arm tools and roadmap for sve compiler support
TRANSCRIPT

©2017ArmLimited
RichardSandifordFlorianHahn
ArmtoolsandroadmapforSVEcompilersupport
ArmHPCWorkshopTokyo2017

©2017ArmLimited2
ToolsandlibrariesforHPConArmv8-AandSVE
SVEsupportforLinux,GLIBC,GDB,etc. Allows runningGNU/LinuxonanSVEsystem
SVEsupportforGCC Systemcompiler forGNU/Linuxsystems
SVEsupportforLLVM/ClangClangisawidely-usedopen-sourcecompiler,andLLVMisnowusedasalibraryinseveralopen-sourceprojects
Arm Allinea Studio Fully-supportedcommercial HPCsuitefortheArmv8-Aarchitecture,includingSVE
ArmInstructionEmulator Allowsuserstoevaluate SVEcode usingexistingArmv8-Ahardware
Commercial
Open-source
©2017ArmLimited3
ArmAllineaStudioAquickglanceatwhatisinArmAllineaStudio
C/C++Compiler• C++14support• OpenMP 4.5withoutoffloading
• SVEready
FortranCompiler• Fortran2003support• PartialFortran2008support
• OpenMP3.1• SVEready
PerformanceLibraries• Optimizedmathlibraries• BLAS,LAPACKandFFT• ThreadedparallelismwithOpenMP
Forge(DDTandMAP)• Profile,TuneandDebug• ScalabledebuggingwithDDT
• ParallelProfilingwithMAP
PerformanceReports• Analyzeyourapplication•Memory,MPI,Threads,I/O,CPUmetrics
TunedbyArmforawide-rangeofserver-classArm-basedplatforms

©2017ArmLimited
SVE

©2017ArmLimited5
IntroducingtheScalableVectorExtension(SVE)AvectorextensiontotheArmv8-Aarchitecturewithsomemajornewfeatures:
Gather-loadandscatter-storeLoadsasingleregisterfromseveralnon-contiguousmemorylocations
Per-lanepredicationOperationsworkonindividuallanesundercontrolofapredicateregister
Predicate-drivenloopcontrolandmanagementEliminatescalarloopheadsandtailsbyprocessingpartialvectors
Vectorpartitioningandsoftware-managedspeculationFirstFaultingLoadinstructionsallowmemoryaccessestocrossintoinvalidpages
NopreferredvectorlengthTheabovefeaturesallowtheproductionofcompiledbinariesthatareagnostictohardwarevectorlength(whichcanbebetween128-2048bitat128bitincrements)
1 2 3 45 5 5 51 0 1 0
6 2 8 4
+
=pred
1 2 0 01 1 0 0
+pred
1 2
n-21 01 0CMPLT n
n-1 n n+1INDEX i
for (i = 0; i < n; ++i)
1 2 3 4 5 6

©2017ArmLimited6
GNU/LinuxsupportforSVEKernelandcoreuserspacecomponents
• LinuxhostOSanduserspace supportmergedforv4.15Details:linux/Documentation/arm64/sve.txt
• Vectorlengthselectableperusertask(upto2048bits,subjecttohardwaresupport)
• Self-hosteddebugandintrospectionsupportedviaptrace
• SupportforSVEinKVMguestscurrentlyunderdiscussionRFCposted,notyetmerged
Linux• SVEsupportcurrentlybeing
upstreamed,expectedtobecommittedinQ12018
• Supportsbothself-hosteddebugandremotedebugging
GDB GNUbinutils
GLIBC• NewGLIBCnotneededtorunSVE
code
• HeaderfilesneedupdatingfornewLinuxuserspace interfaces(minorchange)
[email protected] [email protected] fordetails [email protected] fordetails
libgcc unwinder
• NeededtounwindthroughframesthatspillSVEregisters
• PatchapprovedforGCC8(dueforreleaseinQ22018)
• SVEsupportcommittedinQ32016
• AvailableinGNUbinutils 2.28andlater

