a middleware for storing massive rdf graphs into nosql
TRANSCRIPT

A middleware for storing massive RDF
graphs into NoSQL
Workshop de Teses e Dissertações em Banco de Dados (WTDBD)
Simpósio Brasileiro de Banco de Dados (SBBD)
Uberlândia, Outubro/2017
Luiz Henrique Zambom Santana
PhD Candidate
Prof. Dr. Ronaldo dos Santos Mello
Advisor

Agenda
● Initial information
● Introduction: Motivation, objectives, and contributions
● Background
○ RDF
○ NoSQL
● State of the Art
● Rendezvous
○ Storing: Fragmentation, Partitioning, and Mapping
Querying: Query decomposition and Caching

Initial information
● Data de ingresso: 3/2015
● Data prevista de término: 2/2019
● Requisitos cumpridos:
○ SAD, EQD, Proficiências, Estágio Docência

Introduction: Motivation
● Since the of Semantic Web proposal in 2001, many advances introduced by
W3C
● RDF and SPARQL is currently widespread:
○ Best buy:
■ http://www.nytimes.com/external/readwriteweb/2010/07/01/01readwr
iteweb-how-best-buy-is-using-the-semantic-web-23031.html
○ Globo.com:
■ https://www.slideshare.net/icaromedeiros/apresantacao-ufrj-
icaro2013

Agenda
● Introduction: Motivation, objectives, and contributions
● Background
○ RDF
○ NoSQL
● State of the Art
● Rendezvous
○ Storing: Fragmentation, Partitioning, and Mapping
○ Querying: Query decomposition and Caching
● Evaluation
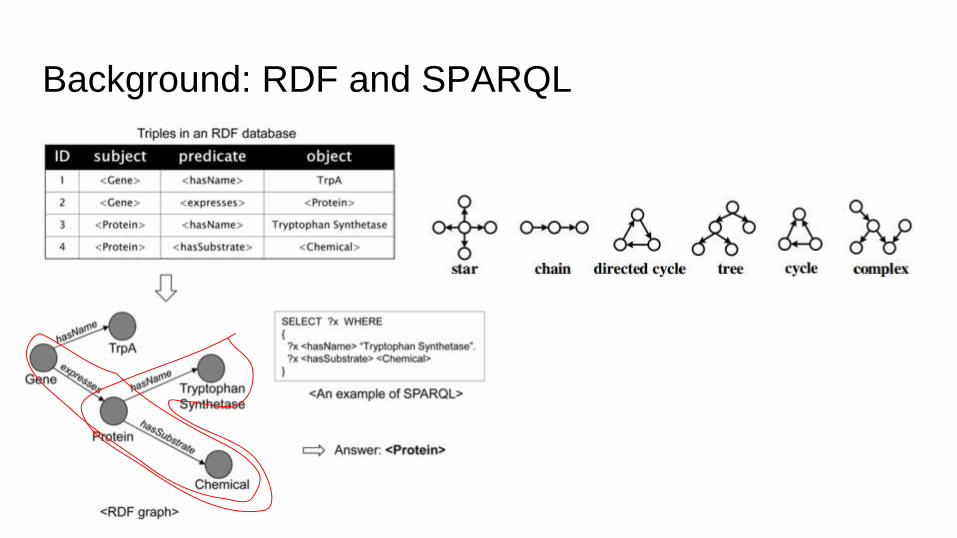
Background: RDF and SPARQL
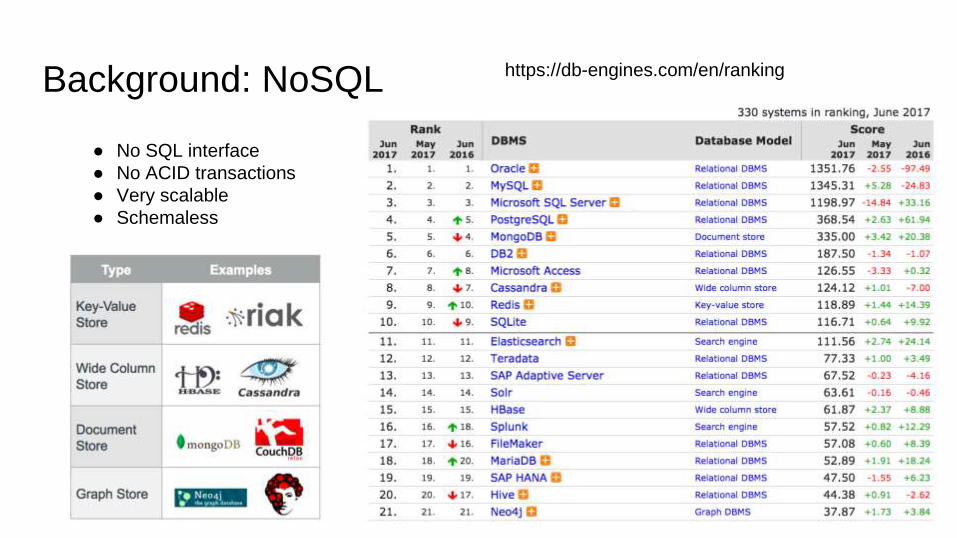
Background: NoSQL
● No SQL interface
● No ACID transactions
● Very scalable
● Schemaless
https://db-engines.com/en/ranking

Agenda
● Introduction: Motivation, objectives, and contributions
● Background
○ RDF
○ NoSQL
● State of the Art
● Rendezvous
○ Storing: Fragmentation, Partitioning, and Mapping
○ Querying: Query decomposition and Caching
● Evaluation
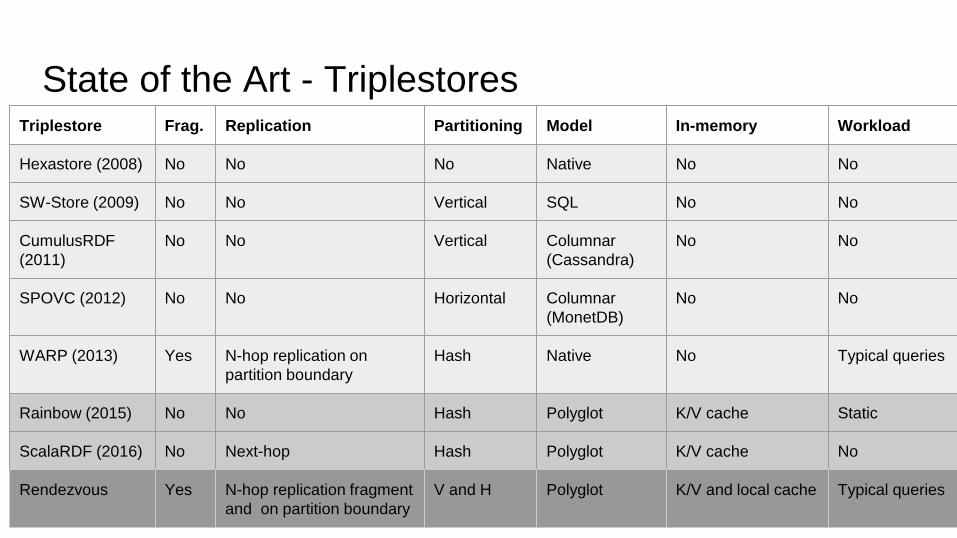
State of the Art - TriplestoresTriplestore Frag. Replication Partitioning Model In-memory Workload
Hexastore (2008) No No No Native No No
SW-Store (2009) No No Vertical SQL No No
CumulusRDF
(2011)
No No Vertical Columnar
(Cassandra)
No No
SPOVC (2012) No No Horizontal Columnar
(MonetDB)
No No
WARP (2013) Yes N-hop replication on
partition boundary
Hash Native No Typical queries
Rainbow (2015) No No Hash Polyglot K/V cache Static
ScalaRDF (2016) No Next-hop Hash Polyglot K/V cache No
Rendezvous Yes N-hop replication fragment
and on partition boundary
V and H Polyglot K/V and local cache Typical queries

