a quick tour of autonomic computing
DESCRIPTION
TRANSCRIPT

A quick tour of Autonomic ComputingSkill Level: Introductory
Daniel WordenAuthor
Nicholas ChaseAuthor
07 Apr 2004
Autonomic computing architecture is a range of software technologies that enableyou to build an information infrastructure that can, to lesser and greater degrees,manage itself, saving countless hours (and dollars) in human management. And allthis without giving up control of the system. This tutorial explains the concepts behindautonomic computing and looks at the tools at your disposal for making it happen -today.
Section 1. Before you start
About this tutorial
This tutorial explains the general concepts behind autonomic computingarchitectures, including control loops and autonomic-managed resources. It alsodiscusses the various tools that are currently available within the IBM AutonomicComputing Toolkit, providing a concrete look at some of the tasks you canaccomplish with it.
The tutorial covers:
• Autonomic computing concepts
• Contents of the IBM Autonomic Computing Toolkit
• Installing applications using solution installation and deploymenttechnologies
• Application administration using the Integrated Solutions Console
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 1 of 27

• Problem determination using the Generic Log Adapter and the Log andTrace Analyzer
• A brief look at Common Base Events
• Autonomic management using the Autonomic Management Engine(AME)
• AME Resource Models and a brief look at programming using AME
When you have completed this tutorial, you should feel comfortable looking furtherinto any of these topics, while understanding their place in the autonomic computinginfrastructure.
This tutorial is for developers who not only want to understand the concepts behindautonomic computing architectures, but who also want begin implementingautonomic computing solutions in their applications with the help of the IBMAutonomic Computing Toolkit.
Although this tutorial is aimed at developers, no actual programming is required inorder to get the full value from it. When present, code samples are shown using theJava language, but an in-depth understanding of the code is not required to gaininsight into the concepts they illustrate.
Prerequisites
This tutorial doesn't actually require you to install any tools, but it does look at thefollowing autonomic computing bundles, available from developerWorks at:http://www.ibm.com/developerworks/autonomic/probdet1.html.
• Autonomic Management Engine
• Resource Model Builder
• Integrated Solutions Console
• Solution installation and deployment scenarios
• Generic Log Adapter and Log and Trace Analyzer Tooling
• Generic Log Adapter Runtime and Rule Sets
• Problem Determination Scenario
• Eclipse Tooling
Section 2. What is autonomic computing?
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 2 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

The current state of affairs
As long-time developers, we've found that the number one most underestimatedarea of software development is maintenance. Everybody wants to build theapplication, but once it's out there, developers just want to forget about it. They tendnot to think about the administrators who have to spend hours and days and evenweeks configuring their systems for the software to work right, or to preventproblems such as full drives and bad equipment. As a general rule, a developer isonly worried about what needs to be done to the system to install his or her ownproduct; the effects on other, previously installed products are frequently overlooked.What's more, optimizing a setup can be a risky process, with changes made in onearea causing problems in another. Management of multiple systems usually meanslearning several different management applications.
How many hours, and by extension dollars (or Euros, or yen, or rupees) areconsumed just keeping software up and running? Surely there are more productivethings these human resources can be doing, such as planning to make the businessrun better?
In short, there's a need in today's computing infrastructure for a better way to dothings. One way to reach that goal is through autonomic computing technology.
Where we want to go
A system built on autonomic computing concepts tries to eliminate much of thatpotentially wasted or duplicated effort. Look at the current state of affairs, but thistime, consider how to apply the principles of autonomic computing technology.
First, the software installation process should truly be a one-click process. Thesoftware would know not only what dependencies must be fulfilled for its ownoperation, but also how to get those dependencies met if the system didn't alreadyhave them in place. Examples would include such things as downloading operatingsystem patches and provisioning additional drive space. The install would know howto avoid conflicts with already deployed applications. Once installed, it would bemanaged from a single, common, management interface used for all applications.After the software was up and running, it would consistently monitor itself and theenvironment for problems. When detected, it would determine the source of the errorand resolve it. All of this would be managed from a consolidated point, so the CEOor system administrator could see at a glance who had access to what, even thoughresources might be spread over multiple applications, platforms and locations.
In other words, you're looking for a system that is self-configuring, self-healing,self-protecting, and self-optimizing. So how do you get it?
Autonomic infrastructure
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 3 of 27

