adaptive resonance theory...2 adaptive resonance theory ery, self-supervised art, and biased art,...
TRANSCRIPT

A
Adaptive Resonance Theory
Gail A. Carpenter1 and Stephen Grossberg2
1Department of Mathematics & Center forAdaptive Systems, Boston University, Boston,MA, USA2Center for Adaptive Systems, GraduateProgram in Cognitive and Neural Systems,Department of Mathematics, Boston University,Boston, MA, USA
Abstract
Computational models based on cognitive andneural systems are now deeply embedded inthe standard repertoire of machine learningand data mining methods, with intelligentlearning systems enhancing performance innearly every existing application area. Beyonddata mining, this article shows how modelsbased on adaptive resonance theory (ART) mayprovide entirely new questions and practicalsolutions for technological applications. ARTmodels carry out hypothesis testing, search,and incremental fast or slow, self-stabilizinglearning, recognition, and prediction in responseto large nonstationary databases (big data). Threecomputational examples, each based on thedistributed ART neural network, frame questionsand illustrate how a learning system (each withno free parameters) may enhance the analysisof large-scale data. Performance of each task
is simulated on a common mapping platform,a remote sensing dataset called the BostonTestbed, available online along with open-sourcesystem code. Key design elements of ARTmodels and links to software for each systemare included. The article further points to futureapplications for integrative ART-based systemsthat have already been computationally specifiedand simulated. New application directionsinclude autonomous robotics, general-purposemachine vision, audition, speech recognition,language acquisition, eye movement control,visual search, figure-ground separation, invariantobject recognition, social cognition, object andspatial attention, scene understanding, space-time integration, episodic memory, navigation,object tracking, system-level analysis of mentaldisorders, and machine consciousness.
Adaptive Resonance Theory
Adaptive resonance theory (ART) neural net-works model real-time hypothesis testing, search,learning, recognition, and prediction. Since the1980s, these models of human cognitive infor-mation processing have served as computationalengines for a variety of neuromorphic technolo-gies (http://techlab.bu.edu/resources/articles/C5).This article points to a broader range of tech-nology transfers that bring new methods to newproblem domains. It describes applications ofthree specific systems, ART knowledge discov-
© Springer Science+Business Media New York 2016C. Sammut, G.I. Webb (eds.), Encyclopedia of Machine Learning and Data Mining,DOI 10.1007/978-1-4899-7502-7 6-1

2 Adaptive Resonance Theory
ery, self-supervised ART, and biased ART, andsummarizes future application areas for large-scale, brain-based model systems.
ART Design ElementsIn this article, ART refers generally to a theoryof cognitive information processing and to aninclusive family of neural models. Design prin-ciples derived from scientific analyses and designconstraints imposed by targeted applications havejointly guided the development of variants of thebasic systems.
Stable Fast Learning with Distributed andWinner-Take-All CodingART systems permit fast online learning,whereby long-term memories reach theirasymptotes on each input trial. With slowlearning, memories change only slightly on eachtrial. One characteristic that distinguishes classesof ART systems from one another is the nature oftheir patterns of persistent activation at the codingfield F2 (Fig. 1). The coding field is functionallyanalogous to the hidden layer of multilayerperceptrons (Encyclopedia cross reference).At the perceptron hidden layer, activation isdistributed across many nodes, learning needsto be slow, and activation does not persist onceinputs are removed. The ART coding field is acompetitive network where, typically, one or afew nodes in the normalized F2 pattern y sustainpersistent activation, even as their generatinginputs shift, habituate, or vanish. The patterny persists until an active reset signal (Fig. 1c)prepares the coding field to register a new F0-to-F2input. Early ART networks (Carpenter andGrossberg 1987; Carpenter et al. 1991a, 1992)employed localist, or winner-take-all, coding,whereby strongly competitive feedback resultsin only one F2 node staying active until the nextreset. With fast as well as slow learning, memorystability in these early networks relied on theirwinner-take-all architectures.
Achieving stable fast learning with distributedcode representations presents a computationalchallenge to any learning network. In order tomeet this challenge, distributed ART (Carpenter1997) introduced a new network configuration
(Fig. 1) in which system fields are identified withcortical layers (Carpenter 2001). New learninglaws (dInstar and dOutstar) that realize stablefast learning with distributed coding predict adap-tive dynamics between cortical layers.
Distributed ART (dART) systems employ anew unit of long-term memory, which replacesthe traditional multiplicative weight (Encyclo-pedia cross reference) with a dynamic weight(Carpenter 1994). In a path from the F2 codingnode j to the F1 matching node i , the dynamicweight equals the amount by which coding nodeactivation yj exceeds an adaptive threshold j i .The total signal i from F2 to the i th F1 nodeis the sum of these dynamic weights, and F1
node activation xi equals the minimum of the top-down expectation i and the bottom-up input Ai .During dOutstar learning, the top-down pattern converges toward the matched pattern x.
When coding node activation yj is below j i ,the dynamic weight is zero and no learning occursin that path, even if yj is positive. This propertyis critical for stable fast learning with distributedcodes. Although the dInstar and dOutstar laws arecompatible with F2 patterns y that are arbitrarilydistributed, in practice, following an initial learn-ing phase, most changes in paths to and from acoding node j occur only when its activation yjis large. This type of learning is therefore calledquasi-localist. In the special case where coding iswinner-take-all, the dynamic weight is equivalentto a multiplicative weight that formally equals thecomplement of the adaptive threshold.
Complement Coding: Learning Both AbsentFeatures and Present FeaturesART networks employ a preprocessing stepcalled complement coding (Carpenter et al.1991b), which models the nervous system’subiquitous computational design known asopponent processing (Hurvich and Jameson1957). Balancing an entity against its opponent,as in opponent colors such as red vs. green oragonist-antagonist muscle pairs, allows a systemto act upon relative quantities, even as absolutemagnitudes fluctuate unpredictably. In ARTsystems, complement coding is analogous toretinal on-cells and off-cells (Schiller 1982).
Adaptive Resonance Theory 3
A
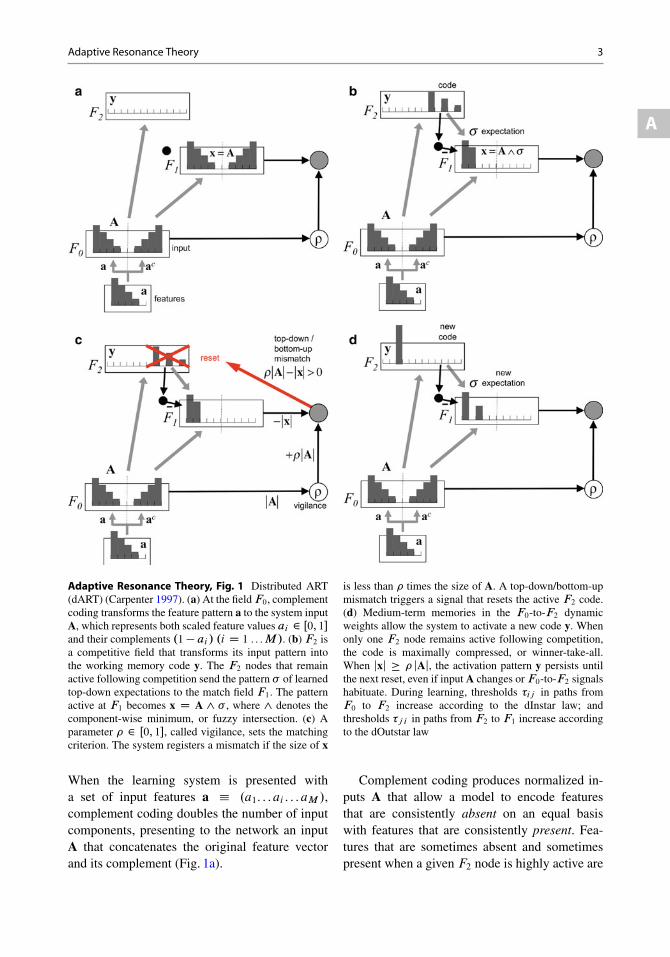
Adaptive Resonance Theory, Fig. 1 Distributed ART(dART) (Carpenter 1997). (a) At the fieldF0, complementcoding transforms the feature pattern a to the system inputA, which represents both scaled feature values ai 2 Œ0; 1and their complements .1 ai / .i D 1 . . .M/. (b) F2 isa competitive field that transforms its input pattern intothe working memory code y. The F2 nodes that remainactive following competition send the pattern of learnedtop-down expectations to the match field F1. The patternactive at F1 becomes x D A ^ , where ^ denotes thecomponent-wise minimum, or fuzzy intersection. (c) Aparameter 2 Œ0; 1, called vigilance, sets the matchingcriterion. The system registers a mismatch if the size of x
is less than times the size of A. A top-down/bottom-upmismatch triggers a signal that resets the active F2 code.(d) Medium-term memories in the F0-to-F2 dynamicweights allow the system to activate a new code y. Whenonly one F2 node remains active following competition,the code is maximally compressed, or winner-take-all.When jxj jAj, the activation pattern y persists untilthe next reset, even if input A changes orF0-to-F2 signalshabituate. During learning, thresholds ij in paths fromF0 to F2 increase according to the dInstar law; andthresholds ji in paths from F2 to F1 increase accordingto the dOutstar law
When the learning system is presented witha set of input features a .a1. . .ai . . .aM /,complement coding doubles the number of inputcomponents, presenting to the network an inputA that concatenates the original feature vectorand its complement (Fig. 1a).
Complement coding produces normalized in-puts A that allow a model to encode featuresthat are consistently absent on an equal basiswith features that are consistently present. Fea-tures that are sometimes absent and sometimespresent when a given F2 node is highly active are

