ab initio nuclear structure – the large sparse matrix - iopscience
TRANSCRIPT

Journal of Physics Conference Series
OPEN ACCESS
Ab initio nuclear structure ndash the large sparse matrixeigenvalue problemTo cite this article James P Vary et al 2009 J Phys Conf Ser 180 012083
View the article online for updates and enhancements
You may also likeInvestigation of the eigenvalue problem oneigenvibration of a loaded stringA A Samsonov D M Korosteleva and S ISolovrsquoev
-
Cavity approach to the first eigenvalueproblem in a family of symmetric randomsparse matricesYoshiyuki Kabashima Hisanao Takahashiand Osamu Watanabe
-
Fault detection with principal componentpursuit methodYijun Pan Chunjie Yang Youxian Sun etal
-
This content was downloaded from IP address 3711523180 on 13022022 at 1823
Ab initio nuclear structure - the large sparse matrix
eigenvalue problem
James P Vary1 Pieter Maris1 Esmond Ng2 Chao Yang2 Masha
Sosonkina3
1Department of Physics Iowa State University Ames IA 50011 USA2Computational Research Division Lawrence Berkeley National Laboratory Berkeley CA94720 USA3Scalable Computing Laboratory Ames Laboratory Iowa State University Ames IA 50011USA
E-mail jvaryiastateedu
Abstract The structure and reactions of light nuclei represent fundamental and formidablechallenges for microscopic theory based on realistic strong interaction potentials Severalab initio methods have now emerged that provide nearly exact solutions for some nuclearproperties The ab initio no core shell model (NCSM) and the no core full configuration (NCFC)method frame this quantum many-particle problem as a large sparse matrix eigenvalue problemwhere one evaluates the Hamiltonian matrix in a basis space consisting of many-fermion Slaterdeterminants and then solves for a set of the lowest eigenvalues and their associated eigenvectorsThe resulting eigenvectors are employed to evaluate a set of experimental quantities to test theunderlying potential For fundamental problems of interest the matrix dimension often exceeds1010 and the number of nonzero matrix elements may saturate available storage on present-dayleadership class facilities We survey recent results and advances in solving this large sparsematrix eigenvalue problem We also outline the challenges that lie ahead for achieving furtherbreakthroughs in fundamental nuclear theory using these ab initio approaches
1 Introduction
The structure of the atomic nucleus and its interactions with matter and radiation have longbeen the foci of intense theoretical research aimed at a quantitative understanding based onthe underlying strong inter-nucleon potentials Once validated a successful approach promisespredictive power for key properties of short-lived nuclei that are present in stellar interiorsand in other nuclear astrophysical settings Moreover new medical diagnostic and therapeuticapplications may emerge as exotic nuclei are predicted and produced in the laboratory Finetuning nuclear reactor designs to reduce cost and increase both safety and efficiency are alsopossible outcomes with a high precision theory
Solving for nuclear properties with the best available nucleon-nucleon (NN) potentialssupplemented by 3-body (NNN) potentials as needed using a quantum many-particle frameworkthat respects all the known symmetries of the potentials is referred to as an rdquoab initiordquo problemand is recognized to be computationally hard Among the few ab initio methods available forlight nuclei beyond atomic number A = 10 the no core shell model (NCSM) [1] and the no corefull configuration (NCFC) [2] methods frame the problem as a large sparse matrix eigenvalueproblem one of the focii of the SciDAC-UNEDF program
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
ccopy 2009 IOP Publishing Ltd 1
2 Nuclear physics goals
Many fundamental properties of nuclei are poorly understood today By gaining insightinto these properties we may better utilize these dense quantum many-body systems to ouradvantage A short list of outstanding unsolved problems usually includes the followingquestions
bull What controls nuclear saturation - the property that the central density is nearly the samefor all nuclei
bull How does a successful shell model emerge from the underlying theory including predictionsfor shell and sub-shell closures
bull What are the properties of neutron-rich and proton-rich nuclei which will be explored atthe future FRIB (Facility for Rare Isotope Beams)
bull How precise can we predict the properties of nuclei - will it be feasible to use nuclei aslaboratories for tests of fundamental symmetries in nature
The past few years have seen substantial progress but the complete answers are yet to beachieved We highlight some of the recent physics achievements of the NCSM that encourageus to believe that those major goals may be achievable in the next 10 years In many cases weshowed the critical role played by 3-body forces and the need for large basis spaces to obtainagreement with experiment
Since 3-body potentials enlarge the computational requirements by one to two orders ofmagnitude in both memory and CPU time we have also worked to demonstrate that similarresults may be achieved by suitable adjustments of the undetermined features of the nucleon-nucleon (NN) potential known as the off-shell properties of the potential The adjustments wereconstructed so as to preserve the original high precision description of the NN scattering dataA partial list of the NCSM and NCFC achievements is included below
bull Described the anomaly of the nearly vanishing quadrupole moment of 6Li [3]
bull Established need for 3-body potentials to explain among other properties neutrino-12Ccross sections [4]
bull Found quenching of Gamow-Teller (GT) transitions in light nuclei due to effects of 3-bodypotential [5] (or off-shell modifications of NN potential) plus configuration mixing [6]
bull Obtained successful description of A = 10 to 13 low-lying spectra with chiral NN + NNNinteractions [7]
bull Explained ground state spin of 10B by including chiral NNN interaction [7]
We have identified several major near-term physics goals on the path to the larger goals listedabove These include
bull Evaluate the properties of the Hoyle state in 12C and the isoscalar quadrupole strengthfunction in 12C to compare with inelastic α scattering data
bull Explain the lifetime of 14C (5730 years) which depends sensitively on the nuclearwavefunction
bull Calculate the properties of the Oxygen isotopes out to the neutron drip line
bull Solve for nuclei surrounding shell closure in order to understand the origins shell closures
Preliminary results for these goals are encouraging and will be reported when we obtainadditional results closer to convergence
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
2
3 Recent NCFC results
Within the NCFC method we adopt the harmonic oscillator (HO) single particle basis whichinvolves two parameters and we seek results independent of those parameters either directly ina sufficiently large basis or via extrapolation to the infinite basis limit The first parameter hΩspecifies the HO energy the spacing between major shells Each shell is labeled uniquely bythe quanta of its orbits N = 2n + l (orbits are specified by quantum numbers n l jmj) whichbegins with 0 for the lowest shell and increments in steps of unity Each unique arrangement offermions (neutrons and protons) within the HO orbits that is consistent with the Pauli principleconstitutes a many-body basis state Many-body basis states satisfying chosen symmetries areemployed in evaluating the Hamiltonian H in that basis The second parameter is Nmax whichlimits the total number of oscillator quanta allowed in the many-body basis states and thuslimits the dimension D of the Hamiltonian matrix Nmax is defined to count the total quantaabove the minimum for the specific nucleus needed to satisfy the Pauli principle
31 Quadrupole moment of 6Li
