analysis of the effects of related fingerprints on
TRANSCRIPT

Kuwahara and Gao J Cheminform (2021) 13:27 https://doi.org/10.1186/s13321-021-00506-2
RESEARCH ARTICLE
Analysis of the effects of related fingerprints on molecular similarity using an eigenvalue entropy approachHiroyuki Kuwahara and Xin Gao*
Abstract
Two-dimensional (2D) chemical fingerprints are widely used as binary features for the quantification of structural similarity of chemical compounds, which is an important step in similarity-based virtual screening (VS). Here, using an eigenvalue-based entropy approach, we identified 2D fingerprints with little to no contribution to shaping the eigenvalue distribution of the feature matrix as related ones and examined the degree to which these related 2D fin-gerprints influenced molecular similarity scores calculated with the Tanimoto coefficient. Our analysis identified many related fingerprints in publicly available fingerprint schemes and showed that their presence in the feature set could have substantial effects on the similarity scores and bias the outcome of molecular similarity analysis. Our results have implication in the optimal selection of 2D fingerprints for compound similarity analysis and the identification of potential hits for compounds with target biological activity in VS.
Keywords: Structure-activity relationship, Similarity-based virtual screening, 2D fingerprint, Unsupervised feature selection, Chemoinformatics
© The Author(s) 2021. This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http:// creat iveco mmons. org/ licen ses/ by/4. 0/. The Creative Commons Public Domain Dedication waiver (http:// creat iveco mmons. org/ publi cdoma in/ zero/1. 0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
IntroductionVirtual screening (VS) is a computational approach that is widely used as a cost-effective alternative to the tra-ditional high-throughput screening for the selection of initial hits in a search for drugs with a given biological activity [1, 2]. The foundation of similarity-based VS is structure-activity relationship (SAR), a concept in which molecules with similar structures are destined to have similar biological activities. In such VS applications, thus, the quantification of structural similarity of molecules is a crucial step. To quantify the structural similarity of a pair of molecules, the Tanimoto similarity measure is commonly applied to fingerprint features based on their two-dimensional (2D) structures. These 2D fingerprints
represent each molecule as a binary (0 or 1) vector characterizing the absence or the presence of specific properties of its 2D structure. Although this feature rep-resentation is simple, it has been reported to be more effective than those using more complex features such as 3D structural patterns [3, 4].
There are libraries of predefined 2D chemical finger-print dictionaries available to represent molecules as binary vectors [5]. Among the most commonly used fin-gerprint schemes for similarity quantification is molecu-lar access system (MACCS) [6], which was reported to cover many useful 2D features for virtual screening [7]. While these predefined fingerprint dictionaries are easy to use, previous studies demonstrated that the selec-tion of relevant 2D fingerprints from the original set resulted in better performance [8–10]. These feature selection methods typically focus on supervised machine learning settings in which to select a subset of relevant 2D fingerprints that intend to enhance the generality to
Open Access
Journal of Cheminformatics
*Correspondence: [email protected] Bioscience Research Center (CBRC), King Abdullah University of Science and Technology (KAUST), Thuwal 23955, Saudi Arabia

Page 2 of 12Kuwahara and Gao J Cheminform (2021) 13:27
discriminate chemical compounds with a given biological activity against those without. For example, Nisius, et al. ranked 2D fingerprints by applying the Kullback-Leibler divergence to each fingerprint to quantify its asymmet-ric usage between the active compound class and the inactive one [11]. Given the nature of drug discovery, however, these supervised feature selection approaches inevitably face a challenging class imbalance problem in practice as available compounds with the target bio-logical activity is most likely very scarce. That is, had the number of target bioactive compounds been large enough to begin with, a pipeline to discover more of the same would not have probably warranted a large cost of investment.
Here, we focus on a different issue in the combination of 2D fingerprints and analyze the effects of related fin-gerprints on the quantification of molecular similarity using eigenvalue-based entropy. The eigenvalue-based entropy was introduced by Alter et al. [12] to indicate the weight distribution of gene expression eigenvectors for analysis of temporal gene expression patterns. Var-shavsky et al. [13] developed an unsupervised feature selection method that ranks each feature by measuring its contribution to the eigenvalue-based entropy. We defined the relatedness of each 2D fingerprint based on the degree to which the shape of the eigenvalue distribu-tion of the feature matrix is changed. And, by using the eigenvalue-based entropy as the scaler value to indicate the distribution of eigenvalues, we determined related 2D fingerprints. Thus, we defined a related 2D fingerprint as a feature that has a (quasi) linear relationship with some other fingerprints in the feature set regardless of its rel-evance and importance for the discriminability. As illus-trated in Fig. 1, the presence of such related fingerprints can inflate or deflate similarity scores, potentially chang-ing the outcome of molecular similarity analysis and VS.
In this paper, we applied MACCS and Pubchem finger-print schemes to human metabolite and drug compound datasets and identified many fingerprints as related ones. While the effects of related fingerprints depended on various factors such as query compounds, the general trend of the effects of the presence of related 2D finger-prints was found to mildly lower overall similarity scores and some of these negative effects were found to be sub-stantial. Our analysis demonstrated that these effects can pose challenges in ranking similar compounds and quali-tatively change the outcome of VS.
MethodsDatasetsFrom Human Metabolome Database (HMDB) [14], we retrieved 2D structure data for 25,376 metabo-lites on September 5, 2019. With a filtering for the
metabolites found in blood with the metabolite status being “Detected and Quantified,” we further obtained the information about 3,202 metabolites for the blood specimen.
From DrugBank (version 5.1.7) [15], we downloaded the dataset for aproved drugs with 2,636 entries. After preprocessing for unique and valid SMILES data, we obtained 2,466 drug compounds for the DrugBank dataset.
