approches prédictives dans le...
TRANSCRIPT

Approches prédictives dans le digitalOnline and Unsupervised Learning
Sébastien Loustau, CEO
Chaire DAMI, le 28 Mars 2017

Contents
Machine Learning : Gentle start
Cas d'application : segmentation clients temps réel
Cas d'application : détection de communautés temps réel

Contents
Machine Learning : Gentle start
Cas d'application : segmentation clients temps réel
Cas d'application : détection de communautés temps réel

Machine learning
x −→ nature −→ y
I prédire la réponse y à partir de x ,
I comprendre le lien entre x et y .
x −→ algorithm −→ y

Machine learning
x −→ nature −→ y
I prédire la réponse y à partir de x ,
I comprendre le lien entre x et y .
x −→ algorithm −→ y

Machine learning
x −→ nature −→ y
I prédire la réponse y à partir de x ,
I comprendre le lien entre x et y .
x −→ algorithm −→ y

Machine learning
x −→ nature −→ y
I prédire la réponse y à partir de x ,
I comprendre le lien entre x et y .
x −→ algorithm −→ y

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}.
New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially. At each time t, we want to make adecision based on past observations. No assumption over thedata mechanism.

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}. New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially. At each time t, we want to make adecision based on past observations. No assumption over thedata mechanism.

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}. New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially.
At each time t, we want to make adecision based on past observations. No assumption over thedata mechanism.

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}. New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially. At each time t, we want to make adecision based on past observations.
No assumption over thedata mechanism.

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}. New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially. At each time t, we want to make adecision based on past observations. No assumption over thedata mechanism.

Statistical Learning vs Online Learning
Statistical Learning
We observe a training set Dn = {(Xi ,Yi ), i = 1, . . . , n}. New x
arrives. We build a model/algorithm thanks to Dn and predict y .
Online Learning
Data arrives sequentially. At each time t, we want to make adecision based on past observations. No assumption over thedata mechanism.

Real time ML : un enjeu de taille

Real time ML : un enjeu de taille

Supervised learning
x −→ nature −→ y
I prédire la réponse y à partir de x ,
I comprendre le lien entre x et y .
x −→ algorithm −→ y

Today : unsupervised learning
nature −→ x
I décrire les observations x ,
I réduire la dimension de x ,
I grouper les observations x .
Vanilla algorithms and recent hot topics
PCA, k-means, gaussian mixtures, change points or more recentlywords embeddings, community detection, generative models(GAN)...

Today : unsupervised learning
nature −→ x
I décrire les observations x ,
I réduire la dimension de x ,
I grouper les observations x .
Vanilla algorithms and recent hot topics
PCA, k-means, gaussian mixtures, change points or more recentlywords embeddings, community detection, generative models(GAN)...

Today : unsupervised learning
nature −→ x
I décrire les observations x ,
I réduire la dimension de x ,
I grouper les observations x .
Vanilla algorithms and recent hot topics
PCA, k-means, gaussian mixtures, change points or more recentlywords embeddings, community detection, generative models(GAN)...

Today : unsupervised learning
nature −→ x
I décrire les observations x ,
I réduire la dimension de x ,
I grouper les observations x .
Vanilla algorithms and recent hot topics
PCA, k-means, gaussian mixtures, change points or more recentlywords embeddings, community detection, generative models(GAN)...

Today : unsupervised learning
nature −→ x
I décrire les observations x ,
I réduire la dimension de x ,
I grouper les observations x .
Vanilla algorithms and recent hot topics
PCA, k-means, gaussian mixtures, change points or more recentlywords embeddings, community detection, generative models(GAN)...

Qu'est-ce que ça change ?

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.I Observe new x and predict y as above.I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.I Observe new x and predict y as above.I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.
I Observe new x and predict y as above.I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.I Observe new x and predict y as above.
I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.I Observe new x and predict y as above.I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Supervised routine
x −→ algorithm −→ y
I Build a model from a training sample {(Xi ,Yi ), i = 1, . . . , n}.I Observe new x and predict y as above.I Problem : over�tting !
I Solution : Training set + test set, Leave-One-Out, V-foldCross validation.

