autotuning large computational chemistry codes peri principal investigators: david h. bailey...
TRANSCRIPT

1
Autotuning Large Computational Chemistry Codes
PERI Principal Investigators:David H. Bailey (lead) Lawrence Berkeley National LaboratoryJack Dongarra and Shirley Moore University of Tennessee at Knoxville
Other Lead Investigators:Samuel WilliamsLawrence Berkeley National LaboratoryMark Gordon and Theresa Windus Ames LaboratoryJoseph Kenny Sandia National LaboratoryAllen Malony and Sameer Shende University of Oregon

2
Ab initio Chemistry Codes and Applications
• Codes: GAMESS, NWChem, MPQC– Community codes: >100,000 users
• DOE Combustion Energy Frontier Research Center (CEFRC)– Emily Carter, Princeton University– Target application and kernel
• Large-scale simulations of the large hydrocarbons and sulfur-containing hydrocarbons that are components of diesel fuel
• Linear scaling multireference configuration interaction (MRCI) module
• Applications– Solar energy cell design– Combustion efficiency– Materials science– Nanoscience and nanoelectronics
• Broader impact: results applicable to other ab initio chemistry codes

3
Motivation for Autotuning
• Large-scale complex architectures– Performance tuning requires expertise and is time-
intensive– Hand-tuned codes difficult to maintain– Discontinuous GPU performance optimization space
• Real-world test case for PERI autotuning tools– Feedback from applications helps improve tools– PAPI, TAU, HPCtoolkit, CHILL, Orio, ROSE, GCO, Active
Harmony– Also using Open|SpeedShop and PerfExpert

4
PERI Autotuning Workflow
original code
transformation and code generation
optimized code variant execution environment
search engine
representative input
performance feedback
transformation recipes
developer
code triage performance data
code outlineroutlined code
HPCToolkit, TAU, PAPI
ROSE compiler
CHiLL, LoopTool, POET, Orio
ActiveHarmony, GCO
optimized code

5
Project Status/Milestones
• Q1, Q2, Q3 milestones largely achieved – Integration of MRCI code into GAMESS, analysis– Profiling of MPQC integral kernels, autotuning– Setup of PerfDMF database– DAG scheduler not yet implemented
• Q4 milestones (current work)– Evaluation of integral code autotuning – Parallelization and autotuning of MRCI code– Identification of additional kernels for autotuning

6
Gprof Profile for MPQC Integral Computation
• GNU gprof flat profile:
% cumulative self self total time seconds seconds #calls s/call s/call name ----------------------------------------------------------------------------------------------------------------------- 27.97 15.10 15.10 18,157,902 0.00 0.00 sc::Int2eV3::blockbuildprim_1( ) 8.40 19.63 4.53 12,508,925 0.00 0.00 sc::Int2eV3::compute_erep( ) 6.82 23.31 3.68 12,500,000 0.00 0.00 sc::EAVLMMap<>::find( ) 6.73 26.94 3.63 5,960,291 0.00 0.00 do_sparse_transform2_3new( ) 6.11 30.23 3.30 8,392,891 0.00 0.00 do_sparse_transform2_1new() 4.97 32.91 2.68 1,332,270 0.00 0.00 sc::Int2eV3::shiftam_34( ) 4.96 35.59 2.68 5,942,149 0.00 0.00 do_sparse_transform2_2new( ) 4.15 37.83 2.24 6,405,352 0.00 0.00 sc::Int2eV3::build_not_using_gcs( ) 3.85 39.91 2.08 2,365,269 0.00 0.00 sc::Int2eV3::shiftam_12( ) 2.71 41.37 1.47 1,2500,000 0.00 0.00 sc::Int2eV3::int_have_stored_integral( ) … …

7
TAU Analysis of Threaded MPQC
Optimized TAU instrumentation using sampling and selective instrumentation Identified blockbuildprim and compute_erep as significant

8
Collected PAPI Data
• Fflop/Cycle = 0.24 (i.e., CPI = 4.2)• L1 cache miss rate = 0.45%• L2 cache miss rate = 5.6%• TLB miss rate = 0.017% • Branch miss prediction rate = 3.7%• Cycles stalled = 261 M (21% of total cycles)• Question: Is it a memory bound or CPU bound
application?– T(n) is between O(n2) and O(n4)