©2017ArmLimited7
2018 2019
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May
LLVMandGCCupstreamingroadmap
1980LLVM6.0
InitialSVEAutovec support
PartialSVEMCsupport
SVEMCsupport
Codegen VectorizedIR
FullSVEAutovec support
1980LLVM7.0 1980LLVM8.0
1980GCC8 1980GCC9
FullSVEintrinsicssupport
AutomaticSVEvectorisation
DeadlinefornewGCC9features
LLVM
GCC

©2017ArmLimited
GCC
©2017ArmLimited9
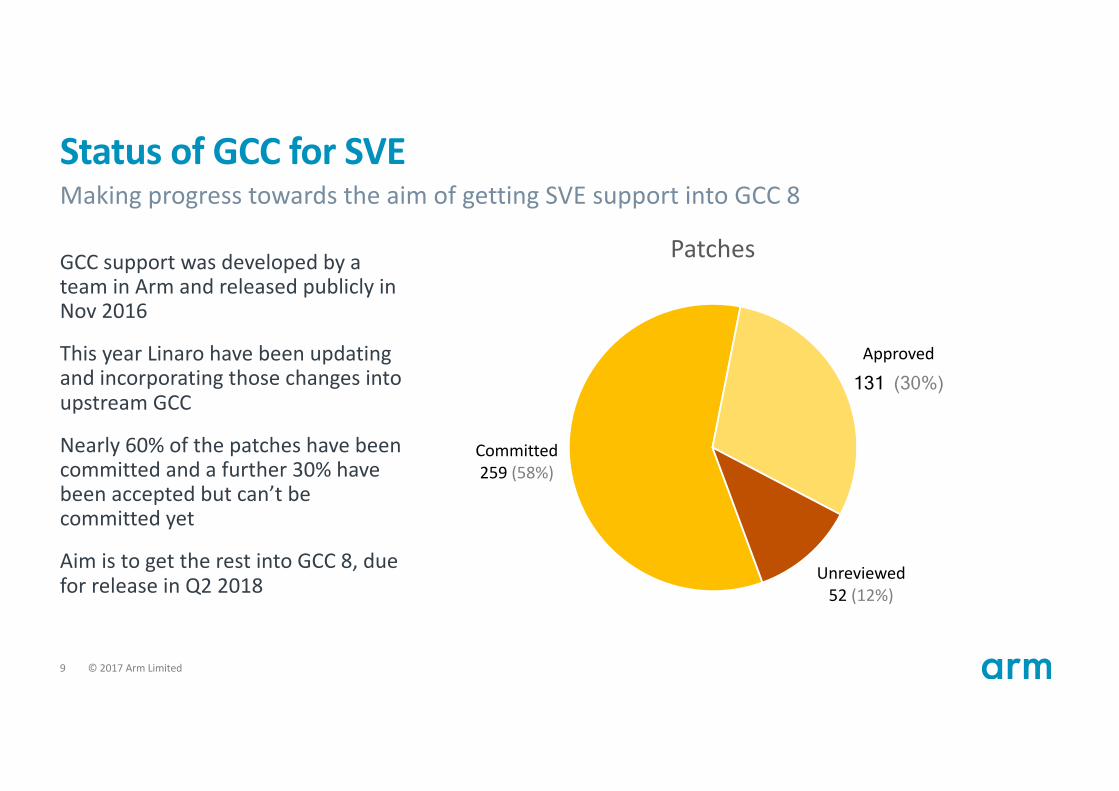
StatusofGCCforSVE
GCCsupportwasdevelopedbyateaminArmandreleasedpubliclyinNov2016
ThisyearLinaro havebeenupdatingandincorporatingthosechangesintoupstreamGCC
Nearly60%ofthepatcheshavebeencommittedandafurther30%havebeenacceptedbutcan’tbecommittedyet
AimistogettherestintoGCC8,dueforreleaseinQ22018
