Primeiro leia o relacionamento em uma direção, e então leia o relacionamento no outro sentido. Exemplo Leia o relacionamento entre EMPREGADO e DEPARTAMENTO.
EM PREGADO DEPARTAM ENTOdesign ado a
r espon sávelpor
Leia essa relação primeiro da esquerda para direita, e então no outro sentido. Relacionamento esquerda para direita (diagrama parcial)
EM PREGA DO DEPA RTA M EN TOdesi g n ado a
Cada EMPREGADO deve ser designado para um e somente um DEPARTAMENTO. Relacionamento da direita para a esquerda(diagrama parcial)
EM PREGA D O D EPA RTA M EN TO
r esp on sávelp or
Cada DEPARTAMENTO pode ser responsável por um mais EMPREGADOs. Exemplo Leia o relacionamento ALUNO e CURSO.
CURSOAL UNO matriculado em
Ministrado para
Cada ALUNO pode se matricular em um mais CURSOs. Cada CURSO pode ser ministrado para um ou mais ALUNOs. Exemplo Leia a relação entre o CHEQUE e EMPREGADO.
CHEQUE EMPREGADOpara
Receber
Cada CHEQUE deve ser para um e somente um EMPREGADO. Cada EMPREGADO pode receber um ou mais CHEQUEs de pagamento.
Exercício 1 Escreva as sentenças que se originam dos relacionamentos mostrados abaixo. Lembre-se que as sentenças devem obedecer ao máximo a convenção.

20
PEDIDO ITEMnúmerotipo número
descrição
primeiro nomeúltimo nome
CLIENTEidDEPÓSITO
endereço
emitido para
compradovia
armazenadoem
repositóriode
requisitadopor
requisitantede
Cada ENTIDADE {deve ser} RELACIONAMENTO {um e somente um} ENTIDADE {pode ser} {um ou mais}
Exercício 2 Desenhe um M.E.R baseado nas seguintes sentenças(relacionamentos): a. Cada EMPREGADO deve ser assinalado em um e somente um DEPARTAMENTO. b. Cada DEPARTAMENTO pode ser responsável por um ou mais EMPREGADOs. c. Cada EMPREGADO pode ser alocado em uma ou mais ATIVIDADEs. d. Cada ATIVIDADE pode ser executada por um ou mais EMPREGADOs.
Exercício 3 Desenhe um MER baseado nas seguintes sentenças(relacionamentos): a. Cada BANCO DE DADOS ORACLE deve ser constituído de uma ou mais TABLESPACEs. b. Cada TABLESPACE deve ser constituída de um e somente um BANCO DE DADOS ORACLE. c. Cada TABLESPACE deve ser constituída de um ou mais ARQUIVOs. d. Cada ARQUIVO pode ser parte de uma e somente uma TABLESPACE. e. Cada TABLESPACE pode ser dividida em um ou mais SEGMENTOs. f. Cada SEGMENTO deve estar em uma e somente uma TABLESPACE. g. Cada SEGMENTO deve ser constituído de um ou mais EXTENTs. h. Cada EXTENT deve estar incluído em um e somente um SEGMENTO. i. Cada EXTENT deve ser composto de um ou mais BLOCOs. j. Cada BLOCO deve ser parte de um e somente um EXTENT. k. Cada ARQUIVO deve ser residente em um e somente um DISCO. l. Cada DISCO pode ser o hospedeiro para um ou mais ARQUIVOs.

21TIPOS DE RELACIONAMENTO Existem 3 tipos de relacionamento • muitos para um (many to one M:1) • muitos para muitos (M:M) • um para um Todos os relacionamentos devem representar as informações requeridas e as regras do negócio. • relacionamento muitos para um tem o grau de um ou mais em uma direção e o grau de um e somente
um na outra. Exemplo Existe um relacionamento muitos para um (M:1) entre CLIENTE e REPRESENTANTE COMERCIAL).
CLIENTE REPRESENTANTEvisitadopor
Designadoa visitar
Notas Rápidas • Os relacionamentos M:1 são muitos comuns. • Os relacionamentos M:1 que são obrigatórios em ambas as direções são raros. O relacionamento Muitos para Muitos (Many to Many, M:M) tem o grau de um ou mais em ambas direções. Exemplos Existe um relacionamento M:M entre ALUNO e CURSO.
ALUNO matriculadoem
inscritopor
CURSO
Cada ALUNO pode ser matriculado em um ou mais CURSOs. Cada CURSO pode ser cursado por um ou mais ALUNOs. Existe um relacionamento M:M entre EMPREGADO e TRABALHO.
designadopara
EMPREGADO EMPREGO
preenchido
Cada EMPREGADO pode ser designado para um ou mais EMPREGOs. Cada EMPREGO ser preenchido por um ou mais EMPREGADOs. Notas Rápidas • Relacionamentos M:M são muito comuns. • Na maioria dos casos os relacionamentos M:M são opcionais em ambas as direções, contudo esta relação pode ser opcional em somente uma direção. O Relacionamento Um para Um (1:1) tem o grau de um e somente um em ambas direções.

22Exemplo Existe um relacionamento 1:1 entre COMPUTADOR e CPU.
CPUCOMPUTADOR o hospedeirode
incorporadono
Cada COMPUTADOR deve ser o hospedeiro de uma e somente uma CPU. Cada CPU pode ser incorporada em um e somente um COMPUTADOR. Notas Rápidas • Este relacionamento é raro. • É obrigatório em ambas direções. • Entidades que pareçam ter uma relação 1:1 podem ser realmente a mesma entidade.
ANALISAR E MODELAR RELACIONAMENTOS Siga os cinco passos para analisar e modelar os relacionamentos. Passos 1 Determine a existência do relacionamento. 2 Nomeie cada direção do relacionamento. 3 Determine a opcionalidade para cada direção do relacionamento. 4 Determine o grau para cada direção do relacionamento. 5 Leia o relacionamento para aprová-lo. PASSO 1 - DETERMINAR A EXISTÊNCIA DO RELACIONAMENTO Determine a existência do relacionamento. Examine cada par de entidades para determinar se a se relacionamento existe. Pergunte sobre a existência do relacionamento. • Existe uma relação significativa entre ENTIDADE A e ENTIDADE B? Exemplos Considere as entidades DEPARTAMENTO e EMPREGADO. Há uma relação significativa entre DEPARTAMENTO e EMPREGADO? Sim, há um relacionamento significativo entre as entidades. Considere as entidades DEPARTAMENTO e ATIVIDADE. Há uma relação significativa entre DEPARTAMENTO e ATIVIDADE? Não há um relacionamento significativo entre as entidades. PASSO 2 - NOMEANDO O RELACIONAMENTO Nomeie cada direção do relacionamento. Perguntar o nome do relacionamento

23• Como a ENTIDADE A é relacionada com a ENTIDADE B? Uma ENTIDADE A “é o nome do relacionamento” uma ENTIDADE B. • Como a ENTIDADE B é relacionada com a ENTIDADE A? Uma ENTIDADE B “é o nome do relacionamento” uma ENTIDADE A. Exemplo Considere o relacionamento entre DEPARTAMENTO e EMPREGADO. Como estas entidades são relacionadas? Cada DEPARTAMENTO é responsável pelo EMPREGADO. Cada EMPREGADO é designado para um DEPARTAMENTO. Usar a lista de pares de nome relação para nomear relacionamentos. Utilizando pares nome relação • baseado em a base para • trazido de o fornecedor de • descrição de para • operado por o operador para • representado por a representação de • responsável por a responsabilidade de Nota Rápida • Não use relacionado a ou associado a como nome de relacionamento. PASSO 3 - DETERMINAR A OPCIONALIDADE DOS RELACIONAMENTOS Determinar a opcionalidade de cada direção dos relacionamentos. Perguntar sobre a opcionalidade das relações • A ENTIDADE A deve ser “ nome do relacionamento” ENTIDADE B? • A ENTIDADE B pode ser “ nome do relacionamento” ENTIDADE A? Exemplo Considere o relacionamento entre DEPARTAMENTO e EMPREGADO. Um EMPREGADO deve ser designado a um DEPARTAMENTO? Sempre? Existe alguma situação em que o EMPREGADO não seria designado a um DEPARTAMENTO? Não, um EMPREGADO deve sempre ser designado a um DEPARTAMENTO. Um DEPARTAMENTO deve ser responsável por um EMPREGADO? Não, um DEPARTAMENTO não tem que ser responsável por um empregado. Desenhe as linhas de relacionamento, com seus respectivos nomes relação. Exemplo
DEPARTAMENTOEMPREGADO designadoao
responsávelpor

24PASSO 4 - DETERMINAR O GRAU DOS RELACIONAMENTOS Determinar o grau em ambas direções Perguntar sobre os graus de relacionamentos • Pode a ENTIDADE A ser “nome do relacionamento” de mais de uma ENTIDADE B? • Pode a ENTIDADE B ser “nome do relacionamento” de mais de uma ENTIDADE A? Exemplo Considere a relação entre DEPARTAMENTO e EMPREGADO. Pode um EMPREGADO ser designado para mais de um DEPARTAMENTO? Não, um EMPREGADO deve ser designado para apenas um DEPARTAMENTO. Pode um DEPARTAMENTO ser responsável por mais de um EMPREGADO? Sim, um Departamento pode ser responsável por mais de um empregado. Adicionar os graus do relacionamentos ao diagrama E-R. Exemplo
DEPARTAMENTOEMPREGADO designadoao
responsávelpor
PASSO 5 - VALIDAR O RELACIONAMENTO Re-examinar o modelo E-R e validar o relacionamento. Leia o Relacionamento • Os relacionamentos devem ser legíveis e fazer sentido ao negócio. Exemplo Leia o relacionamento representado pelo seguinte diagrama.
DEPARTAMENTOEMPREGADODesignadopara
responsávelpor
Cada EMPREGADO deve ser designado a um e somente um DEPARTAMENTO. Cada DEPARTAMENTO pode ser responsável por um ou mais EMPREGADOs. EXERCÍCIO 1 Analisar e modelar relacionamentos. Analisar e modelar os relacionamentos no seguinte grupo de informações requeridas. Usar a matriz relacionamento para traçar a existência das relações entre as entidades.

25“Eu sou gerente de uma companhia de treinamento que oferece cursos na área de manejamento de técnicas. Nós lecionamos vários cursos, cada qual tem um código, um nome, e a remuneração. Introdução ao Unix e Programação C são dois de nossos mais populares cursos. Os cursos variam, em termos de duração, de um a quatro dias. Um professor (instrutor) pode lecionar vários cursos. Egberto Silva e Maria do Carmo são dois de nossos melhores instrutores, nós mantemos o nome e o telefone de cada um deles. Cada curso é lecionado por somente um instrutor. Nós criamos um curso e então nomeamos o professor. Os estudantes podem frequentar vários cursos ao mesmo tempo. João fez todos os cursos que fornecemos. Nós também mantemos nome, fone e endereço dos estudantes. Alguns estudantes e instrutores não têm telefone.”
EXERCÍCIO 2 Analisar e modelar os relacionamentos no seguinte grupo de informações requeridas do exercício
“Eu sou dono de uma pequena loja de vídeo. Nós temos mais de três mil títulos a cadastrar. Cada fita tem um número. Para cada filme temos que saber seu título e categoria (aventura, drama, comédia...). Sim, nós temos títulos repetidos (mais de uma cópia para um filme). Nós damos para cada filme uma identidade específica, e então traçamos que filme a fita contém. As fitas podem ser dos formatos Beta ou VHS. Nós sempre temos no mínimo uma fita para cada filme traçado e cada uma é sempre cópia de um único filme específico. Nossas fitas são bastante longas, e nós não temos nenhum filme que que seja longo o bastante para mais de uma fita. As perguntas mais frequentes dos clientes são sobre filmes novos e atores específicos. Pacino e De Niro são os mais procurados. Então nós gostaríamos de cadastrar as estrelas do cinema em cada filme que elas participam. Nem todos os filmes são feitos por atores famosos. Os clientes gostam de saber seus “reais” nomes e datas de nascimento. Só cadastramos os atores que estão no nosso inventário. Nós temos muitos clientes. Só alugamos videos para pessoas que tenham bom crédito e façam parte do clube. Para cada um destes clientes, nós gostaríamos de guardar seus nomes e seus telefones e endereços atuais. E é claro que cada um deles tem um número. Finalmente precisamos de um cadastro das fitas que cada um deles aluga. Um cliente pode alugar muitas fitas, mas só nos interessa suas locações mais recentes.”
RESUMO - LAY OUT DO DIAGRAMA E-R Faça o diagrama E-R fácil de ler e aplicável às pessoas que precisam trabalhar com isso. Limpo e Arrumado • Caixas entidades em cima. • Desenhe as linhas dos relacionamentos retas. • Usar um ângulo de 30 à 60 graus que é mais fácil seguir quando as linhas das relações devem se cruzar. • Usar bastante espaço em branco para evitar congestionamento visual. • Evitar o uso de muitas linhas paralelas próximas umas das outras pois são difíceis de se seguir. Texto Bem Definido • Faça o texto bem definido sem ambiguidades. • Evite abreviações e jargões. • Adicione adjetivos para para melhorar o entendimento. • Alinhe o texto horizontalmente. • Ponha os nomes dos relacionamentos no fim da linha e no lado oposto da linha. Formas Memoráveis • Faça o diagrama E-R memorável. As pessoas lembram-se de formas e modelos. • Não desenhe o diagrama E-R em uma grade. • Estique ou encolha as caixas (boxes) de entidades para ajudar no layout do diagrama.

26Desenhe os pés de galinha apontando para cima ou para esquerda.
apontando paraesquerda
apontandopara cima
Regra do Layout
• Tente posicionar o pé de galinha à esquerda ou ao topo das linhas de relacionamento. • Posicione as entidades mais volumosas e voláteis em direção ao topo e à esquerda do diagrama. • Posicione as entidades menos volumosas e voláteis abaixo e à esquerda do diagrama.
Nota Rápida
• Até que uma relação M:M seja resolvida, pelo menos um fim do relacionamento apontará para baixo ou para esquerda
ATRIBUTOS Atributos são informações sobre uma entidade que precisa ser conhecida ou mantida. Atributos descrevem uma entidade pela qualificação, identificação, classificação, quantidade ou expressando o estado da entidade. Exemplo Quais são alguns dos atributos da entidade EMPREGADO? código ou número da folha de pagamento identificam um EMPREGADO nome e sobrenome qualificam um EMPREGADO categoria da folha de pagamentto (semanal, mensal) classificam um EMPREGADO a idade quantifica um EMPREGADO status do emprego (ativo, aposentado) expressa a posição do EMPREGADO Atributos representam o tipo de descrição ou detalhe, não uma instância. Exemplo 77506 e 763111 são os valores do atributo número. João é o valor do atributo nome de EMPREGADO. Notas Rápidas
• Os nomes dos atributos devem estar claros aos usuários, não codificados para o desenvolvedor. • Nomes de atributos devem ser específicos-ex., isso é quantidade, quantidade retornada,
ou quantidade adquirida? • Sempre esclareça uma data atributo com uma narrativa ou frase, - ex., data de contato, data do pedido. • Um atributo deve ser designado à uma única entidade.
Convenções do Diagrama

27• Os nomes dos atributos são simples e mostrados abaixo do nome da entidade. • Listar os nomes dos atributos nos soft box de suas devidas entidades.
OPCIONALIDADE DO ATRIBUTO Identificar cada opção de atributo usando uma marca. Atributos Obrigatórios • Um valor deve ser conhecido por cada ocorrência da entidade. • Marque-o com *. Atributos Opcionais • Um valor pode ser conhecido para cada ocorrência da entidade. • Marque-o com o. Exemplo Identificar os atributos para a entidade PESSOA. Determinar sua opcionalidade.
Título e o peso são atributos opcionais. Os atributos remanescentes são obrigatórios. Usar uma amostra de dados dos atributos de um instância para validar a opcionalidade. Exemplo São corretas as marcas de obrigatório e opcional para a entidade PESSOA?
PESSOA# CD_PESSOA* NM_PESSOA* TP_SEXOo DS_PESOo DS_TITULO

28Usar uma tabela entidade instância para validar qual marcas são corretas para a entidade PESSOA.
Nome da entidade: PESSOA
Nome do Atributo
Cd_pessoa Nm_pessoa Ds_titulo Tp_sexo Ds_peso
Marcas * * o * o Dados da Amostra
110 301 134 243 566
João Silva Carmo Bosco Gismonti
Presidente Tesoureiro ---- Secretário ----
M F F M M
----
Nota Rápida • Uma Tabela Instância Entidade é útil para registrar os dados da amostra do atributo. IDENTIFICAR ATRIBUTOS Identificar atributos pelo exame das notas da entrevista e pela solicitação das perguntas do usuário. Atributos podem aparecer nas notas da entrevista como: • Frases ou palavras descritivas • Substantivos • Frases preposicionais (ex.- quantia do salário para cada empregado) • Substantivos possesivos e pronomes (ex.- nome do empregado) Questões para perguntar ao usuário • Que informação você precisa saber ou manter sobre a entidade x? • Que informação você gostaria de exibir sobre a entidade x? Examinar documentação no existente manual de procedimentos ou automatizar sistemas para descobrir atributos adicionais e omissões.
Formas do papel Relatórios do Computador Arquivos do Computador Cabeçalhos Prompts
Campos Cabeçalhos Tipos de pedidos
Lay-out dos Registros Depósito de arquivos
Questões ao usuário
• Este atributo é realmente necessário? Notas Rápidas • Tomar cuidado com requisitos obsoletos pelo sistema anterior. • Fique atento aos dados derivados. EXERCÍCIO 3-7 Desenvolva um M-ER para a seguinte situação. Especifique os atributos de cada entidade e a opcionalidade dos mesmos.
PESSOA# CD_PESSOA* NM_PESSOA* TP_SEXOo DS_PESOo DS_TITULO

29
“Nosso grupo de usuários ORACLE possui mais de 200 membros. Necessitamos de um IS para controlar nossos assuntos. Definitivamente, precisamos automatizar nosso cadastro de membros. Para cada membro, precisamos manter seu nome, título, endereço para correspondência, telefone comercial, tipo de membro (individual ou empresa) e se o membro está ou não em dia com a taxa anual que cobramos dele pela sua participação no grupo. Esta taxa é cobrada em Janeiro para todos os membros. Também gostaríamos de controlar e manter as empresas de cada membro, o que é difícil já que as pessoas vivem trocando de empresa e queremos manter a empresa corrente de cada membro. Alguns membros estão sem emprego no momento. Para cada empresa, mantemos o nome, endereço e tipo de negócio. Temos um conjunto padrão de códigos para os tipos de negócio. Mantemos apenas o endereço principal de cada empresa. Vários instâncias são agendados por nós, anualmente. Alguns de nossos instâncias anuais são: ‘Encontro da Primavera’, ‘Congresso de Novembro’, ‘Encontro de Outono’, etc. Programamos também instâncias especiais. Por exemplo, tivemos no mês passado o ‘Case Day’, onde o Sr. Richard Baker veio da Inglaterra para uma série de palestras. Nossos instâncias são realizados em vários locais da cidade (Hotel Sheraton, Anhembi, etc). Queremos manter informações sobre os instâncias: data, descrição, número máximo de participantes, local,orçamentos e comentários que os participantes fizeram durante a instância. Esses comentários são registrados como anônimos. Pode haver vários comentários para cada instância. Desejamos manter informações sobre quais os membros atendem a quais instâncias. Alguns membros são ativos e participam sempre.Outros nem tanto e alguns só querem receber nosso jornalzinho. Cada membro pode usar tipos de computadores diferentes. Temos um sistema de identificação para cada plataforma. Assim, 001é para IBM/MVS; 002 para IBM/VM; 003 para VAX/VMS; 020 para OS/2;030 para PC/DOS; 050 para SUN/UNIX; 080 para outras plataformas. Também associamos cada embro com áreas de interesse: saúde, farmacêutica, recursos humanos, financeira, etc. As aplicações devem ser portáteis, portanto não relacionamos área de interesse com plataformas.
ATRIBUIR IDENTIFICADORES ÚNICOS Um Identificador Único (UID) é qualquer combinação de atributos e/ou relacionamentos que serve para unicamente identificar uma ocorrência de uma entidade. Cada ocorrência da entidade deve ser unicamente identificável. Exemplo No negócio, cada ocorrência do DEPARTAMENTO é unicamente identificável pelo seu código de departamento.
UID para a entidade DEPARTAMENTO é o atributo cd_departamento. Exemplo Para um pequeno teatro, cada bilhete é unicamente unicamente identificável pela sua data de performance e o número da cadeira.
UID para a entidade BILHETE DO TEATRO é uma combinação dos dois atributos.
DEPARTAMENTO# CD_DEPARTAMENTO* NM_DEPARTAMENTO
BILHETE DE TEATRO# DT_PERFORMANCE# NR_CADEIRA

30
A entidade deve ter um UID, ou então não é entidade Notas Rápidas • Todos os componentes do UID devem ser obrigatórios. • Marque o atributo UID com #.
Uma entidade pode ser unicamente identificada através de uma relação. Exemplo Na indústria dos bancos, para cada banco é atribuido um único número. Dentro de um banco, cada conta tem um único número. Qual é o UID da entidade CONTA?
BANCO#cd_banco
CONTA#nr_conta
gerenciadopor
o gerentede
CONTA é unicamente identificada pelo seu número de atributo e o específico BANCO com que ela está relacionada. Usar a barra UID para indicar que a relação é parte do UID da entidade. Exemplo A barra UID indica que o relacionamento com BANCO é parte do UID da CONTA.
BANCO#cd_banco
CONTA
o gerentede
#nr_conta
gerenciadopor
Nota Rápida • O relacionamento incluído no UID deve ser obrigatória e de um e somente um na direção em que participa. Uma entidade pode ser unicamente identificada através de múltiplas relações. Exemplo A empresa precisa traçar os serviços designados aos seus empregados. Empregados estão prestando serviços designados para projetos. Um empregado pode prestar vários serviços para apenas um simples projeto, cada qual com diferentes datas ou horários.