Molecular similarity measureWe used the implementation of CDK (version 2.3) [16] to compute 166-bit MACCS and 881-bit Pubchem fin-gerprint vectors. To measure the similarity of a pair of compounds, a and b, we computed the Tanimoto coef-ficient of their l-bit fingerprint vectors, va and vb as follows:
where v(i) represents the i-th element of vector v.
(1)sim(a, b) =
∑li=1 va(i)vb(i)
∑li=1 va(i)+ vb(i)− va(i)vb(i)
,
1 0 1 1 1 0 1 1 0F1 F2 F3 F4 F5 F6 F7 F8 F9
query
1 0 1 1 0 0 0 0 1compound 11 1 1 0 0 0 1 0 0compound 20 0 0 0 1 1 1 1 0compound 3
Collinearity: 2F1 = F2 + F3 + F4
With collinearity
Without collinearity
compound 1
compound 2
compound 3
373737
Tc041334
Tc
Fig. 1 An illustrative example for the effects of related fingerprints on similarity measures. A hypothetical fingerprint scheme with nine bit keys ( F1 to F9 ) is used to represent small molecules in a hypothetical compound dataset. The fingerprint matrix of this dataset is found to have a perfect multicollinearity in the first four features with 2 F1 = F2 + F3 + F4 . The similarity of a query compound against three compounds is computed using Tanomoto coefficient (Tc) with and without this collinearity. For the results without the collinearity, the Tanimoto coefficient without the first four features ( F1 to F4 ) is shown

Page 3 of 12Kuwahara and Gao J Cheminform (2021) 13:27
Eigenvalue‑based entropyLet A be an m by n matrix. Then, an n by n symmetric matrix ATA is positive semidefinite and has real eigen-values �1 ≥ �2 ≥ · · · ≥ �n ≥ 0 . By defining qj to be the j-th normalized eigenvalue qj = �j/
∑nk=1 �k , we com-
puted a single value that indicates the complexity of the distribution of eigenvalues with the normalized entropy of eigenvalues [12] as follows:
This entropy ranges from 0 to 1, with 0 indicating that the dataset can be constructed based on a single eigenvec-tor and 1 indicating that each eigenvector has an equal contribution to the dataset. Eigenvalues were computed using the svd function in R.
Eigenvalue‑based fingerprint contribution measureSuppose we have m compounds, each of which is expressed with n-bit 2D fingerprints. That is, we have an m by n matrix A whose element ai,j represents the value of the j-th fingerprint for the i-th compound. Let A[−i] be an m by n matrix that has all but the i-th column of A, with the i-th column replaced by a zero column. We computed the contribution of the i-th ( 1 ≤ i ≤ n ) fingerprint, hi as hi = H(A[−i]) where H(M) is the eigenvalue-based entropy of matrix M given by Equ. 2. Note that, because we can first compute n-by-n matrix from ATA , the computation of each fingerprint entropy depends on the number of the fingerprints and not on the number of compounds, which is presumed to be very large.
Contribution of related fingerprints to the similarity scoreSuppose we have two l-bit fingerprint vectors va and vb . Further suppose that two k-bit fingerprint vectors ua and ub are subvectors of va and vb , respectively, that represent their related fingerprints. To measure the contribution of the related fingerprints to the Tanimoto coefficient, we compute two scores: the contribution to the union set and the contribution to the intersect-ing set. The contribution to the union set of va and vb is defined to be the ratio of the union set of the related fingerprint vectors to the union set of the original fin-gerprint vectors as follows:
while the contribution to the intersecting set of va and vb is defined to be the ratio of the intersecting set of the
(2)H = −1
log (n)
n∑
j=1
qj log (qj).
(3)∑k
i=1 ua(i)+ ub(i)− ua(i)ub(i)
ǫ +∑l
i=1 va(i)+ vb(i)− va(i)vb(i),
related fingerprint vectors to the intersecting set of the original fingerprint vectors as follows:
where ǫ is a small constant (e.g., 10−10 ) to avoid the divi-sion by zero.
ResultsPresence of highly correlated fingerprintsMACCS keys are 166-bit 2D structure fingerprints that are commonly used for the measure of molecular simi-larity. Because each bit is either on (i.e., 1) or off (i.e., 0), MACCS 166 keys can represent more than 9.3× 1049 distinct fingerprint vectors. After removing 454 entries with duplicate canonical SMILES strings, we generated 24,922 MACCS fingerprint vectors using the metabo-lite data we obtained from HMDB [14] (see "Methods"). After filtering out duplicates, we ended up with 3,125 unique fingerprint vectors. On average, thus, 8 metabo-lites were represented by the same MACCS fingerprint vector, indicating a high degree of collisions. The high level of collided metabolites suggests the possibility that many MACCS keys describe related 2D substructure characteristics.
To analyze the use of each MACCS key, we first counted the occurrence of on bit for each key in the 3,125 unique fingerprint vectors (Fig. 2a). We found that 39% of the 166 MACCS keys are on (i.e., 1) for fewer than 10% of the fingerprint vectors, while only 1 key is on for more than 90% of the vectors. This skewed use of molecular fingerprints ( γ1 = 0.777 ) indicates that many fingerprint bits are set to be off (i.e., 0) in most of the vec-tors, resulting in highly similar usage patterns. However, since Tanimoto coefficient, the most commonly used 2D fingerprint-based similarity measure, does not consider the off bits (see "Methods"), its similarity analysis of these HMDB metabolites may not be influenced by the finger-prints with many off bits.