Agenda
● Introduction: Motivation, objectives, and contributions
● Background
○ RDF
○ NoSQL
● State of the Art
● Rendezvous
○ Storing: Fragmentation, Partitioning, and Mapping
○ Querying: Query decomposition and Caching
● Evaluation

Rendezvous
● Triplestore implemented as middleware for storing
massing RDF graphs into multiple NoSQL databases
● Novel data partitioning approach
● Fragmentation strategy that maps pieces of this RDF
graph into NoSQL databases with different data
models
● Caching structure that accelerate the querying response
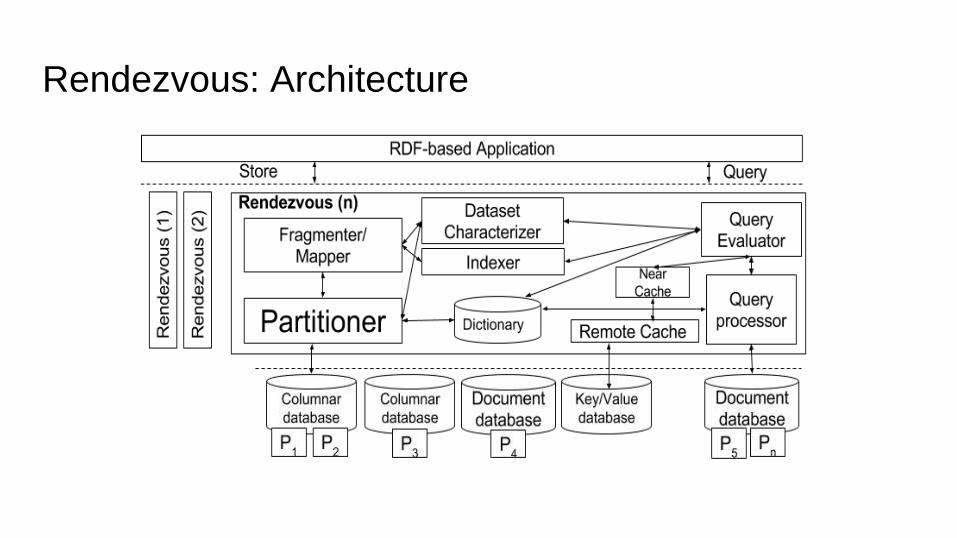
Rendezvous: Architecture
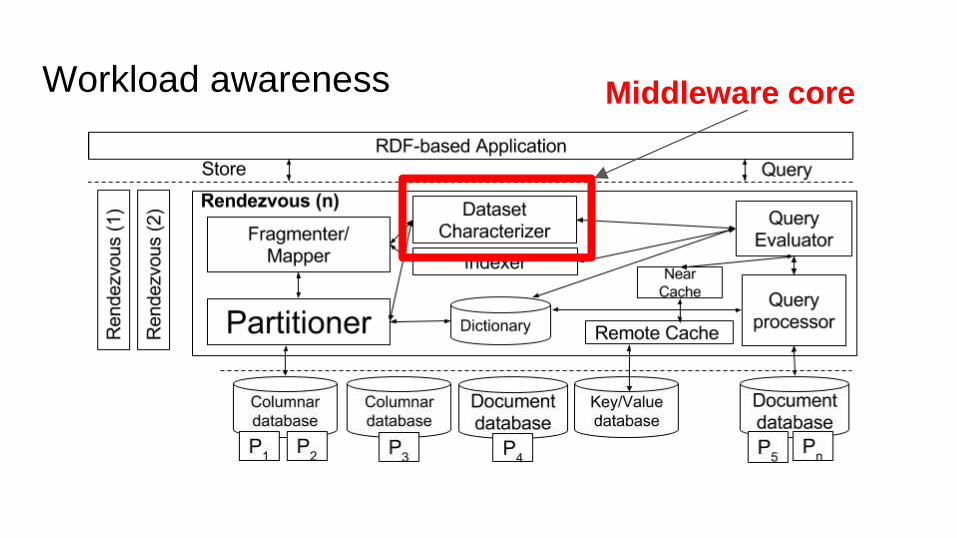
Workload awareness Middleware core
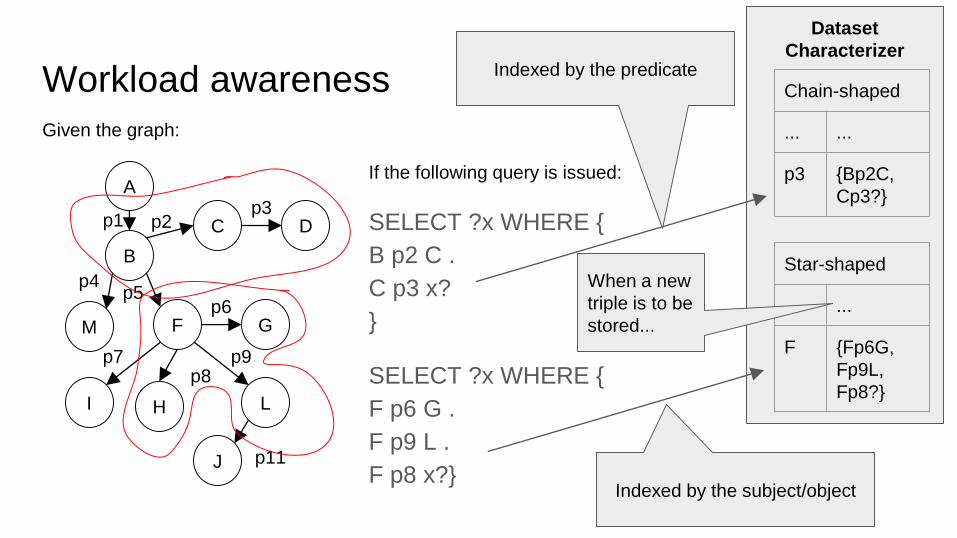
Workload awareness
Given the graph:
If the following query is issued:
SELECT ?x WHERE {
B p2 C .
C p3 x?
}
SELECT ?x WHERE {
F p6 G .
F p9 L .
F p8 x?}
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
Star-shaped
... ...
F {Fp6G,
Fp9L,
Fp8?}
Indexed by the predicateChain-shaped
... ...
p3 {Bp2C,
Cp3?}
Indexed by the subject/object
Dataset
Characterizer
When a new
triple is to be
stored...

