announcements: projects - carnegie mellon school of ...wcohen/10-605/sgd.pdf · announcements:...
TRANSCRIPT

Announcements: projects
–805students:ProjectproposalsaredueSun10/1.Ifyou’dliketoworkwith605studentsthenindicatethisonyourproposal.–605students:theweekafter10/1Iwillposttheproposalsonthewikiandyouwillhavetimetocontact805studentsandjointeams.–805students:letmeknowyourteamby10/8:Iwillapprovetheteams.
1

The course so far• Doingi/oboundtasksinparallel–map-reduce– dataflowlanguages:PIG,Spark,GuineaPig
• Alittlebitaboutiterationandparallelism• Nextup:– thisyearsfavoritebigMLtrick!• don’tbedisappointed…
– stepbackandlookatperceptrons andfancyMLtricks:margins,ranking,kernels,….– stepforwardandtalkaboutparallellearning–midterm
2

LEARNING AS OPTIMIZATION:MOTIVATION
3

Learning as optimization: warmup
Goal:LearntheparameterθofabinomialDataset:D={x1,…,xn},xi is0or1,k ofthemare1
è P(D|θ)=cθk(1-θ)n-k
è d/dθ P(D|θ)=kθk-1(1-θ)n-k+θk(n-k)(1-θ)n-k-1
4

Learning as optimization: warmup
Goal:LearntheparameterθofabinomialDataset:D={x1,…,xn},xi is0or1,k ofthemare1
=0
θ=0θ=1
5
k- kθ – nθ +kθ =0è nθ =kè θ=k/n

Learning as optimization: general procedure• Goal:Learnparameterθ (orweightvectorw)• Dataset:D={(x1,y1)…,(xn ,yn)}• Writedownlossfunction:howwellwfitsthedataDasafunctionofw–Commonchoice:logPr(D|w)
• Maximizebydifferentiating–Thengradientdescent:repeatedlytakeasmallstepinthedirectionofthegradient
6

Learning as optimization: general procedure for SGD (stochastic gradient descent)
• Big-data problem:wedon’t wanttoloadallthedataDintomemory,andthegradientdependsonallthedata
• Solution:– pickasmallsubsetofexamplesB<<D– approximatethegradientusingthem
• “onaverage”thisistherightdirection– takeastepinthatdirection– repeat….
• Math:findgradientofwforasingle example,notadataset
B = oneexample is a very popular choice
7

SGD vs streaming
• Streaming:– passthroughthedataonce– holdmodel+oneexampleinmemory– updatemodelforeachexample
• Stochasticgradient:– passthroughthedatamultipletimes
• streamthroughadiskfilerepeatedly
– holdmodel+Bexamplesinmemory– updatemodelviagradientstep
B = one example is a very popular choice
its simple J
sometimes its cheaper to evaluate 100 examples at once than one example 100 times L
8

Logistic Regressionvs Rocchio• Rocchio lookslike:
• Twoclasses,y=+1ory=-1:
9
f (d) = argmaxy v(d) ⋅v(y)
f (d) = sign [v(d) ⋅v(+1)]−[v(d) ⋅v(−1)]( )= sign v(d) ⋅[v(+1)− v(−1)]( )
f (x) = sign(x ⋅w) w=v(+1)- v(-1)x =v(d)

Logistic Regressionvs Naïve Bayes
• NaïveBayesfortwoclassescanalsobewrittenas:
• Sincewecan’tdifferentiatesign(x),aconvenientvariantisalogisticfunction:
10
f (x) = sign(x ⋅w)
σ (x) = 11+ e−x

Efficient Logistic Regression with Stochastic Gradient
DescentWilliamCohen
11

Learning as optimization for logistic regression
• Goal:Learntheparameterw oftheclassifier
• ProbabilityofasingleexampleP(y|x,w)wouldbe
• Orwithlogs:
12

