alison b lowndes - fueling the artificial intelligence revolution with gaming - codemotion milan...
TRANSCRIPT

1
ALISON B LOWNDES
AI DevRel | EMEA
@alisonblowndes
November 2017
FUELING THE AI
REVOLUTION WITH GAMING

2
The day job
AUTOMOTIVEAuto sensors reporting
location, problems
COMMUNICATIONSLocation-based advertising
CONSUMER PACKAGED GOODSSentiment analysis of what’s hot, problems
$
FINANCIAL SERVICESRisk & portfolio analysis
New products
EDUCATION & RESEARCHExperiment sensor analysis
HIGH TECHNOLOGY /
INDUSTRIAL MFG.Mfg. quality
Warranty analysis
LIFE SCIENCES MEDIA/ENTERTAINMENTViewers / advertising
effectiveness
ON-LINE SERVICES /
SOCIAL MEDIAPeople & career matching
HEALTH CAREPatient sensors, monitoring, EHRs
OIL & GASDrilling exploration sensor
analysis
RETAILConsumer sentiment
TRAVEL &
TRANSPORTATIONSensor analysis for
optimal traffic flows
UTILITIESSmart Meter analysis for network capacity,
LAW ENFORCEMENT
& DEFENSEThreat analysis - social media
monitoring, photo analysis

www.FrontierDevelopmentLab.org

An unlikely hero…
Unreal Engine 4©
Epic Games

5
Gaming
GPU Computing
VR AI & HPC Self-Driving Cars
NVIDIA

6

7
“the machine equivalent of experience”

Definitions

9
GPU Computing
GPUs are latency & throughput optimised(latency = time to do a task, throughput = # of tasks per unit of time)
x86

10
HOW GPU ACCELERATION WORKSApplication Code
+
GPU CPU5% of Code
Compute-Intensive Functions
Rest of SequentialCPU Code

11
https://devblogs.nvidia.com/parallelforall/even-easier-introduction-cuda/

12

13
Describe the differences between these 2 bikes……..

14
http://distill.pub/2017/momentum/

15
HOW DOES IT WORK?
Modeled on the Human Brain and Nervous System
Untrained Neural Network Model
App or ServiceFeaturing Capability
INFERENCEApplying this capability
to new data
NEW DATA
Trained ModelOptimized for Performance
“?”
Trained ModelNew Capability
TRAININGLearning a new capability
from existing data
Deep Learning Framework
TRAINING DATASET
Suzuki
X
“Suzuki”

16
HOW DOES IT WORK?
Trained ModelNew Capability
App or ServiceFeaturing Capability
INFERENCEApplying this capability
to new data
NEW DATA
Trained ModelOptimized for Performance
“?”
MV Agusta F3

17
RNN
Miro Enev, NVIDIA

18
Long short-term memory (LSTM)
Hochreiter (1991) analysed vanishing gradient “LSTM falls out of this almost naturally”
Gates control importance of
the corresponding
activations
Training
via
backprop
unfolded
in time
LSTM:
input
gate
output
gate
Long time dependencies are preserved until
input gate is closed (-) and forget gate is open (O)
forget
gate
Fig from Vinyals et al, Google April 2015 NIC Generator
Fig from Graves, Schmidhuber et al, Supervised
Sequence Labelling with RNNs

19
ResNets vs Highway Nets (IDSIA)
https://arxiv.org/pdf/1612.07771.pdf
Klaus Greff, Rupesh K. Srivastava
Really great explanation of “representation”
Compares the two.. shows for language modelling, translation HN >> RN.
Not quite as simple as each layer building a new level of representation from the previous - since removing any layer doesn’t critically disrupt.

