advances on artificial intelligence, · advances on artificial intelligence, knowledge engineering...
TRANSCRIPT


ADVANCES on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES
Proceedings of the 7th WSEAS International Conference on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08)
University of Cambridge, Cambridge, UK, February 20-22, 2008
Artificial Intelligence Series A Series of Reference Books and Textbooks
Published by WSEAS Press www.wseas.org
ISBN: 978-960-6766-41-1
ISSN: 1790-5109

ADVANCES on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES
Proceedings of the 7th WSEAS International Conference on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08)
University of Cambridge, Cambridge, UK, February 20-22, 2008 Artificial Intelligence Series A Series of Reference Books and Textbooks Published by WSEAS Press www.wseas.org Copyright © 2008, by WSEAS Press All the copyright of the present book belongs to the World Scientific and Engineering Academy and Society Press. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the Editor of World Scientific and Engineering Academy and Society Press. All papers of the present volume were peer reviewed by two independent reviewers. Acceptance was granted when both reviewers' recommendations were positive. See also: http://www.worldses.org/review/index.html
ISBN: 978-960-6766-41-1 ISSN: 1790-5109
World Scientific and Engineering Academy and Society

ADVANCES on ARTIFICIAL INTELLIGENCE,
KNOWLEDGE ENGINEERING and DATA BASES
Proceedings of the 7th WSEAS International Conference on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08)
University of Cambridge, Cambridge, UK, February 20-22, 2008
Honorary Editors:
Lotfi A. Zadeh, University of Berkeley, USA
Janusz Kacprzyk, International Fuzzy Systems Association, Poland
Editors:
Leonid Kazovsky, Stanford University, USA
Pierre Borne, Ecole Centrale de Lille, France
Nikos Mastorakis, Military Institutes of University Education, HNA, Greece
Angel Kuri-Morales, Instituto Tecnologico Autonomo de Mexico, Mexico
Ioannis Sakellaris, National Technical University of Athens, Greece

TABLE OF CONTENTS
Plenary Lecture I: Toward Human-Level Machine Intelligence 15Lotfi A. Zadeh Plenary Lecture II: Decision support systems, human centric/centered computing, and computing with words: a synergistic combination?
17
Janusz Kacprzyk Plenary Lecture III: Clustering with an N-Dimensional Extension of Gielis Superformula
18
Angel Kuri-Morales Plenary Lecture IV: Data Mining through Data Visualisation: Computational Intelligence Approaches
19
Colin Fyfe Plenary Lecture V: Formalisation and Verification in a Type-theoretic Framework
20
Zhaohui Luo Plenary Lecture VI: Probability Measures of Fuzzy Events and Linguistic Fuzzy Modelling - Forms Expressing Randomness and Imprecision
21
Anna Walaszek-Babiszewska PART I: ARTIFICIAL INTELLIGENCE Evaluating approximations generated by the GNG3D method for mesh simplification
25
Pedro Navarro, Leandro Tortosa, Antonio Zamora, Jose F. Vicent Dirichlet process mixture models for finding shared structure between two related data sets
31
Gayle Leen,Colin Fyfe Automatic Extraction of Important Sentences from Story Based on Connecting Patterns of Propositions
41
Hideji Enokizu, Satoshi Murakami, Moriaki Kumasaka, Kazuhiro Uenosono, Seiichi Komiya Proposed Framework to Manage Cognitive Load in Computer Program Learning
50
Muhammed Yousoof , Mohd Sapiyan , K.Ramasmy A hybrid GA & Back Propagation Approach for gene selection and classification of microarray data
56
Omid Khayat, Hamid Reza Shahdoosti, Ahmad Jaberi Motlagh

Identifying Psycho-Social Fingerprints in Medical and Engineering Documents
62
Mateja Verlic, Gregor Stiglic, Peter Kokol Application and comparison of several artificial neural networks for forecasting the Hellenic daily electricity demand load
67
L. Ekonomou, D.S. Oikonomou Huge scale feature selection using GA with special fitness function 72Omid Khayat, Hamid Reza Shahdoosti, Ahmad Jaberi Motlagh Computer Recognition of Aesthetics in a Zero-sum Perfect Information Game
78
Azlan Iqbal, Mashkuri Yaacob Framework for extracting rotation invariant features for image classification and an application using haar wavelets Santiago Akle, Maria-Elena Algorri, Marc Zimmermann 89 Case Based Reasoning for Predicting Multi-Period Financial Performances of Technology-based SMEs
95
Tae Hee Moon, So Young Sohn Enhancing the Security of E-Government Portals using Biometric Voice along with a Traditional Password
101
Khalid T. Al-Sarayreh, Rafa E. Al-Qutaish An overview on Model-Based approaches in face recognition 109Omid Khayat, Hamid Reza Shahdoosti, Ahmad Jaberi Motlagh Artificial Societies: a new paradigm for complex systems modelling 116Monica Dascalu, Eduard Franti, Gheorghe Stefan, Lucian Milea Characteristics Analysis for Small Data Set Learning and the Comparison of Classification Methods
122
Fengming M. Chang Modeling Production with Artificial Societies: the Emergence of Social Structure
128
Monica Dascalu, Eduard Franti, Gheorghe Stefan, Lucian Milea An All Closed Set Finding Algorithm for Data Mining 135Rein Kuusik, Grete Lind Strategies for advancing the status of women scientists and engineers in Korea
142
JongHa Lee, SoYoung Sohn

