azure stack hci the best infrastructure for
TRANSCRIPT

Azure Stack HCIThe best infrastructure for hybrid
Module 5
Storage

Storage

Learnings Covered in this Unit
Deployment Considerations
Introduction to Storage Spaces
Direct
How to Deploy S2D
Things you need to know about
S2D
Working with S2D

Storage Deployment Considerations
The Goal of this module is to help you
understand key decision points in selecting the
storage technology used for your Virtualization
Infrastructure. .

Microsoft offers industry leading portfolio for building on-premises
clouds
Microsoft embraces your choice of storage
Microsoft offers solutions to reduce storage costs
Choice: On-Premises Storage
File Based StorageBlock StorageSAN AlternativeHyper-Converged Cloud Fabric
Fibre Channel or iSCSI SMB3

Storage Spaces Direct is software-defined,shared-nothing storage.

Use industry-standard hardware to buildlower-cost alternative to traditional storage.
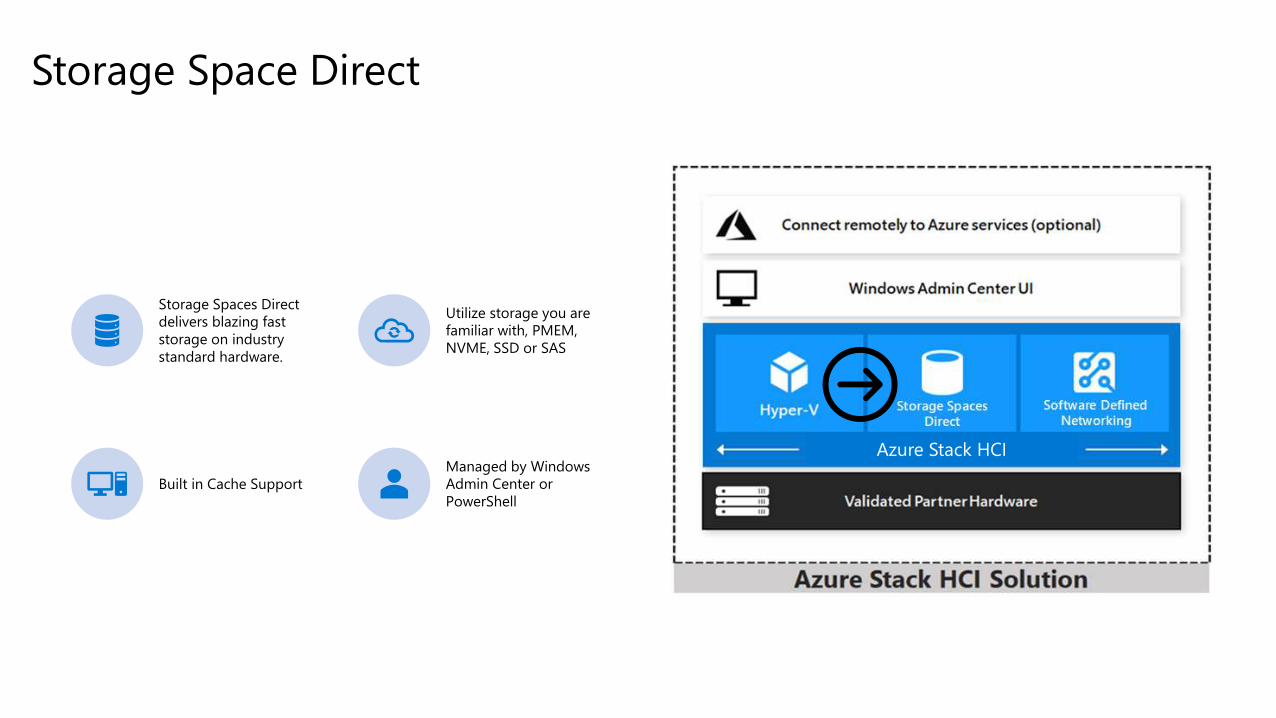
Storage Space Direct
Storage Spaces Direct
delivers blazing fast
storage on industry
standard hardware.
Utilize storage you are
familiar with, PMEM,
NVME, SSD or SAS
Built in Cache Support
Managed by Windows
Admin Center or
PowerShell
Azure Stack HCI

