availability and performance in wide-area service composition bhaskaran raman eecs, u.c.berkeley...
TRANSCRIPT

Availability and Performance in Wide-Area Service Composition
Bhaskaran RamanEECS, U.C.Berkeley
July 2002

Problem Statement
10% of paths have only 95% availability
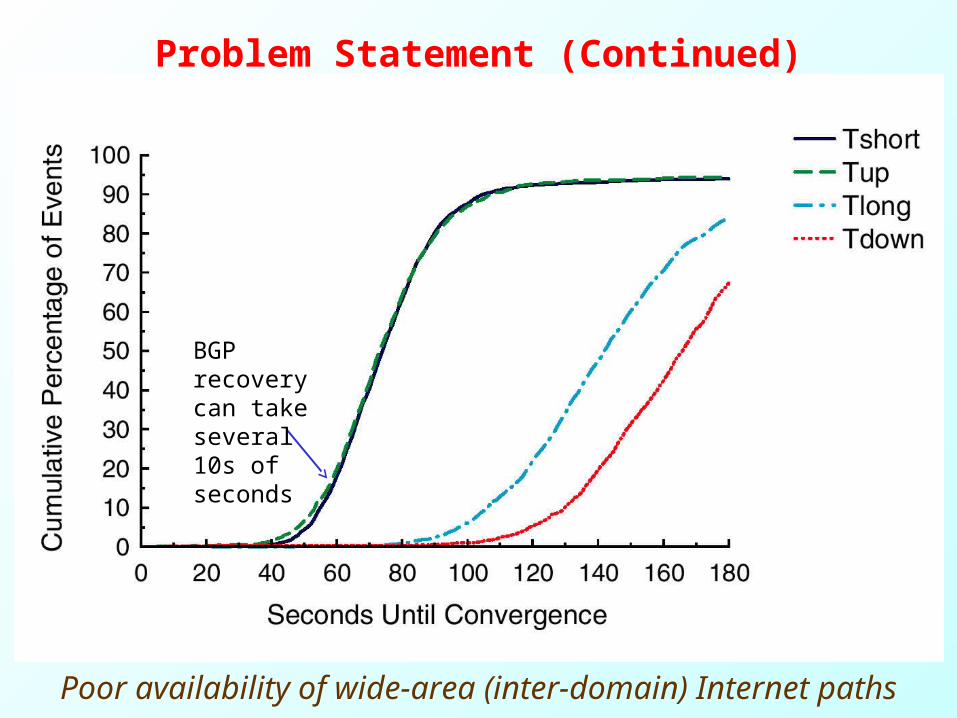
Problem Statement (Continued)
Poor availability of wide-area (inter-domain) Internet paths
BGP recovery can take several 10s of seconds

Why does it matter?
• Streaming applications– Real-time
• Session-oriented applications– Client sessions lasting several minutes to hours
• Composed applications

Service Composition: Motivation
Provider QProvider Q
TextTexttoto
speechspeech
Provider RProvider R
CellularPhone
Emailrepository
Provider AProvider AVideo-on-demandserver
Provider BProvider B
ThinClient
Transcoder
Service-Level Path
Other examples: ICEBERG, IETF OPES’00

Solution Approach: Alternate Services and Alternate Paths

Goals, Assumptions and Non-goals
• Goals– Availability: Detect and handle failures quickly– Performance: Choose set of service instances– Scalability: Internet-scale operation
• Operational model:– Service providers deploy different services at various
network locations– Next generation portals compose services– Code is NOT mobile (mutually untrusting service
providers)
• We do not address service interface issue• Assume that service instances have no
persistent state– Not very restrictive [OPES’00]

Related Work
• Other efforts have addressed:– Semantics and interface definitions
• OPES (IETF), COTS (Stanford)
– Fault tolerant composition within a single cluster• TACC (Berkeley)
– Performance constrained choice of service, but not for composed services
• SPAND (Berkeley), Harvest (Colorado), Tapestry/CAN (Berkeley), RON (MIT)
• None address wide-area network performance or failure issues for long-lived composed sessions

Outline
• Architecture for robust service-composition– Failure detection in wide-area Internet paths
• Evaluation of effectiveness/overheads– Scaling– Algorithms for load-balancing– Wide-area experiments demonstrating availability
• Text-to-speech composed application