In order to create such a system, you've got to create an infrastructure that enablesa system to monitor itself and take action when changes occur. To accomplish that,an autonomic computing solution is made up of a an autonomic manager andmanaged resources. The autonomic manager and the managed resources talk toeach other using the standard Sensor and Effector APIs delivered through themanaged resource touchpoint.
The managed resources are controlled system components that can range fromsingle resources such as a server, database server, or router to collections ofresources like server pools, clusters, or business applications.
The autonomic manager implements autonomic control loops by dividing them intofour parts: monitor, analyze, plan, and execute. The control loop carries out tasks asefficiently as possible based on high-level policies.
• Monitor: Through information received from sensors, the resourcemonitors the environment for specific, predefined conditions. Theseconditions don't have to be errors; they can be a certain load level or typeof request.
• Analyze: Once the condition is detected, what does it mean? Theresource must analyze the information to determine whether actionshould be taken.
• Plan: If action must be taken, what action? The resource might simplynotify the administrator, or it might take more extensive action, such asprovisioning another hard drive.
• Execute: It is this part of the control loop that sends the instruction to theeffector, which actually affects or carries out the planned actions.
Figure 1. Autonomic control loops
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 4 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.
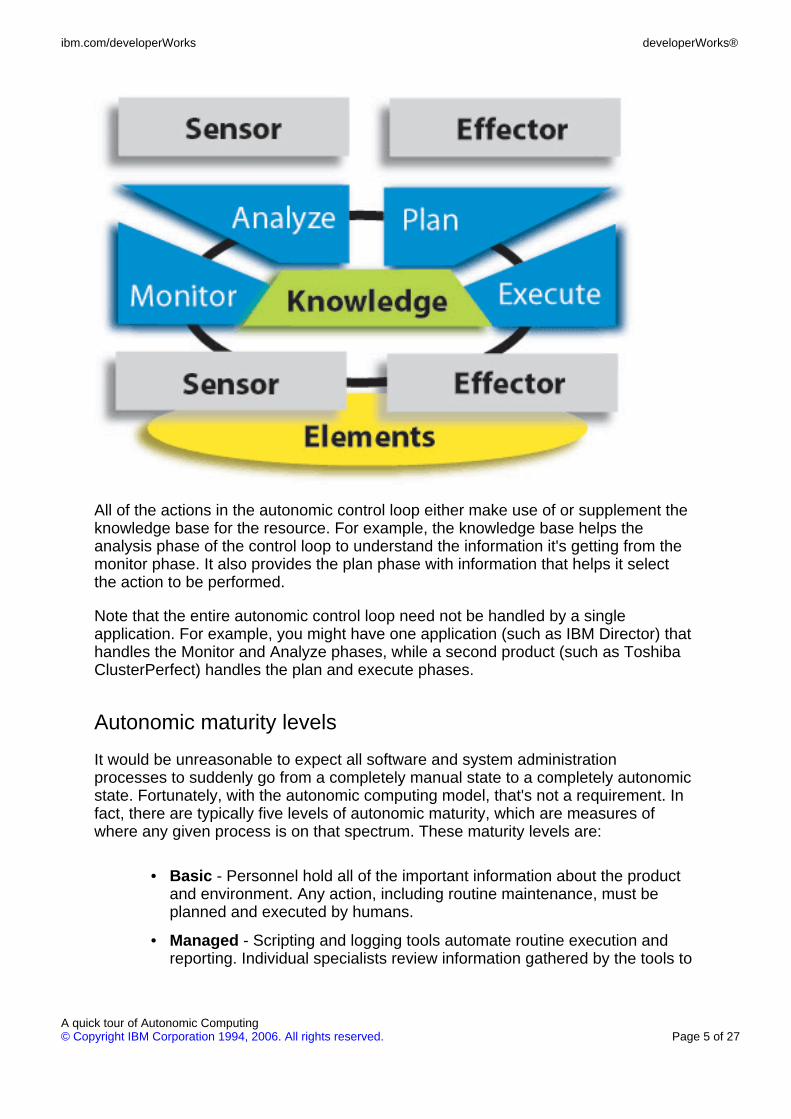
All of the actions in the autonomic control loop either make use of or supplement theknowledge base for the resource. For example, the knowledge base helps theanalysis phase of the control loop to understand the information it's getting from themonitor phase. It also provides the plan phase with information that helps it selectthe action to be performed.
Note that the entire autonomic control loop need not be handled by a singleapplication. For example, you might have one application (such as IBM Director) thathandles the Monitor and Analyze phases, while a second product (such as ToshibaClusterPerfect) handles the plan and execute phases.
Autonomic maturity levels
It would be unreasonable to expect all software and system administrationprocesses to suddenly go from a completely manual state to a completely autonomicstate. Fortunately, with the autonomic computing model, that's not a requirement. Infact, there are typically five levels of autonomic maturity, which are measures ofwhere any given process is on that spectrum. These maturity levels are:
• Basic - Personnel hold all of the important information about the productand environment. Any action, including routine maintenance, must beplanned and executed by humans.
• Managed - Scripting and logging tools automate routine execution andreporting. Individual specialists review information gathered by the tools to
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 5 of 27

make plans and decisions.
• Predictive - As preset thresholds are tripped, the system raises earlywarning flags and recommends appropriate actions from the knowledgebase. The centralized storage of common occurrences and experiencealso leverages the resolution of events.
• Adaptive - Building on the predictive capabilities, the adaptive system isempowered to take action based on the situation.
• Autonomic - Policy drives system activities, including allocation ofresources within a prioritization framework and acquisition of prerequisitedependencies from outside sources.
Most systems today are at the basic or managed level, though there are, of course,exceptions. Take a look at areas in which systems most need improvement, and thetools that can makes this possible.
The Autonomic Computing Toolkit
To make it easier to develop an autonomic solution, IBM has put together theAutonomic Computing Toolkit. Strictly speaking, this is not a single toolkit, but ratherseveral "bundles" of applications intended to work together to produce a completesolution. These bundles include:
• Autonomic Management Engine
• Resource Model Builder
• Integrated Solutions Console
• Solution installation and deployment
• Generic Log Adapter and Log and Trace Analyzer
You can use each of these tools individually, or you can combine them for a largerscope solution. In fact, the toolkit also includes a number of "scenarios" thatdemonstrate the use of some of these applications and their integration, including:
• Problem Determination Scenario
• Solution installation and deployment scenario using ISSI
• Solution installation and deployment scenario using InstallAnywhere
• Solution installation and deployment samples scenario
The toolkit also includes the Autonomic Computing Information bundle, whichincludes much of the available documentation for the other bundles.
If you do not already have Eclipse 3.0 or higher, the toolkit provides an EclipseTooling bundle that includes Eclipse runtimes needed by toolkit components.
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 6 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

Now, take a look at what these bundles provide.
Installation and administration
Before you even think about problem resolution (which we'll talk about next) asoftware application has to be up and running. That means installation andconfiguration. We'll start with installation.
The solution installation and deployment capabilities that come with the IBMAutonomic Computing Toolkit enable you to build an installation engine that candetect missing dependencies and take action. It also tracks the applications thathave been installed and their dependencies, so subsequent installs - and uninstalls-- don't step on each other, even if they come from different vendors. (As long asthey're all autonomically aware, of course.) It does that by maintaining a database ofconditions, and checking it before performing the installation. It also communicateswith the platform through touchpoints . These server-specific interfaces provide dataon available resources, installed components, and their relationships. Touchpointsare a key enabler for autonomic dependency checking. For more information on thedependency checker that comes with the solution installation and deploymenttechnologies, see Installing a solution .
Once you've installed the software, you'll need to administer it. Rather than forcingyou to learn a new management console for every application, the IBM AutonomicComputing Toolkit provides the Integrated Solutions Console. This console is basedon a portal infrastructure, so any autonomically aware application can installcomponents for the administrator to use within this single console. The IntegratedSolutions Console also provides for centralized permissions management throughaccess to a credential vault. In this way, single sign-on, system access, andadmnistration can be consolidated and controlled for multiple servers. For moreinformation on the Integrated Solutions Console, see The Integrated SolutionsConsole.
Problem determination and analysis
The software is installed, configured, and running. This is of course when somethinggoes horribly wrong. With the old way of doing things, you'd have to sort throughpossibly megabytes of log files looking for something you personally might not evenrecognize. In an autonomic solution, events such as log entries are presented in acommon form (the Common Base Events format), correlated into a situation, andcompared to a symptom database to determine the problem and potential actions.
To accomplish all that, the Autonomic Computing Toolkit includes the Generic LogAdapter (GLA) and the Log and Trace Analyzer. The GLA converts logs from legacyapplications into Common Base Events that can then be read by the LTA. The LTAconsults a symptom database to correlate the events, identify the problem, andperform the actions prescribed for that problem. For more information on these tools,see The Generic Log Adapter.
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 7 of 27