Fault Tolerance
✓ Drive / server / network fault tolerance
✓ Optional rack and chassis awareness
✓ Storage replication for BC/DR (sync or async)
✓ High and continuous availability
Software RAID
✓ Two- and three-way mirror (RAID-1)
✓ Dual parity / erasure coding (RAID-6)
✓ Mirror-accelerated parity
✓ Nested resiliency
✓ Striping (RAID-0)
✓ Single parity (RAID-5)
✓ S.M.A.R.T. predictive drive failure
✓ Drive latency outlier detection
✓ Automatic repair and resync
Software Checksum
✓ File integrity checksum
✓ Automatic in-line corruption correction
✓ Proactive file integrity scrubber
Encryption
✓ Data-at-rest (BitLocker)
✓ Data-in-transit (SMB Encryption)
Efficiency
✓ Kernel-embedded architecture
✓ Remote direct memory access (RDMA)
✓ Data deduplication
✓ Compression
Performance
✓ In-memory cache
✓ Persistent read/write cache
✓ Real-time tiering
✓ Hybrid and all-flash support
✓ Persistent memory / NVDIMM support
✓ Intel® Optane™ NVMe support
✓ NVMe, SATA, SAS support
✓ Instant VHD creation / expansion
✓ Instant VHD checkpoint management
Scale
✓ Petabyte scale
✓ Scale-up and scale-out
✓ Proactive storage balancing
✓ From 2 to 16 servers
✓ From 8 to 400+ drives
✓ Cloud Witness for quorum
✓ Dynamic quorum
Flexibility
✓ Hyper-converged infrastructure (Hyper-V)
✓ Scale-Out File Server (SoFS)
✓ Native SQL Server
Management
✓ Built-In failure and capacity alerting
✓ Built-In performance history
✓ Per-VM Quality of Service (QoS) IOPS limits
✓ 100% scripting-friendly (PowerShell)
✓ System Center Integration
0 1 0 1 0 1
0 1 0 1 0 1
0 1 0 1 0 1
0 1 0 1 0 1
0 1 0 1 0 1
0 0 1 1 0 1
0 1 0 1 0 1
0 1 0 0 1 0
Enterprise-grade software-defined storage


Industry-standard servers with internal drives

No shared storage, no fancy cables – just Ethernet


Let’s cluster them


Software-defined “pool” of storage


We’re ready to create volumes!


Scale-Out File Server (SoFS)
SMB3
File Shares

Hyper-Converged


Add new node to cluster



Under 00:15 of real-world time.

Azure Stack HCI
Windows Server 2016/2019 Datacenter
Included in
at no additional cost

Deploying Storage Spaces Direct
The Goal of this module is to help you
understand methods available to Enabling
Cluster Storage Spaces Direct.

Deploying Storage Spaces Direct
• Windows Admin Center
Easy, Simple Wizard
• Virtual Machine Manager
Simple, One Click in Cluster Creation
• PowerShell
Scalable, Repeatable, Customizable

Enable-ClusterS2D
Windows Admin Center Virtual Machine Manager PowerShell

Storage Spaces Direct Deep Dive
The Goal of this module is to help you
understand the key items that define Storage
Spaces Direct

Storage Spaces Direct
• Disk Types
• Understanding Disk Cache
• Fault Tolerance
• Storage Efficiency
• Storage ReSync and Repair
• iWarp vs ROCE
• ReFS

PMEM: Persistent Memory, including
NVDIMM-N in block mode, DAX mode, and
forthcoming Apache Pass (3D X-Point
DIMM).
Also known as SCM: Storage Class Memory
NVMe: Non-Volatile Memory Express,
connected via the PCIe bus. Includes M.2,
U.2, and AIC form factor, and including
Optane (3D X-Point NVMe SSD).
SSD: Any other Solid-State Drive
connected via SATA or SAS.
HDD: Any Hard Disk Drive
connected via SATA or SAS.
Types of drives

Building a Performance Optimized Solution
SCM for Capacity
SCM + NVMe for Capacity
SCM + SSD for Capacity
OR
OR

NVMe for Capacity
SSD for Capacity
Flat design of all flash delivers
the best IOPS and throughput
Building a Balanced Optimized Solution
OR
OR
NVMe for Cache & SSD for Capacity

Building a Capacity Optimized Solution
OR
OR

Random I/O
Optimized I/O
Built-In, Always-On CacheFastest media (e.g. SSD) provides caching
Each SSD dynamically binds to several HDDs
Independent of pool or volumes, no configuration
All writes up to 256KB, and all reads up to 64KB, are cached
Writes are then de-staged to HDDs in optimal order

Cache drives are selected automatically

Cache behavior is set Automatically

Server Side Architecture

Drive bindings are Dynamic

Handling cache Drive Failures

From 2 – 16 servers, and up to over 400 drives
Over 3 PB of raw storage per cluster
Add servers to scale out
Add drives to scale up
Pool automatically absorbs new drives
Better storage efficiency and performance at larger scale
Converged design greatly simplifies procurement
No special hardware or cables – just Ethernet
Simple Scalability and Expansion