Requirements to achieve goals
• Failure detection/liveness tracking– Server, Network failures
• Performance information collection– Load, Network characteristics
• Service location
• Global information is required– Hop-by-hop approach will not work
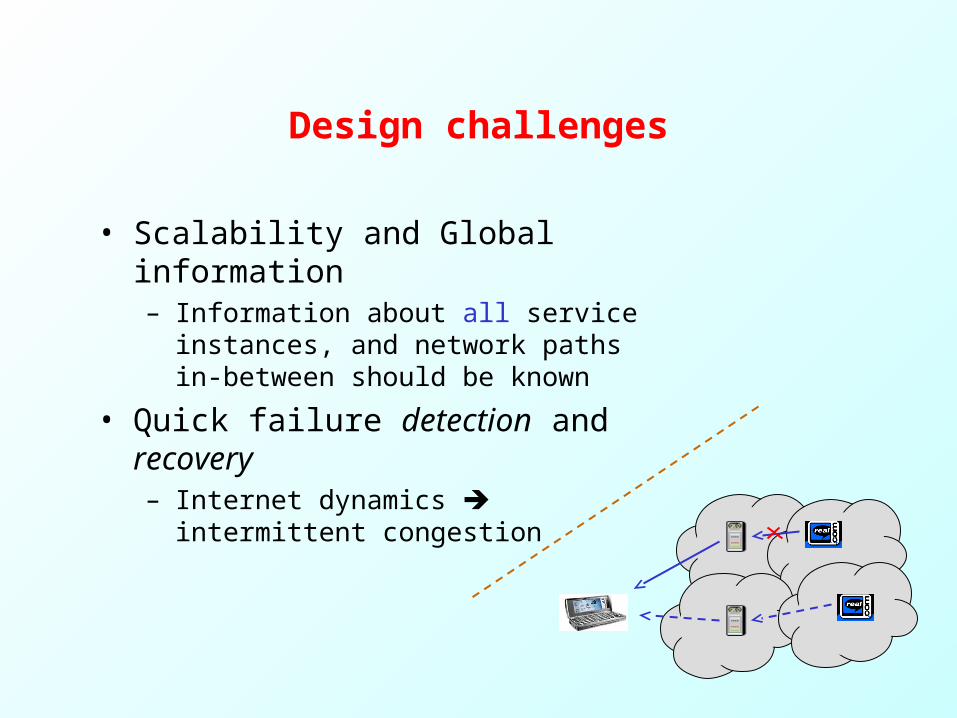
Design challenges
• Scalability and Global information– Information about all service
instances, and network paths in-between should be known
• Quick failure detection and recovery– Internet dynamics intermittent
congestion

Failure detection: trade-off
• What is a “failure” on an Internet path?– Outage periods happen for varying durations
Monitoring for liveness of path using keep-alive heartbeat
Time
TimeFailure: detected by timeout
Timeout period
Time
False-positive: failure detected incorrectly unnecessary overheadTimeout period
There’s a trade-off between time-to-detection and rate of false-positives

Is “quick” failure detection possible?
• Study outage periods using traces– 12 pairs of hosts
• Berkeley, Stanford, UIUC, CMU, TU-Berlin, UNSW• Some trans-oceanic links, some within US (including
Internet2 links)
– Periodic UDP heart-beat, every 300 ms– Measure “gaps” between receive-times: outage
periods– Plot CDF of gap periods
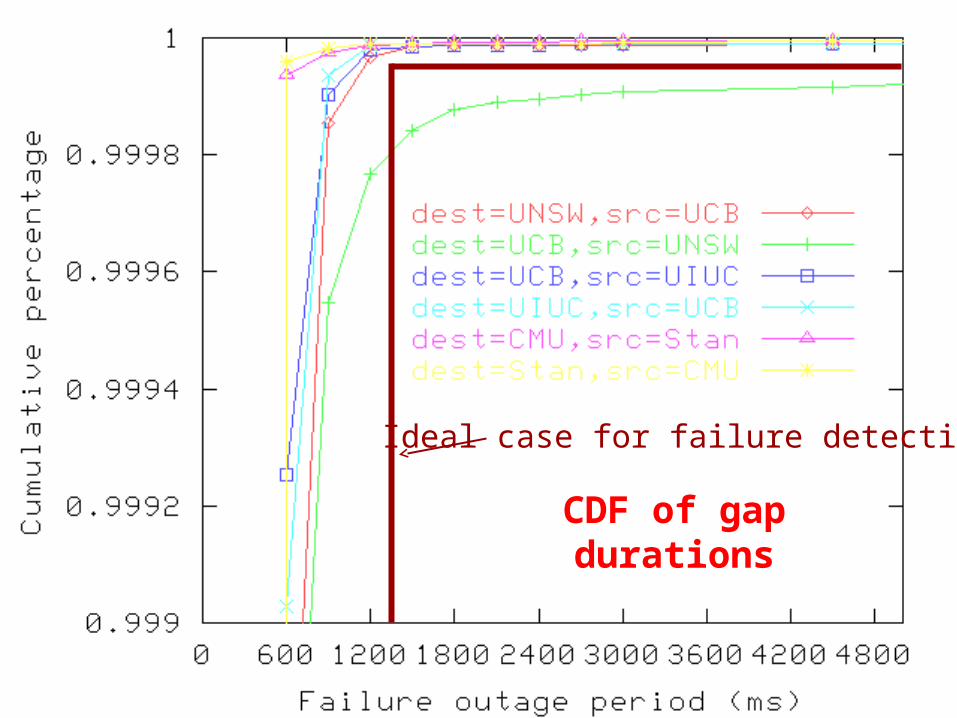
CDF of gap durations
Ideal case for failure detection

