analisis survival dengan pendekatan bayesian …
TRANSCRIPT

1
ANALISIS SURVIVAL DENGAN PENDEKATAN BAYESIAN
UNTUK MEMODELKAN KETAHANAN PROGRAM KB
PADA INDIVIDU IBU DI INDONESIA TAHUN 2007
Oleh:
Preatin 1)
, Kresnayana Yahya2)
dan Yos Rusdiansyah3)
1Mahasiswa S2 Jurusan Statistika, FMIPA-ITS, Surabaya
[email protected], [email protected] 2Dosen Jurusan Statistika, FMIPA-ITS, Surabaya
3Badan Pusat Statistik Provinsi Jawa Timur, Surabaya, Indonesia
Abstrak
Saat ini Indonesia dihadapkan dengan masalah “baby boom”
tahap kedua yang mengancam masalah kependudukan. Beberapa
indikator demografi membenarkan perkiraan para ahli tersebut, antara
lain menurunnya keinginan mempunyai keluarga kecil, menurunnya
penggunaan alat kontrasepsi, menurunnya sumber pelayanan Keluarga
Berencana (KB) pemerintah, tingginya laju pertumbuhan penduduk di
beberapa provinsi, dan pergeseran struktur angka kelahiran menurut umur
wanita ke umur yang lebih muda dibeberapa provinsi. Pembatasan jumlah
anggota keluarga dengan program “Dua Anak Cukup” ternyata mulai
ditinggalkan apalagi setelah kebijakan program KB dilimpahkan ke
pemerintah daerah sejalan dengan semangat otonomi daerah. Gagalnya
program tersebut pada seorang ibu dapat dilihat dengan kelahiran anak
ketiga, sehingga jarak kelahiran antara anak kedua dan ketiga dapat
dijadikan obyek penelitian evaluasi program “Dua Anak Cukup”.
Data jarak kelahiran anak kedua dan ketiga mengandung data
tersensor dimana seorang ibu pada saat pendataan belum memiliki anak
ketiga tetapi ada kemungkinan melahirkan anak ketiga setelah periode
pendataan selesai. Untuk menangani data tersensor maka digunakan
analisis survival dimana memperhitungkan kemungkinan terjadinya
kelahiran anak ketiga pada data tersensor. Dalam penelitian ini jarak
kelahiran anak kedua dan ketiga dihubungkan dengan faktor-faktor yang
mempengaruhinya baik dari sisi sosial, ekonomi, fungsi keluarga, dan

2
intervensi pemerintah, sehingga dimodelkan dengan Model Proporsional
Hazard.
Indonesia terdiri dari 33 provinsi dengan karakteristik masing-
masing baik dari sosial ekonomi, budaya, maupun demografi
kewilayahannya yang tidak menutup kemungkinan antar provinsi terdapat
perbedaan dan persamaan. Menangani masalah dengan menyikapi
perbedaan dan persamaan antar provinsi tentu membutuhkan perlakuan
berbeda. Pembentukan cluster pada provinsi-provinsi yang lebih
homogen berdasarkan karakteristik sosial ekonomi, budaya, fungsi
keluarga dan intervensi pemerintah dilakukan untuk memperkecil
variabilitas. Metode clustering yang digunakan adalah Two Step Cluster
Analysis. Pendekatan Bayesian dengan simulasi numerik Markov Chain
Monte Carlo (MCMC) akan mempermudah estimasi parameter dalam
model hazard proporsional.
Hasil yang diperoleh adalah terbentuk 4 cluster dimana umur
ibu pada saat melahirkan anak kedua berpengaruh terhadap jarak
kelahiran anak kedua dan ketiga di semua cluster. Beberapa faktor lain
mempunyai pengaruh yang berbeda pada setiap cluster seperti akses ke
media informasi, agama, dan lain-lain.
Kata kunci : Analisis Survival, Bayesian, Keluarga Berencana (KB),
Markov Chain Monte Carlo ( MCMC), Two Step Cluster
Analysis.
1. Pendahuluan
Tantangan memakmurkan bangsa Indonesia dalam beberapa
tahun mendatang tidak terlepas dari permasalahan ekonomi, kemiskinan,
kesehatan, bahkan politik. Tantangan ini ternyata tidak terlepas dari
kualitas sumber daya manusia (SDM) yang masih terus ditingkatkan.
Kualitas SDM yang rendah sangat dipengaruhi oleh permasalahan
kependudukan. Mulai dari aspek besarnya penduduk, pertumbuhan
penduduk, kelahiran, kematian, dan perpindahan penduduk maupun
kualitas penduduk. Berawal dari tingginya angka kelahiran sehingga
pertumbuhan penduduk meningkat walaupun dibarengi dengan masalah
angka kematian ibu dan bayi yang relatif tinggi, ternyata pertambahan

3
penduduk Indonesia tidak dibarengi oleh peningkatan kualitas penduduk
dan kemampuan negara untuk membiayai penyediaan kebutuhan dasar
seperti infrastruktur pendidikan, perumahan, kesehatan dan lainnya.
Masalah pengangguran, kemiskinan, kriminalitas, putus sekolah,
kematian ibu dan bayi, rasanya tidak terlalu berlebihan jika dikatakan ada
kaitannya dengan besarnya jumlah penduduk.
Rata-rata jumlah anak per wanita usia produktif saat ini 2,6
anak dan ada indikasi terjadi kenaikan pada wanita di pedesaan. Bahkan
ada indikasi bangsa ini dihadapkan adanya baby boom tahap kedua dan
diperkirakan pada tahun 2015 jumlah penduduk Indonesia mencapai
247,5 juta jiwa dan 273 juta jiwa pada tahun 2025 (Kompas, 28 Agustus
2008). Laju pertumbuhan penduduk Indonesia memang mengalami
penurunan setiap tahunnya, tetapi tidak untuk level provinsi. Pada periode
tahun 2000-2005 terdapat 12 provinsi dari 33 provinsi mengalami
kenaikan yang signifikan dibanding periode 1990-2000. Angka kelahiran
di beberapa provinsi juga mengalami pergeseran struktur, dimana angka
kelahiran menurut umur wanita cenderung ke umur yang lebih rendah.
Hal ini akan berdampak lebih panjangnya sisa masa produktif wanita
sehingga peluang naiknya rata-rata jumlah anak per wanita.
Hasil temuan dari Survei Demografi dan Kesehatan Indonesia
2007 (SDKI 2007) menunjukkan bahwa keinginan untuk membatasi
jumlah anak menurun dibanding SDKI 2002-2003. Pada tahun 2002-2003
persentase wanita yang ingin membatasi jumlah anak sebesar 54,2 persen
dan menurun pada tahun 2007 menjadi 53,5 persen. Penggunaan alat
kontrasepsi juga mangalami penurunan kecuali di Jawa Barat, penurunan
paling signifikan terjadi di DI Yogyakarta (9 persen, dari 76 ke 67
persen) dan DKI Jakarta (3 persen, dari 63 ke 60 persen). Dan sumber
pelayanan kontrasepsi dari pemerintah menurun dari 28 persen pada
tahun 2003 menjadi 22 persen pada tahun 2007. Indikasi-indikasi di atas
menunjukkan bahwa masalah kependudukan di masa yang akan datang
tidak lebih ringan dibanding sekarang.
Adanya stratifikasi permasalahan kependudukan pada provinsi-
provinsi di atas menunjukkan bahwa penanganan permasalahan ini tidak
dapat dilakukan secara umum sama di semua provinsi. Karakteristik
wilayah terbentuk sebagai akumulasi keadaan sosial ekonomi, budaya,
dan keadaan demografis. Provinsi yang agraris dengan industri tentu

4
menghasilkan karakteristik berbeda. Kehidupan metropolis dengan
pedesaan menghasilkan gaya hidup masyarakat yang berbeda.Ruang
lingkup penduduk yang terkecil adalah keluarga, lebih tepatnya keluarga
inti. Dari keluarga intilah kunci pengendalian jumlah penduduk. Keluarga
yang memiliki jumlah anak tidak lebih dari yang bisa dipelihara dengan
baik, akan menjamin keluarga tersebut dari permasalahan kesehatan,
pendidikan, ekonomi, kemiskinan dan lainnya.
Jika Thomas Robert Malthus dengan teorinya tentang
ketidakseimbangan antara penduduk dan bahan makanan, ternyata saat ini
merembet tidak hanya pada masalah pangan tetapi jauh lebih besar dari
itu. Beberapa pengikut teori Malthus yang disebut Neo Malthusionism
beranggapan bahwa untuk menghambat jumlah kelahiran tidak mungkin
hanya mengandalkan moral restraint (berpuasa, penundaan perkawinan,
penegakan moral). Sehingga disarankan metode Birth Control dengan
penggunaan alat kontrasepsi yang akhirnya disebut family planning
(BKKBN, 1981).
Di Indonesia pengendalian penduduk dengan metode Birth
Control pada era sebelum tahun 1957 dikenalkan oleh beberapa tokoh
yang terinspirasi oleh pengikut-pengikut Malthus. Beberapa tokoh
bergerak di daerah-daerah dengan banyak tantangan dari masyarakat
bahkan salah satu tokoh besar KB saat itu yaitu dr. Sulianti mendapat
teguran dari Presiden Sukarno yang tidak menyetujui pembatasan
kelahiran. Pada tahun 1957 akhirnya salah satu tokoh yaitu dr. Suharto
dengan beberapa tokoh yang lain membentuk Perkumpulan Keluarga
Berencana Indonesia (PKBI) yang pada tahun 1968 melalui instruksi
presiden dibentuk LKBN (Lembaga Keluarga Berencana Nasional) yang
dimulai dengan Proyek KB DKI Jaya dengan biaya pemerintah. Pada
tahun 1980 pemerintah menganggap KB perlu dilaksanakan sebagai
integral pembangunan nasional dan dibentuklah BKKBN (Badan
Koordinasi Keluarga Berencana Nasional).
Pembatasan jumlah anak dalam kebijakan family planning
banyak diterapkan di beberapa negara seperti Cina dan Singapura.
Intervensi pemerintah terhadap jumlah anak dalam keluarga dirasakan
masih diperlukan untuk negara berkembang seperti Indonesia. Program
“Dua Anak Cukup” yang diluncurkan BKKBN adalah salah satu bentuk
intervensi untuk pembatasan jumlah anak (limiting family size). Dalam

