autoqsar: an automated tool for best- prac8ces qsar modeling · pdf fileautoqsar: an automated...
TRANSCRIPT

AutoQSAR:AnAutomatedToolforBest-Prac8cesQSARModeling
Dr.Ma'RepaskyDr.SteveDixonOct.19,2016

Overview• Introduc@ontoAutoQSAR• Valida@onofAutoQSARmethodologyagainstQSARmodelsfromliterature
• Predic@ngproteinsolubilitybyQSAR• Exampleofintegra@onofQSARmodelsintoacheminforma@csplaLorm(LiveDesign)

Newmoleculepropertypredic@ons
QSAR–Quan8ta8veStructureAc8vityRela8onships
Newmolecules
Propertytomodelfortrainingsetcompounds
Descriptorsfortraining
setcompounds
Machinelearning
techniques

• AutoQSAR– AccessedthroughMaestroorcommandline
– Automa@callycreatesQSARmodelsfollowingabest-prac@cesapproach
• Canvas– Acompletesetofexpert-capabilitytoolstocreate,validateandemployQSARmodels
– AccessedthroughCanvasGUIorcommandline
• Strike– AccessedthroughMaestroorcommandline
– CreatebasicnumericQSARmodelswithproperty-baseddescriptors
Crea8ngQSARModelsintheSchrödingerSuite

AutoQSARisa“QSARexpertinabox”• HighdemandforourQSARexpert’s@memo@vatedcrea@onofAutoQSAR
• Automa@callygeneratepredic@veQSARmodelsfollowingbest-prac@cesmethodology
• Easilycreate,validate,distribute,andemployQSARmodelsdirectlyfromMaestro– AutoQSARknowshowtogeneratenecessarydescriptorsandapplymodelsforpredic@ons
• QuicklyandeasilydeployQSARmodelsviaLiveDesignorotherinforma@csplaLorms
CorwinHansch–FatherofQSAR

KeyBenefitsofUsingAutoQSARforQSARModeling
• GenerateandemployQSARmodelswithconfidence• Save@meiden@fyingapproachesmost/leastlikelytobesuccessfulbeforemanualQSARmodeling– Evidencesuggeststhereisnosingleidealdescriptorsetormachinelearningmethodapplicabletoallendpoints
• EasilydeployQSARmodelsacrossprojectgroups/labsandarangeofinforma@csplaLorms
• Takeadvantageoflargeamountsofpublicandprivatedata– ChEMBL,PubChem,ChemSpider
• ImproveQSARmodelsasdataareaddedduringaproject11Mol.Inform.30(2-3),256-266(2011)
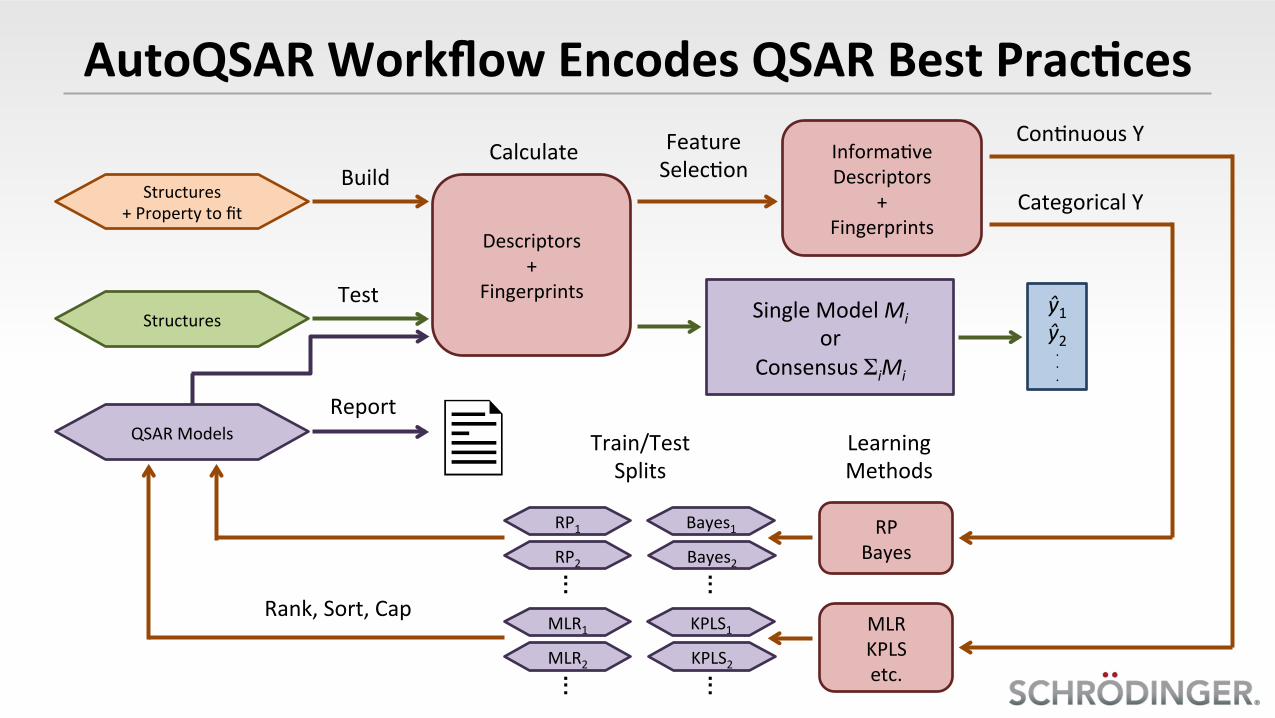
AutoQSARWorkflowEncodesQSARBestPrac8ces
Structures+Propertytofit
Structures
QSARModels
Build
Test
Report
!
Descriptors+
Fingerprints
Informa@veDescriptors
+Fingerprints
Calculate FeatureSelec@on
SingleModelMior
ConsensusΣiMi
Con@nuousY
CategoricalY
RPBayes
MLRKPLSetc.
Train/TestSplits
Bayes1
RP2
RP1
Bayes2
KPLS1
MLR2
MLR1
KPLS2
Rank,Sort,Cap
LearningMethods
ŷ1ŷ2...