We next analyzed the association of MACCS keys whose on-bit counts are more moderate and whose effects on similarity measure are assumed to be more profound. To this end, we focused on a subset of the MACCS keys whose on-bit counts are in a range between 25% and 75% of the total number of the unique vectors. We obtained 68 MACCS keys that satisfied this con-straint and computed their pairwise correlation coeffi-cient values (Fig. 2b). We found that a large fraction of the pairs (73%) had positive correlation ( r ≥ 0 ). Out of 2,278 fingerprint pairs, while none had strong negative correlation ( r ≤ −0.5 ), 105 had strong positive correla-tion ( r ≥ 0.5 ). Among these positively correlated pairs,
(4)∑k
i=1 ua(i)ub(i)
ǫ +∑l
i=1 va(i)vb(i),

Page 4 of 12Kuwahara and Gao J Cheminform (2021) 13:27
0.0003200.002900.000320.00130.000320.0240.00320.000960.0260.00130.0120.00420.000960.00960.0110.0016
0.0680.000320.00320.0250.0240.0360.0490.055
0.00580.016
0.0520.035
0.00160.040.044
0.0240.00064
0.0740.0740.12
0.0270.028
0.0120.0670.11
0.0120.0280.00640.0490.0750.069
0.130.0580.054
0.270.31
0.0740.014F56
F55F54F53F52F51F50F49F48F47F46F45F44F43F42F41F40F39F38F37F36F35F34F33F32F31F30F29F28F27F26F25F24F23F22F21F20F19F18F17F16F15F14F13F12F11F10
F9F8F7F6F5F4F3F2F1
0.00 0.25 0.50 0.75 1.00on fraction
MAC
CS
finge
rprin
t
0.250.0750.0690.0810.083
0.180.023
0.0610.26
0.230.091
0.00580.13
0.0320.051
0.340.087
0.180.26
0.150.24
0.0880.240.24
0.130.27
0.310.21
0.340.25
0.130.17
0.40.480.47
0.290.28
0.140.390.39
0.340.41
0.220.4
0.0490.18
0.10.49
0.430.28
0.160.33
0.280.33
0.45F111F110F109F108F107F106F105F104F103F102F101F100
F99F98F97F96F95F94F93F92F91F90F89F88F87F86F85F84F83F82F81F80F79F78F77F76F75F74F73F72F71F70F69F68F67F66F65F64F63F62F61F60F59F58F57
0.00 0.25 0.50 0.75 1.00on fraction
0.420.35
0.180.350.350.360.35
0.110.39
0.450.39
0.460.23
0.270.36
0.60.36
0.420.17
0.640.54
0.260.17
0.220.43
0.580.31
0.690.46
0.210.46
0.60.4
0.510.64
0.530.47
0.40.58
0.490.63
0.580.69
0.650.6
0.790.65
0.80.670.7
0.670.78
0.830F166
F165F164F163F162F161F160F159F158F157F156F155F154F153F152F151F150F149F148F147F146F145F144F143F142F141F140F139F138F137F136F135F134F133F132F131F130F129F128F127F126F125F124F123F122F121F120F119F118F117F116F115F114F113F112
0.00 0.25 0.50 0.75 1.00on fraction
0.92
a
Fig. 2 Fingerprint usage patterns of MACCS 166 keys on HMDB metabolite dataset. a The on-bit count of each key. b The pairwise Pearson’s correlation coefficient value for each pair of 68 MACCS keys with moderate on-bit counts

Page 5 of 12Kuwahara and Gao J Cheminform (2021) 13:27
the 127th and the 143rd fingerprints, both of which had 1,875 on-bit counts, had the perfect positive correlation, suggesting that 2D structures characterized by these two fingerprints are highly related. Although the correlation coefficient can capture only a limited type of related fin-gerprints, these results suggest the prevalence of related fingerprints in the predefined 2D fingerprint dictionaries.
Characterization of related fingerprintsWe next sought to analyze the extent to which more general types of related fingerprints were present in the MACCS and Pubchem fingerprint dictionaries. To this
end, we gathered 3202 metabolites found in the blood specimen from the HMDB metabolite dataset and fil-tered out compounds with duplicate 2D structures, duplicate fingerprint vectors, and all-zero MACCS fin-gerprint vectors. In addition, we removed each com-pound whose MACCS fingerprint vector has off bits for more than 90% of the fingerprints.
With this data preprocessing, we selected 1023 metab-olites that have unique fingerprint vectors. The 1023 by 166 matrix formed with the MACCS fingerprints had the rank of 144, where the column represents the fingerprints and the row represents the metabolite (see "Methods"),
F53F54F65F72F75F82F83F85F86F89F90F91F92F93F95F96F97F98
F100F104F105F106F108F109F110F111F112F113F115F116F117F118F120F121F122F123F125F126F127F128F129F131F132F133F136F137F138F139F140F142F143F144F145F146F147F148F149F150F151F152F153F154F155F156F158F160F161F162
F53
F54
F65
F72
F75
F82
F83
F85
F86
F89
F90
F91
F92
F93
F95
F96
F97
F98
F100
F104
F105
F106
F108
F109
F110
F111
F112
F113
F115
F116
F117
F118
F120
F121
F122
F123
F125
F126
F127
F128
F129
F131
F132
F133
F136
F137
F138
F139
F140
F142
F143
F144
F145
F146
F147
F148
F149
F150
F151
F152
F153
F154
F155
F156
F158
F160
F161
F162
-1.0
-0.5
0.0
0.5
1.0
PearsonCorrelation
b
Fig. 2 continued

Page 6 of 12Kuwahara and Gao J Cheminform (2021) 13:27
indicating that the pattern of ∼ 15% of MACCS fin-gerprints can be completely captured by the rest. The Pubchem fingerprints resulted in a 1023 by 881 finger-print matrix that had the rank of 377, indicating even more pronounced effects of rank deficiency with more than half of the fingerprints completely characterized by linear combinations of 377 fingerprints.