31
* dt_prestacao*dt duracaoo ds_posicao
EMPREGADO#cd_emp*nm_emp #nr_projeto
PROJETO*ds_titulo
prestando assunto de
por para
SERVIÇO DESIGNADO
Qual é o UID da entidade SERVIÇOS DESIGNADOS? Nota Rápida • Ambos relacionamentos são obrigatórios e um e somente um na direção incluída no UID. Uma entidade pode ter mais de um UID. Exemplo O que unicamente identifica um EMPREGADO?
Candidato UID inclui:
1 número 2 número da folha de pagamento 3 nome/sobrenome Eles são todos únicos? A combinação nome/sobrenome provavelmente não é única.
Selecione um candidato UID para ser o UID primário, e os outros são secundários.
EMPREGADO* CD_EMPREGADO* DS_SOBRENOME* DT_NASCIMENTO* NM_EMPREGADO* NR_FOLHA_PAG
EMPREGADO# CD_EMPREGADO* DS_SOBRENOME* DT_NASCIMENTO* NM_EMPREGADO# NR_FOLHA_PAG

32 Notas Rápidas • Marque também os secundários como (#) ou não marque-os. • Case Dictionary pode documentar vários UIDs secundários.
Estudar a criação do atributo único, artificial para ajudar a identificar cada entidade. Exemplo O que identifica unicamente a entidade CLIENTE?
Possivelmente o nome e sobrenome de CLIENTE poderia ser um UID. De qualquer modo, poderia haver dois CLIENTEs com o mesmo nome. Crie um atributo artificial chamado código CLIENTE que será único para cada ocorrência de CLIENTE.
Notas Rápidas • Atributos artificiais são freqüentemente usados como UIDs. • Defina um código artificial quando o negócio não tem um atributo natural que unicamente identifica uma
entidade. - Procurar por atributos e relacionamentos para identificar cada entidade. Avaliar os Atributos • Quais atributos obrigatórios identificam a entidade? Procurar atributos adicionais que ajudarão a identificar a
entidade. Estudar a criação de atributos artificiais para identificação. • Um atributo identifica unicamente a entidade? • Qual combinação de atributos identifica unicamente a entidade? Considerar os relacionamentos • Quais dos relacionamentos ajudam a identificar a entidade? • Está faltando algum relacionamento que ajuda a identificar a entidade? • O relacionamento ajuda a identificar unicamente a entidade? • O relacionamento é obrigatório e de um e somente um na direção da entidade? Validar o UID
CLIENTE* DS_ENDERECO* DS_SOBRENOME* NM_CLIENTE
CLIENTE# CD_CLIENTE* DS_ENDERECO* DS_SOBRENOME* NM_CLIENTE

33• Examinar a amostra de dados. A combinação de atributos e relações selecionada identifica unicamente cada
ocorrência de um entidade? • Todos os atributos e relações que estão incluídas no UID são obrigatórios?

34EXERCÍCIOS 3-8 Baseado no MER do exercício da página 26, defina a opcionalidade de cada atributo e identifique os UIDs de cada entidade, coloque o nome dos atributos conforme metodologia.
EXERCÍCIO 3-9 • Para a situação da vídeo locadora e do MER do Exercício 3-6, identificar um UID para cada entidade e
adicionar estes ao MER. Marcar também cada atributo com suas devidas marcas. • Baseado no MER do exercício anterior, defina a opcionalidade de cada atributo e identifique os UIDs de
cada entidade, coloque o nome dos atributos conforme metodologia.
FITAnúmeroformato
FILME
categoriaidtítulo
CLIENTEtítulonomesobrenometelefoneendereço
ATORnome artísticonome realdata de nascimento
cópia de
contidoem
estreladopor
de
alugado
locadorde
por
estrela

35EXERCÍCIO Baseado no MER do exercício 3-7( Grupo de usuários ORACLE), defina a opcionalidade de cada atributo e identifique os UIDs de cada entidade.
MEMBRO
nomesobrenomecargoanuidades recebidasendereçotelefonetipo
ÁREA DE INTERESSEnome
PLATAFORMAiddescrição
EMPRESAnomeendereçotipo de negócio
EVENTOnomedatadescriçãolocalcusto
COMENTÁRIOnúmerotexto
REVISÃO: MODELAGEM DE DADOS CONCEITUAL BÁSICA Entidade é alguma coisa de significância( objeto significante) sobre a qual a informação precisa ser conhecida e mantida. Convenções da Diagramação de Entidades
• Box arredondado (soft box) de qualquer tamanho • O nome da entidade deve ser singular e único • Nome da entidade no topo • Opicional: nome sinônimo que deve ser representado entre parênteses • Os nomes dos atributos logo abaixo
Identificar e Modelar Entidades 1. Examine os substantivos. Eles são objetos significantes? 2. Nomeie cada entidade. 3. Existe alguma informação ou interesse sobre a entidade que o negócio (empresa) precisa manter? 4. Cada instância da entidade é unicamente identificável? Qual atributo ou atributos poderiam servir como um
UID? 5. Faça uma descrição disso: “Um empregado tem a importância de um assalariado da companhia. Por
exemplo, Egberto da Silva e Maria do Carmo são EMPREGADOS.” 6. Diagrame cada entidade e alguns de seus atributos.
Revisão: Modelagem de Dados Conceitual Básica

36O relacionamento é a associação bi-direcional, significante entre duas entidades, ou entre a entidade e ela mesma. Syntax da Relação Cada entidade1 { deve ser} nome do relacionamento {um ou mais} entidade2 {ou pode ser } {ou um único} Convenções do Diagrama
muitos
obr igatór ioopcional
um(pé de galinha)
Analizar e Modelar as Relações Entre as Entidades
1 Determine a existência do relacionamento. 2 Nomeie cada direção da relação. 3 Determine a opcionalidade de cada direção do relacionamento. 4 Determine o grau de cada direção da relação. 5 Leia o relacionamento para aprová-lo. Revisão: Modelagem de Dados Conceitual Básica-cont. Atributos são informações sobre uma entidade que precisa ser conhecida ou mantida. Convenções do Diagrama • Os nomes dos atributos são simples e mostrados abaixo do nome da entidade. • Listar os nomes dos atributos nos soft box de suas devidas entidades.

37Analizar e Modelar Atributos 1 Identificar o candidato a atributo. 2 Associar o atributo com a entidade. 3 Nomear o atributo. 4 Determinar a opcionalidade do atributo. 5 Validar que o atributo é realmente um atributo e não um entidade. 6 Quebrar os atributos agregados. 7 Verificar o valor singular do atributo. 8 Verificar que o atributo não é derivado.

38Revisão: Modelagem de Dados Conceitual Básica-cont. Cada entidade deve ser unicamente indentificável. O Identificador Único(UID) é qualquer combinação de atributos e/ou relacionamentos que servem para unicamente identificar uma ocorrência de uma entidade. Convenções do Diagrama
• # indica um atributo que é parte do UID da entidade.
BANCO#cd_banco
CONTA
o gerentede
#nr_conta
gerenciadopor
• A barra UID indica que o relacionamento faz parte do UID (numero do banco e numero da conta compõem a UID da conta) . Identificar UIDs para cada entidade 1 Procurar candidatos atributos que audem a identificar uma entidade. 2 Determinar a dependência da entidade sobre outras a ela relacionadas. 3 Definir o UID para a entidade
DEPARTAMENTO# CD_DEPARTAMENTO* NM_DEPARTAMENTO

39NORMALIZAR O MODELO DE DADOS Normalização é um conceito de banco de dados relacional, mas seus princípios são aplicados na Modelagem de Dados Conceitual.
Validar cada colocação de atributos usando as regras de normalização. Regra da Forma Normal Descrição Primeira Forma Normal Segunda Forma Normal Terceira Forma Normal
Todos os atributos devem ter somente um valor para cada ocorrencia da entidade (valor simples). Um atributo deve depender por inteiro do UID (identificador único)da entidade Nenhum atributo não-UID pode depender de outro atributo não-UID, ou seja, atributo não - chave não deve depender de atributo não- chave.
Um modelo de dados ER normalizado traduz-se automaticamente em um projeto de banco de dados relacional normalizado. Notas Rápidas • A Terceira forma normal é geralmente aceita com o objetivo de eliminar a redundância no projeto de banco de dados. • Formas normais maiores não são largamente usadas.

40Normalizar o modelo de dados-cont. Regra da Primeira Forma Normal (1FN): Todos atributos devem assumir valores únicos para cada instância da entidade. Checagem da Validação • Validar que cada atributo tenha um valor para cada ocorrência da entidade. Nenhum atributo deve ter valores repetidos (mais de um valor). Exemplo A entidade CLIENTE esta na 1FN? Se não, como poderia ser convertido a uma 1FN?
CLIENTE#*identificador *data de contato
O atributo “ data de contato” tem múltiplos valores, portanto a entidade CLIENTE não é uma 1NF. Crie uma entidade CONTATO adicional com um RELACIONAMENTO vários para um.
CONTATO#*data de contato o local o resultado
CLIENTE#*identificador
para
doo assunto
Se um Atributo tem Múltiplos valores, crie uma entidade adicional e a relacione com sua entidade original com um relacionamento vários para um.

41Normalizar o Modelo de Dados-cont. Regra da Segunda Forma Normal(2FN): um atributo deve ser totalmente dependente do UID (IDENTIFICADOR ÚNICO ) da entidade. Checagem de validação • Verificar que o atributo é inteiramente dependente sobre o UID de sua entidade. Cada instância específica do UID deve determinar uma simples instância de cada atributo • Verificar que um atributo não dependente sobre apenas uma parte do seu UID da entidade. Exemplo Validar a colocação dos atributos da entidade CURSO
CURSO#*cod.*nome*duração*taxa
Cada instância de um código de curso especifica um valor para nome, duração e taxa. Os atributos estão apropriadamente colocados. Exemplo Validar a colocação de atributos para as entidades CONTA e BANCO.
CONTA#*numero*balanço*data*agência
BANCO#*númeroban banco*nome
gerenciadopor
o gerenteda
Cada instância de BANCO e número de conta determina valores específicos de balanço e data para cada conta. O atributo agência está mal colocado. Ele depende do BANCO mas não do número da conta. Isto não deveria ser um atributo de CONTA. Se um atributo não é inteiramente dependente do UID da entidade então está mal colocado e deve ser removido.

42Normalizar o Modelo de Dados-cont. Regra da Terceira Forma Normal(3FN): Nenhum atributo não-UID pode ser dependente de outro atributo não-UID. Checagem de Validação • Validar que cada atributo não-UID não seja dependente de outro atributo não-UID. • Mover qualquer atributo não-UID que depende de outro atributo não UID. Exemplo Algum dos atributos não-UID para esta entidade dependem de outros atributos não-UID?
PEDIDO#*id*data *id do cliente *nome do cliente*estado
Os atributos nome do cliente e estado dependem do id do cliente. Crie outra entidade chamada CLIENTE com o UID id do cliente, e coloque os atributos afins.
PEDIDO#*id*data
CLIENTE#*identidade *nome *estado
para
deo mandante
Nota Rápida • Se um atributo depende de um atributo não-UID, mova ambos para uma nova entidade relacionada.

43EXERCÍCIO 4-1 O MER apresentado abaixo não está normalizado. Redesenhe-o produzindo um novo MER normalizado. Para isso verifique entidade por entidade se:
1- Não existem grupos repetitivos(1ªFN). 2- Todos os atributos dependem do UID por inteiro.(2ªFN). 3- Não existe nenhum atributo dependente de outro atributo não-UID.
MATRÍCULAcod.graucod.professordescrição do graunome do curso
DISCIPLINAcódigonomecod.professorcod.departamentonome professornome departamento
ALUNOnúmeronomesobrenomenascimento

44RESOLVER RELACIONAMENTOS M:M Atributos podem parecer associados com o relacionamento M:M. Resolver o relacionamento M:M pela adição de uma entidade intersecção com aqueles atributos. Exemplo Considere qo relacionamento M:M entre PRODUTO e VENDEDOR. Qual o preço atual de um específico PRODUTO de um específico VENDEDOR?
preço atual parece ser um atributo do relacionamento entre PRODUTO e VENDEDOR. Atributos descrevem somente entidades. Se atributos descrevem um relacionamento, o relacionamento deve ser resolvido.

45Resolver Relacionamentos M:M-cont. Substituir ou resolver um relacionamento M:M com uma nova Entidade Intersecção e duas relações M:1. Exemplo O relacionamento M:M entre PRODUTO e VENDEDOR pode ser resolvido pela adição de uma entidade intersecção ITEM DO CATÁLOGO. Preço atual é realmente um atributo desta entidade.
ITEM CATÁLOGO*preço atual*quant. do pacote*unidade de medida
VENDEDOR#*código *nome
PRODUTO#* id *nome *descrição
para
para
fornecedorde
fornecidopor
Uma vez definida a entidade ITEM CATÁLOGO, requeridos os atributos: quantidade do pacote e unidade de medida também são atributos de ITEM CATÁLOGO. O UID para ITEM CATÁLOGO é composto pelos seus dois relacionamentos Notas Rápidas • Uma Entidade Intersecção é frequentemente identificada por seus relacionamentos originais - note a barra de UID. • Os relacionamentos vindos da entidade intersecção são sempre obrigatórios. • Estas entidades frequentemente representam o que realmente acontece no mundo dos negócios. • Estas costumam conter consumíveis como a quantidade usada e datas. Elas tendem a ser as maiores e mais voláteis entidades.

46Resolver Relacionamentos M:M-cont. Posicionar Entidades Intersecção Layout do relacionamento M:M
i d Layout da Entidade Intersecção
entidade intersecção
entidades referentes
ou
Notas Rápidas • A entidade referente é uma entidade que não tem o fim obrigatório conectado a ela • Quando o relacionamento M:M está resolvido, o layout do diagrama inteiro talvez precise ser arrastado. Resolver Relacionamentos M:M-cont. O UID de uma entidade intersecção é frequentemente composto de seus relacionamentos com as entidades originárias. Exemplo

47 Resolver a seguinte relacionamento M:M para acomodar esses requerimentos adicionais: “Trace a data em que cada aluno foi matriculado, a data em que completou o curso e o grau do aluno.”
ALUNO#*id *sobrenome *nome o telefone
CURSO#*código *nome o taxa o duração
matriculadoem
escolhidopor
Solução Adicione a entidade intersecção MATRÍCULA e dois relacioonamentos M:1.
ALUNO#*id *sobrenome *nome o telefone
CURSO#*código *nome o taxa o duração
MATRÍCULA*data da matrículao data em que completouo grau
para para
matriculadoem
escolhidopor
MATRÍCULA tem os atributos data de matrícula, data em que completou e grau. O UID de matrícula é feito de seus relacionamentos com ALUNO e CURSO. Nota Rápida Este modelo guarda somente a última data em que o aluno foi matriculado em um específico curso. Se há necessidade de se manter várias matrículas, inclua o atributo data de matrícula como parte do UID. Resolver Relacionamentos M:M-cont. Um relacionamento com a entidade intersecção, para duas entidades originantes, pode não ser adequada(suficiente) para definir unicamente cada ocorrência da entidade intersecção.

48Exemplo Resolva o seguinte relacionamento M:M para acomodar esses requerimentos adicionais. “Trace a data que cada empregado é designado ao projeto e a duração de cada um.”
EMPREGADO#*id *nome
designado a PROJETO#*número *título
tarefa do
Adicione uma entidade intersecção chamada TRABALHO DESIGNADO com atributos data da tarefa e duração.
para para
PROJETO#*número *título
EMPREGADO#*id *nome
TRABALHO DESIGNADO#*data da tarefa *duração
prestado por o assunto de
TRABALHO DESIGNADO é parcialmente identificado pelas suas relações com EMPREGADO e PROJETO, mas estas duas relações não são suficientes para identificar unicamente um TRABALHO DESIGNADO. Um empregado pode ter múltiplas tarefas para o projeto, com diferentes datas de designação. Portanto, o UID de TRABALHO DESIGNADO deve incluir o EMPREGADO relacionado, o PROJETO relacionado e o atributo DATA DA TAREFA. Resolver Relações M:M-cont. Uma vez definida a entidade intersecção, procure por atributos adicionais que descrevam a entidade intersecção. Exemplo Qual informação sobre o relacionamento entre PRODUTO e VENDEDOR precisa ser conhecida? “Nós precisamos traçar o preço atual de um específico PRODUTO vindo de um específico VENDEDOR.”

49Resolver o seguinte relacionamento M:M para acomodar esses requerimentos adicionais.
Adicione a entidade intersecção ITEM CATÁLOGO com um atributo de preço atual. Que informações precisam ser conhecidas sobre ITEM CATÁLOGO? “Nós também precisamos saber a quantidade do pacote e a unidade de medida para cada ITEM CATÁLOGO.”
ITEM CATÁLOGO*preço atual*quant. do pacote*unidade de medida
VENDEDOR#*código *nome
PRODUTO#* id *nome *descrição
para
para
fornecedorde
fornecidopor

50Resolver Relacionamentos M:M-cont. Procurar por atributos que identificam, ou ajudam a identificar uma entidade intersecção. Exemplo Como você identifica cada ITEM CATÁLOGO? Você usa a combinação relacionada do código do VENDEDOR e o id do PRODUTO? “Não, nós temos um catálogo de todos os itens disponíveis , e cada um tem um único número de catálogo.”
VENDEDOR#*código *nome
PRODUTO#* id *nome *descrição
para
para
fornecedorde
fornecidopor
ITEMÁ#*número catálogo
*preço atual*quant. do pacote*unidade de medida
De acordo com as regras do negócio, cada ITEM CATÁLOGO tem um único número catálogo. Então este deveria ser o UID da entidade ITEM CATÁLOGO.

51Resolver Relacionamentos M:M-cont. Resolver todos os relacionamentos M:M ao fim da fase de Análise. Essa resolução forçada pode resultar em uma entidade relacionamento sem atributos. Exemplo Na situação da Video Locadora, o seguinte relacionamento M:M foi definido.
FILME#*id *título o categoria
ATOR#*código *nome artísticoo nome realo data de nasc.
estrelado por
a estrela do
Ao fim do estágio de análise, o usuário não tinha identificado quaisquer atributos que são associados com o relacionamento M:M. Resolver o relacionamento M:M com uma entidade intersecção sem atributos
para para
FILME#*id *título o categoria
ATOR#*código *nome artísticoo nome realo data de nasc.
ATUAÇÃO DA ESTRELA
estrelado por a estrela de
Notas Rápidas • Uma entidade intersecção sem atributos é apenas uma lista de referência cruzada bi-direcional entre as ocorrências das entidades. • Uma entidade intersecção sem atributos é uma exceção à regra que uma entidade deve ter atributos para ser uma entidade. • O UID para uma entidade intersecção vazia é sempre composta das relações das duas entidades nas quais ela foi originada.

52EXERCÍCIO 4-2 No MER do exercício Grupo de usuários da apostila anterior, existe um relacionamento de M:M entre as entidades MEMBRO e ÁREA DE INTERESSE. Resolva este relacionamento baseado nas seguintes informações adicionais: “Queremos também manter uma pequena descrição do interesse de cada membro numa área específica. Por exemplo, queremos documentar que um membro já tem um grande sistema financeiro que ele desenvolveu dentro de casa. Pode haver, porém, algum membro interessado numa certa área sem que descrevamos seu interesse.” EXERCÍCIO 4-3 Resolver o seguinte relacionamento M:M entre CLIENTE e PRODUTO. Adicione os atributos data do pedido, quantidade e preço.
CLIENTE#*id*nome*sobrenome
PRODUTO#*número* nome* unidade de medida
o solicitantede
pedido por

53MODELO DE DADOS HIERÁRQUICO Representar os dados hierárquicos como um conjunto de relacionamentos M:1. Exemplo Modelar a estrutura de organização hierárquica como um conjunto de relacionamentos M:1.
COMPANHIA
DIVISÃO
DEPARTAMENTO
TIME
TIME
DIVISÃO
COMPANHIA
DEPARTAMENTO
Modelo de Dados Hierárquico-cont. O UID para um conjunto de entidades hierárquicas pode ser propagado através de múltiplos relacionamentos. Exemplo Quais são os UIDs das entidades ANDAR, SUÍTE e QUARTO?

54
QUARTO#*id
SUÍTE#*númeroo inquilino
ANDAR#*número
PRÉDIO#*id *nome *endereço
dentrolocalizado
localizadosobre
que contém
que contém
que contém
está contido
O UID de QUARTO é o id do quarto e a SUÍTE em que está localizado. O UID de SUÍTE é o número da suíte e o andar em que está localizado. O UID de ANDAR é o número do andar e o PRÉDIO em que está localizado.

