automatická s umarizace text ů
DESCRIPTION
Automatická s umarizace text ů. Motivace. P očet uživatelů Internetu 2, 2 miliardy - prosinec 2011, nárůst z 360 milionů v r. 2000. Počet webových stránek 7,51 miliardy (web pages ) - březen 2012 , Počet webových míst 550 milion ů (web sites ) - prosinec 2011. 2. - PowerPoint PPT PresentationTRANSCRIPT

Automatická sumarizace textů
1

MotivacePočet uživatelů Internetu 2,2 miliardy -prosinec 2011, nárůst z 360 milionů v r. 2000. Počet webových stránek 7,51 miliardy (web pages) -březen 2012, Počet webových míst 550 milionů (web sites) -prosinec 2011.
2

Text & Web Mining (information retrieval)
Web content mining (analýza obsahu)• Vyhledávání textů (dokumentů)• Filtrace textů• Klasifikace textů• Shlukování textů• Sumarizace textůWeb structure mining (analýza topologie, využití
linked data)Web usage mining (analýza logů, využití údajů o
přístupech)

Obsah
• ÚvodTaxonomie sumarizačních metodKlasické a pokročilé sumarizační metody
• Vlastní výsledky Naše metoda použití LSA pro sumarizaciVícedokumentová sumarizaceAktualizační sumarizaceDalší řešené sumarizační úlohy
4

5
Typy souhrnů a sumarizačních metod• Podle formy výsledku:
– Extrakty – Abstrakty
• Podle úrovně zpracování:– Povrchní (používají povrchní vlastnosti, např. termy významné
pozičně, frekvenčně, doménově, z dotazu).– Hlubší (používají syntaktické či tezaurové relace, rétorickou
strukturu apod.) • Podle účelu:
– Indikativní (mají umožnit rozhodnutí, zda dokument stojí za to číst, délka do 10% originálu, součást vyhledávačů).
– Informativní (20-30% originálu, nahrazují čtení plného textu zběžným seznámením s tématem).
– Hodnotící (kritiky, recenze, posudky – nejsou automaticky generované).
• . . .

Klasické sumarizační metody - HeuristickéLuhn: The Automatic Creation of Literature Abstracts. In IBM Journal of Research and Development. 1958
významný term t : tf(t) * idf(t) > threshold
1. Najdi významné termy (klíčová slova).
2. Vypočti váhy vět na základě v nich obsažených klíčových slov.
3. Požadovaný počet vět s největšími váhami představují výsledek sumarizace.
6
Inverse document frequency(důležité termy se ale nesmí
vyskytovat ve většině dokumentů)
term frequency (důležité termy se vyskytují
v dokumentu častěji)

Klasické sumarizační metody - HeuristickéEdmundson : New Methods in Automatic Extraction. In Journal of the ACM, 1969
Důležité informace:1. Vyskytují se ve specifických pozicích (začátek, konec),2. Vyskytují se ve specifických odstavcích textu (název, úvod,
závěr),3. Jsou indikovány zdůrazňujícími slovy (hlavní, důležitý,
výsledek, cíl, …),4. Jsou indikovány klíčovými slovy.
Kombinace vlastností 1-4 určuje důležitost (váhu) věty s.
Weigh(s) = a*Title(s)+b*Cue(s)+c*Keyword(s)+d*Position(s)
7

Klasické sumarizační metody - StatistickéBayesův klasifikátor (?zařadit větu s do souhrnu S: ano/ne)
P(F1,F2,…,Fn|sS) P(sS)P(sS|F1,F2,…,Fn) =
P(F1,…,Fn) za předpokladu nezávislosti příznaků Fi (Kupiec at all 1995)
j=1…n P(Fj|sS) P(sS ) P(sS|F1,F2,…,Fn)≈
j=1…n P(Fj)P(sS|F1,F2,…,Fn) pravděpodobnost, že věta s je v souhrnu S při
daných příznacích .
P(sS) pravděpodobnost, že věta s je v souhrnu S nepodmíněně
P(Fj|sS) pravděpodobnost hodnoty příznaku Fj ve větě souhrnu
P(Fj) pravděpodobnost hodnoty příznaku Fj nepodmíněně
8

