aws re:invent 2016| hlc301 | data science and healthcare: running large scale analytics and machine...
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Arnoud Otte, Assistant Director Cloud & Data Architecture, Cambia Health Solutions
Rich Uhl, CTO / Founder, 1Strategy
Ujjwal Ratan, Solutions Architect, AWS
November 28, 2016
HLC301
Data Science and Healthcare: Running Large
Scale Analytics and Machine Learning on AWS

What to Expect from the Session
• Benefits from large-scale analytics with PHI - Arnoud
• Securing Amazon EMR & Elasticsearch - Rich
• Additional solution components for HIPAA compliance [demo] - Rich
• Reducing cost and improve quality of care with Amazon Machine
Learning [demo] - Ujjwal
NOTE: This is a deep dive session on HOW rather than WHAT. We will show
implementation details.
• This session expects familiarity with:
• AWS services - EMR and S3 BDM401 - Deep Dive: Amazon EMR Best Practices & Design Patterns
BDA206 - Building Big Data Applications with the AWS Big Data Platform
• Encryption and distributed systems like Hadoop and Elasticsearch


Cambia Health Solutions
Our Roots
Born from an inspired idea
Our Cause
Becoming catalysts
for transformation
Our Vision
Delivering a reimagined
health care experience
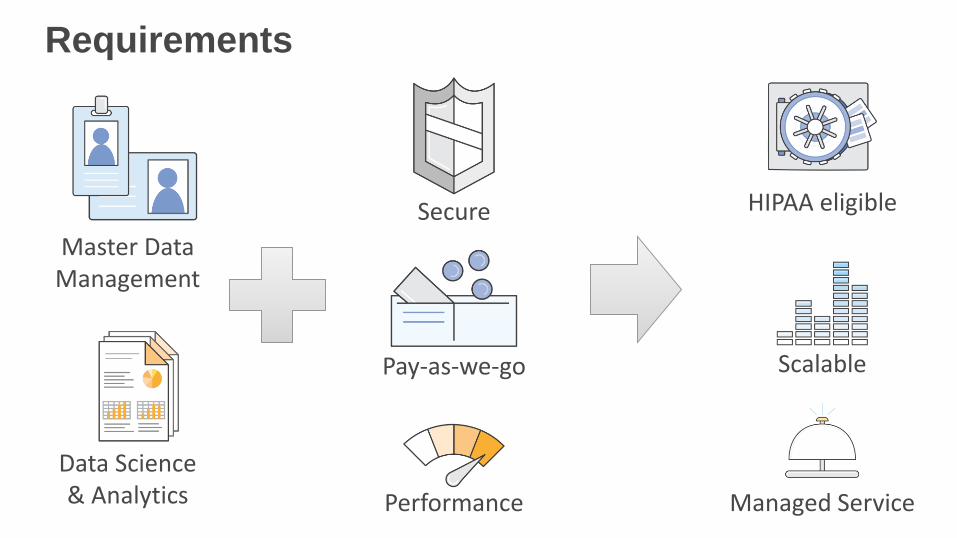
Requirements
HIPAA eligible
Scalable
Managed Service
Secure
Pay-as-we-go
Performance
Master DataManagement
Data Science& Analytics
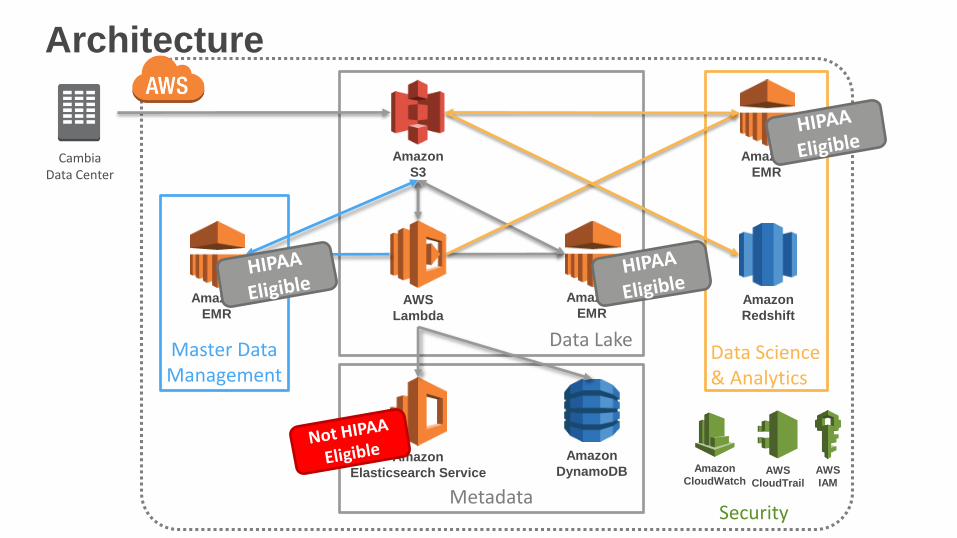
Architecture
Amazon
CloudWatchAWS
CloudTrail
AWS
IAM
CambiaData Center
Amazon
S3
Amazon
DynamoDB
AWS
Lambda
Amazon
EMR
Amazon
Elasticsearch Service
Data Lake
MetadataSecurity
Amazon
Redshift
Amazon
EMR
Data Science& Analytics
Amazon
EMR
Master DataManagement