20

21
Capsules & routing with EM, Hinton et alhttps://arxiv.org/pdf/1710.09829.pdf [NIPS2017]

22

THE NEXT STAGE

24
REINFORCEMENT LEARNING & ROBOTS
THINK / REASON
SENSE / PERCEIVE
ACT

25
DEEPMIND ALPHAGO 2.0 REMATCH5-0
AlphaGo Zero learns to play by itself now.

26
UNIVERSEhttps://universe.openai.com/

27
DeepMind Parkour, July 2017

28
One-shot imitation learninghttps://arxiv.org/pdf/1703.07326.pdf

29
Shakir Mohamed and Danilo Rezende, DeepMind, UAI 2017

30
A PLETHORA OF HEALTHCARE STORIES
Molecular EnergeticsFor Drug Discovery
AI for Drug DiscoveryMedical Decision
MakingTreatment Outcomes
Reducing Cancer Diagnosis Errors by
85%Predicting Toxicology
Predicting Growth Problems
Image Processing Gene Mutations Detect Colon PolypsPredicting Disease from
Medical RecordsEnabling Detection of
Fatty Acid Liver Disease

31
https://dltk.github.io/

32

33

34

35
Photorealistic models
Interactive physics
Collaboration
Early access in September
THE DREAMS OF
SCIENCE FICTION
https://nvidianews.nvidia.com/news/welcome-to-the-holodeck-nvidia-s-design-lab-of-the-future

36
NVIDIA DGX-1
TRAINED DNN ON
NVIDIA JETSON
Photoreal graphics
Physics
AI
Multi-user VR
ISAAC LAB

37

A massive Deep Learning challenge

39
Autonomous vehicles will modernize the $10
trillion transportation industry — making our
roads safer and our cities more efficient. NVIDIA
DRIVE™ PX is a scalable AI car platform that
spans the entire range of autonomous driving.
Toyota recently joined some 225 companies
around the world that have adopted the NVIDIA
DRIVE PX platform for autonomous vehicles.
They range from car companies and suppliers, to
startups and research organizations.
THE BRAIN OF AI CARS

40
PEGASUS 320 TOPSwww.nvidia.com/drive
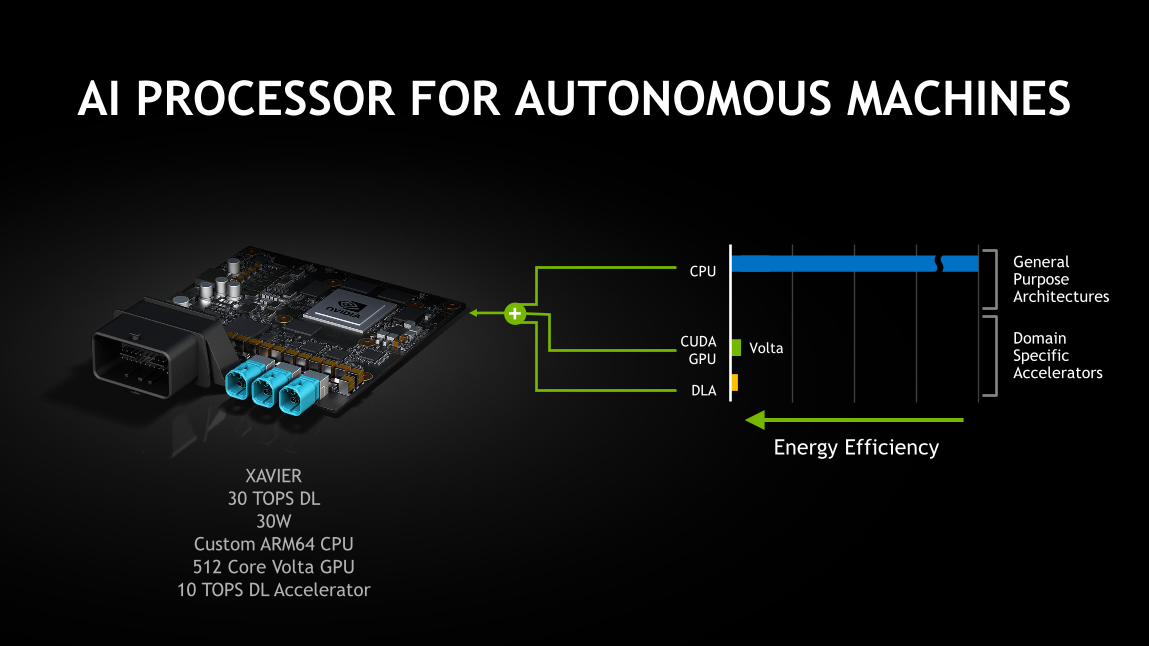
41
AI PROCESSOR FOR AUTONOMOUS MACHINES
XAVIER
30 TOPS DL
30W
Custom ARM64 CPU
512 Core Volta GPU
10 TOPS DL Accelerator
GeneralPurposeArchitectures
DomainSpecificAccelerators
Energy Efficiency
CPU
CUDA
GPU
DLA
Volta
+

