alexandra johnson, software engineer, sigopt, at mlconf nyc 2017
TRANSCRIPT

Common Problems in Hyperparameter Optimization
Alexandra Johnson@alexandraj777

What are Hyperparameters?
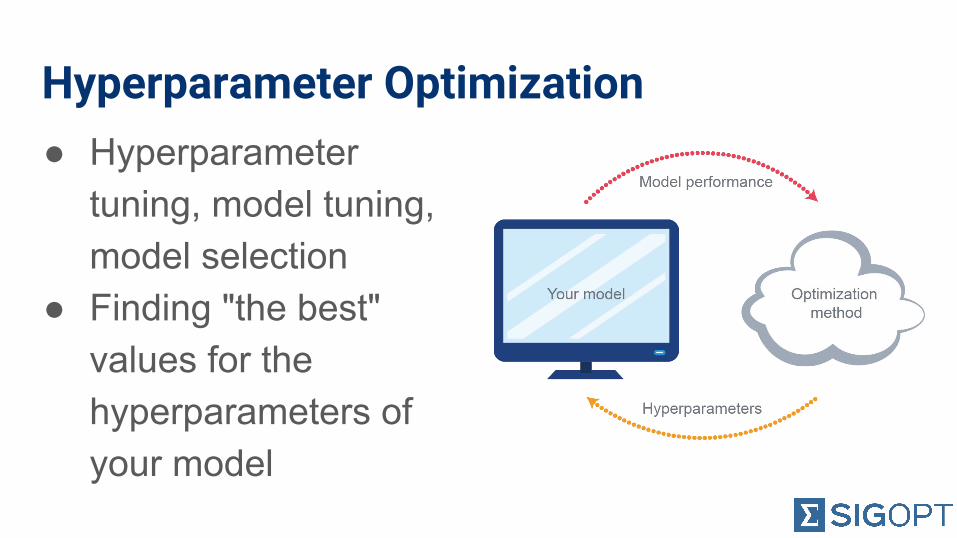
Hyperparameter Optimization● Hyperparameter
tuning, model tuning, model selection
● Finding "the best" values for the hyperparameters of your model

Better Performance● +315% accuracy boost for TensorFlow● +49% accuracy boost for xgboost● -41% error reduction for recommender system

#1 Trusting the Defaults

● Default values are an implicit choice● Defaults not always appropriate for your model● You may build a classifier that looks like this:
Default Values

#2 Using the Wrong Metric
Choosing a Metric● Balance long-term
and short-term goals● Question underlying
assumptions● Example from
Microsoft
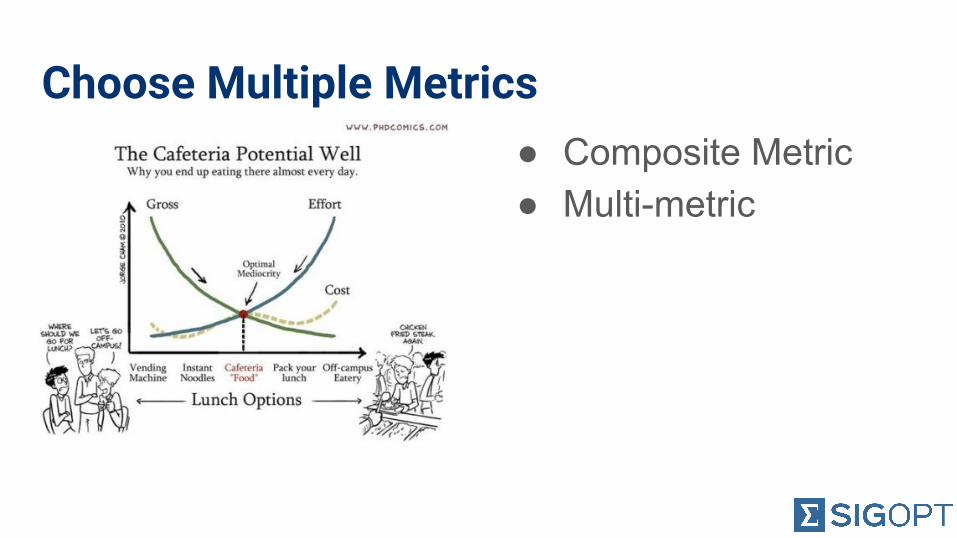
Choose Multiple Metrics● ● Composite Metric
● Multi-metric