5
paparan Prof. Dr. Haryono Suyono tentang Strategi Penyegaran Gerakan
KB di masa depan menyebutkan bahwa peserta KB dapat dijadikan
pelopor dalam upaya penyelesaian masalah pengentasan kemiskinan dan
memenuhi komitmen dunia dalam Millennium Development Goals.
Pendekatan yang selama ini dikembangkan yaitu pelayanan KB bagi
keluarga miskin, sebaiknya diperluas sehingga terkesan KB bukan hanya
untuk orang miskin saja. Slogan “Dua Anak Cukup” memberi dampak
kesempatan keluarga mengembangkan aktivitas meningkatkan
kesejahteraan akan lebih mudah dibanding anak banyak (Gemari edisi
86/Tahun IX/Maret 2008).
Untuk melihat keberhasilan intervensi pembatasan jumlah anak
melalui slogan “Dua Anak Cukup” di Indonesia tentu tidak dapat dilihat
secara global karena antar individu memiliki karakteristik yang beragam.
Dari sisi sebaliknya, bagaimana tingkat kegagalan program tersebut dapat
dilihat dari individu ibu yang memutuskan untuk memiliki anak lebih dari
dua. Kegagalan program “Dua Anak Cukup” pada seorang ibu terjadi
pada saat lahir anak ketiga. Secepat apa seorang ibu gagal bertahan di
program “Dua Anak Cukup” dapat dilihat dari jarak kelahiran anak kedua
dan ketiga. Dan ternyata, jarak kelahiran adalah salah satu faktor yang
paling dominan dalam menentukan angka kelahiran selain pemakaian
kontrasepsi, terutama untuk daerah yang didominasi pedesaan (Polo,
Luna, and Fuster, 2000).
Mahmood (2009) melakukan penelitian tentang jarak kelahiran
di Bangladesh dengan menggunakan Multivariate Proportional Hazards
Model, menyimpulkan faktor yang mempengaruhi jarak kelahiran adalah
pendidikan ibu dan umur ibu. Polo et.al. (2000) menyebutkan hasil
penelitiannya di Alpujarra Spanyol bahwa faktor yang mempengaruhi
jarak kelahiran adalah umur ibu, jumlah anak, dan umur perkawinan
pertama. Al-Almaie (2003) meneliti pola dan faktor yang berhubungan
dengan jarak kelahiran di Arab Saudi bagian timur, menemukan adanya
hubungan antara jarak kelahiran dengan umur ibu, pendidikan ibu, jumlah
anggota keluarga, dan lamanya menyusui anak sebelumnya. Stephen dan
Candra (2003) menghasilkan empat faktor yang mempengaruhi jarak
kelahiran pada wanita di Amerika Serikat yaitu umur ibu pada saat
melahirkan anak sebelumnya, tingkat pendidikan ibu, pendapatan dan
suku. Laporan Reev Consult International hasil penelitian kualitatif

6
tentang jarak kelahiran di Uganda tahun 2008 menyebutkan faktor yang
mempengaruhi jarak kelahiran adalah umur perkawinan pertama, akses
ke media informasi, akses ke KB, agama, dan tipe tempat tinggal.
Sedangkan hasil temuan tim SDKI 2007, ada asosiasi antara
jumlah anak dengan pendidikan ibu, pendidikan bapak, kontrasepsi, dan
umur melahirkan pertama. Namun masih banyak lagi variabel lain yang
mungkin mempengaruhi jarak kelahiran antara lain status bekerja ibu,
status bekerja suami, jabatan dalam pekerjaan suami, jumlah perkawinan,
umur suami, pendidikan suami, kemampuan baca tulis, pendapat suami
tentang KB, penentu keputusan ikut KB, serta keaktifan petugas KB.
Tingkat pendidikan yang berbeda, jenis pekerjaan, lingkungan,
dukungan keluarga dan pemerintah dalam menciptakan kondisi yang
kondusif untuk pelaksanaan program-program KB membentuk suatu
struktur sosial yang dapat menjadikan kunci keberhasilan pelaksanaan
program “Dua Anak Cukup”.
Dalam penelitian jarak kelahiran akan dihadapkan pada masalah
adanya data yang tidak teramati karena terbatasnya waktu penelitian
sehingga terdapat data yang tidak lengkap atau data tersensor. Metode
analisis statistik pada umumnya akan menghasilkan interpretasi yang bias
jika terdapat data yang tidak lengkap atau tersensor (Hobcraft et.al,
1984). Analisis survival merupakan alat statistik yang tujuan utamanya
adalah menganalisis data yang selalu positif dalam skala pengukuran
dengan jarak interval data awal dan akhir yang panjang (longevity data)
((Hobcraft et.al, 1984),(Ducrocq, 1997)). Data dengan karakteristik tidak
lengkap atau tersensor dan masih fokus pada estimasi parameter populasi
dan prediksi sampel dimasa datang merupakan life data, sehingga analisis
yang digunakan adalah life data analysis (Nelson, 1982).
Metode analisis survival yang menghubungkan antara waktu
survival dengan variabel lain adalah model hazard proporsional dimana
formulanya memungkinkan untuk interpretasi pengaruh dari masing-
masing variabel bebasnya lebih mudah dan perbandingan secara statistik
dapat dilakukan dalam bentuk relative risk ((Hobcraft et.al, 1984),
(Kleinbaum, 2005), (Kneib dan Fahrmeir, 2004)).
Kneib dan Fahrmeir (2004) membandingkan antara pendekatan
maksimum likelihood dan Bayesian dalam estimasi parameter dalam
model hazard dengan beberapa variasi jumlah data yang tersensor dan

7
hasilnya tidak jauh berbeda dari sisi akurasi estimasi, namun dari sisi
rata-rata probabilitas cakupannya pendekatan bayesian lebih baik
dibanding maksimum likelihood terutama untuk data tersensor yang
tinggi. Keuntungan lain pendekatan bayesian adalah inferensi dari
parameter yang tidak diketahui langsung dari distribusi posteriornya dan
mengakomodasi informasi penelitian sebelumnya dalam bentuk prior
(Mengersen, 2009).
2. Tinjauan Puataka
2.1. Two Step Cluster
Terdapat dua kelompok besar dalam metode clustering,yaitu
relocation dan hierarchical. Untuk metode pengelompokan relocation
seperti k-means dan Expectation-Maximization (EM), obyek dipindah
secara iteratif dari kelompok satu ke kelompok yang lain sehingga
menghasilkan kelompok-kelompok yang homogen. Pada metode ini
dibutuhkan penentuan jumlah kelompok terlebih dahulu, yang tentunya
memerlukan banyak pertimbangan. Pada metode pengelompokan
hierarchical, jumlah kelompok tidak ditentukan terlebih dahulu karena
prosedurnya akan menghasilkan rangkaian pengelompokan dimana
masing-masing obyek dapat dilihat kedekatannya terhadap kelompok
tertenttu. Namun, dari semua metode pengelompokan akan memerlukan
ukuran jarak, yang masing-masing ukuran memiliki kelebihan dan
kekurangan. Jarak Euclidean contohnya hanya bisa digunakan untuk
variabel kontinu dan ukuran simple matching dissimilarity hanya untuk
variabel kategorik.
Metode two Step cluster adalah metode mengelompokkan
obyek dengan jumlah data yang relatif besar dan dengan tipe data
gabungan antara variabel kontinu dan kategorik. Prosedur pada two step
cluster adalah :
1. Pre-cluster, pada tahap ini obyek dibaca satu per satu dan
ditentukan apakah obyek tersebut masih digabung dengan
kelompok sebelumnya atau digabung dengan kelompok yang

8
baru berdasarkan kriteria jarak. Prosedur ini dijalankan dengan
membangun pohon cluster feature(CF).
2. Pengelompokan data ke sub kelompok. Pada tahap ini
menggunakan metode agglomerative hierarchical clustering
yang akan menghasilkan jumlah kelompok optimal dengan
menggunakan BIC atau AIC.
Ukuran jarak yang digunakan adalah jarak log-likelihood,
karena merupakan jarak berdasarkan probabilita yang dapat
menggabungkan antara variabel kontinu dan kategorik. Jarak antara dua
kelompok adalah penurunan pada log-likelihood dibandingkan jika dua
kelompok tersebut digabung dalam satu kelompok. Jika data hanya terdiri
dari variabel kontinu dapat menggunakan jarak Euclidean.
2.1.1. Pohon Clustering Feature (CF)
Clustering Feature adalah ringkasan informasi yang
menggambarkan suatu kelompok. Jika diberikan N data dalam sebuah
kelompok berdimensi-d; {���}, dimana j = 1,2,..., N. Clustering Feature
(CF) vector didefinikan sebagai : CF = {N,M,V,K}, dimana N adalah
banyaknya data, M adalah rata-rata masing-masing variabel kontinu dari
N data, V adalah varian masing-masing variabel kontinu dari N data dan
K adalah jumlah dari masing-masing kategori untuk masing-masing
variabel kategorik.
Pohon CF adalah suatu pohon keseimbangan yang memiliki dua
parameter yaitu Branching Factor (B) dan Threshold (T). Pohon CF
terdiri atas beberapa level of nodes dan pada masing-masing node terdiri
dari beberapa entries.
CF 1 CF 2 ............ CF B
CF 11 CF 12 ............ CF 1B
CF 111, CF 112, ...., CF 11N11
CF B1 CF B2 ............ CF BB

9
Gambar 2.1. Pohon Clustering Feature
Hasil pengelompokan dengan pohon CF di atas adalah sub-cluster dengan
CF tertentu yang terletak pada sebuah entry pada sebuah node di level
terbawah. Ukuran pohon yang terbentuk bergantung dari parameter
threshold (T), semakin besar T maka semakin kecil pohon yang terbentuk.
2.1.2. Jarak Log-Likelihood Jarak log-likelihood adalah ukuran jarak berdasarkan
probabilita. Untuk menghitung log-likelihood diasumsikan distribusi
normal untuk variabel kontinu dan distribusi multinomial untuk variabel
kategorik dan saling bebas antar variabel. Pada beberapa percobaan
secara empiris, prosedur umum two step clustering dengan menggunakan
jarak log-likelihood cukup robust terhadap pelanggaran asumsi
independence dan distributional.
Jarak antara kelompok j dan s didefinisikan sebagai : ���, � = �� + � − ���, �
�� = −�� �� 12��
��� ��� !"�# + !"��# $ + � %&���'
��� (
%&�� = − � ���)��*+
)�� ��� ���)��
Dimana : �� adalah log-likelihood kelompok ke-j � adalah log-likelihood kelompok ke-s ���, � adalah log-likelihood kelompok gabungan antara kelompok ke-j
dan ke-s
KA adalah jumlah variabel kontinu
KB adalah jumlah variabel kategorik !"�# adalah varian variabel kontinu ke-k !"��# adalah varian variabel kontinu ke-k pada kelompok ke-v

10
%&�� adalah log-likelihood variabel kategorik ke-k pada kelompok ke-v �� adalah jumlah data pada kelompok ke-v ���) adalah jumlah data pada kelompok ke-v untuk variabel kategorik ke-
k dengan kategori ke-l
2.1.3. Auto Cluster
Dalam analisis two step cluster akan menghasilkan jumlah
kelompok yang optimal dengan metode hierarchical clustering. Prosedur
pemilihan jumlah kelompok dilakukan dalam dua tahap yaitu menghitung
BIC masing-masing jumlah kelompok untuk menentukan estimasi awal
terhadap jumlah kelompok optimal, kemudian estimasi awal yang didapat
berdasarkan nilai BIC terendah dibandingkan dengan peningkatan jarak
antar dua kelompok terdekat.
,-.�/ = −2 � ��0
��� + 1� �����
1� = / 2234 + ��5� − 1�'
��� 6
Dimana :
J adalah jumlah kelompok �� adalah log-likelihood kelompok ke-j
N adalah jumlah data
KA adalah jumlah variabel kontinu
KB adalah jumlah variabel kategorik
Lk a dalah jumlah kategori pada variabel kategorik ke-k
2.2. MANOVA Jika sampel acak diambil dari tiga atau lebih populasi, dan akan
dilihat kesamaan rata—ratanya, maka akan dibandingkan sebagaimana
pada Analysis of Variansce (ANOVA). Uji kesamaan vektor rata-rata
untuk tiga atau lebih populasi atau kelompok dimana antar variabel dalam
vektor tersebut saling berkorelasi maka menggunakan Multivariate
Analysis of Variance (MANOVA). Asumsi tentang struktur data pada
MANOVA adalah :

11
1. Observasi dari populasi yang berbeda salinng bebas.
2. Semua populasi memiliki matrik kovarian ∑.
3. Masing-masing populasi adalah multivariate normal.
Asumsi ketiga dapat lebih fleksibel dengan pendekatan Teori Limit Pusat
ketika ukuran sampel masing-masing populasi besar.
Misalkan sampel acak berukuran nl dari popolasi ke-l, dimana l
=1,2,....,g. Maka struktur data seperti berikut : 7�� 7�# ⋯ 7�9:7#� 7## ⋯ 7#9;⋮7=�
⋮7=# ⋱… ⋮7=9@
Satu observasi yang diwakili oleh sebuah vektor dari data di atas dapat
didekomposisi sesuai model MANOVA sebagai berikut : 7)� = A + B) + C)� , j = 1,2,..., nl dan l = 1,2,...,,g.
Dimana C)� adalah independent dan berdistribusi �D�0, ∑. Vektor µ
adalah rata-rata total, dan τl merepresentasikan efek dari perlakuan ke-l
dimana ∑ nι=)�� τι = 0. Hipotesis untuk persamaan vektor rata-rata antar
populasi adalah : HI: B� = B# = ⋯ = B=
Sehingga dapat dihitung tabel MANOVA sebagai berikut :
Source or
variation
Matrix of sum of squares and cross
products (SSP)
Degrees of
freedom (d.f.)
Treatment K = � L)=)�� 7) − 7$ 7) − 7$
g-1
Residual
(Error) M = � � 7)� − 7)$ 7)� − 7)$ 9N
���=)�� � LO
=)��
− �
Total K + M = � � 7)� − 7$ 7)� − 7$ 9N���
=)�� � LO
=)��
− 1
Salah satu pendekatan untuk tes hipotesis di atas adalah menggunakan
statistik Wilks’ lambda (Λ*).