InputsforQSARModelingwithAutoQSAR• LigandsprovidedinSMILES,2D,or3Dformats• Datacura@onrecommenda@ons:– Consistencyinligandprepara@ontonormalizespecificchemotypesandtreatmentoftautomericforms
– Removeduplicates– Removeundesirables–mixtures,salts,etc.– Minimizedatainadequacy
• Predictedpropertyshouldn’tspanmul@pleordersofmagnitude– Converttologarithmicscaleifnecessary,i.e.IC50topIC50
• Endpointshouldbeinmolarandnotweightunits• Dataheterogeneityshouldbeavoidedifpossible,i.e.datafromdifferentspecies/protocols

DescriptorSetsUsedbyAutoQSARFingerprintType Descrip8on
Dendri@c Linearandbranchedfragments
Linear Linearfragments+ringclosures
MOLPRINT2D Radial-likeFPthatencodesatomenvironmentsusinglistsofatomtypeslocatedatdifferenttopologicaldistances
Radial Fragmentsthatgrowradiallyfromeachatom.Alsoknownasextendedconnec@vityfingerprints
497topology-baseddescriptors• Estatecounts• 2Dtopologicaldescriptors• Func@onalgroupcounts
Employalterna@vedescriptorsifdesired

FeatureSelec8on• Descriptors:– Eliminatedescriptorswhere>90%oflearningsethasthesamevalue– EnsurenopairofdescriptorshasanabsolutePearsoncorrela@oncoefficientgreaterthan0.8
• Fingerprints:– Ofallbitssetbyatleastonecompound,onlythemostsignificant10,000withthegreatestvarianceoverthelearningsetareemployed

MachineLearningMethodsEmployed
SupportedVariableTypes
Descrip8on Dependent(y) Independent(x)
Bestsubsetsmul@plelinearregression(MLR)
Con@nuous Descriptors
Par@alleastsquaresregression(PLS)
Con@nuous Descriptors
Principalcomponentsregression(PCR)
Con@nuous Descriptors
Kernel-basedPLS(kPLS) Con@nuous Descriptors,fingerprints
NaïveBayesclassifica@on Categorical Descriptors,fingerprints
Ensemblerecursivepar@@oning(RP)
Categorical Descriptors
NeuralnetworkmodelsarenotcreatedbyAutoQSARastheywerefoundtobetooeasilyoverfit

