a pragmatic approach to facilitating text and data mining
TRANSCRIPT

| 1Open Access
A Pragmatic Approach to Facilitating Text and Data Mining
ITOC WorkshopICSTI 2016 Annual Members’ Meeting Philadelphia, USA
Chris ShillumVP Platform and Data Integration, Elsevier
20 Feb 2016

| 2Open Access
Outline
• How researchers use text and data mining • Publishers and TDM• Elsevier specifics• Practicalities

| 3Open Access
Elsevier’s experience: How researchers use text and data mining

| 4Open Access
Why researchers use TDM Two main use cases:
1. Answering a specific research question
2. Building a new data resource for the community
• How long does it take for concepts in STM literature to reach general media?
• What is the relationship between the research and consulting commitments of economics and finance professors?
• What are the characteristics of subjects in social psychology experiments?
• An HIV mutation database for which mutations found in literature are mapped to the underlying sequence database
• A database on growth and alimentation of fishes, and a fish classification to identify new species for aquaculture
• A database with the electrophysiological properties of diverse neuron types

| 5Open Access
Why use published literature?
• Formal record of scholarship
• Researchers can build on existing results published in scholarly articles
• Curated and trusted source of information
• Believed to contain a lot of “hidden” insights and latent new knowledge
• There is a lot of it, it’s cross discipline and it covers archives as well!
Source: Effect of low frequency repetitive transcranial magnetic stimulation on kindling-induced changes in electrophysiological properties of rat CA1 pyramidal neurons| http://dx.doi.org/10.1016/j.brainres.2015.02.023

| 6Open Access
Run your tools and analyze the error reports
Download all the content
A typical text mining workflow
Define the problem Define your approach Access & extract Analyze & build
Choose your tools: • Off the shelf
(open source)• Outsource to a
specialized company
Write an algorithm that will extract what you want
Test the algorithm to ensure it works• Use corpus and
tree-banking to help
What are you wanting to learn?
What relationships do you need to know?
What content do you want to cover?
Gain access to the relevent literature
Retest your algorithm
Re-run if needed
Process extracted data
Analyze to see if relationships exist
Write your results in a paper
Build the database of extracted values

| 7Open Access
Uptake of text mining
Developing and learning TDM tools
All content is not all structured or available in the same format
Lack of TDM infrastructure - tools are not tailored to STM content
Learning how to fine-tune the pipeline
Effort is needed to create meaningful output and curation
Figuring out how to gain access and permission to the right content
Recognizing specific TDM-based projects well enough to assess implications & offer advice to patrons
Negotiating permissions with multiple providers
Address concerns about any additional costs that might be incurred
Publishers allow for text mining but the uptake is low:To date, Elsevier has provided access to ~120 researchers from ~80 institutions globally
Librarians Ensuring their researchers know
who to contact on campus
Understanding and tracking what is allowed for what resources
Researchers
Why?

| 8Open Access
• TDM is not an off-the-shelf process• It is much more complicated than it looks
• Requires an understanding of specialized tools • Also requires skill to apply them to a particular problem domain
• TDM is not yet a mainstream research tool• Most research today comes from TDM researchers developing tools and
approaches vs. researchers applying TDM techniques
Summary

| 9Open Access
Publishers and TDM

| 10Open Access
First and foremost, providing access…
http://www.stm-assoc.org/2013_11_11_Text_and_Data_Mining_Declaration.pdf

| 11Open Access
Shared challenges of text mining
Uptake is low – why?
• Researchers want to do the research• No standard way to gain access • Not clear who they should contact on campus for
advice or permission• No standard TDM processes on campus• Beyond access as we see no difference in uptake in
regions (UK/Japan) that have copyright exceptions
• Beyond providing access, publishers can further help through supporting the development of standards and shared TDM infrastructure
Why use licenses?
• TDM involves downloading a large amounts of content to a local server
• This content made availalble to be used for TDM research but could also be used for other purposes, some of those illegal/illicit
• Licenses are an easy way to remove uncertainty and define the terms of use across different legal jurisdictions
“Because as a researcher unfortunately I don’t know who my librarians are- I never talk to them.” – Shreejoy Tripathy founder of NeuroElectro

| 12Open Access
How are publishers helping?
• Optimizing content for text mining • Investing in APIs to deliver optimal experiences
to both humans and machines• Providing technical support • Collaborating to provide cross-publisher
solutions• Collaborating with and funding research at
academic institutions

| 13Open Access
How to make TDM more efficient?
• No standard semantic article tagging• Different sections are called different things
(methods vs experimental set up) • Journals provide content in different file
formats • ….So no one pipeline will work for all content
and it takes time and effort to adapt
Publishers are helping:
• Elsevier provides “master tagged” content in XML
• Elsevier standardizes all article formats
• We are participate in industry initiatives such as CrossRef Text and Data mining services