Analysis can take place in a number of ways. For example, you might writeJavaBeans or other code to analyze events and situations.
Or you might find it simpler to use a tool that performs much of the analysis for you,such as the Autonomic Management Engine.
Monitoring and centralized management
The Autonomic Management Engine (AME) is meant to be a fairly self-containedautonomic computing solution, in that it can monitor the environment and anapplication, analyze any conditions that surface, plan a response, and execute it. Itis an extensive monitoring engine that uses resource models as its source ofinformation. A resource model tells AME what to look for, such as the termination ofa process or a particular log event, yet because it is flexible, AME can monitor anyapplication. All you need to do is provide an appropriate resource model.
To do that, you can use the IBM Autonomic Computing Toolkit's Resource ModelBuilder, which is a plugin for the Eclipse IDE.
Optimization and other issues
Some areas of the autonomic computing vision are not yet available as part of thisversion of the IBM Autonomic Computing Toolkit, but can be realized usingindependent products. For example, a major goal of autonomic computingtechnology is to create a system that is self-optimizing. An orchestration productsuch as IBM Tivoli#173; Intelligent ThinkDynamic Orchestrator lets you monitor theoverall system using autonomic computing concepts to determine when an actionneeds to be taken. The Orchestrator then takes appropriate action as defined by theadministrator or per business policy.
You can also provide for autonomic management of provisioning issues such asallocating or deallocating servers based on the relative loads of applications andtheir importance using a product such as Adaptive Replacement Cache from IBM,which yields significant performance increases over least-recently-used (LRU)caching strategies.
Whether you are coding multiserver load balancing applications, or simply lookingfor ways to improve database query performance, the autonomic computing modelfrom IBM provides tools and techniques to move your code to the next level ofautonomic maturity.
Another goal of autonomic computing technology is heterogeneous workloadmanagement, in which the entire application as a whole can be optimized. Oneexample would be a system that includes a web application server, a databaseserver, and remote data storage. Heterogeneous workload management makes itpossible to find bottlenecks in the overall system and resolve them. Products suchas the Enterprise Workload Manager (EWLM) component of the IBM VirtualizationEngine provide hetergeneous workload management capabilities. They enable you
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 8 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

to automatically monitor and manage multi-tiered, distributed, heterogeneous orhomogeneous workloads across an IT infrastructure to better achieve definedbusiness goals for end-user services.
Now, take a closer look at the tools that make up the Autonomic Computing Toolkit.
Section 3. Installing a solution
What solution installation and deployment technologies do
When you install a software package, you generally have three goals:
• Satisfy any dependencies or prerequisites
• Install the actual software
• Don't break anything that already works
This last goal is often the toughest part. With today's complex software, versionconflicts often cause problems. Solution installation and deployment technologiessolve many of these problems by maintaining a database of software that's alreadybeen installed and the relevant dependencies.
When you first attempt to install a new piece of software, the solution installation anddeployment technologies check to see if the prerequisites are met by using webservices to access "touchpoints," which provide information such as the availableRAM and disc space, operating system, and so on. It also checks the database ofinstalled software for other required applications, as well as checking to make surethat installing this new application isn't going to conflict with prerequisites for anyexisting applications.
When the installation is complete, the details of the new application are added to thesolution installation and deployment database so that all the information is availablefor the next install.
This information also comes in handy when you attempt to uninstall a softwaresolution; a central database of prerequisites makes it easier to know what you canand cannot safely delete.
Installable units
The first thing to understand about solution installation and deployment is that thereare two major pieces involved. The first is the actual installer. This is theinfrastructure that includes the installation database and the code that interprets and
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 9 of 27

executes the actions specified in the package itself. The second is the package offiles to be installed.
And what about this package? What is it?
Depending on the situation, a package can consist of a solution module (SM), whichcan contain other solution modules as well as one or more container installableunits. A container installable unit (CIU) can contain zero or more other containerinstallable units, and one or more smallest installable units. The smallest installableunit is exactly what it sounds like: a single piece of software that includes files to becopied to the target system.
It's important to understand that only the SIU contains actual physical files or groupsof files. The CIU and SM are concepts, specified in the Installable Unit's deploymentdescriptor. This is an XML file that includes information on dependencies and onactions that must take place in order for the software to be successfully installed.
Let's look at the process of creating a simple package to be installed via the solutioninstallation and deployment environment.
Create a package
Creating the package of software to install entails the following basic steps:
• Install the solution installation and deployment bundle.
• Install the Solution Module Descriptor plug-in for Eclipse. (This is aconvenience step; the descriptor is simply an XML file, so you can createit with a text editor, but it's complex so you're better off using an editorthat understands its structure.)
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 10 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.
• Create a project that includes the actual files to install. This may be asstraightforward as a text file or as complex as WebSphere Portal. In anycase, this project is independent of any solution installer files; it's just theapplication itself and the application becomes the smallest installable unit.
• Create the deployment descriptor. This step includes the following tasks:
• Create the container installable unit.
• Add the SIU to the CIU.
• Set any SIU dependencies.
• Add actions such as "add file" from the packaged ZIP file to the filesystem.
• Set parameters such as install_dir.
• Set the target, including operating system information.
The descriptions here are intended only to give you an overview of what's involved.For a complete look at creating a solution module and deploying it, see the solutioninstallation and deployment tutorial. (A link is available in Resources.)
A sample descriptor
When you're done, you'll have a deployment descriptor something like this one,abridged from the InstallShield for Multiplatforms scenario:<?xml version="1.0" encoding="UTF-8"?><com.ibm.iudd.schemas.smd:rootIUxmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:com.ibm.iudd.schemas.os.container.actions=
"http://www.ibm.com/IUDD/schemas/OSContainerActions"xmlns:com.ibm.iudd.schemas.smd="http://www.ibm.com/IUDD/schemas/SMD">
<solutionModule IUname="Sample Install"><IUdefinition><identity>
<name>Sample Install</name><UUID>123456789012345678901234567</UUID><version lev="4" ver="0"/><displayName language_bundle="Sample.properties">
<short_default_text key="SAMPLE">"SampleInstall"</short_default_text>
<long_default_text key="Sample_Install_DEMO">"SampleInstall Demonstration"</long_default_text>
</displayName><manufacturer>
<short_default_text key="IBM">"IBM"</short_default_text>
<long_default_text key="IBM">"IBM"</long_default_text>
</manufacturer></identity>
</IUdefinition>
<variables><variable name="install_from_path">
<parameter defaultValue="install/setup"/><description>
<short_default_text key="JAVA_FROM_PATH">"Getting SI demo files from path:"
</short_default_text>
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 11 of 27