13
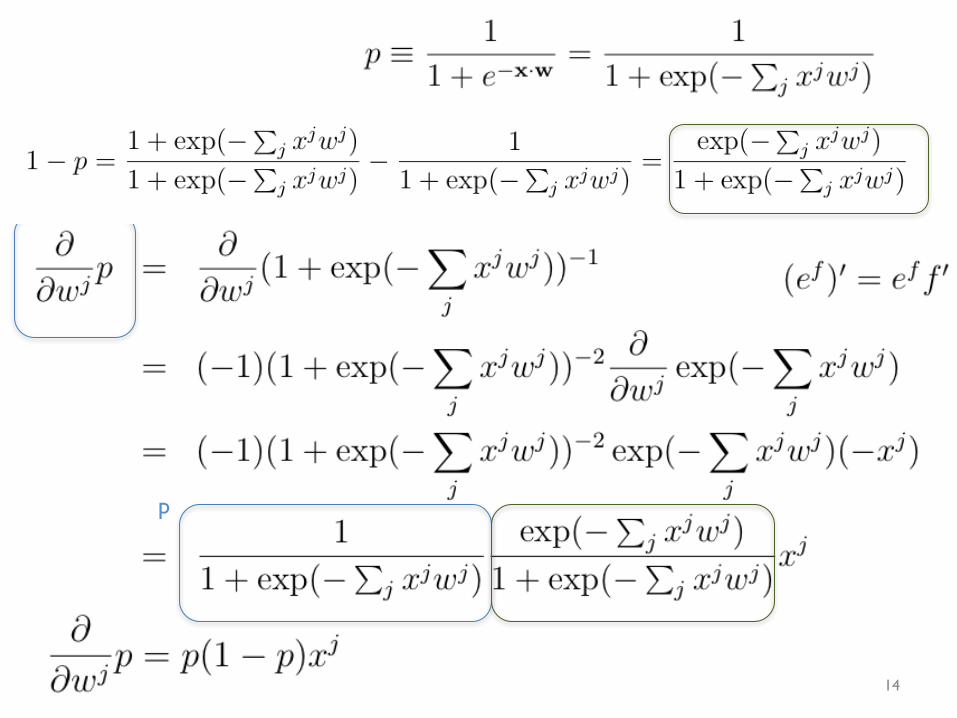
p
14

15

16
update with learning rate
lambda

Again: Logistic regression
• StartwithRocchio-likelinearclassifier:
• Replacesign(...)withsomethingdifferentiable:– Alsoscalefrom0-1not-1to+1
• Definealossfunction:
• Differentiate….
y = sign(x ⋅w)
y =σ (x ⋅w) = p
σ (s) = 11+ e−s
L(w | y,x) =logσ (w ⋅x) y =1
log(1−σ (w ⋅x)) y = 0
#$%
&%
= log σ (w ⋅x)y (1−σ (w ⋅x))1−y( )17

Magically,whenwedifferentiate,weendupwithsomethingverysimpleandelegant…..
p =σ (x ⋅w)
∂∂w
L(w | y,x) = (y− p)x
∂∂w j L(w | y,x) = (y− p)x
j
Theupdateforgradientdescentisjust:
18

Logistic regression has a sparse update
19

Keycomputationalpoint:• ifxj=0thenthegradientofwj iszero• sowhenprocessinganexampleyouonlyneedtoupdateweightsforthenon-zero featuresofanexample.
An observation: sparsity!
20

Learning as optimization for logistic regression• Thealgorithm:
-- do this in random order
21

Another observation
• ConsideraveragingthegradientoveralltheexamplesD={(x1,y1)…,(xn ,yn)}
• Thiswilloverfit badlywithsparsefeatures– Consideranywordthatappearsonlyinpositiveexamples!
22

Learning as optimization for logistic regression
• Practicalproblem:thisoverfits badlywithsparsefeatures– e.g.,ifwj isonlyinpositiveexamples,itsgradientisalways positive!
23

REGULARIZED LOGISTIC REGRESSION
24

Regularized logistic regression• ReplaceLCL
• withLCL+penaltyforlargeweights,eg
• So:
• becomes:
25

Regularized logistic regression• ReplaceLCL
• withLCL+penaltyforlargeweights,eg
• Sotheupdateforwj becomes:
• Or
26

Learning as optimization for logistic regression• Algorithm:
-- do this in random order
27