To assess the degree of related fingerprints, we defined the relatedness using the eigenvalue-based entropy (see "Methods"). This eigenvalue-based entropy measure indicates the shape of the eigenvalue distri-bution [12], with its value ranging from 0 to 1 where a lower value indicates that the matrix can be recon-structed with a linear combination of a smaller num-ber of eigenvectors. The distribution of the normalized eigenvalues for the MACCS and Pubchem fingerprint matrices shows that the first component has > 6 times higher weight than the second one in both (Fig. 3a), indicating that their entropy values must be lower. Indeed, the entropy values of the original MACCS and Pubchem matrices were 0.474 and 0.355, respectively. To measure the relatedness of the i-th fingerprint with the other fingerprints, we computed the change in the entropy between the original fingerprint-feature matrix and the feature matrix without the i-th fingerprint (see "Methods"). This can indicate the contribution of the i-th fingerprint to shaping the eigenvalue distribu-tion, which, in turn, allows us to evaluate the degree to which the i-th fingerprint is linearly related to some other fingerprints. Figure 3b shows the distribution of the fingerprint entropy values for both the MACCS
and Pubchem schemes. We found a high peak at the entropy value of the original fingerprint-feature matrix, with many fingerprints having their entropies in near the original one, indicating that these fingerprints do not contribute much to the eigenvalue distribution and are highly related to some other fingerprints.
By measuring the relatedness based on the distance between the original entropy and the entropy for each fingerprint, we selected related fingerprints from the original MACCS and Pubchem fingerprint dictionar-ies. Let h0 and hi (1 ≤ i ≤ n) be the eigenvalue-based entropy of the original feature matrix and for the i-th fingerprint, respectively. Then, we selected the i-th fin-gerprint as a related feature if hi satisfies the following condition:
where z is a reduced-level threshold parameter, which was set to 0.1, 0.2, and 0.3 in this study. Based on this approach, we found that many fingerprints in the MACCS and Pubchem dictionaries are related (Fig. 4a). With the reduced-level threshold being 0.1, 0.2, and 0.3, we identified 28, 48, 62 related fingerprints in MACCS and 454, 525, and 555 in Pubchem, respectively. A larger fraction of the related fingerprints identified in the Pubchem scheme with the low threshold value was expected given that the distribution of its fingerprint entropies had a higher density of the fingerprints near the original entropy.
(5)|hi − h0| < z
√
∑nj=1
(
hj − h0)2
n,
dens
ity
norm
aliz
ed e
igen
valu
e
entropy0.355 0.356 0.357
original entropy
Pubchem
0.4725 0.4750 0.4775 0.4800
original entropy
MACCS
0.0
0.2
0.4
0.6
1 2 3 4 5 6 7 8 9 10
0.0
0.2
0.4
0.6
1 2 3 4 5 6 7 8 9 10component
Pubchem
MACCSa b
Fig. 3 Eigenvalue-based analysis of MACCS and Pubchem fingerprint matrices. a Normalized eigenvalues of the first 10 components for MACCS and Pubchem fingerprint matrices. b The distribution of the eigenvalue-based entropy for MACCS and Pubchem fingerprints

Page 7 of 12Kuwahara and Gao J Cheminform (2021) 13:27
Effects of related fingerprints on molecular similarity scoresUsing the related fingerprints identified with the eigen-value-based entropy approach, we set out to examine their effects on the similarity score. To this end, we first constructed 1023 by 1023 similarity matrix by comput-ing the Tanimoto coefficient for each metabolite pair and generated the normalized eigenvalues of similarity matrices (Fig. 4b). The comparison of the first six com-ponents suggests that the similarity matrices computed from fingerprint sets with various reduction levels in both MACCS and Pubchem schemes are similar. Next, we measured the absolute difference of 522,753 distinct metabolite pairs between the original fingerprint set and reduced fingerprint sets. We found that the differ-ence increased as the reduced level threshold increased in both MACCS and Pubchem fingerprint dictionaries (Fig. 4c). While both fingerprint schemes had quanti-tatively similar levels of absolute differences with the reduced level at 0.01, the difference became wider as the threshold increases particularly in MACCS, sug-gesting the effects of removing related fingerprints were greater in the MACCS scheme even though a higher fraction of fingerprints were removed in the Pubchem scheme.
To further analyze the effects of related fingerprints on the Tanimoto similarity scores, we grouped the metab-olites in the blood specimen into four classes: drug, microbial, plant, and endogenous using the metabolite annotation retrieved from HMDB. In each of these four categories, we computed the average of the pairwise Tan-imoto similarity scores. The results show that the aver-age similarity scores from the reduced fingerprint sets are quantitatively close to those from the original fingerprint sets (Table 1). Similarity scores from the reduced finger-print sets were found to be marginally higher than those from the original fingerprint sets. In other words, the inclusion of related fingerprints had negative effects and slightly decreased the Tanimoto similarity score.
To characterize the significance of the negative effects of the related fingerprints on individual compound pairs, we identified the pairs with the 30 largest absolute differ-ences in the similarity score computed with two reduced-level thresholds 0 and 0.3 for each of the MACCS and Pubchem fingerprint schemes. From the comparison of the similarity scores for different threshold levels in these 60 compound pairs, the negative effects of the related fingerprints on the similarity score were found to be prevalent (Fig. 5). Indeed, the similarity scores using the reduced fingerprints with the threshold 0.3, for example, demonstrated strong association between the related fin-gerprints and the negative effects on the similarity scores ( p < 10−22 with two-sided exact binomial test).