CDF of gap distributions (continued)
• Failure detection close to ideal case• For a timeout of about 1.8-2sec
– False-positive rate is about 50%
• Is this bad?– Depends on:
• Effect on application• Effect on system stability, absolute rate of occurrence

Rate of occurrence of outages
Timeout for failure detection

Towards an Architecture
• Service execution platforms– For providers to deploy services– First-party, or third-party service platforms
• Overlay network of such execution platforms– Collect performance information– Exploit redundancy in Internet paths

ArchitectureInternet
Service cluster: compute cluster capable of running
services
Peering: exchange perf. info.
Destination
Source
Composed services
Hardware platform
Peering relations,Overlay network
Service clusters
Logical platform
Application plane
• Overlay size: how many nodes?– Akamai: O(10,000) nodes
• Cluster process/machine failures handled within

Key Design Points
• Overlay size:– Could grow much slower than #services, or #clients– How many nodes?
• A comparison: Akamai cache servers• O(10,000) nodes for Internet-wide operation
• Overlay network is virtual-circuit based:– “Switching-state” at each node
• E.g. Source/Destination of RTP stream, in transcoder
– Failure information need not propagate for recovery
• Problem of service-location separated from that of performance and liveness
• Cluster process/machine failures handled within
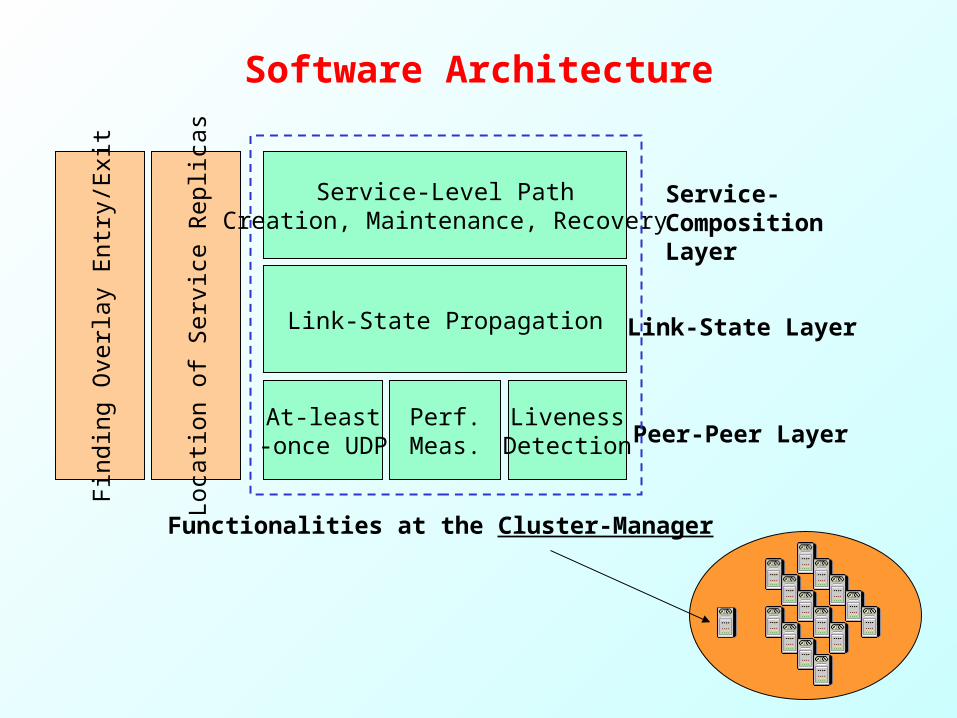
Software ArchitectureFi
ndin
g O
verl
ay E
ntry
/Exi
t
Loc
atio
n of
Ser
vice
Rep
lica
sService-Level Path
Creation, Maintenance, Recovery
Link-State Propagation
At-least-once UDP
Perf.Meas.
LivenessDetection Peer-Peer Layer
Link-State Layer
Service-Composition Layer
Functionalities at the Cluster-Manager