12
Λ∗ = |R||, + R| = S∑ ∑ 7)� − 7)$ 7)� − 7)$′9N���=)�� SS∑ ∑ 7)� − 7$ 7)� − 7$′9N���=)�� S
H0 ditolak atau ada sedikitnya sepasang vektor rata-rata yang sama jika
nilai Λ* sangat kecil atau ekuivalen dengan F-test pada kasus univariat.
2.3. Analisis Survival Analisis survival adalah analisis mengenai data yang diperoleh
dari catatan waktu yang dicapai suatu obyek sampai terjadinya peristiwa
tertentu yang disebut sebagai failure event. Menurut Cox dan Oakes
(1984) dalam menentukan waktu survival, T, terdapat tiga elemen yang
harus diperhatikan yaitu :
1. Waktu awal (time origin)
2. Definisi failure time keseluruhan harus jelas
3. Skala waktu sebagai satuan pengukuran harus jelas.
Perbedaan antara analisis survival dengan analisis statistik
lainnya adalah adanya data tersensor. Menurut Miiler (1998) data
dikatakan tersensor jika pengamatan waktu survival hanya sebagian, tidak
sampai failure event. Penyebab terjadinya data tersensor antara lain :
1. Loss to follow up terjadi bila obyek pindah, meninggal atau menolak
untuk berpartisipasi.
2. Drop Out terjadi bila perlakuan dihentikan karena alasan tertentu.
3. Termination of study terjadi bila masa penelitian berakhir sementara
obyek yang diobservasi belum mencapai failure event.
Jika T melambangkan waktu survival dan mempunyai distribusi
peluang f(t), maka fungsi distribusi kumulatif dinyatakan sebagai berikut :
T�U = V�W ≤ U = Y Z�[\I �[ �2.1
Jika fungsi survival, S(t), didefinisikan sebagai probabilita suatu obyek
bertahan setelah waktu ke-t, maka : ^�U = V�W > U = 1 − V�W ≤ U = 1 − T�U �2.2
Fungsi hazard merupakan laju failure atau kegagalan sesaat dengan
asumsi obyek telah bertahan sampai waktu ke-t, yang didef inisikan
sebagai berikut :

13
ℎ�U = lim∆\eI fV�U ≤ W < U + ∆U|W > U∆U h Dari definisi di atas, dapat diperoleh hubungan antara fungsi survival dan
fungsi hazard. Berdasarkan teori probabilitas bersyarat, bahwa :
V�i|, = V�i,V�, Maka dapat ditentukan hubungan sebagai berikut :
jV�U ≤ W < U + ∆UV�W > U k = fT�U + ∆U − T�U^�U h Sehingga :
ℎ�U = lim∆\eI fT�U + ∆U − T�U∆U h 1^�U Dengan
T′�\ = lim∆\eI fT�U + ∆U − T�U∆U h = Z�U Karena f(t) adalah derivatif dari F(t), maka hubungan antara fungsi
survival dan fungsi hazard sebagai berikut :
ℎ�U = Z�U^�U �2.3
Diketahui, F(t) = 1- S(t), dapat dituliskan sebagai m Z�U�U =1 − ^�U. Jika keduanya diturunkan terhadap t maka diperoleh:
Z�U = ��1 − ^�U�U Sehingga nilai h(t) menjadi :
ℎ�U = j��1 − ^�U�U k^�U = n− ��U ^�Uo^�U −ℎ�U�U = ��^�U^�U
Dengan mengintegralkan maka diperoleh :
− Y ℎ�U�U = Y 1^�U\I � ^�U$ \
I

14
− Y ℎ�U�U = p�L ^�U|I\ = ln ^�U − ln ^�0 = ln ^�U \I
Dimana fungsi kumulatif hazard, H�U = m ℎ�U�U ,\I maka hubungan
antara fungsi kumulatif hazard, H(t), dan fungsi survival adalah : H�U = −�L ^�U �2.4
2.4. Model Hazard Proporsional Jika resiko failure pada waktu tertentu bergantung pada nilai x1,
x2, x3, ...., xp dari p variabel prediktor, X1, X2, X3, ...., Xp, maka nilai
variabel tersebut diasumsikan telah tercatat sebagai time origin. Misalkan
h0(t) sebagai fungsi hazard untuk setiap obyek dengan nilai dari semua
variabel prediktor X adalah nol, maka fungsi h0(t) dikatakan sebagai
fungsi baseline hazard (Collet,1994). Model hazard proporsional atau
lebih dikenal dengan regresi cox adalah sebagai berikut : ℎ�U = ℎI�U exp�u��� + u#�# + uv�v + ⋯ + uD�D �2.5
2.5. Odds Ratio Odds ratio merupakan suatu ukuran yang digunakan untuk
mengetahui tingkat resiko (kecenderungan) yaitu perbandingan antara
Odd individu dengan kondisi variabel prediktor X pada kategori sukses
dengan kategori gagal (Hosmer dan Lemeshow, 2000). Nilai estimasi dari
Odds Ratio diperoleh dengan mengeksponensialkan koefisien regresi cox
masing-masing variabel prediktor yang signifikan berhubungan dengan
hazard rate-nya.
Misal X adalah variabel prediktor dengan dua kategori yaitu 0
dan 1. Hubungan antara variabel X dan h(t) dinyatakan dengan h(tΙx) =
h0(t) eβx
maka :
- Individu dengan x=1, fungsi hazardnya :
h(tΙx=1) = h0(t) eβ.1
= h0(t) eβ
- Individu dengan x=0, fungsi hazardnya :
h(tΙx=1) = h0(t) eβ.0
= h0(t)
- Odds Ratio untuk individu dengan x=1 dibanding x=0 adalah :
xy = ℎ�pU|� = 1ℎ�pU|� = 0 = ℎI�Uz{ℎI�U = z{

15
Sehingga diperoleh nilai OR yang artinya bahwa tingkat kecepatan
terjadinya failure event pada individu dengan kategori x=1 adalah sebesar z{ kali tingkat kecepatan terjadinya resiko terjadinya peristiwa failure
event pada individu dengan kategori x=0.
Pada variabel kontinyu, nilai dari z{ mempunyai interpretasi
perbandingan odds ratio antara individu dengan nilai X lebih besar 1
satuan dibanding individu lain.
2.6. Pendekatan Bayesian pada Estimasi Parameter
Dalam teori estimasi, dikenal dua pendekatan yaitu pendekatan
statistika klasik dan pendekatan statistika Bayesian. Statistika klasik
sepenuhnya mengandalkan proses inferensia pada data sampel yang
diambil dari populasi. Sedangkan statistika Bayesian, disamping
memanfaatkan data sampel yang diperoleh dari populasi juga
memperhitungkan suatu distribusi awal yang disebut prior. Inferensi
statistik dengan pendekatan statistika Bayesian berbeda dengan
pendekatan statistika klasik. Pendekatan statistika klasik memandang
parameter θ sebagai parameter bernilai tetap. Sedangkan pendekatan
statistika Bayesian memandang parameter θ sebagai variabel random
yang memiliki distribusi, disebut distribusi prior. Dari distribusi prior
selanjutnya dapat ditentukan distribusi posterior sehingga diperoleh
estimator Bayesian yang merupakan mean atau modus dari distribusi
posterior.
Informasi yang diketahui tentang parameter θ sebelum
pengamatan dilakukan disebut sebagai prior θ atau p(θ ). Selanjutnya
untuk menentukan distribusi posterior θ , yaitu p( xθ ) didasarkan pada
aturan probabilitas dalam teorema bayes sebagai berikut:
( ) ( )( )
( )=
f x pp x
f x
θ θθ (2.6)

16
dimana
Z�� = %�Z��|| = }m Z��||Z�|�| �~�� | ��LU~L�[∑ Z��||��| �~�� | �~���~U p f (x) adalah suatu konstanta yang disebut sebagai normalized constant
(Gelman et.al, 1995), selanjutnya persamaan (2.6) dapat ditulis menjadi:
( ) ( ) ( )∝p x f x pθ θ θ (2.7)
Persamaan (2.7) menunjukkan bahwa posterior adalah proporsional
terhadap likelihood dikalikan dengan prior dari parameter model.
Penyelesaian masalah melalui pendekatan bayesian mempunyai
kelebihan dari pendekatan klasik, karena pendekatan ini
mengintegrasikan kondisi priornya ke dalam perhitungan selanjutnya
(Niggli, dan Musi, 2005). Keuntungan menggunakan metode Bayesian
dibandingkan statistik secara konvensional adalah:
• Menggunakan informasi kondisi prior dalam proses pengelolaan
atau inferensia data.
• Pendekatan Bayesian menggunakan prinsip distribusi
probabilitas langsung pada parameternya (parameter
diberlakukan sebagai variabel). Hal ini memberikan
kepercayaan yang lebih dibanding cara statistic klasik pada
umumnya.
• Teori Bayesian merupakan alat bantu estimasi model yang
dapat digunakan untuk menyelesaikan berbagai persoalan untuk
berbagai situasi.
• Statistik Bayesian merupakan cara yang sederhana untuk
mempelajari parameter yang bermasalah dalam model.
• Teori Bayesian memberikan cara untuk mendapatkan distribusi
prediksi untuk masa mendatang. Hal ini tidak selalu mudah
dikerjakan dengan cara statistik klasik pada umumnya.
2.6.1. Distribusi Prior
Berdasarkan teorema bayes, informasi awal yang digunakan
sebagai distribusi prior dan informasi sampel yang dinyatakan dengan
fungsi likelihood dikombinasikan untuk membentuk distribusi posterior.