0.0
0.2
0.4
0.6
0.8
1 2 3 4 5 6component
norm
aliz
ed e
igen
valu
e
MACCS
Pubchem
0.00
0.25
0.50
0.75
1 2 3 4 5 6
reduced level00.10.20.3
0.0
0.2
0.4
0.6
0.8
0.01 0.02 0.03 0.04 0.05
0.0
0.2
0.4
0.6
0.01 0.02 0.03 0.04 0.05threshold
frac
of p
airs
with
abs
olut
e di
ffere
nce
> th
resh
old
MACCS
Pubchem
reduced level0.10.20.3
100.0
83.1
71.1
62.7
100.0
48.5
40.4
37.0
0.00 0.25 0.50 0.75 1.00
0.3
0.2
0.1
0
0.3
0.2
0.1
0
fingt
erpr
int s
chem
e
scheme MACCS Pubchem
fraction of used fingerprints
a
b
c
Fig. 4 Comparison of the Tanimoto similarity score based on different reduction levels. a The fraction of used fingerprints with respect to given reduced levels for MACCS and Pubchem fingerprints. The reduced level 0 indicates the fraction for the original fingerprints. b The comparison of the first 6 principal components with respect to different reduction levels. c The comparison of the fraction of metabolite pairs with the absolute similarity score difference between the original set of fingerprints and a given reduced set of fingerprints exceeding specified threshold values

Page 8 of 12Kuwahara and Gao J Cheminform (2021) 13:27
Effects of related fingerprints for different query compoundsNext, we set out to examine the extent to which related fingerprints can impact the analysis of similar com-pounds for different query compounds. To this end, we used the drug compound data from DrugBank 5.1.7 (see "Methods") and generated the fingerprint vectors of the 2,466 drugs using MACCS and Pubchem fingerprint schemes. We performed the eigenvalue-based entropy approach on the dataset with 0.3 as the reduced-level threshold, identifying 34 and 470 fingerprint features as related features for the MACCS and Pubchem schemes, respectively. We then randomly selected 10 drugs as the query compounds and measured their structural similarity against the other 2,456 compounds using the Tanimoto coefficient. To analyze the contribution of the related fingerprint features for each query compound, we used the compounds with the 50 highest similar-ity scores. Because the Tanimoto coefficient of a pair of fingerprint vectors is the ratio of the size of their inter-secting set to that of their union set, we measured the contribution to the intersecting set and the union set, separately (see "Methods"). When the contribution of the related fingerprints to the intersecting set is higher than the union set, they have positive effects on the Tanimoto coefficient. By contrast, when their contribution to the intersecting set is lower than the union set, they have negative effects on the Tanimoto coefficient.
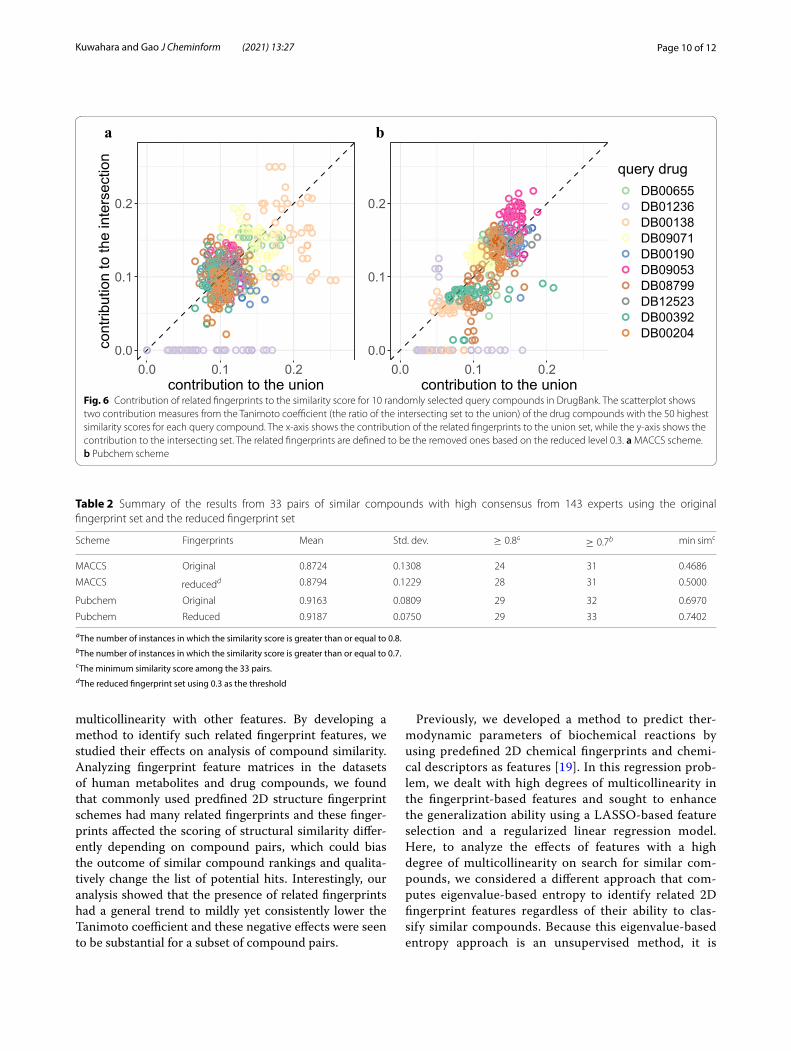
The contribution of related fingerprints to the Tani-moto coefficient was found to vary among different com-pound pairs as well as between MACCS and Pubchem (Fig. 6). Although, in both schemes, the related finger-prints had positive and negative effects on similarity scores of drug pairs, their effects to the union set were more significant and prevalent in the MACCS fingerprint scheme. In addition, consistent with the analysis on the HMDB dataset, stronger effects of the related finger-prints were found in those pairs with higher contribution
to the union set for both MACCS and Pubchem schemes (i.e., those with negative effects).
Interestingly, the contribution of the related finger-prints displayed clustering patterns based on the query compounds. With Sevoflurane (DB01236) as the query drug, for example, the related fingerprints contributed minimal on the intersecting set compared with the union set for both MACCS and Pubchem, indicating that the related fingerprints had stronger negative effects on the similarity scores for this drug. For Ibrutinib (DB09053), while they contributed to both the intersecting and the union sets more than 10%, the related fingerprints influ-enced the intersecting set more, indicating that they had positive effects on the similarity score. These results indi-cates that the impact of related fingerprints can depend strongly on query compounds, suggesting that the pres-ence of related fingerprints can give rise to bias in simi-larity scores, potentially making fair analysis of similar compounds for various query compounds challenging.