CreateandvalidateQSAR
model
Splitdataset
SpliXngLearningSetintoTest/TrainingSets• Intradi@onalsingleQSARmodelcrea@onbiasingtraining/testsetisooendesireddueto“allornothing”outcome
• Toincreaseprobabilityoffindingapredic@vemodelwithgoodpredic@veabilityAutoQSARrandomlysplitslearningsetinto75%training/25%testsetN@mescrea@ngmanyQSARmodels
• With
CreateandvalidateQSAR
model
LearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModelLearningSet TrainingSet TestSetQSARModel
Splitdataset

ScoringFunc8ontoRank-OrderQSARModels
score = accuracytest • 1.0− accuracytrain − accuracytest( )accuracytrain,continuous = R
2 =1.0−σ 2err σ
2y
accuracytest,continuous =1.0−σ2err σ
2Ly
accuracycategorical =1n
fkk=1
n
∑
• RankorderQSARmodelsbytheirpredic@vepower• Retaintop10modelsbydefault– Useofaddi@onalmodelsmaydegradeaccuracyifthosemodelsarenotsufficientlypredic@ve

• Defaultistocreateconsensusmodelfromtop10-rankedmodels
• Forcon@nuousmodels
• Forcategoricalmodels– Eachofthemmodelsvotesforacategoryandcompoundisassignedtocategorywithmostvotes
– Incaseofa@e,categorywithhighestaverageprobabilityofpredic@onisassigned
ApplyConsensusorSingleModelPredic8onsConsensusmodelsooenincreasepredic@onaccuracyandexpandapplicabilitydomainfordiverseQSARmodels
yi =1m
yijj=1
m
∑“Thisobserva@onsuggestthatconsensusmodelsaffordbothhighspacecoverageandhighaccuracyofpredic@on”

AutoQSARApplicabilityDomainEs8mate• Domain_Alertindicateswhetheracompoundisoutsidethesimilarityrangeof95%oftrainingsetcompounds– ForsingleQSARmodelsDomain_Alertsare1or0
• Domain_Scoreisaz-scorethatindicateshowstructurally‘similar’acompoundistotrainingsetcompounds– Tanimoto‘similarity’calculatedtoamodaldendri@cfingerprintfromtrainingsetstructures(logicalORofallonbits):
Domain_Scorei=(simi-µsim)/σsim
Domain_Alertissetto1whenDomain_Score<-2– ForconsensusmodelstheDomain_Scoreisaveragedoverallmodelsintheconsensus
• Applicabilitydomaines@matesmostusefulforlocalmodels
0.0
Domain_Alert1.0

AutoQSARPredic8onErrorRela8onshiptoDomain_ScoreforLocalModels
0
0.5
1
1.5
2
2.5
3
MeanAb
soluteError(log)
0.0-0.3
0.3-0.6
0.6-0.8
0.8-1.0
>1.0
Domain_ScoreRange

AutoQSARDomain_AlertsRecognizeCompoundsDissimilartotheTrainingSet
fxa_1f0r chk1_2e9u lxrb_3kfc throm_1mue cdk2_2bkz metap2_2adu cdk2_1fvt metap2_1r5g hsp90_2ccu fxa_1z6efxa_1f0r 4 100 100 100 100 100 100 100 100 100chk1_2e9u 100 29 100 100 100 100 100 100 100 100lxrb_3kfc 100 100 11 100 100 100 100 100 100 100throm_1mue 100 100 100 4 100 100 100 100 100 100cdk2_2bkz 100 100 100 100 11 100 100 100 100 100metap2_2adu 96 90 75 100 100 7 87 98 90 14cdk2_1fvt 100 100 100 100 100 100 4 100 100 100metap2_1r5g 0 57 36 83 94 100 26 2 50 14hsp90_2ccu 100 100 100 100 100 100 100 100 10 100fxa_1z6e 100 100 100 100 100 100 100 100 100 14
PercentofTestSetCompoundswithDomain_AlertsDataset/Model
SelectCompoundsFromfxa_1f0rtrainingset SelectCompoundsFrommetap2_1r5gtestset