17
Box dan Tiao (1973) menyatakan ada beberapa tipe distribusi prior yang
dikenal dalam metode Bayesian:
1. Conjugate prior VS non conjugate prior ((Box dan Tiao, 1973),
(Gelman et.al,1995), (Tanner, 1996), (Zellner, 1971)). Adalah prior
yang terkait dengan pola model likelihood dari data.
2. Proper prior VS Improper prior (Jeffreys prior). Yaitu prior yang
terkait dengan pemberian bobot/ densitas di setiap titik apakah
terdistribusi secara uniform atau tidak.
3. Informative prior VS Non-Informative Prior, yaitu prior yang
terkait dengan diketahui atau belum diketahuinya pola/ frekuensi
distribusi dari data.
4. Pseudo Prior (Carlin dan Chib, 1995) menjabarkan prior yang
terkait dengan pemberian nilai yang disetarakan dengan hasil
elaborasi dari pendapat kaum frequentist.
2.6.2. Markov Chain Monte Carlo (MCMC) Metode Markov Chain Monte Carlo (MCMC) memudahkan
permodelan yang cukup kompleks sehingga dianggap sebagai suatu
tembusan dalam penggunaan analisis bayesian (Carlin dan Chib, 1995).
Ada beberapa teknik yang tersedia untuk integrasi numerik, dan sebagian
besar metode yang ada sangat berhubungan dengan ide yang ada pada
integral Monte Carlo yaitu sebuah teknik integrasi yang dapat dilakukan
untuk memperoleh sebuah nilai harapan (expectation). Dalam bentuk
yang sederhana dapat dituliskan : m Z������� ≅ :� ∑ ���� ���:�� (2.8)
dimana nilai x1, x2, ..... ,xn dapat diperoleh secara bebas pada kepadatan
p(x) dalam interval (a,b) dalam bentuk yang paling sederhana dapat
menggunakan distribusi uniform (a,b).
Pada analisis Bayesian, penggunaan MCMC dapat
mempermudah analisisnya, sehingga keputusan yang diambil dari hasil
analisis akan dapat dilakukan dengan cepat dan tepat. Ada dua
kemudahan yang diperoleh dari penggunaan metode MCMC pada analisis
bayesian (Iriawan, 2000). Pertama, metode MCMC dapat
menyederhanakan bentuk integral yang komplek dengan dimensi besar
menjadi bentuk integral yang sederhana dengan satu dimensi. Kedua,

18
dengan menggunakan metode MCMC, estimasi densitas data dapat
diketahui dengan cara membangkitkan suatu rantai markov yang
berurutan sebanyak N.
2.6.3. Gibbs Sampling
Salah satu pendekatan MCMC adalah dengan metode Gibbs
Samping (Gelfand dan Smith, 1990). Gibbs Samping merupakan teknik
untuk membangkitkan variabel acak dari distribusi marginal secara tidak
langsung tanpa harus menghitung densitasnya. Dengan menggunakan
Gibbs sampling penghitungan yang sulit dapat dihindari (Casella dan
George, 1992).
Penggunaan Gibbs Sampling pada suatu analisis data ditujukan
untuk mendapatkan data tiap parameter, θk secara individual dari bentuk
distribusi full conditional semua parameter terhadap data, V�|�||��, �,
dimana |�� = �|�, |#, . . . , |���, |���, . . . , |�. Dengan demikian untuk
mendapatkan sampel dari tiap parameter dilakukan dengan membentuk
semua parameter model menjadi sebuah vektor parameter dalam bentuk
partisi yang khusus yaitu : | = �|�, |��.
3. Metode Penelitian
3.1. Metode Penelitian
Untuk dapat mencapai tujuan dari penelitian maka disusun
langkah–langkah penelitian sebagai berikut:
1. Eksplorasi data untuk menentukan variabel prediktor yang masuk
dalam model.
2. Pengelompokkan individu ibu berdasarkan variabel-variabel yang
diduga masuk ke model dengan two step cluster analysis.
3. Identifikasi individu ibu dalam kelompok yang terbentuk menurut
provinsi tempat tinggal.
4. Pengelompokan ulang berdasarkan provinsi.
5. Mengeksplorasi data X dan Y masing-masing kelompok,
menentukan distribusi data Y sebagai dasar pembentukan model
dan deskriptif data X untuk melihat karakteristik individu ibu pada
masing-masing kelompok.

19
6. Menentukan model terbaik dengan software SPSS untuk masing-
masing kelompok.
7. Memeriksa asumsi proportional hazard untuk setiap variabel
prediktor yang signifikan dalam model. Asumsi ini dapat terpenuhi
dengan melihat pola plot antara loge{-loge ( )tS } terhadap t untuk
tiap variabel penjelas. Jika garis antar kategori sejajar maka asumsi
dapat dikatakan terpenuhi.
8. Penentuan distribusi prior untuk setiap parameter dari model.
9. Estimasi parameter fungsi hazard proporsional dibantu software
WinBUGS dan melakukan uji parsial terhadap estimasi yang
diperoleh.
10. Analisa model masing-masing kelompok.
3.2. Variabel yang digunakan dalam penelitian
Variabel dependent (Y) adalah jarak kelahiran anak kedua dan
ketiga dalam bulan, sedangkan variabel dependent (X) yang digunakan
seperti pada Tabel 1.
Tabel 1. Variabel Dependent (X) yang Digunakan dalam Model
Construct Variabel Keterangan
Sosial
X1 Kemampuan Baca Tulis 0= Tidak Bisa Baca Tulis
1= Bisa Baca Tulis
X2 Akses ke Media Informasi 0= Tidak Aktif
1= Aktif Mengakses Media
X3 Umur Ibu Dalam tahun
X4 Umur Suami Dalam tahun
X5 Lama Sekolah Ibu Dalam tahun
X6 Lama Sekolah Suami Dalam tahun
X7 Umur Perkawinan Pertama Dalam tahun
X8 Jumlah Perkawinan 1= Sekali 2= Lebih dr sekali
X9 Anak Yang Diinginkan 1= Diinginkan
2= Diinginkan Nanti
3= Tidak Diinginkan
X10 Lama Menyusui Anak Kedua Dalam bulan
X11 Penggunaan Alat KB 0= Tidak pernah

20
1= Hanya Metode Tradisional
2= Hanya Metode Modern
X12 Agama 1= Islam
2= Protestan
3= Katolik
4= Hindu
5= Budha
6= Konghucu
7= Lainnya
Ekonomi X13 Status Bekerja 0= Tidak Bekerja 1= Bekerja
X14 Status Bekerja Suami 0= Tidak Bekerja 1= Bekerja
X15 Jabatan dalam Pekerjaan
Suami
1= Profesional, kepemimpinan,
dan ketatausahaan
2= Perdagangan dan Jasa
3= Pertanian
4= Lainnya
Fungsi
Keluarga
X16 Pendapat Suami tentang KB 1= Setuju 2= Tidak Setuju
X17 Keputusan ikut KB 1= Sendiri
2= Suami
3= Bersama
4= Lainnya
Intervensi
Pemerintah
X18 Akses ke Alat Kontrasepsi 0= Tidak Tahu 1= Tahu
X19 Keaktifan Petugas KB dalam 6
bulan terakhir
0= Tidak Aktif 1= Aktif
Latar
Belakang
X20 Kota /Desa 1= Perkotaan 2= Pedesaan
X21 Provinsi 33 Provinsi
4. Hasil dan Pembahasan
4.1. Pengelompokan Provinsi Data Sampel SDKI digunakan untuk estimasi pada tingkat
provinsi, sehingga untuk perencanaan maupun evaluasi kebijakan
hanya bisa dilakukan pada kebijakan tingkat provinsi. Kebijakan
pembatasan jumlah anggota keluarga merupakan suatu intervensi
terhadap perilaku individu dimana individu-individu tersebut
memiliki latar belakang sosial ekonomi dan budaya yang berbeda.
Indonesia dengan 33 provinsi yang memiliki tingkat ekonomi,
keadaan sosial, budaya, dan lingkungan yang berbeda tentu akan
menghasilkan perilaku yang berbeda terhadap masyarakatnya. Untuk
melihat pola keberhasilan intervensi “Dua Anak Cukup” di Indonesia
diperlukan pengelompokan provinsi sehingga model yang didapat
lebih menggambarkan perilaku ibu tentang keputusan memiliki anak

21
ketiga dalam kelompok yang lebih homogen. Kayri (2007) setelah
membagi suatu set data yanng heterogen dalam subpopulasi atau
kelompok yang homogen, hasil analisis statistik akan lebih robust
dan unbiased.
Pengelompokan individu berdasarkan variabel-variabel yang
sebagai karakteristik individu dengan skala pengukuran kontinu dan
diskrit dapat dilakukan dengan analisis Two Step Clustering.
Pengelompokan dilakukan berdasarkan kemiripan atau kedekatan
karakteristik dari individu, menghasilkan pengelompokan provinsi
sebagai berikut :
Tabel 2. Hasil Pengelompokan Provinsi Berdasarkan Data SDKI-2007
Kelompok Provinsi
(1) (2)
1 DI Aceh, Sumatera Utara, Sumatera Barat, Jambi, Sumatera Selatan,
Bengkulu, Lampung, Bangka Belitung, Kep. Riau, DKI Jakarta,
Sulawesi Selatan, Sulawesi Tenggara, Maluku, Maluku Utara, Papua,
dan Papua Barat.
2 Banten, Bali, Nusa Tenggara Barat, Kalimantan Selatan, Kalimantan
Timur, Sulawesi Utara, Sulawesi Tengah, Gorontalo, Sulawesi Barat
3 Riau, Jawa Timur, Jawa Barat, Kalimantan Barat
4 Jawa Tengah, DI Yogayakarta, Nusa Tenggara Timur, Kalimantan
Tengah
Sumber : SDKI-2007 (hasil pengolahan)
Masing-masing kelompok provinsi di atas memiliki karakteristik ibu
yang lebih homogen sehingga diharapkan model yang didapatkan nanti
lebih tepat menjelaskan keadaan individu ibu pada masing-masing
kelompok. Pola karakterisrik dari keempat kelompok yang terbentuk di
atas adalah sebagai berikut :
Tabel 3. Perbandingan Karakteristik Kelompok Berdasarkan Data SDKI-2007
Kelompok Karakteristik (1) (2)
1 Pendidikan ibu rendah, umur ibu muda, usia perkawinan pertama
termuda, petugas KB paling aktif, mayoritas menginginkan anak ke-3