Experimentally 6Li has a surprisingly small quadrupole moment Q = minus0083 e fm2 This meansthat there are significant cancellations between contributions to the quadrupole moment fromdifferent parts of the wave function In Ref [3] the NCSM was shown to agree reasonablywell with the data using a nonlocal NN interaction Here we employ the realistic JISP16 NNpotential from inverse scattering that provides a high-quality description of the NN data [8] ThisNN potential is sufficiently well-behaved that we may obtain NCFC results for light nuclei [2]Indeed the left panel of Fig 1 shows smooth uniform convergence of the ground state energyof 6Li The quadrupole moment does not exhibit the same smooth and uniform convergenceNevertheless the results for 15 MeVlt hΩ lt 25 MeV where the ground state energy is closestto convergence strongly suggest a quadrupole moment in agreement with experiment
32 Beryllium isotopes
Next we use the Be isotopes to portray features of the physics results and illustrate some of thecomputational challenges again with the JISP16 nonlocal NN potential [8] Fig 2 displays theNCFC results for the lowest states of natural and unnatural parity respectively in a range ofBe isotopes along with the experimental ground state energy Since our approach is guaranteedto provide an upper bound to the exact ground state energy for the chosen Hamiltonian eachpoint displayed for a particular value of Nmax represents the minimum value as a function of hΩ
0 5 10 15 20 25 30 35 40hΩ [MeV]
-32
-30
-28
-26
-24
-22
-20
-18
-16
bind
ing
ener
gy [
MeV
]
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max=14
expt
0 5 10 15 20 25 30 35 40hΩ [MeV]
-01
0
01
quad
upol
e m
omen
t
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max= 14
experiment
Figure 1 Ground state energy of 6Li (left) and quadrupole moment (right) obtained with theJISP16 NN potential as function of hΩ for several values of Nmax
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
3
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 4N
max = 6
Nmax
= 8N
max = 10
extrapolatedexpt
Be -- lowest natural parity states -- JISP16
preliminaryparity inversion
parity inversion
12-
(12-)
32-
32-
12+
12+
52+
52+
0+
0+
0+ 0
+
12+
52+
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 5N
max = 7
Nmax
= 9exptextrapolated
Be -- lowest unnatural parity states -- JISP16
preliminaryparity inversion
parity inversion
12+
(12-)
12+
2-
1-
1-
52-
3- 12
-
52-
12-
Figure 2 Lowest natural (left) and unnatural (right) states of Be isotopes obtained with theJISP16 NN potential Extrapolated results and their assessed uncertainties are presented as redpoints with error bars
obtained in that basis spaceIn small model spaces Nmax = 4 and 5 the calculations suggest a rdquoU-shapedrdquo curve for the
binding energy as function of A the number of nucleons whereas experimentally the groundstate energy keeps decreasing with A at least over the range in A shown in Fig 2 Howeveras one increases Nmax the calculated results get closer to the experimental values In order toobtain the binding energies in the full configuration space (NCFC) we can use an exponential fitto a set of results at 3 or 4 subsequent Nmax values [2] After performing such an extrapolationto infinite model space our calculated results follow the data very closely as function of A
In both panels of Fig 2 the dimensions increase dramatically as one increases Nmax
or increases atomic number A Detailed trends will be presented in the next section Theconsequence is that results terminate at lower A as one increases Nmax Additional calculationsare in process in order to reduce the uncertainties in the extrapolations
We note that the ground state spins are predicted correctly in all cases except A = 11 (andpossibly at A = 13 where the spin-parity of the ground state is not well known experimentally)where there is a reputed rdquoparity inversionrdquo In this case a state of rdquounnatural parityrdquo oneinvolving at least one particle moving up one HO shell from its lowest location unexpectedlybecomes the ground state While Fig 2 indicates we do not reproduce this parity inversion wedo notice however that the lowest states of natural and unnatural parity lie very close togetherThis indicates that small corrections arising from neglected effects such as three-body (NNN)potentials andor additional contributions from larger basis spaces could play a role here Weare continuing to investigate these improvements
4 Computer Science and Applied Math challenges
We outline the main factors underlying the need for improved approaches to solving the nuclearquantum many-body problem as a large sparse matrix eigenvalue problem Our goals requireresults as close to convergence as possible in order to minimize our extrapolation uncertaintiesAccording to current experience this requires the evaluation of the Hamiltonian in as large abasis as possible preferably with Nmax ge 10 in order to converge the ground state wavefunction
The dimensions of the Hamiltonian matrix grow combinatorially with increasing Nmax andwith increasing atomic number A To gain a feeling for that explosive growth we plot in Fig3 the matrix dimension (D) for a wide range of Oxygen isotopes In each case we select therdquonatural parityrdquo basis space the parity that coincides with the lowest HO configuration for that
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
4
1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

Ab initio nuclear structure - the large sparse matrix
eigenvalue problem
James P Vary1 Pieter Maris1 Esmond Ng2 Chao Yang2 Masha
Sosonkina3
1Department of Physics Iowa State University Ames IA 50011 USA2Computational Research Division Lawrence Berkeley National Laboratory Berkeley CA94720 USA3Scalable Computing Laboratory Ames Laboratory Iowa State University Ames IA 50011USA
E-mail jvaryiastateedu
Abstract The structure and reactions of light nuclei represent fundamental and formidablechallenges for microscopic theory based on realistic strong interaction potentials Severalab initio methods have now emerged that provide nearly exact solutions for some nuclearproperties The ab initio no core shell model (NCSM) and the no core full configuration (NCFC)method frame this quantum many-particle problem as a large sparse matrix eigenvalue problemwhere one evaluates the Hamiltonian matrix in a basis space consisting of many-fermion Slaterdeterminants and then solves for a set of the lowest eigenvalues and their associated eigenvectorsThe resulting eigenvectors are employed to evaluate a set of experimental quantities to test theunderlying potential For fundamental problems of interest the matrix dimension often exceeds1010 and the number of nonzero matrix elements may saturate available storage on present-dayleadership class facilities We survey recent results and advances in solving this large sparsematrix eigenvalue problem We also outline the challenges that lie ahead for achieving furtherbreakthroughs in fundamental nuclear theory using these ab initio approaches
1 Introduction
The structure of the atomic nucleus and its interactions with matter and radiation have longbeen the foci of intense theoretical research aimed at a quantitative understanding based onthe underlying strong inter-nucleon potentials Once validated a successful approach promisespredictive power for key properties of short-lived nuclei that are present in stellar interiorsand in other nuclear astrophysical settings Moreover new medical diagnostic and therapeuticapplications may emerge as exotic nuclei are predicted and produced in the laboratory Finetuning nuclear reactor designs to reduce cost and increase both safety and efficiency are alsopossible outcomes with a high precision theory
Solving for nuclear properties with the best available nucleon-nucleon (NN) potentialssupplemented by 3-body (NNN) potentials as needed using a quantum many-particle frameworkthat respects all the known symmetries of the potentials is referred to as an rdquoab initiordquo problemand is recognized to be computationally hard Among the few ab initio methods available forlight nuclei beyond atomic number A = 10 the no core shell model (NCSM) [1] and the no corefull configuration (NCFC) [2] methods frame the problem as a large sparse matrix eigenvalueproblem one of the focii of the SciDAC-UNEDF program
