application of postgre sql to large social infrastructure
TRANSCRIPT

Copyright © 2016 NTT DATA Corporation
December 2, 2016
NTT Data Corporation
Ayumi Ishii
Application of PostgreSQL to large social
infrastructure
PGCONF.ASIA 2016

Copyright © 2016 NTT DATA Corporation 2
How to use PostgreSQL in social infrastructure

3Copyright © 2016 NTT DATA Corporation
Positioning of smart meter management system
aggregation
device
SM
SMSM
smart meter management
system
SM
Data Center
SM
SM
SMaggregation device
wheeling management system
fee calculation for new menu
other
power
companies
billing
processingmember management
system
reward points system
switching support system
Organization
for Cross-
regional
Coordination
of
Transmission
Operators
★

4Copyright © 2016 NTT DATA Corporation
Main processing and mission of the system
main processing
5 million datasets
per 30 min
validatesave
data
save
calculated datacalculation
within 10minutes
• 240 million additional tuples per
day
• must be saved for 24 months
5 million
tuple
INSERT
Mission 1
Mission 2
large scale
SELECT
Mission 35 million
tuple
INSERT

5Copyright © 2016 NTT DATA Corporation
Mission
1. Load 10 million datasets within 10 minutes !
2. Must save data for 24 months !
3. Stabilize large scale SELECT performance !

6Copyright © 2016 NTT DATA Corporation
(1) Load 10 million datasets within 10 minutes !
★
main processing
5 million datasets
per 30 min
validatesave
data
save
calculated datacalculation
within 10minutes
• 240 million additional tuples per
day
• must be saved for 24 months
5 million
tuple
INSERT
Mission 2
large scale
SELECT
Mission 35 million
tuple
INSERT
Mission 1

7Copyright © 2016 NTT DATA Corporation
Data model
data : [Device ID] [Date] [Electricity Usage]
ex) ID: 1 used 500 at 1:00 August 1st.
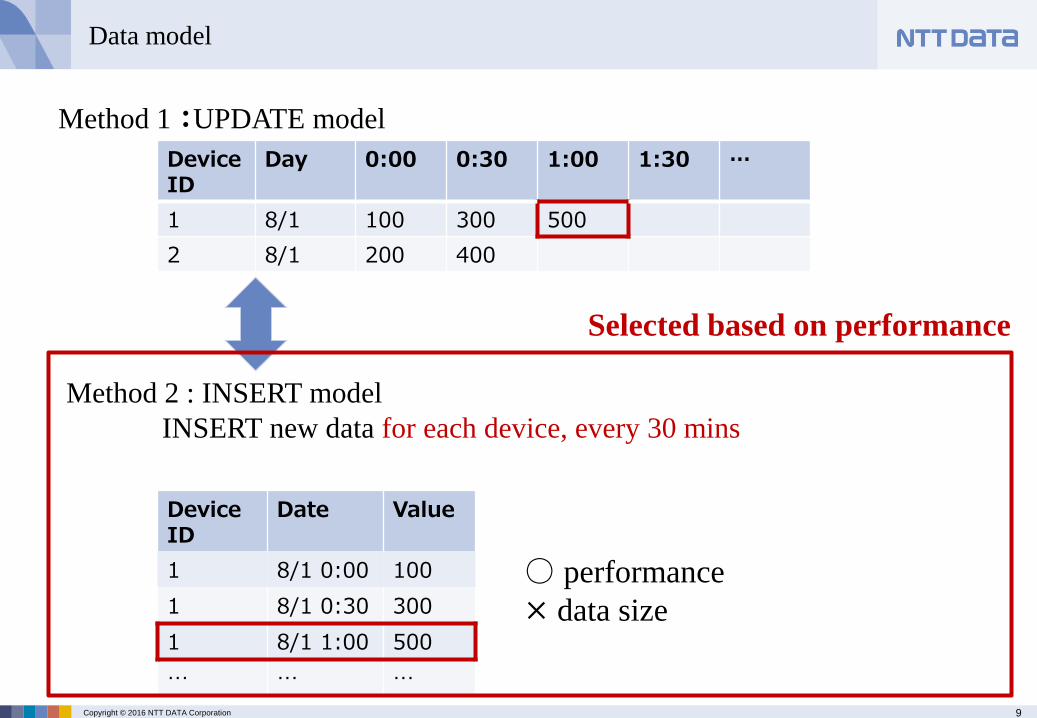
Method 1 :UPDATE model
UPDATE new data for each device, daily
DeviceID
Day 0:00 0:30 1:00 1:30 …
1 8/1 100 300 500
2 8/1 200 400
Frequent UPADATEs are unfavorable for
PostgreSQL in terms of performance