Committed259 (58%)
Approved
131 (30%)
Unreviewed52 (12%)
Patches
MakingprogresstowardstheaimofgettingSVEsupportintoGCC8
©2017ArmLimited10
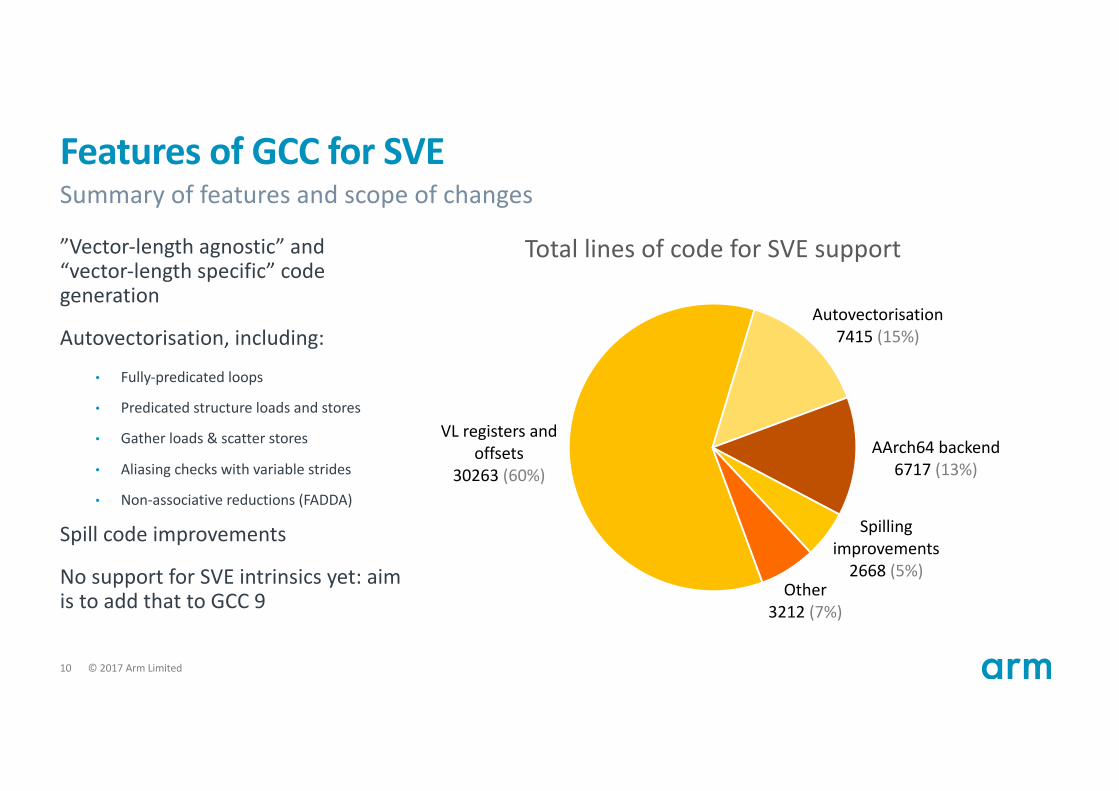
FeaturesofGCCforSVE
”Vector-lengthagnostic”and“vector-lengthspecific”codegeneration
Autovectorisation,including:
• Fully-predicatedloops
• Predicatedstructureloadsandstores
• Gatherloads&scatterstores
• Aliasingcheckswithvariablestrides
• Non-associativereductions(FADDA)
Spillcodeimprovements
NosupportforSVEintrinsics yet:aimistoaddthattoGCC9
VLregistersandoffsets
30263 (60%)
Autovectorisation7415 (15%)
AArch64backend6717 (13%)
Spillingimprovements2668 (5%)
Other3212 (7%)
TotallinesofcodeforSVEsupport
Summaryoffeaturesandscopeofchanges