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
ccopy 2009 IOP Publishing Ltd 1
2 Nuclear physics goals
Many fundamental properties of nuclei are poorly understood today By gaining insightinto these properties we may better utilize these dense quantum many-body systems to ouradvantage A short list of outstanding unsolved problems usually includes the followingquestions
bull What controls nuclear saturation - the property that the central density is nearly the samefor all nuclei
bull How does a successful shell model emerge from the underlying theory including predictionsfor shell and sub-shell closures
bull What are the properties of neutron-rich and proton-rich nuclei which will be explored atthe future FRIB (Facility for Rare Isotope Beams)
bull How precise can we predict the properties of nuclei - will it be feasible to use nuclei aslaboratories for tests of fundamental symmetries in nature
The past few years have seen substantial progress but the complete answers are yet to beachieved We highlight some of the recent physics achievements of the NCSM that encourageus to believe that those major goals may be achievable in the next 10 years In many cases weshowed the critical role played by 3-body forces and the need for large basis spaces to obtainagreement with experiment
Since 3-body potentials enlarge the computational requirements by one to two orders ofmagnitude in both memory and CPU time we have also worked to demonstrate that similarresults may be achieved by suitable adjustments of the undetermined features of the nucleon-nucleon (NN) potential known as the off-shell properties of the potential The adjustments wereconstructed so as to preserve the original high precision description of the NN scattering dataA partial list of the NCSM and NCFC achievements is included below
bull Described the anomaly of the nearly vanishing quadrupole moment of 6Li [3]
bull Established need for 3-body potentials to explain among other properties neutrino-12Ccross sections [4]
bull Found quenching of Gamow-Teller (GT) transitions in light nuclei due to effects of 3-bodypotential [5] (or off-shell modifications of NN potential) plus configuration mixing [6]
bull Obtained successful description of A = 10 to 13 low-lying spectra with chiral NN + NNNinteractions [7]
bull Explained ground state spin of 10B by including chiral NNN interaction [7]
We have identified several major near-term physics goals on the path to the larger goals listedabove These include
bull Evaluate the properties of the Hoyle state in 12C and the isoscalar quadrupole strengthfunction in 12C to compare with inelastic α scattering data
bull Explain the lifetime of 14C (5730 years) which depends sensitively on the nuclearwavefunction
bull Calculate the properties of the Oxygen isotopes out to the neutron drip line
bull Solve for nuclei surrounding shell closure in order to understand the origins shell closures
Preliminary results for these goals are encouraging and will be reported when we obtainadditional results closer to convergence
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
2
3 Recent NCFC results
Within the NCFC method we adopt the harmonic oscillator (HO) single particle basis whichinvolves two parameters and we seek results independent of those parameters either directly ina sufficiently large basis or via extrapolation to the infinite basis limit The first parameter hΩspecifies the HO energy the spacing between major shells Each shell is labeled uniquely bythe quanta of its orbits N = 2n + l (orbits are specified by quantum numbers n l jmj) whichbegins with 0 for the lowest shell and increments in steps of unity Each unique arrangement offermions (neutrons and protons) within the HO orbits that is consistent with the Pauli principleconstitutes a many-body basis state Many-body basis states satisfying chosen symmetries areemployed in evaluating the Hamiltonian H in that basis The second parameter is Nmax whichlimits the total number of oscillator quanta allowed in the many-body basis states and thuslimits the dimension D of the Hamiltonian matrix Nmax is defined to count the total quantaabove the minimum for the specific nucleus needed to satisfy the Pauli principle
31 Quadrupole moment of 6Li
Experimentally 6Li has a surprisingly small quadrupole moment Q = minus0083 e fm2 This meansthat there are significant cancellations between contributions to the quadrupole moment fromdifferent parts of the wave function In Ref [3] the NCSM was shown to agree reasonablywell with the data using a nonlocal NN interaction Here we employ the realistic JISP16 NNpotential from inverse scattering that provides a high-quality description of the NN data [8] ThisNN potential is sufficiently well-behaved that we may obtain NCFC results for light nuclei [2]Indeed the left panel of Fig 1 shows smooth uniform convergence of the ground state energyof 6Li The quadrupole moment does not exhibit the same smooth and uniform convergenceNevertheless the results for 15 MeVlt hΩ lt 25 MeV where the ground state energy is closestto convergence strongly suggest a quadrupole moment in agreement with experiment
32 Beryllium isotopes
Next we use the Be isotopes to portray features of the physics results and illustrate some of thecomputational challenges again with the JISP16 nonlocal NN potential [8] Fig 2 displays theNCFC results for the lowest states of natural and unnatural parity respectively in a range ofBe isotopes along with the experimental ground state energy Since our approach is guaranteedto provide an upper bound to the exact ground state energy for the chosen Hamiltonian eachpoint displayed for a particular value of Nmax represents the minimum value as a function of hΩ
0 5 10 15 20 25 30 35 40hΩ [MeV]
-32
-30
-28
-26
-24
-22
-20
-18
-16
bind
ing
ener
gy [
MeV
]
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max=14
expt
0 5 10 15 20 25 30 35 40hΩ [MeV]
-01
0
01
quad
upol
e m
omen
t
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max= 14
experiment
Figure 1 Ground state energy of 6Li (left) and quadrupole moment (right) obtained with theJISP16 NN potential as function of hΩ for several values of Nmax
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
3
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 4N
max = 6
Nmax
= 8N
max = 10
extrapolatedexpt
Be -- lowest natural parity states -- JISP16
preliminaryparity inversion
parity inversion
12-
(12-)
32-
32-
12+
12+
52+
52+
0+
0+
0+ 0
+
12+
52+
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 5N
max = 7
Nmax
= 9exptextrapolated
Be -- lowest unnatural parity states -- JISP16
preliminaryparity inversion
parity inversion
12+
(12-)
12+
2-
1-
1-
52-
3- 12
-
52-
12-
Figure 2 Lowest natural (left) and unnatural (right) states of Be isotopes obtained with theJISP16 NN potential Extrapolated results and their assessed uncertainties are presented as redpoints with error bars
obtained in that basis spaceIn small model spaces Nmax = 4 and 5 the calculations suggest a rdquoU-shapedrdquo curve for the
binding energy as function of A the number of nucleons whereas experimentally the groundstate energy keeps decreasing with A at least over the range in A shown in Fig 2 Howeveras one increases Nmax the calculated results get closer to the experimental values In order toobtain the binding energies in the full configuration space (NCFC) we can use an exponential fitto a set of results at 3 or 4 subsequent Nmax values [2] After performing such an extrapolationto infinite model space our calculated results follow the data very closely as function of A
In both panels of Fig 2 the dimensions increase dramatically as one increases Nmax
or increases atomic number A Detailed trends will be presented in the next section Theconsequence is that results terminate at lower A as one increases Nmax Additional calculationsare in process in order to reduce the uncertainties in the extrapolations