Layers of Functionality
• Why Link-State?– Need full graph information– Also, quick propagation of failure information– Link-state flood overheads?
• Service-Composition layer:– Algorithm for service-composition
• Modified version of Dijkstra’s– To accommodate for constraints in service-level path
• Additive metric (latency)• Load-balancing metric
– Computational overheads?– Signaling for path creation, recovery
• Downstream to upstream

Link-State Overheads
• Link-state floods:– Twice for each failure– For a 1,000-node graph
• Estimate #edges = 10,000
– Failures (>1.8 sec outage): O(once an hour) in the worst case
– Only about 6 floods/second in the entire network!
• Graph computation:– O(k*E*log(N)) computation time; k = #services
composed– For 6,510-node network, this takes 50ms– Huge overhead, but: path caching helps– Memory: a few MB

Evaluation: Scaling
• Scaling bottleneck:– Simultaneous recovery of all client sessions on a failed
overlay link
• Parameter– Load – number of client sessions with a single overlay
node as exit node
• Metric– Average time-to-recovery of all paths failed and
recovered

Evaluation: Emulation Testbed
• Idea: Use real implementation, emulate the wide-area network behavior (NistNET)
• Opportunity: Millennium cluster
App
LibNode 1
Node 2
Node 3
Node 4
Rule for 12
Rule for 13
Rule for 34
Rule for 43
Emulator

