a pixel to-pixel segmentation method of dild without masks using cnn and perlin noise
TRANSCRIPT

A pixel-to-pixel segmentation of DILD without masks
using CNN and Perlin noise
2016.11 [email protected]

Objectives● Segmenting and labeling regional patterns in
DILD(Diffuse Interstitial Lung Disease) HRCT images.
From : Younjun Chang et al, “Fast and efficient lung disease classification using hierarchical one-against-all SVM and cost-sensitive feature selection”. 2012.

Challenges
● Small dataset○ only 547 ROI ( 20x20 bounding box ) patches
● No human mask label○ Extremely expensive

Dataset

Dataset

Dataset

Dataset

Traditional approach● Superpixel approach

Traditional approach● Superpixel result - factor 0.25

Traditional approach● Superpixel result - factor 2

Traditional approach● Superpixel result - factor 4

Traditional approach● Superpixel result - factor 9
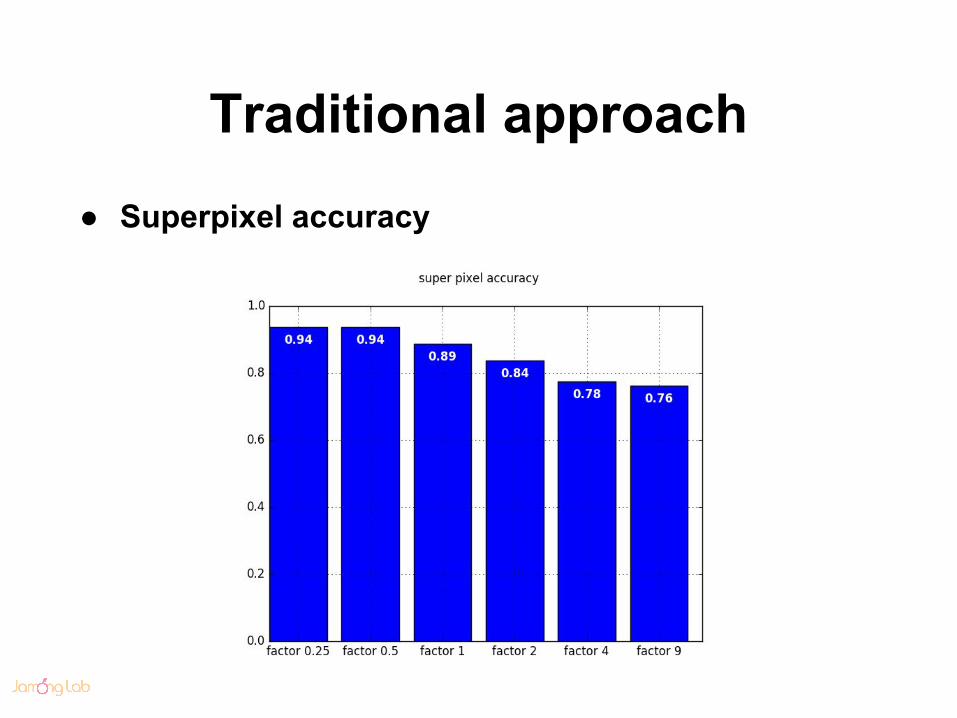
Traditional approach● Superpixel accuracy

Traditional approach
● Superpixel limitation○ deterministic and strong assumption
( Similarity of neighboring pixels )

New approach● Deep learning pixel-to-pixel segmentation.
○ Hand labelled mask is needed.○ Let’s generate it !
From : Ra Gyoung Yoon et al, “Quantitative assesment of change in regional disease patterns on serial HRCT of fibrotic interstitial pneumonia with texture-based automated quantification system”. 2012.

Mask generation● A naive approach → Failed.
○ Because the neural network have learned deterministic patterns instead of lung disease patterns.
Honeycombing
Emphysema

Mask generation● Ken Perlin, “An image Synthesizer”, 1985
○ natural appearing textures○ gradient based fractal noise○ heavily used in game business

Mask generation● One random Perlin noise ( simplex noise )● two randomly selected ROI patches
ConsolidationGGO
Mask ROI Patch

Mask generation● 547 patches → Infinite patches ( O(1006xN) )

Model architecture● UNet + SWWAE architecture
○ Olaf et al, “U-Net: Convolutional Networks for Biomedical Image
Segmentation”, 2015
○ Junbo et al, “Stacked What-Where Auto-encoders”, 2015

Model architecture
Skip connections

Deep learning approach● pixel-to-pixel segmentation result

Deep learning approach● pixel-to-pixel segmentation result

Deep learning approach● pixel-to-pixel segmentation result

Deep learning approach● pixel-to-pixel segmentation accuracy

High resolution segmentation● 20 x 20 patches per 512 x 512 image
○ (512 - 20 + 1)2 → Too expensive

High resolution segmentation● Fully convolutional layer used
○ Various sized image input available

