a longitudinal analysis of search engine index size
TRANSCRIPT

A longitudinal analysis of search engine index sizeAntal van den Bosch^, Toine Bogers*, Maurice de Kunder#
^ Radboud University, Nijmegen, the Netherlands
* Aalborg University Copenhagen, Denmark# De Kunder Internet Media BV, Nijmegen, the Netherlands
ISSI 2015, Istanbul, TurkeyJune 29 – July 3, 2015

Introduction• Webometrics is the study of the content, structure and technologies
of the WWW (Almind & Ingwersen, 1997; Thelwall, 2009)
- Research topics include link structure, Web citation analysis, user
demographics, Web page credibility, search engines, and WWW size
• Size of the WWW is hard to measure!
- Only subset is accessible through search engines and Web crawling (aka
the Surface web)
‣ Deep web is the part of the WWW not indexed by search engines
- Most work has therefore focused on estimating search engine index size
2

Introduction• Our work focuses on the estimation of index sizes of individual
search engines
• Why is this important?
- Index size used to be a competitive advantage for search engines‣ Slowly been superseded by recency and personalization
- Index size is an important aspect of the quality of a Web search engine
- Provides a ceiling estimate of the size of the WWW accessible to the
average Internet user
3

Contributions of this work1. A novel method of estimating the size of a Web search engine’s
index
2. A longitudinal analysis of the size of Google and Bing’s indexes over
a nine-year period
4

Background• Index size estimation
- Bharat & Broder (1998) estimated the size of the indexed WWW using
self-reported index sizes and overlap estimates → 200 million pages
- Gulli et al. (2005) extended their work → 11.5 billion pages
- Lawrence & Giles (1998) estimated the size using capture-recapture
methodology and self-reported index sizes → 320 million pages
- Lawrence & Giles (1999) updated their own work → 800 million pages
- Dobra et al. (2004) updated the original 1998 estimates of Lawrence &
Giles (1998) → doubled to 788 million pages in 1998
5

Background• Some related work on the stability of search engine results
- In terms of hit counts, rankings, and persistence of results
• Problem: no true longitudinal studies on hit counts or index size!
- Longest period for hit count variability studies was 3 months (Rousseau,
1999)
• Question: how stable are studies based on hit counts over time?
- We attempt to provide an answer by analyzing the results of a novel
estimation method over a nine-year period (March 2006 – January 2015)
6

Methodology• Our method: estimation through extrapolation- We extrapolate the unknown index size by using another textual training
corpus that is fully available to us
- We assume that for in-domain corpora the relative document frequencies will be the same
- Results in following formula:
7
= |C |=df w,C ⇥ |T |
df w,Tindex size
|C ||T |
df w,C
df w,T
= size of index
= size of training corpus
= hit count
= doc frequency of w in T

Methodology• Our method: estimation through extrapolation- We extrapolate the unknown index size by using another textual training
corpus that is fully available to us
- We assume that for in-domain corpora the relative document frequencies will be the same
- Results in following formula:
7
= |C |=df w,C ⇥ |T |
df w,Tindex size
|C ||T |
df w,C
df w,T
= size of index
= size of training corpus
= hit count
= doc frequency of w in T

Methodology• Selecting a training corpus
- Should be representative of Web search engine indexes
- Crawled a random selection of 531,624 Web pages from DMOZ‣ 254,094,395 word tokens and 4,395,017 unique word types
• Estimation example for the term ‘are’:
- ‘are’ occurs in 50% of all DMOZ documents
- Google hit count is 17,540,000,000 pages
- Extrapolation: Google’s index contains 35 billion pages
8

Methodology• Which terms should we use for the extrapolation?
- Single-word terms are preferred according to Uyar (2009)
- Random selection of word types will oversample low-frequent words as
predicted by Zipf’s second law
- Terms should be sampled from across document frequency bands →
selected exponential series of selection rank with exponent 1.6, rounded
off to the nearest integer
- Set of words used should be not be overly small → averaged estimations over a set of 28 words (where predictions became stable)
9

Methodology• Final set of 28 selected words:
10
and was photo preliminary accordée
of can headlines definite reticular
to do william psychologists recitificació
for people basketball vielfalt
on very spread illini
are show nfl chèque

Methodology• Validation
- Predictions on an out-of-sample DMOZ test corpus were only off by 1.3%
• Daily procedure
- Estimate index size for each of these 28 words
- Average all estimates into a single estimate
- Rinse and repeat
11

Methodology• Collected data from two search engines from March 2006 – January 2015
- Google: 3,027 data points (93.6% of all possible days)
- Bing: 3,002 data points (92.8% of all possible days)
12
Google Bing (aka Live Search)