42
450+ GPU-ACCELERATED APPLICATIONS
All Top 10 HPC Apps Accelerated
Gaussian
ANSYS Fluent
GROMACS
Simulia Abaqus
NAMD
WRF
VASP
OpenFOAM
LS-DYNA
AMBER
DEFINING THE NEXT GIANT WAVE IN HPC
DGX SATURNV
Fastest AI supercomputer in Top 500
TITECH TSUBAME 3
Japan’s fastest AI supercomputer
Piz Daint
Powered by P100’s sets DL scaling record
EVERY DEEP LEARNING FRAMEWORK ACCELERATED
#1 IN AI & HPC ACCELERATION

43
nvidia.com/gpu-ready-apps

44
SOFTWARE

45
NVIDIA DEEP LEARNING SDK and CUDA
developer.nvidia.com/deep-learning-software
NVIDIA DEEP LEARNING SOFTWARE PLATFORM
TRAINING
Training
Data Management
Model Assessment
Trained NeuralNetwork
TrainingData
INFERENCE
Embedded
Automotive
Data center GRE + TensorRT
DriveWorks SDK
JETPACK SDK

46
• C++ with Python API• builds on the original
Caffe designed from the ground up to take full advantage of the NVIDIA GPU platform
• fast and scalable: multi-GPU and multi-node distributed training
• lightweight and portable: designed for mobile and cloud deployment
http://caffe2.ai/
https://github.com/caffe2/caffe2
http://caffe2.ai/docs/tutorials
https://devblogs.nvidia.com/parallelforall/caffe2-deep-learning-framework-facebook/

47
Circa 2000 - Torch7 - 4th (using odd numbers only 1,3,5,7)
Web-scale learning in speech, image and video applications
Maintained by top researchers including
Soumith Chintala - Research Engineer @ Facebook
All the goodness of Torch7 with an intuitive Python frontend that focuses on rapid
prototyping, readable code & support for a wide variety of deep learning models.
https://devblogs.nvidia.com/parallelforall/recursive-neural-networks-pytorch/http://pytorch.org/tutorials/

Tofu:
Parallelizing
Deep Learning
Systems with
Auto-tiling
Memonger:
Training Deep
Nets with
Sublinear Memory
Cost
MinPy:
High Performance
System with
NumPy Interface
FlexibilityEfficiency Portability
MX NET + Apache https://github.com/dmlc/
https://github.com/NVIDIA/keras
MULTI CORE – MULTI GPU – MULTI NODE
https://devblogs.nvidia.com/parallelforall/scaling-keras-training-multiple-gpus/

49
developer.nvidia.com

May 8-11, 2017 | Silicon Valley
CUDA 9
https://devblogs.nvidia.com/parallelforall/cuda-9-features-revealed/

51NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
NVIDIA DEEP LEARNING SDK UPDATE
GPU-accelerated DL Primitives
Faster training
Optimizations for RNNs
Leading frameworks support
cuDNN 7
Multi-node distributed training (multiple machines)
Leading frameworks support
Multi-GPU & Multi-node
NCCL 2
TensorFlow model reader
Object detection
INT8 RNNs support
High-performanceInference Engine
TensorRT 3