| 14Open Access
• Off-the-shelf natural language processing tools are not well-suited for research content
• STM content is complex and unique• Contains citations, complex technical terms
including symbols and position information.• Doesn’t contain mentions of entertainers,
politicians, organizations, products, elections etc.
Publishers are helping:
• Elsevier has published an OA STM Corpus• Supports the testing and development of STM
NLP tools
• For each article in the corpus we provide:• The XML source,• A simple text version for easier text mining,• Several versions with different annotations:
How to make TDM more effective?
http://elsevierlabs.github.io/OA-STM-Corpus/
110 articles Open access with a CC-BY license
10 domains agriculture, astronomy, biology, chemistry, computer science, earth science, engineering, materials science math and medicine
10 test sets

| 15Open Access
Elsevier specifics

| 16Open Access
Elsevier and text mining
https://www.elsevier.com/about/company-information/policies/text-and-data-mining
• Actively collaborating with researchers & institutes to facilitate TDM• Funding postdocs at the University of Bologna• Funding interns at the University of Melbourne• Joint research grant with the University of Manchester• Funding an NLP Centre of Excellence at Indian Institute of Technology,
Bombay• Sponsoring academic conferences, e.g.
http://www.clips.uantwerpen.be/clin25/home
• Enabling access with an updated policy framework, adapted as we here feedback from the community
• Investing in our platforms to support TDM research• Providing a specific channel for machine-to-machine to content via
well-documented APIs. • Launched a developers’ portal • Providing technical support and services beyond the basic content
access.
• Working on Natural Language Processing tools; Providing resources such as an open access STM corpus and tree-banking

| 17Open Access
Supporting TDM at Elsevier
2006 Started supporting ad-hoc TDM access requests
• Low - but increasing level - of interest from early adopters
2012 First content mining policy published• Developed new APIs & rolled out better TDM technical
solutions
2013 Pilot (~30 academics)• Discovered two main use cases for TDM and input to refine
our TDM technical solutions
2014 Publish updated TDM policy• Automatically give access to subscribed users• Launch a developers portal to facilitate access
2015 Launched STM Open Access Corpus• Valuable open access tool to help researchers refine and
develop their tools in order to TDM more effectively

| 18Open Access
A real-world example
http://neuroelectro.org
• Developed by Shreejoy Tripathy and Richard GerkinUniversity of British Columbia and Arizona State University
• Facilitates the discovery of neuron-to-neuron relationships and better understanding of the role of functional diversity across neuron types.
NeuroElectro: a window to the world's neuron electrophysiology data.Frontiers in Neuroinformatics, April 2014 Tripathy SJ, Savitskaya J, Burton SD, Urban NN, and Gerkin RC .

| 19Open Access
Elsevier’s TDM guidelines
• Researchers at academic institutions can text mine subscribed content on ScienceDirect for non-commercial purposes via the Elsevier APIs
• Access is granted to faculty, researchers, staff and students at the subscribing institution
Excerpts from our subscription content may be shared publically in text mining output can be under these conditions:
• May contain "snippets" of up to 200 characters of the original text
• Proprietary notice• Must include DOI link to original
content
Open access content
• Text and Data mining permission are determined by the author's choice of user license.
• This information is detailed in the individual articles

| 20Open Access
Why use APIs?
• An API (Application Programming Interface) is interface for software programs that enables interaction with other software
• APIs provide developers with stable, well-defined specs for integration with their software
• APIs make the TDM process more efficient for vast quantities of data
• They enable publishers to maintain website site performance, availability, reliability and security for their (human) users.
Separate channels for programmatic and human access to content are standard across the web:
• Wikipedia: http://en.wikipedia.org/wiki/Wikipedia:Database_download
• Twitter: https://twitter.com/tos
• PubMed Central: http://www.ncbi.nlm.nih.gov/pmc/about/copyright/

| 21Open Access
APIs: Accessing content through automated processes

| 22Open Access
Supporting cross-publisher TDM
http://www.crossref.org/tdm/index.html
Addressing two issues:
1. Problem: Researchers want to be able to access full text content from multiple publishers’ sites for OA or subscribed content in a consistent way.Solution: Common API (protocol) for requesting machine readable full text from many different publishers

| 23Open Access
Addressing two issues:
1. Problem: Researchers want to be able to access full text content from multiple publishers’ sites for OA or subscribed content in a consistent way.Solution: Common API (protocol) for requesting machine readable full text from many different publishers
Supporting cross-publisher TDM
http://www.crossref.org/tdm/index.html
2. Problem: Researchers want to know whether text and data mining is allowed, and if not, get permission. Solution: Licensing information embedded in article metadata and a registry for supplemental text and data mining terms and conditions (licenses).