Master Data Management
Source A Source B
First Name
John John
Last Name
Doe Doe
DOB 1970-01-01 2016-11-28
Street 105 Main St 105 Main St
City Portland Portland
State OR OR
Source A Source B
First Name
Jillian Jill
Last Name
Doe Doe-Doe
SSN 123-45-6789 123-45-6789
Street 605 Oak Dr 105 Main Street
City PDX Portland
State OR Oregon
No. Father and son. Yes. Married, changed name, and moved.This is artificial data fabricated for illustration purposes only.
Are these the same people?
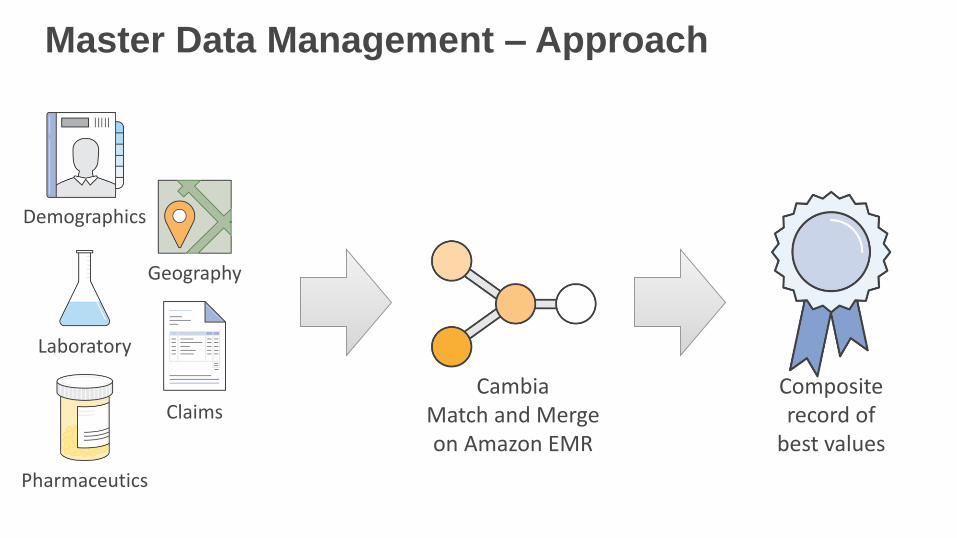
Master Data Management – Approach
Demographics
Laboratory
Pharmaceutics
Geography
ClaimsCompositerecord of
best values
CambiaMatch and Mergeon Amazon EMR

Master Data Management – Quality
98.50%
99.90%99.99%
97.5%
98.0%
98.5%
99.0%
99.5%
100.0%
Match Correctness
Vendor Cambia V1 Cambia V1.1
98.80%
84.30%
98.10%
75.0%
80.0%
85.0%
90.0%
95.0%
100.0%
Match Completeness
Vendor Cambia V1 Cambia V1.1
7,000+ records containing 1,600+ matchesManually checked and confirmed in the real world

Master Data Management – Performance
90 minutes 40 minutes0
500
1000
1500
2000
2500
minutes
Run time
Vendor Cambia V1 Cambia V1.1
2160 minutes
or 36 hours
17.7M records containing 1.8M matches

Next Steps
Scale
in and out or up and down
Amazon Machine
Learning
Amazon
EMR
Build out healthcare
data science models
HIPAA compliant
search on data
Amazon
EC2

SecurityBig Data
1Strategy.com | @1strategy_cloud | Booth #408
Rich UhlFounder & CTO