Rendezvous: Storing
● Fragmentation
and Mapping
● Partitioning
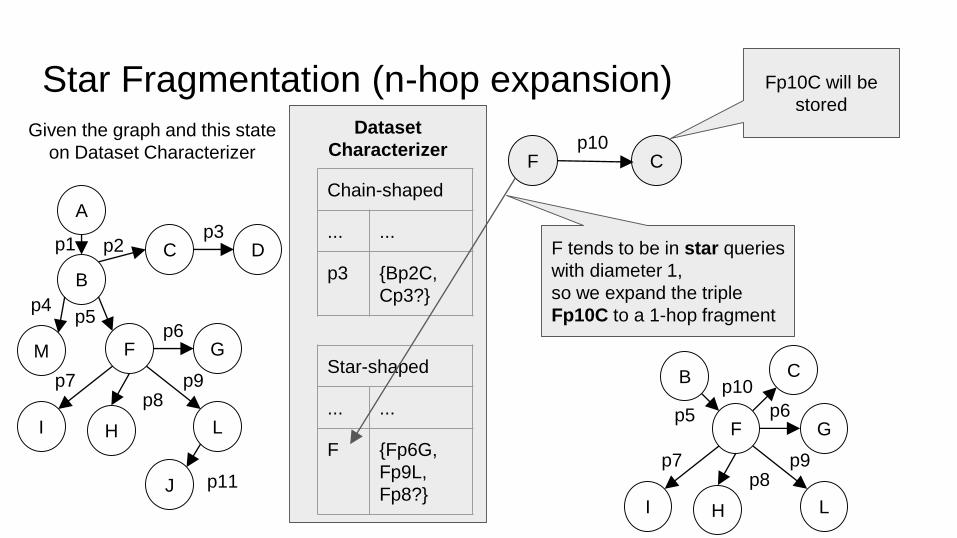
Star Fragmentation (n-hop expansion)
Given the graph and this state
on Dataset Characterizer
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
F Cp10
Chain-shaped
... ...
p3 {Bp2C,
Cp3?}
Dataset
Characterizer
Star-shaped
... ...
F {Fp6G,
Fp9L,
Fp8?}
F tends to be in star queries
with diameter 1,
so we expand the triple
Fp10C to a 1-hop fragment
B C
F G
LHI
p5 p6
p7 p9p8
p10
Fp10C will be
stored
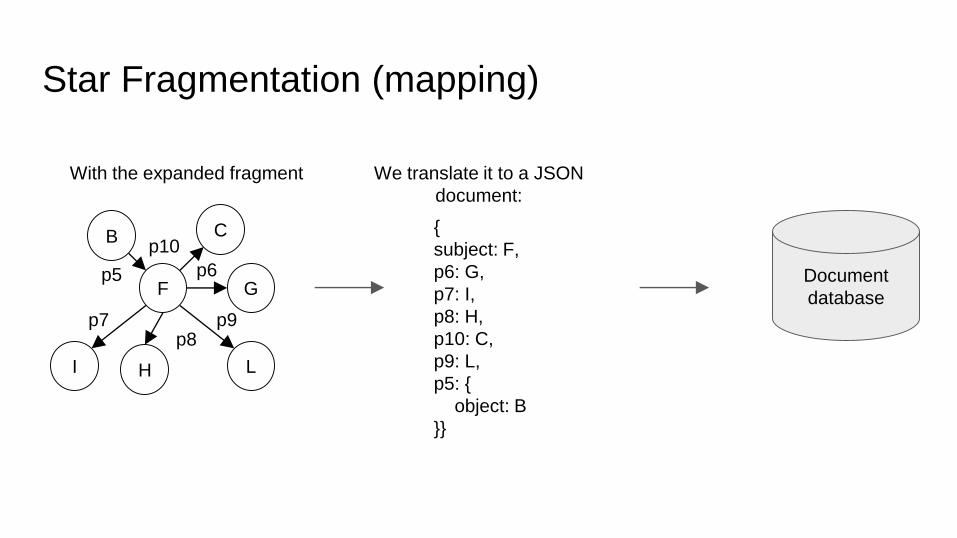
Star Fragmentation (mapping)
With the expanded fragment
B C
F G
LHI
p5 p6
p7 p9p8
p10{
subject: F,
p6: G,
p7: I,
p8: H,
p10: C,
p9: L,
p5: {
object: B
}}
We translate it to a JSON
document:
Document
database
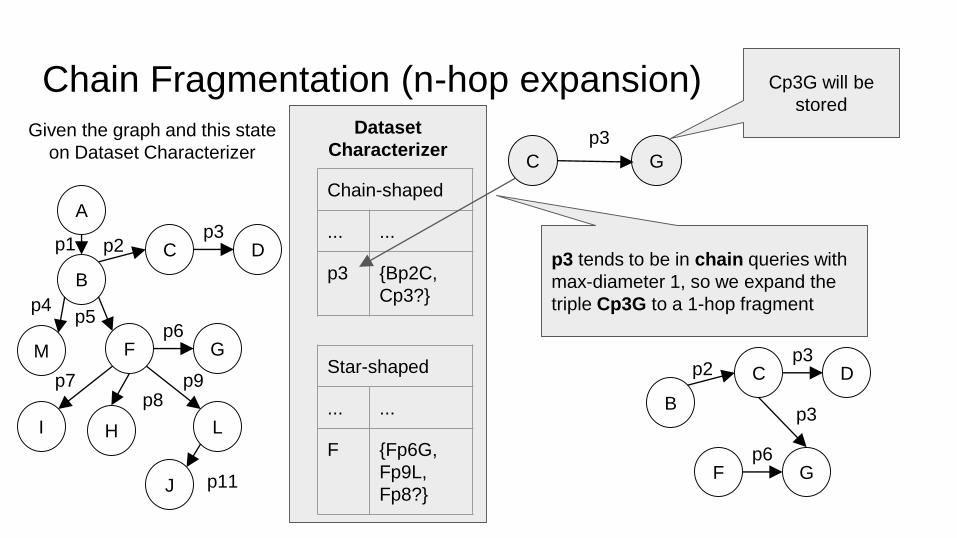
Chain Fragmentation (n-hop expansion)
Given the graph and this state
on Dataset Characterizer
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
C G
p3
Chain-shaped
... ...
p3 {Bp2C,
Cp3?}
Dataset
Characterizer
Star-shaped
... ...
F {Fp6G,
Fp9L,
Fp8?}
p3 tends to be in chain queries with
max-diameter 1, so we expand the
triple Cp3G to a 1-hop fragment
B
C
F G
p2p3
p6
D
p3
Cp3G will be
stored
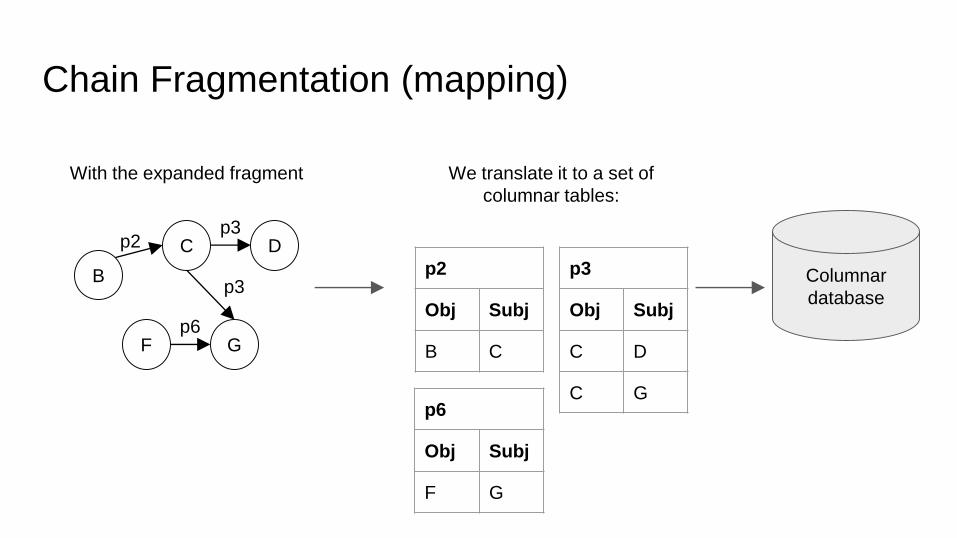
Chain Fragmentation (mapping)
With the expanded fragment We translate it to a set of
columnar tables:
B
C
F G
p2p3
p6
D
p3p2
Obj Subj
B C
p3
Obj Subj
C D
C Gp6