Effects of related fingerprints on drug similarity accuracyAlthough our results showed the effects of related finger-prints on molecular similarity analysis based on the Tani-moto coefficient, it is not clear if those effects can lead to qualitatively significant changes in structural similarity-based molecule screening. To analyze potential effects of related fingerprints in such SAR-based analysis, we used a dataset consisting of 100 drug compound pairs from DrugBank 3.0 [17] that 143 experts analyzed to provide their yes or no binary decisions about the structural simi-larity [18]. To use this dataset as the correct reference for similar compounds, we selected a subset of the 100 pairs whose similarity was supported by at least 80% of the experts, resulting in 33 pairs of similar compounds. The Tanimoto similarity scores of these compound pairs were computed using the original fingerprint set as well as the reduced one from the DrugBank 5.1.7 dataset, with the reduced-level threshold set to 0.3.
Table 1 The average Tanimoto similarity score for five classes of metabolites in the blood specimen for the MACCS and Pubchem fingerprint schemes with different reduction levels
Scheme Level Drug Microbial Plant Endogenous All
MACCS 0 0.3008 0.3531 0.3662 0.3211 0.3142
MACCS 0.1 0.2990 0.3489 0.3696 0.3190 0.3122
MACCS 0.2 0.2944 0.3536 0.3723 0.3188 0.3118
MACCS 0.3 0.3013 0.3578 0.3785 0.3211 0.3149
Pubchem 0 0.3048 0.3323 0.3873 0.2967 0.2968
Pubchem 0.1 0.3104 0.3390 0.3922 0.3012 0.3016
Pubchem 0.2 0.3167 0.3384 0.3974 0.3043 0.3053
Pubchem 0.3 0.3217 0.3395 0.4010 0.3071 0.3085

Page 9 of 12Kuwahara and Gao J Cheminform (2021) 13:27
We first analyzed the performance of each fingerprint set by computing five measures: the mean of the similar-ity scores, the standard deviation of the scores, the num-ber of pairs whose similarity scores are ≥ 0.8 , the number of pairs whose similarity scores are ≥ 0.7 , and the mini-mum similarity score (Table 2). We decided to focus on the number of positives because in virtual screening molecular similarity is used to filter out incompatible
compounds and to generate initial hits with potentially similar bioactive properties in order to capture them in follow-up screenings [1]. That is, in the filtering for the initial hits, as long as true positives are included, the number of false positives is not as important.
The reduced fingerprint set resulted in an increase in the average similarity scores and a decrease in the vari-ance of the similarity scores mildly yet consistently in both MACCS and Pubchem schemes. An increase in the overall similarity score is consistent with the results from the HMDB dataset, while a decrease in the variance can be explained by the enhanced generalization achieved with the removal of related fingerprints. The number of pairs with high similarity sores also increased by remov-ing related fingerprints; in the MACCS scheme, the original fingerprint set and the reduced fingerprint set with the threshold 0.03 correctly predicted 73% and 85% of the reference pairs with the positive-calling thresh-old of 0.8, while in the Pubchem scheme, they correctly predicted 97% and 100% of the pairs with the positive-calling threshold of 0.7. Furthermore, in both fingerprint schemes, the reduced fingerprint set resulted in > 6% increase in the minimum similarity score among the 33 reference pairs, indicating that the filtering of related fingerprints was able to improve the similar compound search more inclusively.
To better understand the significance of the results from the reduced fingerprint set, we generated 10,000 sets of reduced fingerprints by randomly pruning the original fingerprint set to have the same size as the one with the reduced-level threshold 0.03. The comparison revealed that the filtering of related fingerprints had a tendency to substantially increase the similarity scores of a number of pairs, while the random pruning did not show such directionality bias (Fig. 7). To further analyze significant changes from the filtering of related finger-prints, we computed the p-value with the null hypoth-esis that the filtering of related fingerprints is the same as the random pruning. We obtained two and four pairs with significant changes ( p < 0.05 ) from the MACCS and Pubchem schemes, respectively, and all of these pairs resulted in an increase in their similarity scores with the removal of related fingerprints. These results indicate that related fingerprints are likely to contribute to the union set more significantly and that the filtering of such fingerprint features can increase the Tanimoto coefficient of structurally similar compound pairs.
ConclusionsIn this study, we defined related fingerprints to be those that do not contribute to the shape of the eigen-value distribution of the original fingerprint feature matrix and thus are thought to possess a high degree of
HMDB0000996 HMDB0001049HMDB0000996 HMDB0001067HMDB0000996 HMDB0029159HMDB0000641 HMDB0000996HMDB0000641 HMDB0000731HMDB0000731 HMDB0001049HMDB0000168 HMDB0000996HMDB0000812 HMDB0000996HMDB0001232 HMDB0001859HMDB0000731 HMDB0004122HMDB0000996 HMDB0011737HMDB0000996 HMDB0011170HMDB0000125 HMDB0000996HMDB0000731 HMDB0011737HMDB0000731 HMDB0001370HMDB0000731 HMDB0003357HMDB0000731 HMDB0011170HMDB0000731 HMDB0029159HMDB0000925 HMDB0004983HMDB0000099 HMDB0000731HMDB0000996 HMDB0029147HMDB0002878 HMDB0059586HMDB0000731 HMDB0015673HMDB0000996 HMDB0011171HMDB0011753 HMDB0061742HMDB0000148 HMDB0000996HMDB0000731 HMDB0029147HMDB0000148 HMDB0000731HMDB0011741 HMDB0155722HMDB0000996 HMDB0001890HMDB0037547 HMDB0061387HMDB0037547 HMDB0061385HMDB0001139 HMDB0059571HMDB0034902 HMDB0059571HMDB0001885 HMDB0003474HMDB0001220 HMDB0059571HMDB0002664 HMDB0059571HMDB0001232 HMDB0001928HMDB0000900 HMDB0059571HMDB0001398 HMDB0061385HMDB0003634 HMDB0059571HMDB0000876 HMDB0059571HMDB0005176 HMDB0059571HMDB0001438 HMDB0059571HMDB0002277 HMDB0059571HMDB0000159 HMDB0001885HMDB0001403 HMDB0059571HMDB0037547 HMDB0060472HMDB0000021 HMDB0001885HMDB0001885 HMDB0002210HMDB0005010 HMDB0037547HMDB0059571 HMDB0060054HMDB0001885 HMDB0015166HMDB0005028 HMDB0037547HMDB0004472 HMDB0059571HMDB0000610 HMDB0059571HMDB0001928 HMDB0037547HMDB0005010 HMDB0060472HMDB0001885 HMDB0001904HMDB0037547 HMDB0061386
00.