Learning as optimization for regularized logistic regression• Algorithm:
Time goes from O(nT) to O(mVT) where• n = number of non-zero entries, • m = number of examples• V = number of features • T = number of passes over data
28

This change is very important for large datasets• We’velosttheabilitytodosparse updates
• Thismakeslearningmuchmuch moreexpensive– 2*106 examples– 2*108 non-zeroentries– 2*106 +features– 10,000xslower(!)
Time goes from O(nT) to O(mVT) where• n = number of non-zero entries, • m = number of examples• V = number of features • T = number of passes over data
29

SPARSE UPDATES FOR REGULARIZED LOGISTIC REGRESSION
30

Learning as optimization for regularized logistic regression• Finalalgorithm:• Initializehashtable W• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…• ForeachfeatureW[j]–W[j] =W[j] - λ2µW[j]–Ifxij>0then»W[j] = W[j] +λ(yi - pi)xj
31

Learning as optimization for regularized logistic regression• Finalalgorithm:• Initializehashtable W• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…• ForeachfeatureW[j]–W[j] *= (1 - λ2µ)–Ifxij>0then»W[j] = W[j] +λ(yi - pi)xj
32

Learning as optimization for regularized logistic regression• Finalalgorithm:• Initializehashtable W• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…• ForeachfeatureW[j]–Ifxij>0then»W[j] *= (1 - λ2µ)A
»W[j] = W[j] +λ(yi - pi)xj
A is number of examples seen since the last time we did an x>0 update on W[j]
33

Learning as optimization for regularized logistic regression• Finalalgorithm:• Initializehashtables W,Aand set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…;k++• ForeachfeatureW[j]–Ifxij>0then»W[j] *= (1 - λ2µ)k-A[j]»W[j] = W[j] +λ(yi - pi)xj»A[j]=k
k-A[j] is number of examples seen since the last time we did an x>0 update on W[j]
34

Learning as optimization for regularized logistic regression• Finalalgorithm:• Initializehashtables W,Aand set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…;k++• ForeachfeatureW[j]–Ifxij>0then»W[j] *= (1 - λ2µ)k-A[j]»W[j] = W[j] +λ(yi - pi)xj»A[j]=k
• k = “clock” reading• A[j] = clock reading last
time feature j was “active”
• we implement the “weight decay” update using a “lazy” strategy: weights are decayed in one shot when a feature is “active”
35

Learning as optimization for regularized logistic regression
• Finalalgorithm:• Initializehashtables W,Aand set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…;k++• ForeachfeatureW[j]–Ifxij>0then»W[j] *= (1 - λ2µ)k-A[j]»W[j] = W[j] +λ(yi - pi)xj»A[j]=k
Time goes from O(nT) to O(mVT) where• n = number of non-zero entries, • m = number of examples• V = number of features • T = number of passes over data
Memory use doubles.
36

Comments• What’shappenedhere:– Ourupdateinvolvesasparsepartandadensepart• Sparse:empiricallossonthisexample• Dense:regularizationloss– notaffectedbytheexample
– Weremovethedensepartoftheupdate• Oldexampleupdate:
– foreachfeature{dosomethingexample-independent}– Foreachactivefeature{dosomethingexample-dependent}
• Newexampleupdate:– Foreachactivefeature:
» {simulatethepriorexample-independentupdates}» {dosomethingexample-dependent}
37

Comments
• Sametrickcanbeappliedinothercontexts–Otherregularizers (eg L1,…)–Conjugategradient(Langford)–FTRL(Followtheregularizedleader)–Votedperceptronaveraging–…?
38

BOUNDED-MEMORY LOGISTIC REGRESSION
39

Question
• Intextclassificationmostwordsarea. rareb. notcorrelatedwithanyclassc. givenlowweightsintheLRclassifierd. unlikelytoaffectclassificatione. notveryinteresting
40

Question
• Intextclassificationmostbigramsarea. rareb. notcorrelatedwithanyclassc. givenlowweightsintheLRclassifierd. unlikelytoaffectclassificatione. notveryinteresting
41