At Rest – when data is in a stored location
Definition of Terms
In Transit – when data is moved to and from storage
In Process – when data is in temporary space for processing state
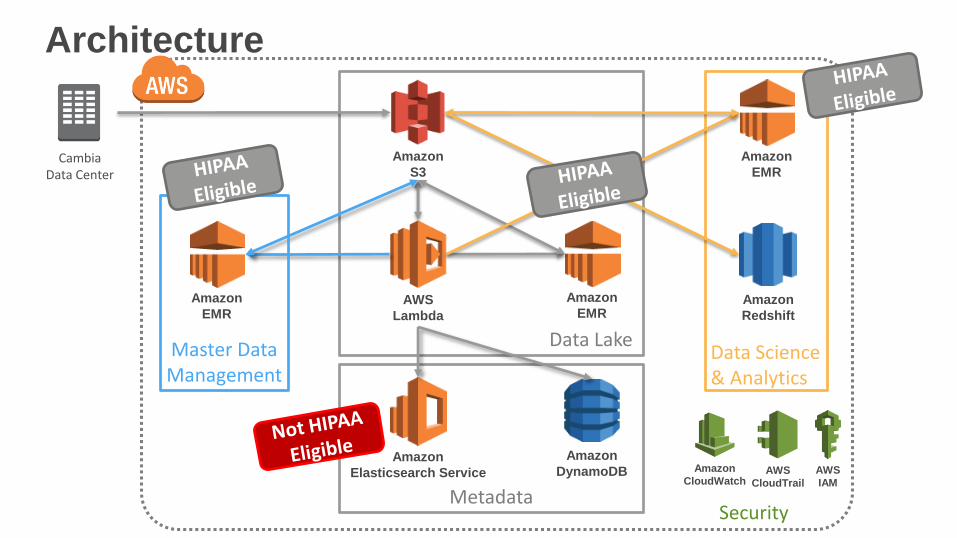
Architecture
Amazon
CloudWatchAWS
CloudTrail
AWS
IAM
CambiaData Center
Amazon
S3
Amazon
DynamoDB
AWS
Lambda
Amazon
EMR
Amazon
Elasticsearch Service
Data Lake
MetadataSecurity
Amazon
Redshift
Amazon
EMR
Data Science& Analytics
Amazon
EMR
Master DataManagement

AWS KMS
Encryption Keys Exchanging Keys Temporary KeysMaster Key
Key Management

Encryption at Rest
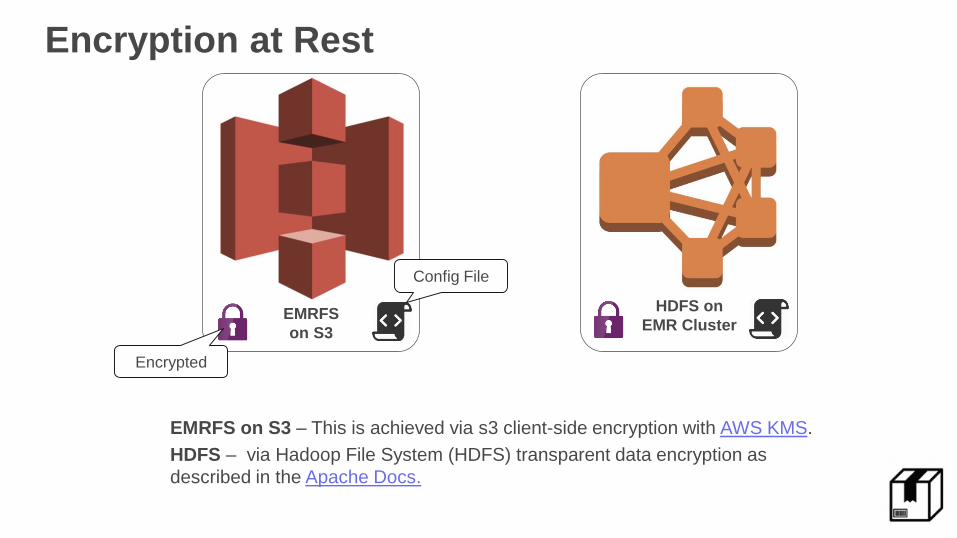
EMRFS
on S3
EMRFS on S3 – This is achieved via s3 client-side encryption with AWS KMS.
HDFS – via Hadoop File System (HDFS) transparent data encryption as
described in the Apache Docs.
HDFS on
EMR Cluster
Config File
Encrypted
Encryption at Rest

{
"Sid": "DenyUnEncryptedObjectUploads",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::prd-datalake/*",
"Condition": {
"StringNotEquals": {
"s3:x-amz-server-side-encryption": "AES256"
}
}
}
EMRFS
on S3
Encryption at Rest

Data
Encryption
Key (DEK)
Envelope Data
Encryption Key
(EDEK)
Hadoop KMS
Bootstrap Script
Uses native Hadoop HDFS Transparent Data Encryption (DEK/EDEK)
HDFS on
EMR Cluster
Encryption at Rest

{
"Classification": "hdfs-site",
"Properties": {
"dfs.encryption.key.provider.uri": "kms://…”,
"dfs.namenode.name.dir": "file:///…",
"dfs.name.dir": "/mnt/encrypted/…",
"dfs.data.dir": "/mnt/encrypted/…",
"dfs.datanode.data.dir": "file:///…"
}
Bootstrap Script
HDFS on
EMR Cluster
Encryption at Rest
EMRFS
on S3
HDFS on
EMR Cluster
Summary of Encryption at Rest