©2017ArmLimited11
ComparisonofGCCoutput:scalarcodevs.WHILE-basedSVEcode
daxpy:cbz x0, .L1mov x3, 0
.p2align 3.L3:
ldr d1, [x1, x3, lsl 3]ldr d2, [x2, x3, lsl 3]fmadd d1, d1, d0, d2str d1, [x2, x3, lsl 3]add x3, x3, 1cmp x0, x3bne .L3
.L1:ret
Scalarcode
daxpy:cbz x0, .L1mov x3, 0mov z0.d, d0whilelo p0.d, xzr, x0ptrue p1.d, all.p2align 3
.L3:ld1d z2.d, p0/z, [x2, x3, lsl 3]ld1d z1.d, p0/z, [x1, x3, lsl 3]fmad z1.d, p1/m, z0.d, z2.dst1d z1.d, p0, [x2, x3, lsl 3]incd x3whilelo p0.d, x3, x0bne .L3
.L1:ret
daxpy:cbz x0, .L1mov x3, 0mov z0.d, d0whilelo p0.d, xzr, x0ptrue p1.d, vl8.p2align 3
.L3:ld1d z2.d, p0/z, [x2, x3, lsl 3]ld1d z1.d, p0/z, [x1, x3, lsl 3]fmad z1.d, p1/m, z0.d, z2.dst1d z1.d, p0, [x2, x3, lsl 3]add x3, x3, 8whilelo p0.d, x3, x0bne .L3
.L1:ret
VL-agnosticcode VL512-specificcode
Vectorcodehasonly3extrainstructions (couldbejust1) NobenefittoVL-specificcodehere!
SVEvectorisationexample:naïvedaxpy
gcc –O3–march=armv8-a gcc –O3–march=armv8-a+sve gcc –O3–march=armv8-a+sve–msve-vector-bits=512

©2017ArmLimited
LLVM/Clang
©2017ArmLimited13
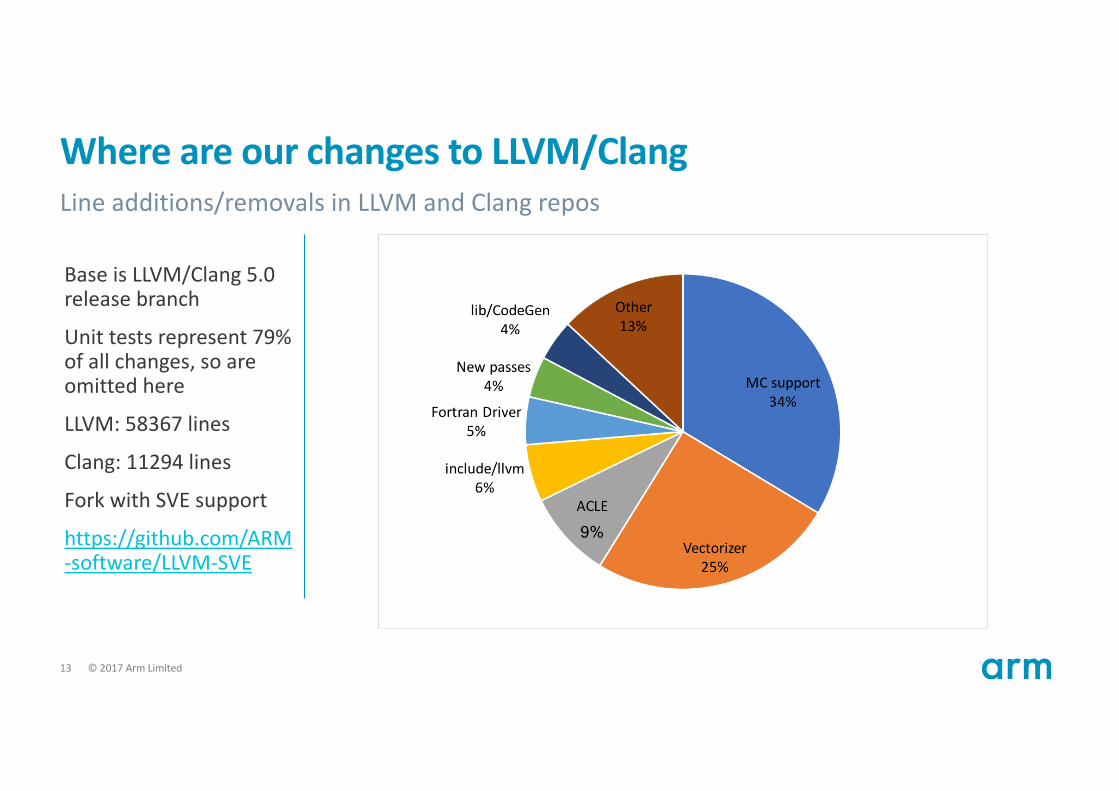
WhereareourchangestoLLVM/ClangLineadditions/removalsinLLVMandClangrepos
BaseisLLVM/Clang5.0releasebranch
Unittestsrepresent79%ofallchanges,soareomittedhere
LLVM:58367lines
Clang:11294lines
ForkwithSVEsupport
https://github.com/ARM-software/LLVM-SVE