AutoQSARDomain_AlertsRecognizeCompoundsDissimilartotheTrainingSet
fxa_1f0r chk1_2e9u lxrb_3kfc throm_1mue cdk2_2bkz metap2_2adu cdk2_1fvt metap2_1r5g hsp90_2ccu fxa_1z6efxa_1f0r 4 100 100 100 100 100 100 100 100 100chk1_2e9u 100 29 100 100 100 100 100 100 100 100lxrb_3kfc 100 100 11 100 100 100 100 100 100 100throm_1mue 100 100 100 4 100 100 100 100 100 100cdk2_2bkz 100 100 100 100 11 100 100 100 100 100metap2_2adu 96 90 75 100 100 7 87 98 90 14cdk2_1fvt 100 100 100 100 100 100 4 100 100 100metap2_1r5g 0 57 36 83 94 100 26 2 50 14hsp90_2ccu 100 100 100 100 100 100 100 100 10 100fxa_1z6e 100 100 100 100 100 100 100 100 100 14
PercentofTestSetCompoundswithDomain_AlertsDataset/Model
SelectCompoundsFromfxa_1f0rtrainingset SelectCompoundsFrommetap2_1r5gtrainingset

AutoQSARModelGenera8onTimings• CPU@mescaleslinearlywiththenumberofmolecules– Minutesforlocalmodels,hoursforglobalmodelson1CPU
• Builtincapof5ktraining/testsetligands• Licensingfavorabletorunningonmul@pleCPUs(1token/subjob)
0
2
4
6
8
10
12
800 1000 1200 1400 1600 1800
HoursT
oMod
el
NumberofTraining/TestSetLigands
SingleCPU
50CPUs

Crea8ngAutoQSARModelsinMaestro

ApplyingAutoQSARModelinMaestro

Valida8onofAutoQSARMethodologyObjec8ve:Examinepredic@veperformanceofAutoQSARmodelscreatedforavarietyofproper@esandcomparetopublished,humanexpert-createdQSARmodels– CanAutoQSARgeneratemodelswithsimilarperformancetothosepublishedbyQSARexperts?
– ResearchpublishedinFutureMed.Chem.,2016,8(15),1825-1839.
ClassifierQSARModelsFishbioconcentra@onfactor
CarcinogenicityMutagenicity
NumericQSARModelsCongenericSeriesBindingaffinity
SolubilityBloodbrainbarrierpermeability

CongenericSeriesBindingAffinity
J.Chem.Inf.Model.,2013,53(9),2312-21.
• PrimarilykPLSmodelswithafewPLSmodels
• kPLSmodelsprimarilyfingerprint-based
• CHK12e9upoorQ2forexternalvalida@onsetduetopredic@ngonecompoundwithIC50of10μMtobe10nM.RMSEis0.82.
54to150compoundsinlearningset18to50compoundsinexternalvalidset

Solubility
LearningsetR2=0.88Externalvalida@onsetQ2=0.89
LearningsetR2=0.88
J.Chem.Inf.Model.,2007,47(4),1395-1404
1708compoundsinlearningset427compoundsinexternalvalid
set

BloodBrainBarrierPermeability
!!BBB"############
predicted#BBB+################
predicted#BBB"# 25! 18!BBB+# 6! 50!!
144compoundsinlearningset99compoundsinexternalvalidset
Accuracy=(25+50)/(99)*100=75.7%Sensi8vity=50/(50+18)*100=73.5%Specificity=25/(25+6)*100=80.5%
Pharm.Res.25(8),1902-1914(2008)

Carcinogenicity
644compoundsinlearningset161compoundsinexternalvalid
set
Chem.Cent.J.,4Suppl1,S3(2010)

Mutagenicity
ChemistryCentralJournal4Suppl1S2(2010)
3367compoundsinlearningset837compoundsinexternalvalid
set