Encryption in Transit

HDFS on
EMR ClusterEMRFS
on S3
Encryption in Transit

EMRFS on
S3
HDFS on
EMR
Cluster
Encryption in Transit<!-- Client certificate Store -->
<property>
<name>ssl.client.keystore.type</name>
<value>jks</value>
</property>
<property>
<name>ssl.client.keystore.location</name>
<value>/etc/emr/security/ssl/keystore.jks</value>
</property>
<property>
<name>ssl.client.keystore.password</name>
<value>changeit</value>
</property>
<!-- Client Trust Store -->
<property>
<name>ssl.client.truststore.type</name>
<value>jks</value>
</property>
<property>
<name>ssl.client.truststore.location</name>
<value>/etc/emr/security/ssl/truststore.jks</value>
</property>
<property>
<name>ssl.client.truststore.password</name>
<value>changeit</value>
</property>
<property>
<name>ssl.client.truststore.reload.interval</name>
<value>10000</value>
</property>
</configuration>
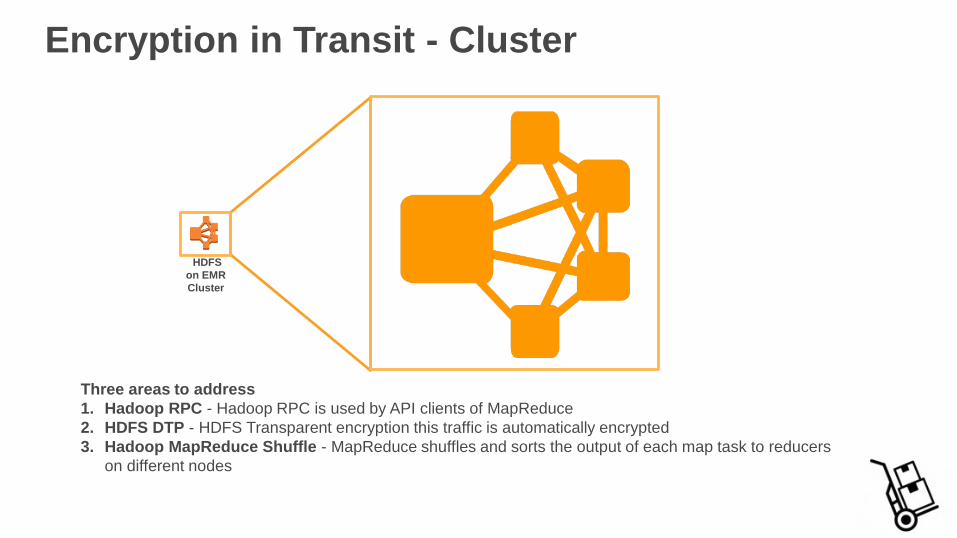
Three areas to address
1. Hadoop RPC - Hadoop RPC is used by API clients of MapReduce
2. HDFS DTP - HDFS Transparent encryption this traffic is automatically encrypted
3. Hadoop MapReduce Shuffle - MapReduce shuffles and sorts the output of each map task to reducers
on different nodes
HDFS
on EMR
Cluster
Encryption in Transit - Cluster

RPCclient
Hadoop RPC - Hadoop RPC is used by API clients of MapReduce
EMR
ClusterEMRFS
on S3
Encryption in Transit - Cluster

RPCclient
<property>
<name>hadoop.security.service.user.name.key</name>
<value></value>
<description>
For those cases where the same RPC protocol is implemented by multiple
servers, this configuration is required for specifying the principal
name to use for the service when the client wishes to make an RPC call.
</description>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
<description>A comma-separated list of protection values for secured sasl
connections. Possible values are authentication, integrity and privacy.
authentication means authentication only and no integrity or privacy;
integrity implies authentication and integrity are enabled; and privacy
implies all of authentication, integrity and privacy are enabled.
hadoop.security.saslproperties.resolver.class can be used to override
the hadoop.rpc.protection for a connection at the server side.
</description>
</property>
Encryption in Transit - Cluster
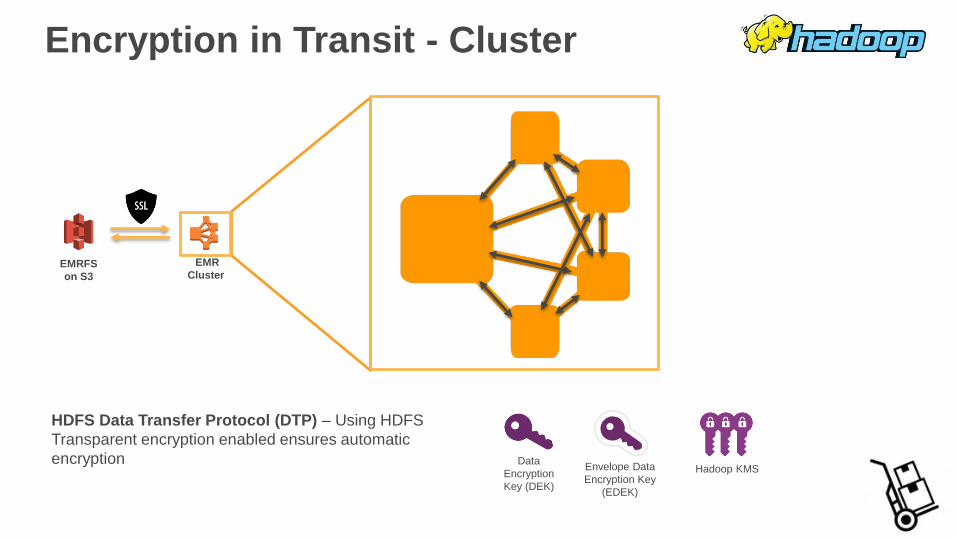
Data
Encryption
Key (DEK)
Envelope Data
Encryption Key
(EDEK)
Hadoop KMS
HDFS Data Transfer Protocol (DTP) – Using HDFS
Transparent encryption enabled ensures automatic
encryption
Encryption in Transit - Cluster
EMRFS
on S3
EMR
Cluster