We note that the ground state spins are predicted correctly in all cases except A = 11 (andpossibly at A = 13 where the spin-parity of the ground state is not well known experimentally)where there is a reputed rdquoparity inversionrdquo In this case a state of rdquounnatural parityrdquo oneinvolving at least one particle moving up one HO shell from its lowest location unexpectedlybecomes the ground state While Fig 2 indicates we do not reproduce this parity inversion wedo notice however that the lowest states of natural and unnatural parity lie very close togetherThis indicates that small corrections arising from neglected effects such as three-body (NNN)potentials andor additional contributions from larger basis spaces could play a role here Weare continuing to investigate these improvements
4 Computer Science and Applied Math challenges
We outline the main factors underlying the need for improved approaches to solving the nuclearquantum many-body problem as a large sparse matrix eigenvalue problem Our goals requireresults as close to convergence as possible in order to minimize our extrapolation uncertaintiesAccording to current experience this requires the evaluation of the Hamiltonian in as large abasis as possible preferably with Nmax ge 10 in order to converge the ground state wavefunction
The dimensions of the Hamiltonian matrix grow combinatorially with increasing Nmax andwith increasing atomic number A To gain a feeling for that explosive growth we plot in Fig3 the matrix dimension (D) for a wide range of Oxygen isotopes In each case we select therdquonatural parityrdquo basis space the parity that coincides with the lowest HO configuration for that
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
4
1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

2 Nuclear physics goals
Many fundamental properties of nuclei are poorly understood today By gaining insightinto these properties we may better utilize these dense quantum many-body systems to ouradvantage A short list of outstanding unsolved problems usually includes the followingquestions
bull What controls nuclear saturation - the property that the central density is nearly the samefor all nuclei
bull How does a successful shell model emerge from the underlying theory including predictionsfor shell and sub-shell closures
bull What are the properties of neutron-rich and proton-rich nuclei which will be explored atthe future FRIB (Facility for Rare Isotope Beams)
bull How precise can we predict the properties of nuclei - will it be feasible to use nuclei aslaboratories for tests of fundamental symmetries in nature
The past few years have seen substantial progress but the complete answers are yet to beachieved We highlight some of the recent physics achievements of the NCSM that encourageus to believe that those major goals may be achievable in the next 10 years In many cases weshowed the critical role played by 3-body forces and the need for large basis spaces to obtainagreement with experiment
Since 3-body potentials enlarge the computational requirements by one to two orders ofmagnitude in both memory and CPU time we have also worked to demonstrate that similarresults may be achieved by suitable adjustments of the undetermined features of the nucleon-nucleon (NN) potential known as the off-shell properties of the potential The adjustments wereconstructed so as to preserve the original high precision description of the NN scattering dataA partial list of the NCSM and NCFC achievements is included below
bull Described the anomaly of the nearly vanishing quadrupole moment of 6Li [3]
bull Established need for 3-body potentials to explain among other properties neutrino-12Ccross sections [4]
bull Found quenching of Gamow-Teller (GT) transitions in light nuclei due to effects of 3-bodypotential [5] (or off-shell modifications of NN potential) plus configuration mixing [6]
bull Obtained successful description of A = 10 to 13 low-lying spectra with chiral NN + NNNinteractions [7]
bull Explained ground state spin of 10B by including chiral NNN interaction [7]
We have identified several major near-term physics goals on the path to the larger goals listedabove These include
bull Evaluate the properties of the Hoyle state in 12C and the isoscalar quadrupole strengthfunction in 12C to compare with inelastic α scattering data
bull Explain the lifetime of 14C (5730 years) which depends sensitively on the nuclearwavefunction
bull Calculate the properties of the Oxygen isotopes out to the neutron drip line
bull Solve for nuclei surrounding shell closure in order to understand the origins shell closures
Preliminary results for these goals are encouraging and will be reported when we obtainadditional results closer to convergence
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
2
3 Recent NCFC results
Within the NCFC method we adopt the harmonic oscillator (HO) single particle basis whichinvolves two parameters and we seek results independent of those parameters either directly ina sufficiently large basis or via extrapolation to the infinite basis limit The first parameter hΩspecifies the HO energy the spacing between major shells Each shell is labeled uniquely bythe quanta of its orbits N = 2n + l (orbits are specified by quantum numbers n l jmj) whichbegins with 0 for the lowest shell and increments in steps of unity Each unique arrangement offermions (neutrons and protons) within the HO orbits that is consistent with the Pauli principleconstitutes a many-body basis state Many-body basis states satisfying chosen symmetries areemployed in evaluating the Hamiltonian H in that basis The second parameter is Nmax whichlimits the total number of oscillator quanta allowed in the many-body basis states and thuslimits the dimension D of the Hamiltonian matrix Nmax is defined to count the total quantaabove the minimum for the specific nucleus needed to satisfy the Pauli principle
31 Quadrupole moment of 6Li
Experimentally 6Li has a surprisingly small quadrupole moment Q = minus0083 e fm2 This meansthat there are significant cancellations between contributions to the quadrupole moment fromdifferent parts of the wave function In Ref [3] the NCSM was shown to agree reasonablywell with the data using a nonlocal NN interaction Here we employ the realistic JISP16 NNpotential from inverse scattering that provides a high-quality description of the NN data [8] ThisNN potential is sufficiently well-behaved that we may obtain NCFC results for light nuclei [2]Indeed the left panel of Fig 1 shows smooth uniform convergence of the ground state energyof 6Li The quadrupole moment does not exhibit the same smooth and uniform convergenceNevertheless the results for 15 MeVlt hΩ lt 25 MeV where the ground state energy is closestto convergence strongly suggest a quadrupole moment in agreement with experiment
32 Beryllium isotopes
Next we use the Be isotopes to portray features of the physics results and illustrate some of thecomputational challenges again with the JISP16 nonlocal NN potential [8] Fig 2 displays theNCFC results for the lowest states of natural and unnatural parity respectively in a range ofBe isotopes along with the experimental ground state energy Since our approach is guaranteedto provide an upper bound to the exact ground state energy for the chosen Hamiltonian eachpoint displayed for a particular value of Nmax represents the minimum value as a function of hΩ
0 5 10 15 20 25 30 35 40hΩ [MeV]
-32
-30
-28
-26
-24
-22
-20
-18
-16
bind
ing
ener
gy [
MeV
]
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max=14
expt
0 5 10 15 20 25 30 35 40hΩ [MeV]
-01
0
01
quad
upol
e m
omen
t
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max= 14
experiment
Figure 1 Ground state energy of 6Li (left) and quadrupole moment (right) obtained with theJISP16 NN potential as function of hΩ for several values of Nmax
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
3
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 4N
max = 6
Nmax
= 8N
max = 10
extrapolatedexpt
Be -- lowest natural parity states -- JISP16
preliminaryparity inversion
parity inversion
12-
(12-)
32-
32-
12+
12+
52+
52+
0+
0+
0+ 0
+
12+
52+
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 5N
