automatically tuning parallel and parallelized programseigenman/app/cetus-autotuning.pdf ·...
TRANSCRIPT

AUTOMATICALLY TUNING PARALLEL AND PARALLELIZED
PROGRAMS Chirag Dave and Rudolf
Eigenmann Purdue University

GOALS • Automatic parallelization without loss of
performance – Use automatic detection of parallelism – Parallelization is overzealous – Remove overhead-inducing parallelism – Ensure no performance loss over original
program • Generic tuning framework
– Empirical approach – Use program execution to measure benefits – Offline tuning

AUTO Vs. MANUAL PARALLELIZATION
Source Program Hand
parallelized
Parallelizing Compiler
Parallel Program
Significant development time
State-of-the-art auto-parallelization in the
order of minutes
User tunes the program for performance

AUTO-PARALLELISM OVERHEAD int foo() { #pragma omp private(i,j,t) for (i=0; i<10; i++) { a[i] = c; #pragma omp private(j,t) #pragma omp parallel for (j=0; j<10; j++) { t = a[i-1]; b[j] = (t*b[j])/2.0; } } }
fork
join Fork/Join overheads Load balancing Work in parallel
section
Loop level parallelism

NEED FOR AUTOMATIC TUNING
• Identify, at compile time, the optimization strategy for maximum performance
• Beneficial parallelism – Which loops to parallelize – Parallel loop coverage

OUR APPROACH
Best combination of loops to parallelize Offline tuning
Decisions based on actual execution time

CETUS: VERSION GENERATION
Cetus Version
Generator
Symbolic Data
Dependence Analysis
Induction Variable
Substitution
Scalar and Array
Privatization
Reduction Recognition

SEARCH SPACE NAVIGATION • Search Space -> The set of parallelizable loops
• Generic Tuning Algorithm – Capture Interaction – Use program execution time as decision metric
• COMBINED ELIMINATION – Each loop is an on/off optimization – Selective parallelization
• Pan, Z., Eigenmann, R.: Fast and effective orchestration of compiler optimizations for automatic performance tuning. In: The 4th Annual International Symposium on Code Generation and Optimization (CGO). (March 2006) 319–330

TUNING ALGORITHM BATCH ELIMINATION ITERATIVE ELIMINATION
COMBINED ELIMINATION
- Considers separately, the effects of each
optimization - Instant elimination
-Considers interactions -More tuning time
New Base Case
- Considers interactions amongst a subset - Iterates over the smaller subset and performs batch elimination

CETUNE INTERFACE int foo() { #pragma cetus parallel… for (i=0; i<50; i++) { t = a[i]; a[i+50] = t + (a[i+50] + b[i])/2.0; }
for (i=0; i<10; i++) { a[i] = c; #pragma cetus parallel… for (j=0; j<10; j++) { t = a[i-1]; b[j] = (t*b[j])/2.0; } } }
cetus –ompGen –tune-ompGen=“1,1” Parallelize both loops
cetus –ompGen –tune-ompGen=“1,0” cetus –ompGen –tune-ompGen=“0,1” Parallelize one and serialize the other
cetus –ompGen –tune-ompGen=“0,0” Serialize both loops
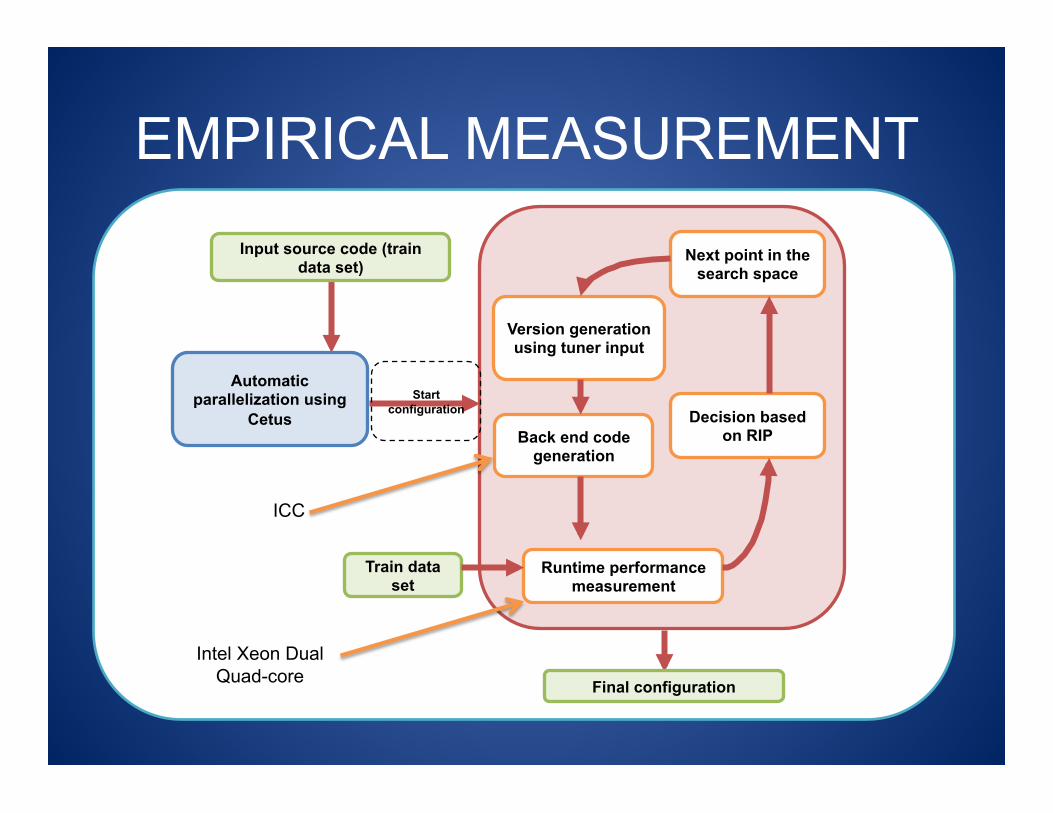
EMPIRICAL MEASUREMENT Input source code (train
data set)
Version generation using tuner input
Back end code generation
Runtime performance measurement
Train data set
Decision based on RIP
Next point in the search space
Automatic parallelization using
Cetus Start
configuration
Final configuration
ICC
Intel Xeon Dual Quad-core

RESULTS

RESULTS

RESULTS

CONTRIBUTIONS • Described a compiler + empirical system that detects parallel
loops in serial and parallel programs and selects the combination of parallel loops that gives highest performance
• Finding profitable parallelism can be done using a generic tuning method
• The method can be applied on a section-by-section basis, thus allowing fine-grained tuning of program sections
• Using a set of NAS and OMP 2001 benchmarks, we show that the auto-parallelized and tuned version near-equals or improves performance over the original serial or parallel program

THANK YOU!