9
Klasické sumarizační metody – Statistické (příklad)Máme 1000 trénovacích vět a manuální 20% extrakt. Ze statistik příznaků zjistíme:Příznak F1 výskyt v 10% (100 s.) P(F1)=0.1 P(notF1)=0.9 -“- F2 -“- 10% (100 s.) P(F2)=0.1 P(notF2)=0.9 -“- F3 -“- 20% (200 s ) P(F3)=0.2 P(notF3)=0.8
P(F1|sS)=0.4 (tj 80 z 200) P(F2|sS)=0.25 (tj. 50 z 200)P(F3|sS)=0.5 (tj.100 z 200)P(F1|sS)=0.025 (tj. 20 z 800) P(F2|sS)=0.0625 (tj. 50 z 800)P(F3|sS)=0.125 (tj.100 z 800)
P(notF1|sS)=0.6 (tj. 120 z 200)P(notF2|sS)=0.75 (tj. 150 z 200)P(notF3|sS)=0.5 (tj. 100 z 200)P(notF1|sS)=0.975 (tj. 780 z 800)P(notF2|sS)=0.9375 (tj. 750 z 800)P(notF3|sS)=0.875 (tj.700 z 800)
P(sS) je konstanta k, tzn pro 20% extract je 0.2, lze ji pominout

10
Klasické sumarizační metody – Statistické (příklad)
Mějme 4 věty textu s1,s2,s3,s4. Pro sumarizaci spočteme P(sS|F1,F2,F3)
Bude-li v s1: F1=yes, F2=yes, F3=yes
P(s1S|F1=yes,F2=yes,F3=yes)=k*.4*.25*.5/.1/.1/.2=
= k* 25P(s1S|F1=yes,F2=yes,F3=yes)=(1-
k)* .025*.0625*.125/.1/.1/.2 = (1-k)*0.0976562
Bude-li v s2: F1=no, F2=no, F3=no
P(s2S|F1=no,F2=no,F3=no)= k* .6*.75*.5/.9/.9/.8 = =k*0.34687
P(s2S|F1=no,F2=no,F3=no) = (1-k)* .975*.9375*.875 /.9/.9/.8 = (1-k)* 1.123

11
Klasické sumarizační metody – Statistické (příklad)Bude-li v s3: F1=yes, F2=no, F3=no
P(s3S|F1=yes,F2=no,F3=no) = k* .4*.75*.5 /.1/.9/.8= k* 2.08
Bude-li v s4: F1=yes, F2=yes, F3=no
P(s4S|F1=yes,F2=yes,F3=no) = k* .4*.25*.5 /.1/.1/.8= k* 6.25
Do souhrnu bychom zařazovali věty s největší podmíněnou pravděpodobností . Tzn v pořadí:
s1, pro25% souhrn 50% souhrns4, 75% souhrns3, s2

Pokročilé sumarizační metody - grafové
12
Vychází z metody hodnocení důležitosti web stránekDůležitá stránka - vede k ní mnoho odkazů,
- odkazují na ní vysoce ohodnocené stránky
NechťPR(u) je hodnocení (rank) webové stránky u, Fu je množina stránek, na které stránka u odkazuje a Bu je množina stránek, které odkazují na u, Nu = Fu je počet odkazů z uc je konstanta používaná pro normalizaci, zajištující konstantní součet ohodnocení všech stránek

Pokročilé sumarizační metody - grafovéPageRankG = (V, E) je orientovaný grafV je množina vrcholů Vi , i = 1..N
E je podmnožinou VxVPočítá PageRank skóre (významnost) uzlů:
d je faktor tlumeníIn(Vi) je množinou vrcholů, ze kterých vede větev do Vi
Out(Vi) je množina vrcholů do nichž vede větev z Vi
)( )(
)(*/)1()(
ij VInV j
ji
VOut
VPRdNdVPR
13

Pokročilé sumarizační metody - grafové
• Vrcholy grafu reprezentují věty textu,• Větve reprezentují vazby mezi větami
– Jsou neorientované– Jsou ohodnocené mírou svázanosti vět wij
• Spočítá se PR skóre vět:
• Věty s nejvyšším PR jsou vybrány do souhrnu.
)(
)(
)(*/)1()(
ij
jk
jk
ji
VInVVOutV
ji
w
VPRwdNdVPR
14