Question
• Mostoftheweightsinaclassifierare– important–notimportant
42

How can we exploit this?• Oneidea:combineuncommonwordstogetherrandomly• Examples:
– replacealloccurrances of“humanitarianism”or“biopsy”with“humanitarianismOrBiopsy”
– replacealloccurrances of“schizoid”or“duchy”with“schizoidOrDuchy”
– replacealloccurrances of“gynecologist”or“constrictor”with“gynecologistOrConstrictor”
– …• ForNaïveBayesthisbreaksindependenceassumptions
– it’snotobviouslyaproblemforlogisticregression,though• Icouldcombine
– twolow-weightwords(won’tmattermuch)– alow-weightandahigh-weightword(won’tmattermuch)– twohigh-weightwords(notverylikelytohappen)
• HowmuchofthiscanIgetawaywith?– certainlyalittle– isitenoughtomakeadifference?howmuchmemorydoesitsave?
43

How can we exploit this?• Anotherobservation:– thevaluesinmyhashtableareweights– thekeysinmyhashtablearestrings forthefeaturenames• Weneedthemtoavoidcollisions
• Butmaybewedon’tcareaboutcollisions?– Allowing“schizoid”&“duchy”tocollideisequivalenttoreplacingalloccurrencesof“schizoid”or“duchy”with“schizoidOrDuchy”
44

Learning as optimization for regularized logistic regression
• Algorithm:• Initializehashtables W,Aand set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• pi =…;k++• Foreachfeaturej:xij>0:
»W[j] *= (1 - λ2µ)k-A[j]
»W[j] = W[j] +λ(yi - pi)xj»A[j]=k
45

Learning as optimization for regularized logistic regression
• Algorithm:• InitializearraysW,AofsizeR and set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• LetV behashtablesothat• pi =…;k++• Foreachhashvalueh:V[h]>0:
»W[h] *= (1 - λ2µ)k-A[j]
»W[h] = W[h] +λ(yi - pi)V[h]»A[h]=k
V[h]= xij
j:hash(xij )%R=h∑
46

Learning as optimization for regularized logistic regression
• Algorithm:• InitializearraysW,AofsizeR and set k=0• Foreachiterationt=1,…T– Foreachexample(xi,yi)• LetV behashtablesothat• pi =…;k++
€
V[h] = xij
j:hash( j )%R ==h∑
???
p ≡ 11+ e−V⋅w
47

IMPLEMENTATION DETAILS
48

Fixes and optimizations
• Thisisthebasicideabut–weneedtoapply“weightdecay”tofeaturesinanexamplebeforewecomputetheprediction–weneedtoapply“weightdecay”beforewesavethelearnedclassifier–mysuggestion:• anabstractionforalogisticregressionclassifier
49

A possible SGD implementationclassSGDLogistic Regression{/**Predictusingcurrentweights**/doublepredict(Map features);/**ApplyweightdecaytoasinglefeatureandrecordwheninA[]**/voidregularize(string feature,int currentK);/**Regularizeallfeaturesthensavetodisk**/voidsave(string fileName,int currentK);/**Loadasavedclassifier**/staticSGDClassifier load(String fileName);/**Trainononeexample**/voidtrain1(Mapfeatures,doubletrueLabel,int k){
//regularizeeachfeature//predictandapplyupdate
}}//main‘train’programassumesastreamofrandomly-orderedexamplesand
outputsclassifiertodisk;main‘test’programprintspredictionsforeachtestcaseininput.
50

A possible SGD implementationclassSGDLogistic Regression{…
}//main‘train’programassumesastreamofrandomly-orderedexamplesandoutputsclassifiertodisk;main‘test’programprintspredictionsforeachtestcaseininput.
<100lines(inpython)
Othermains:• A“shuffler:”
– streamthruatrainingfileTtimesandoutputinstances– outputisrandomlyordered,asmuchaspossible,givenabufferofsizeB
• Somethingtocollectpredictions+truelabelsandproduceerrorrates,etc.
51