4 Adaptive Resonance Theory
regarded as uninformative with respect to thatnode, and the corresponding present and absenttop-down feature expectations shrink to zero.When a new input activates this node, thesefeatures are suppressed at the match field F1
(Fig. 1b). If the active code then produces anerror signal, attentional biasing can enhance thesalience of input features that it had previouslyignored, as described below.
Matching, Attention, and SearchA neural computation central to both scientificand technological analyses is the ART matchingrule (Carpenter and Grossberg 1987), which con-trols how attention is focused on critical featurepatterns via dynamic matching of a bottom-upsensory input with a top-down learned expecta-tion. Bottom-up/top-down pattern matching andattentional focusing are, perhaps, the primaryfeatures common to all ART models across theirmany variations. Active input features that are notconfirmed by top-down expectations are inhib-ited (Fig. 1b). The remaining activation patterndefines a focus of attention, which, in turn, deter-mines what feature patterns are learned. Basingmemories on attended features rather than wholepatterns supports the design goal of encoding sta-ble memories with fast as well as slow learning.Encoding attended feature subsets also enablesone-to-many learning, where the system mayattach many context-dependent labels (Spot, dog,animal) to one input. This capability promotesknowledge discovery (Spot ) dog and dog)animal/ in a learning system that experiencesone input at a time, with no explicit connectionbetween inputs.
When the match is good enough, F2 activa-tion persists and learning proceeds. Where theyexceed the corresponding bottom-up input com-ponents, top-down signals decay as expectationsconverge toward the attended pattern at F1. Thecoding field F2 contains a reserve of uncommittedcoding nodes, which compete with the previouslyactive committed nodes. When a previously un-committed node is first activated during super-vised learning, it is associated with its desig-nated output class. During testing, the selectionof an uncommitted node means I don’t know.
ART networks for supervised learning are calledARTMAP (Carpenter et al. 1991a, 1992).
A mismatch between an active top-downexpectation and the bottom-up input leadsto a parallel memory search (Fig. 1c). TheART matching criterion is set by a vigilanceparameter . Low vigilance permits the learningof broad classes, across diverse exemplars, whilehigh vigilance limits learning to narrow classes.When a new input arrives, vigilance equals abaseline level. Baseline vigilance is set equalto zero to maximize generalization. ARTMAPvigilance increases following a predictiveerror or negative reinforcement (Encyclopediacross reference). The internal computation thatdetermines how far rises to correct the error iscalled match tracking (Carpenter et al. 1991a).As vigilance rises, the network pays moreattention to how well top-down expectationsmatch the bottom-up input. The match trackingmodification MT– (Carpenter and Markuzon1998) also allows the system to learn inconsistentcases. For example, three similar, even identical,map regions may have been correctly labeled bydifferent observers as ocean or water or natural.The ability to learn one-to-many maps, which canlabel a single test input as ocean and water andnatural, is a key feature of the ART knowledgediscovery system described below.
Applications
Three computational examples illustrate howcognitive and neural systems can introduce newapproaches to the analysis of large datasets.Application 1 (self-supervised ART) addressesthe question: how can a neural system learningfrom one example at a time absorb informationthat is inconsistent but correct, as when afamily pet is called Spot and dog and animal,while rejecting similar incorrect information, aswhen the same pet is called wolf? How doesthis system transform scattered informationinto knowledge that dogs are animals, but notconversely? Application 2 (ART knowledgediscovery) asks: how can a real-time system,initially trained with a few labeled examples