max = 7
Nmax
= 9exptextrapolated
Be -- lowest unnatural parity states -- JISP16
preliminaryparity inversion
parity inversion
12+
(12-)
12+
2-
1-
1-
52-
3- 12
-
52-
12-
Figure 2 Lowest natural (left) and unnatural (right) states of Be isotopes obtained with theJISP16 NN potential Extrapolated results and their assessed uncertainties are presented as redpoints with error bars
obtained in that basis spaceIn small model spaces Nmax = 4 and 5 the calculations suggest a rdquoU-shapedrdquo curve for the
binding energy as function of A the number of nucleons whereas experimentally the groundstate energy keeps decreasing with A at least over the range in A shown in Fig 2 Howeveras one increases Nmax the calculated results get closer to the experimental values In order toobtain the binding energies in the full configuration space (NCFC) we can use an exponential fitto a set of results at 3 or 4 subsequent Nmax values [2] After performing such an extrapolationto infinite model space our calculated results follow the data very closely as function of A
In both panels of Fig 2 the dimensions increase dramatically as one increases Nmax
or increases atomic number A Detailed trends will be presented in the next section Theconsequence is that results terminate at lower A as one increases Nmax Additional calculationsare in process in order to reduce the uncertainties in the extrapolations
We note that the ground state spins are predicted correctly in all cases except A = 11 (andpossibly at A = 13 where the spin-parity of the ground state is not well known experimentally)where there is a reputed rdquoparity inversionrdquo In this case a state of rdquounnatural parityrdquo oneinvolving at least one particle moving up one HO shell from its lowest location unexpectedlybecomes the ground state While Fig 2 indicates we do not reproduce this parity inversion wedo notice however that the lowest states of natural and unnatural parity lie very close togetherThis indicates that small corrections arising from neglected effects such as three-body (NNN)potentials andor additional contributions from larger basis spaces could play a role here Weare continuing to investigate these improvements
4 Computer Science and Applied Math challenges
We outline the main factors underlying the need for improved approaches to solving the nuclearquantum many-body problem as a large sparse matrix eigenvalue problem Our goals requireresults as close to convergence as possible in order to minimize our extrapolation uncertaintiesAccording to current experience this requires the evaluation of the Hamiltonian in as large abasis as possible preferably with Nmax ge 10 in order to converge the ground state wavefunction
The dimensions of the Hamiltonian matrix grow combinatorially with increasing Nmax andwith increasing atomic number A To gain a feeling for that explosive growth we plot in Fig3 the matrix dimension (D) for a wide range of Oxygen isotopes In each case we select therdquonatural parityrdquo basis space the parity that coincides with the lowest HO configuration for that
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
4
1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

3 Recent NCFC results
Within the NCFC method we adopt the harmonic oscillator (HO) single particle basis whichinvolves two parameters and we seek results independent of those parameters either directly ina sufficiently large basis or via extrapolation to the infinite basis limit The first parameter hΩspecifies the HO energy the spacing between major shells Each shell is labeled uniquely bythe quanta of its orbits N = 2n + l (orbits are specified by quantum numbers n l jmj) whichbegins with 0 for the lowest shell and increments in steps of unity Each unique arrangement offermions (neutrons and protons) within the HO orbits that is consistent with the Pauli principleconstitutes a many-body basis state Many-body basis states satisfying chosen symmetries areemployed in evaluating the Hamiltonian H in that basis The second parameter is Nmax whichlimits the total number of oscillator quanta allowed in the many-body basis states and thuslimits the dimension D of the Hamiltonian matrix Nmax is defined to count the total quantaabove the minimum for the specific nucleus needed to satisfy the Pauli principle
31 Quadrupole moment of 6Li
Experimentally 6Li has a surprisingly small quadrupole moment Q = minus0083 e fm2 This meansthat there are significant cancellations between contributions to the quadrupole moment fromdifferent parts of the wave function In Ref [3] the NCSM was shown to agree reasonablywell with the data using a nonlocal NN interaction Here we employ the realistic JISP16 NNpotential from inverse scattering that provides a high-quality description of the NN data [8] ThisNN potential is sufficiently well-behaved that we may obtain NCFC results for light nuclei [2]Indeed the left panel of Fig 1 shows smooth uniform convergence of the ground state energyof 6Li The quadrupole moment does not exhibit the same smooth and uniform convergenceNevertheless the results for 15 MeVlt hΩ lt 25 MeV where the ground state energy is closestto convergence strongly suggest a quadrupole moment in agreement with experiment
32 Beryllium isotopes
Next we use the Be isotopes to portray features of the physics results and illustrate some of thecomputational challenges again with the JISP16 nonlocal NN potential [8] Fig 2 displays theNCFC results for the lowest states of natural and unnatural parity respectively in a range ofBe isotopes along with the experimental ground state energy Since our approach is guaranteedto provide an upper bound to the exact ground state energy for the chosen Hamiltonian eachpoint displayed for a particular value of Nmax represents the minimum value as a function of hΩ
0 5 10 15 20 25 30 35 40hΩ [MeV]
-32
-30
-28
-26
-24
-22
-20
-18
-16
bind
ing
ener
gy [
MeV
]
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max=14
expt
0 5 10 15 20 25 30 35 40hΩ [MeV]
-01
0
01
quad
upol
e m
omen
t
Nmax
= 4N
max= 6
Nmax
= 8N
max= 10
Nmax
= 12N
max= 14
experiment
Figure 1 Ground state energy of 6Li (left) and quadrupole moment (right) obtained with theJISP16 NN potential as function of hΩ for several values of Nmax
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
3
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 4N
max = 6
Nmax
= 8N
max = 10
extrapolatedexpt
Be -- lowest natural parity states -- JISP16
preliminaryparity inversion
parity inversion
12-
(12-)
32-
32-
12+
12+
52+
52+
0+
0+
0+ 0
+
12+
52+
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 5N
max = 7
Nmax
= 9exptextrapolated
Be -- lowest unnatural parity states -- JISP16
preliminaryparity inversion
parity inversion
12+
(12-)
12+
2-
1-
1-
52-
3- 12
-
52-
12-
Figure 2 Lowest natural (left) and unnatural (right) states of Be isotopes obtained with theJISP16 NN potential Extrapolated results and their assessed uncertainties are presented as redpoints with error bars
obtained in that basis spaceIn small model spaces Nmax = 4 and 5 the calculations suggest a rdquoU-shapedrdquo curve for the
binding energy as function of A the number of nucleons whereas experimentally the groundstate energy keeps decreasing with A at least over the range in A shown in Fig 2 Howeveras one increases Nmax the calculated results get closer to the experimental values In order toobtain the binding energies in the full configuration space (NCFC) we can use an exponential fitto a set of results at 3 or 4 subsequent Nmax values [2] After performing such an extrapolationto infinite model space our calculated results follow the data very closely as function of A
In both panels of Fig 2 the dimensions increase dramatically as one increases Nmax
or increases atomic number A Detailed trends will be presented in the next section Theconsequence is that results terminate at lower A as one increases Nmax Additional calculationsare in process in order to reduce the uncertainties in the extrapolations