22
2 Pendidikan ibu paling tinggi, akses ke media dan alokon tinggi,
partisipasi kerja rendah, suami bekerja di luar pertanian, suami setuju
KB, menginginkan anak ke-3 terendah
3 Pendidikan ibu paling rendah, akses ke media dan alokon paling
rendah, partisipasi kerja rendah, suami bekerja di sektor pertanian,
persentase suami setuju KB terendah, menginginkan anak ke-3 rendah
4 Pendidikan ibu tinggi,umur ibu tua, usia perkawinan pertama tertinggi,
akses ke media rendah, persentase wanita tidak menginginkan anak ke-
3 tertinggi
Sumber : SDKI-2007 (hasil pengolahan)
4.2. Uji Beda Vektor Rata-rata Hasil analisis two-step clustering terdapat 4 kelompok provinsi
dengan karakteristik berbeda-beda. Dari 20 variabel yang digunakan
dalam pengelompokan terdapat 6 variabel kontinyu yang dapat dilakukan
uji beda vektor rata-rata antar keempat kelompok di atas, sehingga dapat
dilakukan inferensia dari pola pengelompokan di atas. Keenam variabel
kontinyu adalah X3 : Umur Ibu saat Melahirkan Anak Kedua, X4 : Umur
Suami, X5 : Lama Sekolah Ibu, X6 : Lama Sekolah Suami, X7 : Umur
Perkawinan Pertama dan X10 : Lama Menyusui Anak Kedua.
Hipotesis untuk persamaan vektor rata-rata antar kelompok adalah : HI: B� = B# = Bv = B� H�: �~L~1�� �[� �z�U�� ��U� − ��U� �z��z��
Dimana B� = �B�v� B��� B��� B��� B��� B��I�′ , i=1,2,3,4 adalah
vektor rata-rata yang terdiri dari rata-rata variabel X3, X4, X5, X6, X7, dan
X10. Pada Tabel 4.6 berdasarkan keempat kriteria tes multivariate, H0
ditolak yang artinya minimal dua vektor rata-rata dari empat vektor rata-
rata untuk empat kelompok berbeda secara signifikan.
Tabel 4. Tabel MANOVA untuk Multivariate Test Criteria
Statistic Value F Value Num DF Den DF Pr > F
Wilks' Lambda 0.92106304 12.29 18 7501.5 <.0001
Pillai's Trace 0.08020163 12.15 18 7962 <.0001
Hotelling-Lawley Trace 0.08433127 12.42 18 5298 <.0001
Roy's Greatest Root 0.06328477 27.99 6 2654 <.0001
23
S=3 M=1 N=1325
NOTE: F Statistic for Roy's Greatest Root is an upper bound
Sumber : SDKI-07 (hasil penngolahan)
Jika dibandingkan dengan uji beda rata-rata secara univariate, dari
keenam variabel di atas, hanya satu variabel yaitu X4 (Umur Suami) yang
gagal menolak H0 dan satu variabel X10 (Lama Menyusui Anak Kedua)
menolak H0 pada tingkat signifikan 8,75 persen. Sedangkan keempat
variabel lainnya berbeda secara signifikan pada level dibawah 1 persen.
4.3. Model
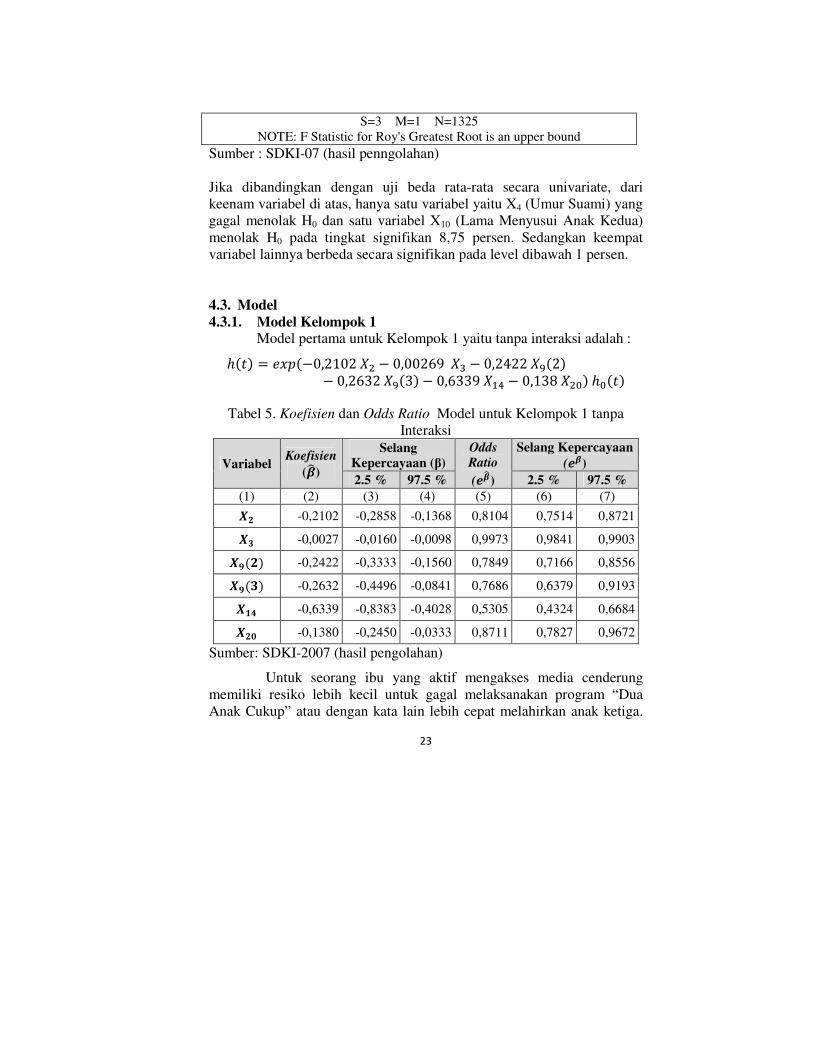
4.3.1. Model Kelompok 1 Model pertama untuk Kelompok 1 yaitu tanpa interaksi adalah : ℎ�U = z���−0,2102 �# − 0,00269 �v − 0,2422 ���2− 0,2632 ���3 − 0,6339 ��� − 0,138 �#I ℎI�U
Tabel 5. Koefisien dan Odds Ratio Model untuk Kelompok 1 tanpa
Interaksi
Variabel Koefisien
(��)
Selang
Kepercayaan (β)
Odds
Ratio
(���)
Selang Kepercayaan
(��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7� -0,2102 -0,2858 -0,1368 0,8104 0,7514 0,8721 7 -0,0027 -0,0160 -0,0098 0,9973 0,9841 0,9903 7¡�� -0,2422 -0,3333 -0,1560 0,7849 0,7166 0,8556 7¡� -0,2632 -0,4496 -0,0841 0,7686 0,6379 0,9193 7¢£ -0,6339 -0,8383 -0,4028 0,5305 0,4324 0,6684 7�¤ -0,1380 -0,2450 -0,0333 0,8711 0,7827 0,9672
Sumber: SDKI-2007 (hasil pengolahan)
Untuk seorang ibu yang aktif mengakses media cenderung
memiliki resiko lebih kecil untuk gagal melaksanakan program “Dua
Anak Cukup” atau dengan kata lain lebih cepat melahirkan anak ketiga.

24
Resiko ibu yang aktif mengakses media informasi sebesar 0,8104 kali
dari resiko ibu yang tidak aktif mengakses media informasi. Sedangkan
faktor umur ternyata memiliki nilai odds ratio mendekati satu yang
artinya umur seorang ibu pada saat melahirkan anak kedua tidak terlalu
membedakan perilaku dalam menentukan bertahan lebih lama dengan dua
anak atau melahirkan anak ketiga lebih cepat.
Jika dilihat dari Kategori Anak yang Diinginkan, anak lahir
dengan kondisi diinginkan nanti memiliki resiko lebih kecil dibandingkan
anak dengan kondisi memang benar-benar diinginkan sekarang yang
artinya jarak kelahirannya akan cenderung lebih panjang. Sedangkan
untuk anak yang tidak diinginkan atau tidak direncanakan cenderung
lebih panjang lagi jarak kelahirannya dengan resiko sebesar 0,7686 kali
anak yang diinginkan. Hal ini wajar jika seorang ibu menginginkan anak
nanti tentu ada usaha untuk menunda kehamilan baik dengan alat
kontrasepsi maupun tidak, berbeda dengan ibu yang menginginkan anak
sekarang yang tidak memakai alat kontrasepsi sehingga resiko terjadinya
kehamilan lebih besar. Apalagi jika tidak menginginkan anak lagi, akan
ada usaha untuk mencegah kehamilan seperti sterilisasi, sehingga resiko
terjadinya kehamilan anak ketiga akan lebih kecil lagi.
Untuk variabel Status Bekerja Suami, seorang ibu dengan suami
yang berstatus bekerja cenderung lebih kecil resiko kelahiran anak
ketiganya yaitu sebesar 0,5305 kali dibanding dengan suami tidak
bekerja. Hal ini biasanya berhubungan dengan tingkat pendidikan suami
yang dimana menentukan status bekerja suami dan wawasan tentang
pentingnya mengatur jarak kelahiran. Tipe tempat tinggal ternyata masih
signifikan untuk provinsi-provinsi di Kelompok 1 ini, yang menarik
adalah ibu yang tinggal di daerah perkotaan cenderung beresiko lebih
tinggi untuk gagal dalam program “Dua Anak Cukup” atau melahirkan
anak ketiga dibanding seorang ibu yang tinggal di pedesaan.
Model kedua untuk Kelompok 1 yaitu dengan interaksi adalah: ℎ�U = z���−0,5361 �# − 0,02238 �v − 0,2395 ���2 − 0,2223 ���3− 0,8228 ��� − 0,9332 �#I + 0,03081 �# ∗ �v + 0,9236 ���∗ �#I − 2,962% − 4 �# ∗ �v ∗ ��� ℎI�U
25
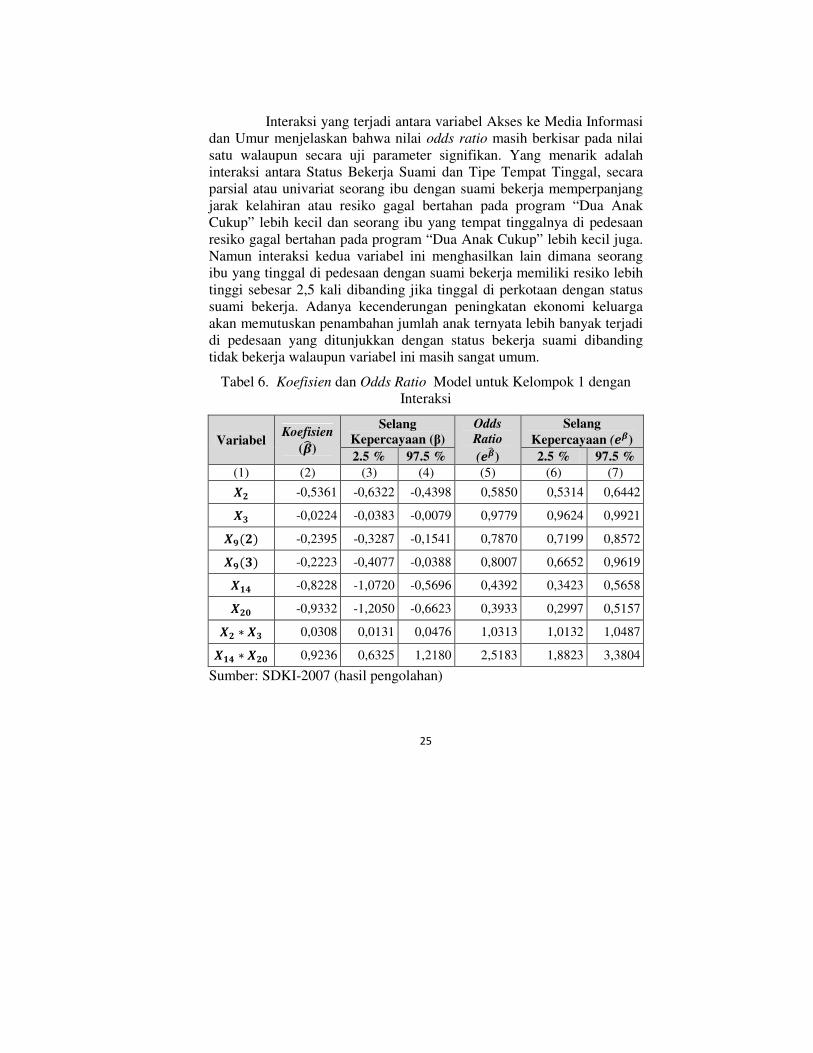
Interaksi yang terjadi antara variabel Akses ke Media Informasi
dan Umur menjelaskan bahwa nilai odds ratio masih berkisar pada nilai
satu walaupun secara uji parameter signifikan. Yang menarik adalah
interaksi antara Status Bekerja Suami dan Tipe Tempat Tinggal, secara
parsial atau univariat seorang ibu dengan suami bekerja memperpanjang
jarak kelahiran atau resiko gagal bertahan pada program “Dua Anak
Cukup” lebih kecil dan seorang ibu yang tempat tinggalnya di pedesaan
resiko gagal bertahan pada program “Dua Anak Cukup” lebih kecil juga.
Namun interaksi kedua variabel ini menghasilkan lain dimana seorang
ibu yang tinggal di pedesaan dengan suami bekerja memiliki resiko lebih
tinggi sebesar 2,5 kali dibanding jika tinggal di perkotaan dengan status
suami bekerja. Adanya kecenderungan peningkatan ekonomi keluarga
akan memutuskan penambahan jumlah anak ternyata lebih banyak terjadi
di pedesaan yang ditunjukkan dengan status bekerja suami dibanding
tidak bekerja walaupun variabel ini masih sangat umum.
Tabel 6. Koefisien dan Odds Ratio Model untuk Kelompok 1 dengan
Interaksi
Variabel Koefisien
(��)
Selang
Kepercayaan (β)
Odds
Ratio
(���)
Selang
Kepercayaan (��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7� -0,5361 -0,6322 -0,4398 0,5850 0,5314 0,6442 7 -0,0224 -0,0383 -0,0079 0,9779 0,9624 0,9921 7¡�� -0,2395 -0,3287 -0,1541 0,7870 0,7199 0,8572 7¡� -0,2223 -0,4077 -0,0388 0,8007 0,6652 0,9619 7¢£ -0,8228 -1,0720 -0,5696 0,4392 0,3423 0,5658 7�¤ -0,9332 -1,2050 -0,6623 0,3933 0,2997 0,5157 7� ∗ 7 0,0308 0,0131 0,0476 1,0313 1,0132 1,0487 7¢£ ∗ 7�¤ 0,9236 0,6325 1,2180 2,5183 1,8823 3,3804
Sumber: SDKI-2007 (hasil pengolahan)