Unsupervised : science or art ?

Unsupervised : the hype

Contents
Machine Learning : Gentle start
Cas d'application : segmentation clients temps réel
Cas d'application : détection de communautés temps réel

The problem of Online Clustering
s
'
&
$
%

The problem of Online Clustering
s
'
&
$
%

The problem of Online Clustering
ss
'
&
$
%

The problem of Online Clustering
sss
'
&
$
%

The problem of Online Clustering
sss
s
'
&
$
%

The problem of Online Clustering
ssss
s ss s
s s
ss
s s
ss ss
s s
sss s s
s
'
&
$
%

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2
'
&
$
%

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s
'
&
$
%

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%
I Principle : clustering as prediction !
I Sparsity assumption : points aregrouped into s clusters.
I Use PAC-Bayesian regularization tochoose the number of clusters.
We prove new kind of sparsity regret bounds:
T
∑t=1
`(ct , xt)− infc∈Rdp
{T
∑t=1
`(c, xt) + λ|c|0
},
where |c|0 = card{j = 1, . . . , p : cj 6= 0Rd } and
`(c, x) = minj=1,...,p
‖cj − x‖22.

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%
I Principle : clustering as prediction !
I Sparsity assumption : points aregrouped into s clusters.
I Use PAC-Bayesian regularization tochoose the number of clusters.
We prove new kind of sparsity regret bounds:
T
∑t=1
`(ct , xt)− infc∈Rdp
{T
∑t=1
`(c, xt) + λ|c|0
},
where |c|0 = card{j = 1, . . . , p : cj 6= 0Rd } and
`(c, x) = minj=1,...,p
‖cj − x‖22.

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%
I Principle : clustering as prediction !
I Sparsity assumption : points aregrouped into s clusters.
I Use PAC-Bayesian regularization tochoose the number of clusters.
We prove new kind of sparsity regret bounds:
T
∑t=1
`(ct , xt)− infc∈Rdp
{T
∑t=1
`(c, xt) + λ|c|0
},
where |c|0 = card{j = 1, . . . , p : cj 6= 0Rd } and
`(c, x) = minj=1,...,p
‖cj − x‖22.

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%
I Principle : clustering as prediction !
I Sparsity assumption : points aregrouped into s clusters.
I Use PAC-Bayesian regularization tochoose the number of clusters.
We prove new kind of sparsity regret bounds:
T
∑t=1
`(ct , xt)− infc∈Rdp
{T
∑t=1
`(c, xt) + λ|c|0
},
where |c|0 = card{j = 1, . . . , p : cj 6= 0Rd } and
`(c, x) = minj=1,...,p
‖cj − x‖22.

The problem of Online Clustering
ssss
s s
2
s s
s s
ss
s s
ss ss
s2s
sss s s
s2s↙↗
'
&
$
%
I Principle : clustering as prediction !
I Sparsity assumption : points aregrouped into s clusters.
I Use PAC-Bayesian regularization tochoose the number of clusters.
We prove new kind of sparsity regret bounds:
T
∑t=1
`(ct , xt)− infc∈Rdp
{T
∑t=1
`(c, xt) + λ|c|0
},
where |c|0 = card{j = 1, . . . , p : cj 6= 0Rd } and
`(c, x) = minj=1,...,p
‖cj − x‖22.

Business case
I Client : éditeur de logiciel dans le commerce conversationnel
I Inputs (X ): comportement de navigations
I Objectifs : satisfaction clients, instantanéité, conversion sanscanibalisme

Business case
I Client : éditeur de logiciel dans le commerce conversationnel
I Inputs (X ): comportement de navigations
I Objectifs : satisfaction clients, instantanéité, conversion sanscanibalisme

Business case
I Client : éditeur de logiciel dans le commerce conversationnel
I Inputs (X ): comportement de navigations
I Objectifs : satisfaction clients, instantanéité, conversion sanscanibalisme

Business case
I Client : éditeur de logiciel dans le commerce conversationnel
I Inputs (X ): comportement de navigations
I Objectifs : satisfaction clients, instantanéité, conversion sanscanibalisme