<property>
<name>dfs.encrypt.data.transfer</name>
<value>true</value>
<description>
Whether or not actual block data that is read/written from/to HDFS should
be encrypted on the wire. This only needs to be set on the NN and DNs,
clients will deduce this automatically. It is possible to override this setting
per connection by specifying custom logic via dfs.trustedchannel.resolver.class.
</description>
</property>
<property>
<name>dfs.encrypt.data.transfer.algorithm</name>
<value></value>
<description>
This value may be set to either "3des" or "rc4". If nothing is set, then
the configured JCE default on the system is used (usually 3DES.) It is
widely believed that 3DES is more cryptographically secure, but RC4 is
substantially faster.
</description>
</property>
Data
Encryption
Key (DEK)
Envelope Data
Encryption Key
(EDEK)
Hadoop KMS
Hadoop Data Transfer Protocol (DTP) configured on
startup with a bootstrap script
Encryption in Transit - Cluster

Hadoop
Encrypted
Shuffle and Sort
Hadoop MapReduce Shuffle - In the shuffle phase, Hadoop MapReduce (MRv2) shuffles the output of
each map task to reducers on different nodes using HTTP by default.
EMR
Cluster
Encryption in Transit - Cluster
EMRFS
on S3

{
"Classification": "mapred-site",
"Properties": {
"mapreduce.shuffle.ssl.enabled": "true",
"mapred.local.dir": "/mnt/encrypted/mapred,/mnt1/encrypted/mapred",
"mapreduce.cluster.local.dir": "/mnt/encrypted/mapred,/mnt1/encrypted/mapred",
"mapreduce.application.classpath": "$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,\n
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*,\n /usr/lib/hadoop-lzo/lib/*,\n
/usr/share/aws/emr/emrfs/conf,\n /usr/share/aws/emr/emrfs/lib/*,\n /usr/share/aws/emr/emrfs/auxlib/*,\n
/usr/share/aws/emr/lib/*,\n /usr/share/aws/emr/ddb/lib/emr-ddb-hadoop.jar,\n
/usr/share/aws/emr/goodies/lib/emr-hadoop-goodies.jar,\n /usr/share/aws/emr/kinesis/lib/emr-kinesis-
hadoop.jar,\n /usr/share/aws/emr/cloudwatch-sink/lib/*,\n /etc/emr/security/conf"
}
Hadoop
Encrypted
Shuffle and Sort
Encryption in Transit - Cluster

EMRFS
on S3EMR
Cluster
Encryption in Transit - Cluster
Spark block transfer service – This is can be encrypted using SASL encryption in Spark 1.5.1 and later.

{
"Classification": "spark-env",
"Properties": {
"spark.authenticate.enableSaslEncryption": "true",
"spark.network.sasl.serverAlwaysEncrypt": "true"
}
Encryption in Transit

Encryption in Process

Temporary
Space on EBS
Volumes
Temporary
Keys
Bootstrap Script
Encryption in Process

Bootstrap Script
function encrypt_disk() {
local dev=$1
local dir=$2
local cryptname="crypt_${dir:1}"
# Unmount the drive
sudo umount "$dev"
# Encrypt the drive
sudo cryptsetup luksFormat -q --key-file "$PWD_FILE" "$dev"
sudo cryptsetup luksOpen -q --key-file "$PWD_FILE" "$dev" "$cryptname"
# Format the drive
sudo mkfs -t xfs "/dev/mapper/$cryptname"
sudo mount -o defaults,noatime,inode64 "/dev/mapper/$cryptname" "$dir"
sudo rm -rf "$dir/lost+found"
sudo mkdir -p "$dir/encrypted"
sudo chown -R hadoop:hadoop "$dir"
echo "/dev/mapper/$cryptname $dir xfs defaults,noatime,inode64 0 0" |
sudo tee -a /etc/fstab
echo "$cryptname $dev $PWD_FILE" | sudo tee -a /etc/crypttab
}
Temporary
Space on EBS
Volumes
Encryption in Process