Obj Subj
F G
Columnar
database
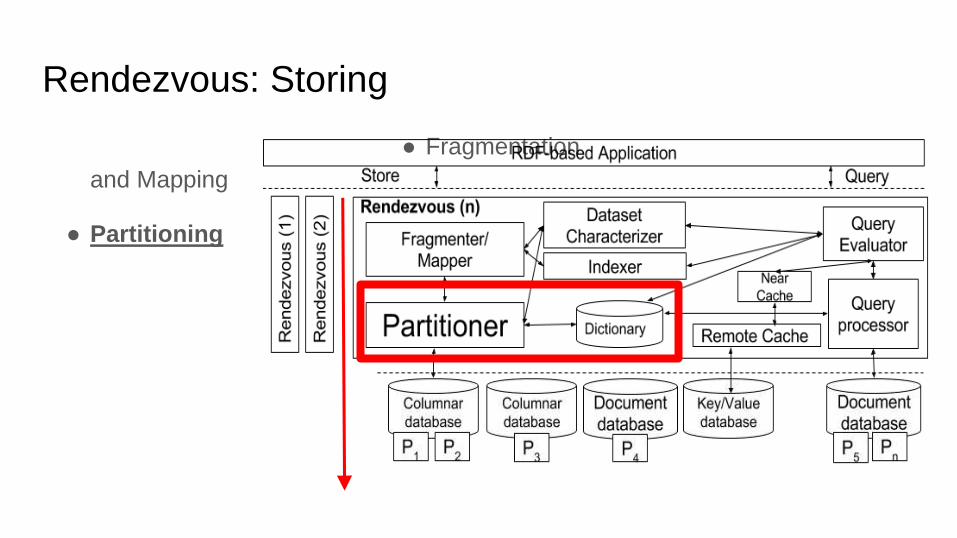
Rendezvous: Storing
● Fragmentation
and Mapping
● Partitioning
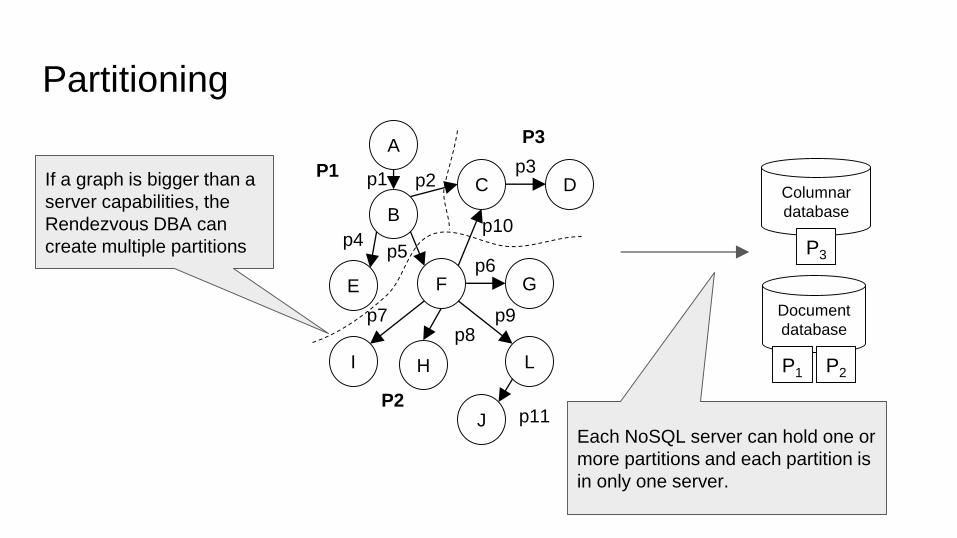
Partitioning
A
B
C
E F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
P2
P1
J p11
D
P3
p10
If a graph is bigger than a
server capabilities, the
Rendezvous DBA can
create multiple partitions
Columnar
database
Document
database
P3
P1 P2
Each NoSQL server can hold one or
more partitions and each partition is
in only one server.
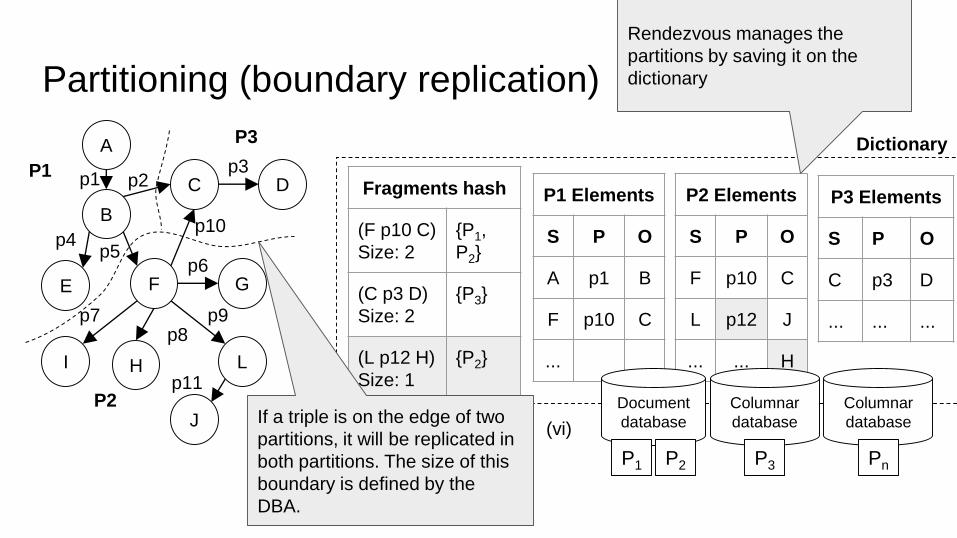
Partitioning (boundary replication)
Fragments hash
(F p10 C)
Size: 2
{P1,
P2}
(C p3 D)
Size: 2
{P3}
(L p12 H)
Size: 1
{P2}
P3 Elements
S P O
C p3 D
... ... ...
P1 Elements
S P O
A p1 B
F p10 C
...
Dictionary
P2 Elements
S P O
F p10 C
L p12 J
... ... H
(vi)
Columnar
database
Columnar
database
Document
database
P3 PnP1 P2
A
B
C
E F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
P2
P1
J
p11
D
P3
p10
If a triple is on the edge of two
partitions, it will be replicated in
both partitions. The size of this
boundary is defined by the
DBA.
Rendezvous manages the
partitions by saving it on the
dictionary
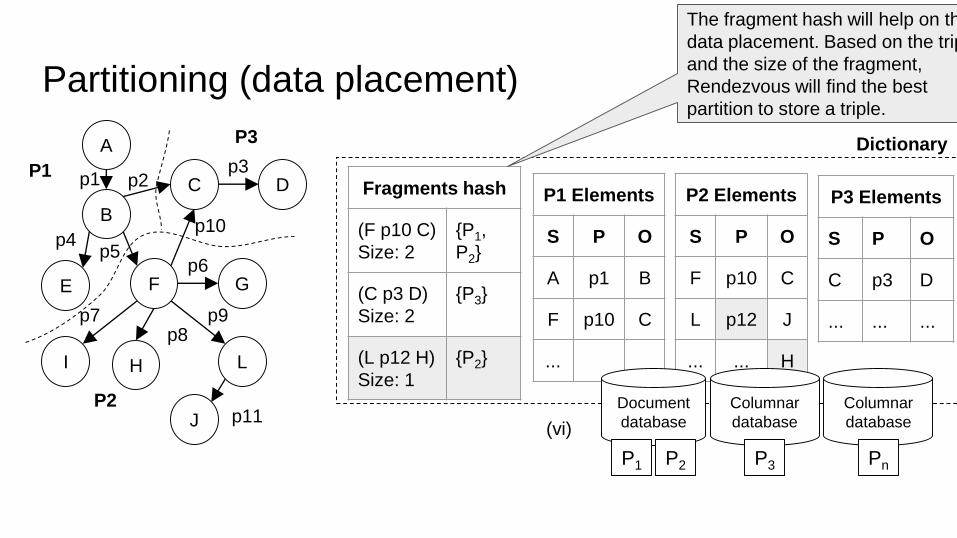
Partitioning (data placement)
Fragments hash
(F p10 C)
Size: 2
{P1,
P2}
(C p3 D)
Size: 2
{P3}
(L p12 H)
Size: 1
{P2}
P3 Elements
S P O
C p3 D
... ... ...
P1 Elements
S P O
A p1 B
F p10 C
...
Dictionary