55Modelo de Dados Hierárquico-cont. Considere a criação de atributos artificiais para ajudar a identificar entidades nas relações hierárquicas. Exemplo Em uma típica organização de estrutura, o que poderia unicamente identificar instâncias das entidades DIVISÃO, DEPARTAMENTO e TIME?
TIME
DIVISÃO
COMPANHIA
DEPARTAMENTO
Cada TIME deveria ser identificado baseado em seus DEPARTAMENTO, DIVISÃO, COMPANHIA. Ou cada entidade poderia ter um único, independente e artificial código de identificação. Notas Rápidas • Estes únicos, independentes e artificiais codigos de identificação tendem a ser curtos no tamanho. • Se a estrutura hierárquica muda constantemente, use identificadores independentes e artificiais.

56MODELO DE RELACIOINAMENTOS RECURSIVOS Um Relacionamento Recursivo é o relacionamento entre a entidade e ela mesma. Exemplo Veja o relacionamento recursivo no seguinte diagrama E-R.
EMPREGADO#*número *nome *sobrenome o trabalho o salário o comissão
gerenciadopor
gerentede
Cada EMPREGADO pode ser gerenciado por um e somente um EMPREGADO. Cada EMPREGADO pode ser o gerente de um ou mais EMPREGADOS. Notas Rápidas • As convenções do diagrama E-R que mostra o relacionamento recursivo é conhecida como orelha de porco. • O loop pode aparecer em qualquer um dos lados do box.

57Modelo de Relacionamentos recursivos-cont. Considere a representação hierárquica como um relacionamento recursivo. Exemplo Um hierarquia de negócio pode ser desenhada como um relacionamento recursivo.
TIME
DIVISÃO
COMPANHIA
DEPARTAMENTO
dentro
dentro
feito de
feito de
dentro
feito de
ELEMENTO DAORGANIZAÇÃO#*id *nome
dentro
feito de
Notas Rápidas • Uma única entidade recursiva deve incluir todos os atributos de cada entidade individual. Idealmente, as entidades em cada nível hierárquico poderiam ter os mesmos atributos. • Um modelo de organização recursiva pode prontamente acomodar a adição ou subtração de organização de camadas. • Um modelo de organização recursiva não pode lidar com relações obrigatórias. Se cada ELEMENTO DA ORGANIZAÇÃO deve estar dentro de outro ELEMENTO DA ORGANIZAÇÃO, a organização hierárquica teria de ser infinita. • Um relacionamento recursivo deve ser opcional em ambas direções.
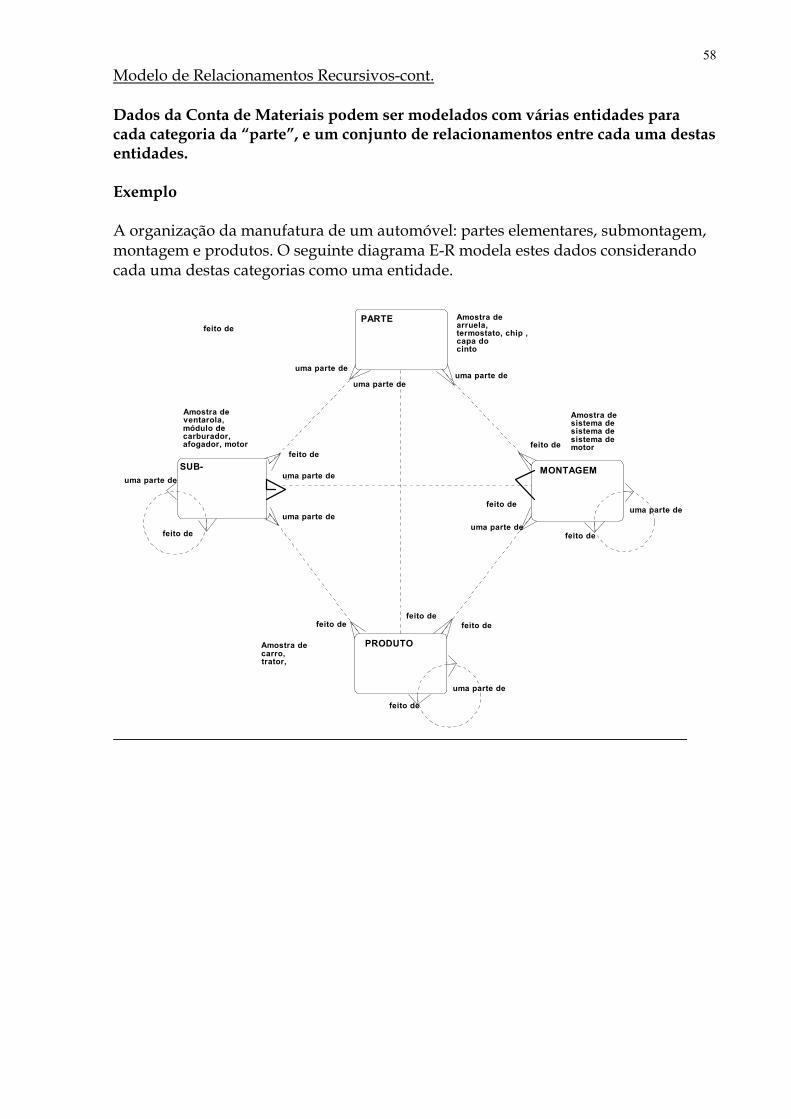
58Modelo de Relacionamentos Recursivos-cont. Dados da Conta de Materiais podem ser modelados com várias entidades para cada categoria da “parte”, e um conjunto de relacionamentos entre cada uma destas entidades. Exemplo A organização da manufatura de um automóvel: partes elementares, submontagem, montagem e produtos. O seguinte diagrama E-R modela estes dados considerando cada uma destas categorias como uma entidade.
PARTE
SUB-
PRODUTO
MONTAGEM
Amostra deventarola,módulo decarburador,afogador, motor
Amostra dearruela,termostato, chip ,capa docinto
Amostra desistema desistema desistema demotor
Amostra decarro,trator,
uma parte de
uma parte deuma parte de
uma parte de
uma parte de
uma parte de
uma parte de
uma parte de
uma parte de
feito de
feito defeito defeito de
feito de
feito de
feito de
feito de
feito de
feito de

59Modelo de Relacionamentos Recursivos-cont. Modelo de dados Conta de Materiais como um relacionamento M:M recursivo. Exemplo Para a organização da manufatura de automóveis, considere todas as partes elementares, sub-montagem, montagem e produtos como instâncias de uma entidade chamada COMPONENTES. Então o complexo prévio do modelo E-R pode ser remodelado como um relacionamento recursivo simples.
COMPONENTE#*identificador uma parte de
feito de
Cada COMPONENTE pode ser uma parte de um mais COMPONENTEs. Cada COMPONENTE pode ser feito de um ou mais COMPONENTEs.

60Modelo de Relacionamentos Recursivos-cont. Resolver o relacionamento recursivo M:M com uma entidade intersecção e duas relacionamentos M:1 para diferentes instâncias de uma entidade original. Exemplo Considere a estrutura do modelo recursivo de Conta de Materiais. Este modelo traçará informações sobre quais componentes são parte da ventarola. Mas se uma arruela fizer parte da ventarola, traçaremos também como várias arruelas fazem parte de uma ventarola. parte de
COMPONENTE#*identificador uma parte d
feito de
O atributo quantidade parece estar associado com o relacionamento recursivo. Resolver este relacionamento M:M recursivo pela adição da entidade intersecção REGRA DE MONTAGEM e duas relações M:M ligadas à entidade COMPONENTE. REGRA DE MONTAGEM terá um atributo de quantidade.
para para
COMPONENTE#*identificador
REGRA DE MONTAGEMo quantidade
feito de feito de
As duas relações M:1 vindas da instância REGRA DE MONTAGEM serão associadas com diferentes instâncias da entidade COMPONENTE. Por exemplo, a instância REGRA DE MONTAGEM de arruela a ventarola terá um relacionamento M:1 com a instância COMPONENTE para arruela e um segundo relacionamento M:1 com a instância COMPONENTE para ventarola. EXERCÍCIO 4-4

61 Desenvolva dois modelos E-R representando a situação abaixo. Um deles na estrutura hierárquica e outro na estrutura recursiva. “Nossa companhia vende produtos em todo Brasil. Assim, dividimos o país em quatro grandes regiões: Sul, SP-Rio, Central e Norte. Cada região de vendas possui identificador único. Cada região ,por sua vez, está dividida em distritos de vendas. Por exemplo, a região Norte engloba os distritos Amazônia, Zona da Mata e Caatinga. Cada distrito também tem um código único. Cada distrito é composto de territórios de vendas. A Zona da Mata por exemplo, engloba os territórios: Costa Norte e Costa Leste. Já o distrito Amazônia engloba os territórios: Solimões-Manaus, Pará-Norte e Pará-Sul. Cada território está dividido em áreas de vendas: Por exemplo, Costa Norte engloba as áreas: Grande São Luiz, Grande Fortaleza etc. Cada vendedor é responsável por uma ou mais áreas de vendas, para qual ele possui uma cota. Também temos gerentes responsáveis por um ou mais distritos, e diretores responsáveis por uma ou mais regiões de vendas. O gerente responsável por um distrito também é responsável pelos territórios deste distrito. Nós não sobrepomos as responsabilidades dos funcionários: uma área de vendas é sempre da responsabilidade de apenas um vendedor. Além disso, as responsabilidades de nossos diretores e gerentes não se sobrepõem. As vezes, algum diretor, gerente ou vendedor está para deixar as empresa ou precisou ficar ausente por algum motivo. Nós identificamos todos nossos funcionários pelos seus IDs. MODELANDO PAPÉIS COM RELACIONAMENTOS Atenção com as entidades que representem papéis. Exemplo No modelo E-R para a Training Company, foi definida uma entidade INSTRUTOR e uma entidade ALUNO. Este modelo trabalha bem se um INSTRUTOR nunca for um ALUNO e se um aluno nunca for INSTRUTOR. Mas o que acontece se um INSTRUTOR é também um ALUNO?

62
ALUNO #*id* sobrenome*nomeo telefone
CURSO#*código*nomeo duraçãoo taxa
INSTRUTOR#*id *sobrenome *nome o telefone
MATRÍCULA*data da matrículao data que completouo grau
para para
matriculado em
matriculado por
lecionadopor
o professorde
Entidades que representam papéis podem dividir instâncias sobrepostas. Modelando Papéis com Relacionamentos-cont. Use relacionamentos para modelar papéis. Relacionamentos permitem uma simples entidade instância a assumir vários papéis. Exemplo Para a Training Company, definir a entidade pessoa que pode suportar os papéis de INSTRUTOR e/ou ALUNO.

63
para
REGRA DE MONTAGEMo quantidade
para
PESSOA#*id *sobrenome *nomeo telefone
CURSO#*código *nome o duração o taxa
alunode
instrutorde
lecionadopor
matriculadopor

64MODELANDO SUBTIPOS Use subtipos para modelar tipos de entidades exclusivas que têm atributos e relações em comum. Exemplo “Uma empresa definiu dois tipos de funcionários: privilegiados e não-privilegiados. Para todos eles, traçar cada número, nome, sobrenome, e o departamento designado. Para os privilegiados traçar também seu salário. Para os não-privilegiados trace a quantia horária, a quantia total e membro da união.” Criar um super tipo FUNCIONÁRIO com dois subtipos. Cada FUNCIONÁRIO é também um FUNCIONÁRIO PRIVILEGIADO ou um FUNCIONÁRIO NÃO-PRIVILEGIADO.
FUNCIONÁRIO #*número *nome *sobrenome
FUNCIONÁRIOPRIVILEGIADO *salário
FUNCIONÁRIONÃO-PRIVILEGIADO *quantia horária *quantia total
DEPARTAMENTO UNIÃO
feitode feito de
membrode
designadoa
Nota Rápida • Tome cuidado com as instâncias que podem ser os dois subtipos-a construção subtipo/supertipo é incorreta nestas situações.

65Modelando Subtipos-cont. Um supertipo é uma entidade que tem subtipos. Um super tipo pode ser dividido em dois ou mais subtipos exclusivos e mútuos. Exemplo Um FUNCIONARIO é também um FUNCIONÁRIO PRIVILEGIADO ou um FUNCIONÁRIO NÃO-PRIVILEGIADO, mas não ambos. Um supertipo pode ter atributos e relacionamentos compartilhados entre seus subtipos. Exemplo Todos FUNCIONÁRIOs devem ter o atributo número, nome, sobrenome. Todos FUNCIONÁRIOs devem ser designados a um e somente um DEPARTAMENTO. Cada subtipo pode ter seus próprios atributos e relacionamentos. Exemplo O subtipo FUNCIONÁRIO PRIVILEGIADO tem um atributo salário. O subtipo FUNCIONÁRIO NÃO-PRIVILEGIADO tem atributos de quantia horária e quantia total, e um relacionamento com a entidade UNIÃO. Nota Rápida • Um subtipo sem atributos ou relacionamentos próprios pode ser um sinônimo da entidade supertipo e não um subtipo.

66Modelando Subtipos-cont. Todas instâncias da entidade supertipo deve pertencer a uma e somente uma entidade subtipo. Subtipos devem formar um conjunto completo sem sobreposições. Exemplo Geralmente, um trabalho manual ou um trabalho de escritório, mas devem haver algumas exceções.
TRABALHO
OUTROTRABALHO
TRABALHOMANUAL
TRABALHO DEESCRITÓRIO
Regras de Leitura de Supertipos “Cada entidade supertipo deve ser também um subtipo1 ou um subtipo2” Exemplo “Cada TRABALHO deve ser também um TRABALHO MANUAL ou um TRABALHO DE ESCRITÓRIO, ou OUTRO TRABALHO.” Regras da leitura de subtipos “...subtipo, que é um tipo do supertipo,...” Exemplo “...TRABALHO DE ESCRITÓRIO, que é um tipo de TRABALHO,...” Sempre use o termo OUTRO quando não se tem certeza sobre o complemento do conjunto.

67Modelando Subtipos-cont. Subtipos podem ser subtipados adiante. Normalmente dois ou três níveis são adequados. Exemplo Definir adiante subtipos para a entidade subtipo AVIÃO.
AERONAVE
AVIÃO
PLANADOR
PROPULSÃO
AVIÃO TURBINADO
AVIÃO A JATO
OUTROSAVIÕES
CARGUEIRO
HELICÓPTERO
AVIÃO é um subtipo de AERONAVE e um supertipo de AVIÃO TURBINADO e PLANADOR. AVIÃO A JATO herda os atributos e relações de AVIÃO TURBINADO, AVIÃO E AERONAVE.

68MODELANDO RELACIONAMENTOS EXCLUSIVOS Modelar dois ou mais relacionamentos mutuamente exclusivos vindos da mesma entidade usando um arco. Exemplo Uma CONTA BANCÁRIA qualquer deve ser apropriada a um INDIVÍDUO ou apropriada a uma COMPANHIA. Usar o arco para modelar este relacionamento.
CONTABANCÁRIA
INDIVÍDUO
COMPANHIA
Adquiridapora
Adquiridapor
o donoda
o donoda
Regras de Leitura das Relações Exclusivas “Cada entidadeA qualquer entidade1 relacionamento1 ou entidade2 relacionamento2.” Exemplo Cada CONTA BANCÁRIA deve ser adquirida por um e somente um INDIVÍDUO ou por uma e somente uma COMPANHIA. Convenções da Modelagem de Arcos • Os relacionamentos em um arco tem frequentemente o mesmo nome. • Os relacionamentos em um arco devem ser todas obrigatórias ou todas opcionais. • Um arco pertence a uma só entidade e devem incluir somente relacionamentos vindos desta entidade. • Uma entidade deve ter vários arcos, mas um relacionamento específico somente pode participar de um único arco.

69Modelando Relacionamenots Exclusivos-cont. Escolha entre duas convenções para desenhar arcos. Convenção de Desenho1-Um Arco com Pontos Opcionais Um ponto no arco é usado para significar que um relacionamento pertence ao arco.
Convenção de Desenho2-Um Arco sem Pontos Qualquer relacionamento cruzado pelo arco pertence a ele. Uma quebra no arco indica que o relacionamento não está incluído no arco.

70EXERCÍCIO 4-5 Desenvolva um MER baseado nas seguintes informações: “A companhia Right-Way Rental Truck aluga pequenos caminhões e trailers para uso local e/ou one way. Temos 347 pontos de aluguéis (escritórios) no Oeste dos EUA. Nossa frota possui um total de 5780 veículos, incluindo vários tipos de caminhões e trailers. Precisamos implementar um sistema para controlar os contratos de locação e alocação de veículos. Cada escritório aluga veículos que estão em estoque para clientes prontos para tomarem posse do veículo. Não fazemos reservas e nem especulamos quando o cliente vai retornar um veículo alugado. A matriz gerencia a distribuição e direciona a transferência de veículos de um escritório a outro. Cada escritório possui um nome e um número de três dígitos que o identifica. Também mantemos o endereço de cada escritório. Cada escritório funciona como uma base para os veículos e cada veículo está baseado em um único escritório. Cada veículo possui um código, situação de registro e número de licença. Temos diferentes tipos de veículos: truck 36, truck 24, truck 10, trailer comum e motorhome. Usamos códigos para identificar cada tipo de veículo. Para cada veículo, guardamos a última data de manutenção e a data do vencimento da licença. Com relação aos caminhões, precisamos guardar quantos quilômetros o odômetro está marcando, a capacidade do tanque e se o veículo possui ou não um rádio. Para grandes viagens, os clientes preferem caminhões equipados com rádio. Assim que alugamos um caminhão, guardamos a quilometragem corrente. Este procedimento é repetido quando o caminhão é devolvido. A maioria dos contratos de aluguéis são para pessoas físicas, apesar da gente também fazer contratos com empresas. Alugamos uma porcentagem de nossos caminhões e trailers para empresas. Para cada nova companhia cadastrada, fornecemos um código e guardamos seu nome e endereço. Para nós da matriz não nos interessa mais qualquer outras informações sobre elas. Para cada cliente pessoa física, mantemos seu nome, telefone residencial, endereço, número da carteira de habilitação e a data do vencimento da habilitação. Além disso, se o cliente danificou o veículo ou não pagou a conta nós o taxamos de “inválido” e nunca mais alugaremos veículos para el outra vez. Cada contrato de locação é feito para apenas um cliente (físico ou jurídico) e apenas um veículo. Claro que temos clientes que alugam mais de um veículo ao mesmo tempo, mas fazemos um contrato para cada locação. Aliás, cada contrato é identificado por um número de contrato e pelo número de escritório do qual o veículo foi retirado. Também guardamos a data do contrato, a duração (esperada) da locação, o número do escritório em que o veículo é devolvido, o valor do depósito, a taxa de locação diária e a taxa de quilometragem. Para trailers não controlamos a quilometragem. IMPORTANTE: não queremos automatizar o lado financeiro, apenas os contratos de locação.”

71MODELANDO DADOS NO TEMPO Adicione entidades e relacionamentos ao modelo E-R para acomodar dados históricos. Perguntar ao Usuário: • É necessário uma auditoria? • Os valores dos atributos podem mudar no tempo? • As relações podem mudar no tempo? • Você precisa examinar dados antigos? • Você precisa manter versões prévias? Nota Rápida • Validar quaisquer requerimentos para armazenamento de dados históricos com o usuário. Armazenar dados históricos desnecessários pode ser muito CARO.

72Modelando Dados no tempo. Criar uma entidade adicional para mapear o valor de um atributo no tempo. Exemplo Uma firma de consultoria precisa manter informações sobre seus contratos. Cada contrato tem um único id de contrato, eles precisam manter a descrição do contrato e o status do contrato (aberto, fechado, ou suspenso). Inicialmente a seguinte entidade CONTRATO foi modelada.
CONTRATO#*id *descrição *valor do status *data efetiva
A entidade CONTRATO acima suporta um único valor de status corrente para CONTRATO. A lei da firma quer traçar as datas em que cada um foi aberto, foi fechado e foi suspenso. Para modelar valores de status excedentes, adicione uma entidade STATUS.
CONTRATO#*id *descrição *valor do status *data efetiva
STATUS#*data efetiva *valor
o estadode
de
O UID entidade STATUS é relacionado ao CONTRATO e a data efetiva. Nota Rápida • Usar uma única entidade para gravar os valores no tempo dos vários atributos associados com uma entidade (tanto como o CONTRATO). Modelando Dados no tempo. Adicione uma nova entidade para comportar um relacionamento que pode mudar no tempo. Exemplo:

73 Um proprietario de imóveis deseja registrar dados de locação de seus apartamentos. O modelo abaixo registra apenas o locatário atual de um apartamento. Adicione a entidade “histórico de alugueis” para capturar os valores do relacionamento de locação no tempo. Modelando Dados no tempo - cont. Uma entidade intersecção é frequentemente usada para guardar informações sobre relações que mudam no tempo. Exemplo Uma sociedade profissional quer mapear a relação entre as companhias e seus membros . Há um relacionamento M:M entre cada membro e cada companhia.
APARTAMENTO #*codigo *endereço
PESSOA #*id *ultimo_nome *primeiro_nome
PESSOA #*id *ultimo_nome *primeiro_nome
Alugado por O locatário de
O locatário de
Histórico de locação #*da_data_de 0 para_data_de
APARTAMENTO #*codigo *endereço
para
para
Locado por

74
MEMBRO#*id *sobrenome *nome
COMPANHIA#*código *nome
contratadopor
o contratantede
Adicione uma entidade intersecção, HISTÓRICO DO EMPREGO, para traçar cada contratação dos empregados no tempo e as datas destes empregos.
parapara
MEMBRO#*id *sobrenome *nome
COMPANHIA#*código *nome
empregadopor
contratantede
HISTÓRICO DODO EMPREGO#*a partir da data o até a data
Pela inclusão do atributo “ a partir da data” UID de HISTÓRICO DO EMPREGO, este modelo traçará vários termos do EMPREGO em uma única empresa por um único empregado. EXERCÍCIO 4-6 Modificar o MER do exercício 3-6 (locadora de vídeo) para acomodar as seguintes informações adicionais que seguem: “Nós realmente precisamos manter o histórico de nossos aluguéis. Cada vez que um cliente aluga uma fita queremos manter a data do aluguel e a data do retorno. Mantendo esse histórico de aluguel, seremos capazes de analisar o padrão de nossos aluguéis. Poderemos determinar quantas fitas cada cliente aluga e quantas vezes um cliente devolveu a fita com atraso. Seremos capazes de saber quantas fitas em particular foram usadas e então saberemos quando retirar cada fita. Também seremos capazes de analisar as preferências de filmes de nossos clientes.”