©2017ArmLimited14
WhereareourchangestoLLVM/ClangTheSVESide
Assembler/MC IRTypes Autovectorization
Extendloopvectorizer touselength-agnosticIR
Makesurelength-agnosticvectorizationfitsintoVPlan
Aim:InitialsupportinLLVM7.0
AssemblersupportforSVE
120patchesready
StartedupstreaminginNovember
Aim:SubmitchangesbyMay
Introducescalablevectortype
Initiallyuseintrinsics forfunctionslikestepvector
Codegen forscalableIR
Aim:InitialsupportafterLLVM6.0release

©2017ArmLimited15
ChangestoClangandlibraries
Vectorized mathlibrarysupportSVEintrinsicssupport
Clanguageextensionwithintrinsics forSVEsupportedbythecommercialcompiler
Allowstohand-optimizecodeforSVE
AimistoupstreamitoncethereisconsensusinthecommunityandLLVMsupportiscommitted
Goal:Vectorizecallstolibm functions
DefinevectorABIforlibrariestouse
ExtendLoopVectorize togeneratecallsusingtheABI
UseSLEEF(avectorizableimplementationofpartsoflibm)
SupportforAdvancedSIMDisalreadyupstream,SVEsupportdownstream

©2017ArmLimited16
Conclusion
CompilerwithSVE&Fortransupportavailable
ArmInstructionEmulatorrunsSVEuserspace binaries
CommercialTools
GCC&LLVMSVEenablementisapriority
WorkingonArmv8-Aperformance
ImprovingFlang
Optimizedlibraries
MakingsureHPCappsworkonArmv8-A
PortHPCapps
BuildArmHPCcommunity
https://arm-hpc.gitlab.io
OpenSource HPCApplications

1717
ThankYou!Danke!Merci!谢谢!ありがとう!Gracias!Kiitos!감사합니다धन्यवाद
©2017ArmLimited

©2017ArmLimited
Backup

©2017ArmLimited19
WhereareourchangestoLLVM
Re-balanceschainsofmultiplies/addstoallowbetteruseofFMAs
Givesasignificant(~30%)improvementonSpecCPU2006Calculix
LoopSpeculativeBoundsCheckAllowsRe-factoringofLoopVersioningLICM
Hoistingofloop-independentloadsthatfeedintotheinductionvariable,withruntimechecksforaliasing
ImprovesSpecCPU2000GCCby~5%
Aim:
AtleastoneofthesepassesforClang6.0,theothersforClang7.0
LoopExprTreeFactoring
PreInlinerTransforms
Splitcallsiteswhereargumentsarepredicatedconditionsinpredecessors
Exposesadditionalinlining opportunities
ImprovesSpecCPU2017GCCby~22%
Newtarget-independentpasses

