applying a meta-data-driven modeling approach to extract
TRANSCRIPT

Applying a meta-data-driven modeling approach to extract-transform-load (ETL) systemsCitation for published version (APA):Ayele, S. G. (2018). Applying a meta-data-driven modeling approach to extract-transform-load (ETL) systems.Technische Universiteit Eindhoven.
Document status and date:Published: 24/10/2018
Document Version:Publisher’s PDF, also known as Version of Record (includes final page, issue and volume numbers)
Please check the document version of this publication:
• A submitted manuscript is the version of the article upon submission and before peer-review. There can beimportant differences between the submitted version and the official published version of record. Peopleinterested in the research are advised to contact the author for the final version of the publication, or visit theDOI to the publisher's website.• The final author version and the galley proof are versions of the publication after peer review.• The final published version features the final layout of the paper including the volume, issue and pagenumbers.Link to publication
General rightsCopyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright ownersand it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights.
• Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal.
If the publication is distributed under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license above, pleasefollow below link for the End User Agreement:www.tue.nl/taverne
Take down policyIf you believe that this document breaches copyright please contact us at:[email protected] details and we will investigate your claim.
Download date: 14. Mar. 2022

/ Department of Mathematics and Computer Science / PDEng Software Technology
Where innovation starts
Applying a meta-data-
driven modeling approach
to Extract-Transform-Load
(ETL) Systems
Sololia G. Ayele

Applying a meta-data-driven modeling approach to
Extract-Transform-Load (ETL) Systems
Sololia G. Ayele
Eindhoven University of Technology
Stan Ackermans Institute – Software Technology
PDEng Report: 2018/097
Partners
Océ, a Canon company Eindhoven University of Technology
Steering Group Pieter Verduin
Johan Hoogendoorn / Tim Paffen
Tim Willemse
Date
October 2018
Document Status
Public
The design that is described in this report has been carried out in accordance with the rules of the TU/e Code of
Scientific Conduct.

Technische Universiteit Eindhoven University of Technology
Date October, 2018
Contact address Eindhoven University of TechnologyDepartment of Mathematics and Computer ScienceMF 5.080AP.O. Box 513NL-5600 MBEindhoven, The Netherlands+31 (0)40 247 4334
Published by Eindhoven University of TechnologyStan Ackermans Institute
Printed by Eindhoven University of TechnologyUniversiteitsDrukkerij
SAI serial number Eindverslagen Stan Ackermans Instituut; 2018/097
Abstract In this report, modeling approaches for Extract-Transform-Load(ETL) systems are investigated. Océ collects data from its variousprinters in the field to store in data warehouses using ETL flows. Withthis project, Océ wanted to investigate modeling methodologies thatcan be applied to increase productivity when adding new ETL flows.Furthermore, Océ is interested in having a uniform ETL frameworkto ease communication, development and re-use between differentteams. Taking two existing ETL systems as case studies, differentmodeling approaches were analyzed. This investigation resulted in ameta-data-driven ETL design approach. The proposed solution aimsto optimize re-usability of ETL components to avoid repetitive imple-mentation tasks when adding new ETL flows. In addition, recommen-dations are proposed to cases where this approach should be appliedto take the full advantage of the proposed meta-data-driven design.
Keywords Model-driven, Meta-data, ETL, Data warehouse
Preferred reference Applying a meta-data-driven modeling approach to Extract-Trans-form-Load (ETL) Systems,.SAI Technical Report, October 2018.(2018/097).
Partnership This project was supported by Eindhoven University of Technologyand Océ, a Canon company
3 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Disclaimer Endorsement Reference herein to any specific commercial products, process, orservice by trade name, trademark, manufacturer, or otherwise, doesnot necessarily constitute or imply its endorsement, recommenda-tion, or favoring by the Eindhoven University of Technology andOcé. The views and opinions of authors expressed herein do notnecessarily state or reflect those of the Eindhoven University ofTechnology and Océ, and shall not be used for advertising or prod-uct endorsement purposes.
Disclaimer Liability While every effort will be made to ensure that the information con-tained within this report is accurate and up to date, Eindhoven Uni-versity of Technology makes no warranty, representation or under-taking whether expressed or implied, nor does it assume any legalliability, whether direct or indirect, or responsibility for the accu-racy, completeness, or usefulness of any information.
Trademarks Product and company names mentioned herein may be trademarksand/or service marks of their respective owners. We use thesenames without any particular endorsement or with the intent to in-fringe the copyright of the respective owners.
Copyright Copyright © 2018 Eindhoven University of Technology. All rightsreserved. No part of the material protected by this copyright no-tice may be reproduced, modified, or redistributed in any form orby any means, electronic or mechanical, including photocopying,recording, or by any information storage or retrieval system, with-out the prior written permission of the Eindhoven University ofTechnology and Océ.
4 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems


Technische Universiteit Eindhoven University of Technology
Foreword
Océ is one of the world leading manufacturers of print systems for the professional market. Thesesystems generate an increasing amount of different data. Within our organization there are also othersources of data, e.g. related to contracts, service activities and products that have evolved separatelyfrom each other, resulting in different systems. We see an increasing usage and thus increasing need toevolve and extent these systems. New big data related projects and developments are on the horizon.Thus a clear need to unify and align the development of those systems was identified. Additionallypast projects show that the complexity and development time of such systems will rapidly grow. Tocounter this a model driven route was taken.
As part of this assignment, Sololia took good initiative and independently consulted stakeholders,colleagues and partner companies. As the project progressed she defined, from the ground up, theconcepts of model driven ETL processing, incorporating requirements from both the architecturalstandpoint as well as engineering and design. Analysis on different design methodologies was done,which resulted in the meta-data driven approach. An inventory of the technical routes resulted in achoice for an ETL design tool to prototype the approach. She used the tool to build a prototype toshowcase the feasibility for all the client project environments. This prototype has been used to demoto all the stakeholders and we are happy how the end result turned out. The work Sololia has done andthe insight she has provided has initiated an internal follow-up assignment. As part of this assignmentwe will take into considerations the future work and ideas she has provided.
As supervisors it is very rewarding to see progress and personal growth in a student and we hopewe contributed in a positive way to that. We see that Sololia has shown great eagerness to learn anddevelop herself, by experimenting and getting out of her comfort zone. With this attitude we areconvinced she will continue to develop herself even further.
We would like to wish Sololia the best of luck in her future career.
Tim Paffen & Pieter Verduin
17 September 2018
ii Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

iii

Technische Universiteit Eindhoven University of Technology
Preface
This report summarizes the project entitled: "Applying a meta-data-driven modeling approach toExtract-Transform-Load Systems". It is part of a ten month graduation assignment for the ProfessionalDoctorate in Engineering (PDEng) program under the supervision of Océ and Eindhoven Universityof Technology (TU/e). The goal of the project is to find a modeling approach to reduce the repetitiveimplementation tasks, have a uniform way of designing ETLs to facilitate communication betweenteams/team members and have ways to express ETL designs in different levels of higher abstraction.
This report documents research regarding ways to model ETL flows, followed by a proposed modelingmethodology. Furthermore, it details the prototype of selected case studies and the project manage-ment approach taken throughout the project timeline.
This report has three main areas – domain context and problem analysis detailed in Chapters 1 - 3,technical details including requirements, design, and realization covered in Chapters 4 - 6, and projectmanagement and retrospective in Chapter 7.
Sololia G. Ayele
20 September 2018
iv Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

v

Technische Universiteit Eindhoven University of Technology
Acknowledgments
This project could not have been possible without the support and encouragement of supervisors,colleagues, friends, and family.
I owe special gratitude to my supervisors from Océ, Tim Paffen, Pieter Verduin, and Johan Hoogen-doorn, and from TU/e, Tim Willemse. You provided continuous guidance, support, and constructivefeedback. I have learned quite a lot from you all. I would also like to thank Jos Jans for giving feed-backs at the joint meetings and helping shape the project. Carmina Azevedo, I am grateful for havingyou next to me from start to end.
I would also like to thank Rob Kersemakers, Roland Fabel and Océ ’s purchasing team for followingup and helping me acquire the necessary product license I needed. It would have been challenging tocomplete the project without your support.
Many people helped explain the current systems and procedures in Océ. I appreciate their willingnessto take the time to explain the new environment and for letting me come with my questions at anytime: Jacques Bergmans, Joost Janse, Jeroen Dopp, Roelof Hamberg, Peter Cornelissen, HermanRoelfs, Fariba Safari, Henk Thijssen, Rob Jacobs, Peter Teeuwen and Jeroen Janssen.
Luc de Smet, thank you for helping to integrate in Océ better and sharing your experiences as both anex-OOTI and current Océ employee. I am grateful to Maarten Plugge for letting me join his car pooland making the every day commute easier. Dmitrii Nikeshkin thank you for the occasional car pooland coffee break discussions. Carlos Giraldo, thank you for convincing me to own a chair I did notneed and for all the interesting topics you brought to our lunch table.
I would also like to pass my gratitude to Hristina Moneva, Eugen Schindler, Mark van den Brand,Robert Decker, Harold Weffers, Mauricio Verano, Ana-Maria Sutii, Berihun F. Yimam and othersboth from Océ and TU/e, who were willing to give their time to brainstorm and provide feedbackduring the project’s timeline.
If it wasn’t for the opportunity I was given by the people involved in the TU/e’s Software TechnologyPDEng program, I wouldn’t have started and completed this project and program. Ad Aerts, YanjaDajsuren, Peter Zomer, Judith Strother, PD coaches and Desiree van Oorschot - Thank you for givingme support, helpful feedbacks and guidance during the past two years.
I would also like to thank my colleagues and friends from the PDEng program, both ST and ASD/MSD,for giving me the opportunity to learn from you all and the good moments we shared together.
Finally, my deepest and sincere gratitude goes to my family for their love and support.
Sololia G. Ayele
September 2018
vi Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

vii

Technische Universiteit Eindhoven University of Technology
Executive Summary
Business information systems produce and store data in various locations. On the one hand, Océcollects data from its multiple printers in the field. This data is being used by its designers andengineers to either improve the printers or understand the printer usage. Data from various printers iscollected and transformed to be loaded in a data warehouse using a system called Extract-Transform-Load flows. On the other hand, Model-driven approaches are being applied to an embedded domain inOcé. Océ wanted to investigate modeling methodologies to model ETL flows to increase productivitywhen adding new ETL flows. Furthermore, Océ is interested in having a uniform data warehousedesign framework to make communications between different teams smooth.
Early on it was realized that the concept of model-driven is broad. One of the project deliverable wasto give directions on modeling ETL flows to stakeholders. As a result, the Model Driven Architecture(MDA) was researched. The output was shared with stakeholders and documented to provide insighton modeling languages and methodologies. Considering the project scope, requirements and time, ameta-data-driven ETL design was proposed. The proposed solution aims to optimize re-usability ofETL components and avoid repetitive implementation tasks when new ETL flows are added. Creatingre-usable components is highly relevant because designing and development of ETL flows is knownto take up-to 70 percent of the implementation tasks [4].
Two existing data warehouse software systems were taken as case studies and used to prototype theproposed solution. By using a data integration framework called CloverETL, the following have beenachieved with the prototype.
• Created generic re-usable ETL components to show how development time can be saved byavoiding repetitive tasks. When it applies, the create-once-and-re-use approach was imple-mented in the prototype of the case studies
• Showed the integration of the proposed solution by using data from an environment similar tothe current implementation environments
• Showed different levels of visualization to communicate complex ETL flows in a higher levelof abstraction.
Based on the lessons learned during the design and prototype of the case studies, the following rec-ommendations are given to take a full advantage of the meta-data-driven design.
It is recommended to examine the current ETL flows to identify the common ETL Process in differentETL scenario and come up with good design patterns. Thus. saving development time by creatingprocesses only once to be re-used in various ETL cases. Furthermore, the more an ETL flow isnot attached to a specific ETL case, the higher the re-usability can get across different cases. Whencreating ETL Processes, one must be careful not to over-use the building blocks, and the specificationsproposed considering future maintainability. In this project, two ETL systems were taken as a casestudy. It is recommended to analyze the requirements of other ETL systems in Océ before deciding
viii Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
to have one ETL framework. Furthermore, for future work it is best to analyze ETL flows with theproposed solution direction taking into account of non-functionals like performance as this was out ofscope in this project.
ix Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

x

Technische Universiteit Eindhoven University of Technology
Glossary
BIML Business Intelligence Markup LanguageCRS Customer Reporting ServiceCSV Comma-separated valuesETL Extract-Transform-LoadETL process Describes a given ETL use-case by parameterizing them so that they can be re-
usedETL stage combination of parameterized ETL processesHDF5 Hierarchical Data FormatIP Intellectual PropertyLDS Large Data StorageMeta-data Information that describes about the dataMPS Managed Print ServiceODAS Optimal Data Analysis SystemORS Océ Remote ServicesPDEng Professional Doctorate in EngineeringPSG Project Steering GroupST Software TechnologySSIS SQL Server Integration ServicesTU/e Eindhoven University of Technology
xi Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

xii

Technische Universiteit Eindhoven University of Technology
Contents
Foreword ii
Preface iv
Acknowledgments vi
Executive Summary viii
Glossary xi
List of tables xvi
List of figures xviii
1 Introduction 2
1.1 Project Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Project Stakeholders . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Project Deliverables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Professional Doctorate in Engineering (PDEng) Program . . . . . . . . . . . . . . . 4
2 Domain Analysis 6
2.1 Data warehouse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 Staging area . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2 Data structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 ETL Frameworks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 ODAS and CRS Domain Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Optimal Data Analysis System (ODAS) . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Customer Reporting Services (CRS) . . . . . . . . . . . . . . . . . . . . . . 11
3 Problem Analysis 15
xiii Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
3.1 Current implementation challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Problem scope definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Requirement Analysis 18
4.1 Use-cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2 Functional and Non-Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5 Modeling Alternatives and Decisions 21
5.1 Modeling ETL processes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.1.1 Modeling ETL activities as graphs using custom constructs . . . . . . . . . . 22
5.1.2 UML Based . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.1.3 BPMN Based . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.1.4 Common warehouse meta-model (CWM) based: Meta-data driven approach 25
5.2 Decisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.2.1 Modeling current ETL flows . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.2.2 Framework choice for prototyping the case-studies . . . . . . . . . . . . . . 27
6 Design and Realization 31
6.1 Design of ETL building blocks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.1.1 Concept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.1.2 ETL process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6.1.3 ETL stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6.1.4 Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.1.5 Meta-data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.2 Design of ETL flows using the building blocks . . . . . . . . . . . . . . . . . . . . 33
6.3 Case study selection for prototype . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.4 Realization of Use-case: Model ETL flows with components that can be re-usable . . 35
6.4.1 Case study from ODAS: Functional Logs . . . . . . . . . . . . . . . . . . . 35
6.4.2 Case study from CRS: CGSTarget . . . . . . . . . . . . . . . . . . . . . . . 36
6.4.3 Realization of Use-case: Visualize an ETL flow on different level . . . . . . 40
6.4.4 Realization of Use-case: Execute ETL flows . . . . . . . . . . . . . . . . . 42
7 Project Management 44
7.1 Project Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
7.2 Communication Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
7.3 Risk Assessment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
xiv Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
7.4 Reflection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
8 Conclusions and Recommendations 50
8.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
8.2 Recommendations and Future works . . . . . . . . . . . . . . . . . . . . . . . . . . 51
A Stakeholder Analysis 54
B Use-case detail 62
C Cockburn’s Use Case Template 64
D ETL framework list used for comparison matrix 65
xv Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

xvi

Technische Universiteit Eindhoven University of Technology
List of Tables
4.1 Functional Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2 Non-functional Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.1 Framework Alternative Comparison Matrix – Functional Requirements . . . . . . . 28
5.2 Framework Alternative Comparison Matrix - Non-functional requirements . . . . . . 29
6.1 Prototype Environment Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
7.1 Communication Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
7.2 Risks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
B.1 Use-case 1 - Model ETL flows with components that can be re-usable . . . . . . . . 62
B.2 Use-case 2 - Visualize ETL flow on different level . . . . . . . . . . . . . . . . . . . 63
B.3 Use-case 3 - Execute ETL flows . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
C.1 Cockburn’s use case glossary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
xvii Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