#3 Overfitting

Metric Generalization● Cross validation● Backtesting
● Regularization terms
Metric Generalization● Cross validation● Backtesting
● Regularization terms
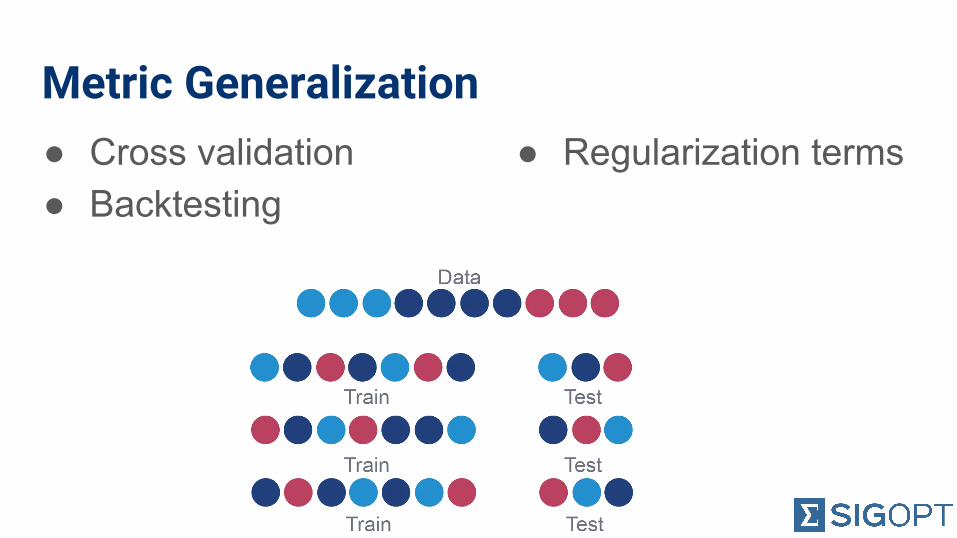
Metric Generalization● Cross validation● Backtesting
● Regularization terms

#4 Too Few Hyperparameters

Optimize all Parameters at Once

Include Feature Parameters
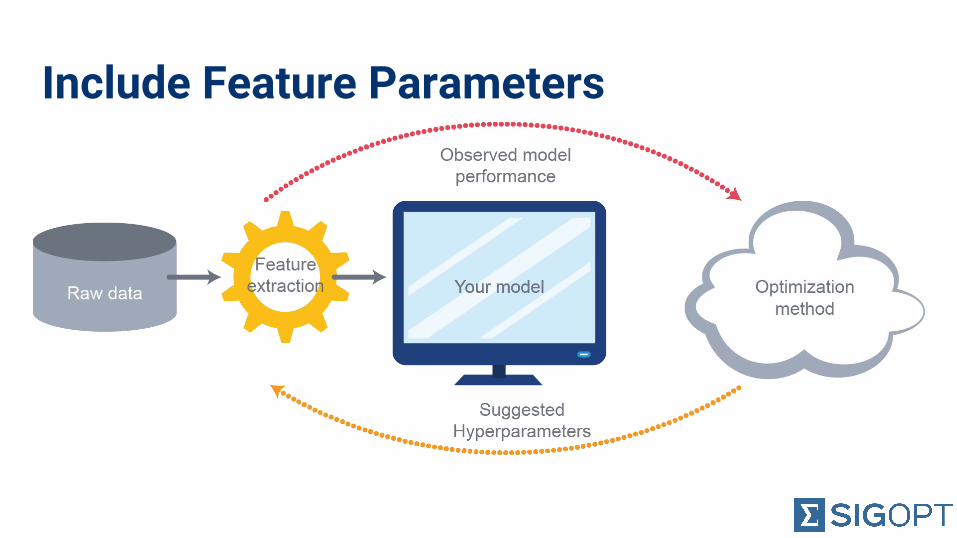
Include Feature Parameters

Example: xgboost● Optimized model
always performed better with tuned feature parameters
● No matter which optimization method