From 2 – 16 servers, and up to over 400 drives
Over 3 PB of raw storage per cluster
Add servers to scale out
Add drives to scale up
Pool automatically absorbs new drives
Better storage efficiency and performance at larger scale
Converged design greatly simplifies procurement
No special hardware or cables – just Ethernet
Simple Scalability and Expansion

Drive Fault ToleranceUp to 2 simultaneous drive failures*
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

All data remains safe and accessible
Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Drive Fault ToleranceUp to 2 simultaneous drive failures
Data stays safe and continuously accessible
Automatic and immediate repair
Single-step replacement

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Server Fault ToleranceUp to 2 simultaneous failures
Copies always land in different servers
Accommodates servicing and maintenance
Data resyncs automatically

Dual parity
4+ servers
Three-way mirror
3+ servers
Single parity
Possible but not recommended
Two-way mirror
2 servers
Resiliency types

ReFS volume
Capacity devices
Mirror Parity
File system layer optimizing parity calculation
• Writes land on mirror
• Data later rotated to parity
• Reads happen from either mirror or
parity with equal performance
Caching devices
Device layer real-time caching
• Writes land on caching devices
• Data later rotated to capacity devices
• Reads are cached on caching devices
Mirror-Accelerated Parity

Capacity efficiency in %
Storage performance in IOPS
* Mirror-accelerated parity outperforms dual parity, especially in Windows Server 2019, but three-way mirror remains the clear performance leader.
* Three-way mirror has 33.3% storage efficiency. Dual parity starts at 50.0% and goes up to 80.0%. Mirror-accelerated parity is in between.
Three-way mirror
Dual parity
Mirror-accelerated parity
Three-way mirror
Dual parity
Mirror-accelerated parity
Resiliency Types in Storage Spaces Direct

Mirror for performance
Parity for capacity
Hybrid for balanced
Resiliency Types and efficiency
Volume Mirror Parity Hybrid
Optimized for Performance Capacity Balanced
Use case All data is hot All data is cold Mix of hot and cold
Efficiency Least (33%) Most (57+%) Depends on mix
File System ReFS (or NTFS) ReFS (or NTFS) ReFS
Minimum Nodes 2 4 4

Understanding and Monitoring Storage Resync

* Using standard ASCII 8-bit encodings for each letter
l0 1 1 0 1 0 0 0
e0 1 1 0 0 1 0 1
h0 1 1 0 1 1 0 0 0 1 1 0 1 1 1 1
ol0 1 1 0 1 1 0 0
Data to store…

0 1 1 0 1 0 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 1 1
Copy No. 1
Copy No. 2
0 1 1 0 1 0 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 1 1
Copy No. 3
0 1 1 0 1 0 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 1 1
Core Concept – Mirror Resiliency