P2 Elements
S P O
F p10 C
L p12 J
... ... H
(vi)
Columnar
database
Columnar
database
Document
database
P3 PnP1 P2
A
B
C
E F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
P2
P1
J p11
D
P3
p10
The fragment hash will help on the
data placement. Based on the triple
and the size of the fragment,
Rendezvous will find the best
partition to store a triple.
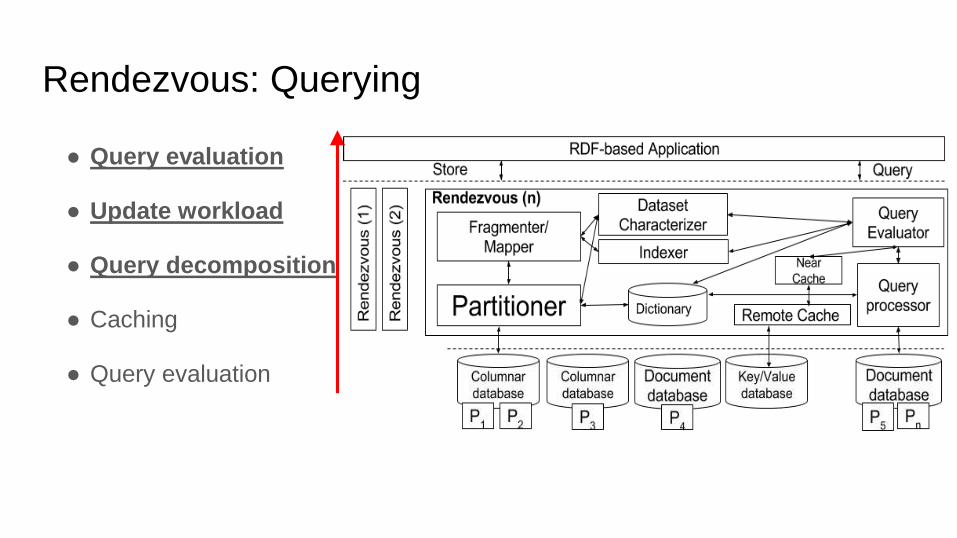
Rendezvous: Querying
● Query evaluation
● Update workload
● Query decomposition
● Caching
● Query evaluation
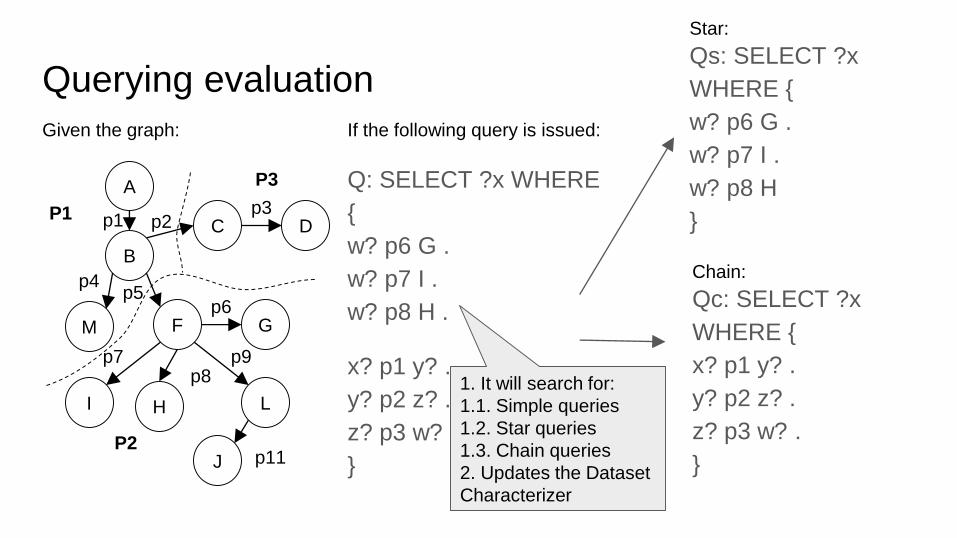
Querying evaluation
Given the graph:
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
If the following query is issued:
Q: SELECT ?x WHERE
{
w? p6 G .
w? p7 I .
w? p8 H .
x? p1 y? .
y? p2 z? .
z? p3 w?
} P2
P1
P3
1. It will search for:
1.1. Simple queries
1.2. Star queries
1.3. Chain queries
2. Updates the Dataset
Characterizer
Chain:
Qc: SELECT ?x
WHERE {
x? p1 y? .
y? p2 z? .
z? p3 w? .
}
Star:
Qs: SELECT ?x
WHERE {
w? p6 G .
w? p7 I .
w? p8 H
}
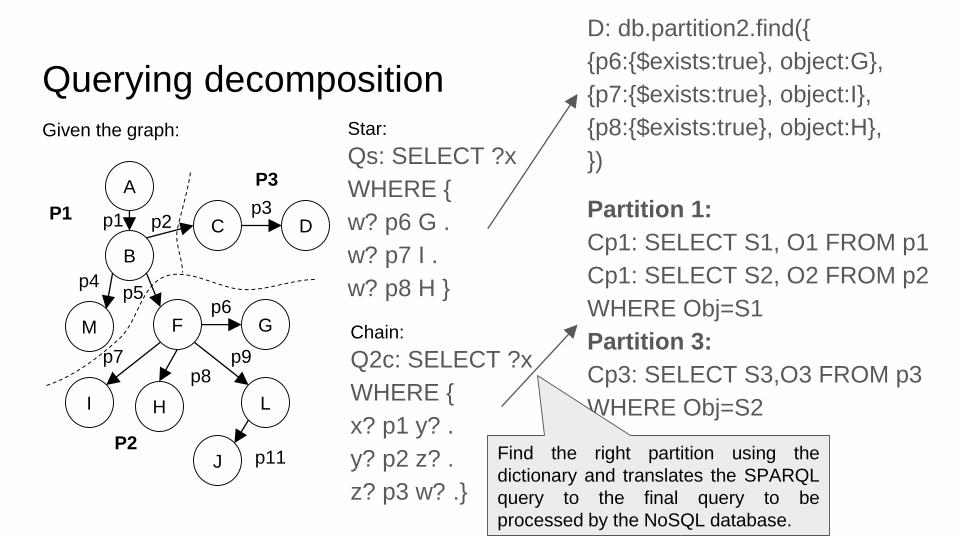
Querying decomposition
Given the graph:
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
P2
P1
P3
Chain:
Q2c: SELECT ?x
WHERE {
x? p1 y? .
y? p2 z? .
z? p3 w? .}
Star:
Qs: SELECT ?x
WHERE {
w? p6 G .
w? p7 I .
w? p8 H }
D: db.partition2.find({
{p6:{$exists:true}, object:G},
{p7:{$exists:true}, object:I},
{p8:{$exists:true}, object:H},
})