75
parapara
por
FILME#*id *títuloo categoria
ATOR#*código *nome artístico o nome real o data de nascimento
estrelado estrelando em
ESTRELA EM CARTAZCLIENTE#*número* nome* sobrenomeo telefone
FITA#*número*formato
o locatário
alugada por a cópia
de
em

76MODELANDO RELACIONAMENTOS COMPLEXOS Atenção aos anéis de relacionamentos M:M. Exemplo Desenvolver um modelo E-R para o histórico de emprego. Para cada pessoa guarde o cargo ocupado, companhia em que trabalhou e a data em que cargo foi ocupado. Uma pessoa pode ocupar vários cargos dentro de uma empresa ao longo de uma carreira. Inicialmente o seguinte modelo foi definido.
PESSOA#*id *sobrenome *nome
COMPANHIA#*código *nome
POSIÇÃO#*título do trabalhoo descrição
ocupantede
ocupadopor
contratadopor
o empregadode
o empregadode
incluido no
A data do cargo parece ser um atributo do relacionamento. Então resolva cada relação M:M.
PESSOA#*id *sobrenome *nome
COMPANHIA#*código *nome
POSIÇÃO#*título do trabalhoo descrição ocupado
por
o empregado
HISTÓRIA HISTÓRIA
HISTÓRIADO CARGO
ORGANIZAÇÃOCOMPANHIA
para
para
para
parapara
contratadoem
contratadoem
para parao empregado
o assuntode
Os atributos data do cargo pertencem a qual entidade intersecção? Todos eles? Nenhum deles? Modelando Relacionamentos Complexos-cont.

77Modelando um relacionamento entre três ou mais entidades como uma Entidade Intersecção com relacionamento obrigatórios com estas entidades. Exemplo O histórico de um emprego de uma pessoa é na real um relacionamento de 3 direções entre entidades PESSOA, COMPANHIA e CARGO. Usar uma única entidade intersecção chamada HISTÓRICO DO EMPREGO para modelar este relacionamento.
HISTÓRICODO EMPREGO#*datado de * datado para
COMPANHIA#*código *nome
CARGO#*título *descrição
PESSOA#*id *sobrenome *nome
empregadorde
incluído
para
em
em
uma partede
Um relacionamento complexo é uma relação entre três ou mais entidades. Notas Rápidas • Uma entidade intersecção em um relacionamento complexo sempre tem relações obrigatórias com as entidades que estão relacionadas. • Para uma entidade intersecção representar um relacionamento complexo, siga as regras da modelagem E-R básica para nomear as entidades e analisar e modelar suas relações, seus atributos e seu UID. • Considerar suas relações obrigatórias como candidatas à inclusão no seu UID. EXERCÍCIO 4-7 No MER do exercicio 3-10 (grupo de usuários) um relacionamento M:M foi modelado entre as entidades MEMBRO e PLATAFORMA. Revise o relacionamento baseando-se nas seguintes informações: “Não, nós realmente não precisamos saber qual plataforma de computador que cada membro esta usando. Em vez disso, que necessitamos saber é quais produtos ORACLE(RDBMS, POR_C, etc) cada membro esta usando e em quais plataformas de computador. Não é necessário manter a versão especifica de cada produto, seu nome é suficiente.

78 EXERCÍCIO 4-8 Desenvolva um modelo para o seguinte negócio: “Eu sou o sócio senior de uma grande e diversificada empresa de advogacia. Minha empresa, Bailey e Associados, trata de uma grande variedade de casos, incluindo trafico, violações, disputas domesticas, questões civis, e casos de homicidios. Nos temos pago um administrador de banco de dados para organizar e mapear vários dados porque a empresa cresceu mais rápido que imaginavamos e agora há casos caindo um atras do outro. Nossa empresa é constituida de departamentos como homicidio, roubo, etc, e cada caso é encaminhado para um departamento particular por razões administrativas. Advogados são tambem lotados em departamentos específicos , mas isto somente para efeito de apropriação de despesass e pagamento, pois um advogado pode trabalhar em casos de outros departamentos. Nos necessitamos uma lista de eventos par um dado caso(essencialmente uma historia para o caso) que inclua um relação de eventos e a data que cada evento tornou-se efetivo. Casos tem que ser identificados por um único numero o qual aparece numa lista com cada data e descrição do evento. Eventos tem codigos especiais, como A para abertura, P para perdido, J para julgamento, e deve ali ser sempre um estado de evento para cada caso. Nós queremos guardar a trilha de informações importantes associadas com o caso incluindo o departamento relacionado e uma breve descrição( com Jones versus Jones). Após um caso ter sido fechado, ele pode ser reaberto numa data futura. Nós atribuimos para casos reabertos novo numero , mas nos precisamos associar o novo numero com o anterior. Advogados podem ser envolvidos em vários casos da mesma maneira varia s pessoas podem ser envolvidas em vários casos. Por exemplo, Jones pode ser um Juiz em um caso e uma testemunha num outro. Nos estamos interessados em guardar as participações e os papeis que eles exerceram no contexto de um particular caso. Envolvimentos devem ser identificados pelo seu nome e a data de nascimento, através de sistema de numeração única. Os tipos de pessoas que podem ser
MEMBRO *nome *sobrenome 0 cargo 0 anuidades recebidas * endereço 0 fone 0 tipo 0
PLATAFORMA #*id * descrição
Usuário de
Usado por

79envolvidas nos casos incluem Juizes(JU), Testemunhas oculares (TO), defensores(DF), e naturalmente Advogados (AD). Por exemplo, nos temos um caso de assassinato, e estamos trabalhando na defesa. Um advogado é designado para o caso, há um juiz presidindo o caso e tambem uma testemunha ocular. Então há quatro pessoas que participam deste caso, e nos precisamos saber tudo a respeito delas. Neste contexto, estamos vendo o advogado simplesmente como parte do caso, e não como uma conta. Para registrar os vários papéis que pessoas podem assumir, considere que elas podem participar em diferentes papeis em diferentes casos, mas apenas num único papel em cada caso .

80

81
Modelo Relacional O Modelo Relacional (MR) foi inicialmente introduzido por Codd (1977) e representa os dados em um banco de dados como uma coleção de relações (tabelas). Observe exemplo na figura 1. EMPREG
Matrícula Nome Sexo Salário111 PEDRO M R$ 1.000,00222 MARIA F R$ 2.000,00333 JOAO M R$ 120,00444 ANA F R$ 120,00321 CARLOS M R$ 150,00123 CLAUDIA F R$ 359,00001 MARCOS M R$ 120,00
Figura 1 – Exemplo de relação (tabela)
Cada linha é denominada tupla; o nome de uma coluna é chamado de atributo; a tabela é chamada de relação. Um domínio D é uma coleção de valores atômicos (que não podem ser divididos). Um domínio está associado a colunas de tabelas. Considere o seguintes exemplos:
Matrícula: conjunto de valores de três dígitos, numéricos, positivos e inteiros. Nome: conjunto de nomes de pessoas; Salário: conjunto de valores numéricos monetários, entre 120,00 e 2000,00.
Um esquema de relação é usado para descrever uma relação. Um esquema de relação R, denotado por R(A1, A2, ..., An), é um conjunto de atributos R = {A1, A2, ..., An}. Cada atributo possui um domínio denotado por dom(Ai ). Cada atributo Ai é o nome do papel de um domínio na relação (por exemplo, o atributo nome refere-se ao papel do domínio de conjunto de nomes de pessoas). O grau de uma relação é o número de atributos n de seu esquema de relação. A relação EMPREG, que possui 4 atributos (grau = 4), pode ser representada segundo o seguinte esquema de relação: EMPREG (Matrícula, Nome, Sexo, Salário) Uma relação r (instância de relação) do esquema de relação R(A1, A2, ..., An), também denotado por r(R), é um conjunto de n-tuplas r = {t1, t2, ..., tm}. O esquema da relação descreve a estrutura da relação; a relação (ou instância da relação) é o conjunto de valores de dados em um determinado instante do mundo real (Observe que, na definição de relação, não se especifica qualquer ordenação para as tuplas de uma relação). Cada n-tupla é uma lista ordenada de valores t = <v1, v2, ..., vn>, onde cada valor vi, 1 < i < n, é um elemento de dom(Ai ) ou um valor nulo. Uma relação r(R) é um subconjunto do produto cartesiano dos domínios que definem R (o produto cartesiano especifica todas as possíveis combinações de valores dos domínios): r(R) ⊆ ( dom(A1) X dom(A2) X ...... X dom(An) )

82Se a cardinalidade de um domínio D é | D |, assumindo todos os domínios com finitos, o número total de tuplas do produto cartesiano é | dom(A1) | * | dom(A2) | * ...... * | dom(An) | A relação, ou instância da relação, é modificada com o tempo, para refletir as alterações do mundo real. O esquema de uma relação é mais estático do que a instância da relação (a alteração do esquema da relação ocorre, por exemplo, quando um novo atributo é adicionado). Vários atributos podem ter o mesmo domínio, mas em diferentes papéis. Por exemplo, os atributos telefone residencial e telefone comercial possui o mesmo domínio, mas indicam papéis distintos. Cada valor em uma tupla é um valor atômico. Portanto, atributos compostos e multivalorados não são permitidos. Atributos multivalorados devem ser representados através de relações separadas. Atributos compostos são representados somente pelos atributos componentes. Adicionalmente, valores nulos são aplicados em atributos de tuplas nos casos de valores não conhecidos e valores não aplicáveis. 2. Atributos Chave de uma Relação Todas as tuplas de uma relação devem ser distintas. Assim, duas tuplas não podem ter a mesma combinação de valores para todos os seus atributos. O subconjunto mínimo de atributos de uma relação onde não existem duas tuplas com a mesma combinação de valores para tais atributos é dito chave da relação (É comum ocorrer várias chaves candidatas para chave da relação). O valor dos atributos chave pode ser usado para identificar unicamente uma tupla em uma relação. Os atributos chave de uma relação constituem uma propriedade do esquema da relação, e não variam a medida em que a relação se modifica (inclusão e exclusão de tuplas). Os atributos selecionados para constituir a chave de um relação são comumente denominados de chave primária da relação (primary key - PK); a chave primária identifica cada tupla da relação. 3. Esquema e Instância de Banco de Dados Relacional Um esquema de banco de dados relacional S é um conjunto de esquemas de relação S = {R1, R2, ..., Rm} e um conjunto de restrições de integridade. Uma instância de banco de dados relacional (ou banco de dados relacional) DB de S é um conjunto de instâncias de relação DB = {r1, r2, ..., rm}, onde ri é uma instância de Ri, e cada instância de relação deve satisfazer as restrições de integridade do esquema de banco de dados relacional. EMPREG Nome Matric Endereço Sexo Salário DataNasc NumDepto MatricSuperv DEPTO NumDepto NomeDepto
Figura 2 – Exemplo de esquema de banco de dados relacional 4. Restrições de Integridade em um Esquema de BD Relacional

83A restrição de integridade de entidade indica que nenhum valor de chave primária pode assumir valor nulo (adicionalmente, valores para a chave primária devem ser únicos em uma relação), pois a chave primária é utilizada para identificar cada tupla de uma relação. A restrição de integridade referencial é uma restrição que é especificada entre duas relações, sendo utilizada para manter a consistência associada a tuplas de duas relações (uma tupla em uma relação está relacionada com uma tupla em outra relação). A integridade referencial entre relações é implementada através de chave estrangeira (foreign key - FK). Considere dois esquemas de relação R1 e R2, onde um conjunto de atributos em R1 é denominado chave estrangeira (FK) se satisfaz as seguintes condições: Os atributos da FK (chave estrangeira) em R1 tem o mesmo domínio dos atributos PK (chave
primária) em R2. O valor de FK em uma tupla t1 de R1 pode assumir os seguintes valores:
• valor de PK de alguma tupla t2 de R2 (t1[FK] = t2[PK]), ou • valor nulo.
Em um banco de dados com muitas relações, usualmente existirão muitas restrições de integridade referencial. Restrições de integridade referencial tipicamente surgem dos relacionamentos associados às entidades. Como exemplo, observe o atributo NumDepto no esquema de relação EMPREG; este atributo é uma chave estrangeira (FK), que referencia a chave primária (PK) no esquema de relação DEPTO, e implementa uma associação entre empregado e departamento (um empregado trabalha para um departamento). Cada tupla de EMPREGADO possui um valor para o atributo NumDepto que identifica um departamento. 5. Álgebra Relacional A álgebra relacional consiste em um conjunto de operações utilizadas para manipular relações. Uma consulta em um banco de dados que segue o modelo relacional é realizada através da aplicação de operações da álgebra relacional; por exemplo, uma consulta pode selecionar algumas tuplas de uma relação (os empregados de sexo masculino) e, adicionalmente, combinar tais tuplas com tuplas de outra relação (os empregados de sexo masculino e seus respectivos dependentes).
Importante O resultado de cada operação da álgebra relacional é uma nova relação, que pode ser manipulada por outras operações da álgebra relacional. Assim, as operações da álgebra relacional são realizadas sobre relações inteiras (não em uma tupla (linha) da relação; o resultado dessas operações é encarado como uma nova relação. 5. Operação de Seleção A operação de seleção é utilizada para selecionar um subconjunto das tuplas de uma relação (linhas de uma tabela), a partir de uma condição de seleção. A seguinte notação pode ser utilizada, onde a operação de seleção é representada pela letra minúscula grega sigma (σ):
σ <condição de seleção> (<nome da relação>) Para selecionar os empregados de sexo masculino, a partir da relação EMPREG da figura 1, aplica-se
σ Sexo=’M’ (EMPREG) resultando na relação
Matrícula Nome Sexo Salário111 PEDRO M R$ 1.000,00333 JOAO M R$ 120,00

84321 CARLOS M R$ 150,00001 MARCOS M R$ 120,00
Observe que a relação resultante possui os mesmos atributos da relação utilizada na operação. Na <condição de seleção>, pode-se utilizar os operadores de comparação { = , < , > , ≠ , ≤ , ≥ }. Outros operadores são também utilizados: NOT, AND e OR; a operação
σ (Sexo=’M’) AND (Salário > 120.00) (EMPREG) resulta na relação
Matrícula Nome Sexo Salário111 PEDRO M R$ 1.000,00321 CARLOS M R$ 150,00
Na verdade, a operação de seleção é aplicada para cada tupla (linha) da relação, com o intuito de compor a relação resultante (conjunto resposta da operação). A operação de seleção é unária; isto é, é aplicada em uma única relação. O número de tuplas da relação resultante é sempre menor ou igual ao número de tuplas da relação utilizada na operação. A operação de seleção é comutativa:
σ <cond 1> (σ <cond 2> (R) ) = σ <cond 2> (σ <cond 1> (R) ) Pode-se combinar operações em cascata em uma única operação que utiliza o operador AND:
σ <cond 1> (σ <cond 2> (R) ) = σ <cond 1> AND <cond 2> (R) 6. Operação de Projeção A operação de projeção é utilizada para selecionar alguns atributos de uma relação (colunas de uma tabela), descartando os demais atributos. Considere a seguinte notação:
π <lista de atributos> (<nome da relação>) Para selecionar somente o nome e o salário de empregados, a partir da relação EMPREG da figura 1, a operação
π Nome, Salário (EMPREG) resulta na relação
Nome SalárioPEDRO R$ 1.000,00MARIA R$ 2.000,00JOAO R$ 120,00ANA R$ 120,00CARLOS R$ 150,00CLAUDIA R$ 359,00MARCOS R$ 120,00
A operação de projeção remove implicitamente as tuplas duplicadas presentes na relação resultante; tal situação pode ocorrer quando não são selecionados os atributos de chave primária da relação (imagine uma operação de projeção das colunas salário e sexo). O número de tuplas na relação resultante é sempre menor ou igual ao número de tuplas da relação utilizada na operação (devido a eliminação de tuplas duplicadas). A operação de projeção não é comutativa:
π <lista 1> (π <lista 2> (R) ) ≠ π <lista 2> (π <lista 1> (R) ) A operação π <lista 1> (π <lista 2> (R) ) será igual a π <lista 1> (R), somente se <lista 2> possui os atributos de <lista 1>; caso contrário, um erro é caracterizado.

85 A operação
T ← π Nome, Salário (σ Sexo=’M’ (EMPREG) ) resulta na relação T com o nome e o salário dos empregados de sexo masculino (operações de seleção e projeção). A referida operação pode ser apresentada da seguinte forma:
S ← σ Sexo=’M’ (EMPREG) T ← π Nome, Salário (S)
7. Operação de Produto Cartesiano A operação de produto cartesiano é uma operação binária que combina as tuplas de ambas as relações envolvidas (tais relações não necessitam ser união-compatíveis). Considere duas relações R (A1, A2, ..., An) e S (B1, B2, ..., Bm); o resultado do produto cartesiano consiste em uma relação Q com n + m atributos: Q (A1, A2, ..., An, B1, B2, ..., Bm), nesta ordem. A relação resultante Q possui uma tupla para cada possível combinação de tuplas de R e S. Como exemplo, considere as relações da figura 3: EMPREG
Matríc Nome Sexo Salário Dep111 PEDRO M R$ 1.000,00 VE222 MARIA F R$ 2.000,00 EN123 CLAUDIA F R$ 359,00 VE001 MARCOS M R$ 120,00 EN
DEPTO
CodDep NomeDepVE VENDASEN ENGENHARIA
Figura 3 – Exemplo de banco de dados com 2 tabelas.
O produto cartesiano, denotado por EMPREG X DEPTO, resulta na relação
Matríc Nome Sexo Salário Dep CodDep NomeDep 111 PEDRO M R$ 1.000,00 VE VE VENDAS 111 PEDRO M R$ 1.000,00 VE EN ENGENHARIA 222 MARIA F R$ 2.000,00 EN VE VENDAS 222 MARIA F R$ 2.000,00 EN EN ENGENHARIA 123 CLAUDIA F R$ 359,00 VE VE VENDAS 123 CLAUDIA F R$ 359,00 VE EN ENGENHARIA 001 MARCOS M R$ 120,00 EN VE VENDAS 001 MARCOS M R$ 120,00 EN EN ENGENHARIA
Observe que a relação resultante não possui significado prático, pois relaciona cada empregado com todos os departamentos (inclusive os departamentos que o empregado não está associado). Assim, é necessário aplicar a operação de seleção na relação resultante do produto cartesiano, relacionando cada empregado ao seu departamento associado. Para obter somente dados sobre os empregados e seus respectivos departamentos, pode-se escrever:
σ Dep = ‘VE’ AND CodDep = ‘VE’ (EMPREG X DEPTO) ou
σ EMPREG.Dep = ‘VE’ AND DEPTO.CodDep = ‘VE’ (EMPREG X DEPTO)