Adaptive Resonance Theory 5
A
and a limited feature set, continue to learnfrom experience, without supervision, whenconfronted with oceans of additional information,without eroding reliable early memories? Howcan such individual systems adapt to their uniqueapplication contexts? Application 3 (biased ART)asks: how can a neural system that has made anerror refocus attention on features that it initiallyignored?
The Boston TestbedThe Boston Testbed was developed to compareperformance of learning systems applied to chal-lenging problems of spatial analysis. Each mul-tispectral Boston image pixel produces 41 fea-ture values: 6 Landsat 7 Thematic Mapper (TM)bands at 30 m resolution, 2 thermal bands at 60 mresolution, 1 panchromatic band at 15 m reso-lution, and 32 derived bands representing localcontrast, color, and texture. In the Boston dataset,each of 28,735 ground truth pixels is labeledas belonging to one of seven classes (beach,ocean, ice, river, park, residential, industrial).For knowledge discovery system training, someocean, ice, and river pixels are instead labeledas belonging to broader classes such as water ornatural. No pixel has more than one label, andthe learning system is given no information aboutrelationships between target classes. The labeleddataset is available from the CNS TechnologyLab Website [http://techlab.bu.edu/classer/datasets/].
A cross-validation procedure divides an imageinto four vertical strips: two for training, onefor validation (if needed for parameter selec-tion), and one for testing. Class mixtures differmarkedly across strips. For example, one stripcontains many ocean pixels, while another stripcontains neither ocean nor beach pixels. Geo-graphically dissimilar training and testing areasrobustly assess regional generalization. In thisarticle, spatial analysis simulations on the BostonTestbed follow this protocol to illustrate ARTsystems for self-supervised learning, knowledgediscovery, and attentional control. Since eachsystem in Applications 1–3 requires no parameterselection, training uses randomly chosen pixelsfrom three strips, with testing on the fourth strip.
Application 1: Learning from Experiencewith Self-Supervised ARTComputational models of supervised patternrecognition typically utilize two learning phases.During an initial training phase, input patterns,described as specified values of a set of features,are presented along with output class labels orpatterns. During a subsequent testing phase, themodel generates output predictions for unlabeledinputs, and no further learning takes place.
Although supervised learning has been suc-cessfully applied in diverse settings, it does notreflect many natural learning situations. Humansdo learn from explicit training, as from a textbookor a teacher, and they do take tests. However,students do not stop learning when they leavethe classroom. Rather, they continue to learnfrom experience, incorporating not only moreinformation but new types of information, all thewhile building on the foundation of their earlierknowledge. Self-supervised ART models suchlife-long learning.
An unsupervised learning system clusters un-labeled input patterns. Semi-supervised learningincorporates both labeled and unlabeled inputs inits training set, but all inputs typically have thesame number of specified feature values. Withoutany novel features from which to learn, semi-supervised learning systems use unlabeled datato refine the model parameters defined using la-beled data. Reviews of semi-supervised learning(Chapelle et al. 2006) have found that many ofthe successful models are carefully selected andtuned, using a priori knowledge of the problem.Chapelle et al. (2006) conclude that none of thesemi-supervised models they review is robustenough to be general purpose. The main difficultyseems to be that, whenever unlabeled instancesare different enough from labeled instances tomerit learning, these differences could containmisinformation that may damage system perfor-mance.
The self-supervised paradigm models twolearning stages. During Stage 1 learning, thesystem receives all output labels, but onlya subset of possible feature values for eachinput. During Stage 2 learning, the system mayreceive more feature values for each input, but

6 Adaptive Resonance Theory
no output labels. In Stage 1, when the systemcan confidently incorporate externally specifiedoutput labels, self-supervised ART (Amis andCarpenter 2010) employs winner-take-all codingand fast learning. In Stage 2, when the systeminternally generates its own output labels, codesare distributed so that incorrect hypotheses do notabruptly override reliable “classroom learning”of Stage 1. The distributed ART learning laws,dInstar (Carpenter 1997) and dOutstar (Carpenter1994), scale memory changes to internallygenerated measures of prediction confidenceand prevent memory changes altogether formost inputs. Memory stability derives fromthe dynamic weight representation of long-termmemories, which permits learning only in pathsto and from highly active coding nodes. Dynamicweights solve a problem inherent in learning lawsbased on multiplicative weights, which are proneto catastrophic forgetting when implementedwith distributed codes and huge datasets, evenwhen learning is very slow.
In addition to emulating the human learningexperience, self-supervised learning maps totechnological applications that need to copewith huge, ever-changing datasets. A supervisedlearning system that completes all training beforemaking test predictions does not adapt to newinformation and individual contexts. A semi-supervised system risks degrading its supervisedknowledge. Self-supervised ART continuesto learn from new experiences, with built-insafeguards that conserve useful memories. Self-supervised ART code is available from the CNSTechnology Lab Website (http://techlab.bu.edu/SSART/).
A simulation study based on the BostonTestbed (Amis and Carpenter 2010) illustratesways in which high-dimensional problems maychallenge any system learning without labels.As in most ground truth datasets, labeledpixels consist primarily of clear exemplars ofsingle classes. Because sensors have a 15–60 mresolution, many unlabeled pixels cover multipleclasses, such as ice and industrial. Stage 2 inputsthus mix and distort features from multipleclasses, placing many of the unlabeled featurevectors far from the distinct class clusters of the
Stage 1 training set. Although the distributedART learning laws are open to unrestrictedadaptation on any pixel, the distributed codes ofStage 2 minimize the influence of mixed pixels.Most memory changes occur on unambiguouscases, despite the fact that the unlabeled pixelsprovide no external indices of class ambiguity.Self-supervised Stage 2 learning dramaticallyimproves performance compared to learningthat ends after Stage 1. On every one of 500individual simulations, Stage 2 learning improvestest accuracy, as unlabeled fully featured inputsconsistently expand knowledge from Stage 1training.
Application 2: Transforming Informationinto Knowledge Using ART KnowledgeDiscoveryClassifying terrain or objects may require the res-olution of conflicting information from sensorsworking at different times, locations, and scalesand from users with different goals and situations.Image fusion has been defined as “the acquisi-tion, processing and synergistic combination ofinformation provided by various sensors or bythe same sensor in many measuring contexts”(Simone et al. 2002, p. 3). When multiple sourcesprovide inconsistent data, fusion methods arecalled upon to appraise information componentsto decide among various options and to resolveinconsistencies, as when evidence suggests thatan object is a car or a truck or a bus. Fusion meth-ods weigh the confidence and reliability of eachsource, merging complementary information orgathering more data. In any case, at most one ofthese answers is correct.
The method described here defines a com-plementary approach to the information fusionproblem, considering the case where sensors andsources are both nominally inconsistent and reli-able, as when evidence suggests that an object isa car and a vehicle and man-made or when a caris alternatively labeled automobile. Underlyingrelationships among classes are assumed to beunknown to the automated system or the humanuser, as if the labels were encrypted.
The ART knowledge discovery model acts as aself-organizing expert system to derive consistent

Adaptive Resonance Theory 7
A
knowledge structures from such nominally incon-sistent data (Carpenter et al. 2005). Once derived,a rule set can be used to assign classes to levels.For each rule x) y, class x is located at a lowerlevel than classy. Classes connected by arrowsthat codify a list of rules and confidence val-ues form a graphical representation of a knowl-edge hierarchy. For spatial data, the resultingdiagram of the relationships among classes canguide the construction of orderly layered maps.ART knowledge discovery code is available fromthe CNS Technology Lab Website (http://techlab.bu.edu/classer/classer toolkit overview). On theBoston Testbed, the ART knowledge discoverysystem places each class at its correct level andfinds all the correct rules for this example.
Application 3: Correcting Errors by BiasingAttention Using Biased ARTMemories in ART networks are based onmatched patterns that focus attention oncritical features, where bottom-up inputsmatch active top-down expectations. While thislearning strategy has proved successful for bothbrain models and applications, computationalexamples demonstrate that paying too muchattention to critical features that have beenselected to represent a given category earlyon may distort memory representations duringsubsequent learning. If training inputs arerepeatedly presented, an ART system will correctthese initial errors. However, real-time learningmay not afford such repeat opportunities. BiasedART (bART) (Carpenter and Gaddam 2010)solves the problem of overemphasis on earlycritical features by directing attention away frominitially attended features after the system makesa predictive error.
Activity x at the ART field F1 computes thematch between the field’s bottom-up and top-down input patterns (Fig. 1). A reset signal shutsoff the active F2 code when x fails to meet thematching criterion determined by vigilance .Reset alone does not, however, induce a differentcode: unless the prior code has left an enduringtrace within the F0–F2 subsystem, the networkwill simply reactivate the same pattern at F2.
Following reset, all ART systems shift atten-tion away from previously active coding nodes atthe field F2. As modeled in ART 3 (Carpenter andGrossberg 1990), biasing the bottom-up input tothe coding field to favor previously inactive F2
nodes implements search by enabling the networkto activate a new code in response to a resetsignal. The ART 3 search mechanism defines amedium-term memory in the F0-to-F2 adaptivefilter so that the system does not perseverateindefinitely on an output class that had just pro-duced a reset. A presynaptic interpretation ofthis bias mechanism is transmitter depletion orhabituation.
The biased ART network (Carpenter andGaddam 2010) introduces a second, top-down,medium-term memory which, following reset,shifts attention away from previously activefeature nodes at the match field F1. In Fig. 1, thefirst feature is strongly represented in the input Aand in the matched patterns x at F1 both beforereset (Fig. 1b) and after reset (Fig. 1d). Followingthe same sequence as in Fig. 1a–c, biased ARTwould diminish the size of the first feature in thematched pattern. The addition of featural biasinghelps the system to pay more attention to inputfeatures that it had previously ignored.
The biasing mechanism is a small modularelement that can be added to any ART net-work. While computational examples and BostonTestbed simulations demonstrate how featuralbiasing in response to predictive errors improvesperformance on supervised learning tasks, theerror signal that gates biasing could have orig-inated from other sources, as in reinforcementlearning. Biased ART code is available from theCNS Technology Lab Website (http://techlab.bu.edu/bART).
Future DirectionsApplications for tested software based on compu-tational intelligence abound. This section outlinesareas where ART systems may open qualitativelynew frontiers for novel technologies. Future ap-plications summarized here would adapt and spe-cialize brain models that have already been math-ematically specified and computationally simu-lated to explain and predict large psychological