Partition 1:
Cp1: SELECT S1, O1 FROM p1
Cp1: SELECT S2, O2 FROM p2
WHERE Obj=S1
Partition 3:
Cp3: SELECT S3,O3 FROM p3
WHERE Obj=S2
Find the right partition using the
dictionary and translates the SPARQL
query to the final query to be
processed by the NoSQL database.
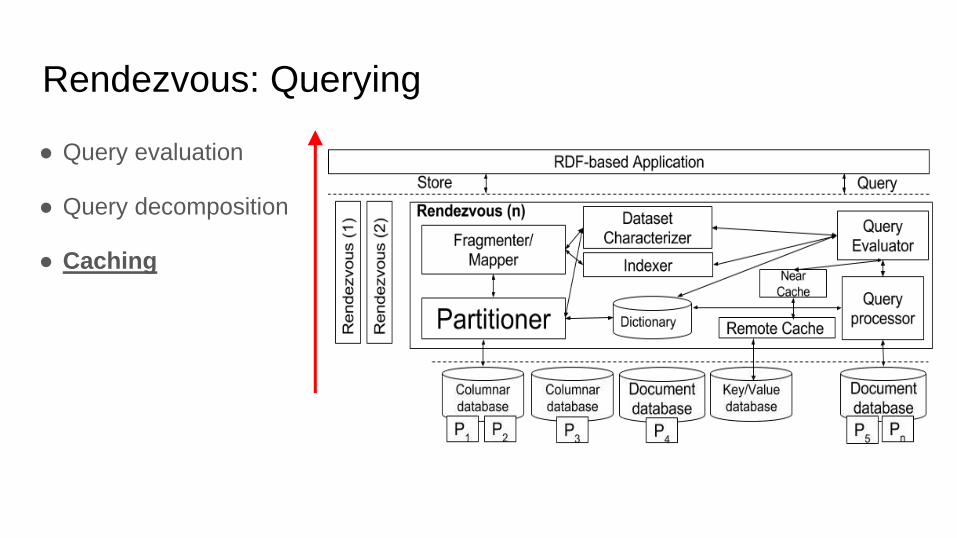
Rendezvous: Querying
● Query evaluation
● Query decomposition
● Caching
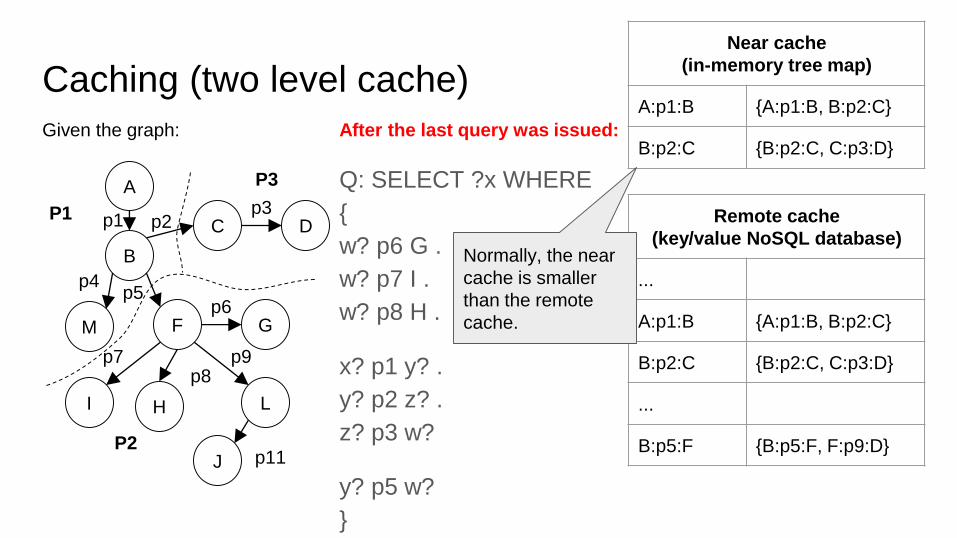
Caching (two level cache)
Given the graph:
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
After the last query was issued:
Q: SELECT ?x WHERE
{
w? p6 G .
w? p7 I .
w? p8 H .
x? p1 y? .
y? p2 z? .
z? p3 w?
y? p5 w?
}
P2
P1
P3
Near cache
(in-memory tree map)
A:p1:B {A:p1:B, B:p2:C}
B:p2:C {B:p2:C, C:p3:D}
Remote cache
(key/value NoSQL database)
...
A:p1:B {A:p1:B, B:p2:C}
B:p2:C {B:p2:C, C:p3:D}
...
B:p5:F {B:p5:F, F:p9:D}
Normally, the near
cache is smaller
than the remote
cache.
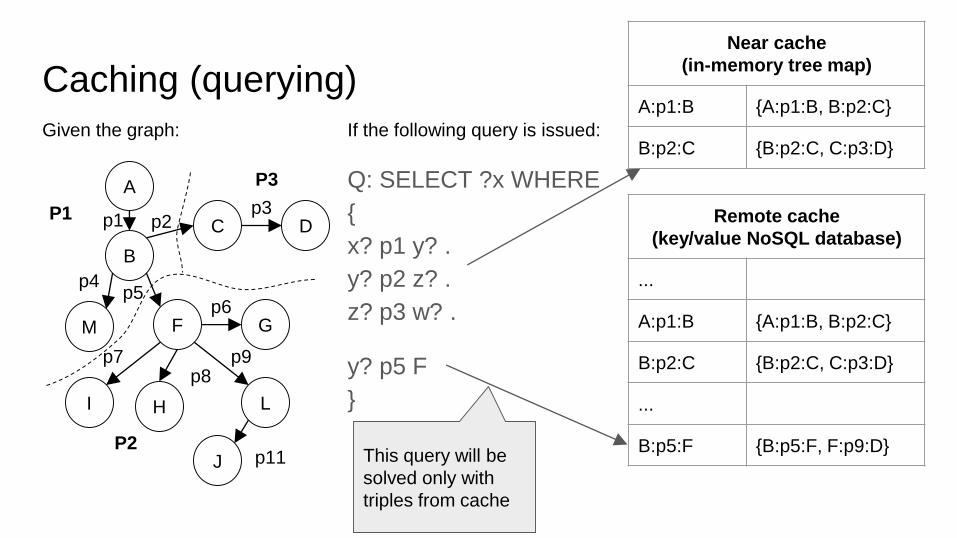
Caching (querying)
Given the graph:
A
B
C
M F G
LHI
p1 p2p3
p4p5
p6
p7 p9p8
J p11
D
If the following query is issued:
Q: SELECT ?x WHERE
{
x? p1 y? .
y? p2 z? .
z? p3 w? .
y? p5 F
}
P2
P1
P3
Near cache
(in-memory tree map)
A:p1:B {A:p1:B, B:p2:C}
B:p2:C {B:p2:C, C:p3:D}
Remote cache
(key/value NoSQL database)
...
A:p1:B {A:p1:B, B:p2:C}
B:p2:C {B:p2:C, C:p3:D}
...
B:p5:F {B:p5:F, F:p9:D}This query will be
solved only with
triples from cache