#5 Hand Tuning
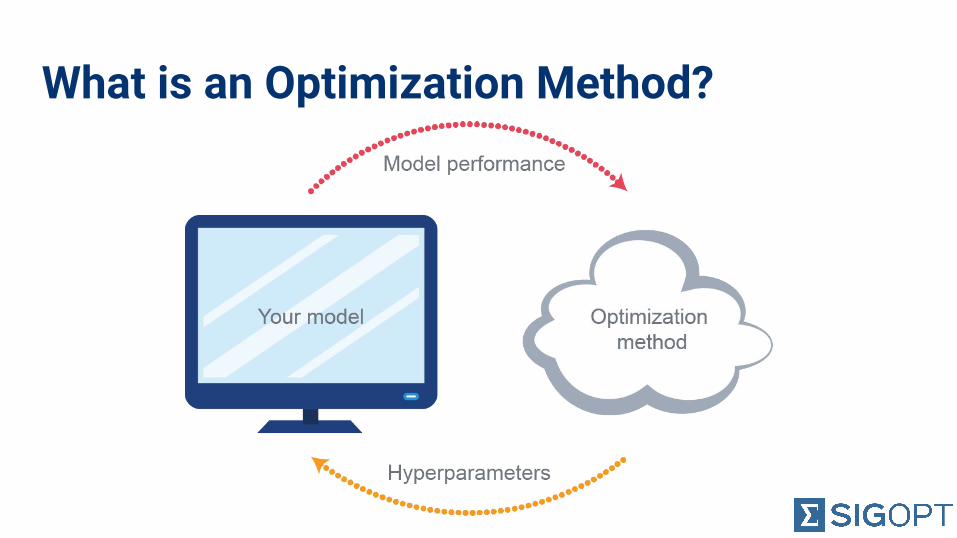
What is an Optimization Method?

You are not an Optimization Method● Hand tuning is time
consuming and expensive
● Algorithms can quickly and cheaply beat expert tuning

Grid Search Random Search Bayesian Optimization
Use an Algorithm

#6 Grid Search
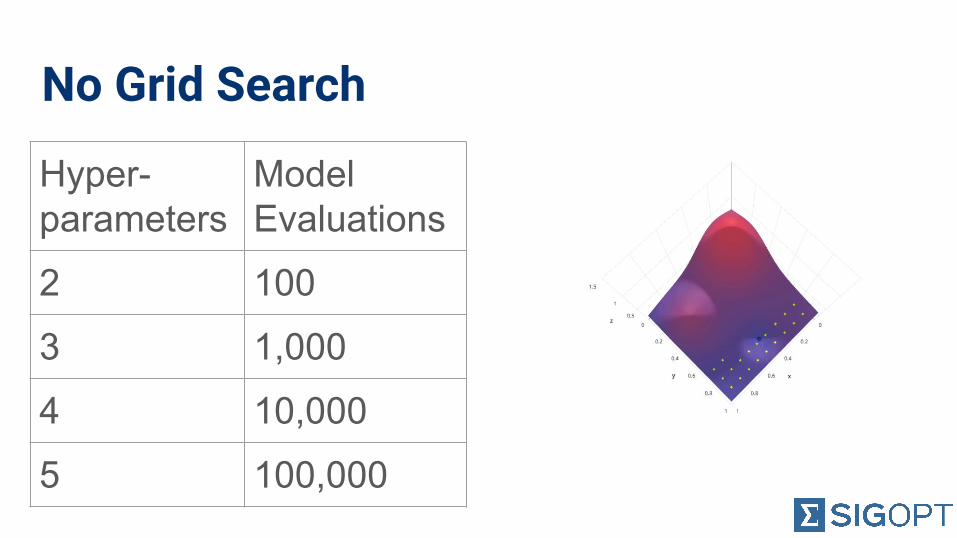
No Grid Search
Hyper-parameters
Model Evaluations
2 100
3 1,000
4 10,000
5 100,000