8 Adaptive Resonance Theory
and neurobiological databases. By linking thebrain to mind, these models characterize bothmechanism (how the model works) and func-tion (what the model is for). Both mechanismand function are needed to design new applica-tions. These systems embody new designs forautonomous adaptive agents, including new com-putational paradigms that are called Complemen-tary Computing and Laminar Computing. Theseparadigms enable the autonomous adaptation inreal time of individual persons or machines tononstationary situations filled with unexpectedevents. See Grossberg (2013) for a review.
New Paradigms for AutonomousIntelligent Systems: ComplementaryComputing and Laminar ComputingFunctional integration is essential to the designof a complex autonomous system such as a robotmoving and learning freely in an unpredictableenvironment. Linking independent modules for,say, vision and motor control will not necessarilyproduce a coordinated system that can adapt tounexpected events in changeable contexts. How,then, should such an autonomous adaptive systembe designed?
A clue can be found in the nature of brainspecialization. How have brains evolved whileinteracting with the physical world and embody-ing its invariants? Many scientists have proposedthat our brains possess independent modules.The brain’s organization into distinct anatom-ical areas and processing streams shows thatbrain regions are indeed specialized. Whereasindependent modules compute their particularprocesses on their own, behavioral data argueagainst this possibility. Complementary Comput-ing (Grossberg 2000a,b, 2013) concerns the dis-covery that pairs of parallel cortical process-ing streams compute computationally comple-mentary properties. Each stream has comple-mentary strengths and weaknesses, much as inphysical principles like the Heisenberg uncer-tainty principle. Each cortical stream can alsopossess multiple processing stages. These stagesrealize a hierarchical resolution of uncertainty.“Uncertainty” here means that computing oneset of properties at a given stage prevents com-
putation of a complementary set of propertiesat that stage. Complementary Computing pro-poses that the computational unit of brain pro-cessing that has behavioral significance consistsof parallel and hierarchical interactions betweencomplementary cortical processing streams withmultiple processing stages. These interactionsovercome complementary weaknesses to com-pute necessary information about a particulartype of biological intelligence.
Five decades of neural modeling have shownhow Complementary Computing is embedded asa fundamental design principle in neural systemsfor vision, speech and language, cognition, emo-tion, and sensory-motor control. ComplementaryComputing hereby provides a blueprint for de-signing large-scale autonomous adaptive systemsthat are poised for technological implementation.
A unifying anatomical theme that enablescommunication among cortical systems isLaminar Computing. The cerebral cortex, theseat of higher intelligence in all modalities,is organized into layered circuits (often sixmain layers) that undergo characteristic bottom-up, top-down, and horizontal interactions. Asinformation travels up and down connectedregions, distributed decisions are made in realtime based on a preponderance of evidence.Multiple levels suppress weaker groupings whilecommunicating locally coherent choices. Thedistributed ART model (Fig. 1), for example,features three cortical layers, with its distributedcode (e.g., at a cortical layer 6) producing adistributed output. Stacks of match fields (inflow)and coding fields (outflow) lay the substrate forcortical hierarchies.
How do specializations of this shared lami-nar design embody different types of biologicalintelligence, including vision, speech, language,and cognition? How does this shared design en-able seamless intercortical interactions? Modelsof Laminar Computing clarify how these differ-ent types of intelligence all use variations of thesame laminar circuitry (Grossberg 2013; Gross-berg and Pearson 2008). This circuitry representsa revolutionary synthesis of desirable computa-tional properties of feedforward and feedbackprocessing, digital and analog processing, and

Adaptive Resonance Theory 9
A
bottom-up data-driven processing and top-downattentive hypothesis-driven processing. Realizingsuch designs in hardware that embodies biolog-ical intelligence promises to facilitate the devel-opment of increasingly general-purpose adaptiveautonomous systems for multiple applications.
Complementary Computing in the Designof Perceptual/Cognitive and Spatial/MotorSystemsMany neural models that embody subsystemsof an autonomous adaptive agent have beendeveloped and computationally character-ized. It remains to unify and adapt themto particular machine learning applications.Complementary Computing implies that notall of these subsystems could be based onvariants of ART. In particular, accumulatingexperimental and theoretical evidence shows thatperceptual/cognitive and spatial/motor processesuse different learning, matching, and predictivelaws for their complementary functions (Fig. 2).ART-like processing is ubiquitous in perceptualand cognitive processes, including excitatorymatching and match-based learning that enablesself-stabilizing memories to form. VectorAssociative Map (VAM) processing is oftenfound in spatial and motor processes, whichrely on inhibitory matching and mismatch-
based learning. In these modalities, spatialmaps and motor plants are adaptively updatedwithout needing to remember past maps andparameters. Complementary mechanisms createa self-stabilizing perceptual/cognitive frontend for intelligently manipulating the morelabile spatial/motor processes that enable ourchangeable bodies to act effectively upon achanging world.
Some of the existing large-scale ART systemsare briefly reviewed here, using visually basedsystems for definiteness. Citations refer to articlesthat specify system equations and simulationsand that can be downloaded from http://cns.bu.edu/steve.
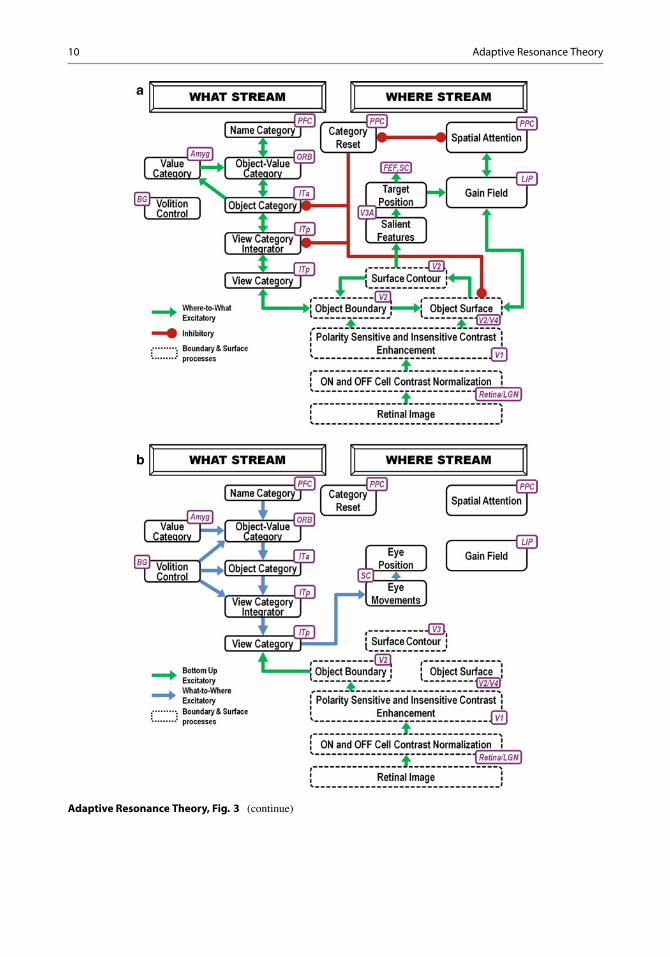
Where’s Waldo? Unifying Spatial andObject Attention, Learning, Recognition,and Search of Valued Objects and ScenesART models have been incorporated into largersystem architectures that clarify how individualsautonomously carry out intelligent behaviors asthey explore novel environments. One such de-velopment is the ARTSCAN family of architec-tures, which model how individuals rapidly learnto search a scene to detect, attend, invariantlyrecognize, and look at a valued target object(Fig. 3; Cao, Grossberg, and Markowitz 2011;Chang, Grossberg, and Cao 2014; Fazl, Gross-
WHAT WHERE
EXCITATORY INHIBITORY
MATCH MISMATCH
Spatially-invariant object learning and recognition
Fast learning without catastrophic forgetting
Spatially-variant reaching and movement
Continually update sensory-motor maps and gains
PPC
MATCHING
LEARNING
WHAT WHERE
IT
Adaptive Resonance Theory, Fig. 2 ComplementaryWhat and Where cortical processing streams for spatiallyinvariant object recognition and spatially variant spatialrepresentation and action, respectively. Perception andrecognition use top-down excitatory matching and match-
based fast or slow learning without catastrophic forget-ting. Spatial and motor tasks use inhibitory matchingand mismatch-based learning to achieve adaptation tochanging bodily parameters. IT inferotemporal cortex,PPC posterior parietal cortex
10 Adaptive Resonance Theory
Adaptive Resonance Theory, Fig. 3 (continue)