9
A Stand-Alone Kernelvoid blockbuildprim_1(double* A2, double* B, int amin, int amax, int am34, int size34) {
for(am12=amin; am12<=amax; am12++) { for (i12=2; i12<=am12; i12++) { for (k12=0; k12<=am12-i12; k12++) { double *A=&A2[am34+1]; double d = half_ooze; k = 0; for (i34=1; i34<=am34; i34++) { for (k34=0; k34<=am34-i34; k34++) { A[k] += d * B[k]; k++; } d += half_ooze; } A2 += size34; } } }}
Lack of ILP
10
Improvement
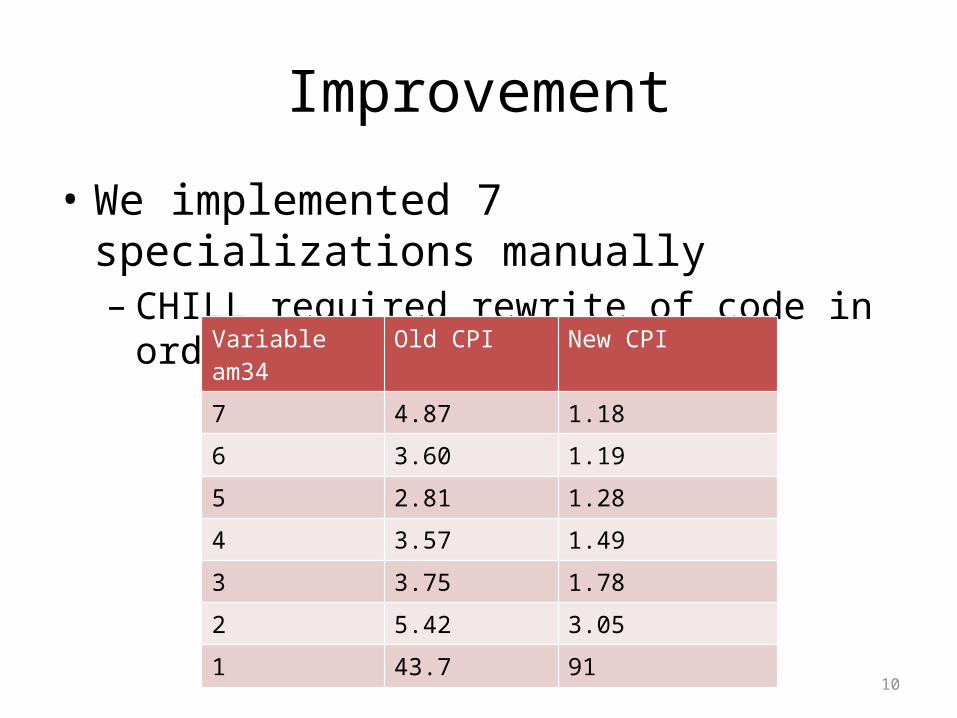
• We implemented 7 specializations manually– CHILL required rewrite of code in order to work
Variable am34 Old CPI New CPI
7 4.87 1.18
6 3.60 1.19
5 2.81 1.28
4 3.57 1.49
3 3.75 1.78
2 5.42 3.05
1 43.7 91

11
Further MPQC Integral Computation Autotuning
• Autotuning parameters set up by code developers (total of 10 parameters, 26244 possible combinations)– Swapping order of general contraction loops– Redundant primitives or not– Generated code or not– Compiler optimization of low level routines
• Wrote GCO scripts to perform exhaustive search• 30% performance improvement over default settings• Need to try more molecules

12
GAMESS+TigerCI Integration

13
TigerCI Optimization and Parallelization
• Integrated the TigeCI code into GAMESS and analyzed performance. • Significant single core performance optimizations have been made
– Replacement of loops over BLAS-1 operations by single BLAS-2 operations • Bottlenecks in the serial code have been identified
– Cholesky decomposition step and the transformation of the Cholesky matrix from the atomic to the molecular basis
– Observation that a loop transformation could accelerate a key part of the code by a factor of three
– Perform these transformations using automatic tools (CHILL, Orio) • Preliminary work to parallelize the code
– BLAS-2 and BLAS-3 operations replaced by multithreaded implementations