Scaling Evaluation Setup
• 20-node overlay network– Created over 6,510 node physical network– Physical network generated using GT-ITM
• Latency variation: according to [Acharya & Saltz 1995]• Load per cluster-manager (CM)
– Vary from 25 to 500
• Paths setup using latency metric• 12 different runs
– Deterministic failure of link with maximum #client paths
– Worst-case in single-link failure
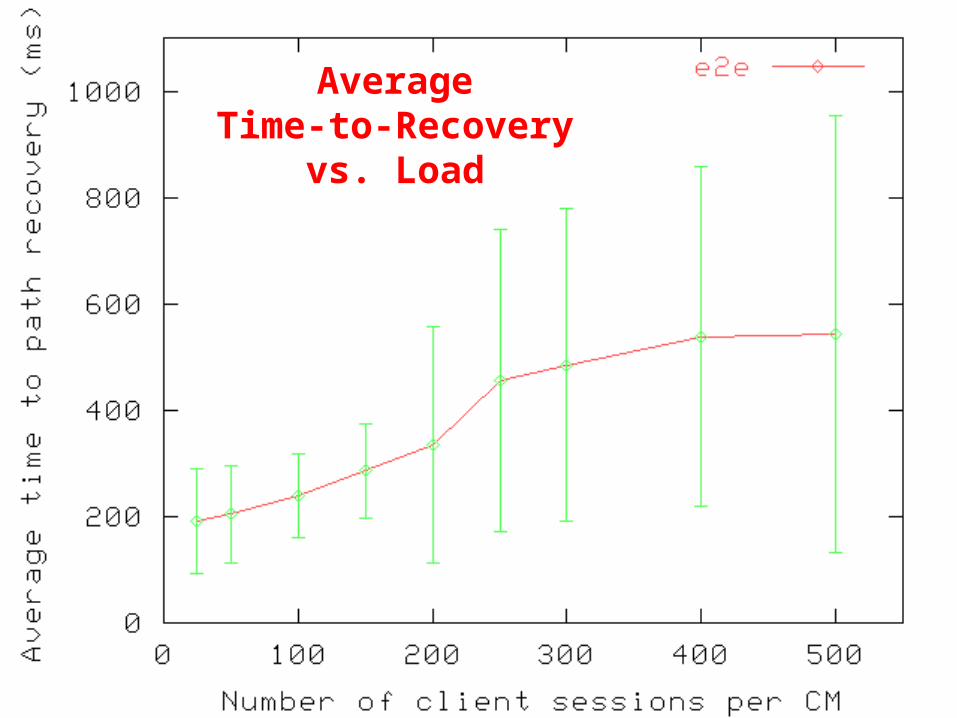
AverageTime-to-Recovery
vs. Load
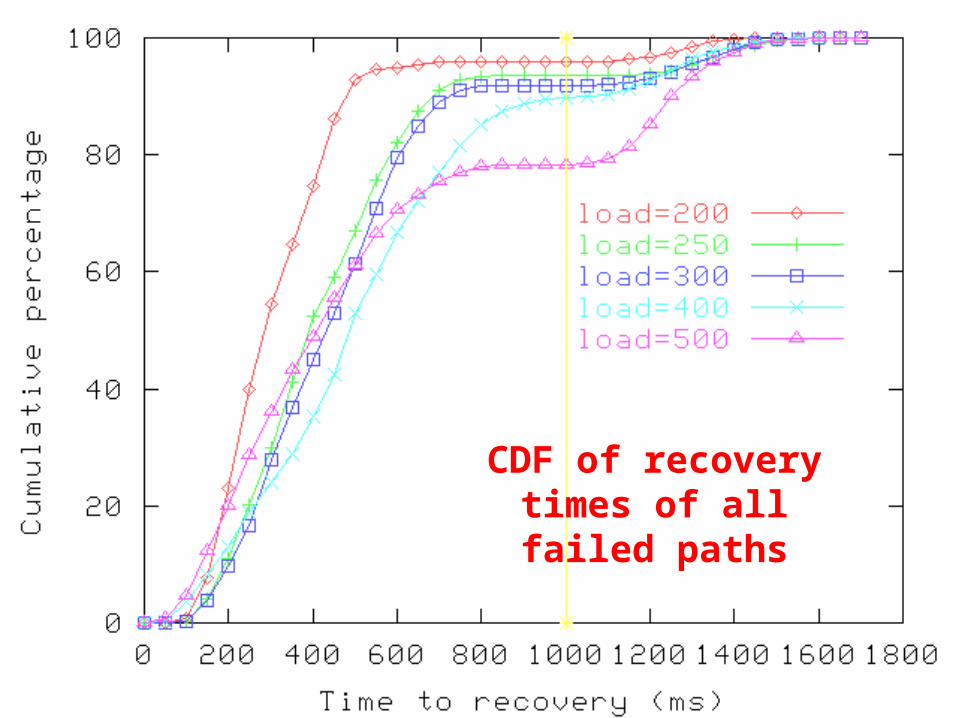
CDF of recovery times of all failed
paths

Path creation: load-balancing metric
• So far used a latency metric– In combination with modified Dijkstra’s algorithm– Not good for balancing load
• How to balance load across service instances?– During path creation and path recovery
• QoS literature:– Sum(1/available-bandwidth) for bandwidth balancing
• Applying this for server load balancing:– Metric: Sum(1/(max_load – curr_load))– Study interaction with
• Link-state update interval• Failure recovery
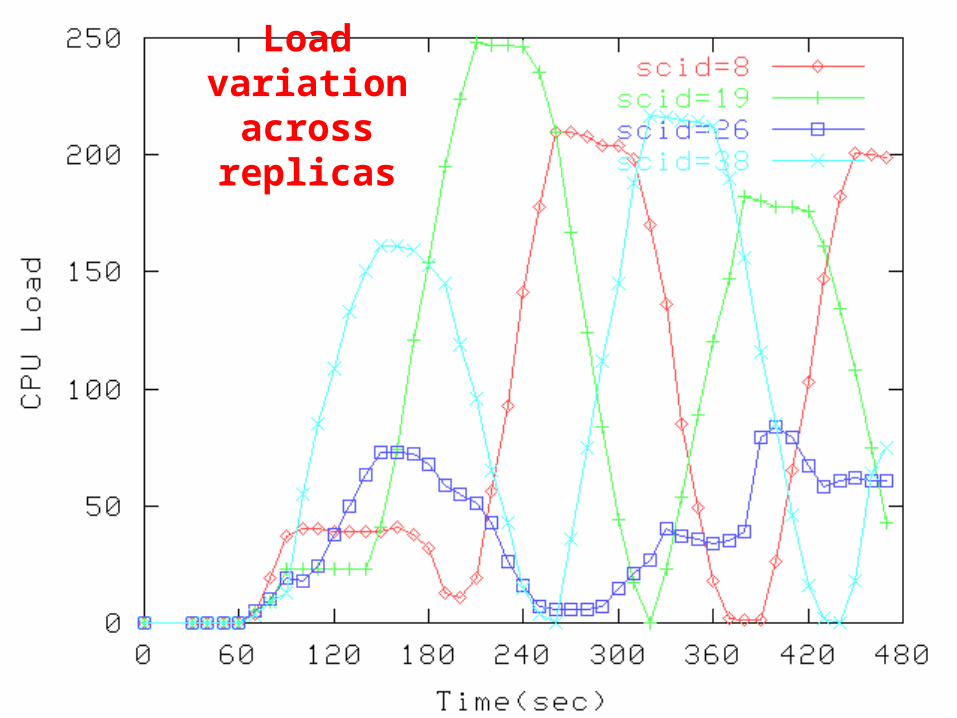
Load variation
across replicas