</description></variable><variable name="install_dir">
<parameter defaultValue="/SIDemo"/><description>
<short_default_text key="JAVA_TO_PATH">"Installing SI Demo to directory:"
</short_default_text></description>
</variable></variables>
<installableUnit><CIU IUname="WAS_Express_5_0" type=
"http://w3.ibm.com/namespaces/2003/OS_componentTypes:MicrosoftWindows"><IUdefinition>
<identity><name> WAS Express 5.0.2</name><UUID>123456789012345678901234501</UUID><version mod="6" rel="0" ver="4"/><displayName>
<short_default_text key="WASExpress">"WAS Express5.0.2"</short_default_text>
</displayName><manufacturer>
<short_default_text key="IBM_WAS">"IBM WAS ExpressGroup"</short_default_text>
</manufacturer></identity>
</IUdefinition><variables>
<variable name="ibm_install_from_path"><parameter defaultValue="install/setup/WAS_Exp"/><description>
<short_default_text key="INSTALL_FROM_PATH">"Installing WAS Express from path: "</short_default_text>
</description></variable><variable name="ibm_install_drive"><parameter defaultValue="$(install_drive)"/><description>
<short_default_text key="INSTALL_TO_DRIVE">"Installing WAS Express on drive: "</short_default_text>
</description></variable>
</variables><installableUnit>
<SIU IUname="WAS_Express_Application_Server" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:MicrosoftWindows">
<IUdefinition><identity>
<name>J2EE Servlet Container</name><UUID>123456789012345678901234502</UUID><version rel="0" ver="1"/><displayName>
<short_default_text key="J2EE_SERV">"J2EE Servlet Container"</short_default_text>
</displayName><manufacturer>
<short_default_text key="IBM_WAS">"WAS"</short_default_text>
</manufacturer></identity><checks>
<capacity checkVarName="J2EE_Serv_Processor_Speed"type="minimum">
<description><short_default_text key="CHECK_CPU"
>"Checking CPU speed..."</short_default_text></description><propertyName>Processor</propertyName><value>100</value>
</capacity><consumption checkVarName="J2EE_Serv_Memory">
<description><short_default_text key="CHECK_RAM"
>"Checking available RAM..."</short_default_text>
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 12 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

</description><propertyName>TotalVisibleMemorySize</propertyName><value>128</value>
</consumption><consumption checkVarName="J2EE_Serv_Disk_Space">
<description><short_default_text key="CHECK_DSK"
>"Checking available disk space..."</short_default_text></description><propertyName>Partition</propertyName><value>18.5</value>
</consumption>
<custom customCheckIdRef="AFileExistsCheck"checkVarName="True_File_Check">
<parameter variableNameRef="classpath">.</parameter><parameter variableNameRef="filename">.</parameter>
</custom>
<custom customCheckIdRef="AFileExistsCheck"checkVarName="False_File_Check">
<parameter variableNameRef="classpath">.</parameter><parameter variableNameRef="filename"
>/Dummy.txt</parameter></custom>
</checks><requirements>
<requirement name="J2EE_Serv_Requirements"operations="InstallConfigure">
<alternative><checkItem checkVarName="J2EE_Serv_Processor_Speed"
/><checkItem checkVarName="J2EE_Serv_Memory"/><checkItem checkVarName="J2EE_Serv_Disk_Space"/>
<checkItem checkVarName="True_File_Check"/><checkItem checkVarName="False_File_Check"/>
</alternative></requirement>
</requirements></IUdefinition><variables>
<variable name="J2EE_Serv_Processor_Speed"/><variable name="J2EE_Serv_Memory"/><variable name="J2EE_Serv_Disk_Space"/><variable name="True_File_Check"/><variable name="False_File_Check"/><variable name="Filename"/>
</variables><unit xsi:type=
"com.ibm.iudd.schemas.os.container.actions:OsActionGroup"><actions>
<addDirectory sequenceNumber="0" add="true"descend_dirs="true">
<destination>$(ibm_install_dir)/WAS Express5.0</destination>
</addDirectory><addDirectory sequenceNumber="0" add="true"
descend_dirs="true"><destination>$(ibm_install_dir)/WAS Express
5.0/bin</destination><source>
<source_directory>$(ibm_install_from_path)/was/bin</source_directory>
</source></addDirectory><addDirectory sequenceNumber="1" add="true"
descend_dirs="true"><destination>$(ibm_install_dir)/WAS Express
5.0/classes</destination></addDirectory><addDirectory sequenceNumber="2" add="true"
descend_dirs="true"><destination>$(ibm_install_dir)/WAS Express
5.0/config</destination>
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 13 of 27

<source><source_directory
>$(ibm_install_from_path)/was/config</source_directory></source>
</addDirectory></actions>
</unit></SIU>
</installableUnit><installableUnit>
<SIU IUname="Common_WAS_Express_Libraries" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:MicrosoftWindows">
<IUdefinition><identity>
<name>Common WAS Express Libraries</name><UUID>123456789012345678901234503</UUID><version mod="6" rel="0" ver="4"/><displayName>
<short_default_text key="WAS_LIB">"Common WASExpress Libraries"</short_default_text>
</displayName><manufacturer>
<short_default_text key="IBM_WAS">"WASExpress"</short_default_text>
</manufacturer></identity>
</IUdefinition><unit xsi:type=
"com.ibm.iudd.schemas.os.container.actions:OsActionGroup"><actions>
<addDirectory sequenceNumber="0" add="true"descend_dirs="true">
<destination>$(ibm_install_dir)/WAS Express5.0/lib</destination>
<source><source_directory>$(ibm_install_from_path)/was/lib</source_directory>
</source></addDirectory>
</actions></unit>
</SIU></installableUnit>
</CIU><target>OperatingSystem</target>
</installableUnit></solutionModule><rootInfo>
<schemaVersion mod="1" rel="1" ver="1"/><build>0</build><size>0</size>
</rootInfo><customChecks>
<customCheck customCheckId="AFileExistsCheck"><invocation_string>java -cp $(classpath) FileExists $(filename)</invocation_string><std_output_file>AFileExistsCheck.out</std_output_file><std_error_file>AFileExistsCheck.err</std_error_file><completion_block>
<return_code to="0" from="0"><severity>SUCCESS</severity>
</return_code><return_code to="1" from="2">
<severity>FAILURE</severity></return_code>
</completion_block><working_dir>.</working_dir><timeout>100</timeout>
</customCheck></customChecks><topology>
<target id="OperatingSystem" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:Operating_System"/>
<target id="WindowsTarget" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:MicrosoftWindows"/>
<target id="LinuxTarget" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:Linux"/>
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 14 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