xviii

Technische Universiteit Eindhoven University of Technology
List of Figures
1.1 VarioPrint i300 printer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Multi-function printer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Stakeholder analysis: influence vs interest chart . . . . . . . . . . . . . . . . . . . . 3
2.1 Kimball method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Example of dimensional model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 HDF5 high level structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 ODAS high level architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.5 Activity flow for fetch in ODAS’s data extraction layer . . . . . . . . . . . . . . . . 11
2.6 CRS data flow architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.7 CRS ETL flow activity diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.8 CRS Load activity diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.9 BIML usage in CRS for generating SSIS package . . . . . . . . . . . . . . . . . . . 13
4.1 Use-cases for a generic ETL framework . . . . . . . . . . . . . . . . . . . . . . . . 18
5.1 Overview of model driven architecture . . . . . . . . . . . . . . . . . . . . . . . . 21
5.2 ARKTOS [8] describing a flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.3 Overview of the ARKTOS framework for modeling ETL activities [27] . . . . . . . 23
5.4 An example of using UML for ETL processes with custom stereotype icons [31] . . 24
5.5 An example of using BPMN for ETL processes [33] . . . . . . . . . . . . . . . . . 25
5.6 Example of meta-data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.7 Concept for modeling ETL flows domain model . . . . . . . . . . . . . . . . . . . . 26
5.8 Concept definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.9 Proposed solution: meta-data-driven approach for modeling ETL flows . . . . . . . . 27
6.1 Overview of building blocks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.2 Example of the design of an ETL process . . . . . . . . . . . . . . . . . . . . . . . 33
6.3 Example of meta-data and parameter usage during execution . . . . . . . . . . . . . 33
xix Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
6.4 ETL flow case study from CRS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.5 ETL flow case study from ODAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.6 ODAS Fetch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.7 Design of the ODAS case study with meta-data-driven ETL Processes . . . . . . . . 36
6.8 CGSTarget Flow: Overview of current dimensional model transformation . . . . . . 36
6.9 CGS Loading DimAccount with a meta-data-driven ETL Process design . . . . . . . 37
6.10 CGS Loading DimCountry with a meta-data-driven ETL Process design . . . . . . . 37
6.11 Design of CGS LoadDimension with meta-data-driven ETL Processes . . . . . . . . 38
6.12 Design of CGS Generate Measures with meta-data-driven ETL Processes . . . . . . 38
6.13 Design of Update device measures with meta-data-driven ETL Processes . . . . . . . 39
6.14 Design of Update target and actual measures with meta-data-driven ETL Processes . 39
6.15 Design of CGS Target with meta-data-driven ETL Processes . . . . . . . . . . . . . 39
6.16 CloverETL Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.17 Example of the CloverETL’s Transformation Language - CTL [36] . . . . . . . . . . 40
6.18 CloverETL parameter, graph and sub-graph usage example . . . . . . . . . . . . . . 41
6.19 Example of CloverETL’s palette usage . . . . . . . . . . . . . . . . . . . . . . . . . 41
6.20 CloverETL’s meta-data editor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6.21 CloverETL Implementation for ODAS to automate file retrieval . . . . . . . . . . . 42
6.22 CloverETL Implementation for ODAS study case . . . . . . . . . . . . . . . . . . . 43
6.23 CloverETL Implementation for CRS study case - loading dimensions . . . . . . . . . 43
7.1 First iteration of project plan - Gantt chart . . . . . . . . . . . . . . . . . . . . . . . 44
7.2 Final project plan - Gantt chart . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
7.3 Project plan planned vs actual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
7.4 TFS Sprints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
1 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
1 Introduction
T¯his report describes the analysis and design methodology of a model driven approach for a data
warehouse system called Extract-Transform-Load (ETL). This chapter introduces the project contextand the stakeholders related to it.
1.1 Project ContextOcé Technologies B.V. was first established in 1877 when the founder Lodewijk van der Grintendeveloped a new coloring agent for margarine. Since then, Océ has been producing different printingtechnologies, such as large format, continuous feed, cut-sheet and sheet-fed printing. In 2013, Océwas acquired by Canon to become a Canon company [1].
Océ has a presence in Europe, North America, Canada, and Asia. This project is in collaboration withtwo of Océ’s projects located in The Netherlands. In the context of this project, two Data warehousesoftware systems from two projects in Océ are involved, the Optimal Data Analysis System (ODAS)and the Customer Reporting Service (CRS).
CRS combines and prepares data from different customer facilities and Canon Back Office (BO)systems. It collects data from Canon office printers, such as the Canon multi-function printer shownin Figure 1.2. Printer usage and customer contracts are examples of the data collected from theseprinters and BO systems. In addition to collecting data, CRS has a reporting tool that informs its usersabout the printer usage.
Figure 1.1: VarioPrint i300 printer Figure 1.2: Multi-function printer
Similar to CRS, ODAS also collects data from printers in the field. However, these printers are differ-ent from CRS’s data sources. They are the high end Océ production printers, such as the VarioPrinti300 (see Figure 1.1). ODAS functions as a remote analysis tool for these printers by collecting andproviding platform to analyze logs such as Functional Logs. Functional logs are records from differenthardware of the printers, for example log from a sensor in a printer. Using ODAS, Océ’s developersand researchers get access to the logs to further maintain and improve the printers.
Both ODAS and CRS have different data sources which are structured differently and have evolved
2 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
separately from each other. This has resulted in different systems and infrastructures. Even thoughboth systems receive their data from different sources, each uses a similar system to integrate datain their respective data warehouse. This system is called an ’Extract, Transform, Load’ (ETL) flow.Details of an ETL flow in discussed in Section 2.1.1.
The goal of this project is to analyze different modeling approaches that can be applied to an ETLflow. Both teams, ORS and MPS, have expressed interest in having:
• A common way of communication across teams and projects to minimize learning curve, language,and framework dependency
• A generic framework that can interface with the current environments
• Generic ETL steps that can be shared across teams and/or projects to increase productivity
Furthermore, beyond these two projects, there is also an interest expressed to have a uniform wayof designing ETL flows in Océ. Section 1.2 below discusses the projects’ stakeholders and theirrespective interest in this project.
1.2 Project StakeholdersThis section discusses the stakeholders that are relevant for this project. Stakeholders were identifiedafter meeting with most of the team members from both projects in Océ. Detail stakeholder analysisis listed in Appendix A. The stakeholders listed have a direct or indirect influence on this project.Because this project involves two main parties, Océ and TU/e, the list is organized accordingly. Figure1.3 below shows a stakeholder influence vs interest chart.
P. Verduin
T. Paffen
J. Bergmans
J. Dopp
R. Kersemakers
J. Jans
T. Willemse
Y. Dajsuren
C. Azevedo
S. Ayele
J. Hoogendoorn
Infl
uen
ce
Interest
Stakeholder analysis
Trainee
Océ
TU/e
Figure 1.3: Stakeholder analysis: influence vs interest chart
3 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
1.3 Project DeliverablesDuring the given ten month project period, the following are the agreed upon deliverables:• Analysis of challenges faced by both ODAS and CRS in relation to the current ETL flows. This is
presented as a problem analysis document. The requirement analysis will be the result of this.
• Knowledge about modeling ETL flows. This includes identifying and comparing different tech-niques of modeling ETL flows to solve the current challenges of ODAS and CRS. This is deliveredin oral presentations to stakeholders and as part of the final documentation.
• Analysis of a modeling approach that can overcome the main challenges of the current implemen-tations. This is showed by a prototype of chosen ETL flows that can cover at-least the requirementsidentified as high priority.
1.4 Professional Doctorate in Engineering (PDEng) ProgramProfessional Doctorate in Engineering (PDEng) is a technological designer program given under thebanner of 4TU.School for Technological Design, Stan Ackermans Institute. The institute is a jointinitiative of the four universities of technology in the Netherlands, including Eindhoven University ofTechnology (TU/e).
Software Technology (ST) of the Department of Mathematics and Computer Science of TU/e is amongthe PDEng programs offered at TU/e. It is a two-year PDEng program focusing on preparing traineesfor an industrial career as a technological designer, and a software or system architect. The aim of theproject is to fulfill the ten month ST design project for the trainee [2].
4 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

5

Technische Universiteit Eindhoven University of Technology
2 Domain Analysis
This chapter discusses the data warehouse domain and gives an overview of the two data warehousesoftware systems, ODAS and CRS, in the context of this project.
2.1 Data warehouseNowadays, different business information systems produce and store data in various locations. In or-der to give meaning to this data collectively, the concept of a data warehouse was introduced. Kimballet al. [4] defined data warehouse as “the process of taking data from legacy and transactional databasesystems and transforming it into organized information in a user-friendly format.”
The Kimball [4] and Inmon [3] approaches are the two widely accepted data warehouse architectures.Yassad et al. [5] compared these methods for a data warehouse. According to Yassad et.al., bothapproaches involve Extract, Transform and Load (ETL) flows. However, one of their main differencesis in how they model the data warehouse.
The Inmon method is a “Data driven” approach. It uses data models of business platforms as a startingpoint to model the data warehouse. In addition, the approach physically separates data warehouse anddata mart. Data mart is a subset of data stored in a data warehouse to answer a specific businessrequirement.
On the other hand, the Kimball method follows an iterative data warehouse development with a focuson dimensional modeling (See Figure 2.1). Dimensional modeling is the process of designing businessactivities into facts and dimension tables.
Business
Requirements
Dimensional
Modeling
Physical
Design
ETL design
and DevelopDeploy
Figure 2.1: Kimball method
According to Kimball, dimensional models have three main components: grain, fact and dimension.Fact tables capture the subjects of analysis questions. They contain numeric measures that can beaggregated to answer business questions that cannot be answered from the original data only. Dimen-sions embody the context of an analysis. Grain is what a single row in a fact table represents andencompasses the finest level to which a question can be answered. Figure 2.2 shows an example ofa dimensional model for a given Order data model. This way of designing data warehouses is usu-ally dictated by business analysts and their questions [4]. CRS uses the Kimball method to design itswarehouse.
According to the Kimball approach [4], a typical data warehouse is composed of two components:
6 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
the back and front room. These can be deployed into different machines and managed by differentprofessionals. The back room is where data management processes happen. Extracting, transformingand delivering the data to a front room are examples of data management processes. In the front room,query based data processing is performed for analytics and reporting purposes.
Figure 2.2: Example of dimensional model
Dimensional models in data warehouses de-normalize tables based on the business question. Thissimplifies how data is accessed by an analysis tool, such as the On-line Analytical Processing (OLAP)cubes. Dimensional modeling avoids complicated queries resulting from joins to answer questionsraised by the business analysts and other users.
The focus of this project is the back room component of a data warehouse, which is where the ETLprocess occurs. The following section describes the main components of the back room of a datawarehouse.
2.1.1 Staging areaThe staging area in a data warehouse domain involves three main steps; the Extract, Transform andLoad (ETL). These stages will have a snapshot of data either in a temporary or permanent storage.Depending on the architecture of a data warehouse, the staging area can be a physical disk storage ora memory [4].
An ETL flow is a base for data warehouses; taking about 70 percent of the implementation resources[4]. It is a mechanism to collect data, apply quality measure, integrate and finally deliver data fordecision making. The ETL stages are discussed in detail below.
Extract : This is the first stage in an ETL flow. Raw data from different sources are written eitherto flat files or relational tables. The captured data is usually discarded after the next steps (Transformand Load) are performed. The data extracted can be either a complete snapshot or differentials of thedata sources [7].
Transform : In this stage, data from the Extract stage is cleaned and conformed to comply with thetarget schema [4]. Data cleaning can involve human intervention and can include:
• Identifying errors
• Fixing errors and omissions in the data
7 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
• Removing duplicates and invalid values
• Checking the consistency of values
Kimball et.al. [4] group cleaning into three levels:
• Column level: makes sure that the input data is as expected. This includes checking for emptyvalues in required columns, column length and spelling
• Structure level: checks for relationships of columns to each other. This includes referentialchecks (checking for the existence of foreign and primary keys) and Parent-child relationships
• Data and Value level : checks if the data complies with the business rule
The other task that can happen during transformation is ’conforming’. It prepares data for a furtherquerying process done by analytics systems. Data from two sources are merged in this stage, thusqueries can be applied to give useful information. This includes data type conversion and standard-izing different value representations: for example changing M and F values to Male and Female.Kimball et al. considers this an irreversible stage where data is prepared for the dimensional modelstructure [4].
Load : This is the final stage in the ETL flow and propagates the data into a data mart or a datawarehouse. In the Kimball method [4], this involves physically structuring data into dimensionalschema.
2.1.2 Data structureData from remote locations can have different formats and structures. In addition, the data structurein an ETL flow can be different based on the design choices. The following are some data structuresand formats.
Flat File : is a collection of data stored in columns and rows in a file system [4]. A comma-separatedvalues (CSV) file is one example. Based on the operating system where the file is created, data storedin a flat file can have different character code; for instance in UNIX or Windows the standard codeis the American Standard Code for Information Interchange (ASCII). Both CRS and ODAS expectinput CSV files to be UTF-8 encoded, which is a subset of the ASCII standard.
Relational Databases : store data in tables with rows and columns. The tables can have relationswith other tables in a database. In CRS, an SQL based relational database is used.
Hierarchical Data Format 5 (HDF5) : is a portable file format with a versatile data model thatcan represent very complex data objects and a wide variety of meta-data [12]. HDF5 supports: N-dimensional datasets, XML, Binary “flat files”, directories, and PDF. HDF5 file’s data model consistsof building blocks for data organization and specification (refer to Figure 2.3). HDF5 allows compres-sion filters, ZLIB and SLIB, to be applied to a dataset to minimize the amount of space it consumes. Inaddition, a user-defined filter can be applied. ODAS stores the final cleaned data with HDF5 format.Figure 2.3 shows a high level structure of an HDF5 file.
8 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Root Group
Sub-group 1 Sub-group 2 Sub-group n
Dataset 1 Sub-group 2n
Dataset 2
Dataset 3
Figure 2.3: HDF5 high level structure
2.1.3 ETL FrameworksIn the current implementation of CRS and ODAS two different frameworks/libraries are used. CRSuses a Microsoft based ETL framework called SQL Server Integration Services (SSIS), while ODASdoes its ETL flows with a python based library called Pandas. Details of these are discussed below.
SQL Server Integration Services (SSIS) : is a graphical tool that facilitates the ETL process. Itincludes a set of built-in tasks and transformations for generating packages [14]. CRS uses SSISpackages to perform the ETL processes. Some of the SSIS packages are being generated using anXML markup language called Business Intelligence Markup Language (BIML). BIML automatespackage generation for Microsoft SSIS. It has advantages such as increasing productivity and easychange management over the manual SSIS package creation [15].
Pandas: is an open source data manipulation and analysis library based on Python [16]. ODAS usesPandas to extract and integrate the data required for the analysis. In addition, Pandas also has a featureto convert CSV files to HDF5 files.
2.2 ODAS and CRS Domain AnalysisIn this section, the current implementation of ODAS and CRS is described and analyzed in detail.This is achieved by referring to documentation (both source code and text), and discussing with themain stakeholders.
2.2.1 Optimal Data Analysis System (ODAS)ODAS aims to support Océ’s designers, engineers and data scientists by creating a feedback loopbetween the machines in the field and the Research and Development (R&D) team. The data sourcesfor ODAS are the high-end production printers. Currently, ODAS supports two of these printers, theVarioPrint i300 and Colorado 1640. Figure 2.4 shows the high level architecture of ODAS.
9 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 2.4: ODAS high level architecture
The large data storage (LDS) shown in Figure 2.4 was intended to store the final data after processing.However, at the moment there are some issues regarding storage space. Therefore, the CSV files arestored in the LDS server. This situation is expected to be solved and the LDS will be the permanentfinal data storage.
The data collected at the moment are functional logs generated by the printers in the form of a CSVfile format. Hardware error, sensor data and usage are examples of functional logs. These logs canbe as big as 5GB per day per printer. Therefore, ODAS’s architecture is optimized to handle suchbig data by compressing the input CSV files to Hierarchical Data Format 5 (HDF5) files. ODAS usesHDF5 files to satisfy two main requirements: large data handling and storage, and fast data access forlarge files.
ODAS Notebook
Users of ODAS access the data collected from the printers using an ODAS Notebook, which isbased on the open-source Jupyter Notebooks [13]. The ODAS Notebook has the data extraction,pre-processing and visualization layers.
ODAS: ETL system
ODAS’s data extraction layer consists of functionalities to handle all the stages of an ETL flow. How-ever, with the current implementation there is no clear distinction between the data analysis and ETLflow. Below is a brief description of the processes in the current ODAS’s ETL system.
Extract
Functional log (FL) data is extracted from printers in the field using a synchronization mechanismcalled RSync. As can be seen in Figure 2.4, once the FL has reached the staging area, it can be usedby the data extraction layer either on the Data Analysis Platform or ODAS Notebook.
Transform and Load
There are three main functions at this layer: fetching data either from the staging area or the LDS,reading a CSV and converting it to an HDF5 file, and repairing the CSV files. Activity diagram inFigure 2.5 shows the processes to fetch a new data and convert to HDF5 file.
In the scope of this project, the data extraction layer of the ODAS notebook is investigated. This s
10 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 2.5: Activity flow for fetch in ODAS’s data extraction layer
because the data extraction layer is responsible for extracting files from different storage areas andapplying data cleanup and correction. Although, this layer does not have a clear distinction of a stan-dard ETL flow as in [4], the functionalities that could happen in an ETL flow have been implementedin this layer. The data extraction layer was intended to be a part of the Data Analysis Platform (referto Figure 2.4). However, during the period of this project, the Data Extraction is part of the ODASNotebook because of storage issues with the LDS mentioned above.
2.2.2 Customer Reporting Services (CRS)CRS supports Canon and Océ business units and/or processes such as sales and customer relations, inaddition to Canon’s customers. CRS supports these units by analyzing and reporting on the printingbehavior of the Canon office printers.
Figure 2.6: CRS data flow architecture
11 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
The high level architecture of CRS is shown in Figure 2.6. CRS collects data from these varioussources and integrates them to be used by a reporting tool. The reports are used by company or Canonback office customer managers.
Monitoring and Validation
Lavastorm is a component that provides monitoring and validation to data sources (See Figure 2.6).However, not all data sources pass through this layer.
CRS - ETL System
In the context of this project, the ETL and dimensional modeling layer of CRS is investigated, as thisis the layer where data extraction and transformation happens. In CRS, the Kimball method is usedto design and continuously update the Data Warehouse and Mart. CRS uses a dimensional modelingdesign pattern called Star Schema.
The ETL flow in CRS is implemented by the Microsoft SQL Server Integration Service (SSIS). AnSSIS package implementation is taken as an example to further explain the ETL flow in CRS. Anactive flow of such a package is shown in Figure 2.7. The ETL steps covered in CRS are explainedbelow.
Extract : As can be seen in Figure 2.7, the data is received from either Lavastorm or the remoteCanon offices. This data is loaded into a staging area.
Transform : Data from a staging area is transformed. This transformation is mostly done on the data-types, such as changing data-type to match the target. When transformation is completed without afailure, it is stored in a good table in a staging area. If the transformation fails, then data is loaded ina bad table (Refer to Figure 2.7).
Figure 2.7: CRS ETL flow activity diagram
Load : Data integration is performed here. The activity diagram in Figure 2.8 shows a Load stage inone ETL flow in CRS. Data from the good tables are merged and loaded in the final storage, a DataWarehouse designed with Kimball’s dimensional model scheme. Integrity checks are also performedin this stage; to validate if the contents to be loaded into the fact tables and dimension tables are valid.If the load fails, data is loaded to a corresponding bad table in a staging area.
12 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 2.8: CRS Load activity diagram
CRS at the moment uses BIML to generate packages for some stages in the ETL flows. Figure 2.9shows an example of how BIML is used to generate packages using the "ExecuteSQL" component.Using BIML like this with the current data model transformation is one challenge identified by stake-holders. In the current way of using BIML, there are not many components that can be re-used whencreating new SSIS Packages. Therefore, to create new flows new BIML scripts have to be created.
Figure 2.9: BIML usage in CRS for generating SSIS package
13 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