86
8. Operações de União, Interseção e Diferença As operações de união, interseção e diferença são ditas binárias, ou seja, são aplicadas em duas relações. Para entender tais operações, considere a existência das relações R e S, referentes aos alunos matriculados nos anos de 1996 e 1997, respectivamente. As relações que participam de tais operações devem ser união-compatíveis, significando que as relações R (A1, A2, ..., Nn) e S (B1, B2, ..., Bn):
- devem ter a mesma quantidade de atributos; e - dom(Ai) = dom(Bi), para 1 ≤ i ≤ n.
A operação de união, denotada por R ∪ S, resulta em uma relação que inclui todas as tuplas das relações R e S, onde as tuplas duplicadas serão eliminadas. Assim, R ∪ S resulta nos alunos que foram matriculados em 1996 ou em 1997. A operação de interseção, denotada por R ∩ S, resulta em uma relação que inclui todas as tuplas presentes em ambas as relações. Assim, R ∩ S resulta nos alunos que foram matriculados em 1996 e em 1997. A operação de diferença, denotada por R − S, resulta em uma relação que inclui todas as tuplas de R que não estão presentes em S. Assim, R − S resulta nos alunos que foram matriculados em 1996 e que não se matricularam em 1997. As operações de união e interseção são comutativas:
R ∪ S = S ∪ R e R ∩ S = S ∩ R A operação de diferença não é comutativa:
R − S ≠ S − R Observe que R ∩ S = R – (R – S) 9. Operação de Renomeação Para efetuar uma operação binária que envolva duas tabelas iguais, utiliza-se o operador de renomeação para eliminar possíveis ambigüidades. A expressão ρ EMPREG2 (EMPREG) renomeia a relação EMPREG para EMPREG2. A consulta “qual o empregado de maior salário ?” pode ser solucionada primeiramente buscando o maior salário e, então, pesquisando dados do(s) empregado(s) que possui(em) tal salário. Na expressão EMPREG X ρ EMPREG2 (EMPREG) o operador ρ renomeia EMPREG para EMPREG2 com o intuito de efetuar um produto cartesiano entre duas imagens da relação empregado. A expressão
σ EMPREG.Salario < EMPREG2.Salario (EMPREG X ρ EMPREG2 (EMPREG) ) resulta em linhas do produto cartesiano onde o salário de EMPREG é sempre menor que o salário de EMPREG2; assim, cada linha de EMPREG é combinada com as linhas de EMPREG2 com maior salário. Pode-se concluir que no resultado do produto cartesiano não aparecerá o maior salário na imagem EMPREG, somente na imagem EMPREG2. A expressão
S π EMPREG.Salario (σ EMPREG.Salario < EMPREG2.Salario (EMPREG X ρ EMPREG2 (EMPREG) ) ) resulta em uma relação que não inclui o maior salário (removendo implicitamente linhas duplicadas), como observado a seguir:

87
SalárioR$ 1.000,00
R$ 120,00 R$ 150,00 R$ 359,00
Para obter o maior salário, pode-se utilizar a seguinte operação de diferença T π Salario (EMPREG) - S
Assim, a consulta “qual o empregado de maior salário ?” poderia ser solucionada com a expressão: π Matric, Nome (σ EMPREG.Salario = T.Salario (EMPREG X T ) )
10. Operação de Junção (Join) A operação de junção (join) é utilizada para combinar tuplas relacionadas de duas relações. Essa operação é fundamental pois permite processar relacionamentos entre relações. Para relacionar cada empregado com o seu departamento associado, a operação de junção (join), denotada por EMPREG Dep = CodDep DEPTO, a partir da figura 3, resulta na relação
Matríc Nome Sexo Salário Dep CodDep NomeDep 111 PEDRO M R$ 1.000,00 VE VE VENDAS 222 MARIA F R$ 2.000,00 EN EN ENGENHARIA 123 CLAUDIA F R$ 359,00 VE VE VENDAS 001 MARCOS M R$ 120,00 EN EN ENGENHARIA
De forma didática, a operação de junção (join) consiste na aplicação da operação de seleção na relação resultante do produto cartesiano entre relações. A operação acima poderia ser apresentada como
σ Dep = CodDep (EMPREG X DEPTO) Assim, a junção (join) resulta nas combinações de tuplas que satisfazem a condição, enquanto que o produto cartesiano resulta em todas as possíveis combinações de tuplas. Uma operação de junção (join) entre as relações R e S é apresentada como
R <condição> AND <condição> AND ... AND <condição> S para <condição> igual a Ai θ Bj onde: Ai é atributo de R
Bj é atributo de S Ai e Bj possuem o mesmo domínio θ consiste em uma da operações { = , < , ≤ , > , ≥ , ≠ }
Um equijoin consiste em um join (junção) que utiliza o operador de igualdade (=) na condição de junção. O exemplo apresentado acima consiste em um equijoin. Um natural join consiste em um equijoin sem repetição de colunas envolvidas na condição de junção. O exemplo acima apresentado não constitui um natural join, pois ocorre tal repetição de condição no resultado da operação (Dep e CodDep). Para alguns autores, um natural join entre duas relações R e S é também denotado por R S. Um outer join mantém no resultado da operação as linhas que não satisfazem a condição de um natural join. Como exemplo, considere a relação abaixo que consiste no resultado de um outer join:
Matríc Nome Sexo Salário Depto NomeDependente 111 PEDRO M R$ 1.000,00 VE PEDRO FILHO 222 MARIA F R$ 2.000,00 EN < null >123 CLAUDIA F R$ 359,00 VE < null >001 MARCOS M R$ 120,00 EN MARCOS JUNIOR

88A relação acima é resultado de um outer join entre as relações EMPREGADO e DEPENDENTE. Observe que os empregados 222 e 123, apesar de não possuírem dependentes, estão presentes nesta relação resultante. 11. Operação de Divisão Considere a consulta: “Qual o nome das livrarias que vendem todos os livros da editora LIVROS MODERNOS ??”. A expressão
X σ NomeEd = ‘LIVROS MODERNOS’ (EDITORA ) obtém dados da referida editora. A expressão
S π ISBN (X LIVRO ) retorna o código dos livros (ISBN) editados pela editora LIVROS MODERNOS. A expressão
T π NomeLivraria, ISBN (LIVRARIA VENDE_LIVRO ) retorna linhas com o nome de livraria e código de livro que é vendido por tal livraria. A expressão T ÷ S retorna os nomes de livrarias que vendem todos os livros da editora LIVROS MODERNOS.

89
Modelo Relacional (cont...) Neste ponto, apresentaremos de forma sucinta alguns dos passos envolvidos ao mapeamento do Modelo Entidade Relacionamento para o Modelo Relacional. Os aspectos explorados neste documento deverão ser enriquecidos em análises complementares. Vale ressaltar que, para melhor entender os elementos apresentados, deve-se conhecer aspectos teóricos dos modelos envolvidos. 1. Para cada tipo de entidade E regular (não fraca) no esquema ER, cria-se uma relação R que inclui
todos os atributos simples de E. Para os atributos compostos, deve-se incluir somente os atributos simples componentes. Deve-se selecionar um dos atributos chave de E (se existirem vários candidatos) como chave primária de R.
2. Para cada tipo de entidade fraca W no esquema ER, com tipo de entidade E que a identifica, cria-
se uma relação R e inclui-se todos os atributos simples de W (e atributos simples componentes) como atributos de R. Adicionalmente, inclui-se como atributos de chave estrangeira (FK) em R os atributos de chave primária do tipo de entidade E (que identifica a entidade fraca). A chave primária (PK) de R é combinação da chave primária do tipo de entidade E com a chave parcial do tipo de entidade fraca W.
3. Para tipo de relacionamento 1:1 binário R no esquema ER, identificam-se as relações S e T que
correspondem aos tipos de entidade que participam de R. Escolhe-se uma das relações e inclui-se como chave estrangeira (FK) dessa relação a chave primária (PK) da outra relação (por exemplo, inclui-se como FK em S a PK de T) (é melhor escolher um tipo de entidade com participação total em R) . Adicionalmente, todos os atributos simples (e atributos simples componentes) do tipo de relacionamento R devem ser incluídos em S.
4. Para cada tipo de relacionamento R binário 1:N, identifica-se a relação S que representa o tipo de
entidade que participa do lado N do tipo de relacionamento. Inclui-se como chave estrangeira (FK) em S a chave primária da relação T que representa o outro tipo de entidade participante em R. Adicionalmente, inclui-se quaisquer atributos simples (e atributos simples componentes) do tipo de relacionamento R como atributo de S.
5. Para cada tipo de relacionamento R binário M:N, cria-se uma nova relação S para representar R.
Inclui-se como atributos de chave estrangeira (FK) em S as chaves primárias das relações que representam os tipos de entidades participantes; tal combinação irá formar a chave primária de S. Inclui-se quaisquer atributos simples (e atributos simples componentes) de R como atributos de S.
6. Para cada atributo multivalorado A, cria-se uma nova relação R que inclui um atributo
correspondente para A mais o atributo chave primária K da relação que representa o tipo de entidade ou tipo de relacionamento que tem A como um atributo. A chave primária (PK) de R é a combinação de A e K. Se o atributo multivalorado é composto, inclui-se seus atributos componentes.
7. Para cada tipo de relacionamento R, envolvendo n tipos de entidade, n > 2, cria-se uma nova
relação S para representar R. Inclui-se como atributos de chave estrangeira (FK) em S as chaves primárias (PK) das relações que representam os tipos de entidade participantes. Adicionalmente, inclui-se quaisquer atributos simples de R (e atributos simples componentes) como atributos de S. A chave primária (PK) de S será a combinação de todas as chaves estrangeiras que referenciam as relações representando os tipos de entidades participantes (observe que se a restrição de participação (min, max) de um dos tipos de entidade E participante em R for max = 1, então a chave primária de S pode ser o único atributo de chave estrangeira (FK) que referencia tal relação).

90
Modelo Relacional (cont...) 1. Generalização/Especialização Através do conceito de generalização/especialização é possível atribuir propriedades particulares a um subconjunto das ocorrências (especializadas) de um tipo de entidade genérico. Observe o diagrama a seguir, onde um triângulo isósceles é utilizado para representar o conceito:
Figura 1 – Exemplo de generalização/especialização. Uma especialização deve ser usada quando sabe-se que as classes especializadas possuem propriedades (atributos, relacionamentos, generalizações, especializações) particulares. Na figura 1, uma pessoa física possui os atributos CPF e Sexo; uma pessoa jurídica possui os atributos CGC e Ramo de Atividade. Adicionalmente, as entidades especializadas herdam os atributos da entidade genérica. Uma forma de traduzir generalização/especialização para o modelo relacional, consiste em criar uma relação para o tipo de entidade genérica e, para cada tipo de entidade especializada, criar uma relação que inclua uma coluna para cada atributo desse tipo de entidade e uma coluna referente ao atributo chave do tipo de entidade genérica, que será o atributo chave da relação; tal atributo também será caracterizada como chave estrangeira. Da figura 1, pode-se obter: CLIENTE (CodCli, Nome, TipoPes) PES_FIS (CodCli, CPF, Sexo, DataNasc) PES_FIS (CodCli) referencia CLIENTE PES_JUR (CodCli, CGC, RamoAtiv) PES_JUR (CodCli) referencia CLIENTE Uma outra alternativa, preferida em generalização exclusiva (uma entidade genérica está associada a uma única entidade especializada) e total (cada entidade genérica deve pertencer a uma entidade especializada), consiste em criar uma relação para cada tipo de entidade especializada, que inclui os atributos desse tipo de entidade e do tipo de entidade genérica. Da figura 1, pode-se obter: PES_FIS (CodCli, Nome, CPF, Sexo, DataNasc) PES_JUR (CodCli, Nome, CGC, RamoAtiv) A segunda alternativa é preferida em generalização exclusiva (uma entidade genérica está associada a uma única entidade especializada) e total (cada entidade genérica deve pertencer a uma entidade especializada) 2. Entidade Associativa
CLIENTE
CodCli Nome
PES. FÍSICA PES. JURÍDICA
CPF Sexo CGC RamoDataNasc
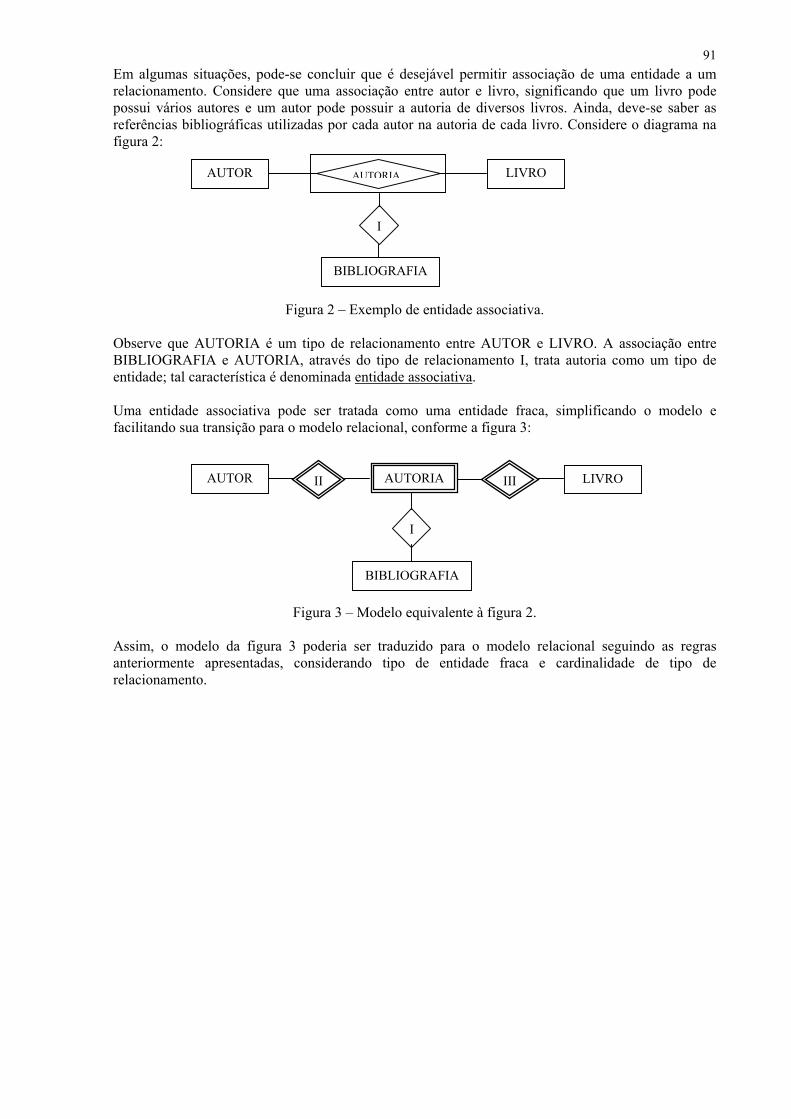
91Em algumas situações, pode-se concluir que é desejável permitir associação de uma entidade a um relacionamento. Considere que uma associação entre autor e livro, significando que um livro pode possui vários autores e um autor pode possuir a autoria de diversos livros. Ainda, deve-se saber as referências bibliográficas utilizadas por cada autor na autoria de cada livro. Considere o diagrama na figura 2:
Figura 2 – Exemplo de entidade associativa. Observe que AUTORIA é um tipo de relacionamento entre AUTOR e LIVRO. A associação entre BIBLIOGRAFIA e AUTORIA, através do tipo de relacionamento I, trata autoria como um tipo de entidade; tal característica é denominada entidade associativa. Uma entidade associativa pode ser tratada como uma entidade fraca, simplificando o modelo e facilitando sua transição para o modelo relacional, conforme a figura 3:
Figura 3 – Modelo equivalente à figura 2. Assim, o modelo da figura 3 poderia ser traduzido para o modelo relacional seguindo as regras anteriormente apresentadas, considerando tipo de entidade fraca e cardinalidade de tipo de relacionamento.
AUTOR AUTORIA LIVRO
BIBLIOGRAFIA
I
AUTOR LIVRO
BIBLIOGRAFIA
I
AUTORIAII III

92

93
SQL Uma linguagem procedural fornece uma descrição detalhada de COMO um tarefa é realizada, operando sobre um registro ou uma unidade de dados a cada vez. Exemplos: Pascal, COBOL, etc. Uma linguagem não procedural é uma descrição de O QUE se deseja; o sistema deverá determinar a forma de fazer; a linguagem SQL é um exemplo dessa classe de linguagem. O contexto de atuação da SQL concentra-se em tabelas com as características: • Dados são gravados em um banco de dados feito de tabelas. • programa pede ao SQL que retorne dados para ele, sem qualquer preocupação com a estrutura
física ou localização dos dados. • A estrutura das tabelas é definida dentro do banco de dados, não em cada programa. • A ordem das tabelas dentro do banco de dados não é importante,. Elas são identificadas por nome. • A ordem das colunas dentro de uma tabela não é importante. Elas são identificadas por nome. • A ordem das linhas dentro de uma tabela não é importante. Elas são identificadas pelos valores em
suas colunas (chaves). • Os dados são sempre apresentados como uma tabela, independente da estrutura interna do banco
de dados. O bom entendimento da álgebra relacional é uma questão fundamental no aprendizado de SQL. Uma consulta complexa pode parecer impossível, até que um dia você comece a pensar em operar sobre conjuntos de dados. Certas descobertas somente ocorrerão se você estiver sensibilizado com a filosofia relacional. A SQL surgiu no início da década de 70, por uma iniciativa da IBM. Nos últimos anos tornou-se a linguagem mais popular para acesso a bancos de dados, juntamente com a difusão de SGBDs relacionais. Existem iniciativas de padronizar a SQL, surgindo padrões SQL-86, SQL-89 e, mais recentemente, SQL-92. De forma geral, os SGBDs implementam padrão SQL e acrescentam características específicas ao padrão; cada SGBD procura incluir elementos que o possam diferenciar de concorrentes. Assim, pode-se observar diversos nomes para a SQL; por exemplo, Transact SQL para o SQL SERVER e PL SQL para ORACLE. Em nossa estudo, procuraremos apresentar SQL tão portável quanto possível, mas as instruções apresentadas poderão ser implementadas no SGBD SQL SERVER. 1. Elementos da SQL Em oportunidade anterior, vimos que SGBD é um software de propósito geral para:
DEFINIÇÃO Implementação de esquema de banco de dados; ou seja, gravação da descrição de dados no banco de dados; ou seja, criação da instância “vazia” do banco de dados. CONSTRUÇÃO carga inicial do banco de dados; ou seja, criação da instância inicial do banco
de dados. MANIPULAÇÃO uso do banco de dados, através de operações de consulta e atualização do dia-
a-dia. • Para a fase de definição, comandos SQL são responsáveis pela criação de tabelas, índices, regras,
etc. Esta classe de comandos é conhecida como DDL (Data Definition Language). • A fase de construção é essencialmente aplicada através dos comandos de atualização
(basicamente, comando INSERT). Alguns SGBDs trazem rotinas dedicadas a esta fase, na forma de programas e utilitários.
• A fase de manipulação é aplicada com os comandos de atualização (INSERT, UPDATE e DELETE) e consulta (SELECT).
Outros comandos podem ser observados: controle de transação, controle de acesso etc.

94 2. Esquema do Banco de Dados DEMO Em nosso banco de dados DEMO, o seguinte esquema pode ser caracterizado: DEPTO ( NumDep, Nome, MatrEmpr, DataInicGer ) DEPTO ( MatrEmpr ) REFERENCIA EMPR ( MatrEmpr ) PROJ ( NumProj, Nome, Local, NumDep ) PROJ ( NumDep ) REFERENCIA DEPTO ( NumDep ) EMPR ( MatrEmpr, PriNome, LetNome, UltNome, Ender, Sexo, Salario, DataNasc, NumDep, MatrSup ) EMPR ( NumDep ) REFERENCIA DEPTO ( NumDep ) EMPR ( MatrSup ) REFERENCIA EMPR ( MatrEmpr ) DEPEND ( MatrEmpr, Nome, Sexo, DataNasc, Parent ) DEPEND ( MatrEmpr ) REFERENCIA EMPR ( MatrEmpr ) TRABALHA_EM ( MatrEmpr, NumProj, Horas ) TRABALHA_EM ( MatrEmpr ) REFERENCIA EMPR ( MatrEmpr ) TRABALHA_EM ( NumProj ) REFERENCIA PROJ ( NumProj ) DEPTO_LOCAL ( NumDep, Local ) DEPTO_LOCAL ( NumDep ) REFERENCIA DEPTO ( NumDep )
Figura 1 – Esquema do banco de dados DEMO 3. Exemplo de Criação de Tabelas (DDL)
TIPOS DE DADOS Cada SGBD implementa um conjunto de tipos de dados para a definição de atributos. Por exemplo, no SQL SERVER alguns dos tipos de dados são:
Classe de Valores Tipo de Dado Valores Binários binary (n) varbinary (n) Cadeia de Caracteres char (n) varchar (n) Data e Hora Datetime smalldatetime Valores Numéricos Exatos decimal (p[,s]) numeric (p[,s]) Valores Numéricos Aproximados float (n) real Valores Inteiros int smallint tinyint Valores Monetários money smallmoney Valores de Imagem e Texto text image Dados Especiais bit timestamp
Figura 2 – Alguns tipos de dados do SQL SERVER CRIAÇÃO DA TABELA EMPR Alternativa 1:
CREATE TABLE EMPR ( MatrEmpr char(06) NOT NULL ,PriNome varchar(30) NOT NULL ,LetNome char(01) NULL ,UltNome varchar(30) NOT NULL ,Ender varchar(40) NULL ,Sexo char(01) NOT NULL CHECK (Sexo = ‘M’ OR Sexo = ‘F’) ,Salario smallmoney NULL ,DataNasc smalldatetime NOT NULL ,NumDep smallint NOT NULL ,MatrSup char(10) NULL ,PRIMARY KEY (MatrEmpr) ,FOREIGN KEY (NumDep) REFERENCES DEPTO (NumDep) ,FOREIGN KEY (MatrSup) REFERENCES EMPR (MatrEmpr) )
Alternativa 2:

95CREATE TABLE EMPR ( MatrEmpr char(06) NOT NULL ,PriNome varchar(30) NOT NULL ,LetNome char(01) NULL ,UltNome varchar(30) NOT NULL ,Ender varchar(40) NULL ,Sexo char(01) NOT NULL CHECK (Sexo = ‘M’ OR Sexo = ‘F’) ,Salario smallmoney NULL ,DataNasc smalldatetime NOT NULL ,NumDep smallint NOT NULL ,MatrSup char(10) NULL ,PRIMARY KEY (MatrEmpr) ) ALTER TABLE EMPR ADD FOREIGN KEY (NumDep) REFERENCES DEPTO (NumDep) ALTER TABLE EMPR ADD FOREIGN KEY (MatrSup) REFERENCES EMPR (MatrEmpr)
Observações: • A sentença ‘CHECK (Sexo = ‘M’ OR Sexo = ‘F’)’ restringe o conjunto de valores para o dado Sexo. • A alternativa 2 utiliza a instrução ALTER TABLE para definir chaves estrageiras. CRIAÇÃO DA TABELA DEPTO
CREATE TABLE DEPTO ( NumDep smallint NOT NULL ,Nome char(30) NOT NULL ,MatrEmpr char(06) NOT NULL ,DataInicGer smalldatetime NOT NULL DEFAULT getdate() ,PRIMARY KEY (NumDep) ,FOREIGN KEY (MatrEmpr) REFERENCES EMPR (MatrEmpr) )
Observações: • A sentença ‘DEFAULT getdate()’ atribui um valor default para o dado DataInicGer; um valor default
é aquele que é assumido quando nenhum outro valor for explicitamente atribuído. No SQL SERVER, a função ‘getdate()’ retorna a data e hora atuais; no ORACLE, tal função chama-se ‘SYSDATE’.

