ad hoc networking course instructor: carlos pomalaza-ráez geographical routing using partial...
Post on 21-Dec-2015
214 views
TRANSCRIPT

Ad Hoc Networking Course Instructor: Carlos Pomalaza-Ráez
Geographical RoutingUsing Partial Information
for Wireless Ad Hoc Networks
Rahul Jain, Anuj Puri, and Raja Sengupta
University of California, Berkeley
Published on IEEE Personal Communications, Vol.8, Issue 1, Feb2001Presented by Jani Saloranta at Ad Hoc Networking Course 27.1.2004

2
Outline• Introduction• Geograhical Routing Algorithm (GRA)• Algorithm• Related Issues• Teardown protocol• Performance• Simulation Results• Conclusion

3
Introduction• The algorithm for routing in wireless ad
hoc networks using information about geographical location of the nodes.
• Why?– Setting up a communication
infrastructure is difficult.– Mobility– Money

4
The Geographical Routing Algorithm
• Doesn’t assume any hierarchical network architecure
• Doesn’t do source routing• Assumes nodes position via global
positioning system (GPS) and existence of geographical location service (GLS).
• Optimal power• Symmetric links• Medium access schedule such that each
node can transmit at a certain bit rate without interference.

5
• Wireless network can be modellad as a graph
G = ( N, L ),where nodes N = {1, 2, ..., n} and edges (links) L = { ( i, j ) | nodes i and j are neighbours }.
• Each node knows about a small number of nodes in the network. More about the those who are nearer to it than those about those further away.

6
S
D

7
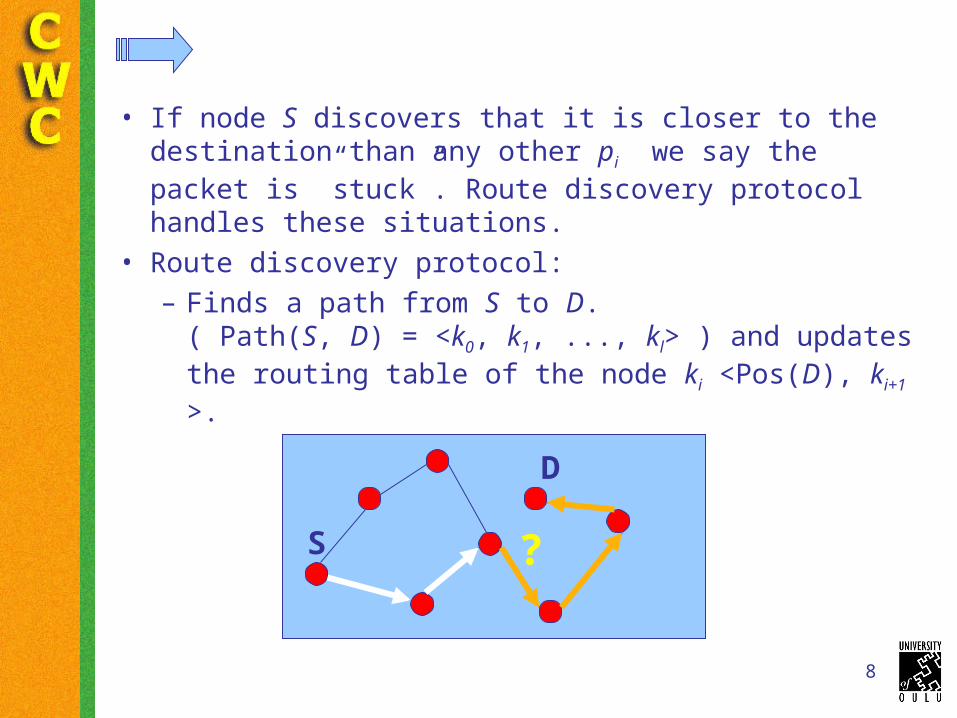
The Algorithm• Start point: Each node knows only about
its neighbours.
• Routing table for node S is a list <(pi, Si)>, where pi is a geographical position and Si is neighbour of S.
• Node S checks from its routing table which pi is closest for packet destination D.
• Each node thus forwards the packet in the same way till the packet reaches the destination.
8
S
D
• If node S discovers that it is closer to the destination than any other pi we say the packet is ”stuck”. Route discovery protocol handles these situations.
• Route discovery protocol:– Finds a path from S to D.
( Path(S, D) = <k0, k1, ..., kl> ) and updates the routing table of the node ki <Pos(D), ki+1 >.
?

9
1) from A to C2) from A to D3) from A to E

10
Related Issues• Positional Errors
– Node i gets its position from GPS and there is an error. i advertises wrong position pi
instead of correct position pi
’.
– If error is big enough packet most propably get ”stuck” Route discovery protocol.
• Multiple Route Discoveries– Avoided by timestamps.