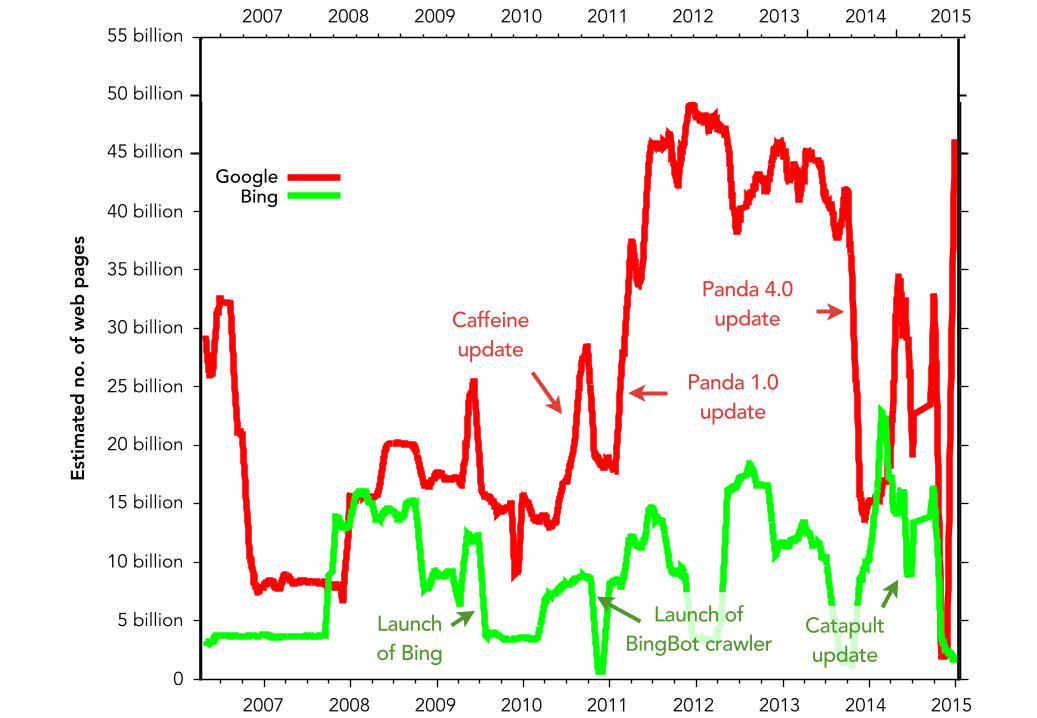
Results• Google usually has the largest index
- Peak of 49.4 billion pages (December 2011)
- Bing has a peak of 23 billion pages (March 2014)
• Both search engines show great variability!
13

0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
Estim
ated
no.
of w
eb p
ages
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. num
ber
of w
eb p
ages
Year
GoogleBing
10 billion
5 billion
20 billion
15 billion
30 billion
25 billion
40 billion
35 billion
45 billion
55 billion
50 billion
0
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
2007 2008 2009 2010 2011 2012 2013 2014 2015
2007 2008 2009 2010 2011 2012 2013 2014 2015
GoogleBing
Each point is a moving average
over 31 days