96
SQL (2) 1. Consulta de Dados – Estrutura Básica A consulta em bancos de dados é efetuada através do comando SELECT. Uma sintaxe simplificada para este comando é:
SELECT lista-de-dados FROM lista-de-tabelas WHERE condição-de-seleção
Onde: lista-de-dados = refere-se às colunas que existirão no conjunto resposta da consulta. lista-de-tabelas = refere-se às tabelas que serão utilizadas como fonte de dados para a consulta. condição-de-seleção = será utilizada para a seleção de linhas da(s) tabela(s) consultada(s). A consulta
SELECT * FROM EMPR
retorna todas as linhas da tabela EMPR (todas as colunas). O uso de * (asterisco) após a cláusula SELECT implica que alterações na estrutura de uma tabela podem modificar o resultado da consulta; por exemplo, se uma nova coluna é incluída em uma tabela, o resultado da consulta irá incluir a nova coluna. A consulta
SELECT * FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
retorna todas as linhas da tabela EMPR onde a condição composta ‘Sexo = M AND Salario > 500’ é satisfeita (todas as colunas). A consulta
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
retorna todas as linhas da tabela EMPR onde a condição composta ‘Sexo = M AND Salario > 500’ é satisfeita; somente as colunas MatrEmpr, PriNome e UltNome estão presentes no resultado da consulta. Esta construção para o comando SELECT seleciona as colunas de uma consulta, e define a seqüência de apresentação dessas colunas. A consulta ‘Qual a matrícula dos empregados sem endereço cadastrado ?’ poderia ser implementada pelo comando
SELECT MatrEmpr FROM EMPR WHERE Ender = NULL
Observe que na cláusula WHERE existe uma condição que referencia explicitamente um valor nulo (NULL).

97
2. Consulta de Dados – Breves Dicas • Inicie com a cláusula SELECT, e escreva uma lista do que você necessita para o conjunto
resposta. Isso fornece a você uma meta e constitui o que deve ser apresentado ao usuário. • Ponha todas as tabelas contendo as tabelas necessárias para complementar a lista SELEC dentro da
cláusula FROM. Excessos podem ser removidos adiante. Todo o trabalho está na cláusula WHERE.
• Pense sobre a solução do problema em termos de conjuntos. As vezes, inverter a ordem da palavras ajuda; por exemplo, em vez de “Dê-me os carros de cor vermelha”, diga “Vermelha é a cor de todos os carros que eu preciso”.
• As vezes, negar o que se deseja pode ajudar; por exemplo, em vez de “Dê-me os carros que atendem a todos os requisitos de teste”, diga “Eu não quero aqueles carros que falharam em quaisquer dos critérios de teste”.
• Esteja atento a sua lógica. Diferentemente de linguagens procedurais, SQL requer que todos o trabalho seja feito em uma única expressão, que pode ser complexa.
• Lembre-se que valores nulos (NULLS) podem ocorrer em todos os possíveis lugares. 3. Consulta de Dados – Alteração de Identificação de Colunas A consulta
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
poderia retornar o seguinte conjunto resposta, onde os nomes de coluna são os mesmos da tabela de origem: MatrEmpr PriNome UltNome 981234 JOSE SILVA 981232 LEO CARDOSO 981212 PAULO VIEIRA
A consulta
SELECT MatrEmpr ‘Matricula’, PriNome ‘Primeiro Nome’, UltNome ‘Ultimo Nome’ FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
retorna o seguinte conjunto resposta, que possui novos nomes de coluna: Matricula Primeiro Nome Ultimo Nome 981234 JOSE SILVA 981232 LEO CARDOSO 981212 PAULO VIEIRA
OBSERVAÇÕES: • A primeira coluna do conjunto resposta teve seu nome modificado de MatrEmpr para Matricula. Esta
mudança poderia ser efetuada de 4 formas distintas: (I) MatrEmpr ‘Matricula’ (II) MatrEmpr Matricula (III) ‘Matricula’ = MatrEmpr (IV) Matricula MatrEmpr As alternativas (II) e (IV) somente podem ser utilizadas se o novo nome de coluna for um identificador;
por exemplo, a expressão PriNome Primeiro Nome não pode ser utilizada, mas a expressão PriNome Primeiro_Nome é possivel, alterando o nome de coluna de PriNome para Primeiro_Nome.

98 4. Consulta de Dados – Inclusão de Valores Constantes A consulta
SELECT ‘Os dados do empregado são:’, MatrEmpr, PriNome, UltNome FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
poderia retornar o seguinte conjunto resposta, onde a primeira coluna possui um valor constante: MatrEmpr PriNome UltNome Os dados do empregado são: 981234 JOSE SILVA Os dados do empregado são: 981232 LEO CARDOSO Os dados do empregado são: 981212 PAULO VIEIRA
5. Consulta de Dados – Computação de Valores A consulta
SELECT MatrEmpr, PriNome, UltNome, Salario, Salario * 1.1 NovoSavario FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500
poderia retornar o seguinte conjunto resposta, onde a coluna NovoSalario possui o valor do salário original acrescido de 10 %:
MatrEmpr PriNome UltNome Salario NovoSalario 981234 JOSE SILVA 600 660 981232 LEO CARDOSO 700 770 981212 PAULO VIEIRA 800 880
OBSERVAÇÕES: • Se a computação envolver algum operador com valor nulo, o resultado da operação também será
nulo. • A ordem de precedência envolve inicialmente as operações de multiplicação (*), divisão (/) e
módulo (%), seguidas das operações de adição (+) e subtração (-); o uso de parêntesis na expressão aritmética pode alterar essa ordem de precedência.
6. Consulta de Dados – Computação na Seleção de Linhas A consulta
SELECT MatrEmpr, PriNome, UltNome, Salario, Salario * 1.1 NovoSavario FROM EMPR WHERE Sexo = ‘M’ AND Salario > 500 AND (Salario + 60) < (Salario * 1.1)
poderia retornar o seguinte conjunto resposta, onde a condição de seleção de linhas possui uma computação de valores:
MatrEmpr PriNome UltNome Salario NovoSalario 981232 LEO CARDOSO 700 770 981212 PAULO VIEIRA 800 880

99
SQL (3) 1. Seleção de Linhas Através de Operadores de Comparação A cláusula WHERE especifica um critério para a seleção de linhas. Os seguintes operadores de comparação estão disponíveis:
Operador Descrição = igual a > maior do que < menor do que >= maior ou igual a <= menor ou igual a <> diferente de !> não maior do que !< não menor do que
OBSERVAÇÕES: • A cláusula NOT pode ser utilizada para negar o valor da condição; por exemplo: WHERE NOT Sexo = ‘M’ 2. Seleção de Linhas Através de Faixa de Valores A cláusula BETWEEN especifica um critério para a seleção de linhas, através da definição de uma faixa de valores. SINTAXE:
SELECT lista-de-colunas FROM tabela WHERE expressão [ NOT ] BETWEEN expressão AND expressão
O comando
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE Salario BETWEEN 500 AND 1000
seleciona a matrícula, primeiro nome e último nome dos empregados com salário entre 500 e 1000, inclusive. OBSERVAÇÕES: • A faixa de valores definida por BETWEEN e AND inclui os valores limites da faixa; • O uso de
expressão BETWEEN x AND y não possui a mesma semântica de
expressão > x AND expressão < y pois a cláusula BETWEEN define uma faixa de valores, onde os valores limites dessa
faixa estão incluídos no intervalo; • A cláusula NOT pode ser utilizada para negar o valor da condição.

100 3. Seleção de Linhas Através de Lista de Valores No presente contexto, a cláusula IN permite a seleção linhas a partir da comparação de um valor com um conjunto de valores presentes em uma lista. SINTAXE:
SELECT lista-de-colunas FROM tabela WHERE expressão [ NOT ] IN lista-de-valores
O comando
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE Salario IN (500, 600, 700)
seleciona a matrícula, primeiro nome e último nome dos empregados com salário igual a 500, 600 ou 700. OBSERVAÇÕES: • A cláusula NOT pode ser utilizada para negar o valor da condição. 4. Seleção de Linhas Através de Padrões de Caracteres A cláusula LIKE pode ser utilizada para selecionar linhas através de combinação de padrões de caracteres. Os seguintes caracteres especiais são utilizados na definição de padrões de caracteres: Caracteres Especiais Descrição % qualquer string (cadeia) de zero ou mais caracteres _ qualquer caractere (um único caractere) [ ] define uma lista de valores para um único caractere, para observar se um caractere está
presente nessa lista [ ^ ] define uma lista de valores para um único caractere, para observar se um caractere não
está presente nessa lista Para um melhor entendimento, considere os exemplos abaixo:
‘P%’ cadeia que inicia com o caractere ‘P’ ‘%P’ cadeia que termina com o caractere ‘P’ ‘%P%’ cadeia que possui o caractere ‘P’ ‘_P%’ cadeia cujo segundo elemento é o caractere ‘P’ ‘[CP]%’ cadeia que inicia com os caracteres ‘C’ ou ‘P’ ‘[^CP]%’ cadeia que não inicia com os caracteres ‘C’ ou ‘P’ ‘%SILVA%’ cadeia que possui a seqüência SILVA
SINTAXE: SELECT lista-de-colunas FROM tabela WHERE { expressão [ NOT ] LIKE expressão | [ NOT ] expressão LIKE expressão }
O comando SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE PriNome LIKE ‘R%O’
seleciona a matrícula, primeiro nome e último nome dos empregados cujo primeiro nome inicia com a letra R e termina com a letra O. OBSERVAÇÕES: • A cláusula NOT pode ser utilizada para negar o valor da condição.

101
5. Eliminação de Linhas Duplicadas A cláusula DISTINCT elimina linhas duplicadas no resultado de uma consulta, caso existam. SINTAXE:
SELECT [ DISTINCT | ALL ] lista-de-colunas FROM tabela WHERE condição
O comando
SELECT DISTINCT MatrEmpr FROM DEPEND
retorna a matrícula dos empregados que possuem dependentes; observe que se um empregado possui mais de um empregado, sua matrícula aparece uma única vez no resultado da consulta. OBSERVAÇÕES: • Uma duplicação de linha é somente caracterizada se todos as colunas da referida linha são iguais
às colunas de alguma linha já existentes na tabela; • A cláusula ALL especifica que todas as linhas do resultado de uma consulta serão consideradas,
independentes de ocorrências de duplicação; essa é conduta default para o comando SELECT; • No contexto de eliminação de linhas duplicadas, uma ocorrência de valor nulo é considerado igual
a outro valor nulo. 6. Ordenação do Resultado de uma Consulta A cláusula ORDER BY ordena o resultado de uma consulta de acordo com uma ou mais colunas. SINTAXE:
SELECT [ DISTINCT | ALL ] lista-de-colunas FROM tabela WHERE condição ORDER BY coluna [ ASC | DESC ] [ , coluna [ ASC | DESC ] ... ]
O comando
SELECT MatrEmpr, PriNome, UltNome FROM EMPR ORDER BY PriNome, UltNome
apresentada uma relação de empregados, ordenada pelo primeiro nome e último nome. OBSERVAÇÕES: • A cláusula ASC determina a ordenação ascendente a partir da coluna especificada; a conduta dessa
cláusula é encarada como default; • A cláusula DESC determina a ordenação descendente a partir da coluna especificada; • Se mais de uma coluna é especificada após a cláusula ORDER BY, a ordenação será aninhada; • A posição relativa de uma coluna após a cláusula SELECT pode ser usada na referência de colunas
para ordenação; no exemplo SELECT MatrEmpr, PriNome, UltNome FROM EMPR ORDER BY 2, 3
a ordenação será efetuada a partir das colunas PriNome e UltNome, nessa ordem.

102
SQL (4) 1. Consulta de Dados em Várias Tabelas: Produto Cartesiano O comando SELECT permite que uma consulta solicite dados de várias tabelas; inúmeras composições podem ser realizadas a partir de dados de várias tabelas. Este item concentra-se em uma operação denominada Produto Cartesiano, conforme sintaxe abaixo: SINTAXE:
SELECT lista-de-colunas FROM tabela [ , tabela ... ]
Considere as seguintes tabelas:
DEPTO NumDep Nome MatrEmpr DataInicGer 01 VENDAS 981222 01/10/1998 02 ENGENHARIA 981234 01/11/1998
PROJ NumProj Nome Local NumDep P01 DRENAGEM Plano Piloto 02 P03 JUROS ZERO Toda Cidade 01 P02 PAVIMENTACAO Planaltina 02
O comando
SELECT * FROM DEPTO, PROJ
resulta em NumDep Nome MatrEmpr DataInicGer NumProj Nome Local NumDep 01 VENDAS 981222 01/10/1998 P01 DRENAGEM Plano Piloto 02 01 VENDAS 981222 01/10/1998 P03 JUROS ZERO Toda Cidade 01 01 VENDAS 981222 01/10/1998 P02 PAVIMENTACAO Planaltina 02 02 ENGENHARIA 981234 01/11/1998 P01 DRENAGEM Plano Piloto 02 02 ENGENHARIA 981234 01/11/1998 P03 JUROS ZERO Toda Cidade 01 02 ENGENHARIA 981234 01/11/1998 P02 PAVIMENTACAO Planaltina 02 Vale ressaltar que a coluna NumDep na tabela PROJ determina o departamento que controla um projeto. No conjunto de dados resultante, observa-se que cada linha da tabela DEPTO é concatenada com cada linha da tabela PROJ; assim, o conjunto resultante possui Ne x Nj linhas, onde Ne e Nj constituem a quantidade de linhas das tabelas DEPTO e PROJ, respectivamente. Embora o usuário que realizou a consulta possa ter tido a intenção de associar cada projeto com o departamento que o controla, a construção do exemplo não é adequada para tal necessidade. OBSERVAÇÕES: • É possível qualificar o nome de uma coluna, através da construção tabela.coluna.
Exemplo 1: SELECT DEPTO.NumDep, DEPTO.Nome, PROJ.NumProj, PROJ.Nome FROM DEPTO, PROJ

103Exemplo 2 (equivalente ao exemplo 1; apenas atribui sinônimo (alias) para cada tabela: D
e P para as tabelas DEPTO e PROJ, respectivamente): SELECT D.NumDep, D.Nome, P.NumProj, P.Nome FROM DEPTO D, PROJ P
• Na prática, a operação de produto cartesiano é pouca utilizada. 2. Consulta de Dados em Várias Tabelas: Junção (Join) Um Join (Junção) entre tabelas consiste, basicamente, na seleção de algumas linhas resultantes do produto cartesiano entre essas tabelas. Essa seleção consiste na utilização da cláusula WHERE, conforme sintaxe abaixo: SINTAXE:
SELECT lista-de-colunas FROM tabela [ , tabela ... ] WHERE condição
O comando
SELECT * FROM DEPTO D, PROJ P WHERE D.NumDep = P.NumDep
resulta em NumDep Nome MatrEmpr DataInicGer NumProj Nome Local NumDep 01 VENDAS 981222 01/10/1998 P03 JUROS ZERO Toda Cidade 01 02 ENGENHARIA 981234 01/11/1998 P01 DRENAGEM Plano Piloto 02 02 ENGENHARIA 981234 01/11/1998 P02 PAVIMENTACAO Planaltina 02 No conjunto de dados resultante, observa-se que as linhas resultantes satisfazem a condição de junção: D.NumDep = P.NumDep (ou seja, um subconjunto do resultado do produto cartesiano). OBSERVAÇÕES: • Simplificando, o relacionamento entre tabelas é implementado através da presença de dados de
coluna(s) de outra(s) tabela(s) no elenco de colunas de uma tabela; por exemplo, os dados da coluna NumDep da tabela DEPTO está presente na tabela PROJ em uma coluna também denominada NumDep. Aplicando boas regras de projeto, chamadas de regras de normalização, é possível utilizar operações de join de forma eficiente;
• Qualquer operador de comparação pode ser utilizado na aplicação de um join.
3. Equijoin e Natural Join Um equijoin consiste em um join onde utiliza-se o operador de igualdade na comparação de colunas, e todas as colunas das tabelas envolvidas são incluídas no conjunto resposta da consulta. EXEMPLO DE EQUIJOIN:
SELECT * FROM DEPTO D, PROJ P WHERE D.NumDep = P.NumDep
No exemplo acima, a coluna NumDep aparece duas vezes no elenco de colunas resultantes, pois esta coluna está presente nas tabelas DEPTO e PROJ. Um natural join consiste em um equijoin sem qualquer repetição de colunas. A seguir, o exemplo de equijoin é alterado para caracterizar um exemplo de natural join. EXEMPLO DE NATURAL JOIN:
SELECT D.NumDep, D.Nome, P.NomProj, P.Nome, P.Local FROM DEPTO D, PROJ P WHERE D.NumDep = P.NumDep

104OBSERVAÇÕES: • O utilização de natural joins é um recurso para explorar a integridade referencial entre tabelas. Nos
exemplos, o relacionamento entre as tabelas DEPTO e PROJ é implementado através da chave estrangeira NumDep na tabela PROJ.
4. Self-join Um Self-join é um join onde somente uma tabela está envolvida. Considere a tabela: EMPR MatrEmpr PriNome LetNome UltNome Ender Sexo Salario DataNasc NumDep MatrSup 981222 JOSE M SILVA CENTRO M 500.00 01/12/1979 01 981225 981225 LIA H NEVES BARRA F 1200.00 01/12/1975 01 981230 981230 JOAO Null CHAVES PRAIA M 1600.00 01/10/1981 02 null 981250 ANA Null CARDOSO CENTRO F 1000.00 12/12/1976 01 981225 O comando SELECT E.MatrSup, E.PriNome, E.UltNome, E.MatrSup, S.PriNome SupPriNome, SultNome SupUltNome FROM EMPR E, EMPR S WHERE E.MatrSup = S.MatrEmpr resulta em
MatrEmpr PriNome UltNome MatrSup SupPriNome SupUltNome 981222 JOSE SILVA 981225 LIA NEVES 981225 LIA NEVES 981230 JOAO CHAVES 981250 ANA CARDOSO 981225 LIA NEVES
A consulta associa dados de um empregado com dados de seu supervisor. Observe que as instâncias da tabela EMPR são referenciadas como E e S (E está associada ao empregado e ao supervisor). Em nosso contexto, um alias consiste em um sinônimo dado a uma tabela para referenciar cada instância envolvida. Observe que o empregado 981230 não aparece no resultado da consulta, pois ele não possui supervisor direto. 5. Join em Múltiplas Tabelas A operação de join pode ser aplicada em diversas tabelas. Considere a tabela TRABALHA_EM, que implementa a associação de empregados a projetos (cardinalidade N:N):
TRABALHA_EM MatrEmpr NumProj Horas 981222 P01 6 981225 P02 5 981222 P02 8 981250 P01 4 981250 P03 4
O comando
SELECT E.MatrEmpr, E.PriNome, E.UltNome, P.NumProj, P.Nome, EP.Horas FROM EMPR E, PROJ P, TRABALHA_EM EP WHERE E.MatrEmpr = EP.MatrProj AND J.NumProj = EP.NumProj
resulta em
MatrEmpr PriNome UltNome NumProj Nome Horas 981222 JOSE SILVA P01 DRENAGEM 6 981225 LIA NEVES P02 PAVIMENTACAO 5 981222 JOSE SILVA P02 PAVIMENTACAO 8 981250 ANA CARDOSO P01 DRENAGEM 4 981250 ANA CARDOSO P03 JUROS ZERO 4

105 No exemplo, são consultados dados de empregado e de projetos em que este empregado trabalha. Observe que apesar de nenhuma coluna da tabela TRABALHA_EM estar presente no resultado da consulta, esta tabela é utilizada na operação de join. 6. Outer Join Em uma operação de equijoin, somente são incluídas as linhas que satisfazem a condição especificada na cláusula WHERE. Entretando, pode ser desejável que o conteúdo das colunas de uma tabela seja incluído no resultado da consulta. O comando SELECT E.MatrSup, E.PriNome, E.UltNome, E.MatrSup, S.PriNome SupPriNome, SultNome SupUltNome FROM EMPR E, EMPR S WHERE E.MatrSup *= S.MatrEmpr resulta em
MatrEmpr PriNome UltNome MatrSup SupPriNome SupUltNome 981222 JOSE SILVA 981225 LIA NEVES 981225 LIA NEVES 981230 JOAO CHAVES 981230 JOAO CHAVES Null Null Null 981250 ANA CARDOSO 981225 LIA NEVES
A consulta associa dados de um empregado com dados de seu supervisor. Observe a presença do operador *=, indica que todos os dados solicitados da tabela EMPR (instância de empregado, não de supervisor) serão incluídos no resultado da consulta, independente se o empregado possui supervisor. Um outer join é implementado através dos operadores =* e *=, onde a posição do asterisco indica qual tabela exibirá todos os dados selecionados, independente da condição que implementa o join ser avaliada como verdadeira ou falsa.