<target id="AIXTarget" type="http://w3.ibm.com/namespaces/2003/OS_componentTypes:IBMAIX"/>
</topology><groups>
<group><description language_bundle="SIDemo.properties">
<short_default_text key="GROUP_KEY"/></description>
</group></groups>
</com.ibm.iudd.schemas.smd:rootIU>
Installing a package
IBM has partnered with two of the leading providers of software installation products,InstallShield and Zero G, to integrate these autonomic solution installation anddeployment technologies into their products. These vendors' installer products aredemonstrated in scenarios provided with the Autonomic Computing Toolkit.
For an in-depth explanation of the scenarios and how they work, see the AutonomicComputing Toolkit Scenario Guide.
Section 4. Administering software
The Integrated Solutions Console
Once you've installed the software, you have to administer it. In a worst-casescenario, every application has its own administration console, a fat client that isinstalled on a particular machine. To administer that application, the right person hasto sit in front of the right machine. And in each case, the administrator has to learnthe operation of the unique console and manage permissions for other users throughit.
The Integrated Solutions Console solves a lot of these problems. First, it's abrowser-based application, so the "right person" can administer it from anywhere, aslong as the computer he or she is sitting in front of can access the server on whichIntegrated Solutions Console is installed over the network. Second, you can use it tomanage all of your autonomically aware applications, so learning is limited tonavigating the features of this single console. You can even manage administrationpermissions for accessing other applications through the Integrated SolutionsConsole.
Let's take a look at how it works.
The Integrated Solutions Console architecture
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 15 of 27
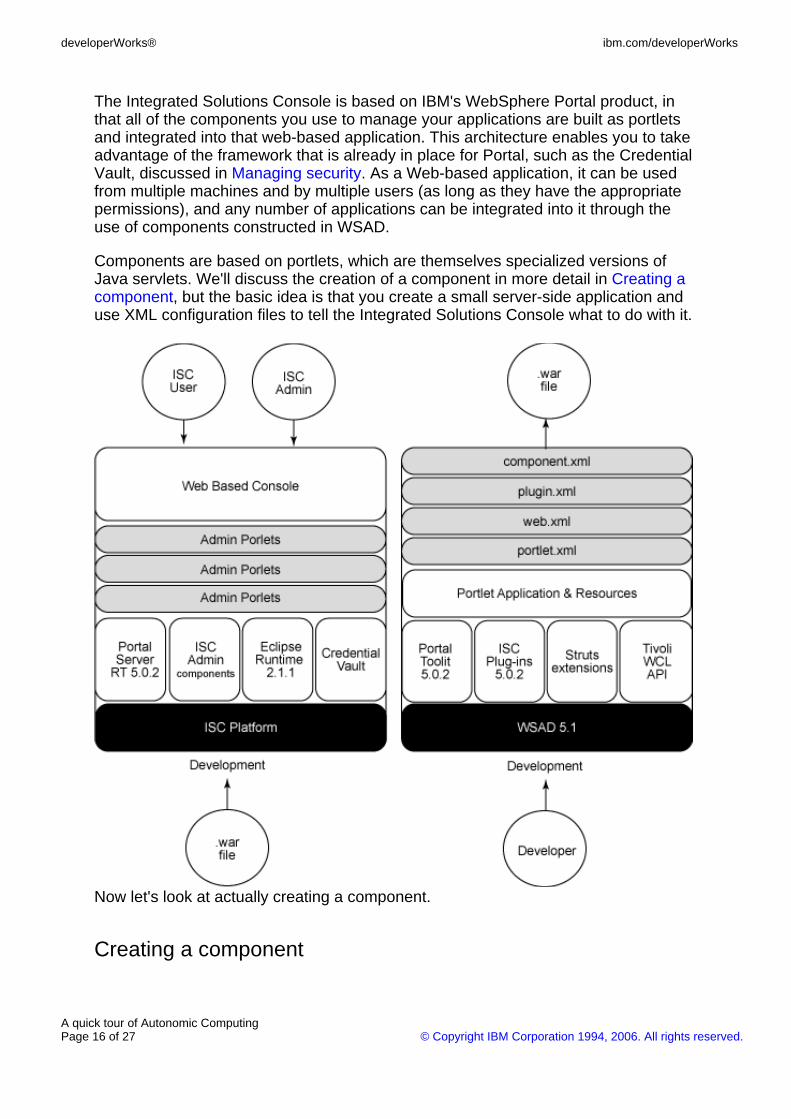
The Integrated Solutions Console is based on IBM's WebSphere Portal product, inthat all of the components you use to manage your applications are built as portletsand integrated into that web-based application. This architecture enables you to takeadvantage of the framework that is already in place for Portal, such as the CredentialVault, discussed in Managing security. As a Web-based application, it can be usedfrom multiple machines and by multiple users (as long as they have the appropriatepermissions), and any number of applications can be integrated into it through theuse of components constructed in WSAD.
Components are based on portlets, which are themselves specialized versions ofJava servlets. We'll discuss the creation of a component in more detail in Creating acomponent, but the basic idea is that you create a small server-side application anduse XML configuration files to tell the Integrated Solutions Console what to do with it.
Now let's look at actually creating a component.
Creating a component
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 16 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