8Copyright © 2016 NTT DATA Corporation
Data model
DeviceID
Date Value
1 8/1 0:00 100
1 8/1 0:30 300
1 8/1 1:00 500
… … …
○ performance
× data size
Method 2 : INSERT model
INSERT new data for each device, every 30 mins
Method 1 :UPDATE model
DeviceID
Day 0:00 0:30 1:00 1:30 …
1 8/1 100 300 500
2 8/1 200 400
9Copyright © 2016 NTT DATA Corporation
Data model
DeviceID
Date Value
1 8/1 0:00 100
1 8/1 0:30 300
1 8/1 1:00 500
… … …
○ performance
× data size
Method 2 : INSERT model
INSERT new data for each device, every 30 mins
Method 1 :UPDATE model
DeviceID
Day 0:00 0:30 1:00 1:30 …
1 8/1 100 300 500
2 8/1 200 400
Selected based on performance

10Copyright © 2016 NTT DATA Corporation
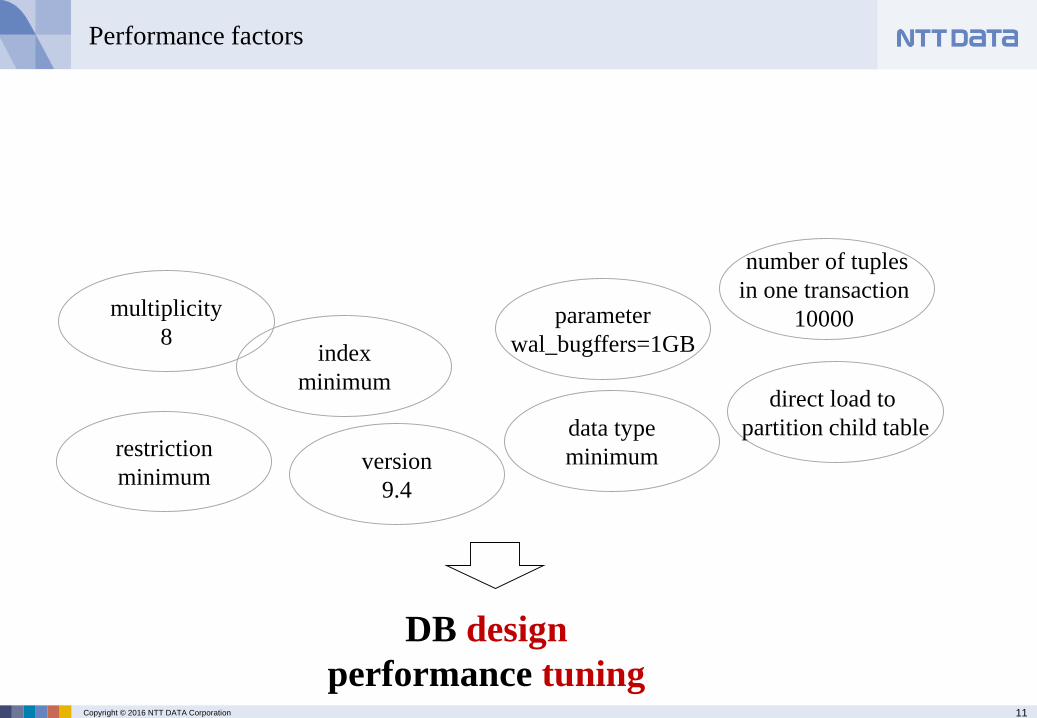
Performance factors
number of tuples
in one transaction ? multiplicity? parameters?
data type?restrictions?
index?
version?
pre research regarding performance factors
how to load to
partition table?
11Copyright © 2016 NTT DATA Corporation
Performance factors
number of tuples
in one transaction
10000 multiplicity
8parameter
wal_bugffers=1GB
data type
minimumrestriction
minimum
index
minimum
version
9.4
direct load to
partition child table
DB design
performance tuning