106
SQL (5) 1. Funções Agregadas - Sumário de Dados
Funções agregadas são utilizadas para obter informações resumidas sobre a(s) tabela(s) consultada(s). As seguintes funções estão disponíveis:
Função Parâmetros Comentário AVG [ ALL | DISTINCT ] expressão média das ocorrências de valores de uma expressão COUNT [ ALL | DISTINCT ] expressão número de ocorrências de valores de uma expressão COUNT * número de linhas selecionadas MAX expressão maior valor dentre as ocorrências de uma expressão MIN expressão menor valor dentre as ocorrências de uma expressão SUM [ ALL | DISTINCT ] expressão soma das ocorrências de valores de uma expressão O comando SELECT COUNT(*), AVG(Salario), MAX(Salario), COUNT(MatrSup) FROM EMPR resulta em
4 1075.00 1600.00 3 onde é solicitada quantidade de empregados, o salário médio dos empregados, o maior salario e a quantidade de empregados que possuem supervisor direto (MatrSup <> null).
OBSERVAÇÕES: • A cláusula DISTINCT denota que ocorrências de valores repetidos não serão consideradas na
aplicação da função agregada; ou seja, COUNT (DISTINCT Salário) informa a quantidade de faixas salariais (quantidade de salários distintos).
• Somente um única é retornada quando se utiliza função agregada. 2. Agrupamento de Dados Uma tabela pode ser dividida em grupos de acordo com algum critério. Por exemplo, os empregados podem ser agrupados por sexo. A cláusula GROUP BY divide uma tabela em grupos. Funções agregadas são comumente utilizadas em agrupamento de dados, produzindo um valor para cada grupo. SINTAXE:
SELECT lista-de-colunas FROM tabela WHERE condição GROUP BY [ ALL ] expressão [ , expressão ] [ HAVING condição ]
O comando SELECT Sexo, COUNT(*), SUM(Salario), AVG(Salario) FROM EMPR GROUP BY Sexo resulta em
Sexo F 2 2200.00 1100.00 M 2 2100.00 1050.00
No exemplo, são apresentados o sexo de empregado e, para cada sexo, a quantidade de empregados, o somatório de salários e a média de salário. Considere a tabela de dependentes:
DEPEND

107MatrEmpr Nome Sexo DataNasc Parent 981222 MARIA F 01/01/1989 FILHO 981225 JOANA F 01/01/1990 FILHO 981222 PEDRO M 12/12/1998 FILHO 981225 MARIA F 11/11/1995 FILHO 981250 PAULO M 10/10/1996 FILHO
A consulta “Quais os empregados que possuem mais de 1 dependente ?” poderia ser respondida pelo comando SELECT MatrEmpr, COUNT(*) QtdeDepend FROM DEPEND GROUP BY MatrEmpr HAVING COUNT(*) > 1 resulta em
MatrEmpr QtdeDepend 981222 2 981225 2
No exemplo, a tabela é dividida em grupos, onde cada grupo deve possuir linhas com o mesmo valor de MatrEmpr (ou seja, separa em cada grupo as linhas de cada empregado). A expressão SELECT MatrEmpr, COUNT(*) computa a quantidade de linhas em cada grupo (ou seja, a quantidade de dependentes para cada empregado) e a expressão HAVING COUNT(*) > 1 seleciona os grupos que possuem mais de uma linha.
OBSERVAÇÕES: • Para fins didáticos, considere a sequência a seguir: 1) se a cláusula WHERE for utilizada, a consulta se inicia pela seleção de linhas solicitadas; 2) as linhas selecionadas são agrupadas, segundo os argumentos associados à cláusula GROUP
BY; 3) se a cláusula HAVING for utilizada, a condição associada a essa cláusula é avaliada para a
seleção de grupos; 4) as informações solicitadas na cláusula SELECT são extraídas de cada grupo selecionado, e
fornecidas para o usuário; • Expressões associadas às cláusulas GROUP BY e WHERE não devem possuir funções
agregadas; • A cláusula ALL inclui todos os grupos da consulta, independente da condição associada à
cláusula HAVING.

108
SQL (6) 1. Subconsultas Uma subconsulta consiste em um comando SELECT posicionado dentro de um outro comando SQL. Em alguns casos, uma consulta pode requerer dados de uma outra consulta para ser processada. EXEMPLO 1: Como exemplo, considere a questão: Que empregado possui o maior salário ? Esta simples pergunta pode ser respondida através do seguinte comando SQL:
SELECT MatrEmpr, PriNome, UltNome, Salario FROM EMPR WHERE Salario = <valor do salário mais alto>
Observe que a informação <valor do salário mais alto> está indefinida, sendo necessário consultá-la no banco de dados; nesse caso, o maior valor para a coluna Salário da tabela EMPR pode ser obtido através do comando:
SELECT MAX(Salario) FROM EMPR
A construção sintática resultante, com um comando SELECT embutido em outro comando SELECT, é alcançada a partir da instrução:
SELECT MatrEmpr, PriNome, UltNome, Salario FROM EMPR WHERE Salario = (SELECT MAX(Salario) FROM EMPR)
EXEMPLO 2: Qual é o percentual de salário de cada empregado, em relação a soma geral de salários de todas os empregados ?
SELECT MatrEmpr, PriNome, UltNome, Salario, 100 * Salario / (SELECT SUM(Salario) FROM EMPR) FROM titles
Neste exemplo, pode-se observar que a consulta mais interna está associada à cláusula SELECT, diferentemente do exemplo anterior. Para cada empregado, é calculado um percentual de salário a partir da consulta mais interna, a qual informa o salário total de todas os empregados. OBSERVAÇÕES:
• Instruções SELECT que possuem uma ou mais subconsultas são freqüentemente denominadas consultas aninhadas;
• Os resultados da consulta mais externa são baseados nos resultados da consulta mais interna; • Uma subconsulta que retorna um conjunto de valores somente pode ser usada se associada à
cláusula WHERE (diferentemente de subconsultas que retornam somente um valor).

109 Neste ponto, exploraremos as palavras IN, ANY, ALL e EXISTS, presentes na cláusula WHERE. SINTAXE PARA CLÁUSULA WHERE:
WHERE expressão [ NOT ] IN ( subconsulta ) WHERE expressão operador-de-comparação [ ANY | ALL ] ( subconsulta ) WHERE [ NOT ] EXISTS ( subconsulta )
EXEMPLO 3:
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE MatrEmpr IN (SELECT DISTINCT MatrEmpr FROM DEPTO)
O exemplo acima seleciona os dados dos empregados que gerenciam algum departamento. O uso da cláusula IN resulta em observar se o que valores do atributo MatrEmpr da tabela EMPR estão presentes na lista resultante da subconsulta. EXEMPLO 4:
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE EXISTS (SELECT MatrEmpr FROM DEPTO WHERE DEPTO.MatrEmpr = EMPR.MatrEmpr)
O exemplo acima é semanticamente idêntico ao exemplo 3, ou seja, produz o mesmo conjunto resposta da consulta do exemplo 3. A cláusula EXISTS testa se a subconsulta produz alguma linha; se isso ocorrer, a condição é avaliada como verdadeira. OBSERVAÇÕES:
• A cláusula IN associada a uma subconsulta resulta em testar se um valor está presente entre os valores produzidos pela subconsulta; se isso ocorrer a condição é avaliada como verdadeira, e, em caso contrário, a condição é avaliada como falsa;
• A cláusula ANY possui semântica similar à cláusula IN, onde a condição será verdadeira se pelo menos um elemento da lista satisfizer a comparação;
• A uso da cláusula ALL difere do uso da cláusula ANY, pois a condição somente será verdadeira se a comparação for satisfeita para todos os elementos da lista;
• Com a cláusula EXISTS, a condição será verdadeira se a subconsulta retornar algum valor (pelo menos um elemento será produzido);
• A cláusula NOT pode ser utilizada para negar o valor da condição.

110
2. Subconsultas Correlatas Em muitos casos, a implementação de subconsultas resulta na execução da subconsulta e, posteriormente, o comando SQL que possui a subconsulta é realizado. Pode ocorrer que a subconsulta utilize dados do comando SQL mais externo em sua sintaxe; neste caso, diz-se que a execução da subconsulta depende do comando SQL mais externo, caracterizando uma subconsulta correla. EXEMPLO:
SELECT MatrEmpr, PriNome, UltNome FROM EMPR WHERE 1 < (SELECT COUNT(*) FROM TRABALHA_EM WHERE TRABALHA_EM.MatrEmpr = EMPR.MatrEmpr)
O comando acima solicita a relação de empregados que trabalham em mais de um projeto. A subconsulta apresentada não pode ser executada independentemente do comando SQL a que pertence. A informação EMPR.MatrEmpr é necessária para a realização da subconsulta, e essa informação será diferente para cada linha da tabela EMPR. Para cada linha da tabela EMPR ocorre a execução da subconsulta, que é necessária à cláusula WHERE do comando SQL mais externo. OBSERVAÇÕES:
• A avaliação da consulta mais interna depende da consulta mais externa, pois a primeira referencia dados da segunda.

111
SQL (7) 1. Atualização de Dados A atualização de dados envolve a inclusão, remoção e modificação dos dados de uma tabela, respectivamente através dos comandos INSERT, DELETE e UPDATE. Uma questão envolvida em atualização de dados é a manutenção da consistência do banco de dados. Por exemplo, uma manutenção em uma tabela pode requerer a atualização de dados em outra(s) tabela(s), significando que a consistência de dados só será alcançada com a atualização em conjunto das tabelas. As regras de integridade definidas no banco de dados constituem uma poderosa ferramenta para a manutenção da consistência de dados, impedindo a atualização de dados que não sigam as regras definidas. Outro recurso importante para a manutenção de consistência de dados refere-se à definição de transações de atualização. Por default, cada comando de atualização (INSERT, DELETE ou UPDATE) é encarado como uma única transação. A SQL fornece suporte para a definição de transações através do agrupamento de vários comandos de atualização. Permissões para atualização de dados podem ser atribuídas aos usuários do banco de dados. Assim, usuários não autorizados ficam impedidos de modificar o banco de dados, evitando as atualizações indevidas e conservando a consistência de dados. Nesta seção introduzimos os comandos de atualização de dados, e esses comandos devem ser utilizados de acordo com as políticas de consistência de dados do banco de dados envolvido. 2. Inclusão de Dados A adição de dados em uma tabela envolve o uso do comando INSERT. Basicamente, duas formas estão disponíveis para a inserção de dados: o usuário referencia explicitamente os dados que devem ser inseridos em uma tabela, ou os dados a serem inseridos serão fornecidos a partir de uma subconsulta. SINTAXE 1:
INSERT [ INTO ] tabela [ ( coluna [ , coluna ... ] ) ] VALUES ( expressão [ , expressão ... ] )
EXEMPLO 1:
INSERT INTO PROJ (NumProj, Nome, Local, NumDep) VALUES (‘P01’, ‘DRENAGEM’, ‘BARRA’, 2)
No exemplo, é inserida uma linha na tabela PROJ, onde são referenciadas as colunas NumProj, Nome, Local e NumDep; as demais colunas, se existirem, irão assumir o valor NULL ou, se especificado na definição de dados, valores default serão assumidos. SINTAXE 2:
INSERT [ INTO ] tabela [ ( coluna [ , coluna ... ] ) ] subconsulta
EXEMPLO 2: Considere a existência de uma tabela denominada EMPR_NOVOS, a qual possui dados de novos empregados:
INSERT INTO EMPR SELECT * FROM EMPR_NOVOS

112No exemplo, o resultado da subconsulta constitui o conjunto de dados a serem inseridos. Assim, todas as linhas da tabela EMPR_NOVOS são incluídas na tabela EMPR. OBSERVAÇÕES:
• O conjunto de dados a serem inseridos deve obedecer as restrições de integridades definidas, incluindo colunas obrigatórias, compatibilidade de tipos de dados e valores valores permitidos. Tal observação aplica-se à referência explícita de valores e ao uso de subconsultas.
3. Exclusão de Dados A exclusão de dados em uma tabela envolve o uso do comando DELETE. Para efetuar essa operação, deve-se especificar que conjunto de linhas será afetado pelo comando. SINTAXE:
DELETE tabela [ FROM tabela [ , tabela ... ] [ WHERE condição ]
EXEMPLO 1:
DELETE EMPR WHERE MatrEmpr = ‘981212’
No exemplo, é removida a(s) linha(s) da tabela EMPR, onde a condição MatrEmpr = ‘981212’ for avaliada como verdadeira. EXEMPLO 2:
DELETE EMPR FROM EMPR, DEPTO WHERE EMPR.MatrEmpr = DEPTO.MatrEmpr AND DEPTO.MatrEmpr = ‘981212’
No exemplo, uma operação de join está embutida no comando DELETE, envolvendo as tabelas EMPR e DEPTO; essa operação é utilizada na seleção de linhas a serem removidas. O comando acima exclui do banco de dados quaisquer informações de empregados que trabalhem para o departamento gerenciado pelo empregado de matrícula igual a ‘981212’. OBSERVAÇÕES:
• O uso da cláusula WHERE determina que linhas de uma tabela serão removidas; • SE A CLÁUSULA WHERE NÃO FOR UTILIZADA, TODAS AS LINHAS DA TABELA
ENVOLVIDA SERÃO REMOVIDAS; • O uso das cláusula FROM e WHERE implementa uma operação de join que será utilizada para
determinar as linhas afetadas pela operação. 4. Modificação de Dados A modificação dos dados de uma tabela é realizada através do comando UPDATE. Para efetuar essa operação deve-se especificar que conjunto de linhas será afetado pelo comando. SINTAXE:
UPDATE tabela SET coluna = expressão [ , coluna = expressão ... ] [ FROM tabela [ , tabela ... ] [ WHERE condição ]
EXEMPLO 1:
UPDATE EMPR SET MatrSup = NULL WHERE Salario > 1900.00

113No exemplo, são alteradas linhas da tabela EMPR, atribuindo NULL para a matrícula do supervisor direto; somente são modificados os dados de empregados onde Salario > 1900,00. EXEMPLO 2:
UPDATE EMPR SET Salario = Salario * 1.1 FROM EMPR, DEPTO WHERE DEPTO.MatrEmpr = EMPR.MatrEmpr
No exemplo, uma operação de join está embutida no comando UPDATE, envolvendo as tabelas EMPR e DEPTO; essa operação é utilizada na seleção de linhas a serem alteradas. O comando acima altera a tabela EMPR, adicionando 10% ao salário (SET Salario = Salario * 1.1), considerando somente os empregados que gerenciam departamentos. OBSERVAÇÕES:
• O uso da cláusula WHERE determina que linhas de uma tabela serão modificadas; • SE A CLÁUSULA WHERE NÃO FOR UTILIZADA, TODAS AS LINHAS DA TABELA
ENVOLVIDA SERÃO ALTERADAS; • O uso das cláusula FROM e WHERE implementam uma operação de join que será utilizada
para determinar as linhas afetadas pela operação.

114
ARQUITETURAS DO SISTEMA DBMS O tipo de sistema computador no qual rodam os banco de dados, pode ser dividido em quatro categorias ou plataformas: Centralizada, PC, Cliente/Servidor e Distribuído. Os quatro diferem , principalmente no local onde realmente ocorre o processamento dos dados. A arquitetura do próprio DBMS não determina, necessariamente, o tipo de sistema computador no qual o banco de dados precisa rodar; contudo, certas arquiteturas são mais convenientes(ou mais comuns) para algumas plataformas do que para outras. Plataformas Centralizadas Em um sistema centralizado, todos os programas rodam em um computador "hospedeiro" principal, incluindo o DBMS, os aplicativos que fazem acesso ao banco de dados e as facilidades de comunicação que enviam e recebem dados dos terminais dos usuários. Os usuários têm acesso ao banco de dados através de terminais conectados localmente ou discados(remotos), conforme aparece na figura 1. Minicomputadorou Mainframe
Terminais Locais
TerminalRemoto
Modem
Modem Geralmente os terminais são "mudos", tendo pouco ou nenhum poder de processamento e consistem somente de uma tela, um teclado e do hardware para se comunicar com o hospedeiro. O advento dos microprocessadores levou ao desenvolvimento de terminais mais inteligentes, onde o terminal compartilham um pouco da responsabilidade de manipular o desenho da tela e a entrada do usuário. Embora os sistemas de mainframe e de minicomputador sejam as plataformas principais para sistemas de banco de dados de grandes empresas, os baseados em PC também se podem se comunicar com sistemas centralizados através de combinações de hardware/software que emulam(imitam) os tipos de terminais utilizados com um hospedeiro em particular. Todo o processamento de dados de um sistema centralizado acontece no computador hospedeiro e o DBMS deve estar rodando antes que qualquer aplicativo possa ter acesso ao banco de dados. Quando um usuário liga um terminal, normalmente vê uma tela de log-in; o usuário introduz um ID de conexão e uma password, a fim de ter acesso aos aplicativos do hospedeiro. Quando o aplicativo de banco de dados é inicializado, ele envia a informação de tela apropriada para o terminal e

115responde com ações diferentes, baseadas nos toques de tecla dados pelo usuário. O aplicativo e DBMS, ambos rodando no mesmo hospedeiro, se comunicam pela área de memória compartilhada ou de tarefa do aplicativo, que são gerenciadas pelo sistema operacional do hospedeiro. O DBMS é responsável pela movimentação dos dados nos sistemas de armazenamento de disco, usando os serviços fornecidos pelo sistema operacional. A figura 2 apresenta um modo possível de interação desses aplicativos: os aplicativos se comunicam com os usuários pelos terminais e com o DBMS; o DBMS se comunica com os dispositivos de armazenamento (que podem ser discos rígidos, mas não estão limitados a isso) e com os aplicativos.