11
Teardown protocol• Extension which tries to maintain the centers
property ans keep the routing tables consistent.• Node S updates its routing table:
1. S receives hello msg from node Ni it puts (Ni, pos(Ni), Ni)
2. If S doesn’t hear anything from node Ni for certain time it removes (Di, pos(Ni), Ni) for every Di.
3. If Table(S) contains the entry (Di, pi, Ni) and S receives Table(Ni) which contains the entry (Di, pj, –), then S updates its entry to (Di, pj, Ni).
4. If Table(S) contains the entry (Di, pi, Ni) and S receives Table(Ni) which does not contain an entry (Di, –, –), then S removes the entry (Dii, pi, Ni) from its table.
5. After any change to its routing table, S broadcasts the new Table(S).

12
Performance• Convergence of Routing Tables
– One of the advantages of algorithm is that a node does not need to have a routing entry for every other node in the network.
• Number of route discoveries per node– O (log n)
• Routing Table Size– The mean routing table size is bounded
above by O ( L1 log n )), where L1 is the mean length of the shortest path between any pair of nodes in an n-node random network.

13
Assumption: network has n nodes in a unit area and each node has transmission radius r.
• Overhead from a single link going down– O ( L log(n) / r 2 )
• Number of links going down due to mobility– O (r v n 2),
where v is speed of certain node. Total overhead
– O ( L v n 2 log(n ) / r ) packets get generated in the network per unit time.
14
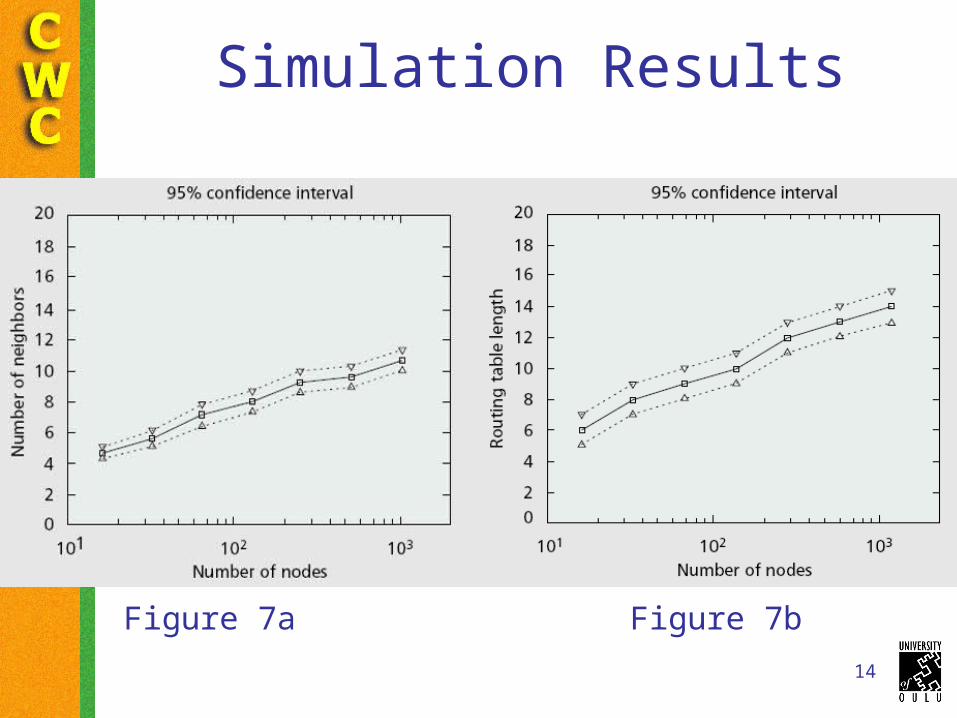
Simulation Results
Figure 7a Figure 7b
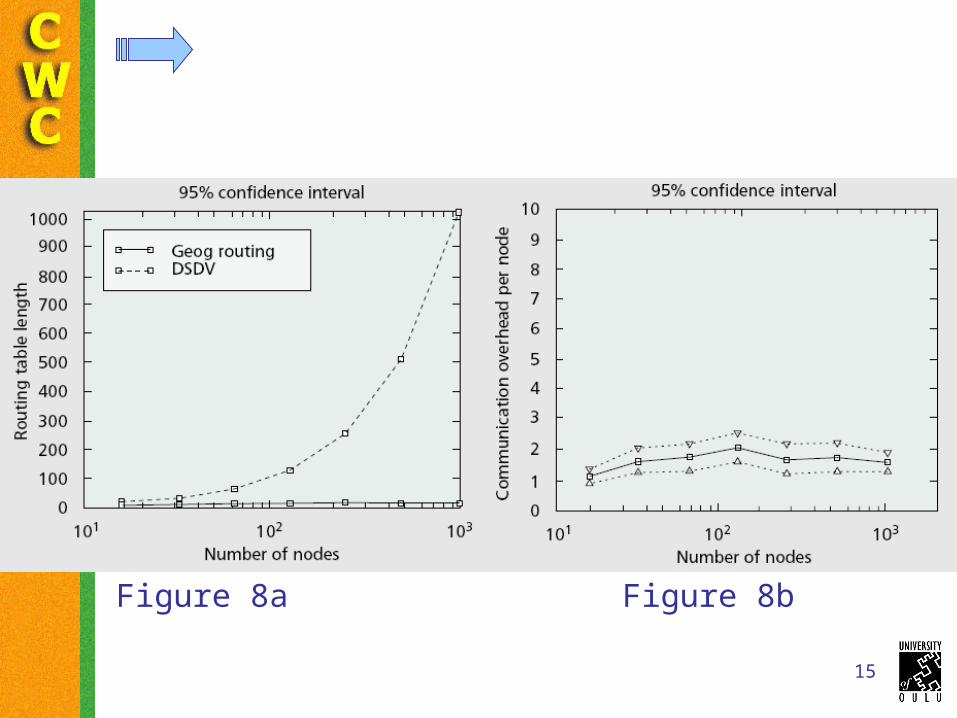
15
Figure 8a Figure 8b
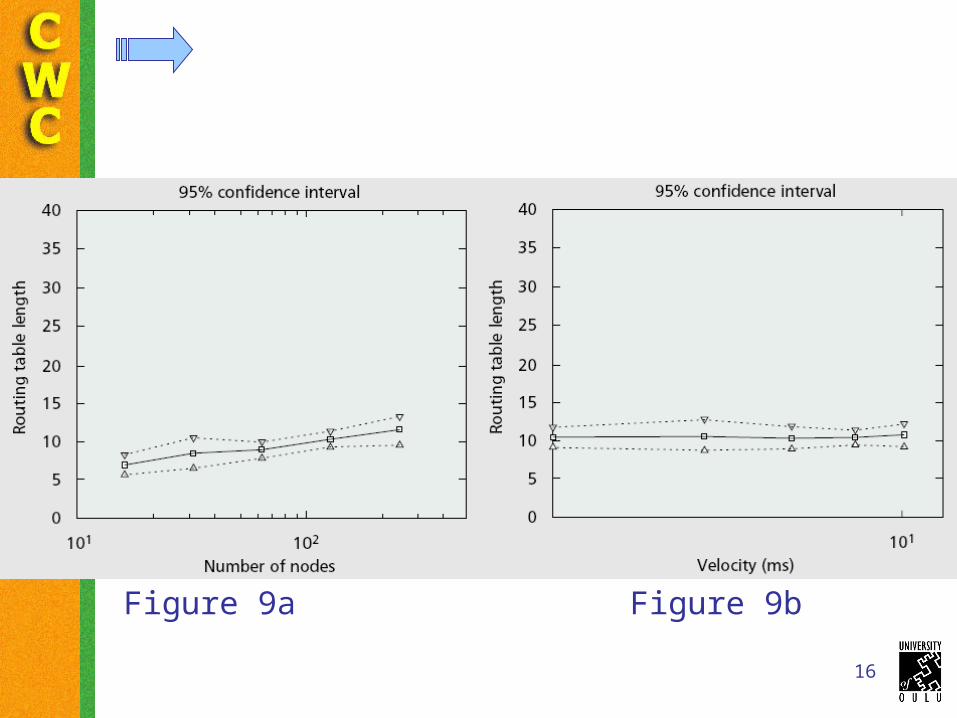
16
Figure 9a Figure 9b

17
Conclusions• Algorithm is asynchronous, real-time,
distributed, and scalable. It does not require an architecture or hierarchy to be imposed on the network, but provides each node with a distance-dependent aggregated view of the network topology.
• Correctness of algorithm has been shown via theoretic calculus and verified through simulations.

18
Teardown misspellingCorrect form can be found from [19].
Says: (di, pi, ni)
Should say: (di, pj, ni)

19
Blurry math• ”We assume the network has n nodes in a unit area and each
node has a transmission radius r.”• ”On average, each node has nπr2 neighbors and cLlog(n)
entries in its routing table. So on average a = cLlog(n)/(nπr2) entries in the routing table of A are using a link from node A to a neighbor B.”
nodes radius neighbours
entries
n r nπr2 cLlog(n)
0.1 10 31 cL* (-1)
1 10 314 0
10 10 3141 cL
2 2 25 cL* (0.3)