12Copyright © 2016 NTT DATA Corporation
Performance factors
number of tuples
in one transaction
10000 multiplicity
8parameter
wal_bugffers=1GB
data type
minimumrestriction
minimum
index
minimum
version
9.4
direct load to
partition child table

13Copyright © 2016 NTT DATA Corporation
Bottleneck Analysis with perf
19.83% postgres postgres [.] XLogInsert ★6.45% postgres postgres [.] LWLockRelease
4.41% postgres postgres [.] PinBuffer
3.03% postgres postgres [.] LWLockAcquire
WAL is the
bottleneck !
perf
WAL
WAL
file
Disk
I/O
memory
WAL buffer
write
・commit
・buffer is full

14Copyright © 2016 NTT DATA Corporation
wal_buffers parameter
“The auto-tuning selected by the default
setting of -1 should give reasonable results
in most cases.”
by PostgreSQL Document

15Copyright © 2016 NTT DATA Corporation
wal_buffers
※INSERT only
(except SELECT)0:00:00
0:01:00
0:02:00
0:03:00
0:04:00
0:05:00
0:06:00
0:07:00
0:08:00
0:09:00
16MB 1GB
Tim
e
Impact of WAL_buffers

16Copyright © 2016 NTT DATA Corporation
PostgreSQL version
・WAL performance improved
・JSONB
・GIN performance improved
・CONCURRENTLY option
9.3 9.4

17Copyright © 2016 NTT DATA Corporation
Version up
• We had originally planned to use 9.3, but changed to 9.4.
0:00:00
0:01:00
0:02:00
0:03:00
0:04:00
0:05:00
0:06:00
0:07:00
0:08:00
9.3 9.4
tim
e
impact of version up
※INSERT only
(except SELECT)

18Copyright © 2016 NTT DATA Corporation
0:07:570:06:59
0:05:49
0:03:29
0:03:29
0:03:29
0:00:00
0:02:00
0:04:00
0:06:00
0:08:00
0:10:00
0:12:01
9.3, 16MB 9.3, 1GB 9.4, 1GB
tim
e
Result
target
accomplished!!
other processes
are already
tuned.
■INSERT
■others

19Copyright © 2016 NTT DATA Corporation
(2) Must save data for 24 months !
★
main processing
5 million datasets
per 30 min
validatesave
data
save
calculated datacalculation
within 10minutes
• 240 million additional tuples per
day
• must be saved for 24 months
5 million
tuple
INSERTlarge scale
SELECT
Mission 35 million
tuple
INSERT
Mission 1
Mission 2

108TB
21Copyright © 2016 NTT DATA Corporation
Reduce data size by selecting the best data type
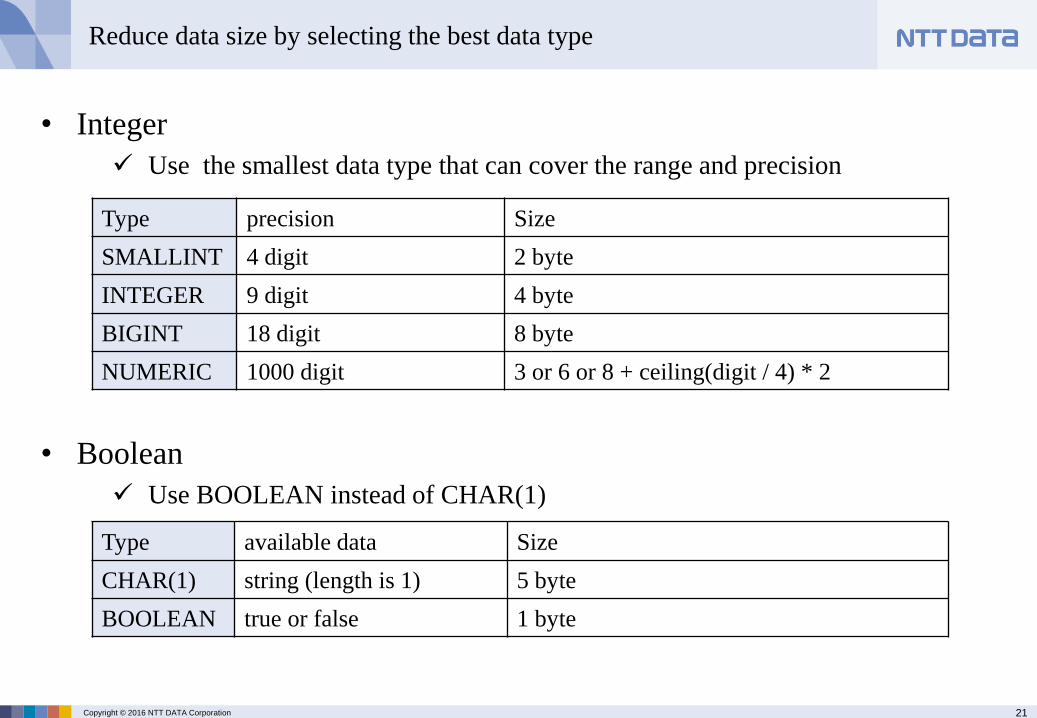
• Integer
Use the smallest data type that can cover the range and precision
• Boolean
Use BOOLEAN instead of CHAR(1)
Type precision Size
SMALLINT 4 digit 2 byte
INTEGER 9 digit 4 byte
BIGINT 18 digit 8 byte
NUMERIC 1000 digit 3 or 6 or 8 + ceiling(digit / 4) * 2
Type available data Size
CHAR(1) string (length is 1) 5 byte
BOOLEAN true or false 1 byte