14
TAU Analysis of GAMESS+TigerCI
Performance data were added to a PerfDMF profile database.
Data were collected for experiments on C2H6, C3H8, C4H10, C5H12, C6H14, C8H18 and C9H20 chemistry.
Preliminary analysis was conducted, comparing all trials with respect to input complexity.
15
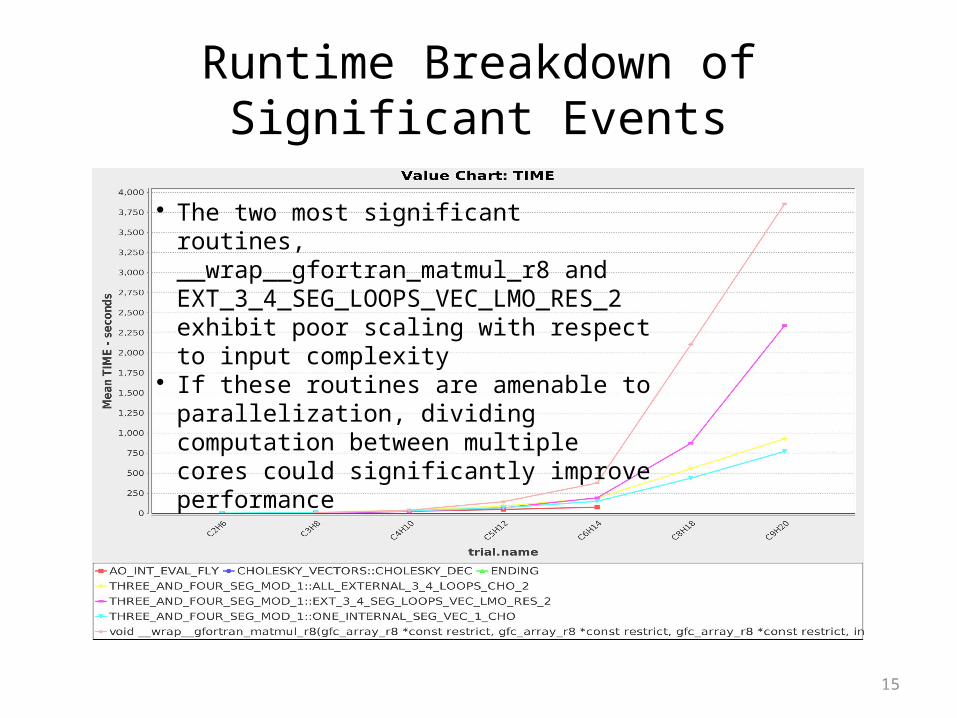
Runtime Breakdown of Significant Events
The two most significant routines, __wrap__gfortran_matmul_r8 and EXT_3_4_SEG_LOOPS_VEC_LMO_RES_2 exhibit poor scaling with respect to input complexity
If these routines are amenable to parallelization, dividing computation between multiple cores could significantly improve performance

16
Runtime Scaling
Note the inflection point at C6H14, beyond this level of input complexity the runtime increases rapidly.

17
Continuing Work
Currently focusing on collecting more significant profile data from GAMES+TigerCI PAPI Hardware Counter Data Callpath Profiling Sampling
Collecting data in profile database for extensive analysis across multiple trials
Comparison of parallelization strategies for Tiger CI

18
Exploring further GPU optimizations of GAMESS modules
• Current GPU implementations of kernels yield 4-17x speedup compared to GAMESS on CPU
• Model and predict optimal GPU performance– Hardware counter data from PAPI GPU component– TAU– PerfExpert and MACPO from TACC
• Additional optimizations for Fermi architecture– Resource usage
• Registers and memory• Optimal use of special functional units (SFUs)• Optimal partitioning of shared memory/L1 cache
– Increase compute to memory access ratio• Unroll and jam
– Combinations of optimizations• Discontinuous optimization space!