Dealing with load variation
• Decreasing link-state update interval– More messages– Could lead to instability
• Use path-setup messages to update load– Do it all along the path
• Each node that sees the path setup message– Adds its load info to the message– Records all load info collected so far

Load variation with piggy-back
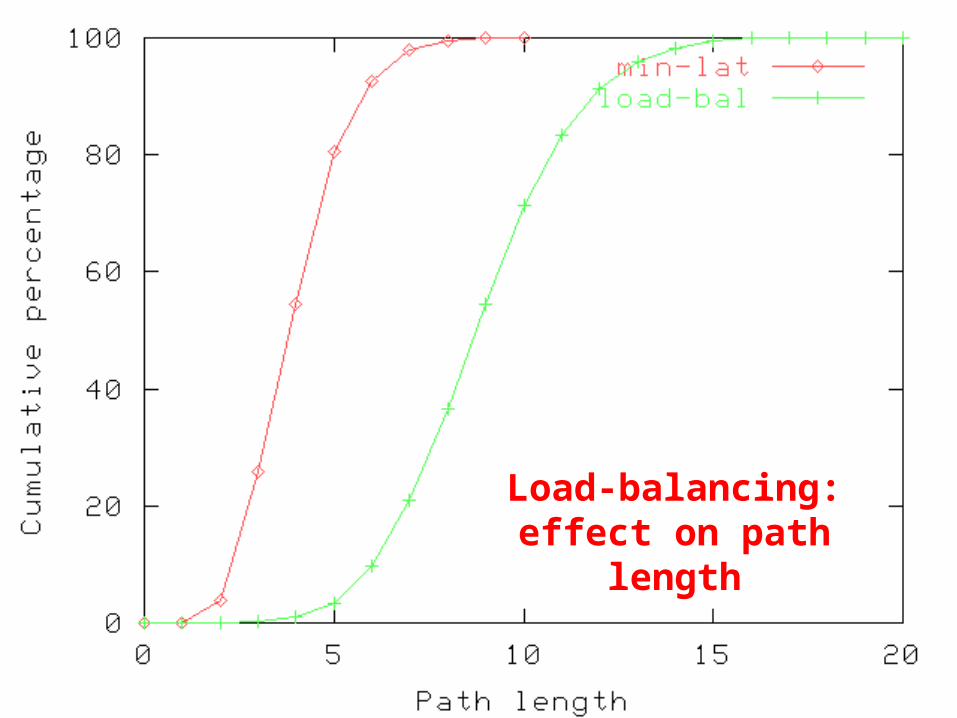
Load-balancing: effect on path
length