Agenda
● Introduction: Motivation, objectives, and contributions
● Background
○ RDF
○ NoSQL
● State of the Art
● Rendezvous
○ Storing: Fragmentation, Partitioning, and Mapping
○ Querying: Query decomposition and Caching
● Evaluation

Evaluation
● LUBM: ontology for the University domain, synthetic RDF data scalable to any
size, and 14 extensional queries representing a variety of properties
● Generated dataset with 4000 universities (around 100 GB and contains
around 500 million triples)
● 12 queries with joins, all of them have at least one subject-subject join, and
six of them also have at least one subject-object join
● Apache Jena version 3.2.0 with Java 1.8, and we use Redis 3.2, MongoDB
3.4.3, and Apache Cassandra 3.10
● Amazon m3.xlarge spot with 7.5 GB of memory and 1 x 32 SSD capacity
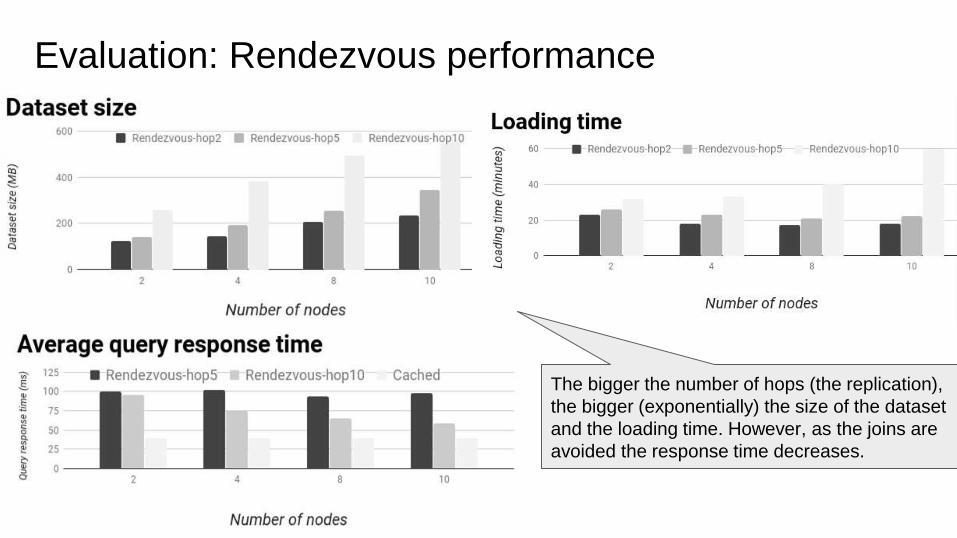
Evaluation: Rendezvous performance
The bigger the number of hops (the replication),
the bigger (exponentially) the size of the dataset
and the loading time. However, as the joins are
avoided the response time decreases.