Routing Framework for FTIMA – A Fault Tolerance Infrastructure for Mobile Agents
148
Kiran Ijaz, Umar Manzoor, Arshad Ali Shahid Optimizing Bandwidth Usage and Supporting Block Level Synchronizing in MultiSync – A MultiAgent System for Ubiquitous File Synchronization
154
Umar Manzoor, Kiran Ijaz Using Genetic Programming & Neural Networks for learner evaluation 160John Vrettaros, John Pavlopoulos, George Vouros, Athanasios S. Drigas State Space Optimization Using Plan Recognition and Reinforcement Learning on RTS Game
165
Jaeyong Lee, Bonjung Koo and Kyungwhan Oh A multi-agent Cooperative Model for Crisis Management System 170Abeer El-Korany Khaled El-Bahnasy Topology perserving mappings using cross entropy adaptation 176Ying Wu and Colin Fyfe Customer Pattern Search for A/S Association in Manufacturing 182Jin Sook Ahn, So Young Sohn Comparative analysis of classical and fuzzy PI algorithms 189Jenica Ileana Corcau, Eleonor Stoenescu, Mihai Lungu Stable Relief in feature weighting 193Omid Khayat, Hamid Reza Shahdoosti, Mohammad Hosein Khosravi Image classification using Principal Feature Analysis 198Omid Khayat, Hamid Reza Shahdoosti, Mohammad Hosein Khosravi PART II: Computational Intelligence 205 Probability measures of fuzzy events and linguistic fuzzy modelling - forms expressing randomness and imprecision
207
Anna Walaszek-Babiszewska Association-Based Image Retrieval for Automatic Target Recognition 214Arun Kulkarni, Harikrisha Gunturu, And Srikant Datla A Model Constructed Based on Multi-Criteria Decision Making With Incomplete Linguistic Preference Relations
220
Tien-Chin Wang,Shu-Chen Hsu Feature Selection Strategies for Poorly Correlated Data: Correlation Coefficient Considered Harmful
226
Silang Luo, David Corne

Position control of a robotic manipulator using neural network and a simple vision system
232
Bach H. Dinh, Matthew W. Dunnigan, Donald S. Reay Clustering with alternative similarity functions 238Wesam Barbakh and Colin Fyfe Optimization of Mine Machine Modes of Operation on the Basis of Fuzzy Logic Technology
245
E.S. Balbino, P.I. Ekel Predicting admission counseling triumph of colleges using neural networks
250
Priti Puri, Maitrei Kohli Application of the Self Organizing Maps for Visual Reinforcement Learning of Mobile Robot
257
Hiroshi Dozono, Ryouhei Fujiwara and Takeshi Takahashi Successful joint venture strategies based on data mining 263Jin Hyung Kim, So Young Sohn Robust decision making using Data Envelopment Analytic Hierarchy Process
269
Subramanian Nachiappan and Ramakrishnan Ramanathan Artificial Societies Simulator 276Monica Dascalu, Eduard Franti, Gheorghe Stefan, Lucian Milea, Marius Stoian Using Fuzzy Multiple Criterion Methods for Fourth Party Logistics Criteria Selection
282
Jao-Hong Cheng, Shiuann-Shuoh Chen, Yu-Wei Chuang Relative Distance Identification in “Smart Dust” Networks for Environmental Modelling
289
Graham Rollings, David Corne Simulator for Production Modeling - Virtual Experiments 295Monica Dascalu, Eduard Franti, Lucian Milea, Marius Stoian, Gabriel Sebe An Alternative Approach for Computing the Union and Intersection of Fuzzy Sets: A Basis for Design of Robust Fuzzy Controllers
301
Vincent O. S. Olunloyo, Abayomi M. Ajofoyinbo, Adedeji B. Badiru Image to Sound Transforms and Sound to Image Visualizations based on the Chromaticism of Music
309
Dionysios Politis, Dimitrios Margounakis, Michail Karatsoris Predicting the Success of B2B E-commerce in Small and Medium Enterprises: Based on Consistent Fuzzy Preference Relation
318
Wang Tien-Chin, Lin Ying-Ling

Tabu-based Evolutionary Algorithm with Negative Selection for Pareto optimization in Distributed Systems
327
Jerzy Balicki Implementation of an Autonomous Tracking System for UGVs using FPGAs
333
Akhtar Nawaz, Muhammad Ali, Tipu Qureshi Applying Incomplete Preference Linguistic Relations to Criteria for Evaluating Multimedia Authoring System
338
Tien-Chin Wang, Ying-Hsiu Chen, Yu-Chen Chiang Clustering with an N-Dimensional Extension of Gielis Superformula 343Angel Kuri Morales, Edwin Aldana Bobadilla Investigating methods for improving Bagged k-NN classifiers 351Fuad M. Alkoot A Fuzzy Logic Based Hierarchical Driver Aid for Parallel Parking 357Tarik Ozkul, Muhammed Mukbil, Suheyl Al-Dafri PART III: Knowledge Engineering 363 Peer to Peer Model for Virtual Knowledge Communities 365Pierre Maret, Julien Subercaze, Jacques Calmet Global Model For Rapid And Easy Learning 2007 – 2020 371Vinko Viducic A new method for computer aided detection of pulmonary nodules in X-ray CT images
379
Noriyasu Homma, Kazunori Takei, Tadashi Ishibashi Minimal Representation of Type-Hierarchies 385Richard Elling Moe Generating the Translation Equivalent of Agentive Nouns Using Two-Level Morphology
392
Arbana Kadriu, Lejla Abazi Blending e-Learning and Knowledge Management for Optimizing Learning Paths
396
Dumitru Dan Burdescu, Marian Cristian Mihaescu Social networks, collaboration and groupware software for the scientific research process in the web 2.0 world
403
Serena Pastore