Fixing the long-path
effect
Metric:Sum_services(1/(max_load-curr_load)) + Sum_noop(0.1/(max_load-curr_load))
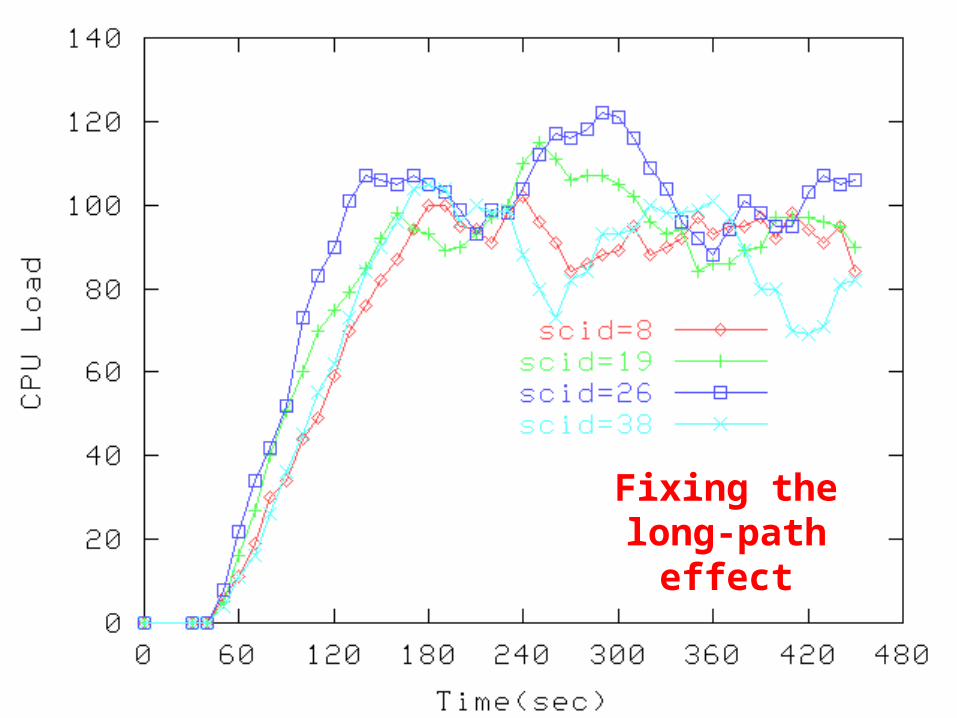
Fixing the long-path
effect

Wide-Area experiments: setup
• 8 nodes:– Berkeley, Stanford, UCSD, CMU– Cable modem (Berkeley)– DSL (San Francisco)– UNSW (Australia), TU-Berlin (Germany)
• Text-to-speech composed sessions– Half with destinations at Berkeley, CMU– Half with recovery algo enabled, other half disabled– 4 paths in system at any time– Duration of session: 2min 30sec– Run for 4 days
• Metric: loss-rate measured in 5sec intervals
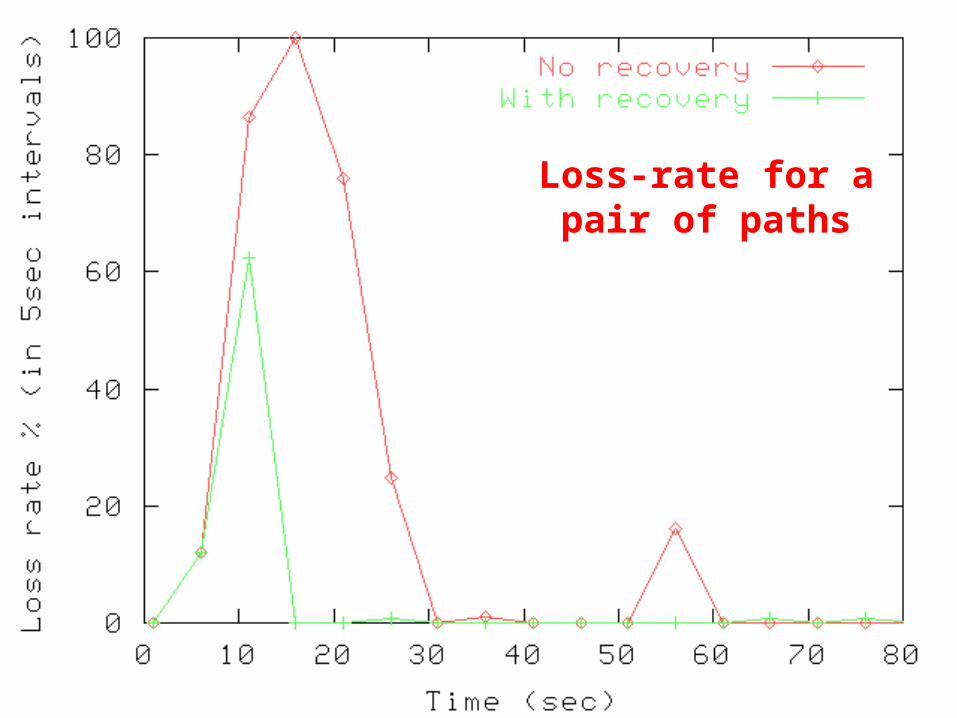
Loss-rate for a pair of paths