L'existant
I Absence de stockage
I Absence d'architecture Big Data
I Réglage manuel des règles de ciblage

L'existant
I Absence de stockage
I Absence d'architecture Big Data
I Réglage manuel des règles de ciblage

L'existant
I Absence de stockage
I Absence d'architecture Big Data
I Réglage manuel des règles de ciblage

L'existant
I Absence de stockage
I Absence d'architecture Big Data
I Réglage manuel des règles de ciblage

Proof of concept (POC) : périmètre
I 11 sites
I 20M pvues/mois
I 160k events/heure

Proof of concept (POC) : objectifs
I Automatiser le ciblage
I Simpli�er l'administration et la mise à jour
I Améliorer les performances
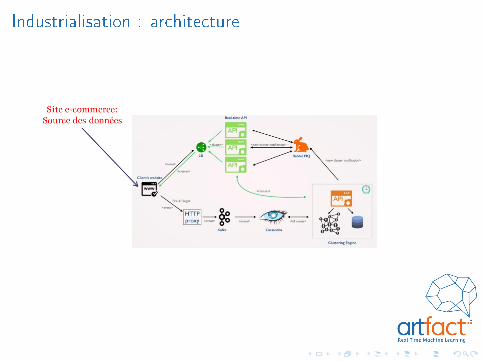
Industrialisation : architecture

Industrialisation : architecture

Industrialisation : architecture
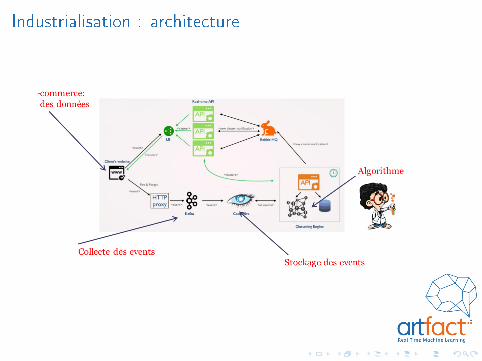
Industrialisation : architecture

Industrialisation : architecture

Industrialisation : architecture

Industrialisation : architecture

Contents
Machine Learning : Gentle start
Cas d'application : segmentation clients temps réel
Cas d'application : détection de communautés temps réel

Graph clustering
I Proposer l'analyse précédente sur un graphe
I Nouveaux challenges
I Have a look !

Graph clustering
I Proposer l'analyse précédente sur un graphe
I Nouveaux challenges
I Have a look !

Graph clustering
I Proposer l'analyse précédente sur un graphe
I Nouveaux challenges
I Have a look !

Ingrédients
I Théorie des graphes
I Optimisation par Monte Carlo Markov Chain (MCMC)
I Calculs parallèles

Qu'est-ce qu'un graphe ?
Dé�nition (Wikipédia) :
Un graphe est un ensemble de points nommés n÷uds
(parfois sommets ou cellules) reliés par des traits
(segments) ou �èches nommées arêtes (ou liens ou arcs).
L'ensemble des arêtes entre n÷uds forme une �gure
similaire à un réseau.
Keyp point : relational structure.

Qu'est-ce qu'un graphe ?
Dé�nition (Wikipédia) :
Un graphe est un ensemble de points nommés n÷uds
(parfois sommets ou cellules) reliés par des traits
(segments) ou �èches nommées arêtes (ou liens ou arcs).
L'ensemble des arêtes entre n÷uds forme une �gure
similaire à un réseau.
Keyp point : relational structure.