Adaptive Resonance Theory 11
A
berg, and Mingolla 2009; Foley, Grossberg, andMingolla 2012; Grossberg, Srinivasan, and Yaz-danbakhsh 2014). Such a competence representsa proposed solution of the Where’s Waldo prob-lem.
The ventral What stream is associated withobject learning, recognition, and prediction,whereas the dorsal Where stream carries outprocesses such as object localization, spatialattention, and eye movement control. To achieveefficient object recognition, the What streamlearns object category representations thatbecome increasingly invariant under view, size,and position changes at higher processingstages. Such invariance enables objects tobe learned and recognized without causing acombinatorial explosion. However, by strippingaway the positional coordinates of each objectexemplar, the What stream loses the abilityto command actions to the positions of valuedobjects. The Where stream computes positionalrepresentations of the world and controls actionsto acquire objects in it, but does not representdetailed properties of the objects themselves.
ARTSCAN architectures model how an au-tonomous agent can determine when the viewsthat are foveated by successive scanning move-ments belong to the same object and thus de-termine which view-selective categories shouldbe associatively linked to an emerging view- ,size-, and positionally-invariant object category.
This competence, which avoids the problem oferroneously merging pieces of different objects,works even under the unsupervised learning con-ditions that are the norm during many objectlearning experiences in vivo. The model identifiesa new role for spatial attention in the Wherestream, namely, control of invariant object cat-egory learning by the What stream. Interactionsacross the What and Where streams overcome thedeficiencies of computationally complementaryproperties of these streams.
In the ARTSCAN Search model, both Where-to-What and What-to-Where stream interactionsare needed to overcome complementaryweaknesses: Where stream processes of spatialattention and predictive eye movement controlregulate What stream processes whereby multipleview- and positionally-specific object categoriesare learned and associatively linked to view-and positionally-invariant object categoriesthrough bottom-up and object-attentive top-downinteractions. What stream cognitive-emotionallearning processes enable the focusing ofmotivated attention upon the invariant object cat-egories of desired objects (Brown, Bullock, andGrossberg 1999, 2004; Dranias, Grossberg, andBullock 2008; Grossberg and Seidman 2006).What stream cognitive names or motivationaldrives can, together with volitional signals,drive a search for Waldo. Mediated by objectattention, search proceeds from What stream
J
Adaptive Resonance Theory, Fig. 3 ARTSCANSearch macrocircuit and corresponding brain regions.Dashed boxes indicate boundary and surface pre-processing. (a) Category learning system. Arrowsrepresent excitatory cortical processes. Spatial attentionin the Where stream regulates view-specific and view-invariant category learning and recognition, and attendantreinforcement learning, in the What stream. Connectionsending in circular disks indicate inhibitory connections.(b) Where’s Waldo search system. Search begins whena name category or value category is activated andsubliminally primes an object-value category via theART matching rule. A volition control signal enablesthe primed object-value category to fire output signals.Bolstered by volitional control signals, these outputsignals can, in turn, propagate through a positionally-invariant object category to all the positionally-variant
view category integrators whose various views andpositions are represented by the object category. Theview category integrators can subliminally prime,but not fully activate, these view categories. All thisoccurs in the What stream. When the bottom-up inputfrom an object’s boundary/surface representation alsoactivates one of these view categories, its activitybecomes suprathreshold, wins the competition acrossview categories for persistent activation, and activatesa spatial attentional representation of Waldo’s positionin the Where stream. ITa anterior part of inferotemporalcortex, ITp posterior part of inferotemporal cortex, PPCposterior parietal cortex, LIP lateral intraparietal cortex,LGN lateral geniculate nucleus, ORB orbitofrontal cortex,Amyg amygdala, BG basal ganglia, PFC prefrontal cortex,SC superior colliculus, V1 striate visual cortex, V2, V3,and V4 prestriate visual cortices