We note that the ground state spins are predicted correctly in all cases except A = 11 (andpossibly at A = 13 where the spin-parity of the ground state is not well known experimentally)where there is a reputed rdquoparity inversionrdquo In this case a state of rdquounnatural parityrdquo oneinvolving at least one particle moving up one HO shell from its lowest location unexpectedlybecomes the ground state While Fig 2 indicates we do not reproduce this parity inversion wedo notice however that the lowest states of natural and unnatural parity lie very close togetherThis indicates that small corrections arising from neglected effects such as three-body (NNN)potentials andor additional contributions from larger basis spaces could play a role here Weare continuing to investigate these improvements
4 Computer Science and Applied Math challenges
We outline the main factors underlying the need for improved approaches to solving the nuclearquantum many-body problem as a large sparse matrix eigenvalue problem Our goals requireresults as close to convergence as possible in order to minimize our extrapolation uncertaintiesAccording to current experience this requires the evaluation of the Hamiltonian in as large abasis as possible preferably with Nmax ge 10 in order to converge the ground state wavefunction
The dimensions of the Hamiltonian matrix grow combinatorially with increasing Nmax andwith increasing atomic number A To gain a feeling for that explosive growth we plot in Fig3 the matrix dimension (D) for a wide range of Oxygen isotopes In each case we select therdquonatural parityrdquo basis space the parity that coincides with the lowest HO configuration for that
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
4
1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 4N
max = 6
Nmax
= 8N
max = 10
extrapolatedexpt
Be -- lowest natural parity states -- JISP16
preliminaryparity inversion
parity inversion
12-
(12-)
32-
32-
12+
12+
52+
52+
0+
0+
0+ 0
+
12+
52+
6 8 10 12 14total number of nucleons A
-70
-60
-50
-40
-30
grou
nd s
tate
ene
rgy
[M
eV]
Nmax
= 5N
max = 7
Nmax
= 9exptextrapolated
Be -- lowest unnatural parity states -- JISP16
preliminaryparity inversion
parity inversion
12+
(12-)
12+
2-
1-
1-
52-
3- 12
-
52-
12-
Figure 2 Lowest natural (left) and unnatural (right) states of Be isotopes obtained with theJISP16 NN potential Extrapolated results and their assessed uncertainties are presented as redpoints with error bars
obtained in that basis spaceIn small model spaces Nmax = 4 and 5 the calculations suggest a rdquoU-shapedrdquo curve for the
binding energy as function of A the number of nucleons whereas experimentally the groundstate energy keeps decreasing with A at least over the range in A shown in Fig 2 Howeveras one increases Nmax the calculated results get closer to the experimental values In order toobtain the binding energies in the full configuration space (NCFC) we can use an exponential fitto a set of results at 3 or 4 subsequent Nmax values [2] After performing such an extrapolationto infinite model space our calculated results follow the data very closely as function of A
In both panels of Fig 2 the dimensions increase dramatically as one increases Nmax
or increases atomic number A Detailed trends will be presented in the next section Theconsequence is that results terminate at lower A as one increases Nmax Additional calculationsare in process in order to reduce the uncertainties in the extrapolations
We note that the ground state spins are predicted correctly in all cases except A = 11 (andpossibly at A = 13 where the spin-parity of the ground state is not well known experimentally)where there is a reputed rdquoparity inversionrdquo In this case a state of rdquounnatural parityrdquo oneinvolving at least one particle moving up one HO shell from its lowest location unexpectedlybecomes the ground state While Fig 2 indicates we do not reproduce this parity inversion wedo notice however that the lowest states of natural and unnatural parity lie very close togetherThis indicates that small corrections arising from neglected effects such as three-body (NNN)potentials andor additional contributions from larger basis spaces could play a role here Weare continuing to investigate these improvements
4 Computer Science and Applied Math challenges
We outline the main factors underlying the need for improved approaches to solving the nuclearquantum many-body problem as a large sparse matrix eigenvalue problem Our goals requireresults as close to convergence as possible in order to minimize our extrapolation uncertaintiesAccording to current experience this requires the evaluation of the Hamiltonian in as large abasis as possible preferably with Nmax ge 10 in order to converge the ground state wavefunction
The dimensions of the Hamiltonian matrix grow combinatorially with increasing Nmax andwith increasing atomic number A To gain a feeling for that explosive growth we plot in Fig3 the matrix dimension (D) for a wide range of Oxygen isotopes In each case we select therdquonatural parityrdquo basis space the parity that coincides with the lowest HO configuration for that
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
4
1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

1E+0
1E+1
1E+2
1E+3
1E+4
1E+5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
12O
14O
16O
18O
20O
22O
24O
26O
28O
M-scheme matrix dimensionfor Oxygen Isotopes
Petascale
Exascale
Figure 3 Matrix dimension versus Nmax
for stable and unstable Oxygen isotopesThe vertical red line signals the boundarywhere reasonable convergence emergeson the right of it
1x100
1x101
1x102
1x103
1x104
1x105
1x106
1x107
1x108
1x109
1x1010
1x1011
1x1012
0 2 4 6 8 10 12 14
Ma
trix
Dim
en
sio
n
Nmax
6Li
10B
12C
16O
24Mg
28Si
32S
40Ca
2N
4N
3N
Figure 4 Matrix dimension versus Nmax
for a sample set of stable N=Z nuclei up toA = 40 Horizontal lines show expected limitsof Petascale machines for specific ranks of thepotentials (ldquo2Nrdquo=NN ldquo3Nrdquo=NNN etc)
nucleus The heavier of these nuclei have been the subject of intense experimental investigationand it is now believed that 28O is not a particle-stable nucleus even though it is expected tohave a doubly-closed shell structure according to the phenomenological shell model It wouldbe very valuable to have converged ab initio NCFC results for 28O to probe whether realisticpotentials are capable of predicting its particle-unstable character
We also include in Fig 3 the estimated range that computer facilities of a given scale canproduce results with our current algorithms As a result of these curves we anticipate wellconverged NCFC results for the first three isotopes of Oxygen will be achieved with Petascalefacilities since their curves fall near or below the upper limit of Petascale at Nmax = 10
Dimensions of the natural parity basis spaces for another set of nuclei ranging up to A = 40 areshown in Fig 4 In addition we include estimates of the upper limits reachable with Petascalefacilities depending on the rank of the potential It is important to note that theoreticallyderived 4N interactions are expected to be available in the near future Though relatively lessimportant than 2N and 3N potentials their contributions are expected to grow dramaticallywith increasing A
A significant measure of the computational burden is presented in Figs 5 and 6 wherewe display the number of non-zero many-body matrix elements as a function of the matrixdimension (D) These results are for representative cases and show a useful scaling property ForHamiltonians with NN potentials we find a useful fit F (D) for the non-zero matrix elementswith the function
F (D) = D + D1+12
14+ln D (1)
The heavier systems displayed tend to be slightly below the fit while the lighter systems areslightly above the fit The horizontal red line indicates the expected limit of the Jaguar facility(150000 cores) running one of these applications assuming all matrix elements and indices arestored in core By way of contrast we portray the more memory-intensive situation with NNNpotentials in Fig 6 where we retain the fitted curve of Fig 5 for reference The horizontal redline indicates the same limit shown in Fig 5