A possible SGD implementation• Parametersettings:–W[j] *= (1 - λ2µ)k-A[j]–W[j] = W[j] +λ(yi - pi)xj
• Ididn’ttuneespeciallybutused–µ=0.1– λ=η*E-2whereE is“epoch”,η=½• epoch:numberoftimesyou’veiteratedoverthedataset,startingatE=1
52

ICML 2009
53

An interesting example• SpamfilteringforYahoomail– Lotsofexamples andlotsofusers– Twooptions:• onefilterforeveryone—butusersdisagree• onefilterforeachuser—butsomeusersarelazyanddon’tlabelanything
– Thirdoption:• classify(msg,user)pairs• featuresofmessagei arewordswi,1,…,wi,ki• featureofuserishis/heridu• featuresofpair are:wi,1,…,wi,ki andu�wi,1,…,u�wi,ki• basedonanideabyHalDaumé
54

An example• E.g.,thisemailtowcohen
• features:– dear,madam,sir,….investment,broker,…,wcohen�dear,wcohen�madam,wcohen,…,
• idea:thelearnerwillfigureouthowtopersonalizemyspamfilterbyusingthewcohen�X features
55
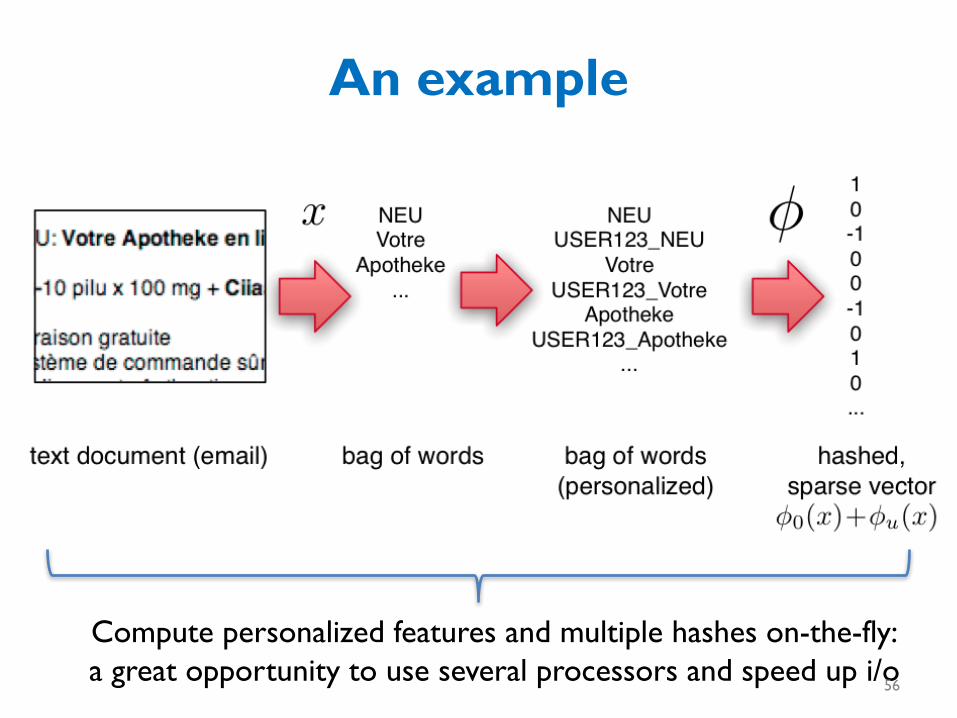
An example
Compute personalized features and multiple hashes on-the-fly:a great opportunity to use several processors and speed up i/o
56