Pokročilé sumarizační metody - grafové
K ohodnocení větví mírou podobnosti vět používají:
buď– Počet společných (příbuzných) slov ve větách,
nebo– Kosinové podobnosti vět X a Y v prostoru slov
V prostoru slov lze každou větu (nebo i celý dokument) reprezentovat vektorem a jejich podobnost měřit cosinem.
15
2*
2
*),cos(
ii
ii
ii
yx
yxYX

0,17 0,17
0,47 věta3
věta1 věta2
voyage
Armstrong
cosmonaut
věta1 věta2 věta3 dfi idfi=log(počet_vět/dfi)term tf1.věta tf2.věta tf3.věta
cosmonaut 0 0 1 1 0,47Armstrong 0 1 1 2 0,17voyage 1 1 0 2 0,17

Latentní sémantická analýza• LSA
– dovoluje analyzovat vztahy mezi termy a částmi textů pomocí algebraické metody singulární dekompozice (SVD),
– na základě kontextu nalezne skryté dimenze sémantické reprezentace termů, vět a dokumentů,
– umožňuje redukovat data jejich zobrazením v prostoru vhodnějších dimenzí,
– LSA je použitelné pro vyhledávání, klasifikaci, shlukování i sumarizaci dokumentů.
Princip SVD rozkladu probereme nejprve pro sumarizaci jednoho dokumentu.
17
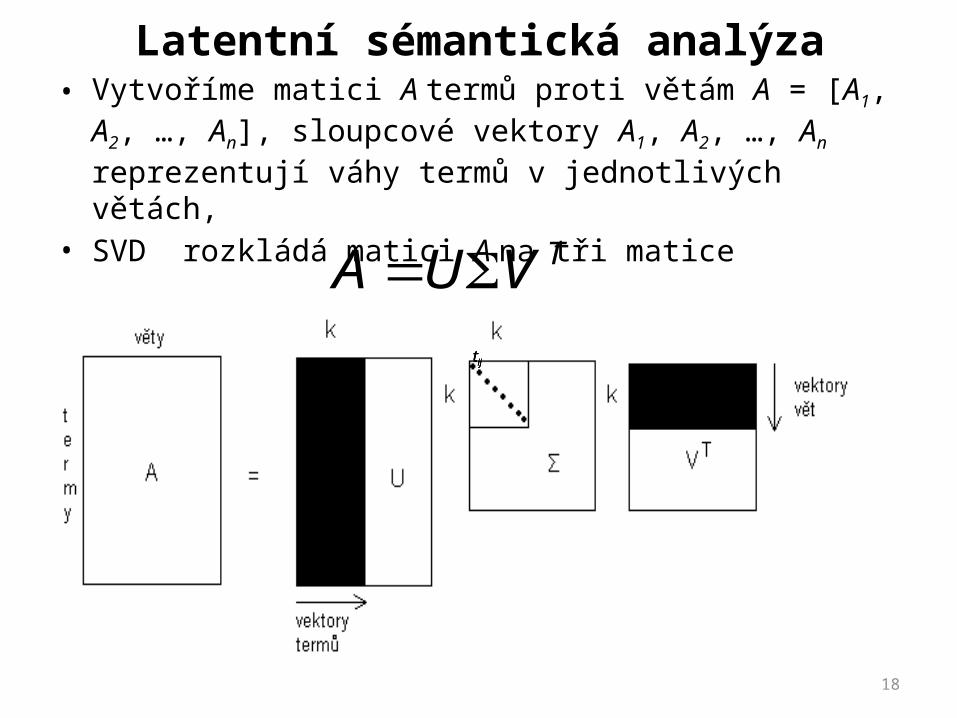
Latentní sémantická analýza• Vytvoříme matici A termů proti větám A = [A1, A2, …, An],
sloupcové vektory A1, A2, …, An reprezentují váhy termů v jednotlivých větách,
• SVD rozkládá matici A na tři matice
TVUA ijtijtijt
18