Coordination Mechanism for Optimized Provision os Services in an Area 409Yuki Mori, Fumiko Harada, Hiromitsu Shimakawa Structuring Technological Information for Technology Roadmapping: Data Mining Approach
417
Byungun Yoon, Robert Phaal, David Probert Knowledge organization with pattern recognition in an auto-adaptive system
423
Camille Havas, Othalia Larue, Mickael Camus Aspects Regarding the Use of Sec-Ded Codes to the Cache Level of A Memory Hierarchy
430
Ovidiu Novac, Mircea Vladutiu, Stefan Vari-Kakas, Francisc Ioan Hathhayi, Mihaela Novac The impact of independent model formation on model-based service interoperability
434
Teun Hendriks CKBLS: An Interactive System for Collaborative Knowledge Building and Learning
442
Kathiravelu Ganeshan Productivity Improvement of manufacturing SMEs via Technology Innovation in Korea
448
Min Kyun Doo, So Young Sohn Efficient Determination of the Sequence of Attributes of an N-attributed Database for Obtaining an Optimal Tree Representation
454
Ranjeet Kumar, Preetham Kumar, Ananthanarayana V S IRQAS: Information Retrieval and Question Answering System Based on A Unified Logical-Linguistic Model
460
Tengku M. Sembok, Halimah Badioze Zaman, Rabiah Abdul Kadir An Image Based Interactive Digital Library of Mechanical Engineering Objects
465
Muhammad Abuzar Fahiem, Saadia Jehangir Early Fault Detection using A Novel Spectrum Enhancement Method for Motor Current Signature Analysis
470
Niaoqing Hu, Yue Zhang, Fengshou Gu, Guojun Qin, Andrew Ball Classifier Based Text Mining for Radial Basis Function 476Govindarajan M, Chandrasekaran RM

Appraisal of Course Learning Outcomes using Rasch Measurement: A Case Study in Information Technology Education
482
Azlinah Mohamed, Azrilah Abd Aziz , Sohaimi Zakaria & Mohdsaidfudin Masodi Minimization of OR-XNOR Expressions Using Four New Linking Rules 489Khalid. Faraj Adaptive Filtering of Heart Rate Variation Signal Based on an Efficient Model
495
S. Seyedtabaii & R. Seyedtabaii Distributed Mining of Censored Production Rules in Data Streams: An Evolutionary Approach
500
Saroj, K. K. Bharadwaj PART IV: Data Bases 507 Extracting data from virtual data warehouses – a practical aproach of how to improve query performance
509
Adela Bara, Ion Lungu, Manole Velicanu, Vlad Diaconita, Iuliana Botha Mining Infrequent and Interesting Rules from Transaction Records 515Alex Tze Hiang Sim, Maria Indrawan, Bala Srinivasan Towards a Network – Oriented System for Cooperative Music Composition
521
Dimitrios Margounakis, Dionysios Politis, Panagiotis Linardis The Romanian Universities in the Process of Data and Information System Integration
527
Ana Ramona Lupu, Razvan Bologa, Gheorghe Sabau, Mihaela Muntean Portal oriented integration in public institutions 532Diaconita Vlad, Botha Iuliana, Bara Adela, Lungu Ion, Velicanu Manole Complete Algorithm for fragmentation in Data warehouse 537Ziyati Elhoussaine, Driss Aboutajdine, El Qadi Abderrahim Mathematical model for storing and effective processing of directed graphs in semistructured data management systems
541
Andrei Malikov,Yury Gulevsky, Dmitry Parkhomenko Business Intelligence Solutions For Gaining Competitive Advantage 549Mihaela Muntean, Gabriela Mircea

A web based geoenvironmental data exchange information system 553Charalampos Stergiopoulos, Panagiotis Tsiakas, Dimos Triantis, Filippos Vallianatos Evaluating Business Intelligence Platforms: a case study 558Carlo dell’Aquila, Francesco Di Tria, Ezio Lefons, and Filippo Tangorra Holistic Approach for Classifying and Retrieving Personal Arabic Handwritten Documents
565
Salama Brook and Zaher Al Aghbari Web programing for conference and electronic publication management 571Cioca Marius, Cioca Lucian-Ionel, Cioranu Cosmin Cluster analysis and Association analysis for the same data 576Huaiguo Fu