It's impossible to describe the complete process of creating an Integrated SolutionsConsole component in just one section -- see Resources for a tutorial on doing justthat - but here's an overall view of the process:
1. Install the Integrated Solutions Console Toolkit for WebSphereApplication Developer, Portal Toolkit and the Eclipse help framework withthe Integrated Solutions Console installation routine.
2. Using WSAD, create a portlet project.
3. Create a portlet or portlets to manage your application.
4. Create an Integrated Solutions Console Component Project.
5. Assign the project to an administration suite.
6. Add the portlets to the component.
7. Determine the placement for each portlet. Some portlets are displayed inthe work pane, some are shown as the result of a message sent fromanother portlet, and some are only opened within other portlets.
8. Determine the layout of the work pane and the order items appear on thenavigation tree.
9. Set security for the component.
10. Add help resources.
11. Export the component project as a .WAR file and deploy it to theIntegrated Solutions Console server.
12. Connect to the Integrated Solutions Console and operate yourcomponent.
Managing security
One of the strengths of the Integrated Solutions Console is the way in which it easesthe burden of managing permissions for administrative tasks. In addition to the factthat permissions for all of your autonomically aware applications can be managedfrom within the console, you also have the advantage of the layers of abstractionthat Integrated Solutions Console uses.
For one thing, you never actually give an individual user permissions for a specificresource. Rather, you assign users to groups, or "entitlements," and then you givethe entitlements permissions on the portlets that control the resource. In otherwords, you can create an entitlement such as MagnetPeople that has administrativeaccess to some MagnetApp components and user access to others. To change theset of people who have these permissions, you can add people to or remove people
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 17 of 27

from the MagnetPeople group.
This structure provides a layer of insulation whose value may not be immediatelyobvious. If you want to give user Sarah the ability to make changes to a DB2database, under normal circumstances you would have to provide her with ausername and password for the database itself. In the case of the IntegratedSolutions Console, you give her permissions on the portlet, and the portlet accessesthe database. However, the portlet doesn't need to have a username and passwordfor the database either. Instead, it can access the Credential Vault (a feature ofWebSphere Portal that has been included in the Integrated Solutions Console). Thecredential vault "slot" has all of the information needed to access the resource - inthis case, the database - so neither the user nor the portlet the user is accessingever needs to know the actual authentication information. You can use the credentialvault not just for userids and passwords, but also for certificates and private keys.
Section 5. Logging and problems
The Generic Log Adapter
The goal of an autonomic system is to create an environment in which allapplications can be monitored and tracked from within a single location, such as theIntegrated Solutions Console. For that to happen, the overall system needs to beable to understand messages put out by an application and any servers on which itdepends. That means that logging of exceptions and events must first be translatedinto some sort of common format. In the case of the IBM Autonomic ComputingToolkit, that format is called the Common Base Events model. We'll talk about that inmore detail next, but first let's deal with the issue of how we get to that point.
If you were building an application from scratch, it would make sense to output allevents in the Common Base Events format so they could be immediately analyzedby the autonomic system. If, however, you have a legacy application that alreadyputs out events in some other form, you have a problem. You can either rewrite theapplication to change the log format, which isn't likely, or you can choose to convertthe logs it does produce to the Common Base Events format.
The Generic Log Adapter serves this purpose. The GLA is designed to take any textformatted log and convert those entries into Common Base Events so that it can beused as input by other autonomic tools. To do that you define the transformationwithin Eclipse by creating an adaptor (as we'll discuss in Using the Generic LogAdapter), and then run the GLA against the desired target log.
Before we look at how to do that, let's look at what we're trying to accomplish.
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 18 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

Common Base Events
Common Base Events are just that: a consistent, published way to express theevents that normally happen during the functioning of an application, such asstarting or stopping a process or connecting to a resource. The Common BaseEvents specification creates specific situation types, such as START, STOP,FEATURE, and CREATE, and specifies how they must be represented. The CommonBase Events specification also provides a way to identify components experiencingor observing events, as well as the correlation of events into situations that describethem.
Common Base Events are expressed as XML, such as this example adapted fromthe specification:<?xml version="1.0" encoding="UTF-8"?><CommonBaseEvents xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="commonbaseevent1_0.xsd"><AssociationEngine id="a0000000000000000000000000000000"
name="myassociationEngineName" type="Correlated" /><CommonBaseEvent creationTime="2001-12-31T12:00:00"
elapsedTime="0" extensionName="CommonBaseEvent"globalInstanceId="i0000000000000000000000000000000"localInstanceId="myLocalInstanceId" priority="0"repeatCount="0" sequenceNumber="0" severity="0"situationType="mySituation">
<contextDataElements name="Name" type="myContextType"><contextValue>contextValue</contextValue>
</contextDataElements><extendedDataElements name="z" type="Integer">
<values>1</values></extendedDataElements><associatedEvents associationEngine="a0000000000000000000000000000000"
resolvedEvents="i0000000000000000000000000000001" /><reporterComponentId application="myApplication" component="myComponent"
componentIdType="myComponentIdType" executionEnvironment="myExec"instanceId="myInstanceId" location="myLocation"locationType="myLocationType" processId="100"subComponent="mySubComponent" threadId="122" />
<sourceComponentId application="myApplication1"component="myComponent1" componentIdType="myComponentIdType1"executionEnvironment="myExec1" instanceId="myInstanceId1"location="myLocation1" locationType="myLocationType1"processId="102" subComponent="mySubComponent1"threadId="123" />
<msgDataElement msgLocale="en-US"><msgCatalogTokens value="2" /><msgId>myMsgId2</msgId><msgIdType>myMsgIdType</msgIdType><msgCatalogId>myMsgCatalogId</msgCatalogId><msgCatalogType>myMsgCatalogType</msgCatalogType><msgCatalog>myMsgCatalog</msgCatalog>
</msgDataElement></CommonBaseEvent>
</CommonBaseEvents>
From the tags you can see that the component reporting the event ismyApplication. The component experiencing the problem is myComponent1within myApplication1. The reporting component does not necessarily have to bedifferent than the one experiencing difficulty although this is the case in the exampleshown here.
Now let's look at how you go from a raw log file to a file of Common Base Events.
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 19 of 27

Using the Generic Log Adapter
A Generic Log Adapter is essentially a script that runs against a raw log to create aCommon Base Events log. To create that adapter, you use an editor that runs as anEclipse plug-in. A tutorial on using the GLA to create adapters is available ondeveloperWorks and a link is provided in Resources. A short view of the processlooks like this:
1. You will need to have an Eclipse 3.0 or higher platform environment. Ifyou do not have one running on your machine already, download theEclipse Tooling package from the Autonomic Computing Toolkit.
2. Install the Generic Log Adapter and Log and Trace Analyzer Toolingplug-in bundle.
3. Create a Simple project.
4. Create a new Generic Log Adapter File.
5. Select a template log to use in the creation of the adapter. This is a reallog of the type you will be transforming, so you can test the transformationwith real data as you define your adapter. If your goal were to create aGLA for WebSphere Application Server log files, you would use a sampleWAS log file to create the GLA itself. Since the format stays the same forall WAS log files, the adapter would work for subsequently generatedfiles. Each template must have its own context and a sensor is defined forthat context.
6. Define the extractor. The extractor contains the information necessary forinterpreting a specific log file, such as the convention that an error entrystarts with the text [error], including the characters used as separators,and so on. You can also use regular expressions for complex stringhandling to get the extractor to interpret the raw data.
7. Test the adapter on your template file, viewing the transformation of eachentry in the original log file to make sure the output is what you expect.You should also look at the actual Common Base Events XML file tomake sure you don't need to tweak the transformation.
Once you've created a Generic Log Adapter, you can use it from the command lineto transform any file of the appropriate type, which allows you to embed this processinto another application.
The Log Trace Analyzer
Once you have the logs in the appropriate format, the next step is to analyze them.You can make this process easier using the Log Trace Analyzer, which is set up as
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 20 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