14

Technische Universiteit Eindhoven University of Technology
3 Problem Analysis
In Chapter 2, the high level architectures of both ODAS and CRS was discussed. In addition, descrip-tions of the respective ETL flows was elaborated. In this Chapter the main challenges in the currentimplementations of ODAS and CRS in relation to an ETL flow are highlighted.
3.1 Current implementation challengesThe first challenge is the data repair and fetch that occurs as part of the data extraction layer in ODAS.Integrating the repair and fetch in such a way, the process has become more complicated and lessflexible. There is a need to separate the repair functionality from data fetch in ODAS.
The second issue is manual error correction. When an error is encountered during a conversion, thefiles are corrected manually. In ODAS, some of these corrections are hard coded inside the implemen-tation code, making maintenance difficult. In the case of CRS, handling new requirements for datacorrection in the ETL stage is difficult. This issue will be tackled by another OOTI assignment andwill not be given emphasis in this project.
The third challenge is slow performance of data analysis. This is specially true in the case of ODAS.ETL stages are performed on demand when data is requested by the users and performed every timeagain. This has resulted in a slow performance of data analysis. This is mainly because reading datafrom a CSV file and converting it to an HDF5 file takes time.
The fourth issue is lack of re-usability of components. There are repetitive processes in the ETLflows that are not being re-used. As a result, every time there is a new ETL scenario to be added,these processes are created from scratch. As a result, development time is spend in these repetitivetasks. In CRS, using BIML is being used to generate SSIS packages. However, it has not beenapplied to all processes. This is specially seen with the packages used to generate dimensional modeltransformations. With the current BIML scripts, there are a lot of hard-coded sections. This hasdiminished the usage of a package generator (BIML). Therefore, one has to copy-paste scripts writtenand change the hard coded parts, instead of just re-using sections to create new flows.
Lastly, there is a high learning curve for new people joining a team, specially in the case of CRS. Thisis because at the moment there is no way of describing ETL flows in a high level of abstraction andhide the complex implementations.
The next section discusses the project scope based on the challenges listed above.
3.1.1 Problem scope definitionSection 3.1 discusses the challenges of the current implementation of the two data warehouses, ODASand CRS, in Océ. In this section, the scope of the project is defined based on the domain analysis ofSection 2.2 and the project goal.
Conceptually, these two products share similar ETL processes. However, their implementation has
15 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
followed two separate directions resulting in different challenges. This project does not try to mergethe two products into one and come up with a solution route. This is because the two data warehouseprojects have their own specific requirements. Therefore, coming up with one solution route does notmake sense.
This project focuses on finding a methodology to model processes in ETL flows (such as transforma-tions) to optimize re-usability. By doing this, Océ can have a methodology to design and share theseprocesses to avoid repetitive implementation tasks. Thus, reducing the cost of adding new flows It alsotries to find ways the team members can show an overview of the design so that they can communicatebetter across teams and internally.
16 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