#7 Random Search
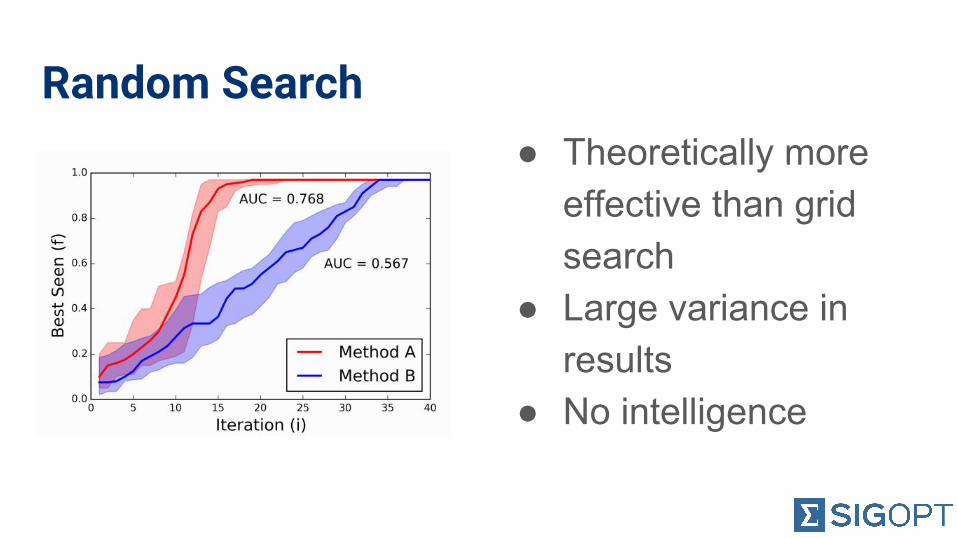
Random Search● Theoretically more
effective than grid search
● Large variance in results
● No intelligence

Use an Intelligent MethodGenetic algorithms
Bayesian optimizationParticle-based methods
Convex optimizersSimulated annealing
To name a few...
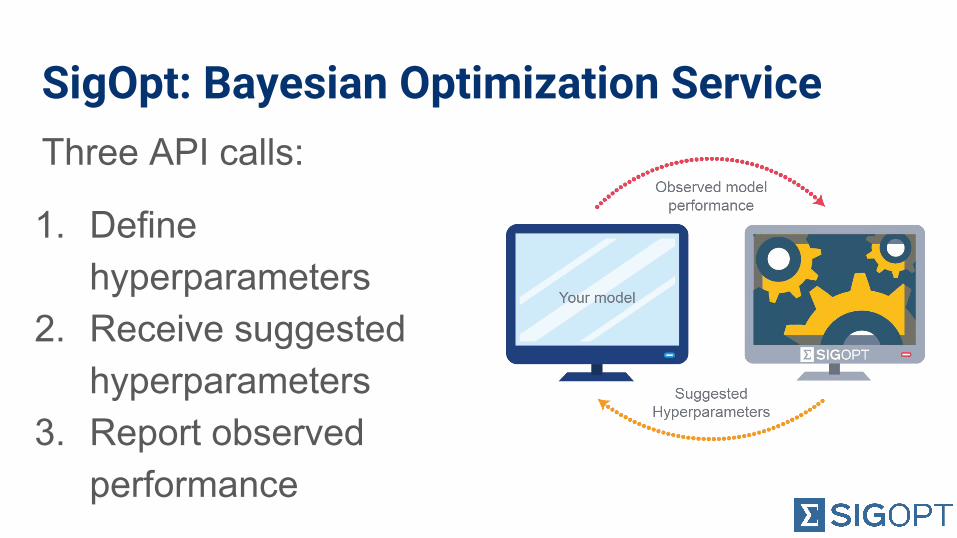
SigOpt: Bayesian Optimization ServiceThree API calls:
1. Define hyperparameters
2. Receive suggested hyperparameters
3. Report observed performance

Thank You!

IntroIan Dewancker. SigOpt for ML: TensorFlow ConvNets on a Budget with Bayesian Optimization.Ian Dewancker. SigOpt for ML: Unsupervised Learning with Even Less Supervision Using Bayesian Optimization.Ian Dewancker. SigOpt for ML : Bayesian Optimization for Collaborative Filtering with MLlib.#1 Trusting the DefaultsKeras recurrent layers documentation#2 Using the Wrong MetricRon Kohavi et al. Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained. Xavier Amatriain. 10 Lessons Learning from building ML systems [Video at 19:03]. Image from PhD Comics.See also: SigOpt in Depth: Intro to Multicriteria Optimization.#4 Too Few HyperparametersImage from TensorFlow Playground.Ian Dewancker. SigOpt for ML: Unsupervised Learning with Even Less Supervision Using Bayesian Optimization.#5 Hand TuningOn algorithms beating experts: Scott Clark, Ian Dewancker, and Sathish Nagappan. Deep Neural Network Optimization with SigOpt and Nervana Cloud.#6 Grid SearchNoGridSearch.com
References - by Section

References - by Section#7 Random SearchJames Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. Ian Dewancker, Michael McCourt, Scott Clark, Patrick Hayes, Alexandra Johnson, George Ke. A Stratified Analysis of Bayesian Optimization Methods. Learn Moreblog.sigopt.comsigopt.com/research