HDFS on
EMR ClusterEMRFS on S3
Temporary Space
on EBS Volumes
RPCHadoop Encrypted
Shuffle and Sort
Native DTP
Summary of the EMR Encryption Process

EMR Updates
1Strategy blog links
amzn.to/2g0JJIN
September 21st, 2016
bit.ly/1strategy_emr
AWS EMR Encryption Documentation

EMR Updates and how they play into this


Temporary
Space on EBS
Volumes
ElasticSearch for HealthCare
Encryption and Authentication ElasticSearch
on EC2
Instances

EMRFS on S3
Temporary Space
on EBS VolumesElasticSearch on EC2
Instances
ElasticSearch Encryption Process Summary

HIPAA is more than encryption
Auditing & custom tools:
• Audit script to show limited users have access to encrypted S3 data
• S3 Buckets are encrypted
• Show S3 Objects are encrypted
*Working with Cambia to open source these tools
bit.ly/1strategy_emr_code

Demo


Machine Learning inside Healthcare
Analyzing Medical Images
Prescription Compliance Prediction
Evidence Based & Precision Medicine
Text classification and mining
Medicare and Medicaid Fraud
Hospital Bed Utilization
Treatment Queries and Suggestions
Drug Discovery and Clinical Trials
Population Health
Vaccination and Immunization
Omics and Clinical Data Integration
Patient Outcomes
Patient Readmission
Prediction through risk
stratification

Real World Problem – Hospital Readmissions
• Hospital Readmission Reduction
Program (HRRP) part of the Affordable
Care Act.
• Centers for Medicare & Medicaid
Services (CMS) required to reduce
payments to hospitals with excess
readmissions.
• Not all readmissions can be prevented
• Facilities with high readmission rates
had their Medicare payment cut by 1%
in 2013 which rose to 2% in 2014.
Source - www.ncbi.nlm.nih.gov/pmc/articles/PMC3558794
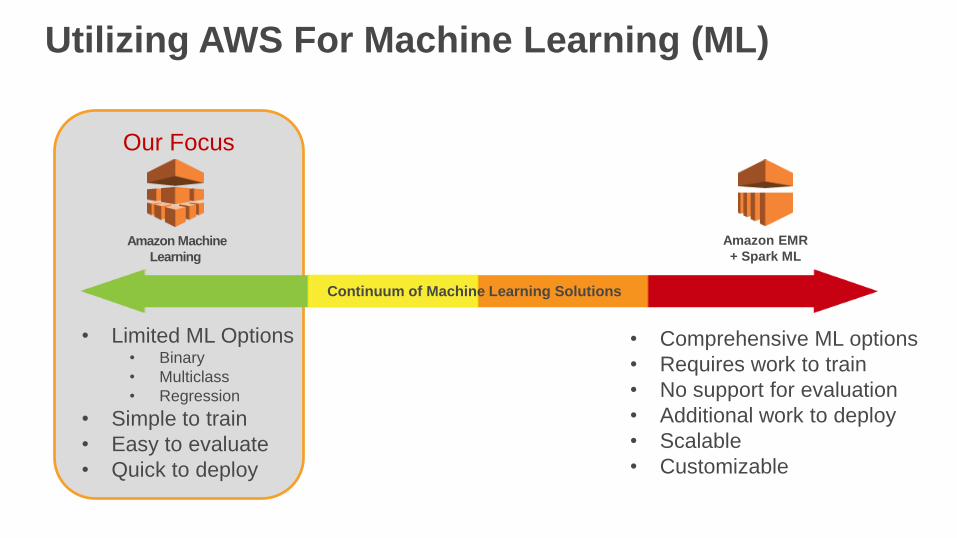
Our Focus
Utilizing AWS For Machine Learning (ML)
Continuum of Machine Learning Solutions
• Limited ML Options• Binary
• Multiclass
• Regression
• Simple to train
• Easy to evaluate
• Quick to deploy
• Comprehensive ML options
• Requires work to train
• No support for evaluation
• Additional work to deploy
• Scalable
• Customizable
Amazon EMR
+ Spark MLAmazon Machine
Learning
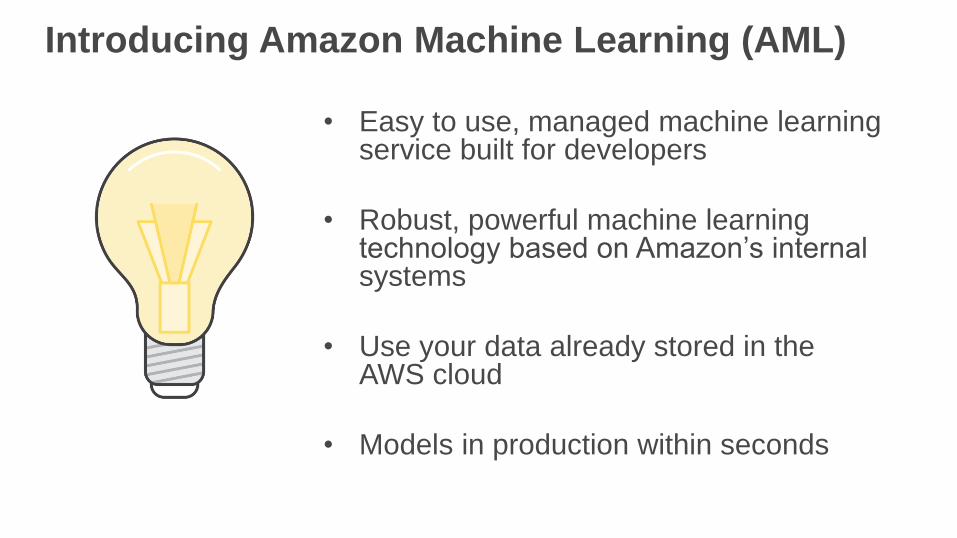
Introducing Amazon Machine Learning (AML)
• Easy to use, managed machine learning service built for developers
• Robust, powerful machine learning technology based on Amazon’s internal systems
• Use your data already stored in the AWS cloud
• Models in production within seconds