17

Technische Universiteit Eindhoven University of Technology
4 Requirement Analysis
In this section, system use-cases and requirements are discussed in detail based on the stakeholder,problem and domain analysis explained before.
In the scope of this project, priority level of the requirements were differentiated with three terms;Must, Should, and Could. Those described with "Must" have the highest priority to emphasize thatit has to be satisfied, while requirements with "Should" and "Could" have medium and low priorityrespectively.
4.1 Use-casesBased on the problem analysis, three main system use-cases have been identified. These are shown inFigure 4.1 with their extensions. The detailed descriptions of these use-cases are listed in AppendixB using the Cockburn’s use-case template (refer to Appendix D). The actors are ETL Designers anddevelopers. These are people who are designing and implementing ETL flows.
Figure 4.1: Use-cases for a generic ETL framework
4.2 Functional and Non-RequirementsFunctional and non-functional requirements are listed in Tables 4.1 and 4.2 respectively. Require-ments are addressed based on priorities. Acceptance criteria are also listed for those with the highestpriority.
18 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
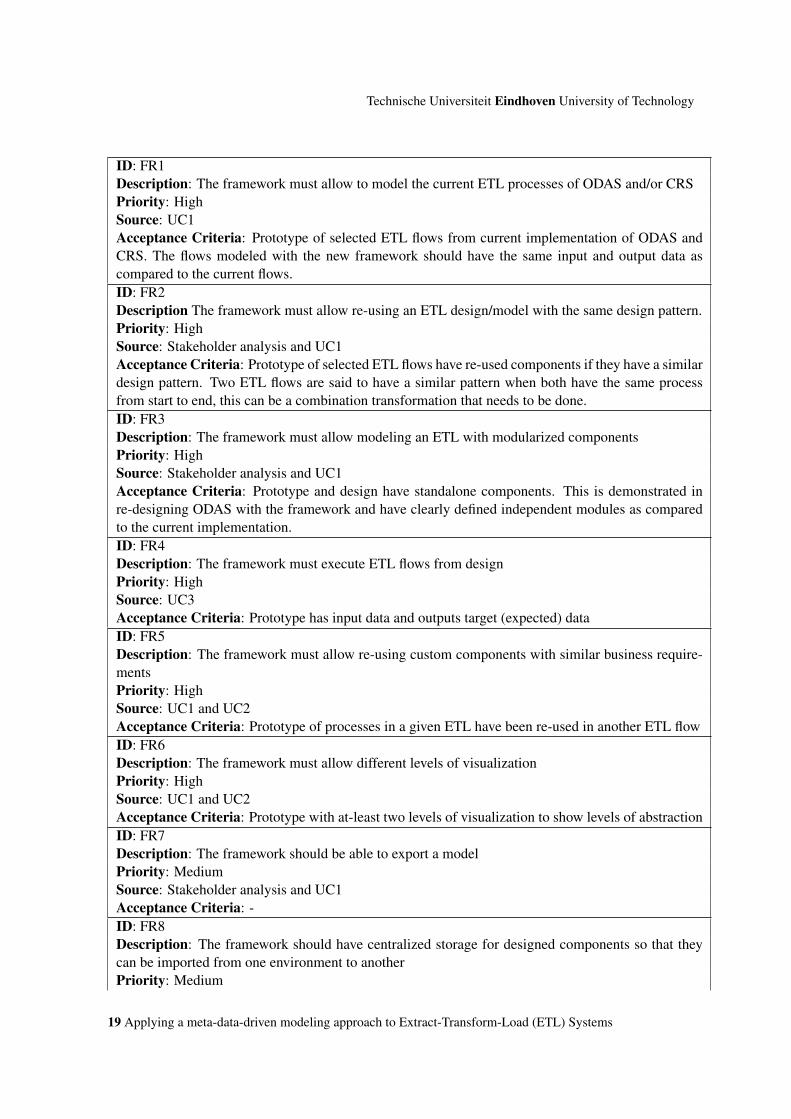
Technische Universiteit Eindhoven University of Technology
ID: FR1Description: The framework must allow to model the current ETL processes of ODAS and/or CRSPriority: HighSource: UC1Acceptance Criteria: Prototype of selected ETL flows from current implementation of ODAS andCRS. The flows modeled with the new framework should have the same input and output data ascompared to the current flows.ID: FR2Description The framework must allow re-using an ETL design/model with the same design pattern.Priority: HighSource: Stakeholder analysis and UC1Acceptance Criteria: Prototype of selected ETL flows have re-used components if they have a similardesign pattern. Two ETL flows are said to have a similar pattern when both have the same processfrom start to end, this can be a combination transformation that needs to be done.ID: FR3Description: The framework must allow modeling an ETL with modularized componentsPriority: HighSource: Stakeholder analysis and UC1Acceptance Criteria: Prototype and design have standalone components. This is demonstrated inre-designing ODAS with the framework and have clearly defined independent modules as comparedto the current implementation.ID: FR4Description: The framework must execute ETL flows from designPriority: HighSource: UC3Acceptance Criteria: Prototype has input data and outputs target (expected) dataID: FR5Description: The framework must allow re-using custom components with similar business require-mentsPriority: HighSource: UC1 and UC2Acceptance Criteria: Prototype of processes in a given ETL have been re-used in another ETL flowID: FR6Description: The framework must allow different levels of visualizationPriority: HighSource: UC1 and UC2Acceptance Criteria: Prototype with at-least two levels of visualization to show levels of abstractionID: FR7Description: The framework should be able to export a modelPriority: MediumSource: Stakeholder analysis and UC1Acceptance Criteria: -ID: FR8Description: The framework should have centralized storage for designed components so that theycan be imported from one environment to anotherPriority: Medium
19 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Source: UC1 and UC2Acceptance Criteria: -ID: FR9Description: The framework should be flexible to handle future components to satisfy new use-casesand requirementsPriority: MediumSource: Stakeholder analysis and UC1Acceptance Criteria: -ID: FR10Description: The framework should be flexible to create new componentsPriority: LowSource: UC2Acceptance Criteria: -
Table 4.1: Functional Requirements
ID: NFR1Description: The framework must have a license that can be used by OcéPriority: HighSource: Project goalAcceptance Criteria: Accepted by the IP departmentID: NFR2Description: The framework must be usable by both ODAS and CRSPriority: HighSource: Stakeholder analysis and UC1Acceptance Criteria: Prototype with selected and most important components of ODAS and CRSID: NFR3Description: The framework should make adding new flows more efficientPriority: HighSource: Stakeholder analysisAcceptance Criteria: Since this requirement is a result of hard coding, the prototype must havere-usable components used for those process that have been seen in other flows/stages.ID: NFR4Description: The framework should have active supportPriority: MediumSource: Stakeholder analysisAcceptance Criteria: - Table 4.2: Non-functional Requirements
20 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
5 Modeling Alternatives and Decisions
This chapter discusses the alternatives for modeling ETL systems based on the requirement analysis.
5.1 Modeling ETL processesModel driven software development (MDSD) is an approach where models play a crucial role to rep-resent a process in a given domain. A model is an expression that describes a system under study [19].The Object Management Group’s (OMG) Model Driven Architecture (MDA) provides an approachfor deriving values from models in support of the full software systems’ life cycle.
In MDA, one of the components is a model, and may represent domain-specific aspects of a system[23]. Models can be either platform-independent or platform-specific (refer to Figure 5.1). The OMGspecification for MDA defines these categories as follows: "A platform is a set of subsystems andtechnologies that provide a coherent set of functionality through interfaces and usage patterns. Whena model of a system is defined in terms of a specific platform it is called a "Platform Specific Model"(PSM). A model that is independent of such a platform is called a "Platform Independent Model"(PIM)". A UML model used to describe a software system is one example of a PIM, while Pythoncode generated from such a model is a PSM [23]. In the case of ODAS and CRS, the Python scriptsand SSIS packages used can be mapped to PSM in MDA.
Platform Independent
Models (PIM)
Platform Specific Models (PSM)
OMG Standard Modeling Languages
Domain Specific Languages and Others
General Purpose Languages
Others
Transformed
Expressed Expressed
Figure 5.1: Overview of model driven architecture
The other component in MDA is a modeling language. According to the MDA specification, modelsmust be “expressed in a language understood by stakeholders and their supporting technologies”. Amodeling language is thus composed of notations, syntax, semantics, and integrity rules to expressa model. Modeling languages are defined with models called meta-models. Models conform to themeta-models that are used to define them. UML, BPMN and XML-schema are examples of the OMGStandard modeling languages [23]. Domain Specific Languages, such as DSLs created with MetaProgramming System (MPS), are grouped in other non-OMG standard modeling languages.
21 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Models can be used to create other models based on transformation patterns. In this way, the concep-tual content can be used to create another representation of the model. In most cases, PIMs are inputfor the transformation to PSMs, for example, a UML class model transformed to a Python class.
In summary, models can be used to
• Formalize the system development process to facilitate communication by specifying software com-ponents with PIM. For e.g. a UML description a software artifacts can be used to communicate withdifferent stakeholders from requirements to deployment phase. This also includes writing the im-plementation code using the specifications described using PIM.
• Drive the development from end-to-end by transforming design specification in PIM to PSM without manually wiring source code.
The following section reviews literature that focuses on modeling ETL flows and lists the pros andcons.
5.1.1 Modeling ETL activities as graphs using custom constructsVassiliadis et.al. in [27–29] showcased the usage of custom constructs to model ETL flows. Accordingto Vassiliadis et.al., their work has two goals. The first is to facilitate smooth redefinition and revisionefforts, and serve as a means of communication. The second purpose is to document and formalizethe particularities of data sources with respect to a data warehouse. Their work led to a frameworkshown in Figure 5.2 called ARKTOS-II [30]. Custom constructs are those that are defined by the teamitself, thus, does not follow any standard modeling language.
Figure 5.2: ARKTOS [8] describing a flow
Their work is limited to logical abstraction of ETL processes and the architecture is composed of threelayers: Meta-model, Template, and Schema layer (refer to figure 5.3). The schema layer describes aspecific ETL scenario. The components in this layer are instance of the components in the meta-modellayer. The template layer is a sub-set of the meta-model layer and it can be taken as a meta-class.However, they are customized for ETL cases.
They argue that the standard modeling language UML does not treat attributes as first-class-citizen.Treating attributes as first-class-citizen is important because an operation done in an ETL process
22 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
involves manipulating the columns in data, and attributes represent columns in a given data. Therefore,they opted for using custom constructs to describe ETL activities.
Figure 5.3: Overview of the ARKTOS framework for modeling ETL activities [27]
Pros:
• The concept can be extended with other domain specific languages such as Jetbrains MPS
• ARKTOS’s Java implementation exists, thus can be re-used to extend since it is under an open-source license (provided the license can be used by Océ)
Cons:
• Their original work is limited to a conceptual modeling of ETL flows. Thus, it does not includea transformation to some form of implementation code (PSM). This will add an extra overheadto generate code as the transformation has to be built from scratch, i.e., if this work is to beextended to an operational framework.
• ARKTOS’s implementation is no longer supported, thus it takes more effort to maintain theexisting code base.
5.1.2 UML BasedTrujillo et.al. [31] used UML to model an ETL process in a data warehouse. They argued that theirapproach can help the design of an ETL system from two points of view: providing a general overviewand a detailed description of processes in an ETL flow. They used UML stereotypes to compensatefor UML’s lack of treating attributes as a first-class-citizen (See example given from [31] in Figure5.4). Similar to the Vassiliadis et.al., their work is also limited to specification of ETL processes, and
23 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
does not cover transformation of models to implementation code.
Figure 5.4: An example of using UML for ETL processes with custom stereotype icons [31]
Pros:
• UML is an OMG standard, thus many tools can be used to extend this work, for exampleEnterprise Architect that is used in Océ.
• Because UML is a standard modeling language, it can be extended to generate source code withother open-source transformation plug-ins.
Cons:
• Like the custom constructs work, this research is also limited to a conceptual modeling of ETLflows. It does not include transformation to some form of implementation code.
• Even though there are plug-ins that can generate source code from UML, extra work still has tobe done to make this operational in a real system.
5.1.3 BPMN BasedAkkaoui et.al. [32] described conceptual modeling of ETL flows using Business Process ModelingNotation (BPMN), another OMG standard modeling language. In this work, ETL flows are expressedas a combination of control and data processes. The Control process is used for a high level overviewof an ETL process. The data process view captures the original nature of an ETL process. It managesthe branching and synchronization of the flow, and handles execution errors (refer to figure 5.5). Theyalso extended their work in [33] to transform models to vendor-specific code using model-to-text(M2T) and model-to-model (M2M) transformation for maintaining and evolving models.
24 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 5.5: An example of using BPMN for ETL processes [33]
Pros:
• BPMN is an OMG standard, thus many tools can be used to extend this work, for example,Enterprise Architect that is used in Océ.
• It covers end-to-end transformation (from Modeling to code generation).
Cons:
• Not many people are familiar with BPMN in Océ; therefore there could be a higher learningcurve to introduce this.
• The language to model the ETL process is provided, however, all processes specific to ETL(such as transformations) have to be modeled taking into account the ETL domain. This mightlead to a maintenance issue in the long run and addition of an extra overhead.
5.1.4 Common warehouse meta-model (CWM) based: Meta-data driven approachCommon Warehouse Meta-model (CWM) is an OMG standard specification for modeling meta-datadescribing data resources, such as relational and non-relational data, and other components of a typicaldata warehouse environment [24]. This specification is an approach focused on interchanging meta-data between software systems. According to the specification, the CWM is based on OMG’s.
• Unified Modeling Language, UML.
• Meta Object Facility, MOF, a meta-modeling and meta-data repository standard
• XML Meta-data Interchange, XMI, used to interchange data warehouse meta-data based onCWM meta-model
This results in models that are not dependent on hard-coded logic. Instead, models can be extendedby changing the active object model at runtime [25].
Meta-data is an information that describes about the data. In the case of a data warehouse, an exampleof a meta-data is shows in Figure 5.6. In the example, it shows an Order data with columns Order_Id,Date and Status structured in table. The meta-data shown in this case is the information about thecolumns.
25 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Order_Id
1
2
3
Date
1/1/2016
1/10/2016
11/9/2017
Status
Sold
Pending
Pending
Column
Order_Id
Date
Status
Datatype
Integer
Date
String
Meta-data
Figure 5.6: Example of meta-data
Pros:
• It uses a standard modeling language and meta-data exchange format. This makes it easier toextend models since the meta-model used to define UML is also standard.
• The basic idea behind this methodology is usage of meta-data and changing the model. Onegood example is using this to create generic models and pass meta-data and/or data at runtime.
Cons:
• Similar to the BPMN based, although the modeling language is provided, one has to define theETL processes in order to model an ETL flow. This will add some overhead.
5.2 DecisionsIn Section 5.1, some alternatives for modeling ETL flows were discussed. Based on this research, thissection gives in detail the decisions made in what way to model the ETL flows.
5.2.1 Modeling current ETL flowsTaking the modeling research discussed into account, the domain model of the current implementa-tions of ETL flows were analyzed. This led to a meta-model of the components and is shown in Figure5.7).
A Concept is a generic building block used to express data input-output handler, a transformation, anda relationship between these. It can be a built-in component in tools like SSIS or can be defined witha DSL or other modeling language. Data is manipulated using ETL processes called transformations.Example of concepts is shown in Figure 5.8 resulting from the domain study in Chapter 2. Forexample, the Reader Concept has a function to read content from either CSV file or a table in an SQLDatabase. While a Convert can have a function to change a data type.
Concept
Input-output handler
Transformation Relationships
ETL FlowsUse
Is A
Figure 5.7: Concept for modeling ETL flows domain model
26 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 5.8: Concept definition
Based on these high level Concept definitions, there are several modeling language options to createthese Concepts (as discussed in Section 5.1). Using modeling languages such as UML or creating do-main specific languages (DSL) are two option. The other option is using frameworks that have alreadyimplemented the basic Concepts. Taking into account the project period and the goal, using frame-works that have the basic Concept definitions were the best way forward. This is further elaborated in5.2.2.
The other aspect is the choice of modeling methodology to cover requirements of re-usability, FR2and FR5. The methodology chosen is the meta-data-driven approach stated under the OMG’s speci-fication of Common Warehouse Meta-model (refer to Section 5.1). By adopting the meta-data-drivenapproach, a template based design can optimize the re-usability of ETL processes.
A high level architecture of a meta-data-driven ETL process template is shown in Figure 5.9. An ETLprocess describes the transformation of source data to a target data by a making use of one or moreConcepts. During the rest of the project, this methodology was prototyped using the selected ETLflow case-studies from ODAS and CRS.
The proposed solution approach aims to increase re-usability of components to reduce repetitive de-sign (Refer to NFR3 in requirement list in chapter 4 ). This is achieved by abstracting from the actualdefinition of data during design. Instead, using the structure of meta-data during the design of ETLflows.
ETL Process Template
Input Data
Input meta-data
Uses to define
Target Data
Target meta-data
Output
Input
Input
Uses to define
Figure 5.9: Proposed solution: meta-data-driven approach for modeling ETL flows
5.2.2 Framework choice for prototyping the case-studiesA list of ETL frameworks, including framework used to create the ETL flows in CRS, SSIS, werecompared. The criteria used in the comparison matrix were derived from the requirements listed in
27 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Chapter 4, in addition to support for meta-data-driven design. The 2017 Gartner Magic Quadrant forData Integration Tools was also referenced [34].
A summary of how the comparison of the frameworks was done is shown in Tables 5.1 and 5.2. Inthese tables, the current technologies used in ODAS and CRS, Pandas and SSIS, are compared withtwo data integration tools, CloverETL and Pentaho. The comparison criteria are requirements thathave high priority.
CloverETL is a Java based data integration tool. It consists of a design and an execution environment.CloverETL has open source and enterprise licenses. In addition, CloverETL includes a proprietaryhigh level language, CloverETL Transformation Language (CTL) [36]. Pentaho is an open sourceBusiness Intelligence (BI) suite that covers the full spectrum of BI life cycle including ETL, reporting,analytics, visualization, and data mining. In this comparison, Pentaho’s ETL tool was the focus.
Requirements Detail CloverETL Pentaho Pandas SSISFR1:The framework mustmodel the current ETLprocesses of ODAS and/orCRS.
Built-in HDF5 writer ortransformation
5 5 3 5
Built-in SQL table readerand writer
3 3 3 3
Built-in CSV reader andwriter
3 3 3 3
FR2:The framework mustallow reusing an ETL de-sign/model with the samedesign pattern.
Has Built-in meta-data ed-itor
3 3 5 5
Allows dynamic values toall of its built-in compo-nent fields
3 5 3 3(using BIML 1)
FR3:The framework mustallow modeling an ETLwith modularized compo-nents (on ETL stage level).
- 3 5 5 5
FR4:The framework mustexecute ETL flows fromdesign.
Allows running scheduledETL flows as executable
3 3 3 3
FR5:The framework mustallow re-using customcomponents with similarbusiness requirements.
Allows parametrization ofall fields in built-in compo-nents
3 5(only some2) 5 3(using BIML)
FR6:The framework mustallow different levels visu-alization.
Allows levels of abstrac-tion of ETL design de-scription
3 3 5 5
Table 5.1: Framework Alternative Comparison Matrix – Functional Requirements
2BIML supports meta-data-driven SSIS package generation2Refer to [37]
28 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
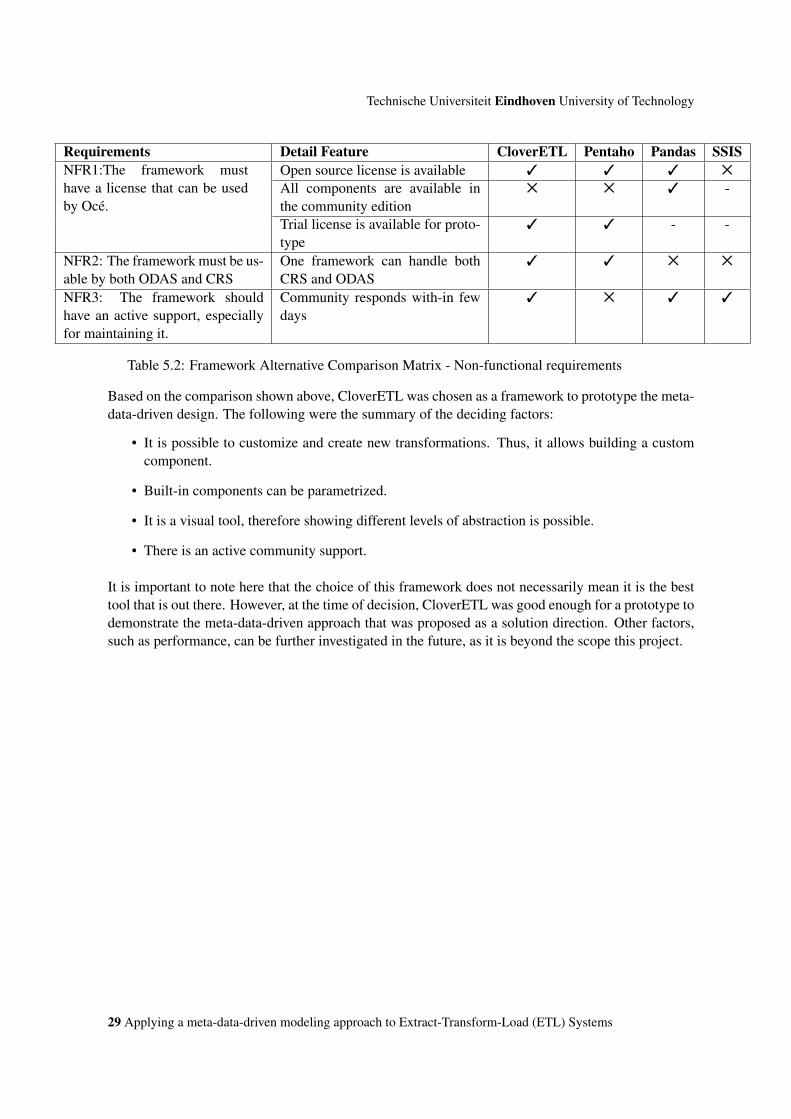
Technische Universiteit Eindhoven University of Technology
Requirements Detail Feature CloverETL Pentaho Pandas SSISNFR1:The framework musthave a license that can be usedby Océ.
Open source license is available 3 3 3 5
All components are available inthe community edition
5 5 3 -
Trial license is available for proto-type
3 3 - -
NFR2: The framework must be us-able by both ODAS and CRS
One framework can handle bothCRS and ODAS
3 3 5 5
NFR3: The framework shouldhave an active support, especiallyfor maintaining it.
Community responds with-in fewdays
3 5 3 3
Table 5.2: Framework Alternative Comparison Matrix - Non-functional requirements
Based on the comparison shown above, CloverETL was chosen as a framework to prototype the meta-data-driven design. The following were the summary of the deciding factors:
• It is possible to customize and create new transformations. Thus, it allows building a customcomponent.
• Built-in components can be parametrized.
• It is a visual tool, therefore showing different levels of abstraction is possible.
• There is an active community support.
It is important to note here that the choice of this framework does not necessarily mean it is the besttool that is out there. However, at the time of decision, CloverETL was good enough for a prototype todemonstrate the meta-data-driven approach that was proposed as a solution direction. Other factors,such as performance, can be further investigated in the future, as it is beyond the scope this project.
29 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