12 Adaptive Resonance Theory
positionally-invariant representations to Wherestream positionally-specific representations thatfocus spatial attention on Waldo’s position.ARTSCAN architectures hereby model howthe dynamics of multiple brain regions arecoordinated to achieve clear functional goals.
The focus of spatial attention on Waldo’s po-sition in the Where stream can be used to controleye and hand movements toward Waldo, afternavigational circuits (see below) bring the ob-server close enough to contact him. VAM-typelearning circuits have been developed for thecontrol of goal-oriented eye and hand movementsthat can be used for this purpose (e.g., Bul-lock and Grossberg 1988, 1991; Bullock, Cisek,and Grossberg 1998; Contreras-Vidal, Grossberg,and Bullock 1997; Gancarz and Grossberg 1999;Grossberg, Srihasam, and Bullock 2012; Pack,Grossberg, and Mingolla 2001; Srihasam, Bul-lock, and Grossberg 2009).
The ARTSCENE system (Grossberg andHuang 2009) models how humans can incremen-tally learn and rapidly predict scene identity bygist and then accumulates learned evidence fromscenic textures to refine its initial hypothesis,using the same kind of spatial attentionalshrouds that help to learn invariant objectcategories in ARTSCAN. The ARTSCENESearch system (Huang and Grossberg 2010)models how humans use target-predictivecontextual information to guide search for desiredtargets in familiar scenes. For example, humanscan learn that a certain combination of objectsmay define a context for a kitchen and trigger amore efficient search for a typical object, such asa sink, in that context.
General-Purpose Vision and How ItSupports Object Learning, Recognition,and TrackingVisual preprocessing constrains the quality ofvisually based learning and recognition. On anassembly line, automated vision systems suc-cessfully scan for target objects in this carefullycontrolled environment. In contrast, a human orrobot navigating a natural scene faces overlaidtextures, edges, shading, and depth information,with multiple scales and shifting perspectives.
In the human brain, evolution has produced ahuge preprocessor, involving multiple brain re-gions, for object and scene representation andfor target tracking and navigation. One reasonfor this is that visual boundaries and surfaces,visual form and motion, and target tracking andvisually based navigation are computationallycomplementary, thus requiring several distinctbut interacting cortical processing streams.
Prior to the development of systems suchas ARTSCAN and ARTSCENE, the FACADE(Form-And-Color-And-DEpth) model provideda neural theory of form perception, including3D vision and figure-ground separation (e.g.,Cao and Grossberg 2005, 2012; Fang andGrossberg 2009; Grossberg, Kuhlmann, and Min-golla 2007; Grossberg and Swaminathan 2004;Kelly and Grossberg 2000). The 3D FORMO-TION model provides a neural theory of motionprocessing and form-motion interactions (e.g.,Baloch and Grossberg 1997; Baloch, Grossberg,Mingolla, and Nogueira 1999; Berzhanskaya,Grossberg, and Mingolla 2007; Grossberg,Leveille, and Versace 2011; Grossberg, Min-golla, and Viswanathan 2001; Grossberg andRudd 1992). The FACADE model has just theproperties that are needed for solving the Where’sWaldo problem, and the 3D FORMOTIONmodel has just the properties that are neededfor tracking unpredictably moving targets.Their complementary properties enabled theseextensions.
Visual and Spatial Navigation, CognitiveWorking Memory, and PlanningIn addition to being able to see, learn, recognize,and track valued goal objects, an animal or au-tonomous robot must also be able to navigateto or away from them and to interact with themthrough goal-oriented hand and arm movements.Navigation is controlled by two distinct and in-teracting systems: a visually guided system and aspatial path integration system.
Visually guided navigation through a clutterednatural scene is modeled using the 3D FORMO-TION model as a front end. The STARS andViSTARS neural systems (Browning, Grossberg,and Mingolla 2009a, b; Elder, Grossberg, and

Adaptive Resonance Theory 13
A
Mingolla 2009) model how primates use objectmotion information to segment objects and op-tic flow information to determine heading (self-motion direction), for purposes of goal approachand obstacle avoidance in response to realisticenvironments. The models predict how compu-tationally complementary processes in parallelstreams within the visual cortex compute objectmotion for tracking and self-motion for navi-gation. The models’ steering decisions computegoals as attractors and obstacles as repellers, asdo humans.
Spatial navigation based upon path integrationsignals has been a topic of great interest recently.Indeed, the 2014 Nobel Prize in Physiology orMedicine was awarded to John O’Keefe for hisdiscovery of place cells in the hippocampal cortexand to Edvard and May-Britt Moser for theirdiscovery of grid cells in the entorhinal cor-tex. The GridPlaceMap neural system (Gross-berg and Pilly 2012, 2014; Pilly and Grossberg2012, 2014; Mhatre, Grossberg, and Gorchetch-nikov 2012; Pilly and Grossberg 2014) proposeshow entorhinal grid cells and hippocampal placecells may be learned as spatial categories in ahierarchy of self-organizing maps. The modelresponds to realistic rat navigational trajectoriesby learning both grid cells with hexagonal gridfiring fields of multiple spatial scales, and placecells with one or more firing fields. Model dy-namics match neurophysiological data about theirdevelopment in juvenile rats. The GridPlaceMapmodel enjoys several parsimonious design fea-tures that will facilitate their embodiment in tech-nological applications, including hardware: (1)similar ring attractor mechanisms process bothlinear and angular path integration inputs thatdrive map learning; (2) the same self-organizingmap mechanisms can learn grid cell and place cellreceptive fields in a hierarchy of maps, and bothgrid and place cells can develop by detecting,learning, and remembering the most frequent andenergetic co-occurrences of their inputs; and (3)the learning of the dorsoventral organization ofgrid cell modules with multiple spatial scalesthat occur in the pathway from the medial en-torhinal cortex to hippocampus seems to usemechanisms that are homologous to those for
adaptively timed temporal learning that occur inthe pathway from the lateral entorhinal cortex tohippocampus (Grossberg and Merrill 1989, 1992;Grossberg and Schmajuk 1989). The homologousmechanisms for representing space and time inthis entorhinal-hippocampal system has led to thephrase “neural relativity” for this parsimoniousdesign.
Finally, the GridPlaceMap model is an ARTsystem. It proposes how top-down hippocampus-to-entorhinal attentional mechanisms may sta-bilize map learning and thereby simulates howhippocampal inactivation may disrupt grid cellproperties and explains challenging data abouttheta, beta, and gamma oscillations.
Visual and path integration information coop-erate during navigation. Cognitive planning alsoinfluences navigational decisions. More researchis needed to show how learning fuses visual, pathintegration, and planning circuits into a unifiednavigational system. The design of a generalplanning system will be facilitated by the fact thatsimilar circuits for short-term storage of eventsequences (working memory) and for learningof sequential plans are used by the brain tocontrol linguistic, spatial, and motor behaviors(Grossberg and Pearson 2008; Silver, Grossberg,Bullock, Histed, and Miller 2011).
Social CognitionHow can multiple autonomous systems interactintelligently? Individuals experience the worldfrom self-centered perspectives. What we learnfrom each other is thus computed in differentcoordinates within our minds. How do we bridgethese diverse coordinates? A model of socialcognition that explains how a teacher can in-struct a learner who experiences the world froma different perspective can be used to enable asingle human or robotic teacher to instruct a large“class” of embodied robots that all experience theteacher from different perspectives.
Piaget’s circular reaction notes the feedbackloop between the eye and hand in the learninginfant, laying the foundation for visually guidedreaching. Similarly, feedback between babbledsounds and hearing forms the learned substrateof language production. These intrapersonal cir-