22Copyright © 2016 NTT DATA Corporation
Reduce the data size by changing column order
• alignment
• PostgreSQL does not store data across the alignment
1 2 3 4 5 6 7 8
column_1(4byte) ***PADDING***
column_2(8byte)
8 byte
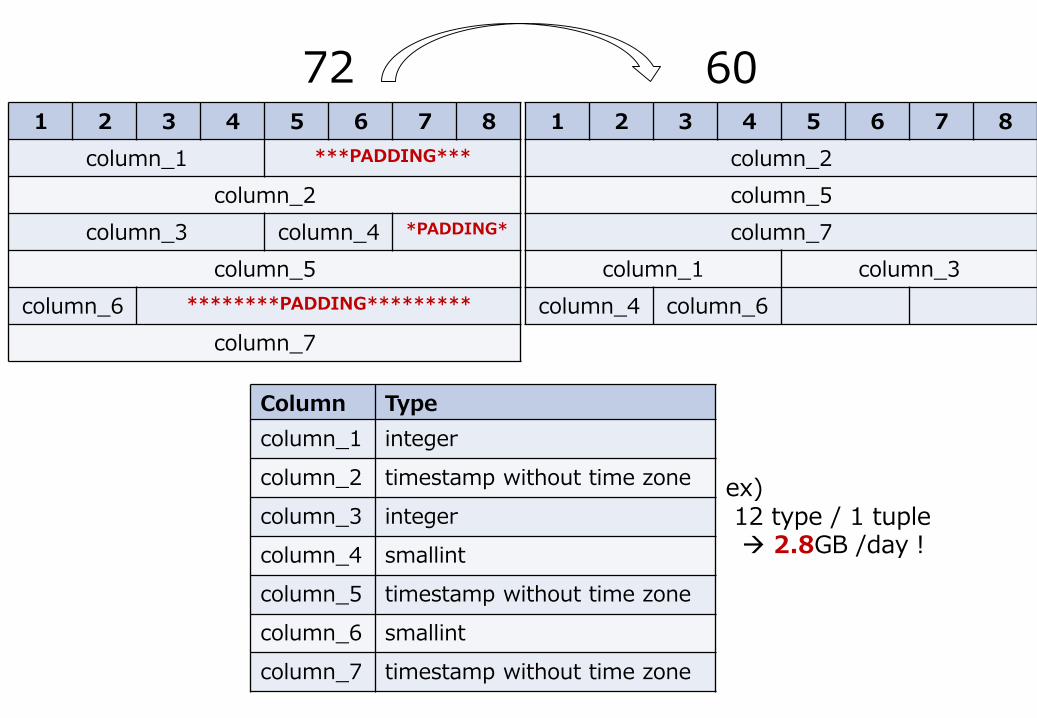
Column Type
column_1 integer
column_2 timestamp without time zone
column_3 integer
column_4 smallint
column_5 timestamp without time zone
column_6 smallint
column_7 timestamp without time zone
1 2 3 4 5 6 7 8
column_1 ***PADDING***
column_2
column_3 column_4 *PADDING*
column_5
column_6 ********PADDING*********
column_7
1 2 3 4 5 6 7 8
column_2
column_5
column_7
column_1 column_3
column_4 column_6
72 60
ex) 12 type / 1 tuple 2.8GB /day!