Evaluation: Rendezvous vs. ScalaRDF

Conclusions
● Rendezvous contributes on:
○ Graph partitioning problem via fragments
○ Better query response time through n-hop and partition boundary
replication
○ Better query response time via two-level caching
○ Scalable RDF storage provided by NoSQL databases (polyglot
persistence)
● About the preliminary evaluation:
○ Fragments are scalable

Current state● Accepted papers
○ SBBD 2017: “Workload-Aware RDF Partitioning and SPARQL Query Caching for Massive
RDF Graphs stored in NoSQL Databases”
● Submissions
○ SAC 2018: “Large scale RDF storage using multiple NoSQL databases”
○ TKDE: “Persistence of RDF Data into NoSQL Databases: A Survey and a Unified Reference
Architecture”
○ VLDB 2018: TBD
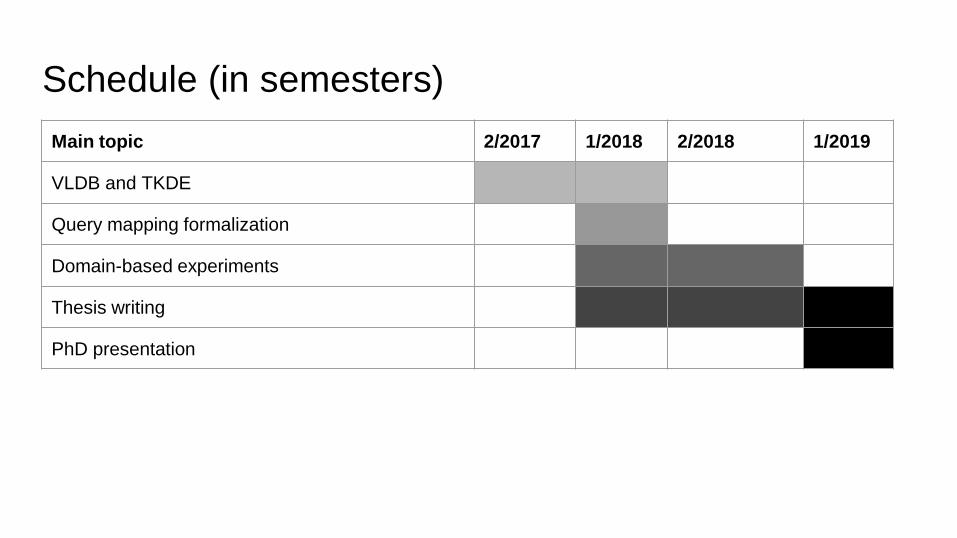
Schedule (in semesters)
Main topic 2/2017 1/2018 2/2018 1/2019
VLDB and TKDE
Query mapping formalization
Domain-based experiments
Thesis writing
PhD presentation

Obrigado!
Simpósio Brasileiro de Banco de Dados (SBBD)
Uberlândia, Outubro/2017
Luiz Henrique Zambom Santana
Prof. Dr. Ronaldo dos Santos Mello
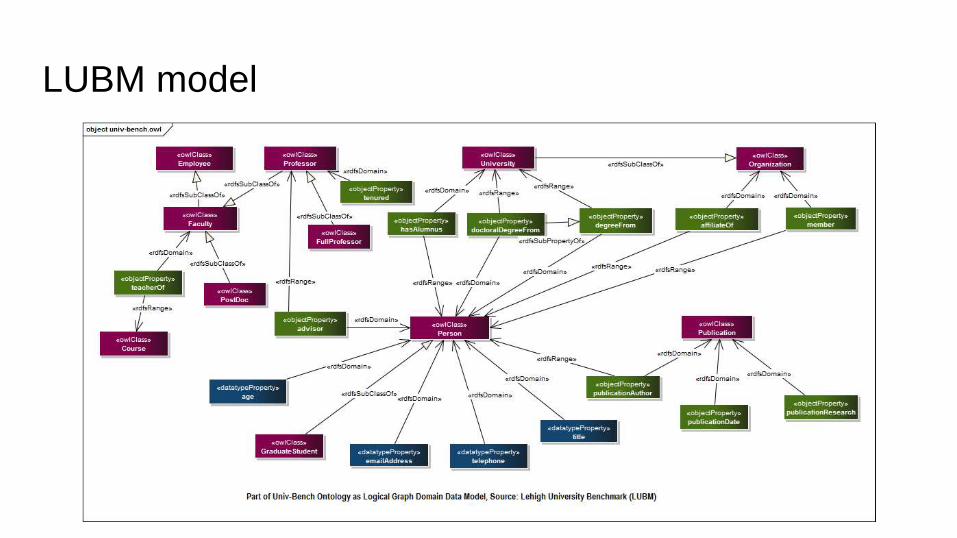
LUBM model

Storing: Fragmentation

Storing: Fragmentation

Storing: Fragmentation

Storing: Partitioning
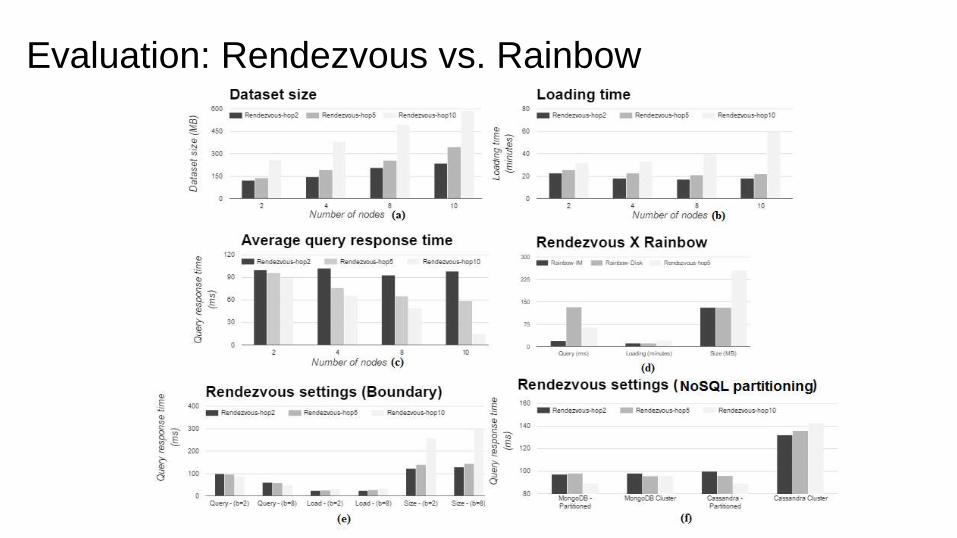
Evaluation: Rendezvous vs. Rainbow

State of the Art - NoSQL Triplestores
RDFJoin, RDFKB, Jena+HBase, Hive+HBase, CumulusRDF,
Rya, Stratustore, MAPSIN, H2RDF, AMADA, Trinity.RDF,
H2RDF+, MonetDBRDF, xR2RML, W3C RDF/JSON,
Rainbow, Sempala, PrestoRDF, RDFChain, Tomaszuk,
Bouhali, and Laurent, Papailiou et al., and, ScalaRDF.

Scope limit
● Indexing is only for completeness
● No machine learning nor statistical analysis