CDF of loss-rates of all paths failed

CDF of gaps seen at client

Improvement in Availability
Availability % table(Client at Berkeley)
Without recovery
With recovery
Day 1 99.58 99.63
Day 2 99.65 99.67
Day 3 99.65 99.65
Day 4 99.86 99.91
Day 5 99.87 99.92
Day 6 99.63 99.69
Day 7 99.84 99.88
Day 8 99.71 99.80
Day 9 99.79 99.93
Day 10 99.10 99.23
Day 11 99.86 99.88
Availability % table(Client at CMU)
Without recovery
With recovery
Day 1 99.59 99.59
Day 2 99.73 99.96
Day 3 99.79 99.98
Day 4 100.00 100.00
Day 5 99.45 99.45
Day 6 98.29 98.67
Day 7 95.79 96.21
Day 8 97.43 97.45
Day 9 98.98 98.99
Day 10 97.98 97.96
Day 11 98.69 98.74
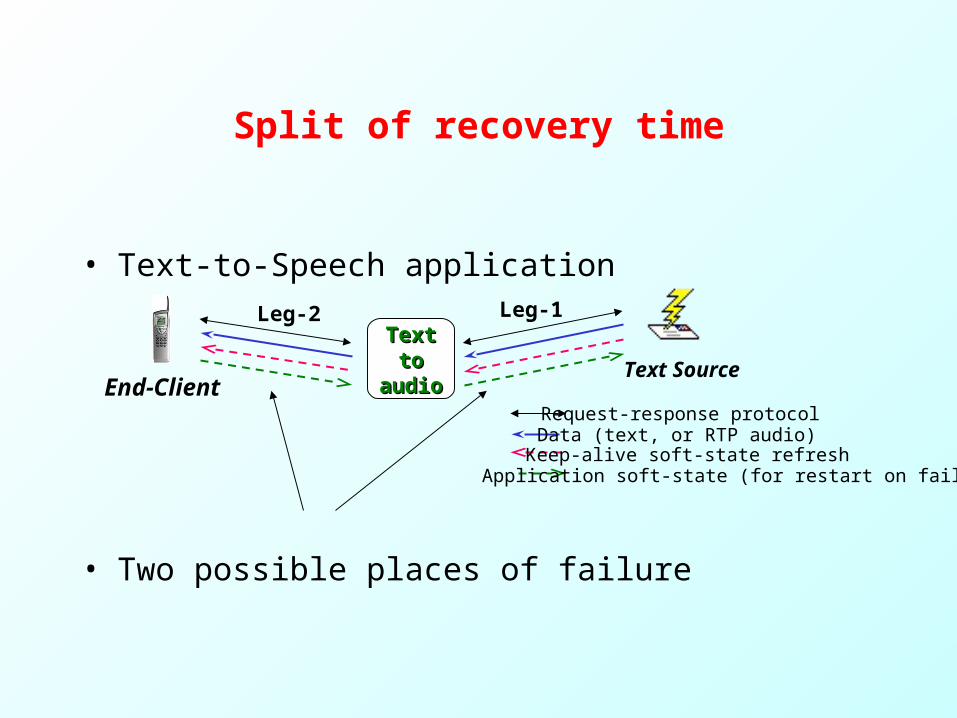
Split of recovery time
• Text-to-Speech application
• Two possible places of failure
Leg-2 Leg-1TextText
totoaudioaudio
Text SourceEnd-Client
Request-response protocolData (text, or RTP audio)Keep-alive soft-state refreshApplication soft-state (for restart on failure)

Split of Recovery Time (continued)
• Recovery time:– Failure detection time– Signaling time to setup alternate path– State restoration time
• Experiment using tts application, using emulation– Recovery time = 3,300ms– 1,800ms failure detection time– 700ms signaling– 450ms for state restoration
• New tts engine has to re-process current sentence

Summary
• Wide-area Internet paths have poor availability– Availability issues in composed sessions
• Architecture based on overlay network of service clusters
• Failure detection feasible in ~ 2sec• Software-arch scales with #clients• WA experiments show improvement in
availability