FishBioconcentra8onFactor
0.0
0.1
0.2
0.3
0.4
0.5
0.6
CAESARPredic@on AutoQSARconsensusmodelalldescriptors*
AutoQSARconsensusmodelonlyfingerprints
AutoQSARbestmodelalldescriptors
AutoQSARbestmodelonlyfingerprints
ExternalValida8onSetQ2
473compoundsinlearningset119compoundsinexternalvalidset
Chem.Cent.J.,4Suppl1,S1(2010)

UsingAutoQSARtoPredictProteinSolubility
Trainoretal.,JMB,Vol428,(6),Mar2016,pp1365–1374
31FG-Loopvariants
0%10%20%30%
Percen
tofFG
Loop
Seq
uences
PercentInsoluble
Goal:UseproteindescriptorstocreateanAutoQSARmodeltopredictproteinsolubilityforAdnec@ns
• Adnec@nsareengineeredtargetbindingproteinsfromthefibnectrintypeIIIdomain
• Muta@onsinFGLoopgreatlyinfluenceforma@onofinclusionbodies(IB)thatnega@velyimpactsolubility
• Conforma@onallyverymobile,facilitatesbindingtotarget
• IB-forma@oncannotbeexplainedbyvaria@oninthermalstabilityamongtheloopmutants(DSCdata)
• IB-forma@oniscorrelatedwiththeaveragelocalstabilityofFG-loop

ProteinDescriptors• Scalardescriptors(25):calculatedontheen@restructure
– pI,netcharge,electrophore@cmobility,hydrodynamicradius,radiusofgyra@on,dipolemoment,hydrophobicmoment,aggrega@onpropensi@es,etc…
• Region-specificdescriptors(25-residueaware):– Charge,zetapoten@al,surfaceexposure,hydrogenbond
donors/acceptors,hydrophobicity,energe@ccontribu@onstoposi@ve,nega@veandhydrophobicpatches,AggrescanandZyggregatorprofilescores,etc…
– e.g.full-lengthimmunoglobulin(25regions->625datapoints):
• VL,VL_Fc,FR,FR1,FR2,FR3,FR4,L1,L2,L3,CL
• VH,VH_Fc,FR,FR1,FR2,FR3,FR4,H1,H2,H3,CH1,CH2,CH3,Hinge
• Patch-specificdescriptors(27): – Basedonpatchsize,energyscores– Notresidue-awareness
Workflowtocomputeproteindescriptors

ProteinDescriptors–Adnec8nBenchmarkSet• Adnec8ns:engineeredtargetbindingproteinsfromthefibnectrintypeIIIdomain– Residuemuta@onsinthreelociofasolvent-exposedbindingloop(FG-Loop)greatlyalterforma@onofinclusionbodies(IB)
– FG-LoopisanalogoustoCDRH3domaininimmunoglobulins• conforma@onallyverymobile,facilitatesbindingtotarget
– IB-forma@oncannotbeexplainedbyvaria@oninthermalstabilityamongtheloopmutants(DSCdata)
– IB-forma@oniscorrelatedwiththeaveragelocalstabilityofFG-loop• Modelledwithcomputa@onallyexpensiveloopsamplingmethod(R2=0.61)
– Zyggregatorpredic@on(sequence-basedaggrega@onpredic@onmethod)correlateswithIB-forma@on(R2=0.63)