Latentní sémantická analýza
• LSA najde nejlepší k-rozměrnou aproximaci matice A, kde k<nSlovo1 Slovo2 Slovo3 . . . Slovo n
koncept1 koncept2 . . . koncept k• Vytvoří nové dimenze reprezentující témata (koncepty)
dokumentu kombinací původních dimenzí.• Redukovaná matice U mapuje termy do k nejvýznamnějších
témat.• Redukovaná matice VT mapuje věty do k nejvýznamnějších
témat. Udává významnost vět v tématech.• Důležitost tématu je určena odpovídající singulární hodnotou,
platí: σ1> σ2 >…> σn > 0 a klesá s jejím kvadrátem.• Lze inkrementálně spočítat jen k nejdůležitějších dimenzí.
19

Latentní sémantická analýza a sumarizace• Gong&Liu postup: Pro j=1,2,…, délka souhrnu provádí
– Při hledání j-té věty souhrnu vybere j-tý pravý singulární vektor z VT , tj. [vj1, vj2, …, vjk]T.
– Do souhrnu dá větu i s největší indexovou hodnotou vji . • Nevýhodou je považování všech témat za stejně důležitáNáš nápad:• Rozdílnost důležitosti témat indikuje matice Σ.• Vylepšit souhrn zařazením vět, jejichž vektorová
reprezentace v matici součinu Σ a VT má největší délku vektoru dr .
Důležité téma pak může býtzastoupeno více větami
k
iirir vd
1
22 *
20

Latentní sémantická analýzaHlavní publikace:• Two Uses of Anaphora Resolution in Summarization. Information
Processing & Management , Elsevier Ltd, Vol.43, Issue 6, November 2007, pp. 1669-1680, ISSN 0306-4573 (13 citací).
• Text Summarization and Singular Value Decomposition. ADVIS 2005, Lecture Notes in Comp.Sc.2457 pp.245-254, Springer-Verlag 2004, ISSN 0302-9743 (7 citací)
• Using Latent Semantic Analysis in Text Summarization and Summary evaluation, Proc. of 7th International Conference ISIM 04, pp. 93-100, ISBN 80-85988-99-2 (13 citací).
Použití LSA pro hodnocení kvality souhrnů publikováno v:• Evaluation Measures for Text Summarization. In Computing and
Informatics, volume 28, number 2, pages 251-275, Slovak Academy of Sciences, ISSN 1335-9150, 2009.
• Text Summarization: An Old Challenge and New Approaches. In Foundations of Computational Intelligence Vol.6, pages 127- 149, Data Mining Book Series, Springer, ISSN 1860-949X, 2009
21

Vícedokumentová sumarizace• Vytváří souhrn z kolekce dokumentů C = {D1, D2, … , Dd}, obvykle
pojednávajících o stejném tématu.• Pracujeme se všemi větami i termy dokumentů.
Nový problém:• Dokumenty obsahují velmi podobné věty s redundantní informací.
Postup řešení:1. Ohodnotíme věty LSA skórem vhodnosti (lze i jinou metodou),2. Před jejím zařazením do souhrnu ověříme, zda již neobsahuje podobnou větu.
Např. nepřesahuje práh kosinové podobnosti v prostoru témat
Publikace:Web Topic Summarization, Proceedings of the 12th International Conference on Electronic Publishing, ISBN 978-0-7727-6315-0, pp 322-334, Toronto, Canada 2008.
2*
2
*),cos(
ii
ii
ii
yx
yxYX
22

Aktualizační sumarizace
• Uživatel má předchozí znalosti z kolekce dokumentů Cold
• Uživatel chce být seznámen s dokumenty z kolekce Cnew.
• Nechce informace z Cnew, které již byly obsaženy v Cold .
Náš postup: Z Cold a Cnew vytvoříme matice Anew a Aold , na kterých
provedeme separátně SVD . Získáme redukované matice Unew a Uold . Jejich sloupce
představují k témat množin dokumentů vyjádřené v lineárních kombinacích termů.
Pro každé „nové“ téma t, (t je index sloupce matice Unew), vyhledáme nejpodobnější staré téma (sloupec matice Uold).
23