30

Technische Universiteit Eindhoven University of Technology
6 Design and Realization
This chapter discusses how the requirements listed in Chapter 4 are realized. It includes detaileddesign and a prototype of the chosen ETL case studies.
6.1 Design of ETL building blocksIn this section, ETL building blocks are identified based on the proposed meta-data-driven designsolution direction.
Accordingly, three building blocks, shown in Figure 6.1, were proposed. These are Concept, ETL Pro-cess, and ETL Stage. These are used to realize the meta-data-driven design concerning requirementsFR2, FR3, FR5 and NFR3. A detailed explanation of each building block is given below.
Figure 6.1: Overview of building blocks
6.1.1 ConceptBased on the definition given in Section 5.2, the building block ’Concept’ is further elaborated here.It has a function to perform generic actions to handle data input-output and manipulate data. Forexample, for a ’Reader’ Concept to read data from CSV, it should have the function to get the data froma file. When designing a flow using these building blocks, the input and target data are representedby meta-data. This means, the function is defined with this meta-data, which serves as a placeholder
31 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
for the actual data. Furthermore, functions in the Concepts are parameterized. Taking the example ofa ’Reader’ Concept, a parameter in the function that reads data is the ’FileUrl’, to read from differentlocations.
Parameters are defined once, and values are passed when the block is used in a flow. In this way, aConcept can be used in different ETL designs. A detailed explanation of the usage of meta-data andparameters is given in Section 6.1.4. Every time an ETL process is executed, this function is invoked.
6.1.2 ETL processAn ETL process is used to describe ETL scenarios by combining Concepts. Since, it makes use ofConcepts, by extension, it uses the Concepts’ functions to manipulate data. Like Concepts, duringdesign, an ETL Process also uses meta-data of input and output as placeholders for the actual data.Actual data can then be passed from an ETL process to Concept when ETL flows are executed. Takingthe case of loading a dimension as an example, one can design the ’Load Dimension’ ETL Process bymaking use of different Concepts.
A given ETL process can embed other ETL Processes; in most cases, this is to cover specific ETLscenarios. One example is when loading measures in a fact table, the process of inserting all measurescan involve different processes. One can choose to break down these processes and wrap them in onebig process. As one big process, this Load Dimension ETL Process can not be used in other ETLcases; mainly because loading different dimensions could require different processes. But by usingindividual sub-processes, re-use by other cases is made possible. This is demonstrated in Section 6.4.2for the CRS case study.
To further optimize the re-usability, a proper way of defining ETL processes is important. The bestpractice proposed here is to aim for creating ETL Processes that do not necessarily have to be for aspecific ETL use-case. In this way, one can create more generic ETL Processes to use across differentuse-cases. Specific ETL Processes are those related to a certain ETL use-case. For instance, ’LoadingMeasures’ are specific to ETL flows involving dimensional models. More details on this are given inSection 6.3.
The best practice proposed is recommended as it can reduce the development time when adding newETL use-cases. For example, the release cycle for adding new CRS ETL flows can take up to two/threemonths. ETL flows could take up 70 percent of implementation resources [4]. Using the proposedsolution, by creating re-usable processes, designers can avoid repetitive tasks in the release cycle andsave development time when adding new Flows. In addition, updates to the generic processes can bemade in one place. Thus, when new requirements arise and changes are applied to the small process,the changes can reflect in the existing flows.
The more an ETL process definition is not attached to a specific use-case, the more usable it can beacross different use-cases. This argument is illustrated by the prototype design and realization of theCGSTarget flow. Section 6.1.4 shows an example of the usage of the building block to create an ETLprocess that sorts and aggregates input data.
6.1.3 ETL stageAn ETL Stage is used to describe the whole ETL flow or any of the steps in an ETL flow. Theessential difference between ETL Stage and Process is the generalization level. An ETL Process isused to describe specific parts of ETL flow. While an ETL Stage describes the common aspects of anETL flow such as configuration of an execution sequence or detection of new CSV files in a repository.
ETL Stage is a combination of parameterized ETL processes. An ETL Stage can also be parameterized
32 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
to re-use in flows with a similar pattern. For example, in ODAS for different functional logs thetransformations required are the same but located in different locations. Therefore, one can design anETL Stage that has the required ETL processes and parametrize the location of the functional logs. Insome cases, this building block can also be used just for simplifying and visualizing complex flows.
6.1.4 ParametersParameters are placeholders, for the values that affect how the data is transformed when a Conceptfunction is invoked. It is an important aspect of the proposed meta-data-driven design. Values arepassed from a higher block (either ETL Stage or Process) to a lower level (an ETL Process or Con-cept). For parameters to be part of this design, Concepts must allow parameterizing.
As an example, in Figure 6.2 a generic ETL process "Sort and aggregate" is defined using "Sort"and "Aggregate" Concepts. To use this ETL process values must be passed to the "SortKey" and"AggregateFields" parameters to the corresponding Concept (during or before execution). Dependingon the Design, parameters can be exposed once the ETL Process is defined using these Concepts.
Figure 6.2: Example of the design of an ETL process6.1.5 Meta-dataIn the proposed design solution, the expected meta-data is the signature of data in the context of a givenETL flow. At any step in an ETL flow, processes manipulate data to match the target structure. Insteadof designing a given ETL process with the actual data, meta-data is used as placeholders for the actualdata. The actual data, for instance, can be passed during execution time. In this way, components canbe re-used for other use-cases. Figure 6.3 shows how meta-data and data are passed to the "Sort andAggregate" process at runtime. The same process can be re-used with another meta-data/data input.
Column
Order_Id
Date
Amount
Type
Integer
Date
Integer
Order_Id
1
2
3
Date
1/1/2016
1/1/2016
11/9/2017
Amount
100
10
36
Parameter
SortKey
AggregateFields
Value
Date
Amount
<<flow>>
<<flow><<flow>>
<<flow>>
<<flow>>
Figure 6.3: Example of meta-data and parameter usage during execution
6.2 Design of ETL flows using the building blocksIn this section, the usage of ETL building blocks is discussed. To take full advantage of the proposedsolution, it is recommended to follow some steps. These steps are compiled from the lessons gatheredafter analyzing the case-studies. The steps involve identifying:
33 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
• Meta-data for input and target data
• Transformations needed to manipulate and change the input data to a target data
• Parameters needed to make functions in the Concept re-usable
• Patterns (of process and data input combination) that can be re-used in a practical way
The proposed solution is trying to optimize the re-usability of components. To achieve a proper levelof re-usability, one should look into more ETL flows to find a good pattern. This is helpful to decideif a given ETL process should be designed either as a specific or generic ETL Process.
One has to be cautious when deciding which parameters to expose as it can be challenging to maintainand keep track of parameters. One example is the following: an ETL Process with the same two ormore generic ETL Processes that have the same parameter will not help the designer understand thedesign. Furthermore, it can cause unexpected results during execution as values might be passed tothe wrong process. In addition, creating one big process that appears to be like a ’God’ class mightalso be difficult to maintain and re-using such a process in different ETL cases will be a challenge.
6.3 Case study selection for prototypeThis section discusses the selection of ETL case studies for prototyping the meta-data-driven ETLdesign.
To verify the system requirements are satisfied with the proposed solution direction, ETL flows fromboth ODAS and CRS were chosen as case studies. The ETL flows in Figures 6.4 and 6.5 are theselected case studies to prototype. For CRS case, ’CGSTarget’ is one of the ETL flows implementedwith SSIS. CGSTarget is flow handling the device (printer) installations per global account per coun-try. In the case of ODAS, functional log data are collected from printers in the field to improve theprinters. The flows shown in Figures 6.4 and 6.5 are very high-level descriptions, and detailed designsare discussed in section 6.4. The choice of ETL flows as case studies was dictated by the followingfactors:
• Patterns of ETL processes. For example, retrieving data from a CSV file is the starting pointfor both ETL flows of CRS and ODAS.
• Processes that are unique to either CRS or ODAS. For instance, the process of convertingCSV to HDF5 file is unique to ODAS.
• Processes identified by stakeholders as a challenge in the current implementations. Forexample, loading data to dimensional models is one challenge that was identified in CRS flows.
Figure 6.4: ETL flow case study from CRS
In this project, built-in components of CloverETL represent the Concepts (Refer to Figure 6.1). Ifa required Concept is not part of the CloverETL’s built-in pool of components, CloverETL supportscreating a custom component [35].
34 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 6.5: ETL flow case study from ODAS
Some pre-conditions were applied to focus on proving the methodology chosen, a meta-data drivenETL design, can indeed solve the current challenges. The following are the pre-conditions consideredfor the prototype:
• Data cleaning is one stage in the ETL domain (refer to domain analysis in Chapter 5). However,there was another concurrent OOTI assignment with a focus on Data quality and cleaning (referto stakeholder analysis in 1.2). As a result, in this project data cleaning was given less emphasis.Nevertheless, some basic data cleaning already happening in the current implementations hasbeen included.
• The meta-data of the data in an ETL flow, is assumed to exist. This means the modeling method-ology does not dictate how to generate these meta-data.
6.4 Realization of Use-case: Model ETL flows with components thatcan be re-usable
In this section, the use-case that covers modeling ETL flows with re-usable components is realized.The acceptance criteria for FR1 is to model the case studies from CRS and ODAS with the chosenmodeling methodology. Furthermore, the execution of a flow should match the input and targets ofthe current implementations. The latter is demonstrated in section 6.4.4.
6.4.1 Case study from ODAS: Functional LogsIn section 2.2.1, the domain analysis of ODAS is given. Based on that, the chosen steps in the ODAS-Fetch is designed with a meta-data-driven approach. ODAS-Fetch retrieved CSVs from a repository,cleans and converts the CSV input to an HDF5 file (Figure 6.6).
ODAS Fetch
ODAS Staging Area
Functional Logs
ODAS LDS
Functional Logs
HDF5 HDF5HDF5
<<flow> <<flow>>
Figure 6.6: ODAS Fetch
The same steps discussed in Section 6.2 were followed to come up with the design shown in Figure6.7. As discussed in chapter 2, CSV files are converted to HDF5 after going through some transfor-mation (including cleanups). In the meta-data-driven design shown below, the parameters needed areidentified referencing the current implementation.
35 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 6.7: Design of the ODAS case study with meta-data-driven ETL Processes
6.4.2 Case study from CRS: CGSTargetCGSTarget flow of CRS was taken as one of the case studies to demonstrate the meta-data-drivendesign discussed in Section 6.1. The transformation to a dimensional model in the ETL flow wasgiven priority, thus discussed here.
Figure 6.8 shows the input data (CgsTargets) and expected dimensional models (two dimensions,DimCountry and DimCgsAccount, and one fact, FactCgs). The ETL process labeled as "CGSTargetFlow" is the current SSIS package implementation that converts the input to a dimensional model. Inthis section, the detailed design and results of a meta-data driven approach applied to this part of theflow are discussed.
In the current implementation of CGSTarget Flow no attempt is made to create re-usable componentsfor dimensional model transformation. The one effort made was using BIML as discussed in Section2.2.2. However, the BIML scripts analyzed cannot be re-used in other scrips, since most of them havesome hard-coded logic.
CGSTarget Flow
CGS Staging Area
CGSTargets
CRS Data warehouse
DimCountry
<<flow><<flow>>
FactCGS
DimCgsAccount
Figure 6.8: CGSTarget Flow: Overview of current dimensional model transformation
To realize the meta-data driven approach, steps recommended in Section 6.3 were followed. Thefirst step was identifying all the inputs that are required by the package. After that, processes andfunctions used to transform the input data to a dimensional model were analyzed. This was important,as parameters needed to be defined, in order to re-use them in generalized processes.
The ETL processes involved to load data in the two dimensions, DimAccount and DimCountry, areshown in Figures 6.9 and 6.10. As shown, the ETL processes involved are the same except the additionof one ETL process to load DimCounty, i.e., the Combine generic ETL process.
36 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
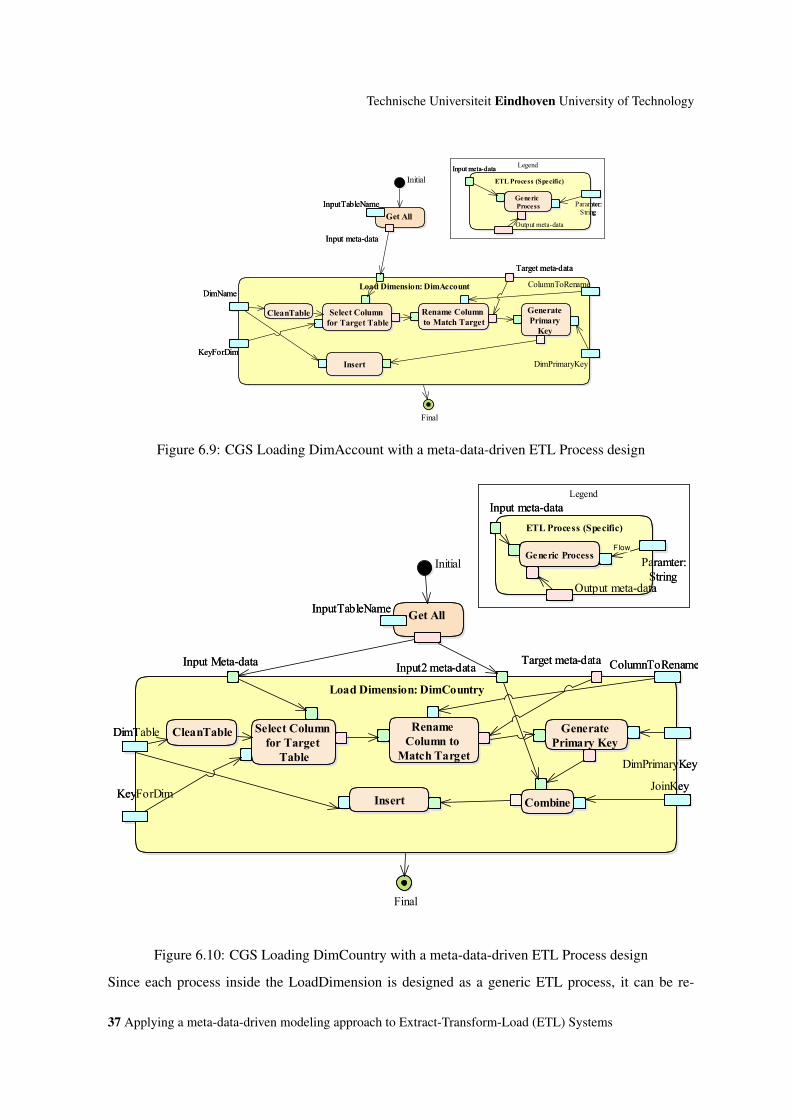
Technische Universiteit Eindhoven University of Technology
Legend
Initial
KeyForDimDimPrimaryKey
DimName
Target meta-data
ColumnToRenameLoad Dimension: DimAccount
KeyForDimDimPrimaryKey
DimName
Target meta-data
ColumnToRename
Select Column for Target Table
Rename Column to Match Target
Final
Insert
Generate Primary
Key
Paramter:String
Input meta-data
Output meta-data
ETL Process (Specific)
Paramter:String
Input meta-data
Output meta-data
Generic ProcessInputTableName
Input meta-data
Get All
InputTableName
Input meta-data
CleanTable
Figure 6.9: CGS Loading DimAccount with a meta-data-driven ETL Process design
Legend
Initial
Input Meta-data
KeyForDim
DimPrimaryKey
JoinKey
DimTable
Target meta-data ColumnToRename
Load Dimension: DimCountry
Input Meta-data
KeyForDim
DimPrimaryKey
JoinKey
DimTable
Target meta-data ColumnToRename
Select Column for Target
Table
Rename Column to
Match Target
Final
Insert Combine
Generate Primary Key
Paramter:String
Input meta-data
Output meta-data
ETL Process (Specific)
Paramter:String
Input meta-data
Output meta-data
Generic Process
InputTableName
Input2 meta-data
Get All InputTableName
Input2 meta-data
CleanTable
Flow
Figure 6.10: CGS Loading DimCountry with a meta-data-driven ETL Process design
Since each process inside the LoadDimension is designed as a generic ETL process, it can be re-
37 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
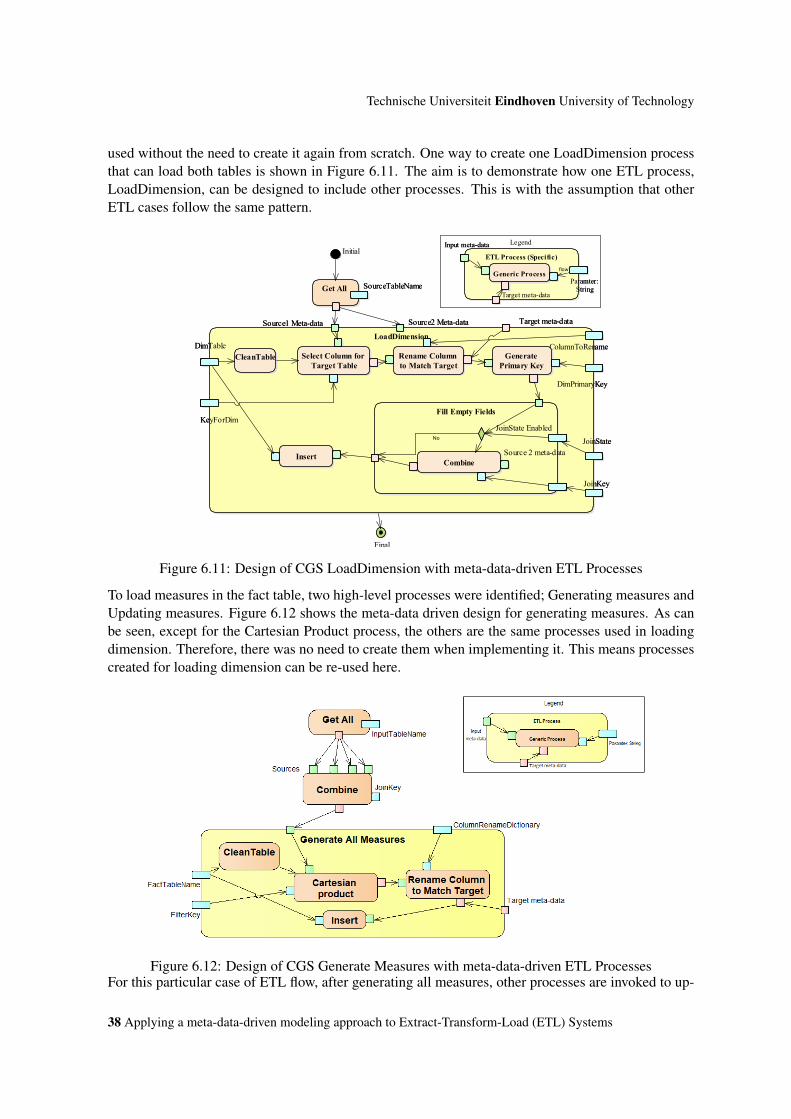
Technische Universiteit Eindhoven University of Technology
used without the need to create it again from scratch. One way to create one LoadDimension processthat can load both tables is shown in Figure 6.11. The aim is to demonstrate how one ETL process,LoadDimension, can be designed to include other processes. This is with the assumption that otherETL cases follow the same pattern.
LegendInitial
KeyForDim
DimPrimaryKey
JoinState
JoinKey
DimTable
Target meta-dataSource2 Meta-data
ColumnToRenameLoadDimension
KeyForDim
DimPrimaryKey
JoinState
JoinKey
DimTable
Target meta-dataSource2 Meta-data
ColumnToRenameSelect Column for
Target TableRename Column to Match Target
Final
Fill Empty Fields
InsertCombine
Source 2 meta-data
JoinState Enabled
Generate Primary Key
Paramter:String
Input meta-data
Target meta-data
ETL Process (Specific)
Paramter:String
Input meta-data
Target meta-data
Generic Process
Source1 Meta-data
SourceTableNameGet All
Source1 Meta-data
SourceTableName
CleanTable
No
flow
Figure 6.11: Design of CGS LoadDimension with meta-data-driven ETL Processes
To load measures in the fact table, two high-level processes were identified; Generating measures andUpdating measures. Figure 6.12 shows the meta-data driven design for generating measures. As canbe seen, except for the Cartesian Product process, the others are the same processes used in loadingdimension. Therefore, there was no need to create them when implementing it. This means processescreated for loading dimension can be re-used here.
Figure 6.12: Design of CGS Generate Measures with meta-data-driven ETL ProcessesFor this particular case of ETL flow, after generating all measures, other processes are invoked to up-
38 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
date the measures. Figures 6.13 shows the ETL Process to update Device measures. While Figure 6.14shows the target and actual measures. Here as well, most of the processes are common. Therefore,they can be designed once as generic ETL processes and re-used for both steps in the Flow.
Figure 6.13: Design of Update device measures with meta-data-driven ETL Processes
Figure 6.14: Design of Update target and actual measures with meta-data-driven ETL Processes
Figure 6.15 shows one way to design the CGSTarget flow. The purpose here is to indicate when anETL Process is found to be used by other steps in the flow, a designer can aim to create it only once,and re-use as much as needed.
Figure 6.15: Design of CGS Target with meta-data-driven ETL Processes
39 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
6.4.3 Realization of Use-case: Visualize an ETL flow on different levelThe last use-case is covered by the choice of an implementation tool, CloverETL. As discussed inChapter 5, ClovetETL has a visual design and an execution environment. In addition, the visualcomponents in the design environment can be programmed with either a high-level language calledthe CloverETL Transformation Language (CTL). CTL is built on top of Java. This is done to hide thecomplexity of data transformation and allowing a uniform access to its components. Figures 6.16 and6.17 show CloverETL’s design environment and sample of the CTL code respectively.
Graph Area
Palettes
Edge
Figure 6.16: CloverETL Environment
Figure 6.17: Example of the CloverETL’s Transformation Language - CTL [36]
The design environment shown in Figure 6.16 includes a Graph area and Palettes. A Graph areais a place where the visual ETL scenarios are created by either dragging and dropping the Palettes.Palettes are components that represent generic data integration Concepts. In the scope of this project,the Graph is where ETL Processes are created. While Palettes are the Concepts proposed in Section6.1. Edge, shown in the figure, is one example a Palett. Edge is used to connect other Palettes andpass meta-data/data. In addition, CloverETL includes a feature called ’Sub Graph’ to show different
40 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
levels of abstraction.
To show the different levels of visualization, ODAS’s CloverETL implementation is shown in Fig-ure 6.18. The realization in Figure 6.18 reflects the ETL Processes discussed in Section 6.4. TheFigure also shows the ETL Process ’Clean_and_Merge’ is composed of two Generic ETL Processes.Such details are realized using Clover’s Sub Graph feature. A third level of visualization is shown inFigure 6.19. For this particular example, in third level Clover’s Reformat Palette are used; mappingthe Palettes to the Concepts discussed in Section 6.1. It is also shown in this Figure the transforma-tion function the Reformat Palette has and how parameters are passed. The function performs datamanipulation.
Generic ETL Process as Clover’s Sub-graph
Meta-data passed during run-time
Parameter
Figure 6.18: CloverETL parameter, graph and sub-graph usage example
Generic ETL Processes as Clover’s Sub-graph
Clover’s Palette used in a Sub-graph
Figure 6.19: Example of CloverETL’s palette usage
Furthermore, CloverETL has a meta-data editor to either extract meta-data from sources such as flat
41 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
files and database or create manually. The meta-data editor is shown in Figure 6.20.
Figure 6.20: CloverETL’s meta-data editor
6.4.4 Realization of Use-case: Execute ETL flowsThis use-case covers executing the flows to transform and load the actual data. To realize this use-case,data from the current CRS and ODAS was used with the designs shows in Section 6.4 above. Accord-ingly, environments similar to the current systems was setup. The summary of the environments andverification method is listed in Table 6.1.
Data Storage Input Target VerificationODAS File System Functional Log -
CSVFunctional Log -HDF5
Jupyter Note-book
CRS MSSQL2012database
CGSTarget DimCountry,DimCGSAc-count, FactCGS
SQL Scripts
Table 6.1: Prototype Environment Setup
In this section, the realization of the design shown above is discussed. For the case of ODAS, the firstimplementation Figure 6.21 shows how to automatically detect new input files and loading the data toa target. This is to show how an ETL Stage can be used to configure common aspects of an ETL flow.For this the same functional log storage repository was duplicated to match the current environment.CloverETL does not have a default HDF5 writer. As a result, using CloverETL’s custom Palette anHDF5 writer was built. The HDF5 writer uses a Pandas library from Python. The meta-data requiredis provided on the edges of the graph.
Figure 6.21: CloverETL Implementation for ODAS to automate file retrieval
42 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Figure 6.22: CloverETL Implementation for ODAS study case
To verify the implementation shown in Figure 6.22 the flow is executed using the functional logs thatin the existing ODAS. Furthermore, using a Jupyter Notebook, it was verified that the logs had beenconverted to HDF5 by extracting the logs.
Similarly, by using the environment configuration listed in Table 6.1, CRS’s CGSTarget design wasimplemented with CloverETL. The result is verified by taking the input data from current CRS envi-ronment. The output from this is compared with the output from the existing CRS SQL Scripts. Theimplementation for loading dimensions is shown in Figure 6.23. The ETL Processes ’Get_All_table’and ’LoadDimCgsAccount’ were implemented once and re-used twice by changing the respectiveparameters. The appropriate meta-data is provided during runtime to the Edges.
Figure 6.23: CloverETL Implementation for CRS study case - loading dimensions
43 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
7 Project Management
This chapter discusses the project management process adopted, including the risks involved and howthey were handled.
7.1 Project PlanThe project plan involved both waterfall and agile methodologies. The plan was revised regularlydepending on the project’s progress, path and risks identified. These changes were continuouslycommunicated with the major stakeholders during project progress and steering meetings. For theten-month project period, eight phases were identified. The first plan created at the start of the projectis shown in Figure 7.1.
Figure 7.1: First iteration of project plan - Gantt chart
By mid February, during the domain and problem analysis phase, it became clear that the approachoriginally outlined was not suited for this project. This is because it became clear that not all stake-holders has the same view regarding what a model-based ETL design is. This has resulted in uncer-tainties in the project path. Therefore, to give stakeholders results they could visualize early on anapproach change was required. Accordingly, an iterative approach was adopted. The final projectplan is shown in Figure 7.2.
44 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
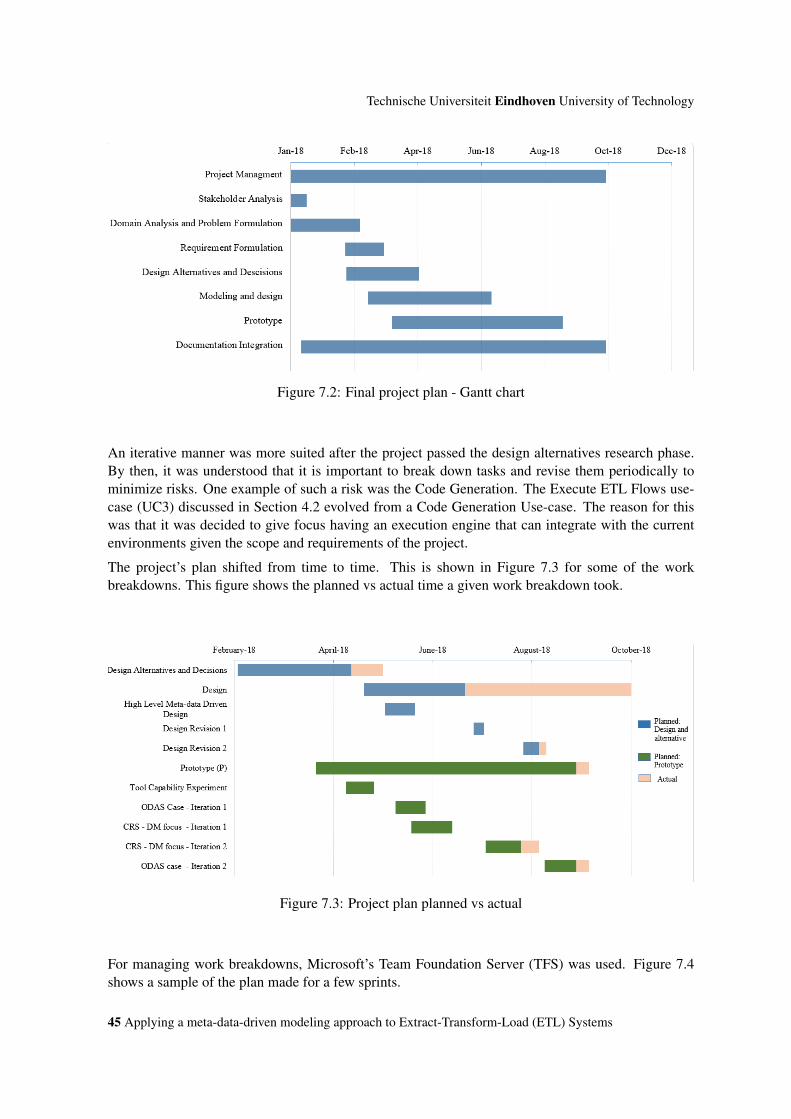
Technische Universiteit Eindhoven University of Technology
Figure 7.2: Final project plan - Gantt chart
An iterative manner was more suited after the project passed the design alternatives research phase.By then, it was understood that it is important to break down tasks and revise them periodically tominimize risks. One example of such a risk was the Code Generation. The Execute ETL Flows use-case (UC3) discussed in Section 4.2 evolved from a Code Generation Use-case. The reason for thiswas that it was decided to give focus having an execution engine that can integrate with the currentenvironments given the scope and requirements of the project.
The project’s plan shifted from time to time. This is shown in Figure 7.3 for some of the workbreakdowns. This figure shows the planned vs actual time a given work breakdown took.
Figure 7.3: Project plan planned vs actual
For managing work breakdowns, Microsoft’s Team Foundation Server (TFS) was used. Figure 7.4shows a sample of the plan made for a few sprints.
45 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
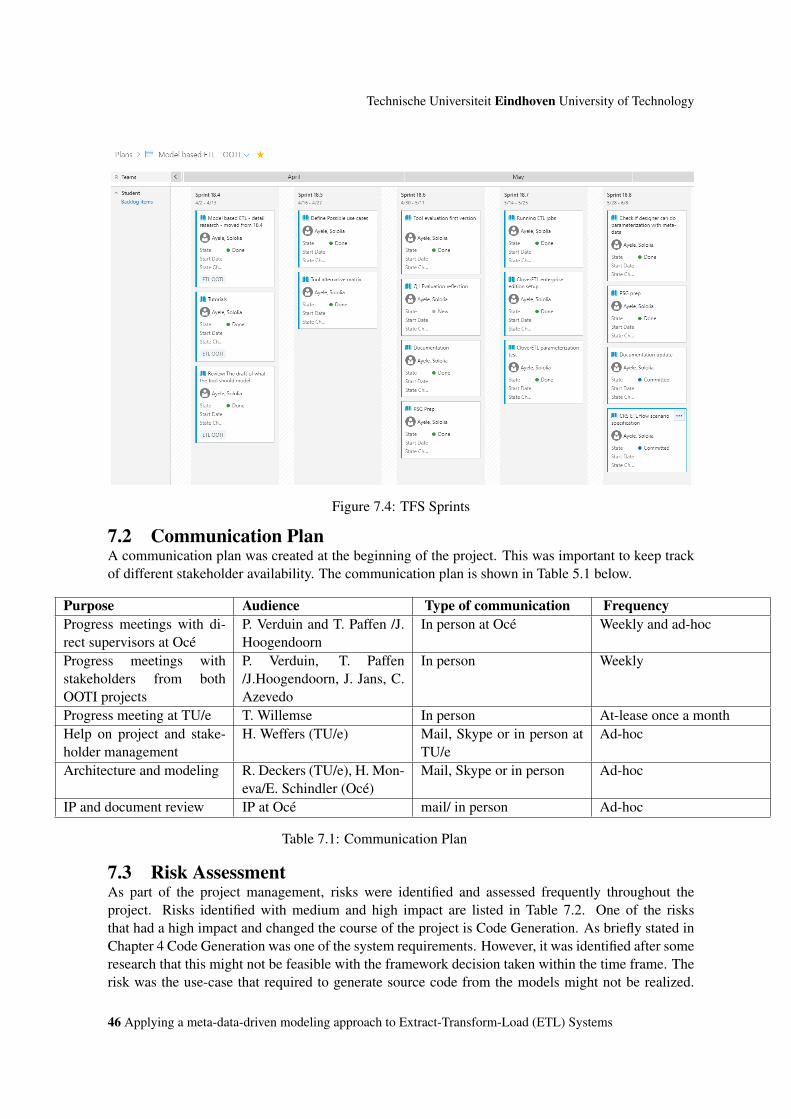
Technische Universiteit Eindhoven University of Technology
Figure 7.4: TFS Sprints
7.2 Communication PlanA communication plan was created at the beginning of the project. This was important to keep trackof different stakeholder availability. The communication plan is shown in Table 5.1 below.
Purpose Audience Type of communication FrequencyProgress meetings with di-rect supervisors at Océ
P. Verduin and T. Paffen /J.Hoogendoorn
In person at Océ Weekly and ad-hoc
Progress meetings withstakeholders from bothOOTI projects
P. Verduin, T. Paffen/J.Hoogendoorn, J. Jans, C.Azevedo
In person Weekly
Progress meeting at TU/e T. Willemse In person At-lease once a monthHelp on project and stake-holder management
H. Weffers (TU/e) Mail, Skype or in person atTU/e
Ad-hoc
Architecture and modeling R. Deckers (TU/e), H. Mon-eva/E. Schindler (Océ)
Mail, Skype or in person Ad-hoc
IP and document review IP at Océ mail/ in person Ad-hoc
Table 7.1: Communication Plan
7.3 Risk AssessmentAs part of the project management, risks were identified and assessed frequently throughout theproject. Risks identified with medium and high impact are listed in Table 7.2. One of the risksthat had a high impact and changed the course of the project is Code Generation. As briefly stated inChapter 4 Code Generation was one of the system requirements. However, it was identified after someresearch that this might not be feasible with the framework decision taken within the time frame. Therisk was the use-case that required to generate source code from the models might not be realized.
46 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
Technische Universiteit Eindhoven University of Technology
The main reason being getting the language definition of a framework and building a code generationfrom that would add maintenance overhead in the long run.
Description: Communication mismatch between two projectsImpact: MediumMitigation Strategy:
• Plan regular updates and progress meetings between two projects together
• Define Project scope with a clear boundary
Description: Project scope is not defined on timeImpact: HighMitigation Strategy:
• By the third month, take control and push to decide the scope of the project
• Discuss with stakeholders on how this will affect the deliverable of the project
• Propose to define the scope in an iterative manner
Description: There is no in-house knowledge on a proposed modeling languageImpact: HighMitigation Strategy:
• Early on discuss with modeling experts in Océ
• Look for input from the people with knowledge around Océ
• Look for experts in TU/e early on and make a contact in case they are needed
Description: Code generation: Meta-model of the tools is not accessibleImpact: HighMitigation Strategy:
• Research for meta-model independent transformations
• Build up the meta-model step by step. This is risky if the tool changes overtime
• Check with the framework’s development team about their experience regarding generating othersource codes that don’t support