Enhancing the Security of E-Government Portals using Biometric Voice along with a Traditional Password
KHALID T. AL-SARAYREH AND RAFA E. AL-QUTAISH
Faculty of Information Technology Applied Science University
Amman 11931 JORDAN
[email protected], [email protected] http://www.rafa-elayyan.net
Abstract: - The security is a very important characteristic for any e-government portal. In this paper, we have introduced a methodology to use the voice as a support security characteristic along with the traditional password. In this way, the security could be increased since the user needs to use his voice beside his password. Therefore, no any unauthorized person can enter the e-government portal even if he gets a password. Key-Words: - Security Systems, E-Government, Biometric Voice, Speaker Verification, Authentication. 1 Introduction Security approaches can be broken down into two approaches: passive and active. Passive approaches are like a shield in that they protect against a clear and present danger such as a hacker attempting to access a computer system, while active approaches are more like prevention via a preemptive strike as in arresting terrorists before they plant a bomb.
All cards, keys, and username/password combinations have a common flaw: anybody can use them. Credit cards can also be easily counterfeited, and even the most sophisticated card can be lost, stolen, or maliciously taken away. The use of PINs and passwords somehow improves the situation, but the fundamental problem with PINs is that they identify a card but not its user. Obtaining both the card and the PIN might be more difficult than obtaining the card alone, but is quite feasible, particularly if the owner of the card is forced to cooperate. Thus, cards, PINs and passwords can hardly provide highly secure solutions. The same flaw applies to the username/password combination: the password really identifies the username, not the actual user! While all of the traditional approaches have their strengths, they also have corresponding weaknesses.
Whereas the requirement for physical access security has existed since time immemorial, computer threats and problems gained prominence during the 1990s due to the explosive growth of Internet, e-commerce and other computer technologies.
From above we found that typing a text password to open a system is not enough to identify
the current user because: 1. Authorized persons give their own passwords to
unauthorized ones. 2. Clever intruders may guise the password of this
system if the given time is enough. 3. Smart programs with intelligence methods that
can find the password in short time are available. 4. This password is used by a group of people.
Security approaches can be broken down into two approaches, that is: 1. Passive (Authentication) Applications, which
contains: Physical access control, Border control systems, and PC/Network access control.
2. Active (Identification) Applications: in which the intruders will find it difficult since there is an ability to record their voice, which will lead to identifying them. Through this paper, we will introduce a
methodology to use the voice as a support security feature to the traditional passwords. In this way, the security could be increased since the user needs to use his voice beside his password. Therefore, no any unauthorized person can enter the e-government portal even if he/she gets the password.
The rest of this paper is organized as follows: Section 2 introduces an overview of the previous work in this topic, section 3 presents an overview of the proposed system, section 4 describes the methods which we used in our system, section 5 gives the details of the theoretical and practical parts of the speaker verification, and section 6 illustrates some testing examples with their results. Finally, section 7 concludes the paper and gives some trends on future works.
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 101ISBN: 978-960-6766-41-1