Aktualizační sumarizace
Kosinová podobnost těchto vektorů udává míru redundance red(t) nového tématu t.
Kde k je počet témat v redukovaném prostoru sloupců Uold Novost tématu t počítáme vztahem 1 – red(t) , Zohledníme důležitost jednotlivých témat t v aktualizačním
skóre:us(t) = σ(t)*(1- red(t))
Z vypočtených skóre sestavíme diagonální matici US, Vynásobením US .Vnew
T dostaneme matici F, která v sobě agreguje novost i důležitost nových témat ve větách.
2
1
2
1
1
1],[*],[
],[*],[max)(
m
j new
m
j old
new
m
j oldk
itjUijU
tjUijUtred
24

Aktualizační sumarizace
První dáme do souhrnu větu, která má nejdelší vektor fbest v matici F,
Odečteme informaci z fbest od ostatních sloupců matice F, tj. přepočteme F dle vzorce:
Proces zařazování do souhrnu probíhá iteračně, až do získání potřebné délky souhrnu.
Výsledky:náš LSA sumarizátor v TAC soutěži: r.2008 9.místo z 58, r.2009 2.místo z 52Update Summarization Based on Novel Topic Distribution. Proceedings of the
ACM Symposium on Document Engineering, Munich, Germany, 2009. Update Summarization Based on Latent Semantic Analysis. Proceedings of 12th
International Conference, TSD 2009, LNAI 5729, Springer-Verlag Berlin Heidelberg New York, ISSN 0302-9743, 2009.
25
bestjj fFF 1
bestjj fFF 1

Další aktuální sumarizační úlohy
• Multijazyková sumarizace Účast na přípravě a vyhodnocení TAC 2011 10 témat po 10 článcích v 7 jazycích.
• Komparativní sumarizace – cílem je souhrnně informovat o rozdílech v jednotlivých dokumentech,(odlišnosti hlavních témat – probíhá výzkum formou PhD).
• Cílená sumarizace – ke vstupním datům je přidána informace o uživatelově zájmu (dotazem/tématem). Do výsledku přednostně zařazuje věty, jejichž téma odpovídá přidávané informaci.
• Sumarizace mínění – zpracovává dokumenty obsahující mínění o entitě a vytváří průměrný názor.
26

Další probíhající a přípravované úlohy z oblasti extrakce informací z textů
• Získávání znalostí pro personalisty integrováním informací z webových zdrojů (F solutions, s.r.o. Praha a TextKernel NL).
• Porovnávání náplně výukových kurzů na amerických univerzitách a jejich řazení na základě požadavku klienta (Owen Software USA ).
• Pre-seed projekt: Získávání informací z textů.
Stránky výzkumné skupiny: http://www.textmining.zcu.cz/
27

Děkuji za pozornost
28

Hodnocení kvality sumarizátorů • Přímé metody
– Porovnání lingvistické kvality (ručně)• Gramatická správnost• Neredundantnost• Struktura, souvislost, srozumitelnost
– Porovnání obsahu textu s ideálním souhrnem• Ko-selekční přístupy• Podobnostní míry
• Nepřímé metody– Kategorizace dokumentů– Vyhledávání informací– Zodpovídání dotazů
29

Hodnocení kvality sumarizátorů – přímé metody•
30

Hodnocení kvality sumarizátorů – přímé metodyPodobnostní míry - Také základ v IR ale použitelné k porovnání jak s ideálním
standardem tak s originálem• Kosinová podobnost v prostoru slov s využitím tf-idf vah.• Kosinová podobnost v latentním prostoru témat. Po SVD hledá
– Podobnost hlavního tématu = kosinus uhlu mezi jejich prvými levými singulárními vektory souhrnu i originálu jsou normalizované
– Podobnost n hlavních témat. Pro souhrn i originál po SVD spočteme a
Pro každý řádkový vektor matice BS (resp BO) spočteme jeho délku dkS (dkO). Ta odpovídá důležitosti k-ho termu v latentním
prostoru.Z délek dkS, dkO vytvoříme vektory dS dO.
Kosinus jejich úhlu je mírou kvality souhrnu.
m
iii usuo *)cos(
2ooo UB 2
sss UB
n
ikik bd
1
2
31