Machine Learning
Proactive Prediction of Readmission
Patient
Demographics
Patient History
Admission
Attributes
Other features
Patient
High Risk Patient
Low Risk Patient
Moderate Risk
Patient
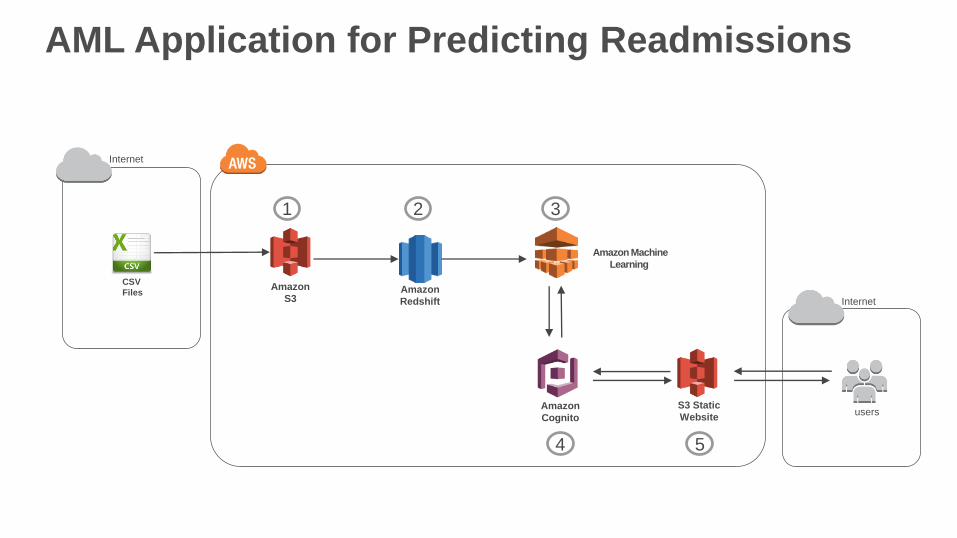
Amazon
S3Amazon
Redshift
Amazon Machine
Learning
users
Internet
CSV
Files
1 2 3
5
Amazon
Cognito
S3 Static
Website
Internet
4
AML Application for Predicting Readmissions

Clinical Data Set
https://archive.ics.uci.edu/ml/datasets/Diabetes+130-US+hospitals+for+years+1999-2008
• 101,766 rows
• 10 years of clinical care
• 130 US hospitals
• 50+ attributes of diabetes patients and hospital outcomes

Ingesting Data into S3 - Staging
Table Name Table Type
admission_source.csv Master
admission_type.csv Master
discharge_disposition.csv Master
Diabetic_data.csv Transaction
aws s3 cp /tmp/foo/ s3://bucket/ --recursive \

Schema in RedshiftFact
create table admission_type (
admission_type_id INTEGER NOT NULL,
description varchar(100)
);
create table discharge_disposition (
discharge_disposition_id INTEGER NOT NULL,
description VARCHAR(500)
);
create table admission_source (
admission_source_id INTEGER NOT NULL,
description VARCHAR(500)
);
create table diabetes_data (
// ~50 attributes
);
Dim2
Dim3
Dim1