2 Previous Work: An Overview Voice is a combination of physiological and behavioral biometrics. The features of an individual’s voice are based on the shape and size of the appendages (e.g., vocal tracts, mouth, nasal cavities, and lips) that are used in the synthesis of the sound. These physiological characteristics of human speech are invariant for an individual, but the behavioral part of the speech of a person changes over time due to age, medical conditions (such as a common cold), and emotional state, etc. Voice is also not very distinctive and may not be appropriate for large-scale identification.
Based on the spoken text, there are two types of the biometric voice recognition systems, that is, text dependent and text independent. A text dependent voice recognition system is based on the utterance of a fixed predetermined phrase. A text independent voice recognition system recognizes the speaker independent of what he/she speaks, as we used in our proposed system.
A text-independent system is more difficult to design than a text-dependent system but offers more protection against fraud. The problem with the voice recognition is that speech features are sensitive to a number of factors such as background noise, medical conditions, etc [1]. We solved this problem by adding different voices in different situations (for the same person) to learn the system on the different possibilities of variant voices for the same person.
Furthermore, for the text dependent, Monrose et al. [2] have introduced an algorithm to generate a cryptographic key from a user’s utterance of a password. In addition, Jian and Ross [3] have stated that the NIST in 2002 implemented a text dependent biometric voice system and get 10-20% of false reject rate and 2-5% false accept rate.
3 Overview of the Proposed System A speaker verification system consists of two parts: feature extraction and template based comparison. In the first part, the system records the user’s speech and applies short-term analysis to find the parameters that distinguish the user. These parameters are then recorded as the reference template for any future comparison. The next time, when the user needs to be verified, he speaks the same utterance. Short term analysis is again performed, and the parameters are extracted once more. In order to give access to the user, the new extracted parameters are compared with the previously recorded (reference) parameters. If the similarity between the two parameter sets is above a given threshold, the user is verified. Otherwise, access is denied.
4 Methods Used in the System In this section, the step-by step algorithms used for feature extraction and comparison phases are illustrated. 4.1 End Point Detection Algorithm Steps of the end-point detection algorithm are listed as follows: • Removing the DC part (mean) of the speech
signal, which is considered to be an important step because the zero-crossing rate of the signal is calculated and it plays a role in determining where the unvoiced sections of speech exist. If the DC offset is not removed, we will be unable to find the zero-crossing rate of noise in order to eliminate it from our signal.
• Framing speech signal. • Computing the total zero-crossings number of
each frame such that:
∑=
−−=N
mmkxmkxkZ
1))1(sgn())(sgn()( (1)
Where Z(k) is the average magnitude of the kth frame and sgn(x) is the signum function that finds the sign of x.
• Compute noise statistics (mean & standard deviation) and the maximum of average Magnitude and zero-crossings of the first five frames assuming that the first five frames are inconsiderable parts.
• Find end-points according to the average magnitudes assuming that the average magnitude of the spoken parts is greater than a threshold TA (sum of the mean and standard deviation in our paper) determined by the mean and the standard deviation of the average magnitude of the noisy part. End-points should be in pair such that one of them is the beginning of a specific spoken part and the other one is the end of that part.
• Correct end-points according to the zero-crossings assuming that the zero crossings of spoken parts are smaller than a threshold TZ (sum of the mean and standard deviation in our paper) determined by the mean and the standard deviation of the average magnitude of the noise part. [4] End point detection is applied to all of our speech signals before they are processed.
4.2 Feature Extraction Algorithm In order to compare different users, we need to extract the parameters from the speech signal. These parameters help us to distinguish one user from the others. However, the speech signal must first be divided into frames. The parameters are calculated
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 102ISBN: 978-960-6766-41-1
separately for each frame. For the framing part, we choose to use a hamming window with a window size of 30msec and skip a rate (frame overlap) of 10msec. After each feature extraction algorithm, we get a matrix as a result. The columns of these matrices are the feature vectors for each frame. 4.2.1 Mel-Spectrum Mel-spectrum coefficients are known to model the human ear well, and it is mentioned in the literature few times that the performance of the mel-cepstrum coefficients is better than the performance of other parameters [5]. Mel-cepstrum coefficient extraction is based on the fact that the sensitivity of the human ear varies with frequency. Our ear is more sensitive to low frequency sounds than to high frequency ones. The following steps could be used to compute the extraction of these parameters: • Apply framing to the end detected speech signal. • Then the 512-point Fast Fourier Transform
(FFT) of each frame is applied and the algorithm of the magnitude response is taken. Due to the symmetry property of the FFT, only the first 256 samples (Si) are processed [6].
• The frequency range (0-fs/2 Hz) is divided into uniformly spaced triangular overlapping windows (K windows in total).
• Then the Mel scale is converted back to the linear scale by the following equation:
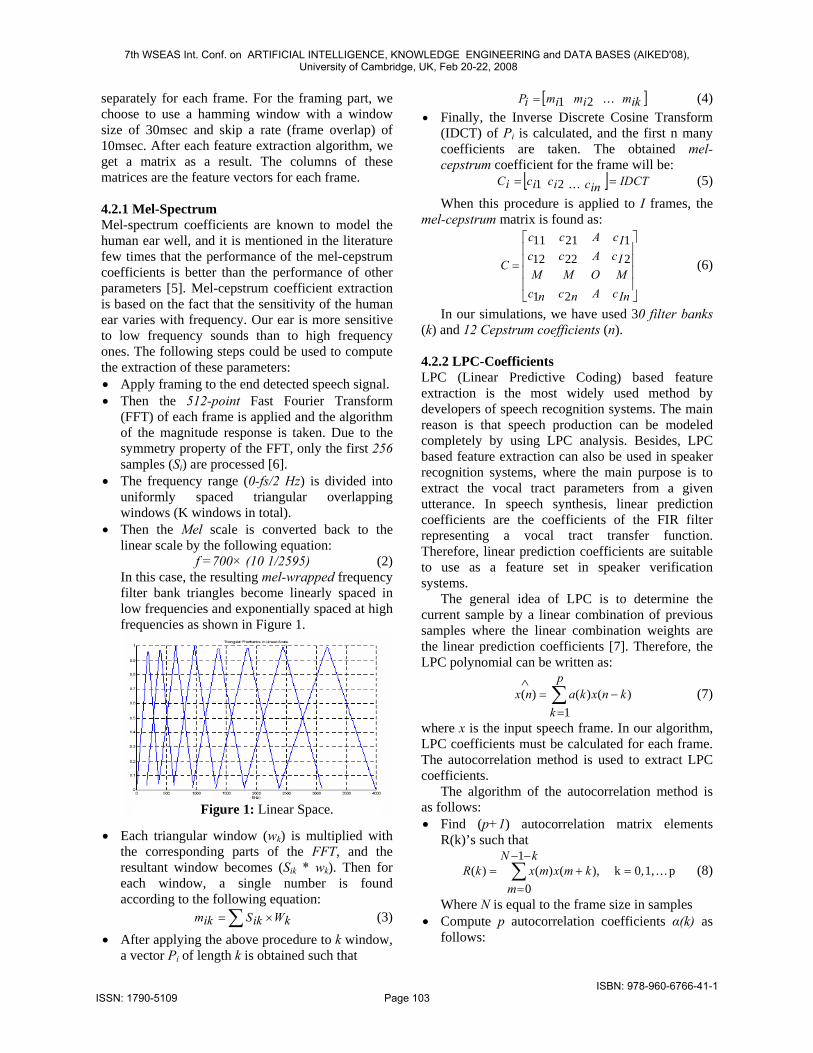
f =700× (10 1/2595) (2) In this case, the resulting mel-wrapped frequency filter bank triangles become linearly spaced in low frequencies and exponentially spaced at high frequencies as shown in Figure 1.
• Each triangular window (wk) is multiplied with the corresponding parts of the FFT, and the resultant window becomes (Sik * wk). Then for each window, a single number is found according to the following equation:
∑ ×= kWikSikm (3) • After applying the above procedure to k window,
a vector Pi of length k is obtained such that
[ ]ikmimimiP . . . 2 1= (4) • Finally, the Inverse Discrete Cosine Transform
(IDCT) of Pi is calculated, and the first n many coefficients are taken. The obtained mel-cepstrum coefficient for the frame will be:
[ ] IDCTinciciciC == . . . 2 1 (5)
When this procedure is applied to I frames, the mel-cepstrum matrix is found as:
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
IncAncncMOMMIcAccIcAcc
C
21
2221212111
(6)
In our simulations, we have used 30 filter banks (k) and 12 Cepstrum coefficients (n). 4.2.2 LPC-Coefficients LPC (Linear Predictive Coding) based feature extraction is the most widely used method by developers of speech recognition systems. The main reason is that speech production can be modeled completely by using LPC analysis. Besides, LPC based feature extraction can also be used in speaker recognition systems, where the main purpose is to extract the vocal tract parameters from a given utterance. In speech synthesis, linear prediction coefficients are the coefficients of the FIR filter representing a vocal tract transfer function. Therefore, linear prediction coefficients are suitable to use as a feature set in speaker verification systems.
The general idea of LPC is to determine the current sample by a linear combination of previous samples where the linear combination weights are the linear prediction coefficients [7]. Therefore, the LPC polynomial can be written as:
∑=
−=∧ p
kknxkanx
1)()()( (7)
where x is the input speech frame. In our algorithm, LPC coefficients must be calculated for each frame. The autocorrelation method is used to extract LPC coefficients.
The algorithm of the autocorrelation method is as follows: • Find (p+1) autocorrelation matrix elements
R(k)’s such that
∑−−
==+=
kN
mkmxmxkR
1
0p . . . 1, 0,k ),()()( (8)
Where N is equal to the frame size in samples • Compute p autocorrelation coefficients α(k) as
follows:
Figure 1: Linear Space.
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 103ISBN: 978-960-6766-41-1

⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡−
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−−
−−
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⇒
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−−
−−
)(...
)1()0(1
)0(...)2()1(............
)2(...)1()1()1(...)1()0(
)(...
)2()1(
)(...
)2()1(
)(...
)2()1(
)0(...)2()1(............
)2(...)1()1()1(...)1()0(
pR
RR
RpRpR
pRRRpRRR
pa
aa
pR
RR
pa
aa
RpRpR
pRRRpRRR
(9)
• Repeat Steps 1 and 2 for each frame of the
utterance. To see the effect of the linear prediction order in
our system, we have used different values for “p”. One of the values has been chosen according to the following formula:
21000
+= sfP (10)
4.3 Feature Comparison After the feature extraction step, the similarity between the parameters derived from the spoken utterance and the reference parameters need to be computed. The three most commonly encountered algorithms in the literature are: Dynamic Time Warping (DTW), Hidden Markov Modelling (HMM) and Vector Quantization (VQ). In our project, we use DTW for comparing the parameter matrices extracted in the previous section. The algorithm is given as follows: • Each column of the parameter matrix is
considered as a point in the vector space. • A Local Distance Matrix (LDM) is defined such
that each element of the matrix is a distance from one point (parameter matrix column) to another. As (wrong use of as, unless you mean as it's here, it's there, so it should be without and) the distance metric one is used for the LPC coefficients, another distance is used for the MFCC and spectral coefficients. If the numbers of columns in the reference and the new parameter matrices are M and N respectively, the LDM becomes an MxN matrix.
• An accumulated distance matrix is computed such that each element of the matrix contains the corresponding LDM matrix element plus the smallest neighboring accumulated distance.
• To calculate the ADM, we start by equating: ADM(1,1) to LDM(1,1)
• The other elements of the ADM are calculated as follows:
ADM (m,n) = LDM(m,n) + min { ADM(m,n-1), ADM(m-1,n-1) ,ADM(m-1,n)}
• When the lower right corner of the matrix is reached, this value shows the Minimum global distance between the two-parameter matrices. If two identical matrices are fed as the input to
this algorithm, the minimum global distance
becomes zero. The output of the DTW algorithm is the minimum global distance value [8]. Small values mean similar parameter matrices, and high values indicate that the two parameter matrices are highly unlikely. 4.4 Decision Making There are usually three approaches to construct the decision rules [9]: • Geometric. • Topological. • Probabilistic rules.
The most popular speech verification models are based on probabilistic rules. 4.5 Decision Function In classical speech verification systems, when no prior information is given on the cost of the different kinds of errors, the Bayes Decision rule is applied by selecting the value of Δi in equation 5 that minimizes the Half Total Error Rate:
HTER = 1/2(%FA +%FR) (11) where %FA is the rate of false acceptances, and %FR is the rate of false rejects. Note that this cost function changes the relative weight of client and impostor accesses in order to give them equal weight, instead of the one induced by the training data.
If the probabilities are perfectly estimated, then the Bayes Decision is the optimal decision. Unfortunately, this is usually not the case. In that case, the Bayes Decision might not be the optimal solution, and we should thus explore other forms of decision rules. In this thesis, we will discuss two sorts of decision rules, which are based either on linear functions or on more complex functions such as Support Vector Machines. 5 Speaker Verification 5.1 Theoretical Part Speaker verification is verifying a user’s identity by his voice, which is assumed to be unique for that person. Even a very secure cryptology system has the chance of being cracked; a unique human voice is very attractive to be used in systems where security should be provided. In the proposed enhanced security system, a text-dependent speaker verification system is implemented by using various
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 104ISBN: 978-960-6766-41-1
feature extraction and feature comparison methods [10].
The feature extraction methods are mel-cepstrum, Linear Prediction (LP) coefficients and fundamental frequency and magnitude. The feature comparison methods are Vector Quantization (VQ) and Dynamic Time Warping (DTW).
5.2 Practical Part 5.2.1 Step 1: Training the System and Build a
Dataset Training the system for the recognition of the speaker
When a speaker attempts to verify himself with this system, his or her incoming signal is compared to that of a "key". This key should be a signal that
produces a high correlation for both magnitude and pitch data (datasets) when the authorized user utters the password, but not in cases where: • the user says the wrong word (the password is
forgotten). • an intruder says either the password or a wrong
word. To develop such a key, the system is trained for
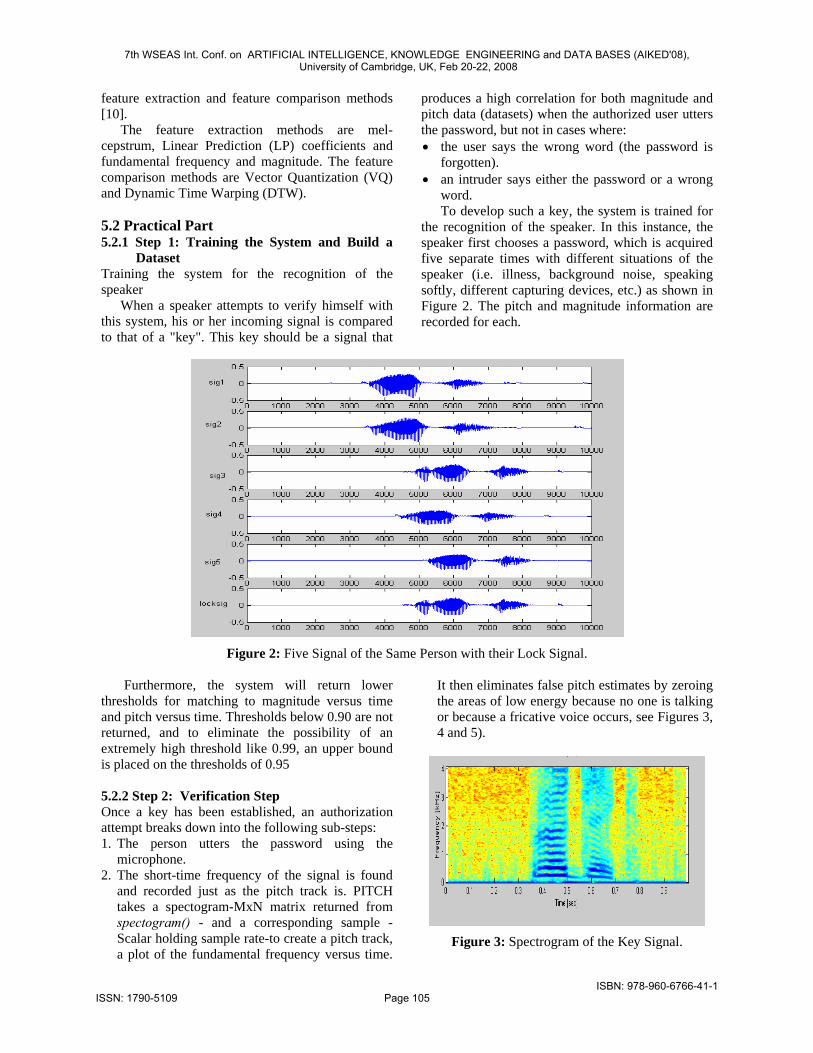
the recognition of the speaker. In this instance, the speaker first chooses a password, which is acquired five separate times with different situations of the speaker (i.e. illness, background noise, speaking softly, different capturing devices, etc.) as shown in Figure 2. The pitch and magnitude information are recorded for each.
Figure 2: Five Signal of the Same Person with their Lock Signal.
Furthermore, the system will return lower
thresholds for matching to magnitude versus time and pitch versus time. Thresholds below 0.90 are not returned, and to eliminate the possibility of an extremely high threshold like 0.99, an upper bound is placed on the thresholds of 0.95
5.2.2 Step 2: Verification Step Once a key has been established, an authorization attempt breaks down into the following sub-steps: 1. The person utters the password using the
microphone. 2. The short-time frequency of the signal is found
and recorded just as the pitch track is. PITCH takes a spectogram-MxN matrix returned from spectogram() - and a corresponding sample -Scalar holding sample rate-to create a pitch track, a plot of the fundamental frequency versus time.
It then eliminates false pitch estimates by zeroing the areas of low energy because no one is talking or because a fricative voice occurs, see Figures 3, 4 and 5).
Figure 3: Spectrogram of the Key Signal.
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 105ISBN: 978-960-6766-41-1
Figure 4: Spectrogram of the New Signal.
Track 1 Track 2
Figure 5: Track signals 3. To prepare for a Dynamic Time Warp (DTW),
see Figures 6: a. Cut the trailing and leading zeros of
track1. b. Cut the trailing and leading zeros of track2.
Track 1 Cut Track 2 Cut
Figure 6: Track Signals after Cutting. c. Perform the Dynamic Time Warping by
mapping track2 onto track1, and calculating the dot product, then map track1 onto track2 and calculate the dot product, and finally,
map track2 onto track1 and calculate the dot product, see Figure 7.
Path2on1 Track2dtw
Figure 7: Path2on1 and Track2dtw.
d. Map Track1 onto Track2 and calculate the dot product, see Figure 8.
Path1on2 Track1dtw
Figure 8: Path1on2 and Track1dtw. 4. The short-time magnitude of the signal is found
and recorded, as is the magnitude. a. Find out where to cut the two signals. b. Find the average magnitude for the two
cutting signals. c. Perform Dynamic Time Warping (DTW)
linking one signal to another in order to let the peaks match up. The time warp is performed both ways (matching sig1 to sig2 and vice versa).
5. These numbers are compared to the thresholds (0.95). If both the magnitude and pitch correlations are above this threshold, the speaker has been verified.
6 Examples and Results We have tested the system by performing the following examples:
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 106ISBN: 978-960-6766-41-1