26
Nilai deviance model kedua yaitu model dengan interaksi lebih
kecil dibanding model pertama namun penurunannya hanya sekitar 0,4
persen dari model pertama. Jika kesederhanaan model yang
dipertimbangkan maka model pertama lebih disarankan, tetapi jika dilihat
dari hasil temuan interaksi beberapa variabel pada model kedua yang
sangat berarti menjelaskan permasalahan maka penulis menyarankan
pemakaian model kedua untuk melihat fenomena permasalahan ini.
4.3.2. Model Kelompok 2 Model untuk Kelompok 2 yaitu tanpa interaksi adalah : ℎ�U = z���−0,05756 �v − 0,8791 ��#�2 − 0,6673 ��#�3 − 0,9844 ��#�4− 1,095 ��#�5 + 0,3186 ��#�7 + 1,176 �#I ℎI�U
Berdasarkan uji hipotesis pada βi, distribusi posterior untuk β12 (5), β12 (7)
dan β20 tidak signifikan karena selang kepercayaan memuat angka nol.
Tabel 7. Koefisien dan Odds Ratio Model untuk Kelompok 2 tanpa
Interaksi
Variabel Koefisien
(��)
Selang Kepercayaan
(β)
Odds
Ratio
(���)
Selang
Kepercayaan (��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7 -0,0576 -0,0767 -0,0355 0,9441 0,9261 0,9652 7¢��� -0,8791 -0,9382 -0,8217 0,4152 0,3913 0,4397 7¢�� -0,6673 -0,8821 -0,4653 0,5131 0,4139 0,6279 7¢��£ -0,9844 -1,5530 -0,4755 0,3737 0,2116 0,6216
Sumber: SDKI-2007 (hasil pengolahan)
Pada Kelompok 2 ini faktor umur ternyata lebih terlihat
pengaruhnya dibanding Kelompok 1 yang mendekati satu, walaupun nilai
odds ratio hanya sedikit lebih kecil yaitu 0,9441 yang artinya semakin
tua seorang ibu pada saat memiliki anak dua akan memiliki resiko lebih
kecil dibanding ibu yang lebih muda. Variabel lain yang signifikan adalah
Agama. Kategori 1 sebagai reference adalah Islam sebagai agama untuk

27
mayoritas penduduk Indonesia. Seorang ibu yang menganut agama Hindu
memiliki resiko paling kecil yaitu 0,3737 kali ibu dengan agama Islam,
kemudian agama Protestan sebesar 0,4152 dan yang paling dekat dengan
Islam adalah Katolik sebesar 0,5131 kali. Sedangkan agama Budha dan
Lainnya tidak signifikan pada uji parameter. Tentu hal ini perlu kajian
lebih dalam karena representasi sampel SDKI juga belum
memperhitungkan variabel agama. Variabel Tipe Tempat Tinggal
ternyata juga tidak signifikan pada Kelompok 2.
4.3.3. Model Kelompok 3 Model untuk Kelompok 3 yaitu tanpa interaksi adalah :
ℎ�U = z�� −0,1009 �v − 0,6571 ���2 − 0,4093 ���3$ ℎI�U
Berdasarkan selang kepercayaan 2,5% - 97,5%, semua
distribusi posterior koefisien di atas tidak memuat angka nol sehingga
semua variabel signifikan dalam model.
Tabel 8. Koefisien dan Odds Ratio Model untuk Kelompok 3 tanpa
Interaksi
Variabel Koefisien
(��)
Selang
Kepercayaan (β) Odds Ratio
(���)
Selang
Kepercayaan (��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7 -0,1099 -0,1366 -0,0835 0,8959 0,8723 0,9199 7¡�� -0,6571 -0,7170 -0,5949 0,5184 0,4882 0,5516 7¡� -0,4093 -0,5856 -0,2321 0,6641 0,5568 0,7929
Sumber: SDKI-2007 (hasil pengolahan)
Pada Kelompok 3 ini faktor umur memiliki nilai odds ratio
lebih kecil dibanding 2 kelompok sebelumnya yaitu 0,8959 yang artinya
semakin tua seorang ibu memiliki anak 2 akan memiliki resiko lebih kecil
dibanding ibu yang lebih muda. Variabel lain yang signifikan adalah
Kategori Anak yang Diinginkan, anak lahir dengan kondisi diinginkan
nanti memiliki resiko lebih kecil dibandingkan anak dengan kondisi

28
memang benar-benar diinginkan sekarang yaitu sebesar 0,5184 kali anak
yang diinginkan. Sedangkan untuk anak yang tidak diinginkan atau tidak
direncanakan cenderung memiliki resiko sebesar 0,6641 kali dibanding
anak yang diinginkan.
4.3.4. Model Kelompok 4 Model pertama untuk Kelompok 4 yaitu tanpa interaksi adalah :
ℎ�U = z�� −0,4838 �� − 0,06106 �v − 0,3092 ���2− 0,4788 ���3$ ℎI�U
Hasil pengujian hipotesis untuk setiap parameternya menunjukkan semua
parameter model signifikan.
Tabel 9. Koefisien dan Odds Ratio Model untuk Kelompok 4 tanpa
Interaksi
Variabel Koefisien
(��)
Selang
Kepercayaan (β)
Odds
Ratio
(���)
Selang
Kepercayaan (��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7¢ -0,4838 -0,7790 -0,1829 0,6164 0,4589 0,8329 7 -0,0611 -0,0784 -0,0430 0,9408 0,9246 0,9579 7¡�� -0,3092 -0,4925 -0,1285 0,7340 0,6111 0,8794 7¡� -0,4788 -0,6495 -0,3126 0,6195 0,5223 0,7315
Sumber: SDKI-2007 (hasil pengolahan)
Untuk seorang ibu yang mempunyai kemampuan baca tulis
cenderung memiliki resiko lebih kecil untuk bertahan pada program “Dua
Anak Cukup” yaitu sebesar 0,6164 kali dari resiko ibu yang tidak bisa
baca tulis. Sedangkan faktor umur hampir sama dengan Kelompok 2
yaitu mempunyai nilai odds ratio mendekati satu yang artinya umur
seorang ibu pada saat melahirkan anak kedua tidak terlalu berbeda
perilaku dalam menentukan bertahan lebih lama dengan dua anak atau
melahirkan anak ketiga lebih cepat. Jika dilihat dari Kategori Anak yang
Diinginkan, anak lahir dengan kondisi diinginkan tetapi waktunya nanti

29
memiliki resiko lebih kecil dibandingkan anak dengan kondisi memang
benar-benar diinginkan sekarang yaitu sebesar 0,7340 kali dibanding
anak yang diinginkan sekarang. Sedangkan untuk anak yang tidak
diinginkan atau tidak direncanakan lebih panjang lagi jarak kelahirannya
dengan resiko sebesar 0,6195 kali jika anak diinginkan saat ini.
Model kedua untuk Kelompok 4 yaitu dengan interaksi adalah:
ℎ�U = z�� 0,02845 �v − 0,145 ���2 − 0,4591 ���3 − 0,2684 �� ∗ ���2− 0,4617 �� ∗ ���3$ ℎI�U
Tabel 10. Koefisien dan Odds Ratio Model untuk Kelompok 4 dengan
Interaksi
Variabel Koefisien
(��)
Selang
Kepercayaan (β)
Odds
Ratio
(���)
Selang
Kepercayaan (��)
2.5 % 97.5 % 2.5 % 97.5 %
(1) (2) (3) (4) (5) (6) (7) 7 0,0285 0,5635 0,0533 1,0289 1,7568 1,0547 7¡�� -0,1450 -0,1716 -0,1183 0,8650 0,8423 0,8884 7¡� -0,4591 -0,6349 -0,2887 0,6319 0,5300 0,7492 7¢ ∗ 7¡�� -0,2684 -0,4488 -0,0882 0,7646 0,6384 0,9156 7¢ ∗ 7¡� -0,4617 -0,5942 -0,2438 0,6302 0,5520 0,7836
Sumber: SDKI-2007 (hasil pengolahan)
Interaksi yang terjadi antara variabel Kemampuan Baca Tulis
dan Anak Yang Diinginkan menjelaskan bahwa nilai odds ratio masih
sejalan dengan odds ratio variabel Anak Yang Diinginkan secara parsial.
Namun setelah berinteraksi dengan variabel Kemampuan Baca Tulis
terlihat bahwa seorang ibu yang bisa baca tulis akan menurunkan resiko
gagalnya program “Dua Anak Cukup” atau memperpanjang jarak
kelahiran anak ketiga dari anak kedua. Hal ini berlaku untuk kategori
anak diinginkan nanti maupun tidak diinginkan yang berinteraksi dengan
kemampuan baca tulis memiliki nilai odds ratio lebih kecil dibanding jika
tanpa interaksi. Untuk seorang ibu yang mampu baca tulis dan anak
ketiga diinginkan nanti memiliki nilai odds ratio sebesar 0,7646 kali