• Look into creating a similar tool with known meta-models such as ’ecore/emf’
• Focus on the data (input and output) and execution engine to integrate the proposed solution withthe existing environment. Thus, Code Generation becomes less important
Description: Model based approach is not a way to go to overcome current challengesImpact: High
47 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Mitigation Strategy:
• Research other works in relation to modeling ETL flows
• Define why model based solution is suitable
• Research modeling alternatives to carefully consider all the requirements
• Communicate findings with stakeholders frequently
Description: One of the stakeholders is not happy with the outcomeImpact: MediumMitigation Strategy:
• Prioritize stakeholders and their needs
Description: Framework chosen doesn’t come with a built-in HDF5 writerImpact: HighMitigation Strategy:
• Include in the criteria for generic components to build the converter
• Include in the criteria for components that allow re-using current Python script
Table 7.2: Risks
7.4 ReflectionAfter starting the project, and during the domain analysis phase, it was understood that not all stake-holders had the same vision of the project outcomes and paths. One of the approaches that I took tohelp narrow down the paths was to present my findings to stakeholders regularly. In addition, reachingout and talking to other people in the model-driven domain (both from Océ and TU/e) has helped alot.
Although figuring out the path of this project has been challenging, I have also learned a lot - bothfrom the process and the technical aspect. As a result, the following are some of the rule of thumbsthat I have gathered.
• Power of brainstorming: I learned during this project how useful brainstorming with people is. Thisbrings a fresh perspective and gives lots of ideas. And it can also increase the awareness people inthe company have of the project. Reflecting back on the process, I am satisfied that I was able to dothis when fresh perspective from others was needed.
• Finding a goal when stakeholders do not see eye-to-eye: I learned that looking for alternatives andpresenting the options continuously to stakeholders helps understand requirements. Explicitly defin-ing the goal of a project early on has definably helped pave the way of this project. Furthermore, Ihave also learned that explicitly stating goals and what is expected of a meeting is quite importantto get good feedbacks from stakeholders.
• Prioritizing stakeholders: If there is a lot of pressure from different stakeholders and their need doesnot really match, the following could be options to handle this situation
48 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
1. Bring all the stakeholders to one table and explain the pros, cons, and risks associated witheach conflicting needs. And state clearly why everyone needs to come to one point of view
2. Explicitly agree with everyone what are the goals of the project and expected deliverables.
3. Take control of the project and recommend what is the best way to go forward
• Communicating on a different level of abstraction: This was one of the challenging aspects for mein this project. I learned that not all stakeholders are seeking the same level of details in discus-sions. Therefore, it is important to take into account the levels of abstraction the audience needs toefficiently communicate.
Reflecting on the processes, the one thing I would re-consider now is the time I spend on some tasks.For example, on the domain analysis I spent around three months. This phase included going throughthe current implementations. However, I could have done a lot more if I spent that time in diving intothe modeling approaches and have followed a shorter cycle. Considering the uncertainties and how itwas started, the project has ended up having well defined structure.
49 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
8 Conclusions and Recommendations
8.1 ConclusionsOcé collect data from it’s various printers in the field to either improve the printers or understandthe printer usage. The data is collected and transformed to match the target data warehouses usingsystems called ETL flows. With this project, modeling approaches have been researched and analyzedwith respect to ETL flows to increase productivity of the development team and ease communicationbetween projects’ teams.
At the start of this project, it was discovered that stakeholders did not share one view of what amodeling approach entails in relation to data warehouse domain. The major contribution of thisproject is in helping the stakeholders gain a better understanding of modeling approaches and proposeone that can be applied to the ETL domain of Oc’e. Continuous discussion on new findings has helpedconverge different ideas and opinions.
Sections 5.1 and 5.2 detailed the findings of the research in relation to possible modeling routes.Referencing the Model Driven Architecture, the findings are summered below:• An approach where software models are the key artifacts in software development, i.e., models driv-
ing software development. For instance, a designer can model a system using platform-independentmodels expressed, for example, in UML. Then, using model transformations, such as a model-text,one can generate the source code. Model-to-model transformations also allow transformation fromone model to another [22].
• An approach where models are used for communicating the development process between differ-ent stakeholders. For example, a designer can outline designs using UML to communicate withdevelopers so that the source code written by developers reflect the designs.
Based on these findings, taking into account the current ETL systems’ environments, requirements andproject goal, a meta-data-driven approach was proposed as a solution route. The standard behind theproposed solution is the Common Warehouse Meta-model specification from OMG’s Model-Driven-Architecture (MDA). A meta-data-driven ETL design in which a generic ETL process is defined onceand re-used was proposed. This is further demonstrated in the prototypes of the selected case-studiesfrom current ETL systems in Océ. The result of the prototypes is summarized:• By using meta-data as placeholders for the real data in ETL components during design, components
were made re-usable.
• Parameterization of ETL component’s functions has further optimized the re-usability of such com-ponents.
• By using a visual framework that allows different levels of abstractions to design ETL flows, compli-cated details were hidden. This helped to capture a story in the design and communication purposes.
50 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
• By generating executable ETL designs, it was possible to integrate with the existing environmentsby matching the input and target data environments. This led to a verified and validated output.
In conclusion, by applying a meta-data driven and parameterizable ETL processes, emphasis has beengiven to create re-usable components to minimize repetitive tasks. In addition, by providing a visualtool that allows to show different levels of abstractions, one can communicate complex designs to newmembers in a project or across projects.
8.2 Recommendations and Future worksIn this section recommendations and future works are listed.
Future works
As briefly discussed in Section 6.1, a meta-data-driven approach can be extended to specify othersystem parameters when using the ETL Stage building block. As to what other system parameters canbe generalized is left for future work but example of such parameters is demonstrated using the ODAScase-study. Future work in relation to non-functionals (such as performance of the ETL framework) isrecommended, as the main focus in this project was finding suitable modeling framework to increaseproductivity and ease communications. Extending this work to include other measures will help makethe choice of ETL framework future proof.
Recommendations
In this project, two ETL systems were taken as case studies. There is an interest expressed in hav-ing a uniform ETL framework in Océ. Therefore, it is recommended to analyze the requirementsof other ETL systems in Océ before deciding to have one ETL framework. Furthermore, It is ad-vised to look into more ETL scenarios to come up with better and more re-usable patterns. Whenexposing parameters, one has to be careful on the level of abstraction considering future maintenance,understandability and system behaviors. In this project, to integrate the proposed solution with theexisting environments focusing on the data storage environment was decided. This is to show howOcé could include other environments by picking an execution engine that can handle different datastorage environments.
51 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Bibliography
[1] https://www.oce.com/about/
[2] https://www.tue.nl/en/education/tue-graduate-school/pdeng-programs/pdeng-programs-overview/pdeng-software-technology-st/
[3] B. Inmon, Building the Warehouse, Newyork: John Wiley & Sons, 1996.
[4] Kimball, R. and Caserta, J. Metadata. In R. Elliott (Ed.), The Data Warehouse ETL ToolKit. WileyPublishing, Inc., Indianapolis, USA, pp. 22-36, 2004
[5] L. Yessad, and A. Labiod. Comparative study of data warehouses modeling approaches: Inmon,Kimball and Data Vault, System Reliability and Science (ICSRS), International Conference, Paris,France, 15-18 Nov. 2016
[6] P. Vassiliadis, A Survey of Extract-Transform-Load Technology, International Journal of DataWarehousing Mining, 2009
[7] P. Vassiliadis, A. Simitsis and S. Skiadopoulos Conceptual Modeling for ETL Processes, In theproceedings of the 5th International Workshop on Data Warehousing and OLAP (DOLAP ’02),PAGES 14-21,2002
[8] http://www.cs.uoi.gr/~pvassil/projects/arktos_II/arktos_2005_pgeor/index.html
[9] Mark A. Beyer, Eric Thoo, Mei Yang Selvage, Ehtisham Zaidi, Gartner Magic Quadrant for DataIntegration Tools, Published on https://www.gartner.com, 03 August 2017.
[10] https://www.hdfgroup.org/
[11] https://support.hdfgroup.org/HDF5/doc/UG/HDF5_Users_Guide.pdf
[12] https://support.hdfgroup.org/products/java/hdfview/UsersGuide/ug02start.html#ug02load
[13] https://jupyter.org/
[14] https://docs.microsoft.com/en-us/sql/integration-services/sql-server-integration-services
[15] A. Leonard, B. Weissman, B. Fellows, C. Wilhelmsen, J. Alley, M. Andersson, P. Avenant,R. Sondak, R. Smith, S. Currie, and S. Peck, The Biml Book: Business Intelligence and DataWarehouse Automation,Apress, 2017
52 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
[16] https://pandas.pydata.org/
[17] http://www.gaudisite.nl/ArchitecturalReasoning.html
[18] A. Cockburn, Writing Effective Use Cases, Addison-Wesley, c. 2001 http://alistair.cockburn.us/get/2465
[19] E. Seidewitz, "What models mean",IEEE Software, Vol. 20, Issue: 5, pp. 26-32, Sept.-Oct. 2003
[20] C. Atkinson and T. Kuhne, "Model-driven development: a metamodeling foundation," Software,IEEE, vol. 20, pp. 36-41, 2003
[21] M. Saleem, L. Jaafar, and M. Hassan, Model driven software development: An overview, Com-puter and Information Sciences (ICCOINS), 2014 International Conference
[22] OMG, OMG Model Driven Architecture,http://www.omg.org/mda/
[23] Object Management Group Model Driven Architecture (MDA) MDA Guide rev. 2.0 OMG Doc-ument ormsc/2014-06-01
[24] CWM,Common warehouse metamodel specification, https://www.omg.org/spec/CWM/About-CWM/
[25] J.D. Poole, "The Common Warehouse Metamodel as a Foundation for Active Object Models inthe Data Warehouse Environment", http://www.cwmforum.org/CwmAOM.pdf
[26] C.Y. Seo, R.Y.C. Kim, Y.B. Park, Model Transformation Rule for Generating Database Schema
[27] P. Vassiliadis, A. Simitsis, and S. Skiadopoulos, "Conceptual Modeling for ETL Processes"
[28] P. Vassiliadis, A. Simitsis, and S. Skiadopoulos, "Modeling ETL Activities as Graphs"
[29] A. Simitsis and P. Vassiliadis, "Methodology for the conceptual modeling of ETL processes"
[30] P. Vassiliadis, A. Simitsis, P. Georgantas and M. Terrovitis, "Arktos II A framework for designof ETL scenarios"
[31] J. Trujillo, S. Lujan-Mora, "A UML Based Approach for Modeling ETL Processes in DataWarehouses"
[32] Z.E. Akkaoui, J. Mazon, A. Vaisman and E. Zimanyi, "BPMN-Based Conceptual Modeling ofETL processes"
[33] Z.E. Akkaoui, E. Zimanyi, J. Mazon, and J. Trujillo "A BPMN-Based Design and MaintenanceFramework for ETL Process"
[34] https://www.informatica.com/nl/data-integration-magic-quadrant.html#fbid=pg276JvzpeY
[35] https://blog.cloveretl.com/extending-ctl-with-java-functions
[36] http://doc.cloveretl.com/documentation/UserGuide/index.jsp?topic=/com.cloveretl.gui.docs/docs/ctl-overview.html
[37] https://wiki.pentaho.com/display/EAI/ETL+Metadata+Injection
53 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
A Stakeholder Analysis
Definitions
Role: What role a stakeholder played in the projectImpact: How much the project impacted a stakeholder.Influence: How much influence a stakeholder had on a projectInterests: What a stakeholder wanted from the projectResponsibility: What duties of a stakeholder has in relation to the projectInvolvement : How involved a stakeholder was in the project and what communication mechanismswere used
54 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder Pieter VerduinRole Project mentor and supervisor (MPS team)Impact HighInfluence HighInterest • Having an analysis for a model based ETL flow that can lower software release
cycle from the current release cycle of two/three months per new ETL flow
• Identification of a common ETL flow process that can be modeled in a genericway with the aim of making reusable components across the flow
• Minimizing, with a goal of ultimately removing, hard coding in a model,specifically as done in the Dimensional Modeling of the current ETL flow im-plementation
• Having a model based ETL flow that can be integrated and deployed into CRS’senvironment, with the possibility of including others
• Having a model based ETL flow that can be integrated with the Lavastormlayer of CRS: an existing data inspection and validation layer
Responsibility • Monitor, evaluate, review, and provide feedback on the project deliverables andprogress
• Provide domain knowledge or give direction to company contacts
• Review final project report
Involvement For the entire duration of the project by attending weekly progress meetings inaddition to the monthly progress steering meeting (PSG)
55 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder Tim PaffenRole Project mentor and supervisor (ORS team)Impact HighInfluence HighInterest • Having an analysis for a model based ETL flow approach with a purpose of
differentiating ETL flows from data analysis
• Having a modularized ETL flow to allow re-usability of components
• Having an architecture document that outlines the design of a modularized ETLflow approach
• Having a model based ETL flow that can be integrated and deployed intoODAS’s environment, with the possibility of including others
• Having a model based ETL flow that can be possible to integrate with thenew OOTI project of design and implementation of data quality, mining andcorrection
Responsibility • Monitor, evaluate, review, and provide feedback on the project deliverables andprogress
• Provide domain knowledge or give direction to company contacts
• Review final project report
Involvement For the entire duration of the project by attending weekly progress meetings inaddition to the monthly progress steering meeting (PSG)
56 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder Jos JansRole Domain knowledge source (MPS team) and project initiatorImpact HighInfluence MediumInterest • Having an analysis for a model based ETL flow that can allow flexibility of
each ETL flow steps; taking into account a dimensional data model withoutcompromising quality of the software
• Having only one version of the truth data warehouse
• Traceability of data in an ETL flow
• Having a model based ETL flow that can be integrated and deployed into CRS’senvironment, with the possibility of including others
• Having a modeling scheme that can allow re-use of ETL flow patterns, tasksand processes
• Having a model based ETL flow that can be integrated with the current envi-ronments
• Having a model based ETL flow that can be integrated with the OOTI projectof design and implementation of data quality, mining and correction
Responsibility • Provide domain knowledge or give direction to company contacts
• Provide relevant technical information
• Review reports that are mainly related with the interests mentioned above
Involvement For the entire duration of the project with weekly progress meetings and other ondemand meetings
57 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder Johan HoogendoornRole Project mentor and Domain knowledge source (ORS team)Impact MediumInfluence LowInterest • Identification and documentation of current ETL process for ODAS
• Having a modularized ETL flow to allow re-usability of components
• Having an analysis for a model based ETL flow approach with a purpose ofdifferentiating the ETL flow from data analysis
• Having formalized model description that can be used to create code imple-mentation
• Having an architecture document that outlines the design of a modularized ETLflow approach
• An ETL flow that can handle daily large (up to 5GB/day/per printer) printerlog data from the log server
• Better structured ETL flow in ODAS
• To have a code implementation that always follows the model
• An ETL flow that can handle daily large (up to 5GB/day/per printer) printerlog data from the log server
Responsibility • Provide domain knowledge or give direction to company contacts
Involvement For the first phase the project with a weekly progress meeting and monthlyprogress steering meeting (PSG)
Stakeholder Jacques BergmansRole ETL flow implementation knowledge source and direct user (ORS team)Impact HighInfluence LowInterest • Separation of fetch and data repair functionality in ODAS
• Lowering hard coded error correction
Responsibility • Provide domain knowledge regarding current implementation
• Provide relevant technical information
Involvement Communication until April and with on-demand meetings
58 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder Jeroen DoppRole ETL flow implementation knowledge source and direct usersImpact HighInfluence LowInterest • Low learning curve for new people in the team using the ETL flow models
• Have an ETL flow with better performance than the existing once, such asmemory and speed of access.
Responsibility • Provide domain knowledge regarding current implementation
• Provide relevant technical information
Involvement For the entire project duration with on-demand meetings
Stakeholder Henk ThijssenRole Data quality knowledge sourceImpact LowInfluence LowInterest • Having an ETL flow that can integrate with existing Lavastorm data quality
and correction tool
• Having an ETL flow that can avoid patches done by Lavastorm
Responsibility • Provide domain knowledge regarding Lavastorm and data quality and valida-tion
• Provide relevant technical information
Involvement For the entire project duration with on-demand meetings
Stakeholder R. KersemakersRole Team leader of ORSImpact MediumInfluence MediumInterest • Making the process during this project smooth
Responsibility • Give the necessary permission for acquiring product license
Involvement For the entire project duration by ad-hoc communication
59 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder IP departmentRole IP revisionImpact LowInfluence LowInterest • Protecting the interests of Océ regarding intellectual property (IP)
Responsibility • Review reports and presentations
Involvement For the entire project duration by communicating at-least a week in advance perrevision
Stakeholder Tim WillemseRole Mentor and supervisor (TU/e)Impact LowInfluence HighInterest • Having a final documentation that satisfies TU/e’s design standards
• Making the process during this project smooth
Responsibility • Monitor, evaluate, assess and provide feedback on the design process, deliver-ables and project progress
• Provide relevant domain knowledge or university contacts
• Review final project report
Involvement For the entire duration of the project with a bi-weekly progress and monthlyprogress steering meetings (PSG)
Stakeholder Y. DajsurenRole TU/e software technology program managerImpact LowInfluence MediumInterest • Having a final documentation that satisfies TU/e’s design standards
Responsibility • Provide relevant technical information or contacts
Involvement For the entire project duration with demand meetings and attending atleast oneprogress steering group meeting (PSG)
60 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
Stakeholder C. AzevedoRole PDEng Trainee for Data Quality Mining and Correction ProjectImpact MediumInfluence LowInterest • Having an ETL flow that is possible to integrate with the new design and im-
plementation of data quality, mining and correction
Responsibility • Provide relevant interface definition
Involvement For the entire project duration with on demand meetings and attending weeklyprogress meetings
Stakeholder S. AyeleRole PDEng TraineeImpact HighInfluence HighInterest • Meeting the design standards to successfully finish the traineeships
• Identify requirements that are relevant for the major stakeholders and output adesign that can influence the current process
Responsibility • Document project progress and provide timely reports
• Fulfill the responsibility of assessing a model based ETL flow approach thatsatisfies the main requirements
• Come up with a design that can be prototyped within the given project period
Involvement For the entire project duration.
61 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
B Use-case detail
Use-case: UC1Name Model ETL flows with components that can be re-usableGoal in Context To describe an ETL flow or stage in detailScope Model Driven ETL frameworkLevel Primary taskPrimary Actor Designers and Developers
Stakeholders’ Interests1. To have a formalized model description that can be used to create executable ETL flows2. To have a modularized ETL flow to allow re-usability of components and models3. Identification of common ETL flow that can be modeled in a generic way
Priority HighSuccess End Condition The designer has enough components to describe data structures, ETL stage and flow to
cover the use-cases from ODAS and/or CRS.
Main Success Scenario1. Designer: uses components in the framework to model an ETL flow that satisfies ateam’s requirements2. Designer: can re-use the same component for another use-case
Extensions
Designer wants to re-use components already defined for another use-case or another team1.a. Designer: imports components1.b. Designer: applies the components to a model
Designer wants to extend a model1.a. Designer: imports a model1.b. Designer: extends the model to satisfy a new requirement1.c. Designer: stores the customized model as a new model
Table B.1: Use-case 1 - Model ETL flows with components that can be re-usable
62 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
Technische Universiteit Eindhoven University of Technology
Use-case: UC2Name Visualize ETL flow on different levelGoal in Context To define a general overview of an ETL flow with a certain level of abstraction for the
purpose of documentingScope Model Driven ETL frameworkLevel SummaryPrimary Actor Designers and Developers
Stakeholders’ Interests1. To have a generic ETL framework for communicating across teams and projects2. Low learning curve for new people in the team4. Low learning curve for new people in the team
Priority HighSuccess End Condition Designer has adequate components to describe overview of an ETL flow or stage with a
different level of abstraction
Main Success Scenario1. Designer: uses components in the framework to model an ETL flow or stage withatleast two level of abstraction2. Framework: stores the model
Table B.2: Use-case 2 - Visualize ETL flow on different level
Use-case:UC3Name Execute ETL flowsGoal in Context To execute an ETL flow from the logical detail model and transform data from one form
to anotherScope Model Driven ETL frameworkLevel Sub-functionPrimary Actor DevelopersStakeholders’ Interests Requirement change from code generation1
Pre-Condition There is a model that describes an ETL flow or a component of an ETL flow (Use-case:UC 2)
Priority MediumSuccess End Condition An ETL flow is executed resulting in the expected data output either in a Data warehouse
or Large Data Storage.
Main Success Scenario1. Developer: imports/creates model of an ETL flow2. Developer: runs the model3. Framework: executes the model and the output data is in the target
Table B.3: Use-case 3 - Execute ETL flows
1Originally, the stakeholders’ interest was to generate source code from a model. However, this use-case has evolved toexecution of the model due to factors like limited project time and addition of complexity in maintaining extra conversionsin the long run.
63 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
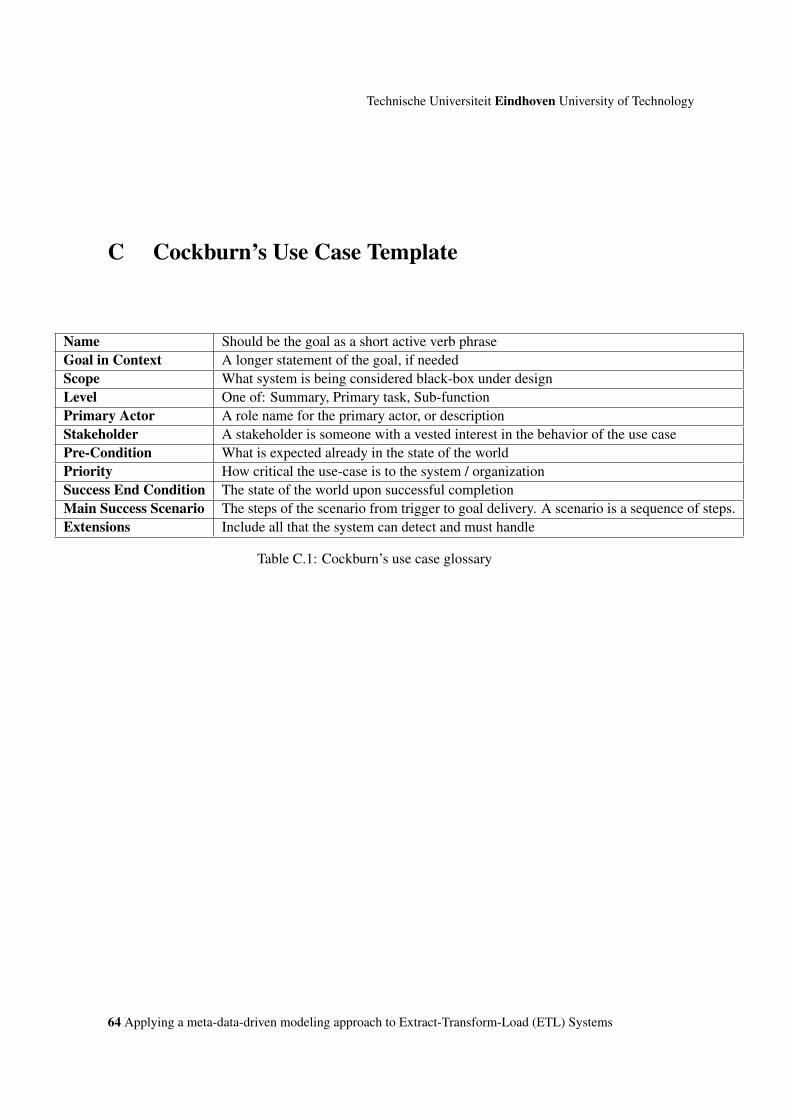
Technische Universiteit Eindhoven University of Technology
C Cockburn’s Use Case Template
Name Should be the goal as a short active verb phraseGoal in Context A longer statement of the goal, if neededScope What system is being considered black-box under designLevel One of: Summary, Primary task, Sub-functionPrimary Actor A role name for the primary actor, or descriptionStakeholder A stakeholder is someone with a vested interest in the behavior of the use casePre-Condition What is expected already in the state of the worldPriority How critical the use-case is to the system / organizationSuccess End Condition The state of the world upon successful completionMain Success Scenario The steps of the scenario from trigger to goal delivery. A scenario is a sequence of steps.Extensions Include all that the system can detect and must handle
Table C.1: Cockburn’s use case glossary
64 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Technische Universiteit Eindhoven University of Technology
D ETL framework list used for comparison matrix
Here are the list of ETL and data integration frameworks that were included in the comparison matrix.ETL listing sources [41,45] were used as a starting point. At the end CloverETL was chosen for theprototype taking into acount of the system requirements an use-cases.
65 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems
Framework/ language Description
1. CloverETL /
Clover Transformation Language [1]
Integrated into the Eclipse environment
2. Talend Open Studio for
Data Integration / Java [4]
Eclipse based including
- Big Data, Data preparation, Data
Quality, Master Data management
- metadata-driven solution
development environment provides
both a graphical and functional view
of the integration processes
3. Pentaho Data Integration [5] A graphical based on SWT (The Standard
Widget Toolkit)
- Includes metadata configuration
wizards to help configure
heterogeneous data sources and
complex file formats including
positional, delimited, CSV, RegExp,
XML, and LDIF data.
4. Jedox ETL / Java for custom functions
Groovy and JS for scripts based jobs
or functions [6]
Eclipse based client- server based
application for automatic data import that
extracts data from heterogeneous sources
and uploads it to the Jedox OLAP server
5. Jaspersoft data integration [7] Seems to use Talend’s (#2 )metadata
manager (may be can be integrated)
6. RapidMiner [8] Not intended for ETL and building OLAP
cubes. Thus might end up hard coding
But possible to do
7. Oracle Data Integrator (ODI) [9]
Declarative rules driven approach
generates native code for disparate
RDBMS or big data engines (SQL,
HiveQL, PySpark, Pig Latin or bulk
loader scripts, for example)
-includes the Jython Interpreter
8. SQL Server data tool/ SQL Server
Integration Services (SSIS) [10]
A platform for building enterprise-level
data integration and data transformations
solutions.
9. SQL Server data tool
/Business Intelligence Markup
Language( BIML) [11]
Uses XML and small nuggets of C# or
VB code to automatically create huge
amounts of SQL scripts, SSIS packages,
SSAS cubes, tabular models, and more
10. LeapFrogBI [12] Web-based end-to-end business
intelligence solution, automates
development of SQL Server data
solutions
11. BI Builder for SQL Server [13] A pure T-SQL application for MSSQL
data warehouse developers: It generates
staging and dimension tables as well as
ETL stored procedures.