52
NVIDIA Collective CommunicationsLibrary (NCCL)Multi-GPU and multi-node collective communication primitives
High-performance multi-GPU and multi-node collective communication primitives optimized for NVIDIA GPUs
Fast routines for multi-GPU multi-node acceleration that maximizes inter-GPU bandwidth utilization
Easy to integrate and MPI compatible. Uses automatic topology detection to scale HPC and deep learning applications over PCIe and NVink
Accelerates leading deep learning frameworks such as Caffe2, Microsoft Cognitive Toolkit, MXNet, PyTorch and more
Multi-Node:
InfiniBand verbs
IP Sockets
Multi-GPU:
NVLink
PCIe
Automatic
Topology
Detection
github.com/NVIDIA/ncclhttps://developer.nvidia.com/nccl

53
GRAPH ANALYTICS with NVGRAPHdeveloper.nvidia.com/nvgraph
GPU Optimized Algorithms
Reduced cost & Increased performance
Standard formats and primitives
Semi-rings, load-balancing
Performance Constantly Improving

54
WHAT’S NEW IN DIGITS 6?
TENSORFLOW SUPPORT NEW PRE-TRAINED MODELS
Train TensorFlow Models Interactively with DIGITS
Image Classification: VGG-16, ResNet50Object Detection: DetectNet
DIGITS 6 Release Candidate available now on Docker Hub for testing and feedback
General availability in September

55
WHAT’S NEW IN DEEP LEARNING SOFTWARE
TensorRT
Deep Learning Inference Engine
DeepStream SDK
Deep Learning for Video Analytics
36x faster inference enablesubiquitous AND responsive AI
High performance video analytics on Tesla platforms
https://devblogs.nvidia.com/parallelforall/deploying-deep-learning-nvidia-tensorrt/

56
HARDWARE

57
SINGLE UNIVERSAL GPU FOR ALL ACCELERATED WORKLOADS
10M Users 40 years of video/day
270M Items sold/day43% on mobile devices
V100 UNIVERSAL GPU
BOOSTS ALL ACCELERATED WORKLOADS
HPC AI Training AI Inference Virtual Desktop
1.5XVs P100
3XVs P100
3XVs P100
2XVs M60

58
VOLTA: A GIANT LEAP FOR DEEP LEARNING
P100 V100 P100 V100
Images
per
Second
Images
per
Second
2.4x faster 3.7x faster
FP32 Tensor Cores FP16 Tensor Cores
V100 measured on pre-production hardware.
ResNet-50 Training ResNet-50 Inference
TensorRT - 7ms Latency

59
NEW TENSOR CORENew CUDA TensorOp instructions & data formats
4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]
Optimized for deep learning
Activation Inputs Weights Inputs Output Results

60
NEW TENSOR CORENew CUDA TensorOp instructions & data formats
4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]
Optimized for deep learning
Activation Inputs Weights Inputs Output Results

61

62
NVIDIA ® DGX-1™
Containerized Applications
TF Tuned SW
NVIDIA Docker
CNTK Tuned SW
NVIDIA Docker
Caffe2 Tuned SW
NVIDIA Docker
Pytorch Tuned SW
NVIDIA Docker
CUDA RTCUDA RTCUDA RTCUDA RT
Linux Kernel + CUDA Driver
Tuned SW
NVIDIA Docker
CUDA RT
Other
Frameworks
and Apps. . .
THE POWER TO RUN MULTIPLE FRAMEWORKS AT ONCE
Container Images portable across new driver versions

63
Productivity That Follows You From Desk to Data Center to Cloud
Access popular deep learning
frameworks, NVIDIA-optimized
for maximum performance
DGX containers enable easier
experimentation and
keep base OS clean
Develop on DGX Station, scale on
DGX-1 or the NVIDIA Cloud
63
EFFORTLESS PRODUCTIVITY

64
Registry of
Containers, Datasets,
and Pre-trained models
NVIDIA
GPU CLOUD
CSPs
ANNOUNCING NVIDIA GPU CLOUD
Containerized in NVDocker | Optimization across the full stackAlways up-to-date | Fully tested and maintained by NVIDIA | In Beta now
GPU-accelerated Cloud Platform Optimized for Deep Learning