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
5
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10
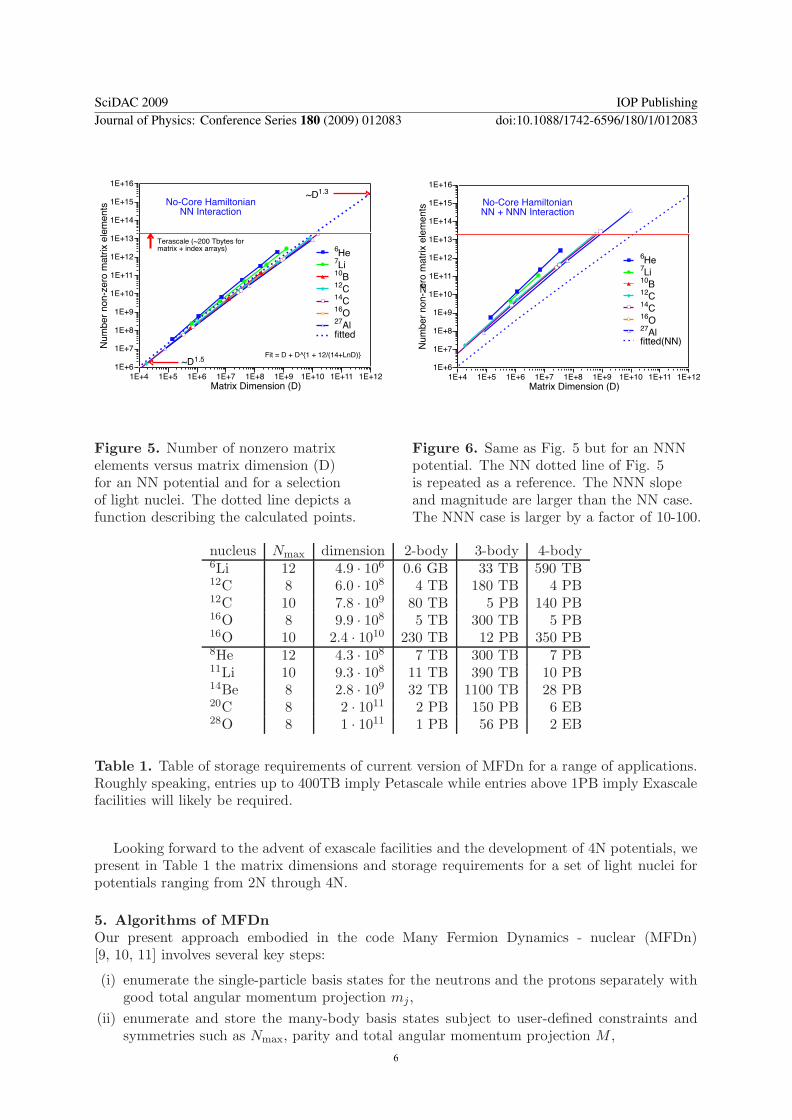
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
6He
7Li
10B
12C
14C
16O
27Al
fitted
Terascale (~200 Tbytes formatrix + index arrays)
Fit = D + D^1 + 12(14+LnD)
~D13
No-Core HamiltonianNN Interaction
~D15
Figure 5 Number of nonzero matrixelements versus matrix dimension (D)for an NN potential and for a selectionof light nuclei The dotted line depicts afunction describing the calculated points
1E+6
1E+7
1E+8
1E+9
1E+10
1E+11
1E+12
1E+13
1E+14
1E+15
1E+16
1E+4 1E+5 1E+6 1E+7 1E+8 1E+9 1E+10 1E+11 1E+12
Nu
mb
er
no
n-z
ero
ma
trix
ele
me
nts
Matrix Dimension (D)
No-Core HamiltonianNN + NNN Interaction
6He
7Li
10B
12C
14C
16O
27Al
fitted(NN)
Figure 6 Same as Fig 5 but for an NNNpotential The NN dotted line of Fig 5is repeated as a reference The NNN slopeand magnitude are larger than the NN caseThe NNN case is larger by a factor of 10-100
nucleus Nmax dimension 2-body 3-body 4-body6Li 12 49 middot 106 06 GB 33 TB 590 TB12C 8 60 middot 108 4 TB 180 TB 4 PB12C 10 78 middot 109 80 TB 5 PB 140 PB16O 8 99 middot 108 5 TB 300 TB 5 PB16O 10 24 middot 1010 230 TB 12 PB 350 PB8He 12 43 middot 108 7 TB 300 TB 7 PB11Li 10 93 middot 108 11 TB 390 TB 10 PB14Be 8 28 middot 109 32 TB 1100 TB 28 PB20C 8 2 middot 1011 2 PB 150 PB 6 EB28O 8 1 middot 1011 1 PB 56 PB 2 EB
Table 1 Table of storage requirements of current version of MFDn for a range of applicationsRoughly speaking entries up to 400TB imply Petascale while entries above 1PB imply Exascalefacilities will likely be required
Looking forward to the advent of exascale facilities and the development of 4N potentials wepresent in Table 1 the matrix dimensions and storage requirements for a set of light nuclei forpotentials ranging from 2N through 4N
5 Algorithms of MFDn
Our present approach embodied in the code Many Fermion Dynamics - nuclear (MFDn)[9 10 11] involves several key steps
(i) enumerate the single-particle basis states for the neutrons and the protons separately withgood total angular momentum projection mj
(ii) enumerate and store the many-body basis states subject to user-defined constraints andsymmetries such as Nmax parity and total angular momentum projection M
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
6
Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

Figure 7 MFDn scheme for distributing thesymmetric Hamiltonian matrix over n(n + 1)2PErsquos and partitioning the Lanczos vectors Weuse n = 5 rdquodiagnonalrdquo PErsquos in this illustration
Figure 8 MFDn scheme for performing theLanczos iterations based on the Hamiltonianmatrix stored in n(n + 1)2 PErsquos We usen = 4 rdquodiagnonalrdquo PErsquos in this illustration
(iii) evaluate and store the many-nucleon Hamiltonian matrix in this many-body basis usinginput files for the NN (and NNN interaction if elected)
(iv) obtain the lowest converged eigenvalues and eigenvectors using the Lanczos algorithm witha distributed re-orthonormalization scheme
(v) transform the converged eigenvectors from the Lanczos vector space to the original basisand store them in a file
(vi) evaluate a suite of experimental observables using the stored eigenvectors
All these steps except the first which does not require any significant amount of CPU timeare parallelized using MPI Fig 7 presents the allocation of processors for computing andstoring the many-body Hamiltonian on n(n + 1)2 processors (We illustrate the allocationwith 15 processors so the pattern is clear for an arbitrary value of n) We assume a symmetricHamiltonian matrix and computestore only the lower triangle
In step two the many-body basis states are round-robin distributed over the n diagonalprocessors Each vector is also distributed over n processors so we can (in principle) deal witharbitrary large vectors Because of the round-robin distribution of the basis states we obtainexcellent load-balancing however the price we pay is that any structure in the sparsity patternof the matrix is lost We have implemented multi-level blocking procedures to enable an efficientdetermination of the non-zero matrix elements to be evaluated These procedures have beenpresented recently in Ref [11]
After the determination and evaluation of the non-zero matrix elements we solve for thelowest eigenvalues and eigenvectors using an iterative Lanczos algorithm step four The matvecoperation and its communication patterns for each Lanczos iteration is shown in Fig 8 wheretwo sets of operations account for the storage of only the lower triangle of the matrix
MFDn also employs a distributed re-orthonormalization technique developed specifically forthe parallel distribution shown in Fig 7 After the completion of the matvec the new elementsof the tridiagonal Lanczos matrix are calculated on the diagonals The (distributed) normalizedLanczos vector is then broadcast to all processors for further processing Each previouslycomputed Lanczos vector is stored on one of (n + 1)2 groups of n processors Each group
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
7
receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

receives the new Lanczos vector computes the overlaps with all previously stored vectors withinthat group and constructs a subtraction vector that is the vector that needs to be subtractedfrom the Lanczos vector in order to orthogonalize it with respect to the Lanczos vectors storedin that group These subtraction vectors are accumulated on the n diagonal processors wherethey are subtracted from the current Lanczos vector Finally the orthogonalized Lanczos vectoris re-normalized and broadcast to all processors for initiating the next matvec One group isdesignated to also store that Lanczos vector for future re-orthonormalization operations
The results so far with this distributed re-orthonormalization appear stable with respect tothe number of processors over which the Lanczos vectors are stored We can keep a considerablenumber of Lanczos vectors in core since all processors are involved in the storage and eachpart of a Lanczos vector is stored on one and only one processor For example we have run5600 Lanczos iterations on a matrix with dimension 595 million and performed the distributedre-orthonormalization using 80 groups of stored Lanczos vectors We converged about 450eigenvalues and eigenvectors Tests of the converged states such as measuring a set of theirsymmetries showed they were reliable No converged duplicate eigenstates were generated Testcases with dimensions of ten to forty million have been run on various numbers of processorsto verify the strategy produces stable results independent of the number of processors A keyelement for the stability of this procedure is that the overlaps and normalization are calculatedin double precision even though the vectors (and the matrix) are stored in single precisionFurthermore there is of course a dependence on the choice of initial pivot vector we favor arandom initial pivot vector
6 Accelerating convergence
We are constantly seeking new ideas for accelerating convergence as well as saving memory andCPU time The situation is complicated by the wide variety of strong interaction Hamiltoniansthat we employ and we must simultaneously investigate theoretical and numerical methods forrdquorenormalizingrdquo (softening) the potentials Softening an interaction reduces the magnitude ofmany-body matrix elements between very different basis states such as those with very differenttotal numbers of HO quanta However all methods to date soften the interactions at theprice of increasing their complexity For example starting with a strong NN interaction onerenormalizes it to improve the convergence of the many-body problem with the softened NNpotential [12] but in the process one induces a new NNN potential that is required to keepthe final many-body results invariant under renormalization In fact 4N potentials and higherare also induced[7] Given the computational cost of these higher-body potentials in the many-body problem as described above it is not clear how much one gains from renormalization -for some NN interactions it may be more efficient to attempt larger basis spaces and avoid therenormalization step This is a current area of intense theoretical research