Illustrations : political blog
Network of U.S.political blogs byAdamic and Glance(2004)

Illustrations : LinkedIn community
LinkedIn communityof Chris Volinski(2011, ColumbiaUniversity), seewww.socilab.com

Illustrations : Facebook friends
Facebook of ChrisVolinski (2011,Columbia Univer-sity)
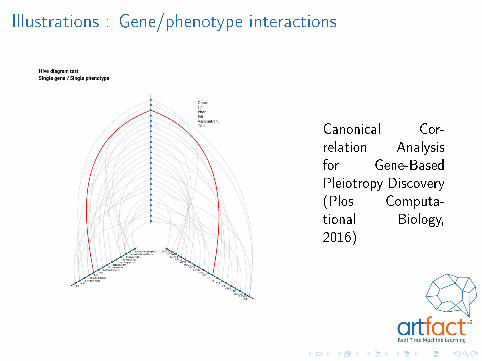
Illustrations : Gene/phenotype interactions
Canonical Cor-relation Analysisfor Gene-BasedPleiotropy Discovery(Plos Computa-tional Biology,2016)

Formalisme mathématique
De�nitionUn graphe G est une structure constituée d'un couple (E ,V ) où :
I V = {v1, . . . , vN} est un ensemble de N n÷uds,
I E est un ensemble d'arêtes ou liens.
|V | = N est appelé l'ordre de G et |E |la taille de G .
De�nitionPour un graphe G = (E ,V ), le degré d'un n÷ud v ∈ V est lenombre d'arêtes dans E partant de v .

Formalisme mathématique
De�nitionUn graphe G est une structure constituée d'un couple (E ,V ) où :
I V = {v1, . . . , vN} est un ensemble de N n÷uds,
I E est un ensemble d'arêtes ou liens.
|V | = N est appelé l'ordre de G et |E |la taille de G .
De�nitionPour un graphe G = (E ,V ), le degré d'un n÷ud v ∈ V est lenombre d'arêtes dans E partant de v .

Formalisme mathématique
De�nitionUn graphe G est une structure constituée d'un couple (E ,V ) où :
I V = {v1, . . . , vN} est un ensemble de N n÷uds,
I E est un ensemble d'arêtes ou liens.
|V | = N est appelé l'ordre de G et |E |la taille de G .
De�nitionPour un graphe G = (E ,V ), le degré d'un n÷ud v ∈ V est lenombre d'arêtes dans E partant de v .

Formalisme mathématique
De�nitionUn graphe G est une structure constituée d'un couple (E ,V ) où :
I V = {v1, . . . , vN} est un ensemble de N n÷uds,
I E est un ensemble d'arêtes ou liens.
|V | = N est appelé l'ordre de G et |E |la taille de G .
De�nitionPour un graphe G = (E ,V ), le degré d'un n÷ud v ∈ V est lenombre d'arêtes dans E partant de v .

Formalisme mathématique
De�nitionUn graphe G est une structure constituée d'un couple (E ,V ) où :
I V = {v1, . . . , vN} est un ensemble de N n÷uds,
I E est un ensemble d'arêtes ou liens.
|V | = N est appelé l'ordre de G et |E |la taille de G .
De�nitionPour un graphe G = (E ,V ), le degré d'un n÷ud v ∈ V est lenombre d'arêtes dans E partant de v .

Propriétés élémentaires
De�nitionA sparse graph is a graph (E ,V ) such that |E | is of order |V |.
De�nitionA scale-free network is a network whose degree distributionfollows a power law, that is to say:
P(di = k) ∼ k−γ.
De�nitionA graph G with N vertices satis�es the small-world property if inexpectation, 2 randomly chosen vertices i and j have distancesproportional to logN.

Propriétés élémentaires
De�nitionA sparse graph is a graph (E ,V ) such that |E | is of order |V |.
De�nitionA scale-free network is a network whose degree distributionfollows a power law, that is to say:
P(di = k) ∼ k−γ.
De�nitionA graph G with N vertices satis�es the small-world property if inexpectation, 2 randomly chosen vertices i and j have distancesproportional to logN.

Propriétés élémentaires
De�nitionA sparse graph is a graph (E ,V ) such that |E | is of order |V |.
De�nitionA scale-free network is a network whose degree distributionfollows a power law, that is to say:
P(di = k) ∼ k−γ.
De�nitionA graph G with N vertices satis�es the small-world property if inexpectation, 2 randomly chosen vertices i and j have distancesproportional to logN.