14 Adaptive Resonance Theory
cular reactions were extended to interpersonalcircular reactions within the Circular Reactionsfor Imitative Behavior (CRIB) model (Grossbergand Vladusich 2010). This model shows howsocial cognition builds upon ARTSCAN mecha-nisms. These mechanisms clarify how an infantlearns how to share joint attention with adultteachers and to follow their gaze toward valuedgoal objects. The infant also needs to be capableof view-invariant object learning and recognitionwhereby it can carry out goal-directed behaviors,such as the use of tools, using different objectviews than the ones that its teachers use. Suchcapabilities are often attributed to mirror neu-rons. This attribution does not, however, explainthe brain processes whereby these competencesarise. CRIB proposes how intrapersonal circularreactions create a foundation for interpersonalcircular reactions when infants and other learnersinteract with external teachers in space. Bothtypes of circular reactions involve learned co-ordinate transformations between body-centeredarm movement commands and retinotopic visualfeedback, and coordination of processes withinand between the What and Where cortical pro-cessing streams. Specific breakdowns of modelprocesses generate formal symptoms similar toclinical symptoms of autism.
Mental Disorders and HomeostaticPlasticityOptimally functioning autonomous intelligentsystems require properly balanced complemen-tary systems. What happens when they becomeimbalanced? In humans, they can experiencemental disorders.
Scientific literature on human mental disor-ders such as autism and schizophrenia is, ofnecessity, more anecdotal than parametric and is,therefore, an insufficient foundation for modelconstruction. Real-time models of normal mentalbehavior that are based on the huge databasesfrom decades of psychological and neurobiologi-cal experiments have, however, provided insightsinto the mechanisms of abnormal behaviors (e.g.,Carpenter and Grossberg 1993; Grossberg 1984,2000a, b; Grossberg and Seidman 2006).
Imbalanced processes across the complemen-tary systems that control normal behaviors canproduce constellations of model symptoms thatstrikingly resemble mental disorders. For exam-ple, fixing the ART vigilance parameter attoo high a level leads to symptoms familiar inautistic individuals, notably learning of hyper-concrete categories and difficulty paying atten-tion to the meaning of a task. Underarousal ofthe model amygdala can lead to insensitivity tosocial meanings and also to intense emotionaloutbursts and coping strategies to reduce eventcomplexity and unexpectedness. Damage to themodel cerebellum can lead to defects of adap-tively timed learning and thus a host of problemsin socialization.
In both humans and robots, it remains anopen problem to model how biologically basedautonomous systems can discover and maintaintheir own optimal operating parameters inresponse to the challenges of an unpredictableworld. An initial step toward solving thishomeostatic plasticity problem was made inChandler and Grossberg (2012).
Machine Consciousness?An early ART prediction is that all consciousstates are resonant states, though not allresonant states are conscious: Since that time,ART has predicted how specific resonancessupport different kinds of consciousness. Theseobservations suggest the question: can machinesthat embody ART resonant dynamics experiencea type of consciousness? For example, ARTmodels predict that surface-shroud resonancessubserve conscious percepts of visual qualia,feature-category resonances subserve recogni-tion of familiar objects and scenes, spectral-shroud resonances subserve conscious perceptsof auditory streams, spectral-pitch-and-timberesonances subserve conscious recognition ofauditory streams, item-list resonances subserveconscious percepts of speech and language,and cognitive-emotional resonances subserveconscious feelings and knowing the objects orevents that cause them. ART models also identifythe brain regions and interactions that wouldsupport these resonances.

Adaptive Resonance Theory 15
A
These results about model correlates ofconsciousness emerge from ART analyses ofthe mechanistic relationships among processesof Consciousness, Learning, Expectation,Attention, Resonance, and Synchrony (theCLEARS processes). Recall, however, that notall resonant states are conscious states. Forexample, entorhinal-hippocampal resonances arepredicted to dynamically stabilize the learningof entorhinal grid cells and hippocampal placecells, and parietal-prefrontal resonances arepredicted to trigger the selective opening ofbasal ganglia gates to enable the read-out ofcontext-appropriate actions. Grossberg (2013,2016) reviews these and other aspects of ART asa cognitive and neural theory.
Recommended Reading
Amis GP, Carpenter GA (2010) Self-supervisedARTMAP. Neural Netw 23:265–282
Baloch AA, Grossberg S (1997) A neural model ofhigh-level motion processing: line motion and for-motion dynamics. Vis Res 37:3037–3059
Baloch AA, Grossberg S, Mingolla E, Nogueira CAM(1999) A neural model of first-order and second-order motion perception and magnocellular dynam-ics. J Opt Soc Am A 16:953–978
Berzhanskaya J, Grossberg S, Mingolla E (2007) Lam-inar cortical dynamics of visual form and motion in-teractions during coherent object motion perception.Spat Vis 20:337–395
Brown J, Bullock D, Grossberg S (1999) How the basalganglia use parallel excitatory and inhibitory learn-ing pathways to selectively respond to unexpectedrewarding cues. J Neurosci 19:10502–10511
Brown JW, Bullock D, Grossberg S (2004) How lami-nar frontal cortex and basal ganglia circuits interactto control planned and reactive saccades. NeuralNetw 17:471–510
Browning A, Grossberg S, Mingolla M (2009a) Aneural model of how the brain computes headingfrom optic flow in realistic scenes. Cogn Psychol59:320–356
Browning A, Grossberg S, Mingolla M (2009b) Cor-tical dynamics of navigation and steering in naturalscenes: motion-based object segmentation, heading,and obstacle avoidance. Neural Netw 22:1383–1398
Bullock D, Grossberg S (1988) Neural dynamics ofplanned arm movements: emergent invariants andspeed-accuracy properties during trajectory forma-tion. Psychol Rev 95:49–90
Bullock D, Grossberg S (1991) Adaptive neural net-works for control of movement trajectories invariant
under speed and force rescaling. Hum Mov Sci10:3–53
Bullock D, Cisek P, Grossberg S (1998) Cortical net-works for control of voluntary arm movements un-der variable force conditions. Cereb Cortex 8:48–62
Cao Y, Grossberg S (2005) A laminar cortical modelof stereopsis and 3D surface perception: closure andda Vinci stereopsis. Spat Vis 18:515–578
Cao Y, Grossberg S (2012) Stereopsis and 3D surfaceperception by spiking neurons in laminar corticalcircuits: a method of converting neural rate modelsinto spiking models. Neural Netw 26:75–98
Cao Y, Grossberg S, Markowitz J (2011) How doesthe brain rapidly learn and reorganize view- andpositionally-invariant object representations in infe-rior temporal cortex? Neural Netw 24:1050–1061
Carpenter GA (1994) A distributed outstar network forspatial pattern learning. Neural Netw 7:159–168
Carpenter GA (1997) Distributed learning, recogni-tion, and prediction by ART and ARTMAP neuralnetworks. Neural Netw 10:1473–1494
Carpenter GA (2001) Neural network models of learn-ing and memory: leading questions and an emergingframework. Trends Cogn Sci 5:114–118
Carpenter GA, Gaddam SC (2010) Biased ART: aneural architecture that shifts attention toward pre-viously disregarded features following an incorrectprediction. Neural Netw 23:435–451
Carpenter GA, Grossberg S (1987) A massively par-allel architecture for a self-organizing neural patternrecognition machine. Comput Vis Graph Image Pro-cess 37:54–115
Carpenter GA, Grossberg S (1990) ART 3: hierar-chical search using chemical transmitters in self-organizing pattern recognition architectures. NeuralNetw 4: 129–152
Carpenter G, Grossberg S (1993) Normal and am-nesic learning, recognition, and memory by a neuralmodel of cortico-hippocampal interactions. TrendsNeurosci 16:131–137
Carpenter GA, Markuzon N (1998) ARTMAP-IC andmedical diagnosis: instance counting and inconsis-tent cases. Neural Netw 11:323–336
Carpenter GA, Grossberg S, Reynolds JH (1991a)ARTMAP: supervised real-time learning and clas-sification of nonstationary data by a self-organizingneural network. Neural Netw 4:565–588
Carpenter GA, Grossberg S, Rosen DB (1991b) FuzzyART: fast stable learning and categorization ofanalog patterns by an adaptive resonance system.Neural Netw 4:759–771
Carpenter GA, Grossberg S, Markuzon N, ReynoldsJH, Rosen DB (1992) Fuzzy ARTMAP: a neu-ral network architecture for incremental supervisedlearning of analog multidimensional maps. IEEETrans Neural Netw 3:698–713
Carpenter GA, Martens S, Ogas OJ (2005) Self-organizing information fusion and hierarchicalknowledge discovery: a new framework using