High resolution segmentation● 200 x 80 grids

High resolution segmentation● 500 x 20 grid ( Vertical grids )
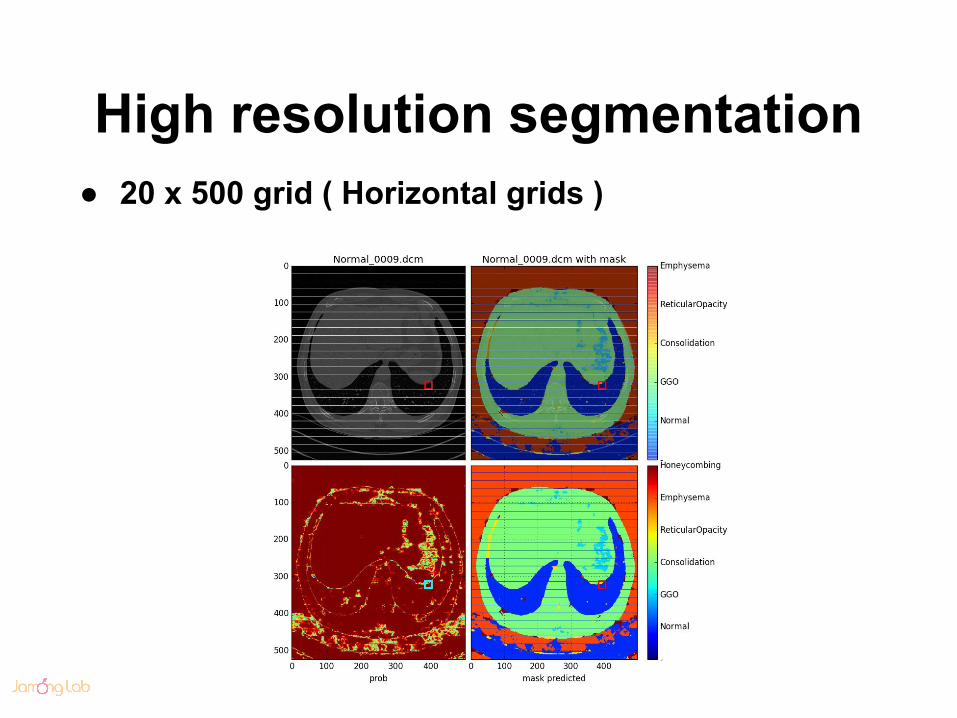
High resolution segmentation● 20 x 500 grid ( Horizontal grids )

High resolution segmentation
● Computation complexity

High resolution segmentation● Results ( Hortz )
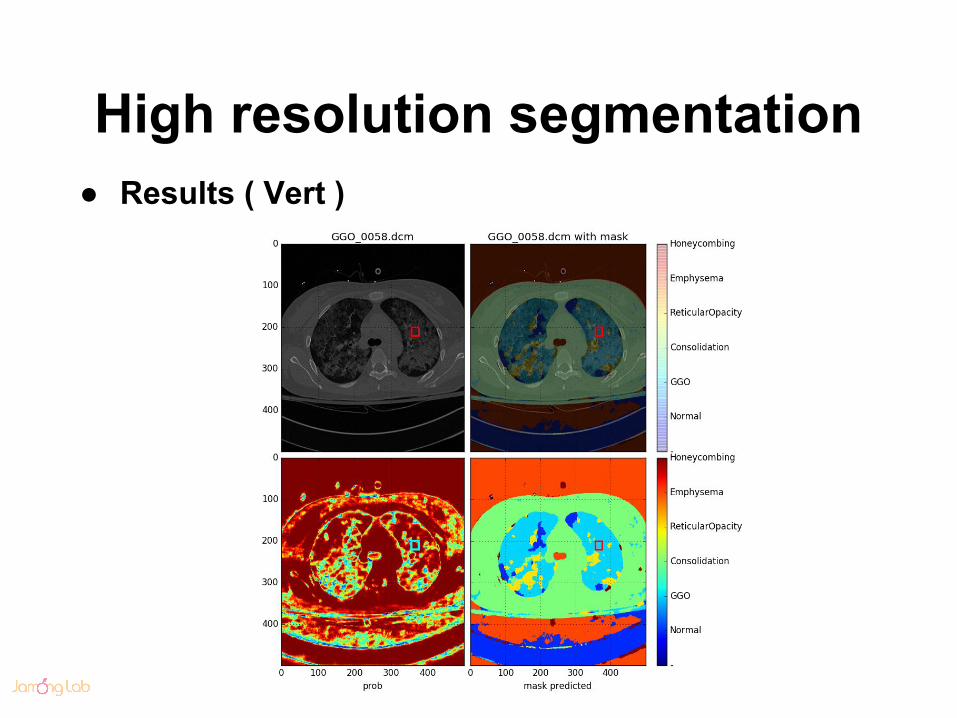
High resolution segmentation● Results ( Vert )
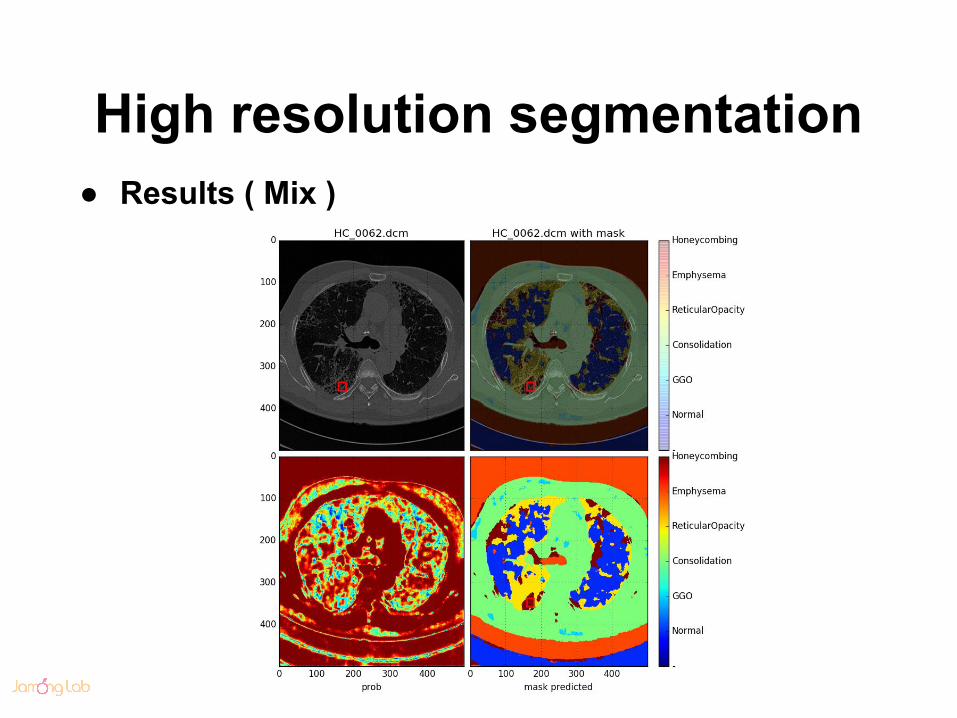
High resolution segmentation● Results ( Mix )