30
dibanding ibu yang mampu baca tulis dan menginginkan anak sekarang
dan untuk kondisi ibu yang mampu baca tulis dan anak ketiga tidak
diinginkan memiliki nilai odds ratio sebesar 0,6302 kali dibanding ibu
yang mampu baca tulis dan menginginkan anak sekarang.
Variabel Anak Yang Diinginkan cenderung berkaitan dengan
penggunaan alat kontrasepsi, dimana jika kategori 1 yaitu diinginkan
maka seorang ibu cenderung tidak menggunakan alat kontrasepsi. Jika
menginginkan nanti maka cenderung menggunakan alat kontrasepsi
untuk mencegah kehamilan saat ini dan akan berhenti jika waktunya
dianggap tepat. Sedangkan kategori 3 yaitu tidak diinginkan, maka
penggunaan alat kontrasepsi cenderung untuk jangka panjang seperti
sterilisasi. Sehingga wajar jika berinteraksi dengan kemampuan baca
tulis yang berkaitan dengan wawasan terhadap informasi tentang
pengaturan jarak kelahiran.
Nilai deviance model kedua yaitu model dengan interaksi lebih
kecil dibanding model pertama namun penurunannya hanya sekitar 0,9
persen dari model pertama. Jika dilihat dari hasil temuan interaksi
beberapa variabel pada model kedua ternyata menghasilkan interpretasi
yang tidak jauh berbeda dengan model pertama, dan mempertimbangkan
kemudahan interpretasi model pada model pertama maka penulis
menyarankan pemakaian model pertama untuk melihat fenomena
permasalahan pada kelompok 4 ini.
Beberapa struktur karakteristik individu ibu di Indonesia dapat
terjelaskan dari proses pengelompokan provinsi dan permodelan di atas.
Varibel umur pada saat melahirkan anak kedua sangat berpengaruh
terhadap jarak kelahiran dengan anak ketiga yang ditunjukkan dengan
masuknya variabel ini ke semua model yang terbentuk pada 4 kelompok.
Makin tua seorang ibu melahirkan anak kedua, semakin kecil peluangnya
untuk melahirkan anak ketiga yang artinya akan memperpanjang jarak
kelahiran. Variabel ini tidak dapat terlepas dari umur perkawinan pertama
dan jarak kelahiran sebelumnya serta terbatasnya masa reproduksi
seorang wanita.
Penundaan umur perkawinan pertama sangat erat dengan faktor
pendidikan perempuan, semakin tinggi perempuan berpartisipasi dalam
pendidikan secara langsung akan menunda usia perkawinan pertama. Dari
empat kelompok yang terbentuk, kelompok 2 dan kelompok 3

31
memberikan gambaran yang sangat jelas akan kondisi di atas. Kelompok
2 dengan tingkat pendidikan ibu paling tinggi yaitu dengan rata-rata lama
sekolah 9,22 tahun yang artinya mayoritas lulus sekolah menengah
pertama, memiliki rata-rata umur perkawinan pertama relatif lebih tinggi
yaitu 21,20 tahun. Tingkat pendidikan lebih tinggi juga dibarengi dengan
kemampuan baca tulis serta tingkat akses ke media informasi yang lebih
baik. Sehingga akses ke alat kontrasepsi juga mengikuti serta keinginan
memiliki anak ketiga paling rendah dibanding kelompok lainnya yang
didukung dengan penggunaan alat kontrasepsi. Pada kelompok ini fungsi
keluarga juga lebih baik, terlihat dari pendapat suami tentang KB dan
keputusan ikut ber-KB yang lebih mudah. Secara ekonomi, keluarga pada
kelompok 2 ini lebih banyak ditopang oleh pekerjaan suami dibidang
perdagangan dan jasa serta profesional, dan status bekerja ibu memiliki
persenatse paling kecil dibanding ketiga kelompok lainnya.
Sebaliknya, pada kelompok 3 dengan tingkat pendidikan paling
rendah yaitu rata-rata lama sekolah hanya berkisar pada 7,49 tahun yang
artinya lulus sekolah dasar dan pernah duduk di sekolah menengah
pertama tetapi tidak lulus. Umur perkawinan pertama adalah 20,25 tahun
dengan persentase ibu yang mampu baca tulis hanya 87 persen dan yang
aktif mengakses media informasi sekitar 65 persen, tingkat terendah dari
keempat kelompok yang diikuti pula dengan akses ke alat kontrasepsi
yang rendah. Dari sisi intervensi pemerintah yang tidak mengena jika
lewat media informasi, ternyata melalui petugas KB juga memiliki
tingkat keaktifan terendah yaitu hanya 2,9 persen. Dari sisi keluarga,
suami yang setuju KB hanya 59 persen dan pekerjaan suami mayoritas di
sektor pertanian. Di sektor ini persentase perempuan bekerja lebih tinggi
karena sebagai pemilik lahan dan pekerja keluarga.

32
Gambar 4.11. Hazard rate kelompok 1,2,3, dan 4
Namun, terdapat fenomena yang tidak seperti pada umumnya
yaitu kenaikan tingkat pendidikan yang tidak linier dengan penurunan
tingkat kegagalan program “Dua Anak Cukup”. Terlihat pada Gambar
4.11 bahwa hazard rate kelompok 2 lebih tinggi dibanding kelompok 3.
Hal ini terjadi tidak hanya pada kelahiran anak ketiga saja, tetapi fertilitas
secara umum di Indonesia jika dihubungkan dengan tingkat pendidikan
ibu memiliki hubungan huruf U-terbalik. Perempuan tidak berpendidikan
memiliki TFR terendah dan meningkat pada perempuan belum dan tamat
SD kemudian menurun pada tingkat pendidikan belum tamat sekolah
menengah dan menurun lagi pada tingkat pendidikan tinggi tetapi tidak
lebih rendah dibanding perempuan tidak berpendidikan. Fertilitas
menurut indek kekayaan juga mempunyai hasil yang tidak diharapkan.
TFR tertinggi justru terjadi pada kalangan kuantil terbawah atau
termiskin, diikuti kuantil menengah dan kuantil teratas atau terkaya.
Tabel 11. Angka Fertilitas Total (TFR) Menurut Tingkat Pendidikan dan
Indek Kekayaan Ibu Tahun 2007
12 24 36 48 60 72 84 96 108 120
h1 0,01 0,01 0,02 0,02 0,02 0,03 0,03 0,03 0,03 0,03
h2 0,01 0,01 0,02 0,02 0,02 0,02 0,03 0,03 0,03 0,03
h3 0 0,01 0,01 0,02 0,02 0,02 0,02 0,02 0,03 0,03
h4 0,01 0,01 0,02 0,02 0,02 0,02 0,02 0,03 0,03 0,03
0
0,005
0,01
0,015
0,02
0,025
0,03
0,035
0,04
ha
zard
rate

33
Tingkat Pendidikan Ibu TFR Indek Kekayaan TFR
(1) (2) (3) (4)
Tidak Berpendidikan 2,4 Kuantil Terbawah 3,0
Belum Tamat SD 2,8 Kuantil Kedua 2,5
Tamat SD 2,8 Kuantil Menengah 2,8
Belum Tamat Sekolah Menengah 2,7 Kuantil Keempat 2,5
Tamat Sekolah Menengah 2,5 Kuantil Teratas 2,7
Sumber: SDKI-2007
Tingkat pendidikan ibu di Indonesia tidak dapat menjadi
jaminan turunnya fertilitas, justru naiknya taraf pendapatan yang dapat
diwakili oleh indek kekayaan menyatakan bahwa peningkatan
kesejahteraan sejalan dengan penurunan TFR. Hal ini menjadi perhatian
bersama bahwa program KB tidaklah semata-mata kebijakan
kependudukan, tetapi merupakan program strategis pembangunan yang
dalam jangka panjang akan berdampak pada kesejahteraan penduduk
dalam arti luas. Penelitian di beberapa negara yang telah mencapai bonus
demografi menunjukkan bahwa pengeluaran pemerintah sebesar 1 US
dolar akan memberikan keuntungan pada negara sebesar 4 US dolar.
Tentu hal ini akan tercapai dengan adanya komitmen bersama terutama
pemerintah daerah dimana saat ini kebijakan program KB dilimpahkan
pada pemerintah daerah dengan diterbitkannya perundang-undangan yang
mendukung yaitu UU No.32/2004, PP No.38/2007, PP No.41/2007 dan
UU No.39/2008. Walaupun pelaksanaannya sampai saat ini belum semua
daerah memiliki kelembagaan KB sesuai amanat undang-undang dan
yang sudah terbentuk cenderung digabung dengan unit atau dinas lain
yang akhirnya program KB terpinggirkan. Akhirnya program ini
tergantung pada persepsi dan pemahaman pemerintah daerah tentang
program KB.
Di antara 4 kelompok provinsi di atas, paling membutuhkan
perhatian adalah kelompok 1. Kelompok 1 terdiri dari 16 provinsi hampir
setengah dari jumlah seluruh provinsi di Indonesia, memiliki hazard rate
tertinggi pada waktu kapanpun. Rata-rata lama sekolah ibu rendah yang
diikuti oleh usia perkawinan pertama muda, walaupun petugas KB aktif

34
di kelompok ini lebih tinggi persentasenya dibanding kelompok lain
namun keinginan ibu untuk memiliki anak ketiga masih tinggi. Hal ini
mengindikasikan intervensi program “Dua Anak Cukup” pada kelompok
1 tidak mengena pada sasaran. Untuk bidang ekonomi, kelompok ini juga
paling rentan dengan resiko gagalnya program “Dua Anak Cukup”
dengan berubahnya status bekerja suami. Status suami bekerja
mengurangi resiko 53 persen dibanding suami tidak bekerja, tetapi jika
seorang ibu memiliki suami bekerja antara di pedesaan dan perkotaan
memiliki resiko yang sangat berbeda dimana di pedesaan 2,5 kali lebih
besar resikonya untuk gagal bertahan di program “Dua Anak Cukup”.
5. Kesimpulan dan Saran
5.1. Kesimpulan Berdasarkan hasil dan pembahasan, dapat disimpulkan bahwa :
1. Indikasi adanya ledakan penduduk di Indonesia yang ditunjukkan
beberapa indikator demografi menjadikan pengendalian penduduk
menjadi masalah yang tidak dapat diabaikan. Pergeseran perilaku
ibu dalam membatasi jumlah anak, pergeseran usia perkawinan
pertama, dan beberapa masalah lain ditunjukkan hasil SDKI-2002
dan SDKI-2007 cukup mengkhawatirkan. Namun permasalahan-
permasalahan di atas tidak terjadi di semua provinsi. Masing-
masing provinsi memiliki permasalahan masing-masing yang
dipengaruhi keadaan ekonomi, sosial, budaya dan kondisi
demografinya, sehingga pengelompokan provinsi-provinsi
dilakukan untuk mendapatkan kelompok provinsi yang lebih
homogen (variabilitas kecil) dan antar kelompok lebih heterogen.
Pengelompokan provinsi menghasilkan 4 kelompok yaitu :
i. Kelompok 1 terdiri dari 16 provinsi yaitu DI Aceh, Sumatera
Utara, Sumatera Barat, Jambi, Sumatera Selatan, Bengkulu,
Lampung, Bangka Belitung, Kep. Riau, DKI Jakarta,
Sulawesi Selatan, Sulawesi Tenggara, Maluku, Maluku
Utara, Papua, dan Papua Barat memiliki karakteristik rata-
rata lama sekolah ibu rendah (7,59 tahun), umur ibu muda
(31,8 tahun), usia perkawinan pertama termuda (19,26
tahun), keaktifan petugas KB paling tinggi (6,2 persen), dan
mayoritas menginginkan anak ke-3 (77,1 persen).