116
O DBMS que roda no sistema hospedeiro pode ser baseado em qualquer um dos quatro modelos. Contudo, os modelos hierárquico e relacional são os mais comuns. Nos mainframes, o DBMS é normalmente baseado no IMS da IBM, que é um banco de dados hierárquico. Recentemente , entretanto, mais e mais mainframes estão rodando DBMSs baseados no modelo relacional, principalmente o DB2 da IBM. As principais vantagens de um sistema centralizado são a segurança centralizada e a capacidade de manipular enormes quantidades de dados em dispositivos de armazenamento. Os sistemas centralizados também podem suportar vários usuários simultaneamente; é comum, para um banco de dados em um mainframe IBM, suportar até 1000 usuários de uma vez. As desvantagens geralmente estão relacionadas aos custos de aquisição e manipulação desses sistemas. Os grandes sistemas de mainframe e de minicomputadores exigem facilidades de suporte específicas, como o habitual centro de dados com pisos elevados, sistemas de refrigeração e grandes sistemas de controle climático. Normalmente é necessário um staff de operadores e programadores altamente treinados para manter o sistema ativo e funcionando, com considerável custos adicionais de pessoal. Finalmente , o
Para/de terminais Sistema operacional (I.e., UNIX)
Aplicativo de banco de dados
DBMS
Aplicativo de banco da dados
Outros aplicativos . . .
Disk
Disk
Disk Para/de terminais
Fluxo de dados
Comunicação entre os aplicativos
Memória do computador
Para armazenamento
em disco

117preço de aquisição de hardware de grandes sistemas centralizados freqüentemente atinge milhões de dólares e a manutenção é também onerosa. Atualmente , as empresas têm optado cada vez mais por minicomputadores dimensionados para departamento, como o Micro Vax da DEC e o AS/400 da IBM, pois não custam tanto e são bem suportados como sistemas centralizados, e , geralmente, não exigem um ambiente especial. Esses sistemas são mais convenientes para pequenas empresas com poucos usuários(não mais do que 200) ou para aplicativos de banco de dados que só interessam a um único departamento de uma grande empresa (isto é um minicomputador que roda aplicativos de engenharia só pode interessar ao departamento de projetos). Os computadores menores também pode ser colocado em rede com outros minicomputadores e mainframes, para que todos os computadores possam compartilhar dados. Sistemas de Computador Pessoal Os computadores pessoais (PCs) apareceram no final dos anos 70 e revolucionaram a maneira de ver e utilizar computadores. Um dos primeiros sistemas operacionais de sucesso para PCs foi c CP/M(Control Program for Microcomputers), da Digital. O primeiro DBMS baseado em PC de sucesso , dBase II, da Ashtan-Tate, rodava sob CP/M. Quando a IBM lançou o primeiro PC baseado no MS-DOS, em 1981, a Ashton-Tate portou o dBASE para o novo sistema operacional. Desde então, o dBASE gerou versões mais novas, compatíveis e parecidas e DBMSs competitivos que têm provado, à comunidade de processamento de dados, que os PCs podem executar muitas das tarefas dos grandes sistemas. Quando um DBMS roda em um PC, este atua como computador hospedeiro e terminal. Ao contrário dos sistemas maiores, as funções do DBMS e do aplicativo de banco de dados são combinadas em um único aplicativo. Os aplicativos de banco de dados em um PC, manipulam a entrada do usuário, a saída da tela e o acesso aos dados do disco. Combinar essas diferentes funções em uma unidade, dá ao DBMS muito poder, flexibilidade e velocidade; contudo, normalmente ao custo da diminuição da segurança e da integridade dos dados. Os PCs originaram-se como sistemas stand-alone, mas, recentemente, muitos têm sido conectados em redes locais (LANs). Em uma LAN, os dados, e normalmente os aplicativos do usuário, residem no servidor de arquivo um PC que roda um sistema operacional de rede (NOS) especial, como o NetWare da Novell ou o LAN Manager da Microsoft. O servidor de arquivo gerencia o acesso aos dados compartilhados pelos usuários da rede em seus discos rígidos e, freqüentemente, da acesso a outros recursos compartilhados, como impressoras . Embora uma LAN permita aos usuários de bancos de dados baseados em PC, compartilhar arquivos de dados comuns, ela não muda o funcionamento do DBMS significativamente. Todo o processamento de dados real ainda é executado no PC que roda o aplicativo de banco de dados. O servidor de arquivo somente procura em seus discos os dados necessários para o usuário e envia esses dados para o PC, através do cabo da rede. Os dados são, então, processados pelo DBMS que está rodando no PC e quaisquer mudanças no banco de dados exige, do PC, o envio de todo o arquivo de dados de volta ao servidor de arquivo, para ser novamente armazenado no disco. Essa troca esta mostrada na figura 3. Embora o acesso de vários usuários a dados compartilhados seja uma vantagem, existe uma desvantagem significativa, de um DBMS baseado em LAN, relativa à rapidez ou ao poder do servidor de arquivo, terem seu desempenho limitado pelo poder do PC que está rodando o DBMS real. Quando vários usuários estão tendo acesso ao banco de dados, os mesmos arquivos precisam ser enviados do servidor para cada PC que está tendo acesso a eles. Esse tráfego ampliado pode diminuir a velocidade da rede.

118
Arquivo de dados alterado enviado ao Servidor
Arquivo de dados enviado ao PC
pc pc
pcServidor de
Arquivos
cabo de Rede
A única melhoria necessária para um DBMS multiusuário, em relação a um monousuário, é a capacidade de manipular, simultaneamente, as alterações dos dados realizados por vários usuários. Normalmente isso é feito por algum tipo de esquema de bloqueio, no qual o registro ou o arquivo de dados que um usuário está atualizando ou alterando, é bloqueado para evitar que os outros usuários também o alterem. A maioria dos DBMSs, baseada em LAN, disponível hoje em dia, são simplesmente versões multiusuários de sistemas de banco de dados stand-alone comuns, contudo, os tipos de esquemas de bloqueio variam bastante e podem afetar significativamente o desempenho de um banco de dados multiusuário. A maioria dos DBMSs baseada em PC é projetada no modelo relacional, mas o fato de o DBMS não estar separado do aplicativo de banco de dados significa que muitos (senão a maioria) dos princípios relacionais não estão implementados. Os componentes ausentes mais notáveis são os que tratam da integridade dos dados. A maior parte dos bancos de PC permite acesso direto aos arquivos de dados, fora do DBMS que os criou. Isso cria uma situação, na qual podem ser feitas alterações nos arquivos, violadores Das regras pelas quais o aplicativo assegura a integridade dos dados. Tal violação pode até tornar ilegível o arquivo de dados para o DBMS. Por essa razão os bancos de dados de PC baseados num modelo relacional, são descritos mais precisamente, como semi-relacionais. Alguns dos bancos de dados de PC semi-relacionais mais comuns, disponíveis hoje em dia, incluem o R:Base da Microrim, o dBASE IV da Borland (a Borland adquiriu a Ashton-Tate no final de 1991) e seus muitos "clones", como o FoxPro da Microsoft, o Paradox da Borland, o DataEase da DataEase International e o Advanced Revelation, da Revelation Technologies. Conforme mencionado anteriormente, os bancos de dados de PC mais limitados, normalmente são baseados no modelo do sistema de gerenciamento de arquivo. Também existem DBMSs, baseados em PC, derivados do modelo em rede como o DataFlex, da Data Access Corporation e o db- Vista III, da Raima Corporation. A maioria dos sistemas de banco de dados multiusuário baseado em PC, manipula o mesmo número de usuários dos sistemas centralizados menores. Entretanto, os problemas decorrentes da manipulação de várias transações simultâneas, do aumento no tráfego da rede e do limite do poder de processamento dos PCs que rodam o DBMS, provocam o aumento da complexibilidade e a degradação no desempenho, à medida que o número de usuários se multiplica. A solução desenvolvida para essas limitações é o sistema de banco de dados Cliente/Servidor. BANCOS DE DADOS CLIENTE/SERVIDOR Na sua forma mais simples, um banco de dados Cliente/Servidor (C/S) divide o processamento de dados em dois sistemas: o PC cliente, que roda o aplicativo de banco de dados, e o servidor, que roda totalmente ou parte do DBMS real. O servidor de arquivo da rede local continua a oferecer recursos compartilhados, como espaço em disco para os aplicativos e impressoras. O servidor de

119banco de dados pode rodar no mesmo PC do servidor de arquivo ou (como é mais comum) em seu próprio PC. O aplicativo de banco de dados do PC cliente, chamado sistema front-end, manipula toda a tela e o processamento de entrada/saída do usuário. O sistema back-end do servidor de banco de dados manipula o processamento dos dados e o acesso ao disco. Por exemplo, um usuário do front-end gera um pedido (consulta) de dados do servidor de banco de dados, e o aplicativo front-end envia, para o servidor, o pedido pela rede. O servidor de banco de dados executa a pesquisa real e retorna somente os dados que respondem a pergunta do usuário, conforme aparece na figura 4.
pc pc
pc
cabo de Rede
Servidor de Banco de Dados
Consulta
Resultado da consulta
A vantagem imediata de um sistema C/S é óbvia: dividir o processamento entre dois sistemas reduz a quantidade do tráfego de dados no cabo da rede. Em um dos casos tipicamente confusos sobre o significado de um mesmo termo que às vezes encontramos no campo da computação, a definição de Cliente/Servidor é aparentemente o contrário dos sistemas baseados em UNIX, rodando a interface gráfica X-Windows. A divisão no processamento é a mesma do sistema C/S baseado em PC, mas o front-end é chamado servidor no X-Windows, pois fornece os serviços de apresentação e de interface do usuário. O sistema back-end, no qual roda o DBMS, é referido como cliente dos serviços fornecidos pelo sistema front-end. O número de sistemas C/S está aumentando rapidamente-novos sistemas estão sendo projetados e divulgados quase mensalmente. Embora os sistemas clientes normalmente rodem em PC, o sevidor do banco de dados pode rodar de um PC a um mainframe. Mais e mais aplicativos de front-end estão aparecendo, incluindo desde os que ampliam o escopo dos DBMSs baseados em PC tradicionais, até os servidores de banco de dados. A maior desvantagens dos sistemas de bancos de dados descritos até aqui é que eles exigem o armazenamento dos dados em um único sistema. Isso pode ser um problema para empresas grandes que precisam suportar usuários do banco de dados espalhados em uma área geográfica extensa ou que precisem compartilhar parte de seus dados departamentais com outros departamentos ou com um hospedeiro central. É necessário um modo de distribuir os dados entre os vários hospedeiros ou localidades, o que levou ao desenvolvimento dos sistemas de processamento distribuído.

120
Como Selecionar APIS
API significa “Aplication Program Interface”. É um protocolo de comunicação entre o front-
end ou a lógica de negócio e o banco de dados.
Os fornecedores de Servidores de Banco de Dados costumam prover uma interface de mais
alto nível para comunicação com seus servidores.
Estas APIs são específicas para cada produto.
Exemplos : SQL Net da Oracle
DB/Library da Microsoft/Sybase.
Como cada servidor, geralmente, possui sua própria API, quando uma aplicação cliente quer
acessar servidores diferentes é preciso escolher entre as seguintes alternativas:
• APIs específicas para cada SGBD.;
• Interface comum;
• Gateway.
Acessando servidores diferentes com APIS específicas para cada SGBD
É uma alternativa que prevê que a utilização de uma API específica para cada servidor
diferente que vier a ser acessado pela aplicação cliente. Se precisar acessar banco de dados diferentes,
necessitará carregar na memória APIs diferentes.
Vantagens:
• Performance
• Tuning individual
Desvantagens
• Incompatibilidade de transações
• Necessidade de mais de uma API cliente
Acessando servidores diferentes com interface comum
É uma alternativa onde uma API, situada no lado cliente, provê um protocolo único para
acesso aos diferentes servidores.
Esta API irá carregar os “drives” específicos de cada servidor para estabelecer a comunicação.
Exemplo : ODBC(Open DataBase Comunication) da Microsoft.

121
Vantagens:
• O cliente só fala a lingua, ODBC, que traduz os comandos para cada API cliente
Desvantagens:
• Tuning individual impossível;
• Desempenho. A Microsoft admite uma perda de 30% utilizando ODBC
Acessando servidores diferentes com gateways
Os gateways são produtos que possibilitam a comunicação entre uma aplicação cliente,
desenvolvida para um certo servidor, com outro servidor específico, sem que a aplicação cliente seja
modificada..
Exemplos : MicroDecision Ware, Gupta SQLHost, Oracle Gateway.
Vantagens:
• Só uma API cliente
• Desempenho bom
Desvantagens:
• Tuning para apenas um servidor
• Gateways custam caro
ODBC (Open DataBase Comunication) Conectividade de Banco de Dados Aberto
ODBC é uma API da Microsoft que facilita a interoperabilidade entre o Windons e outros
bancos de dados.
Para usar o ODBC as ferramentas de aplicação devem ser habilitadas para aceitar este padrão.
Os servidores de banco de dados por outro lado deve aceitar chamadas no padão ODBC.
Para que um aplicativo possa acessar vários servidores de bancos de dados, vários esforços
foram feitos.
Um dos mais bem sucedidos resultou na criação, pela Microsoft, do ODBC -Open Data Base
Connectivity.

122Usando um drive ODBC, um programa escrito em qualquer linguagem de programação pode
acessar uma enorme variedade de servidores de banco de dados. Além disso, o programador não
precisa se preocupar com os comandos específicos de consulta á base de dados. Ele deselvolve seu
aplicativo e o ODBC se encarrega de encaminhar as consultas.
Devido a facilidade do padrão ODBC, a maioria dos produtores de software oferece
conectividade por meio dele.
O ODBC foi baseado nas especificações do SQL Access Group e do X Open, duas
organizações que estabelecem padrões técnicos de conectividade.
Desenvolvido inicialmente para Windows, ele foi lançado em 1992 e, hoje, se encontra na
terceira geração. A arquitetura ODBC tem quatro componentes básicos. O primeiro é o próprio
aplicativo, que executa o processamento no cliente e emite as chamadas de consulta aos dados.
O gerenciador de drives, um arquivo do tipo DLL que a Microsoft fornece com seus sistemas
operacionais, carrega os controladores de acordo com a solicitação da aplicação.
O terceiro elemento é o drive ODBC, que processa as chamadas de função, submete
requisições SQL a fonte de dados e remete o resultado ao aplicativo. A estrutura se completa com
fonte de dados, a origem das informações que o usuário quer acessar, normalmente um banco de dados
relacional.
Existem dois tipos de drives ODBC - monocamada e multicamadas. O drive do tipo
monocamada processa as chamadas do ODBC e os comandos SQL. Ele assume, assim, parte da
funcionalidade que caberia, em princípio, à fonte de dados.
Esse tipo de driver é normalmente utilizado para acessar bases de dados que não sejam
compatíveis com o padrão SQL, como as do tipo xBase. Os comandos SQL são processados pelos
próprios drives, que transmitem a consulta ao gerenciador de banco de dados na forma de uma
operação básica de arquivo. Um driver do tipo multicamadas envia as requisições diretamente ao
servidor, que se encarrega de processá-las: Esse driver permite que a aplicação, o gerenciador de
drives e o próprio controlador ODBC fiquem em uma máquina cliente, enquanto o gerenciador de
banco de dados roda em outra máquina - o servidor.
Quando o banco de dados é compatível com SQL, o driver apenas repassa, a ele, comandos
nessa linguagem. No caso de sistemas não compatíveis, o gerenciador de banco de dados terá fazer um
trabalho extra de tradução dos comandos. Além dos fabricantes de banco de dados, surgiram diversas
empresas especializadas em driveers ODBC.
Embora os produtos de todas essas companhias atendem às mesmas especificações, cada um
deles pode apresentar melhor ou pior desempenho que os demais. Observa-se, também que há outros

123fatores, além do driver ODBC, que têm grande influência no desempenho do sistema. Entre esses
fatores estão o protocolo de rede, o gerenciador de banco de dados e o hardware. Apesar da sua ampla
aceitação, o ODBC ganhou a fama de ser um método muito lento de acesso aos dados. Por isso, muitas
empresas preferem construir aplicativos usando os comandos nativos do gerenciador de banco de
dados para comunicação entre o cliente e o servidor.
Recentes testes foram realizados por uma empresa americana Resource Group, sob a liderança
de Ken Norht, autor do livro Windows Multi-DBMS Programing.
Nessa avaliação, foram usados os mesmos micros clientes, servidores, rede, tabelas e
declarações SQL para avaliar o desempenho do ODBC e compará-los com o acesso em modo nativo.
Comparações - Um exame dos resultados dos 27 testes revela que, em 11 deles, o drive
nativo se saiu melhor. Nas outras 16 operações, a vitória foi do ODBC. Desses 16 testes em que o
ODBC foi melhor do que o acesso nativo, a diferença foi maior que 10% em 7 Dos 11 testes em que o
acesso foi mais rápido, em apenas 2 a diferença foi maior que 10%. No Oracle 7 o tempo de acesso via
ODBC foi 2% mais rápido que o acesso nativo.. No Informix, o ODBC foi 1% mais rápido em média.
No Sybase a diferença foi de 13% a fovor do ODBC.
Com estes números acaba o mito do mau desempenho do ODBC. O uso do driver ODBC pode
economizar muito tempo e dinheiro no desenvolvimento de aplicativos multiplataformas. O sucesso
dessa implementação vai depender não só do uso do driver correto, mas de um conjunto de escolhas
acertadas de hardware e software.
Interfaces Gráficas (GUIs)
As interfaces gráficas(GUIs) contribuíram para os sistemas cliente/servidor porque os
tornaram mais fáceis de serem usados e aumentaram a produtividade. Os recursos de GUI, como
multitarefa, cumutação de tarefas e intercâmbio de dados entre aplicativos, também contribuíram para
que esses sistemas ficassem mais atraentes. Um sistema não precisa ter GUI para ser classificado
como um sistema cliente/servidor - no qual um módulo cliente conectado por rede a um módolo
servidor constitui os componentes essenciais. No entanto, as GUIs são usadas com freqüência em
sistemas cliente/servidor, devido os seus benefícios.
Os gastos associados às GUIs incluem treinamento de usuários finais e custos da construção
de uma GUI. Se uma empresa quiser uma GUI personalizada para uma aplicativo interno, seus
analistas de desenvolvimento e programadores devem construí-la.
O desenvolvimento de uma GUI consiste em programação direcionada por eventos, na qual os
programas reagem às ações de usuários finais. Isso é diferente do código gerado por programação

124sequencial tradicional. Há várias abordagens diferentes para desenvolvimento de interfaces gráficas
internas.
Dez Considerações Importantes sobre GUIs
A) As GUIs podem aumentar a produtividade tornando os sistemas mais fáceis de usar o
oferecendo recursos como multitarefa e intercâmbio de dados entre os aplicativos.
B) A facilidade de uso não é automática; alguns treinamentos preparatórios para os usuários
serão necessários.
C) As GUIs podem levar bastante tempo para serem construídas - usar ferramentas de
contrução de GUIs acelera o processo.
D) Falta de consistência nas GUIs pode confundir, irritar e frustar os usuários finais.
E) Um guia de estilos confere a uma GUI sua “aparencia visual”.
F) Padrões internos devem ser adotados para garantir que um guia de estilo escolhido ou um
estilo desenvolvido pela empresa esteja obedecido.
G) Transformar um sistema existente em front-end com uma GUI - embora seja uma técnica
que gera controvésias - pode ser útil em sistemas de utilização complexa.
H) O software GUI do Windows da Microsoft e do Presentation Maneger da IBM reside em
um plataforma de cliente; mas, no sistema X Windows para UNIX, um servidor oferece
gerenciamento de vídeo para a GUI.
I) Há ferramentas disponíveis para construir interfaces “genéricas” que são “portáveis” para
uma ampla variedade de estruturas.
J) Os usuários finais podem ter diferentes GUIs, como X Windows e Windows da Microsoft, operando simultaneamente em seus micros. SISTEMAS DE PROCESSAMENTO DISTRIBUÍDO Uma forma simples de processamento distribuído já existe a alguns anos. Nessa forma limitada, os dados são compartilhados entre vários sistemas hospedeiros, através de atualizações enviadas pelas conexões diretas (na mesma rede) ou por conexões remotas, via telefone ou via linhas de dados dedicadas. Um aplicativo rodando em um ou mais dos hospedeiros, extras a parte dos dados alterados durante um período de tempo definido pelo programador e, então, transmite os dados para um hospedeiro centralizado ou para outros hospedeiros do circuito distribuído. Os outros bancos de dados são, então, atualizados para que todos os sistemas estejam sincronizados. Esse tipo de processamento de dados distribuído normalmente ocorre entre computadores departamentais ou entre

125LANs e sistemas hospedeiros. Após o dia de trabalho, os dados vão para um grande microcomputador central ou para um hospedeiro mainframe. Embora esse sistema seja ideal para compartilhar parte dos dados entre diferentes hospedeiros, ele não responde ao problema do acesso, pelo usuário, aos dados não armazenados em seus hospedeiros locais. Os usuários devem mudar suas conexões para os diferentes hospedeiros, a fim de ter acesso aos vários bancos de dados, lembrando-se, entretanto, de onde está cada banco. Combinar os dados dos bancos de dados existentes em hospedeiros, também apresenta alguns sérios desafios para os usuários e para os programadores. Há ainda, o problema dos dados duplicados; embora os sistemas de armazenamento em disco tenham diminuído de preço através dos anos, fornecer vários sistemas de disco para armazenar os mesmos dados pode ficar caro. Manter todos os conjuntos de dados duplicados em sincronismo, aumenta a complexidade do sistema. A solução para esses problemas está emergindo da tecnologia do acesso "sem costura" a dados, denominada processamento distribuído. No sistema de processamento distribuído o usuário pede dados do hospedeiro local; se este informar que não possui os dados, sai pela rede procurando o sistema que os tenha. Em seguida, retorna os dados ao usuário, sem que este saiba que foram trazidos de um sistema desconhecido exceto, talvez, por um ligeiro atraso na obtenção dos dados. A figura 5 ilustra uma forma de sistema de processamento distribuído. Primeiramente, o usuário cria e envia uma busca de dados para o servidor do banco de dados local. O servidor, então, envia, para o mainframe (possivelmente através de um gateway ou de um sistema de ponte que une as duas redes), o pedido dos dados que não possui. Ele responde à consulta. Finalmente, o servidor do banco de dados local combina esse resultado com os dados encontrados em seu próprio disco e retorna a informação ao usuário.
O ideal é que esse sistema distribuído também possa funcionar de outro modo: os usuários de terminal conectado diretamente ao mainframe podem ter acesso aos dados existentes nos servidores de arquivos remotos. O projeto e a implementação dos sistemas de processamento distribuído é um campo muito novo. Muitas partes ainda não estão no lugar e as soluções existentes nem sempre são compatíveis uma com as outras.

126
BIBLIOGRAFIA .ELMASRI, Ramez e NAVATHE, ShamKant B. Sistemas de Banco de Dados - Fundamentos e Aplicações. Ed. LTC. Rio de Janeiro, 2000. .KORTH, Henry F. & SILBERSCHATZ, Abraham. Sistemas de Bancos de Dados, São Paulo. Ed. Makron Books, 1999. .DATE, C.J., Introdução a Sistemas de Bancos de Dados, Rio de Janeiro. Ed. Campus, 1991. .BOCHENSKI, Barbara. Implementando Sistemas Cliente/Servidor de Qualidade, São Paulo. Ed. Makron Books, 1995. .CHEN, P.; Modelagem de Dados: A abordagem em entidade-relacionamento para projeto lógico. São Paulo. Ed. McGraw-Hill, 1990.