part of the Generic Log Adapter installation.
The LTA actually serves several purposes. In addition to actually analyzingindividual log files, it enables you to correlate (bring two events together to create asituation) events both within and between logs, and to analyze logs on an ongoingbasis by attaching to a Java Virtual Machine. It also enables you to plug in a custom"correlation engine" to determine the relationships between events. This can let yousee how failures in one subsystem or service cascade over to create othersituations, allowing you to identify the 'root cause' of an event.
The LTA analyzes events by comparing them to a symptom database. A symptomdatabase is a collection of potential problems, signs of those problems, and potentialsolutions. By comparing the events to the symptom database, the LTA can take aseemingly obscure event and tell you not only what it means, but in the case of anerror, what to do about it.
Using the Log Trace Analyzer
In order to analyze a log (or logs) using the Log Trace Analyzer, you would take thefollowing general steps:
1. Prepare a symptom database (or databases) by importing them andspecifying them as "in use." A symptom database can be local or it can beon a remote server accessible by URL.
2. Import the log file itself.
3. If necessary, filter and/or sort the records to be analyzed. You can selector exclude specific fields of information such as the severity, or youcan choose records based on specific criteria. For example, you mightwant to include only events that were part of a specific thread or date.
4. Analyze the log. This action compares each record to the symptomdatabase, and if it finds a match, it highlights the record in blue. Clickingthe record shows the information from the symptom database.
5. If necessary, correlate the log. You can correlate events within a singlelog, or you can correlate the events in a pair of logs. You can alsocombine multiple logs into a single log in order to correlate more than twologs.
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 21 of 27

Correlating events
Correlation of events can take place within logs or between logs. Using the LTA, youcan view both Log interaction diagrams (within a single log) and Log threadinteraction diagrams (between two logs):
The LTA supports the following types of correlation "out of the box":
• Correlation by Time
• Correlation by URLs and Time
• Correlation by Application IDs and Time
• Correlation by URLs, Application IDs and Time
• Correlation by PMI Request Metrics
You can also create a custom correlation engine with your own specificrequirements.
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 22 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

Section 6. The autonomic manager
The Autonomic Management Engine (AME)
Now that we've looked at a lot of the pieces that surround an autonomic solution,let's get to the heart of the matter.
In order to make any autonomic solution work, you need managed resources, and inorder to have managed resources, you need an autonomic manager. At the centerof IBM's Autonomic Computing Toolkit is the Autonomic Management Engine (AME).AME provides you with the capability of handling all four aspects of the autonomiccontrol loop.
AME communicates with your application via Resource Models, as discussed in thenext panel.
Resource Models
A Resource Model is, in many ways, like the universal adapter you can buy at thestore when you lose the power supply for a piece of electronics. It has plugs ofmultiple sizes, and you can set the voltage and polarity to match the piece ofequipment for which you want to provide power. A Resource Model serves the samepurpose for "plugging in" an application and the Autonomic Management Engine.
It comes down to this: AME needs to know how to access information from theapplication and how to provide information to the application. Is it described ascommon base events? Is it a proprietary log format? Should a particular process bemonitored? A Resource Model defines all of that.
The IBM Autonomic Computing Toolkit comes with a Resource Model that has beencustomized for use with Problem Determination Scenario. You can implement yourown Resource Model by looking at the source code for the one that comes with thescenario.
The Resource Model Builder
The Resource Model Builder bundle, part of the IBM Autonomic Computing Toolkit,enables you to create a Resource Model for AME.
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 23 of 27
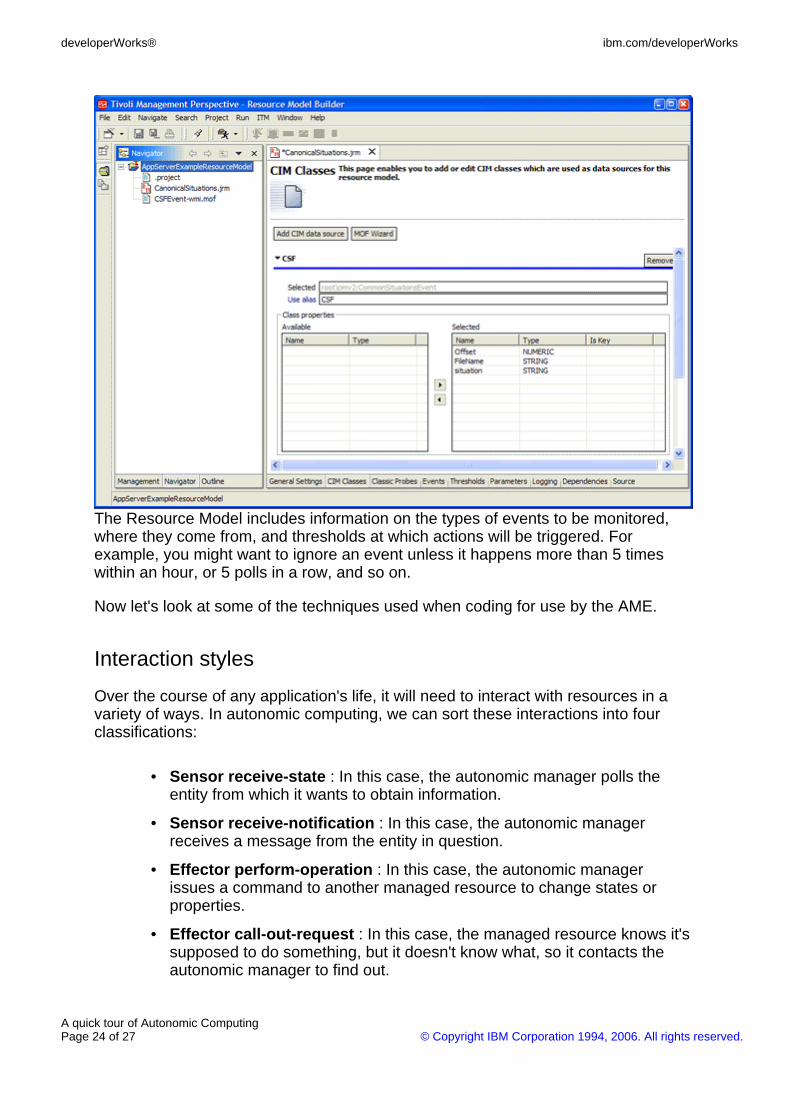
The Resource Model includes information on the types of events to be monitored,where they come from, and thresholds at which actions will be triggered. Forexample, you might want to ignore an event unless it happens more than 5 timeswithin an hour, or 5 polls in a row, and so on.
Now let's look at some of the techniques used when coding for use by the AME.
Interaction styles
Over the course of any application's life, it will need to interact with resources in avariety of ways. In autonomic computing, we can sort these interactions into fourclassifications:
• Sensor receive-state : In this case, the autonomic manager polls theentity from which it wants to obtain information.
• Sensor receive-notification : In this case, the autonomic managerreceives a message from the entity in question.
• Effector perform-operation : In this case, the autonomic managerissues a command to another managed resource to change states orproperties.
• Effector call-out-request : In this case, the managed resource knows it'ssupposed to do something, but it doesn't know what, so it contacts theautonomic manager to find out.
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 24 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