12. BixPress [14] Real-time Monitoring and notification for
SSIS package
Not an ETL tool, rather can generate
SSIS packages based on templates
13. EzAPI [15,16] Alternative package creation API
14. SAS Data Management [17] Out-of-the-box SQL-based transforms
delivering ELT capabilities
Data governance and metadata
management
15. Informatica PowerCenter [18]
Data-centric enterprise with capability for
Big Data integration
- Comes with Enterprise Information
Catalog metadata management tool
for handling Metadata-driven
architecture
16. Elixir Repertoire for Data ETL [19] Built with java entirely on Service-
Oriented Architecture with REST
(Representational State Transfer1)
interface
17. Data Migrator (IBI) (Information
Builders iWay) [20,35]
Accelerates the deployment and reduces
the risk of all types of data integration
projects – including extract, transform,
and load (ETL), enterprise information
integration (EII) initiatives, and Web
services deployments
18. Sagent Data Flow [21] Single data integration platform for
customer profiling, data warehousing,
ETL and business intelligence (BI)
19. Actian DataConnect [22] Generates metadata that is stored in a
RDBMS
20. Open Text Integration Center [23]
OpenText Integration Center is used to
move unstructured, semi-structured, or
structured data between any source and
target system. It is built on client/server
architecture, and incorporates a
centralized and open metadata repository.
21. Centerprise Data Integrator-
DWAccelerator [24]
Complete data integration solution that
includes data integration, data
transformation, data quality, and data
profiling in a flexible environment that
enables users to choose from multiple
integration scenarios
22. Adeptia Integration Server [25] A hybrid integration solution that
enables you to quickly and easily design,
deploy, and manage integrations on
premise, in the cloud, or in hybrid
environments with no limits on data types
or volumes
23. Syncsort DMX [26] Not supported anymore
24. Attunity [27]
Targeted cloud data
integration- Amazon Web Services
and Microsoft Azure
25. Cisco Information Server [28]
Data-virtualization-focused optimized for
IoT
26. Denodo [29]
On-demand real-time data access to many
sources as integrated data services with
high performance using intelligent real-
time query optimization, caching, in-
memory and hybrid strategies
27. SAP Data Services [30]
Can integrate with SAP Power Designer
for metadata and modeling
28. IBM Infosphere Information
Server[31]
Client-server based application
29. IBM Infosphere Warehouse Edition
[32]
Integrator + data quality
30. IBM Data
Integration for Enterprise [33]
The combination of technical and
business processes used to combine data
from disparate sources into meaningful
and valuable information
31. IBM Cognos Data Manager [34] provides dimensional ETL capabilities for
high performance business intelligence
32. Eclipse Papyrus / UML [36] A modeling and development
environment that uses the Unified
Modeling Language 33. Enterprise Architect/ UML, BPMN
[37]
34. Rational Software Architect /UML,
BPMN [38]
35. MPS Jetbrains [39] A meta-programming system design
Domain-specific languages
36. ARKITOS / Java, or C#
implementation
A modeling environment using custom
constructs to facilitate, manage and
optimize the design and implementation
of the ETL processes both during the
initial design and deployment stage and
during the continuous evolution of the
data warehouse
Reference
1. https://www.cloveretl.com/
2. https://blog.cloveretl.com/python-scripts-cloveretl
3. https://blog.cloveretl.com/building-data-warehouse-scd2
4. https://help.talend.com/reader/iYcvdknuprDzYycT3WRU8w/3Lyn4CR4M5Q2u
OD8FWmOwg
5. https://www.hitachivantara.com/en-us/products/big-data-integration-
analytics/pentaho-data-integration.html
6. https://knowledgebase.jedox.com/knowledgebase/development-of-customer-
specific-etl-components/
7. https://www.jaspersoft.com/data-integration