ProteinDescriptors–Aggrega8onPredic8on• AGGRESCAN Vendrelletal.BMC(2007)8:65,1-17
– Intracellularaggrega@onpropensityformutantsofAβ42pep@de– Algorithmwasparameterizedonmutants– Validatedwithexperimentaldataof24fibril-formingpep@desa3v:amino-acidaggrega@onpropensityvalue(basedonexperiment)a4v:smoothedamino-acid(smoothingwindowsize:5,7,9,11)HS:aggrega@onhotspots
• ZYGGREGATOR Pawaretal.J.Mol.Biol.(2005)350,379–392
– Algorithmcalculatestherela@vefoldingpropensityandaggrega@on– Combina@onof4factorsintrinsictoasequence:
• charge,hydrophobicity,SSEandpa'erning
– Parameterizedonshortpep@des– Validatedonknownamyloidogenicpep@des
chains, such as charge,26–29 hydrophobicity,30–32
patterns of polar and non-polar residues,33 andthe propensities to adopt diverse secondary struc-ture elements.27,32,34,35 In the case of globularproteins, the propensities to form amyloid struc-tures are generally inversely related to the stabilityof their native states.24,36–42 Many of the proteinsassociated with amyloid diseases are, however, atleast partially unfolded under physiological con-ditions. In addition, it is thought that many globularproteins unfold, at least partially, before aggre-gating. The present study is therefore focused onthe conversion of unfolded or partially unfoldedstates into amyloid aggregates.
One of the most intriguing recent observations instudies of the kinetics of amyloid formation is thatpolypeptide sequences appear to contain localregions that are “sensitive” for aggregation.32 Singleamino acid mutations in these regions can changethe aggregation rates dramatically, while similarchanges in other regions may have relatively littleeffect.32,43 In addition, it has been shown that it ispossible to describe with considerable accuracy thein vitro amyloid aggregation propensities of poly-peptides using algorithms that take into account thephysico-chemical properties of their sequences andof their environment.44–48 Here, our purpose is toapply this type of analysis to the rationalisation andthe prediction of the sensitive regions of poly-peptide sequences in general and of proteinsassociated with neurodegenerative diseases inparticular.
Results
Definition of intrinsic aggregation propensities
We define the intrinsic propensity of an unfoldedpolypeptide chain to form amyloid aggregates, Pagg,by considering just the intrinsic factors in theformula that we have recently introduced to definethe absolute aggregation rates of unstructuredpolypeptide chains:45
Pagg Z ahydrIhydr CaaI
a CabIb CapatI
pat
CachIch (1)
where Ihydr represents the hydrophobicity of thesequence,49,50 Ia is the a-helical propensity,51 Ib isthe b-sheet propensity,51 Ipat is the hydrophobicpatterning,52 and Ich is the absolute value of the netcharge of the sequence; the coefficients a, whichweight the individual factors, were determined asdescribed and are listed in Table 1 (see Materialsand Methods).45 Since pH influences some of theseterms, such as Ihydr, Ia and Ich, it must be specifiedfor equation (1), and the hydrophobicity andsecondary structure propensities are normalisedfor the length of the polypeptide chain. The valuesthat we found for the coefficients indicate thathydrophobicity, the presence of specific
hydrophobic patterns and the propensity to formb-sheets favour aggregation; in contrast, the netcharge and the propensity to form a-helices reducethe tendency to aggregate. It has been suggestedthat aromatic residues may play an important rolein promoting aggregation,48,53 although otherstudies have indicated that their importance maybe limited.54 The systematic collection of exper-imental data relevant to this factor will allow its roleto be clarified.
Definition of intrinsic Z-scores for aggregation
The intrinsic Z-score for aggregation, Zagg,enables comparisons to be made between theaggregation propensities of different polypeptidesequences. It is calculated as:
Zagg ZPagg Kmagg
sagg(2)
where magg is the average value of Pagg over a set ofrandom polypeptides having the same length as thesequence of interest, and sagg is the correspondingstandard deviation from the average (see Materialsand Methods). If ZaggO0, the sequence is moreprone to aggregation than a randomly generatedsequence at that particular pH, while it is less proneif Zagg!0.
Intrinsic aggregation propensities of individualamino acids
The intrinsic propensities pagg of individualamino acids to promote the conversion of apolypeptide chain into amyloid aggregates can becalculated from equation (1) if one considers apolypeptide sequence of length 1. In this case, theterm describing the patterning of polar and non-polar residues, Ipat, does not contribute to theresulting pagg value. The aggregation propensityscale obtained in this way should be useful for aqualitative estimate of the effect of mutations on theaggregation behaviour of a given polypeptidechain, at least when hydrophobic patterns are notinvolved. The scales at three different values of pHare shown in Table 2, where the various amino acidsare listed in decreasing order of amyloid formationpropensity at neutral pH. At this pH, tryptophan,phenylalanine, cysteine, tyrosine, and isoleucinehave the highest amyloid propensities, while
Table 1. Coefficients of equation (1)
Parameter a p-value