In light of these features of strongly interacting nucleons and the goal to proceed to heaviernuclei it is important to investigate methods for improving convergence A number of promisingmethods have been proposed and each merits a significant research effort to assess their valueover a range of nuclear applications A sample list includes
bull Symplectic no core shell model (SpNCSM) - extend basis spaces beyond their current Nmax
limits by adding relatively few physically-motivated basis states of symplectic symmetrywhich is a favored symmetry in light nuclei [13]
bull Realistic single-particle basis spaces [14]
bull Importance truncated basis spaces [15]
bull Monte Carlo sampling of basis spaces [16 17]
bull Coupled total angular momentum J basis space
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
8
Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

Se
tup
Ba
sis
Eva
lua
te H
50
0 L
an
czo
s
Su
ite
Ob
se
rvs
IO
TO
TA
L
0
1000
2000
3000
4000
5000
6000
Op
tim
alT
ime
(se
cs)
on
Fra
nklin
49
50
pe
s
V10-B05 April 2007V12-B00 October 2007V12-B01 April 2008V12-B09 January 2009
13C Chiral NN+NNN -- N
max= 6 Basis Space
MFDn Version Date
Figure 9 Performance improvement ofMFDn over a 2 year span displayed formajor sections of the code
0x100
5x106
10x106
15x106
20x106
25x106
30x106
35x106
2000 4000 6000 8000
To
tal C
PU
Tim
e (
Se
cs)
Number of Cores
V10-B05V12-B00V12-B01V12-B09
Figure 10 Total CPU time for the same testcases evaluated in Fig 9 running on variousnumbers of Franklin cores
Several of these methods can easily be explored with MFDn For example while MFDnhas some components that are specific for the HO basis it is straightforward to switch toanother single-particle basis with the same symmetries but with different radial wavefunctionsAlternative truncation schemes such as Full Configuration Interaction (FCI) basis spaces are alsoimplemented and easily switched on by appropriate input data values These flexible featureshave proven convenient for addressing a wide range of physics problems
There are additional suggestions from colleagues that are worth exploring as well such as theuse of wavelets for basis states These suggestions will clearly involve significant research effortsto implement and assess
7 Performance of MFDn
We present measures of MFDn performance in Figs 9 and 10 Fig 9 displays the performancecharacteristics of MFDn from the beginning of the SciDAC-UNEDF program to the presentroughly a 2 year time span Many of the increments along the path of improvements have beendocumented [11 18 19]
Fig 9 displays the timings for major sections of the code as well as the total time for atest case in 13C using a NNN potential on 4950 Franklin processors The timings are specifiedfor MFDn versions that have emerged during the SciDAC-UNEDF program The initial versiontested V10-B05 represents a reasonable approximation to the version prior to SciDAC-UNEDFWe note that the overall speed has improved by about a factor of 3 Additional effort is neededto further reduce the time to evaluate the many-body Hamiltonian H and to perform the matvecoperations as the other sections of the code have undergone dramatic time reductions
We present in Fig 10 one view of the strong scaling performance of MFDn on Franklin Herethe test case is held fixed at the case shown in Fig 9 and the number of processors is varied from2850 to 7626 Due to memory limitations associated with the very large input NNN data file(3 GB) scaling is better than ideal at (relatively) low processor numbers At the low end thereis significant redundancy of calculations since the entire NNN file cannot fit in core and mustbe processed in sections As one increases the number of processors more memory becomesavailable for the NNN data and less redundancy is incurred At the high end the scaling beginsto show signs of deteriorating due to increased communications time relative to computations
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
9
The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10

The net result is the dip in the middle which we can think of as the rdquosweet spotrdquo or the idealnumber of processors for this application Clearly this implies significant preparation work forlarge production runs to insure maximal efficiency in the use of limited computational resourcesFor the largest feasible applications this also implies there is high value to finding a solutionfor the redundant calculations brought about by the large input files We are currently workingon a hybrid OpenMPMPI version of MFDn which would significantly reduce this redundancyHowever at the next model space the size of the input file increases to 33 GB which we needto process in sections on Franklin
8 Conclusions and Outlook
Microscopic nuclear structurereaction physics is enjoying a resurgence due in large part tothe development and application of ab initio quantum many-body methods with realistic stronginteractions True predictive power is emerging for solving long-standing fundamental problemsand for influencing future experimental programs
We have focused on the no core shell model (NCSM) and the no core full configuration(NCFC) approaches and outlined our recent progress Large scale applications are currentlyunderway using leadership-class facilities and we expect important progress on the path todetailed understanding of complex nuclear phenomena
We have also outlined the challenges that stand in the way of further progress More efficientuse of memory faster IO and faster eigensolvers will greatly aid our progress
Acknowledgments
This work was supported in part by DOE grants DE-FC02-09ER41582 and DE-FG02-87ER40371 Computational resources are provided by DOE through the National EnergyResearch Supercomputer Center (NERSC) and through an INCITE award (David Dean PI)at Oak Ridge National Laboratory and Argonne National Laboratory
References[1] P Navratil J P Vary and B R Barrett Phys Rev Lett 84 5728 (2000) Phys Rev C 62 054311 (2000)[2] P Maris J P Vary and A M Shirokov Phys Rev C 79 014308(2009) arXiv 08083420[3] P Navratil JP Vary WE Ormand BR Barrett Phys Rev Lett 87 172502(2001)[4] E Caurier P Navratil WE Ormand and JP Vary Phys Rev C 66 024314(2002) A C Hayes P Navratil
and J P Vary Phys Rev Lett 91 012502 (2003)[5] A Negret et al Phys Rev Lett 97 062502 (2006)[6] S Vaintraub N Barnea and D Gazit nucl-th 09031048[7] P Navratil V G Gueorguiev J P Vary W E Ormand and A Nogga Phys Rev Lett 99 042501(2007)
nucl-th 0701038[8] A M Shirokov J P Vary A I Mazur and T A Weber Phys Letts B 644 33(2007) nucl-th0512105[9] JP Vary The many-fermion dynamics shell-model code 1992 unpublished[10] JP Vary and DC Zheng The many-fermion dynamics shell-model code ibid 1994 unpublished[11] P Sternberg EG Ng C Yang P Maris JP Vary M Sosonkina and H V Le Accelerating
Configuration Interaction Calculations for Nuclear Structure Conference on High Performance Networkingand Computing IEEE Press Piscataway NJ 1-12 DOI= httpdoiacmorg10114514133701413386
[12] S K Bogner R J Furnstahl P Maris R J Perry A Schwenk and J P Vary Nucl Phys A 801 21(2008) [arXiv07083754 [nucl-th]
[13] T Dytrych KD Sviratcheva C Bahri JP Draayer and JP Vary Phys Rev Lett 98 162503 (2007)Phys Rev C 76 014315 (2007) J Phys G 35 123101 (2008) and references therein
[14] A Negoita to be published[15] R Roth and P Navratil Phys Rev Lett 99 092501 (2007)[16] WE Ormand Nucl Phys A 570 257(1994)[17] M Honma T Mizusaki and T Otsuka Phys Rev Lett 77 3315 (1996) [arXivnucl-th9609043][18] M Sosonkina A Sharda A Negoita and JP Vary Lecture Notes in Computer Science 5101 Bubak M
Albada GDv Dongarra J Sloot PMA (Eds) pp 833 842 (2008)[19] N Laghave M Sosonkina P Maris and JP Vary paper presented at ICCS 2009 to be published
SciDAC 2009 IOP PublishingJournal of Physics Conference Series 180 (2009) 012083 doi1010881742-65961801012083
10