Propriétés élémentaires
De�nitionA sparse graph is a graph (E ,V ) such that |E | is of order |V |.
De�nitionA scale-free network is a network whose degree distributionfollows a power law, that is to say:
P(di = k) ∼ k−γ.
De�nitionA graph G with N vertices satis�es the small-world property if inexpectation, 2 randomly chosen vertices i and j have distancesproportional to logN.

Détection de communautés (ou graph clustering)
I Partition des n÷uds qui véri�e : beaucoup d'arêtes à l'intérieurdes groupes, peu d'arêtes entre les groupes.
I Tâche non-supervisée (!)
I Méthodes spectrales consistant à diagonaliser :
L = D − A,
où A est la matrice d'adjacence et D la matrice des degrés.
I Optimisation d'un critère appelé la modularité :
MG (c) =1
2m ∑(i ,j)
(Aij −
kikj2m
)δc(i , j).

Détection de communautés (ou graph clustering)
I Partition des n÷uds qui véri�e : beaucoup d'arêtes à l'intérieurdes groupes, peu d'arêtes entre les groupes.
I Tâche non-supervisée (!)
I Méthodes spectrales consistant à diagonaliser :
L = D − A,
où A est la matrice d'adjacence et D la matrice des degrés.
I Optimisation d'un critère appelé la modularité :
MG (c) =1
2m ∑(i ,j)
(Aij −
kikj2m
)δc(i , j).

Détection de communautés (ou graph clustering)
I Partition des n÷uds qui véri�e : beaucoup d'arêtes à l'intérieurdes groupes, peu d'arêtes entre les groupes.
I Tâche non-supervisée (!)
I Méthodes spectrales consistant à diagonaliser :
L = D − A,
où A est la matrice d'adjacence et D la matrice des degrés.
I Optimisation d'un critère appelé la modularité :
MG (c) =1
2m ∑(i ,j)
(Aij −
kikj2m
)δc(i , j).

Détection de communautés (ou graph clustering)
I Partition des n÷uds qui véri�e : beaucoup d'arêtes à l'intérieurdes groupes, peu d'arêtes entre les groupes.
I Tâche non-supervisée (!)
I Méthodes spectrales consistant à diagonaliser :
L = D − A,
où A est la matrice d'adjacence et D la matrice des degrés.
I Optimisation d'un critère appelé la modularité :
MG (c) =1
2m ∑(i ,j)
(Aij −
kikj2m
)δc(i , j).

Algorithme glouton

Algorithme MCMC
I Select at random a neighborhood C ′ of the current colorationC
I Accept the proposal with standard Metropolis accept/rejectratio

Algorithme �nal

Algorithme �nal

Algorithme �nal

Business case : appel à volontaire

Business case : appel à volontaire

Business case : appel à volontaire

Propaganda :-)
Website : http://www.artfact-online.fr
Twitter : @artfact-labYoutube : Le Machine Learning par l'exempleMeetup Machine Learning : Nantes Rennes PauPlateforme d'innovation ouverte : Learnation Square

Propaganda :-)
Website : http://www.artfact-online.frTwitter : @artfact-lab
Youtube : Le Machine Learning par l'exempleMeetup Machine Learning : Nantes Rennes PauPlateforme d'innovation ouverte : Learnation Square

Propaganda :-)
Website : http://www.artfact-online.frTwitter : @artfact-labYoutube : Le Machine Learning par l'exemple
Meetup Machine Learning : Nantes Rennes PauPlateforme d'innovation ouverte : Learnation Square

Propaganda :-)
Website : http://www.artfact-online.frTwitter : @artfact-labYoutube : Le Machine Learning par l'exempleMeetup Machine Learning : Nantes Rennes Pau
Plateforme d'innovation ouverte : Learnation Square

Propaganda :-)
Website : http://www.artfact-online.frTwitter : @artfact-labYoutube : Le Machine Learning par l'exempleMeetup Machine Learning : Nantes Rennes PauPlateforme d'innovation ouverte : Learnation Square

Propaganda :-)
- Merci de votre attention ! -
Website : http://www.artfact-online.frTwitter : @artfact-labYoutube : Le Machine Learning par l'exempleMeetup Machine Learning : Nantes Rennes PauPlateforme d'innovation ouverte : Learnation Square