Data Load and Standardization
COPY<Redshift_Table_Name> FROM's3://<file_path.csv>' CREDENTIALS
'aws_access_key_id=<>;aws_secret_access_key=<>’ DELIMITER ',’ IGNOREHEADER 1;
Data Load
• Updated NULL values
• Change attributes values which do not comply with standard patterns.
• ex: Phone = (206) XXX-XXXX
• Complete geographical data where possible
• Include timeline values if possible
• Group granular attributes in sets.
• ex: Ages 0 to 20 as youth, 20 to 40 as adult and so on.
Data Standardization

Create AML Data Source with Redshift
CreateDataSourceFromRedshift API
Console
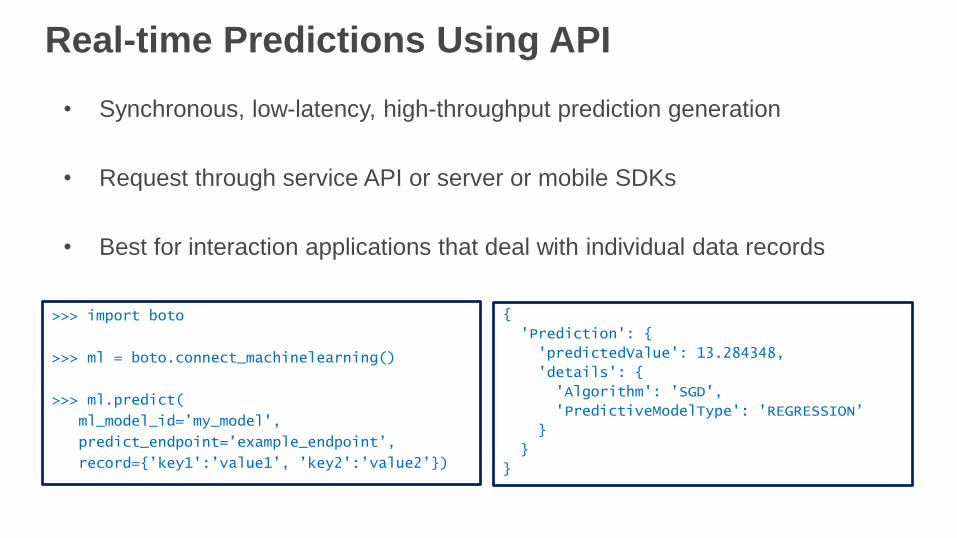
Real-time Predictions Using API
• Synchronous, low-latency, high-throughput prediction generation
• Request through service API or server or mobile SDKs
• Best for interaction applications that deal with individual data records
>>> import boto
>>> ml = boto.connect_machinelearning()
>>> ml.predict(
ml_model_id=’my_model',
predict_endpoint=’example_endpoint’,
record={’key1':’value1’, ’key2':’value2’})
{
'Prediction': {
'predictedValue': 13.284348,
'details': {
'Algorithm': 'SGD',
'PredictiveModelType': 'REGRESSION’
}
}
}


Application Website Hosted on S3
var machinelearning = new AWS.MachineLearning({apiVersion: '2014-12-12'});var params = {
MLModelId: ‘<AML Model ID>',PredictEndpoint: ‘<AML Model Real Time End Point>',Record: <Selected Attributes record set>
};var request = machinelearning.predict(params);
Application calls the Predict() API using necessary parameters
Website hosting in S3 without web servers eliminates complexities of
scaling hardware based on traffic routed to your application.
bit.ly/aml_demo - Demo bit.ly/hcl301_blog - Blog

Expanded Architecture
Amazon
S3Amazon
Redshift
Amazon Machine
Learning Amazon
EC2
Amazon
EMR
users
Internet
Corporate Data Center
Make data suitable to acting as
an ML data source
An ML model is
created with Redshift
as the data source
EC2 as a frontend
for AML end point
Process unstructured and
semi-structured data
Data Lake
Amazon
S3
Amazon
QuickSightAmazon
RDS users
Batch prediction
generated and
stored in S3
DB Schemas
CSV Files
Unstructured files
QuickSight
generates BI reports
on prediction data.
An RDS schema
acts as a source
for QuickSight

Thank you!

Join us tonight at the Health Care happy hour
sponsored by Cambia Health Solutions,
8KMiles.com and AWS at:
Japonais restaurant in the Mirage
on Monday 11/28 from 6-8 PM
AWS and Cambia are co-presenting:
SEC305 – Scaling Security Resources for
Your First 10 Million Customers
Tuesday, Nov 29, 12:30 PM - 1:30 PM
Do you want to know
more about how to
secure health data?

Remember to complete
your evaluations!