10.
20.
3 00.
10.
20.
3
0.00
0.25
0.50
0.75
1.00
Similarityvalue
MACCS Pubchem
Fig. 5 Illustration of 60 metabolite pairs with high levels of changes in Tanimoto similarity measures. Heatmap showing the similarity scores of 60 metabolite pairs based (y-axis) on given levels of reduced fingerprint sets (x-axis). From the MACCS and Pubchem fingerprint dictionaries, 30 pairs are selected from each based on the difference between the original set of fingerprints and a reduced set of fingerprints with reduced level 0.3
Page 10 of 12Kuwahara and Gao J Cheminform (2021) 13:27
multicollinearity with other features. By developing a method to identify such related fingerprint features, we studied their effects on analysis of compound similarity. Analyzing fingerprint feature matrices in the datasets of human metabolites and drug compounds, we found that commonly used predfined 2D structure fingerprint schemes had many related fingerprints and these finger-prints affected the scoring of structural similarity differ-ently depending on compound pairs, which could bias the outcome of similar compound rankings and qualita-tively change the list of potential hits. Interestingly, our analysis showed that the presence of related fingerprints had a general trend to mildly yet consistently lower the Tanimoto coefficient and these negative effects were seen to be substantial for a subset of compound pairs.
Previously, we developed a method to predict ther-modynamic parameters of biochemical reactions by using predefined 2D chemical fingerprints and chemi-cal descriptors as features [19]. In this regression prob-lem, we dealt with high degrees of multicollinearity in the fingerprint-based features and sought to enhance the generalization ability using a LASSO-based feature selection and a regularized linear regression model. Here, to analyze the effects of features with a high degree of multicollinearity on search for similar com-pounds, we considered a different approach that com-putes eigenvalue-based entropy to identify related 2D fingerprint features regardless of their ability to clas-sify similar compounds. Because this eigenvalue-based entropy approach is an unsupervised method, it is
0.0
0.1
0.2
0.0 0.1 0.2contribution to the union
cont
ribut
ion
to th
e in
ters
ectio
n
0.0
0.1
0.2
0.0 0.1 0.2contribution to the union
query drugDB00655DB01236DB00138DB09071DB00190DB09053DB08799DB12523DB00392DB00204
a b
Fig. 6 Contribution of related fingerprints to the similarity score for 10 randomly selected query compounds in DrugBank. The scatterplot shows two contribution measures from the Tanimoto coefficient (the ratio of the intersecting set to the union) of the drug compounds with the 50 highest similarity scores for each query compound. The x-axis shows the contribution of the related fingerprints to the union set, while the y-axis shows the contribution to the intersecting set. The related fingerprints are defined to be the removed ones based on the reduced level 0.3. a MACCS scheme. b Pubchem scheme
Table 2 Summary of the results from 33 pairs of similar compounds with high consensus from 143 experts using the original fingerprint set and the reduced fingerprint set
aThe number of instances in which the similarity score is greater than or equal to 0.8.bThe number of instances in which the similarity score is greater than or equal to 0.7.cThe minimum similarity score among the 33 pairs.dThe reduced fingerprint set using 0.3 as the threshold
Scheme Fingerprints Mean Std. dev. ≥ 0.8a
≥ 0.7b min simc
MACCS Original 0.8724 0.1308 24 31 0.4686
MACCS reducedd 0.8794 0.1229 28 31 0.5000
Pubchem Original 0.9163 0.0809 29 32 0.6970
Pubchem Reduced 0.9187 0.0750 29 33 0.7402

Page 11 of 12Kuwahara and Gao J Cheminform (2021) 13:27
expected to be integrated seamlessly to exiting similar-ity-based VS pipelines that use 2D fingerprints as fea-ture vectors.
Our results indicate that the presence of related fin-gerprints in predefined fingerprint dictionaries can pose challenges in objectively ranking the degree of similarity among compounds from different datasets and for different query compounds, making the evalu-ation of structural similarity for not only multiple-mol-ecule queries but also single-molecule queries difficult. As each compound dataset can have different sets of related fingerprints, our results demonstrate the impor-tance of knowing which fingerprints have high degrees of relatedness and how such related features affect the Tanimoto similarity scores. This study also emphasizes
that an increase in the number of structural finger-prints may not always enhance the search performance for similar compounds and that feature selection is a valuable preprocessing step for the task of SAR analysis.
Authors’ contributionsHK designed the study, developed tools, performed analysis, and wrote the paper. XG oversaw the project and wrote the paper. All authors read and approved the final manuscript.
FundingThis work was supported by the King Abdullah University of Science and Technology (KAUST) Office of Sponsored Research (OSR) under Awards No. BAS/1/1624-01, URF/1/3412-01, URF/1/3450-01, FCC/1/1976-18, FCC/1/1976-23, FCC/1/1976-25, FCC/1/1976-26, and FCS/1/4102-02.