High resolution segmentation● Comparison - Accuracy
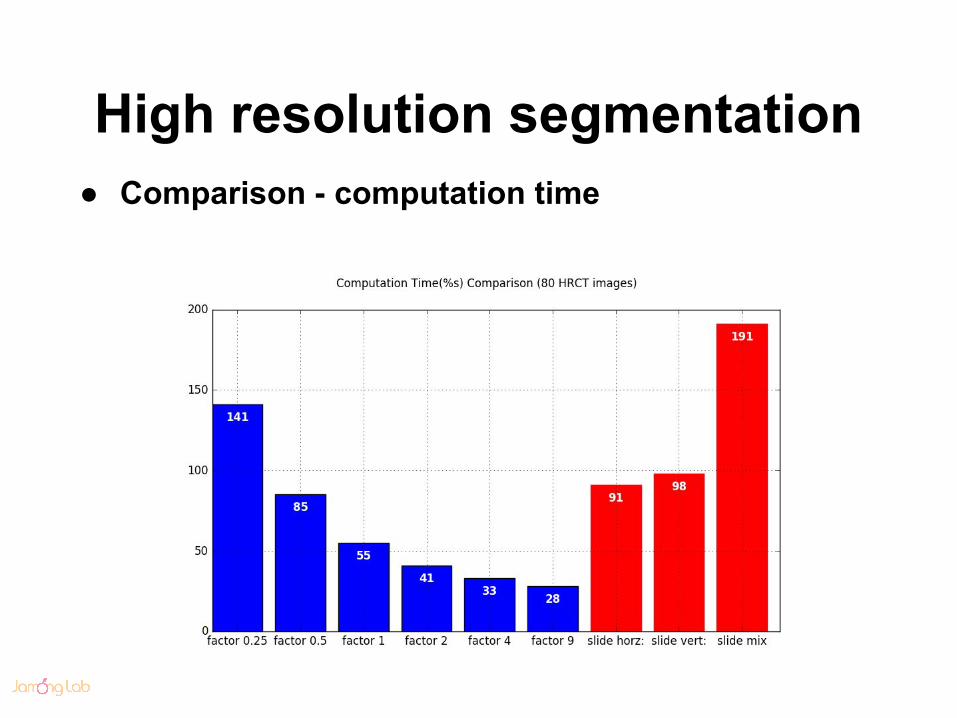
High resolution segmentation● Comparison - computation time

Our contributions
● A simple and practical pixel mask generation method for DILD ROI dataset using Perlin noise.○ No radiologist mask needed.
● We applied state-of-the-art deep CNN based pixel-to-pixel segmentation method to DILD dataset.○ High accuracy with reasonable computing time.

Thank you !!!