65
PULL CONTAINERDEPLOY IMAGESIGN UP
THREE STEPS TO DEEP LEARNING WITH NGC
To get an NGC account, go to:
www.nvidia.com/ngcsignup
Pick your desired framework (TensorFlow, PyTorch, MXNet, etc.), and pull the container into your instance
On Amazon EC2, choose a P3 instance and deploy the NVIDIA Volta Deep Learning AMI for NGC

GPU DEEP LEARNING IS A NEW COMPUTING MODEL
DGX-1
Training Inference in the Datacenter
Tesla
Inference at the Edge
Jetson

WHY AI AT THE EDGE MATTERS
LATENCYBANDWIDTH AVAILABILITY
1 billion cameras WW (2020)
10’s of petabytes per day
30 images per second
200ms latency
50% of populated world < 8mbps
Bulk of uninhabited world no 3G+
PRIVACY
Confidentiality
Private cloud or on-premise storage
PRIVACY

Max-Q operating mode (< 7.5 watts) delivers up to 2x energy efficiency vs. Jetson TX1 maximum performance Max- P operating mode (< 15 watts) delivers up to 2x performance vs. Jetson TX1 maximum performance
JETSON TX2
EMBEDDED AI
SUPERCOMPUTER
Advanced AI at the edge
JetPack SDK
< 7.5 watts full module
Up to 2X performance or 2X energy efficiency

Jetson TX1 Developer Kit reduced to €549/£459 – Jetson TX1/TX2 Developer kits have same price for education
JETSON TX2DEVELOPER KIT
€649/£544 Web or retail
€350/£300 education

70
Available to Instructors Now! developer.nvidia.com/teaching-kits
Robotics Teaching Kit with ‘Jet’ - ServoCity
D E E P L E A R N I N G

71
Sample Code
Deep Learning
CUDA, Linux4Tegra, ROS
Multimedia API
MediaComputer Vision Graphics
Nsight Developer Tools
Jetson Embedded Supercomputer: Advanced GPU, 64-bit CPU, Video CODEC, VIC, ISP
JETPACK SDK FOR AI @ THE EDGE
TensorRT
cuDNN
VisionWorks
OpenCV
Vulkan
OpenGL
libargus
Video API

72
Develop and deploy
Jetson TX1 and Jetson TX1 Developer Kit

73
Wrap Up

74
Training organizations and individuals to solve challenging problems using Deep Learning
On-site workshops and online courses presented by certified experts
Covering complete workflows for proven application use casesImage classification, object detection, natural language processing, recommendation systems, and more
www.nvidia.com/dli
Hands-on Training for Data Scientists and Software Engineers
NVIDIA Deep Learning Institute

75

76

77
NVIDIAINCEPTION PROGRAMAccelerates AI startups with a boost of
GPU tools, tech and deep learning expertise
Startup Qualifications
Driving advances in the field of AI
Business plan
Incorporated
Web presence
Technology
DL startup kit*
Pascal Titan X
Deep Learning Institute (DLI) credit
Connect with a DL tech expert
DGX-1 ISV discount*
Software release notification
Live webinar and office hours
*By application
Marketing
Inclusion in NVIDIA marketing efforts
GPU Technology Conference (GTC) discount
Emerging Company Summit (ECS) participation+
Marketing kit
One-page story template
eBook template
Inception web badge and banners
Social promotion request form
Event opportunities list
Promotion at industry events
GPU ventures+
+By invitation
www.nvidia.com/inception

COME DO YOUR LIFE’S WORKJOIN NVIDIA
We are looking for great people at all levels to help us accelerate the next wave of AI-driven
computing in Research, Engineering, and Sales and Marketing.
Our work opens up new universes to explore, enables amazing creativity and discovery, and
powers what were once science fiction inventions like artificial intelligence and autonomous
cars.
Check out our career opportunities:
• www.nvidia.com/careers
• Reach out to your NVIDIA social network or NVIDIA recruiter at