24Copyright © 2016 NTT DATA Corporation
Change data model
num data select
frequency
update
frequency
policy model
1 1st day
~65th day
high high performance is the
priority
INSERT
2 66th day
~24 months
low low data size is the
priority
UPDATE
We adopted INSERT model considering the performance
• However, data size is large making it difficult to store long term
convert model for old data

25Copyright © 2016 NTT DATA Corporation
Change data model
ID date 0:00 0:30 1:00 … 22:30 23:00 23:30
1 8/1 100 300 500 … 1000 1100 1200
2 8/1 100 200 300 … 800 900 1000
ID timestamp value
1 8/1 0:00 100
2 8/1 0:00 100
1 8/1 0:30 300
2 8/1 0:30 200
1 8/1 1:00 500
2 8/1 1:00 300
… … …
1 8/1 22:30 1000
2 8/1 22:30 800
1 8/1 23:00 1100
2 8/1 23:00 900
1 8/1 23:30 1200
2 8/1 23:30 1000
INSERT model UPDATE model
remove duplicated data (ID, timestamp)
num of tuples/day: 240 million →5 million
size: 22GB→3GB

26Copyright © 2016 NTT DATA Corporation
result
108
11
0
20
40
60
80
100
120
dat
a si
ze(
TB
)reduce data size
before after

27Copyright © 2016 NTT DATA Corporation
(3) Stabilize large scale SELECT performance !
★
main processing
5 million datasets
per 30 min
validatesave
data
save
calculated datacalculation
within 10minutes
• 240 million additional tuples per
day
• must be saved for 24 months
5 million
tuple
INSERTlarge scale
SELECT
5 million
tuple
INSERT
Mission 1
Mission 2
Mission 3

28Copyright © 2016 NTT DATA Corporation
Stabilize the performance of 10 million SELECT statements!
“stable performance” is important• Performance degradation is caused by sudden changes in
execution plan is problem
control
execution plans
pg_hint_plan
lock statistical
information
pg_dbms_stats
stable performance

29Copyright © 2016 NTT DATA Corporation
Before using pg_hint_plan & pg_dbms_stats
In most cases, optimizer generates the best execution plan
fixing execution plan does not always bring good result
• The best execution plan at this time may not be best in the future.
However, it is necessary to reduce the risk.
If execution plan suddenly changed during operation, and
performance maybe reduced.
→Understand the demerits and use these extensions
• SELECT immediately after batch, before
ANALYZE
• SELECT from a lot of tables (JOIN)
• …

30Copyright © 2016 NTT DATA Corporation
pg_dbms_stats
Plannerpg_dbms_stats
PostgreSQL
Original
statistics
Plan
generate
Lock
“Locked”
statistics

31Copyright © 2016 NTT DATA Corporation
pg_dbms_stats in this system
usage
data
day
table
locked
statistics
day
table
locked
statistics
day
table
locked
statistics
day partitionset locked statistics with new table
COPYsome statistics are different
depending on each child table
We can certainly get best plan even without
using ANALYZE.
• table’s OID, table name
• partition key, date

32Copyright © 2016 NTT DATA Corporation
Replacing statistics that should be changed according to table
• Create assumed dummy data
• ANALYZE dummy data
Column statistic
partition key Most Common Value
Date Histogram
Ex) “ 8/1 0:00” , “8/1 0:30”, “8/1 1:00”
48 pattern per day. Uniform distribution.

33Copyright © 2016 NTT DATA Corporation
1. Load 10 million datasets within 10 minutes !
2. Must save data for 24 months !
3. Stabilize large scale SELECT performance !
Mission
COMPLETE

34Copyright © 2016 NTT DATA Corporation
conclusion
The 20th anniversary of PostgreSQL
PostgreSQL finally evolved to be adopted in large scale social infrastructure.
Both PostgreSQL technical knowledge and business application knowledge are necessary
to be successful in difficult and large scale projects.
Pre research and know-how are important to get the full out of PostgreSQL.

Copyright © 2011 NTT DATA Corporation
Copyright © 2016 NTT DATA Corporation