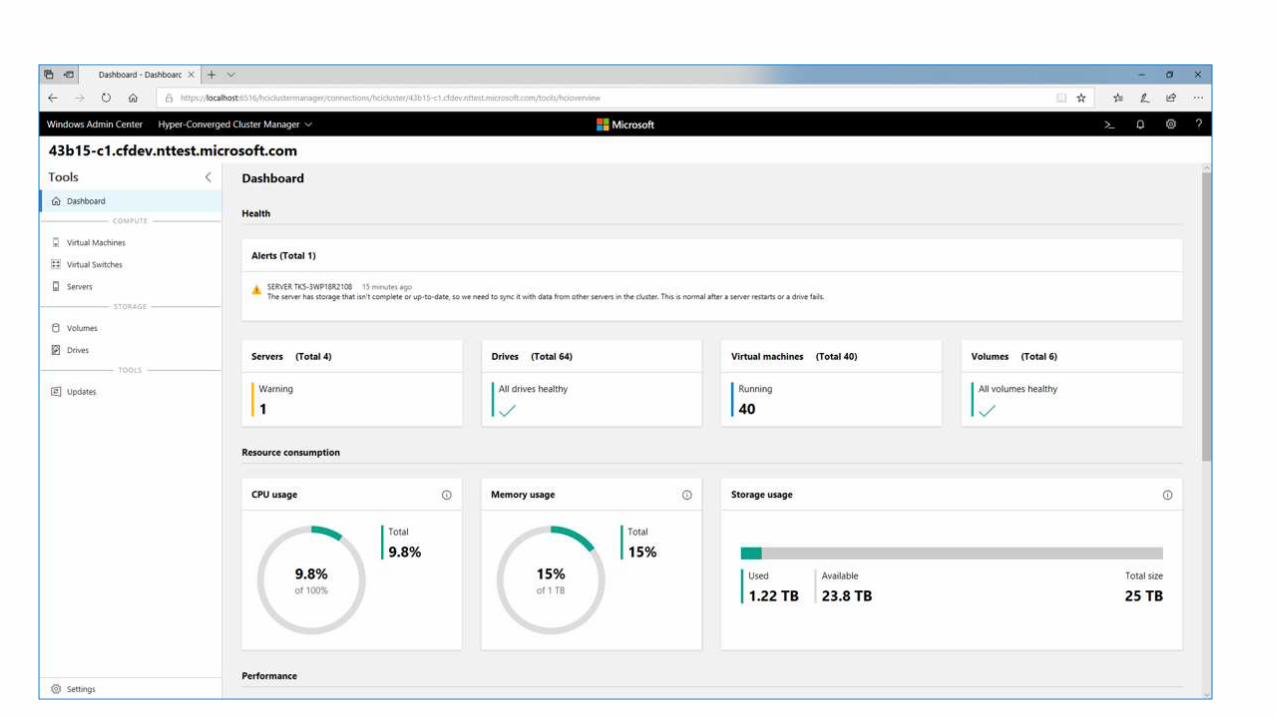

Monitoring Storage ReSync
Easily view Storage Rebuild
Jobs in Windows Admin
Center
-
View in PowerShell with the
Health Service.

No dedicated storage fabric – just Ethernet
Lots of “East-West” traffic to synchronize data between servers
RDMA allows this to largely bypass CPU, leaving more resources for Virtual Machines!
Remote Direct Memory Access

iWARP is TCP/IP based Safe to drop packet.
Simple to configure.
Speeds up to 100Gb/port
RoCE is UDP based Less communication overhead
Requires lossless infrastructure (PfC, ETS)
Tricky to configure
Speeds up to 200Gb/port
More on this in our Networking Module.
RoCE vs iWARP

When to use NTFS
• In traditional (not Storage Spaces Direct) clusters
▪ As ReFS volume gets redirected to owner on CSV (increased east-west traffic)
• In Shared Storage Spaces deployments
▪ As NTFS tiering can be used (ReFS“tiered” volumes cannot be used on Shared SS)

When to use ReFS
• Storage Spaces Direct Deployments
Including Volumes that need Data Deduplication
• As Filesystem for Backups (DPM, Veeam)

ReFS key features - Resiliency
• Integrity Streams
• ReFS uses checksums for metadata and optionally for file data, giving ReFS the ability to reliably detect corruptions.
• Storage Spaces integration
• automatically looks for alternate data copy)
• Salvaging data
• if alternate copy does not exist, corrupt data are removed from namespace
• Proactive error correction
• ReFS introduces a data integrity scanner, known as a scrubber. Scrubber scans for corruptions and triggers repair.

ReFS key features - Performance
Real-time tier optimization (discussed later in workshop)
Multi-resilient volumes (Mirror-Accelerated parity)
Hybrid volumes (MirrorSSD – MirrorHDD)
VM Optimizations
Block Cloning
Sparse VDL
Scalability
ReFS is designed to support extremely large data sets--millions of terabytes--without negatively impacting performance, achieving greater scale than prior file systems.

ReFS VM Optimizations
Basics
Metadata checksums with optional user data checksum
Data corruption detection and repair
On-volume backup of critical metadata with online repair
Efficient VM Checkpoints and Backup
VHD(x) checkpoints cleaned up without physical data copies
Data migrated between parent and child VHD(x) files as a ReFS metadata
operation
Reduction of I/O to disk
Increased speed
Reduces impact of checkpoint clean-up to foreground workloads
Accelerated Fixed VHD(x) Creation
Fixed VHD(x) files zeroed with metadata operations
Minimal impact on workloads
Decreases VM deployment time
Quick Dynamic VHD(x) Expansion
Dynamic VHD(x) files zeroed with metadata operations
Minimal impact on workloads
Reduces latency spike for foreground workloads

Working with S2SThe Goal of this module is to help you
understand how to do everyday task in S2D.

Create a Volume
Create a Three-Way Mirror
Volume in Admin Center
Create a Mirror Accelerated
Parity Volume in Admin
Center
Turn on De-Duplication and
Compression in Admin Center

Volume Maintenance
Extend a Volume in Admin Center Delete a Volume in Admin Center

Host Maintenance
Verify its Safe to take Server
Offline
Pause/Drain the Server
Shutdown, Reboot Node
Resuming the Node
Waiting for Storage to Resync