Experiments
• 3.2Memails• 40Mtokens• 430kusers• 16Tuniquefeatures– afterpersonalization
57
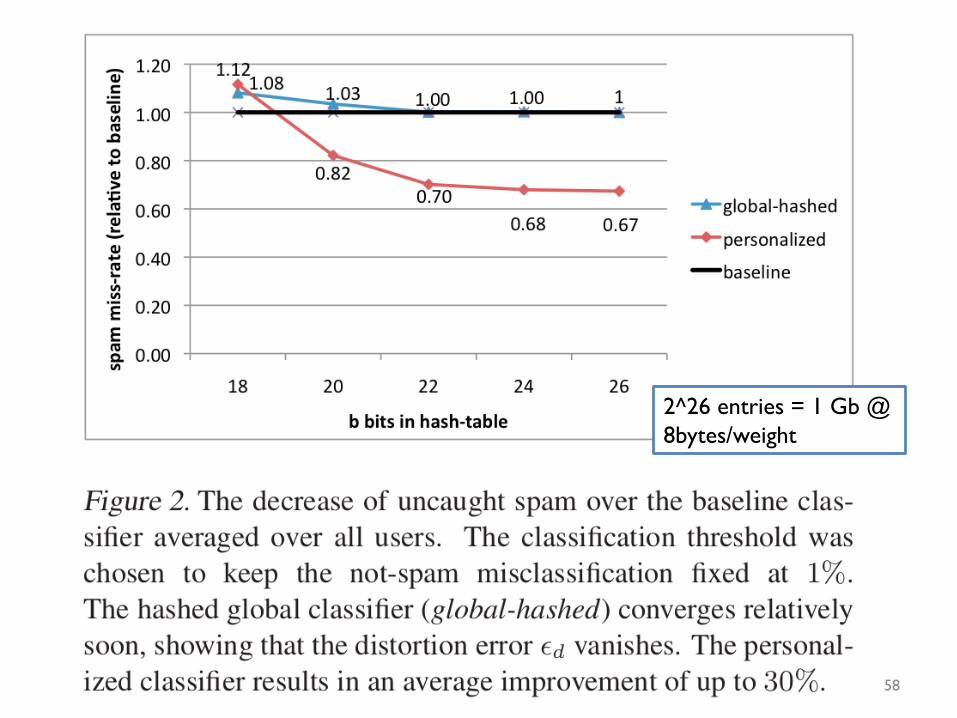
An example
2^26 entries = 1 Gb @ 8bytes/weight
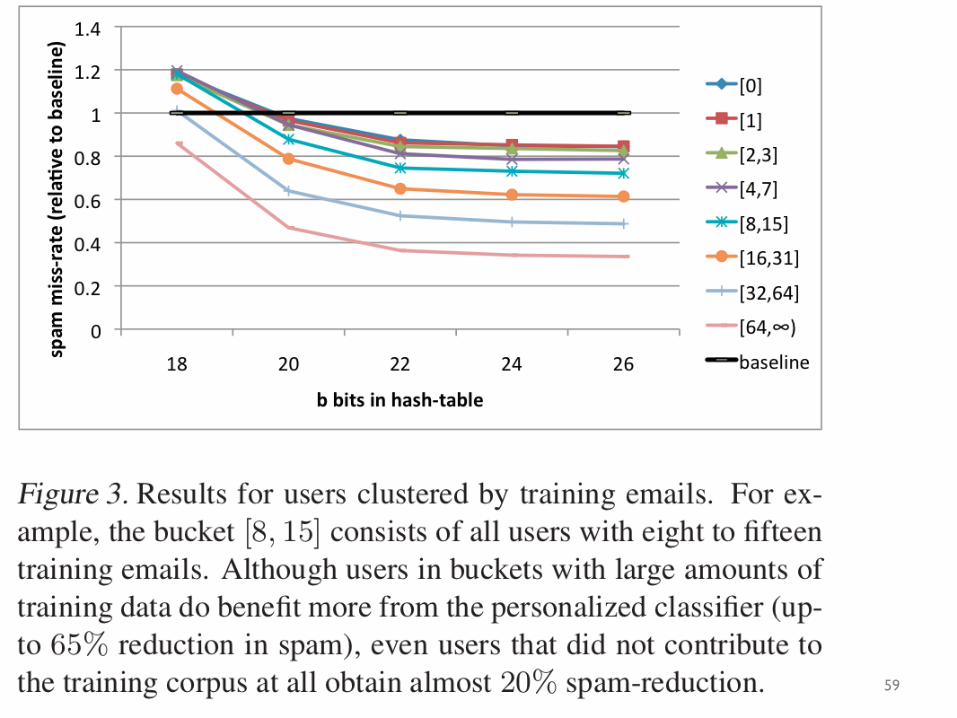
58
59