Example 1: >> speak now Key and results: Pitch0.9996, Magnitude 0.9916
*****MATCH**** Example 2: >> speak now Key and results: Pitch 0.99955, Magnitude 0.98929
*****MATCH**** Example 3: >> speak now Key and results: Pitch 0.94346, Magnitude 0.97949
** NO MATCH** Example 4: >> speak now Key and results: Pitch 0.95588, Magnitude 0.95045
*****MATCH**** Example 5: >> speak now Key and results: Pitch 0.95457, Magnitude 0.82971
**** NO MATCH**** We have repeated this test for two different
persons as keys (as in the above examples) for around 1000 times during the run time of the system. Next are the results of our tests.
Table 1 shows the system capability to distinguish between two different persons as keys (Dr. Khalid and Dr. Rafa).
Table 1: Comparing Ratio.
Dr. Rafa Dr. Khalid Dr. Rafa 67% 17% Dr. Khalid 19% 74.5%
Whereas, Table 2 shows the ratio in which the
system can distinguish an unauthorized (intruder with a password) from the two stored keys (Dr. Khalid and Dr. Rafa).
Table 2: Intruder with Two Keys. Dr. Rafa Dr. Khalid Dr. Rafa and Dr. Khalid (with PWD) 67% 74.5%
Intruder (with PWD) 21% 18.5%
7 Conclusion and Future Work This system was designed to be installed on the server of the e-government portals to connect clients using the voice beside the traditional password. The reason behind this is that most of the financial transactions are done via the portal of e-Government. Using this system, it would not be possible for a person to deny his or her access to the portal as it will authenticate the person and make sure it is the person allowed to access the data.
The training should be done over a period of time to take into account differences in background noise, the speaker's health, microphones, and other various factors. Furthermore, an instantaneous key could be skewed because the user will attempt to sound similar at each training session, which will actually produce dissimilarities.
A composite key could help alleviate this problem by taking the five signals that are used in training and producing an ‘average’ of them in terms of magnitude and fundamental frequency. In addition, the results could be improved over the time if the system took successful attempts and added them to the average key. In this case, the recognition could get better over time without extra training sessions.
The current lower thresholds for matching are set rather high, in a range between 0.90 and 0.95. The reason why the number is set high is to provide the utmost security for your password in the worst case scenario, which is when it is known to the intruder. As seen in the results, intruders without knowledge of the password were never successful in accessing the system. Therefore, it is possible to set the thresholds lower so that the owner's acceptance rates increase while an intruder's acceptance rate remains nominal.
Moreover, a speaker's voice has many other characteristics that make it identifiable to the human ear. Computationally, a system can also try to draw out such unique differences and match those to users as well. For example, formants are a function of a person's vocal tract, so tracking such data could improve further results. As mentioned earlier, using LPC and spectrum techniques may produce more accurate results that increase the rates of acceptance and denial.
Finally, this proposed system can be developed in the future through connecting it to other software programs or through the authentication process, which is done through the iris or the fingerprint. The voice will be widely used in the coming software programs. The system could also be installed on special chips as an embedded system that would work on its own. References: [1] Jain, A. K.; Ross, A. and Prabhakar, S., “An
introduction to biometric recognition”, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 14, No. 1, 2004, pp. 4-20.
[2] Monrose, F.; Reiter, M. K.; Li, Q. and Wetzel, S., “Cryptographic Key Generation from Voice”, in Proceedings of the IEEE Symposium
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 107ISBN: 978-960-6766-41-1