The first release of the Autonomic Computing Toolkit includes classes illustratinghow the Sensor receive-notification and Effector perform-operation interaction stylescan be implemented in an application.
Management topic implementation classes
The current version of the IBM Autonomic Computing Toolkit includes theManagement Topic Implementation classes, as part of the Problem DeterminationScenario. They includecom.ibm.autonomic.manager.AutonomicManagerTouchPointSupport andcom.ibm.autonomic.resource.ManagedResourceTouchPoint, which bothextend Java's UnicastRemoteObject class. The advantage of this is your abilityto invoke these objects remotely via the RMI registry. (See the Resources for moreinformation on Java RMI.)
Actual coding is beyond the scope of this tutorial, but consider this example ofbinding a touchpoint into the local RMI registry.package com.ibm.autonomic.scenario.pd.manager;
import com.ibm.autonomic.manager.IManagerTouchPoint;import com.ibm.autonomic.manager.ManagerProcessControl;
public class PDManagerProcessControl extends ManagerProcessControl{
public PDManagerProcessControl(){
super();}
public void start(){
boolean done = false;int count = 0;while ( !done ){
try{
// create an instance of the problem determination// manager touchpoint...this extends the abstract// manager touch point classIManagerTouchPoint mgrTouchPoint = new PDManagerTouchPoint();
// publish the manager touch point and connect to the// resource...the method below is a convenience// method when only one resource exists...there is// also a method for multiple resourcesconnectAndPublish(mgrTouchPoint,
"//localhost/ManagerTouchPoint","//localhost/ResourceTouchPoint");
done = true;System.out.println("Sucessfully connected to ResouceTouchPoint");
} catch (Throwable th) {try {
Thread.sleep(5000);} catch ( Exception e) {
e.printStackTrace();}if (count++ > 20 ){
System.out.println("Error connecting to managed resources:Tried 20 times");
th.printStackTrace();done = false;
}System.out.println("Retrying");
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 25 of 27

}}
}
public static void main(String[] args) throws Exception{
// create an instance and start it upPDManagerProcessControl mpc = new PDManagerProcessControl();
mpc.start();}
}
For more examples of how to use these classes, see thecom.ibm.autonomic.scenario.pd.manager.PDAutonomicManagerTouchpointSupportandcom.ibm.autonomic.scenario.pd.manager.PDManagedResourceTouchpointclasses in the Problem Determination Scenario.
Section 7. Summary
Summary
The IBM Autonomic Computing Toolkit provides you with the tools and technologiesyou need to begin creating a solution that is self-healing, self-configuring,self-optimizing, and self-protecting. This tutorial provides an overview of theconcepts integral to an understanding of how autonomic computing can beimplemented, through autonomic control loops and autonomic tools. It also providesa treatment of the tools provided in the IBM Autonomic Computing Toolkit and howthey relate to each other. These tools and technologies include:
• Application install using a solution installation and deploymenttechnologies
• Administering and configuring applications using the Integrated SolutionsConsole
• Common Base Events and the Generic Log Adapter
• Symptom databases and the role of the Log Trace Analyzer
• Autonomic management using the Autonomic Management Engine
developerWorks® ibm.com/developerWorks
A quick tour of Autonomic ComputingPage 26 of 27 © Copyright IBM Corporation 1994, 2006. All rights reserved.

Resources
Learn
• The developerWorks Autonomic Computing zone includes information for thosewho are new to autonomic computing, those who want to know more about thecore technologies, and for those who want to know more about the AutonomicComputing Toolkit itself.
• An autonomic computing roadmap gives you a firm grip of the conceptsnecessary to understand this tutorial.
• Read more about Autonomic Computing Maturity Levels.
• Learn about Common Base Events.
• Learn more about Java Remote Method Invocation (Java RMI).
Get products and technologies
• You can also download the various Autonomic Toolkit Bundles.
About the authors
Daniel WordenDaniel Worden, a Studio B author, got his first root password in 1984. He has beeninstalling, de-installing, configuring, testing, and breaking applications since that timeas both a sys admin and manager of systems administration services. In 1996, he leda team that developed in-house a consolidated Web reporting tool for several dozencorporate databases. His Server Troubleshooting, Administration & Remote Support(STARS) team have been working with IBM as partners since 1998. His next book -Storage Networks From the Ground Up is available from Apress in April 2004. Hecan be reached at [email protected].
Nicholas ChaseNicholas Chase, a Studio B author, has been involved in Web site development forcompanies such as Lucent Technologies, Sun Microsystems, Oracle, and the TampaBay Buccaneers. Nick has been a high school physics teacher, a low-levelradioactive waste facility manager, an online science fiction magazine editor, amultimedia engineer, and an Oracle instructor. More recently, he was the ChiefTechnology Officer of an interactive communications company in Clearwater, Florida,and is the author of five books, including XML Primer Plus (Sams ). He loves to hearfrom readers and can be reached at [email protected].
ibm.com/developerWorks developerWorks®
A quick tour of Autonomic Computing© Copyright IBM Corporation 1994, 2006. All rights reserved. Page 27 of 27