©2017ArmLimited20
GCCspillcodeimprovements
Problem Solution
Instruction schedulingtendstoincreaseregisterpressure • Usepressure-sensitive schedulingbydefault• Assumeforregister-pressurepurposesthatonly8
predicateregistersareavailable
Stackframes cancontainamixtureofvariable-lengthandfixed-lengthdata
• Don’tshare stackslotsbetweenfixed-lengthandvariable-lengthdata
• Useshared”anchor”addressestoaccessnearbyspills
Normal functioncallsdonotpreserveSVEstate,butoptimisationscanmovevectoroperationsacrosscalls
• Anew“earlyrematerialisation”passthatrunsbeforeregisterallocationand triestomakesurethatSVEvaluesarerecalculatedaftercallswherenecessaryØ Moreeffectivethantryingtostopoptimisations
movingvaluesacrosscallsØ Handlesmorecasesthantheregisterallocator
Spiltvaluesareoftenduplicatedinvariants • Spilltheduplicatedinvariantinstead ofthevectorØ Futurework
Morevectorisationopportunitiesmeansmorepotentialforspilling

©2017ArmLimited21
EvaluatingSVE
Compile Emulate Analyse
ArmCompiler
C/C++/Fortrancode
SVE viaauto-vectorization,intrinsicsandassembly.
CompilerInsight:Compilerplacesresultsofcompile-timedecisionsandanalysisintheresultingbinary.
SuppliedwithSVEPerformanceLibraries.
ArmInstructionEmulator
Runsuserspace binariesforfutureArmarchitecturesontoday’ssystems.
Supportedinstructionsrununmodified.
Unsupportedinstructionsaretrappedandemulated.
ArmCodeAdvisor
Consoleorweb-basedoutputshowsprioritizedadvicein-linewithoriginalsourcecode.

©2017ArmLimited22
Communitybuilding
Ourappworkisengagingwithcodeownersandusers togetsuitabletestcases,togetArmsupportbuiltin,andincludinghelpingthemmakeAArch64testingpartoftheirdevelopmentprocesses
Outsidethepeoplewecollaboratewith,variouscomplementaryArmHPCcommunitiesalreadyexist:
• ArmHPCUserGroup(SC)andGoingArm (ISC/ArmRS)
• ArmHPCGoogleGroup(https://groups.google.com/d/forum/arm-hpc)
• ArmHPCGitLabpages(https://gitlab.com/arm-hpc)
EncouragingourpartnerstouseGitLabisapriority

©2017ArmLimited23
Wikihttps://gitlab.com/arm-hpc/packages/wikis/home
DynamiclistofcommonHPCapplications Up-to-datesummaryofpackagestatus
Providesfocusforportingprogress
Communitydriven.
MaintainedbyArm,butanyonecanjoinandcontribute.
Allowsdeveloperstosharerecipes,andlearnfromprogressonotherapplications
Providesamechanismfortrackingstatusofapplicationsandpackagesets(e.g.OpenHPCpackages,Mantevo,etc.)

©2017ArmLimited24
Opensourcelibrariesforhelpingincreaseperformance
ArmOptimizedRoutineshttps://github.com/ARM-software/optimized-routines
Theseroutinesprovidehighperformingversionsofmanymath.h functions• Algorithmicallybetterperformancethan
standardlibrarycalls
• Nolossofaccuracy
SLEEFlibraryhttps://github.com/shibatch/sleef/
Vectorized math.h functions
• ProvidedasanoptionforuseinArmCompiler
Perf-libs-toolshttps://github.com/ARM-software/perf-libs-tools
Understandinganapplication’sneedsforBLAS,LAPACKandFFTcalls
• UsedinconjunctionwithArmPerformanceLibraries cangeneratelogginginfotohelpprofileapplicationsforspecificcasebreakdowns
Examplevisualization:DGEMMcasescalled