Hydrophobicity K1.99G0.31 !0.001a K5.7G2.3 !0.001b 5.0G1.7 !0.001Charge K0.08G0.03 0.17Patterns 0.39G0.02 !0.001
The coefficients a used in equation (1). These values and thecorresponding statistical errors were derived as described.45
380 Sensitive Regions for Protein Aggregation
chains, such as charge,26–29 hydrophobicity,30–32
patterns of polar and non-polar residues,33 andthe propensities to adopt diverse secondary struc-ture elements.27,32,34,35 In the case of globularproteins, the propensities to form amyloid struc-tures are generally inversely related to the stabilityof their native states.24,36–42 Many of the proteinsassociated with amyloid diseases are, however, atleast partially unfolded under physiological con-ditions. In addition, it is thought that many globularproteins unfold, at least partially, before aggre-gating. The present study is therefore focused onthe conversion of unfolded or partially unfoldedstates into amyloid aggregates.
One of the most intriguing recent observations instudies of the kinetics of amyloid formation is thatpolypeptide sequences appear to contain localregions that are “sensitive” for aggregation.32 Singleamino acid mutations in these regions can changethe aggregation rates dramatically, while similarchanges in other regions may have relatively littleeffect.32,43 In addition, it has been shown that it ispossible to describe with considerable accuracy thein vitro amyloid aggregation propensities of poly-peptides using algorithms that take into account thephysico-chemical properties of their sequences andof their environment.44–48 Here, our purpose is toapply this type of analysis to the rationalisation andthe prediction of the sensitive regions of poly-peptide sequences in general and of proteinsassociated with neurodegenerative diseases inparticular.
Results
Definition of intrinsic aggregation propensities
We define the intrinsic propensity of an unfoldedpolypeptide chain to form amyloid aggregates, Pagg,by considering just the intrinsic factors in theformula that we have recently introduced to definethe absolute aggregation rates of unstructuredpolypeptide chains:45
Pagg Z ahydrIhydr CaaI
a CabIb CapatI
pat
CachIch (1)
where Ihydr represents the hydrophobicity of thesequence,49,50 Ia is the a-helical propensity,51 Ib isthe b-sheet propensity,51 Ipat is the hydrophobicpatterning,52 and Ich is the absolute value of the netcharge of the sequence; the coefficients a, whichweight the individual factors, were determined asdescribed and are listed in Table 1 (see Materialsand Methods).45 Since pH influences some of theseterms, such as Ihydr, Ia and Ich, it must be specifiedfor equation (1), and the hydrophobicity andsecondary structure propensities are normalisedfor the length of the polypeptide chain. The valuesthat we found for the coefficients indicate thathydrophobicity, the presence of specific
hydrophobic patterns and the propensity to formb-sheets favour aggregation; in contrast, the netcharge and the propensity to form a-helices reducethe tendency to aggregate. It has been suggestedthat aromatic residues may play an important rolein promoting aggregation,48,53 although otherstudies have indicated that their importance maybe limited.54 The systematic collection of exper-imental data relevant to this factor will allow its roleto be clarified.
Definition of intrinsic Z-scores for aggregation
The intrinsic Z-score for aggregation, Zagg,enables comparisons to be made between theaggregation propensities of different polypeptidesequences. It is calculated as:
Zagg ZPagg Kmagg
sagg(2)
where magg is the average value of Pagg over a set ofrandom polypeptides having the same length as thesequence of interest, and sagg is the correspondingstandard deviation from the average (see Materialsand Methods). If ZaggO0, the sequence is moreprone to aggregation than a randomly generatedsequence at that particular pH, while it is less proneif Zagg!0.
Intrinsic aggregation propensities of individualamino acids
The intrinsic propensities pagg of individualamino acids to promote the conversion of apolypeptide chain into amyloid aggregates can becalculated from equation (1) if one considers apolypeptide sequence of length 1. In this case, theterm describing the patterning of polar and non-polar residues, Ipat, does not contribute to theresulting pagg value. The aggregation propensityscale obtained in this way should be useful for aqualitative estimate of the effect of mutations on theaggregation behaviour of a given polypeptidechain, at least when hydrophobic patterns are notinvolved. The scales at three different values of pHare shown in Table 2, where the various amino acidsare listed in decreasing order of amyloid formationpropensity at neutral pH. At this pH, tryptophan,phenylalanine, cysteine, tyrosine, and isoleucinehave the highest amyloid propensities, while
Table 1. Coefficients of equation (1)
Parameter a p-value
Hydrophobicity K1.99G0.31 !0.001a K5.7G2.3 !0.001b 5.0G1.7 !0.001Charge K0.08G0.03 0.17Patterns 0.39G0.02 !0.001
The coefficients a used in equation (1). These values and thecorresponding statistical errors were derived as described.45
380 Sensitive Regions for Protein Aggregation
μagg=averagePaggonrandomsequenceσagg=stdevofPaggonrandomsequence