Hodnocení kvality sumarizátorů – přímé metody•ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
automatická, založena na podobnosti n-gramůvýpočet skóre
RSS - referenční souhrny od anotátorů je počet n-gramů v referenčním souhrnu je maximální počet n-gramů, které se společně
vyskytují jak v hodnoceném, tak i v referenčním souhrnu
• PyramidsSemi-automatická metoda založená na tzv. sumarizačních jednotkách SCU.
SCU (věty nebo fráze) to jsou části souhrnů tvořených anotátory SCU které jsou v více souhrnech se přiřadí vyšší váha, vzniká SCU pyramida V hodnoceném souhrnu se hledají shody s SCU a sčítají se jejich váhy.
RSSC Cgram n
RSSC Cgram nspolu
n
n
gramPocet
gramPocetnROUGE
ngramPocet
nspolu gramPocet
32

Hodnocení kvality sumarizátorů – nepřímé metodyKriteriem je uplatnění souhrnu ve zvolené úloze• Kvalita vyhledávání na souhrnech versus na plných textech
1. Vyhledávači se zadá stejný dotaz jak nad kolekcí souhrnů S tak kolekcí plnotextovou D. Pak seřadí výsledky podle jejich relevance.
2. K porovnání pořadí lze použít např. Kendall’s tau nebo Spearman’s rank correlation. Také lze využít údaj o relevanci z vyhledávačea spočítat korelaci relevance
Kde xi je relevance dokumentu Di ϵ D k dotazu Q,
yi je relevance souhrnného dokumentu Si ϵ S k dotazu Q.
a je průměrná relevance dokumentů z D (resp. z S) k dotazu Q.
• Kvalita kategorizace podle souhrnů namísto plných textůMírou kvality je přesnost a úplnost či F-skóre zatřídění souhrnů do tříd proti známému správnému zatřídění původních textů
ii
ii
iii
yyxx
yyxxRC
22 )()(
))((
x y
33

Latentní sémantická analýza - poznámkyPokud dokument obsahuje m termů a n vět je matice A o rozměru
m × nU = [uij] je m × n sloupcově ortonormální matice, jejíž sloupce se
nazývají levé singulární vektoryΣ = diag(σ1, σ2, …,σn) je n × n diagonální matice, jejíž diagonální
prvky jsou nezáporné singulární hodnoty seřazené sestupně V = [vij] je n × n ortonormální matice, jejíž sloupce se nazývají pravé
singulární vektory Rozměr matic je redukován na k dimenzí, kde k < n, takže U je
redukována na m×k, Σ na k×k a VT k×nPozn. ortonormální matice má všechny sloupcové vektory délky 1 a navzájem
kolmé. Σ 2 je matice vlastních hodnot matice AA T a také A TA. Sloupce U jsou
vlastními vektory AA T a sloupce V jsou vlastními vektory A TA .
34

35
Latentní sémantická analýza
term v1 v2 v3 v4 v5 v6cosmonaut 1 0 1 0 0 0Armstrong 0 1 1 0 0 0voyage 1 1 0 0 1 0moon 1 0 0 1 1 0track 0 0 0 1 1 1
Matice A:
Latentní prostor redukovaný na 2 dimenze:
dim1
dim2
v1
v2
v5
v4
v3
v6
cosmonaut Armstrongvoyage
moon
track

Latentní sémantická analýza a sumarizace
Další možnosti modifikace výběru vět do souhrnu s použitím LSA: Pracovat jen se singul. čísly, která jsou větší než zvolený zlomek σ1
Zařadit počty vět na základě procentního podílu singulárního čísla k součtu singulárních čísel.
Kombinace grafové a LSA sumarizační metody:1. Zkonstruuj matici A (slova proti větám)2. Proveď SVD faktorizaci matice A3. Redukuj rozměr matic U,Σ,V na U’Σ’V’4. Rekonstruuj odpovídající matici A’=U’Σ’V’T . Její sloupce
představují sémanticky reprezentované věty5. Z takto reprezentovaných vět vytvoř graf, který zachycuje strukturu
textu obdobně jako graf vytvořený z vět vyjádřených na bázi frekvence termů.
6. Na graf aplikuj ranking algoritmus 7. Do výsledku zařaď věty odpovídající nejvýše ohodnoceným uzlům
36