Availability of data and materialsThe code and data used in this study have been uploaded to GitHub and are available at https:// github. com/ hkuwa hara/ chem- fp- lambda- entro py.
Declarations
Competing interestsWe declare that we have no competing interests.
Received: 8 May 2020 Accepted: 13 March 2021
References 1. Smith A (2002) Screening for drug discovery: the leading question.
Nature 418:453–459 2. Lyne PD (2002) Structure-based virtual screening: an overview. Drug
Discovery Today 7:1047–1055 3. Willett P (2006) Similarity-based virtual screening using 2D fingerprints.
Drug Discovery Today 11:1046–1053 4. Scior T, Bender A, Tresadern G, Medina-Franco JL, Martínez-Mayorga K
et al (2012) Recognizing pitfalls in virtual screening: a critical review. J Chemical Information Modeling 52:867–881
5. Cereto-Massagué A, Ojeda MJ, Valls C, Mulero M, Garcia-Vallvé S et al (2015) Molecular fingerprint similarity search in virtual screening. Meth-ods 71:58–63
6. Durant JL, Leland BA, Henry DR, Nourse JG (2002) Reoptimization of MDL keys for use in drug discovery. J Chemical Information Computer Sci 42:1273–1280
7. Mellor CL, Marchese Robinson RL, Benigni R, Ebbrell D, Enoch SJ et al (2019) Molecular fingerprint-derived similarity measures for toxicologi-cal read-across: Recommendations for optimal use. Regulatory Toxicol Pharmacol 101:121–134
8. Bender A, Mussa HY, Glen RC, Reiling S (2004) Molecular similarity search-ing using atom environments, information-based feature selection, and a naïve bayesian classifier. J Chemical Information Computer Sci 44:170–178
9. Geppert H, Vogt M, Bajorath J (2010) Current trends in ligand-based virtual screening: molecular representations, data mining methods, new application areas, and performance evaluation. J Chemical Information Modeling 50:205–216
10. Heikamp K, Bajorath J (2011) How do 2D fingerprints detect structur-ally diverse active compounds? Revealing compound subset-specific fingerprint features through systematic selection. J Chemical Information Modeling 51:2254–2265
11. Nisius B, Vogt M, Bajorath J (2009) Development of a fingerprint reduc-tion approach for Bayesian similarity searching based on Kullback-Leibler divergence analysis. J Chemical Information Modeling 49:1347–1358
12. Alter O, Brown PO, Botstein D (2000) Singular value decomposition for genome-wide expression data processing and modeling. Proceedings
92a91a89a87a85a84a82a80a77a71a67a66a65a60a58a57a56a51a48a44a40a36a33a31a29a22a21a15a11a10a
7a5a2a
0.0 0.1 0.2 0.3relative change
mol
ecul
e pa
ir ID
92a91a89a87a85a84a82a80a77a71a67a66a65a60a58a57a56a51a48a44a40a36a33a31a29a22a21a15a11a10a
7a5a2a
0.00 0.05 0.10relative change
a b
Fig. 7 Relative changes of the Tanimoto similarity measure with the fingerprints in the reduced level 0.3 with respect to the one with the original fingerprints. The relative similarity changes are shown for the 33 similar-compound pairs with a high consensus by the 143 experts ( ≥ 80% ). The error bars indicate the 1st and the 3rd quartiles of 10,000 Tanimoto coefficients computed with random pruning of the original fingerprints. These randomly selected fingerprint vectors have the same length as the one for the the reduced level 0.3. a MACCS scheme. b Pubchem scheme

Page 12 of 12Kuwahara and Gao J Cheminform (2021) 13:27
• fast, convenient online submission
•
thorough peer review by experienced researchers in your field
• rapid publication on acceptance
• support for research data, including large and complex data types
•
gold Open Access which fosters wider collaboration and increased citations
maximum visibility for your research: over 100M website views per year •
At BMC, research is always in progress.
Learn more biomedcentral.com/submissions
Ready to submit your researchReady to submit your research ? Choose BMC and benefit from: ? Choose BMC and benefit from:
of the National Academy of Sciences of the United States of America 97:10101–10106
13. Varshavsky R, Gottlieb A, Linial M, Horn D (2006) Novel unsupervised feature filtering of biological data. Bioinformatics (Oxford, England) 22:e507–e513
14. Wishart DS, Feunang YD, Marcu A, Guo AC, Liang K et al (2018) HMDB 4.0: the human metabolome database for 2018. Nucleic Acids Res 46:D608–D617
15. Wishart DS, Feunang YD, Guo AC, Lo EJ, Marcu A et al (2018) Drugbank 5.0: a major update to the drugbank database for 2018. Nucleic Acids Res 46:D1074–D1082
16. Willighagen EL, Mayfield JW, Alvarsson J, Berg A, Carlsson L et al (2017) The chemistry development kit (cdk) v2.0: atom typing, depiction, molecular formulas, and substructure searching. J Cheminformatics 9:33
17. Knox C, Law V, Jewison T, Liu P, Ly S et al (2011) DrugBank 3.0: a com-prehensive resource for ‘omics’ research on drugs. Nucleic Acids Res 39:D1035–D1041
18. Franco P, Porta N, Holliday JD, Willett P (2014) The use of 2d fingerprint methods to support the assessment of structural similarity in orphan drug legislation. J Cheminformatics 6:5
19. Alazmi M, Kuwahara H, Soufan O, Ding L, Gao X (2019) Systematic selec-tion of chemical fingerprint features improves the Gibbs energy predic-tion of biochemical reactions. Bioinformatics 35:2634–2643
Publisher’s NoteSpringer Nature remains neutral with regard to jurisdictional claims in pub-lished maps and institutional affiliations.