on Security and Privacy - S&P’01, Oakland, CA, USA, May 14-16, 2001, pp. 202-213.
[3] Jian A. K. and Ross, A., “Multibiometric Systems”, Communications of the ACM, Vol. 47, No. 1, 2004, pp. 34-40.
[4] O’Shaughnessy, D., Speech Communications: Human and Machine, the Institute of Electrical and Electronics Engineers, Inc., New York, 2000.
[5] Guo, S. and Liddel, H, “Support Vector Regression and Classification Based Multi-view Detection and Recognition”, in Proceedings of the IEEE International Conference on Automatic Face & Geusture Recognition, 2000, pp.300-305.
[6] Davis, S. B. and Mermelstein P., "Comparison of parametric representations for Monosyllabic word recognition in continuously spoken sentences", IEEE Transactions on Signal Processing, Vol. 28, No. 4., 1980, pp. 357-366.
[7] Xafopoulus, A., “Speaker Verification: an Overview”, Technical Report, Artificial Intelligence & Information Analysis laboratory, Informatics Department, Aristotle Univ. of Thessaloniki, Thessaloniki, Greece, 2001.
[8] Yu, K.; Mason, J. and Oglesby, J., “Speaker Recognition Using Hidden Markov Models, Dynamic Time Warping and Vector Quantization”, in IEE proceedings on Vision, Image and Signal Processing, Vol. 142, No. 5, 1995, pp. 313-318.
[9] Gonzales, Rafael and Woods, Richard, Digital image processing, 2nd edition, Prentice-hall, 2002.
[10] Gold, B. and Morgan, N., Speech and Audio Signal Processing: Processing and Perception of Speech and Music, John Wiley & Sons, Inc., New York, 2000.
7th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING and DATA BASES (AIKED'08), University of Cambridge, UK, Feb 20-22, 2008
ISSN: 1790-5109 Page 108ISBN: 978-960-6766-41-1