8. https://rapidminer.com/
9. https://www.oracle.com/middleware/technologies/data-integrator.html
10. https://docs.microsoft.com/en-us/sql/integration-services/sql-server-integration-
services?view=sql-server-2017
11. https://varigence.com/Biml
12. http://www.leapfrogbi.com/
13. https://archive.codeplex.com/?p=bibuilder
14. https://www.sentryone.com/products/pragmatic-workbench/bi-xpress/ssis-
development-monitoring-tools
15. https://blogs.msdn.microsoft.com/mattm/2008/12/30/ezapi-alternative-package-
creation-api/
16. https://archive.codeplex.com/?p=sqlsrvintegrationsrv
17. https://www.sas.com/en_us/software/data-management.html
18. https://www.informatica.com/nl/products/data-
integration/powercenter.html#fbid=pg276JvzpeY
19. http://www.elixirtech.com/products/DataETL.html
20. https://www.informationbuilders.com/products/data-management-platform
21. https://www.pitneybowes.com/us/customer-information-management/data-
integration-management/sagent-data-flow.html
22. https://www.actian.com/data-integration/dataconnect-integration/
23. https://www.opentext.com/products-and-
solutions/products/discovery/information-access-platform/opentext-integration-
center
24. http://www.astera.com/centerprise
25. https://adeptia.com/
26. http://www.syncsort.com/en/Products/BigData/DMX
27. https://www.attunity.com/
28. https://blogs.cisco.com/datacenter/cisco-data-virtualization
29. https://www.denodo.com/en
30. https://www.sap.com/products/data-services.html
31. https://www.ibm.com/analytics/information-server
32. https://www.ibm.com/support/knowledgecenter/en/SSEPGG_9.5.0/com.ibm.dwe.
welcome.doc/dwev9welcome.html
33. https://www-01.ibm.com/common/ssi/cgi-
bin/ssialias?infotype=OC&subtype=NA&htmlfid=897/ENUS5737-
C60&appname=System%20Storage
34. https://www.ibm.com/support/knowledgecenter/en/SSRL5J_1.0.0/com.ibm.ration
al.raer.overview.doc/topics/c_datamanager.html
35. https://www.informationbuilders.com/
36. https://www.eclipse.org/papyrus/
37. https://sparxsystems.com/products/ea/
38. http://www-01.ibm.com/support/docview.wss?uid=swg27014042
39. https://www.jetbrains.com/mps/
40. http://www.cs.uoi.gr/~pvassil/projects/arktos_II/arktos_2005_pgeor/index.html
41. https://www.etltool.com/etl-vendors/
42. https://www.gartner.com


Technische Universiteit Eindhoven University of Technology
About the author
Sololia G. Ayele received her Bachelors degree in Elec-trical Engineering (2011) from Haramaya University,Ethiopia and a Masters degree in Computer Science andEngineering from Ajou University, in South Korea (2014).As part of her Masters, she published a journal paperon "Efficient FTL-Aware Data Categorization Scheme ForFlash Memory" in the Journal of Circuits, Systems andComputers (2014). After graduation, she worked as aSoftware Engineer for John Snow Inc, Ethiopia and wasalso involved in various freelance software developmentprojects (2014-2016). In October 2016, she joined the4TU.Stan Ackermans Institute, the Eindhoven Universityof Technology, as a PDEng trainee in Software Technol-ogy. During her graduation project, she worked for Océon "Applying a meta-data-driven modeling approach toExtract-Transform-Load (ETL) Systems".
71 Applying a meta-data-driven modeling approach to Extract-Transform-Load (ETL) Systems

Where innovation starts