MethodologytoPredictAdnec8nSolubility1. FG-LoopmodelingusingPrimeandBioLuminate2. Calculateproteindescriptorswithlowestenergyloopstructureofeachmutant3. CreateQSARmodelwithAutoQSAR
• Learningsetwasall31compounds• Usedproteindescriptorsonly• Otherwiseemployeddefaultse�ngs
4. Create4-foldcrossvalidatedmodeltoaccountforsmalldatasetsize• Extractfourexternalvalida@onsetsfromnon-overlappingrandomsamples
of25%ofthedata• BuildAutoQSARmodelsfromeachoftheremaining75%ofthedata• UseeachofthefourAutoQSARmodelstomakepredic@onsonthe
correspondingexternalvalida@onset

ProteinDescriptors–Adnec8nBenchmark
0
10
20
30
40
50
60
70
80
0 10 20 30 40 50 60 70 80
Pred
icted
Observed(Y)
Adnec8n4-FoldCrossValida8on
Q2=0.66RMSE=10.76
Predic8onsfromotherapproaches• Computa@onallyexpensive
loopsamplingmethodR2=0.61
• Zyggregatorsequence-basedaggrega@onpredic@onmethodR2=0.63
• Linearcombina@onofZyggregatorandloopsamplingR2=0.8

Integra8ngAutoQSARintoExis8ngITInfrastructure
• ToapplyanAutoQSARmodelonlya1D,2D,or3DstructureandanAutoQSARmodelarerequired– Noknowledgeofthemodelordescriptorsusedrequiredwithdefaultdescriptors
• Benefitfromimprovedpredic@vepoweroverthecourseofaprojectbyautoma@callyupda@ngQSARmodelsperiodically

EasilyIntegrateAutoQSARintoAutomatedWorkflows
AutoQSAR

AutoQSARinLiveDesign
RunningAutoQSARtotestnewcompoundsisaone-clickopera@on

AutoQSARinLiveDesign
Onceclicked,thecalcula@onsrunonallmoleculesinthereport,andresults
arereturnedasanewcolumn

AutoQSARinLiveDesign
Whennewcompoundsaresketched,AutoQSARisruninreal-@metooffer
instantfeedbackonideas

AutoQSARinLiveDesign
Whenthenewideaisaddedtothereport,thecalculatedresultisstored.

FutureDirec8ons–Interpre8ngAutoQSARModels• InterpretabilityishighlydesiredinanyQSARmodel– Atom/group-basedprojec@on– Interpretcoefficientvalues,RPtrees,etc.
• KPLSmodelsemployingfingerprintsareinterpretableinCanvasbutnoteasytovisualizeAutoQSARmodelsinCanvas
• Inves@ga@ngamodetogenerateandvisualizeinterpretableQSARmodelsinAutoQSAR

Conclusions• AutoQSARgenerateshigh-quality,predic@veQSARmodelsonparwithpublishedmodelsforawidevarietyofproper@esofinterest
• CreateandvalidateQSARmodelsfarmorequicklythenmanualcrea@on
• GenerateandemployQSARmodelswithconfidence• Save@meiden@fyingapproachesmost/leastlikelytobesuccessfulbeforemanualQSARmodeling