| 24Open Access
Practicalities

| 25Open Access
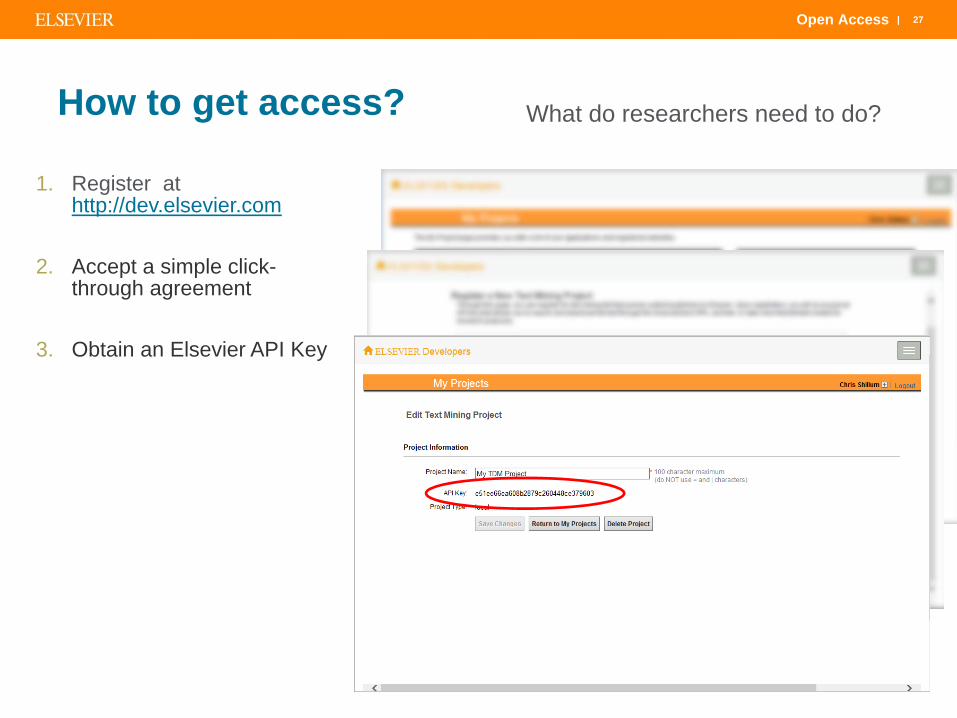
How to get access?
1. Register at http://dev.elsevier.com
What do researchers need to do?

| 26Open Access
1. Register at http://dev.elsevier.com
2. Accept a simple click-through agreement
What do researchers need to do?How to get access?
| 27Open Access
How to get access?
1. Register at http://dev.elsevier.com
2. Accept a simple click-through agreement
3. Obtain an Elsevier API Key
What do researchers need to do?

| 28Open Access
Practicalities
1. Registration and click-through agreement- Automatic, instant process- No additional liability- Aligned with institutional subscription agreement- Provides guidelines on reuse- Can offer one-to-one support - We no longer require project description in response
to feedback
https://www.elsevier.com/about/company-information/policies/text-and-data-mining/text-and-data-mining-faq

| 29Open Access
Practicalities
2. Mining images- We always have allowed this on request- Now include permission automatically- There are terms of reuse, as we aren’t always the
rightsholder
https://www.elsevier.com/about/company-information/policies/text-and-data-mining/text-and-data-mining-faq

| 30Open Access
Practicalities
3. Download caps- Our initial TDM service capped downloads per
month, based on experience gained in our pilot- In response to feedback, we have removed the
download cap however still impose a reasonable rate limit on the API by default
- This enables us to fairly share capacity among all researchers wishing to text mine
- We are always open to discuss increased rate limits for specific projects
https://www.elsevier.com/about/company-information/policies/text-and-data-mining/text-and-data-mining-faq

| 31Open Access
• To distribute the TDM Output externally, which may include a few lines of query-dependent text of individual full text articles or book chapters which shall be up to a maximum length of 200 characters surrounding and excluding the text entity matched (“Snippets”) or bibliographic metadata.
• Where Snippets and/or bibliographic metadata are distributed, they should be accompanied by a DOI link that points back to the individual full text article or book chapter.
• Where images are used you should clear the rights for reuse with the relevant copyright owner and/or rightsholder.
• TDM Output should include a proprietary notice in the following form:“Some rights reserved. This work permits non-commercial use, distribution, and reproduction in any medium, provided the original author and source are credited.”
• Open access content usage terms defined by license
Practicalities
4. TDM outputs- No copyright claim on original research findings- We do have output requirements when our material
is quoted as follows, in line with standard citation practices:
https://www.elsevier.com/about/company-information/policies/text-and-data-mining/text-and-data-mining-faq
| 32Open Access
5. Flexibility - We consider all requests and help all researchers
with any queries- Continued evolution in response to feedback:
project descriptor, license outputs, images
Practicalities
https://www.elsevier.com/about/company-information/policies/text-and-data-mining