16 Adaptive Resonance Theory
ARTMAP neural networks. Neural Netw 18:287–295
Chandler B, Grossberg S (2012) Joining distributedpattern processing and homeostatic plasticity in re-current on-center off-surround shunting networks:noise, saturation, short-term memory, synaptic scal-ing, and BDNF. Neural Netw 25:21–29
Chang H-C, Grossberg S, Cao Y (2014) Where’sWaldo? How perceptual cognitive, and emotionalbrain processes cooperate during learning to cate-gorize and find desired objects in a cluttered scene.Front Integr Neurosci doi:10.3389/fnint.2014.0043
Chapelle O, Scholkopf B, Zien A (eds) (2006) Semi-supervised learning. MIT, Cambridge
Contreras-Vidal JL, Grossberg S, Bullock D (1997)A neural model of cerebellar learning for armmovement control: cortico-spino-cerebellar dynam-ics. Learn Mem 3:475–502
Dranias M, Grossberg S, Bullock D (2008) Dopamin-ergic and non-dopaminergic value systems in condi-tioning and outcome-specific revaluation. Brain Res1238:239–287
Elder D, Grossberg S, Mingolla M (2009) A neuralmodel of visually guided steering, obstacle avoid-ance, and route selection. J Exp Psychol Hum Per-cept Perform 35:1501–1531
Fang L, Grossberg S (2009) From stereogram to sur-face: how the brain sees the world in depth. Spat Vis22:45–82
Fazl A, Grossberg S, Mingolla E (2009) View-invariantobject category learning, recognition, and search:how spatial and object attention are coordinated us-ing surface-based attentional shrouds. Cogn Psychol58:1–48
Foley NC, Grossberg S, Mingolla E (2012) Neural dy-namics of object-based multifocal visual spatial at-tention and priming: object cueing, useful-field-of-view, and crowding. Cognitive Psychology 65:77–117
Gancarz G, Grossberg G (1999) A neural model ofthe saccadic eye movement control explains task-specific adaptation. Vis Res 39:3123–3143
Grossberg S (1984) Some psychophysiological andpharmacological correlates of a developmental, cog-nitive, and motivational theory. In: Karrer R, CohenJ, Tueting P (eds) Brain and information: eventrelated potential. New York Academy of Sciences,New York, pp 58–142.
Grossberg S (2000a) The complementary brain: uni-fying brain dynamics and modularity. Trends CognSci 4:233–246
Grossberg S (2000b) The imbalanced brain: fromnormal behavior to schizophrenia. Biol Psychiatry48:81–98
Grossberg S (2013) Adaptive resonance theory: howa brain learns to consciously attend, learn, andrecognize a changing World. Neural Netw 37:1–47
Grossberg, S. (2016). Towards solving the hard prob-lem of consciousness: the varieties of brain res-onances and the conscious experiences that they
support. Submitted for publicationGrossberg S, Huang T-R (2009) ARTSCENE: a neu-
ral system for natural scene classification. J Vis9(6):1–19
Grossberg S, Merrill JWL (1992) A neural networkmodel of adaptively timed reinforcement learningand hippocampal dynamics. Cogn Brain Res 1:3–38
Grossberg S, Merrill JWL (1996) The hippocampusand cerebellum in adaptively timed learning, recog-nition, and movement. J Cogn Neurosci 8:257–277
Grossberg S, Pearson L (2008) Laminarcortical dynamics of cognitive and motorworking memory, sequence learning andperformance: toward a unified theory of howthe cerebral cortex works. Psychol Rev 115:677–732
Grossberg S, Pilly PK (2012) How entorhinal gridcells may learn multiple spatial scales froma dorsoventral gradient of cell response ratesin a self-organizing map. PLoS Comput Biol8(10):31002648. doi:10.1371/journal.pcbi.1002648
Grossberg S, Pilly PK (2014) Coordinated learning ofgrid cell and place cell spatial and temporal prop-erties: multiple scales, attention, and oscillations.Philos Trans R Soc B 369:20120524
Grossberg S, Rudd ME (1992) Cortical dynamics ofvisual motion perception: short-range and long-range apparent motion (with Rudd ME). PsycholRev 99:78–121
Grossberg S, Schmajuk NA (1989) Neural dynamics ofadaptive timing and temporal discrimination duringassociative learning. Neural Netw 2:79–102
Grossberg S, Seidman D (2006) Neural dynamics ofautistic behaviors: cognitive, emotional, and timingsubstrates. Psychol Rev 113:483–525
Grossberg S, Swaminathan G (2004) A laminar corti-cal model for 3D perception of slanted and curvedsurfaces and of 2D images: development, attentionand bistability. Vis Res 44:1147–1187
Grossberg S, Vladusich T (2010) How do childrenlearn to follow gaze, share joint attention, imitatetheir teachers, and use tools during social interac-tions? Neural Netw 23:940–965
Grossberg S, Leveille J, Versace M (2011) How doobject reference frames and motion vector decom-position emerge in laminar cortical circuits? AttenPercept Psychophys 73:1147–1170
Grossberg S, Kuhlmann L, Mingolla E (2007) A neu-ral model of 3D shape-from-texture: multiple-scalefiltering, boundary grouping, and surface filling-in.Vis Res 47:634–672
Grossberg S, Mingolla E, Viswanathan L (2001) Neu-ral dynamics of motion integration and segmenta-tion within and across apertures. Vis Res 41:2521–2553
Grossberg S, Srihasam K, Bullock D (2012) Neu-ral dynamics of saccadic and smooth pursuit eyemovement coordination during visual tracking ofunpredictably moving targets. Neural Netw 27:1–20

Adaptive Resonance Theory 17
A
Huang T-R, Grossberg S (2010) Cortical dynamicsof contextually cued attentive visual learning andsearch: spatial and object evidence accumulation.Psychol Rev 117:1080–1112
Hurvich LM, Jameson D (1957) An opponent-processtheory of color vision. Psychol Rev 64:384–390
Kelly FJ, Grossberg S (2000) Neural dynamics of 3-D surface perception: figure-ground separation andlightness perception. Percept Psychophys 62:1596–1619
Mhatre H, Gorchetchnikov A, Grossberg S (2012)Grid cell hexagonal patterns formed by fast self-organized learning within entorhinal cortex. Hip-pocampus 22:320–334
Pack C, Grossberg S, Mingolla E (2001) A neuralmodel of smooth pursuit control and motion per-ception by cortical area MST. J Cogn Neurosci13:102–120
Pilly PK, Grossberg S (2012) How do spatial learningand memory occur in the brain? Coordinated learn-ing of entorhinal grid cells and hippocampal placecells. J Cogn Neurosci 24:1031–1054
Pilly PK, Grossberg S (2014) How does the modularorganization of entorhinal grid cells develop? FrontHum Neurosci. doi:10.3389/fnhum.2014.0037
Schiller PH (1982) Central connections of the retinalON and OFF pathways. Nature 297:580–583
Simone G, Farina A, Morabito FC, Serpico SB, Bruz-zone L (2002) Image fusion techniques for remotesensing applications. Inf Fusion 3:3–15
Srihasam K, Bullock D, Grossberg S (2009) Targetselection by frontal cortex during coordinated sac-cadic and smooth pursuit eye movements. J CognNeurosci 21:1611–1627