35
ii. Kelompok 2 terdiri dari 9 provinsi yaitu Banten, Bali, Nusa
Tenggara Barat, Kalimantan Selatan, Kalimantan Timur,
Sulawesi Utara, Sulawesi Tengah, Gorontalo, dan Sulawesi
Barat memiliki karakteristik rata-rata lama sekolah ibu
paling tinggi (9,22 tahun), akses ke media dan alokon tinggi
(88 persen dan 91,2 persen), partisipasi kerja rendah (55,9
persen), suami bekerja di luar pertanian tinggi (72 persen),
suami setuju KB (80,1 persen), menginginkan anak ke-3
terendah (68,9 persen).
iii. Kelompok 3 terdiri dari 4 provinsi yaitu Riau, Jawa Timur,
Jawa Barat, dan Kalimantan Barat memiliki karakteristik
rata-rata lama sekolah ibu paling rendah (7,49 persen), akses
ke media dan alokon paling rendah (65 persen dan 70,2
persen), partisipasi kerja rendah (57,8 persen), suami bekerja
di sektor pertanian (56,1 persen), persentase suami setuju
KB terendah (59,2 persen), menginginkan anak ke-3 rendah
(72 persen).
iv. Kelompok 4 terdiri dari 4 provinsi yaitu Jawa Tengah, DI
Yogyakarta, Nusa Tenggara Timur, Kalimantan Tengah
memiliki karakteristik rata-rata lama sekolah ibu tinggi (8,22
tahun), umur ibu tua (33,17 tahun), usia perkawinan pertama
tertinggi (21,3 tahun), akses ke media rendah (67,8 persen),
dan persentase wanita tidak menginginkan anak ke-3
tertinggi (13,7 persen) .
2. Data jarak kelahiran anak kedua dan ketiga yang dihubungkan
dengan beberapa faktor yang mempengaruhinya mengandung data
tersensor yang dapat ditangani dalam analisis survival dengan
Model Proporsional Hazard. Model yang terbentuk masing-masing
kelompok adalah :
i. Kelompok 1 menggunakan model dengan interaksi yaitu: ℎ�U = z���−0,5361 �# − 0,02238 �v − 0,2395 ���2− 0,2223 ���3 − 0,8228 ��� − 0,9332 �#I+ 0,03081 �# ∗ �v + 0,9236 ��� ∗ �#I − 2,962%− 4 �# ∗ �v ∗ ��� ℎI�U Pada kelompok 1 ini faktor yang mempengaruhi jarak
kelahiran anak kedua dan ketiga adalah akses ke media

36
informasi, umur ibu pada saat melahirkan anak kedua, anak
yang diinginkan, status bekerja suami dan tipe tempat
tinggal.
ii. Model untuk Kelompok 2 adalah model tanpa interaksi
yaitu: ℎ�U = z���−0,05756 �v − 0,8791 ��#�2 − 0,6673 ��#�3− 0,9844 ��#�4 − 1,095 ��#�5 + 0,3186 ��#�7+ 1,176 �#I ℎI�U Kelompok 2, faktor yang mempengaruhi bertahannya
propgram “Dua Anak Cukup” pada individu ibu adalah umur
ibu pada saat melahirkan anak kedua, agama dan tipe tempat
tinggal.
iii. Model untuk Kelompok 3 yaitu tanpa interaksi dengan
persamaan: ℎ�U = z�� −0,1009 �v − 0,6571 ���2 − 0,4093 ���3$ ℎI�U
Pada kelompok 3, ketahanan program “Dua Anak Cukup”
dipengaruhi oleh faktor umur ibu pada saat melahirkan anak
kedua dan anak yang diinginkan.
iv. Model untuk kelompok 4 menggunakan model tanpa
interaksi yaitu : ℎ�U = z�� −0,4838 �� − 0,06106 �v − 0,3092 ���2− 0,4788 ���3$ ℎI�U
Pada kelompok terakhir ini program “Dua Anak Cukup”
dipengaruhi oleh faktor kemampuan baca tulis, umur ibu
pada saat melahirkan anak kedua dan anak yang diinginkan.
3. Kelompok yang paling membutuhkan perhatian adalah kelompok
1, dimana memiliki hazard rate tertinggi, rata-rata lama sekolah
rendah dan usia perkawinan pertama muda. Keadaan
perekonomian keluarga mempengaruhi keputusan mempunyai anak
ketiga yang mayoritas ibu masih menginginkan memiliki anak
ketiga walaupun keaktifan petugas KB paling tinggi dibanding
kelompok lain. Selain itu, umur ibu saat melahirkan anak kedua
sangat kecil mempengaruhi resiko gagalnya program “Dua Anak
Cukup”. Meskipun ada penundaan usia perkawinan pertama yang
akibatnya menunda kelahiran anak kedua dan memperkecil resiko
lahirnya aanak ketiga, namun efeknya sangat kecil. Jadi dibutuhkan

37
kerja keras pemerintah dan semua pihak untuk dapat melakukan
intervensi pembatasan jumlah anak pada kelompok 1 ini.
5.2. Saran Dalam kerangka pembangunan nasional baik ditinjau dari sisi
ekonomi maupun pembangunan manusia, masalah kependudukan tidak
bisa diabaikan. Untuk mencapai pertumbuhan ekonomi pada level
tertentu tidak dapat dipisahkan dari pengendalian jumlah pengangguran,
jumlah penduduk miskin, partisipasi sekolah, dan lain-lain yang berkaitan
erat dengan penduduk. Sehingga pengendalian jumlah penduduk rasanya
masih diperlukan di Indonesia dengan kebijakan yang mengintervensi
jumlah anggota keluarga seperti “Dua Anak Cukup” yang sekarang di
perbarui dengan “Dua Lebih Baik”.
Beberapa hal yang dapat disarankan adalah:
1. Untuk pemerintahan pusat, menunda usia perkawinan adalah usaha
yang dapat dilakukan secara nasional dengan melalui pendekatan
kesehatan seperti bahayanya melahirkan di usia dini, dari sisi
pendidikan dengan meningkatkan partisipasi sekolah untuk
perempuan pada tingkat sekolah menengah atas dan perguruan
tinggi, dari sisi ekonomi dengan meningkatkan partisipasi angkatan
kerja perempuan dan lain-lain. Selain itu, memberikan pemahaman
yang sama kepada pemerintah daerah tentang pentingnya program
kependudukan bagi pembangunan.
2. Untuk pemerintah daerah, faktor-faktor yang mempengaruhi
kurang berhasilnya program “Dua Anak Cukup” berbeda antar
wilayah sehingga disesuaikan dengan kondisi wilayahnya masing-
masing. Bahkan jika memungkinkan sampai tingkat
kabupaten/kota dapat dilakukan dengan pendekatan yang berbeda
mengingat pada era otonomi beberapa urusan telah dijadikan
urusan wajib bagi pemerintah daerah termasuk kelembagaan KB
sesuai dengan peraturan perundang-undangan yang berlaku.
3. Untuk Badan Pusat Statistik sebagai penyelenggara SDKI,
pengambilan sampel dapat dilakukan dengan penimbang beberapa
variabel yang memungkinkan mempengaruhi perilaku individu
dibidang demografi dan kesehatan seperti suku dan agama. Bahkan
kenyataan bahwa dalam provinsipun terdapat perbedaan-perbedaan

38
karakteristik antar kabupaten/kota yang dalam pemecahan masalah
seperti kependudukan tidak dapat digeneralisir menurut provinsi.
Pengambilan sampel untuk estimasi tingkat kabupaten/kota kiranya
perlu menjadi perhatian untuk penyelenggaraan SDKI yang akan
datang.
DAFTAR PUSTAKA
AL-Almaie, S.M. (2003), The Pattern and Factors Associated with Child
Spacing in Eastern Saudi Arabia, The Journal of the Royal Society
for the Promotion of Health. Vol.123, No.4, 217-221
BKKBN, (1981), Sejarah Perkembangan Keluarga Berencana dan
Program Kependudukan, BKKBN, Jakarta.
Bongaarts, J. (1978). A Framework for Analysing the Proximate
Determinants of Fertility. Population and Development Review,
4(1), 105-132.
Box, G.E.P dan Tiao, G.C. (1973), Bayesian Inference in Statistical
Analysis, Reading, MA: Addison-Wesley.
BPS, BKKBN, DEPKES, dan ORC Macro (2008), Indonesia
Demographic and Health Survey 2007, BPS, BKKBN, DEPKES,
dan ORC Macro, Jakarta.
Carlin, B.P. dan Chib, S. (1995), “Bayesian Model Choice via Markov
Chain Monte Carlo Methods”, Journal of The Royal Statistical
Society. Series B(Methodological), Vol.57, No. 3, hal. 473 – 484.
Casella, G. dan George, E.I. (1992), “Explaining Gibbs Sampler”,
Journal of The American Statistical Association, 46(3), 167 – 174.
Collet, D. (1994), Modelling Survival Data in Medical Research,
Chapman and Hall, London.
Cox, DR. and Oakes, D. (1984), Analysis of Survival Data, Chapman and
Hall, London.
Ducrocq, V. (1997), “Survival Analysis, a Statistical Tool for Longevity
Data”, 48th Annual Meeting of the European Association for

39
Animal Production, Institut National de la Recherche
Agronomique, Vienna.
Gelfand, A. E., Hills, S.E., Recine-Poon, A. and Smith,A.F.M. (1990),
Illustration of Bayesian Inference in Normal Data Models Using
Gibbs Sampling, Journal of the American Statistical Association
85(412), 972-985.
Gelman, A, Carlin, J.B, Stern, H.S, dan Rubin, D.B. (1995), Bayesian
Data Analysis, Chapman and Hall, London.
Hobcraft, J., McDonald, J., Menken, J., Rodriguez, G. and Trussel, J.
(1984), A Comparative Analysis of determinants of Birth Intervals.
In, WFS Comparative Study: Cross-National Summaries (World
Fertility Surveys). Voorburg, Netherland, International Statistical
Institute, 31 pp.
Iriawan, N. (2000), Computationally Intensive Approuches to Inference in
Neo Normal Linear Model , Ph.D Thesis, CUT - Australia.
Kayri, M. (2007), “Two-Step Clustering Analysis in Researches: A Case
Study”, Eurasian Journal of Educational Researches Vol : 28,
pp,89-99.
Kleinbaum, D.G, and Klein, M.(2005), Survival Analysis: A Self-
Learning Text, Second Edition, Springer, New York.
Kneib,T and Fahrmeir, L, (2004), “A Mixed Model Approach for
Structured Hazard Regression”, Sonderforchungsbereich 386
paper 400, Department of Statistics, University of Munich,
Munich.
Mahmood, S. (2009), Estimating Multivariate Proporsional Hazards
Model: an Application to the Birth Interval in Bangladesh.Thesis,
ISRT, Bangladesh.
Mengersen, K. (2009), “Modul 1 Bayesian Analysis”, Short Course on
Bayesian Modelling, Jurusan Statistika Institut Teknologi Sepuluh
Nopember, Surabaya.

40
Miller, R. (1998), Survival Analysis, John Willey and Sons Inc. New
York.
Nelson, W.B. (1982), Applied Life Data Analysis, John Willey and Sons
Inc., New York.
Niggli, M. dan Musy, A. (2005), A Bayesian combination method of
flood models: Principles and application results. Agricultural
Water Management. Vol: 7, Pp. 110–127
Polo, V., Luna, F., and Fuster,V. (2000), Determinants of Birth Interval in
a Rural Mediterranean Population (La Alpujarra, Spain).
http://findarticles.com/p/articles/mi_qa3669/is_20001/ai_n8924237
Reev Consult International (2008), Uganda Birth Spacing Qualitative
Research Study.
http://jhuccp.org/training/Webconference/ChangingNorms07/Ugan
da
Rindfuss, R. R., Palmore, J. A., & Bumpass, L. L. (1987). Analyzing
Birth Intervals: Implications for Demographic Theory and Data
Collection. Sociological Forum, 2(4), 811-828.
Stephen, E.H, and Chandra, A. (2007). The Long and the Short : Birth
Interval Spacing among Women in United States.
http://paa2007.princeton.edu/download.aspx?submissionId=71525
Tanner, M.A. (1996), Tools for Statistical Inference: Methods to the
Eksploration of Posterior Distributions and Likelihood Functions,
3th
ed. Springer-Verlag, New York.
Zellner, A. (1971), An Introduction to Bayesian Inference in
Econometrics, John Willey and Sons Inc., New York.