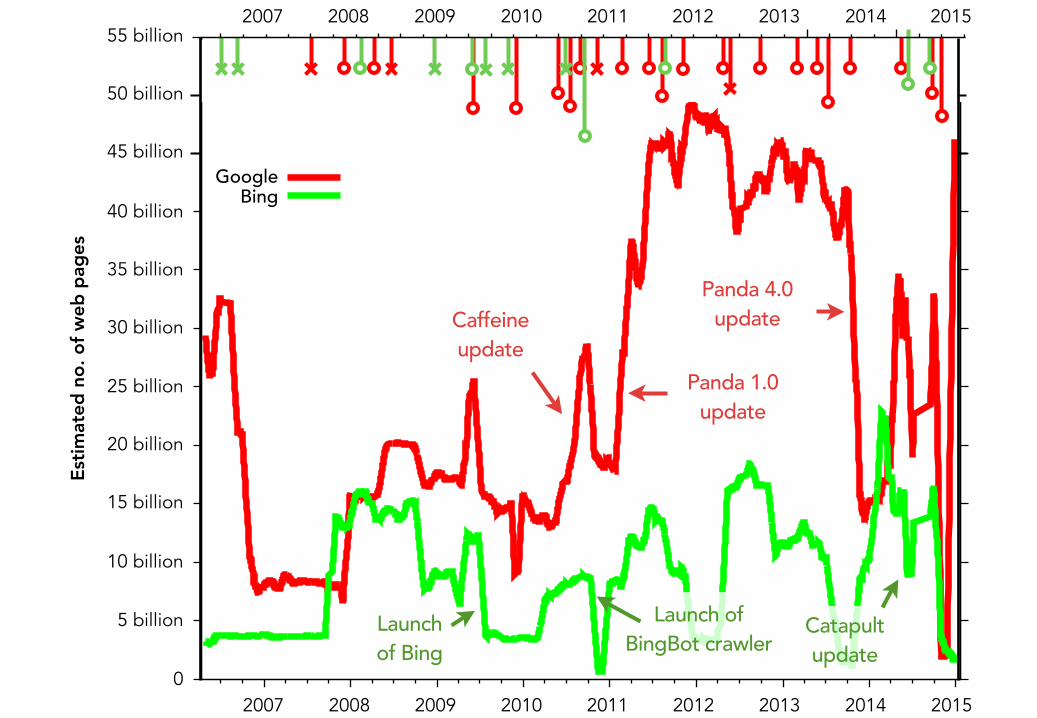
What causes this variability?• Intrinsic variability- However, it performs well on a representative in-domain sample - Rel. doc. frequency is unlikely to radically change over short time periods!
• Extrinsic variability- Changes in indexing and ranking infrastructure happen all the time‣ Google makes “roughly 500 changes to our search algorithm in a typical year” (Cutts,
2011)
- Affects the hit count estimates and thus the index size estimates!
- Examined Google and Bing search engine blogs for reported changes
15
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
Estim
ated
no.
of w
eb p
ages
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. num
ber
of w
eb p
ages
Year
GoogleBing
10 billion
5 billion
20 billion
15 billion
30 billion
25 billion
40 billion
35 billion
45 billion
55 billion
50 billion
0
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
2007 2008 2009 2010 2011 2012 2013 2014 2015
2007 2008 2009 2010 2011 2012 2013 2014 2015
GoogleBing
Caffeine update
Panda 1.0 update
Panda 4.0 update
Launch of Bing
Launch of BingBot crawler
Catapult update
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
Estim
ated
no.
of w
eb p
ages
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. num
ber
of w
eb p
ages
Year
GoogleBing
10 billion
5 billion
20 billion
15 billion
30 billion
25 billion
40 billion
35 billion
45 billion
55 billion
50 billion
0
0
5x109
1x1010
1.5x1010
2x1010
2.5x1010
3x1010
3.5x1010
4x1010
4.5x1010
5x1010
2007 2008 2009 2010 2011 2012 2013 2014 2015
Est
. n
um
be
r o
f w
eb
pa
ge
s
Year
GoogleBing
2007 2008 2009 2010 2011 2012 2013 2014 2015
2007 2008 2009 2010 2011 2012 2013 2014 2015
GoogleBing
Launch of Bing
Caffeine update
Panda 1.0 update
Panda 4.0 update
Launch of BingBot crawler
Catapult update

Discussion• Estimation bias
- Distributed indexes result in hit count variability‣ Different servers contain different shards in different states of up-to-dateness
- Modern search engines use Document-at-a-time (DAAT) processing
‣ Means they traverse the postings list of an index until they have found enough matching documents, not until they’ve found all matching documents
‣ Overall hit counts are then estimated using statistical prediction methods
• Language
- English dominates the WWW (55%), DMOZ might suffer from this even more
19

Discussion• Cut-off bias
- Search engines are reported to cut off indexing up to a certain size
- If that size is equal to the average DMOZ page size, then our estimates
are great :)
• Quality bias
- DMOZ is a curated directory of ‘good’ websites
- May not be representative of the ‘average’ website
20

Conclusions• Long-term longitudinal analysis of search engine index sizes
- Estimation using hit counts shows great variability over time!
• Much of the variability seems attributable to infrastructure changes- 72% of infrastructure changes are reflected in estimate variation
- Be careful when using hit counts for one-off Webometric studies!- Confirmation of work by Rousseau (1999), Bar-Ilan (1999), and Payne &
Thelwall (2008)
• Future work will focus on extending the analysis to other languages
21

Questions? Comments? Suggestions?
Thanks for your attention!
22

References• Almind, T.C. & Ingwersen, P. (1997). Informetric Analyses on the World
Wide Web: Methodological Approaches to ‘Webometrics’. Journal of
Documentation, 53, pp. 404–426.
• Bar-Ilan, J. (1999). Search Engine Results over Time: A Case Study on
Search Engine Stability. Cybermetrics, 2, 1.
• Bharat, K. & Broder, A. (1998). A Technique for Measuring the Relative Size
and Overlap of Public Web Search Engines. In Proceedings of WWW ’98
(pp. 379–388). New York, NY, USA: ACM Press.
23

References• Cutts, M. (2011). Ten Algorithm Changes on Inside Search, Google Official
Blog. Available at http://googleblog.blogspot.com/2011/11/ten-algorithm-changes-on-inside-search.html, last visited January 21, 2015.
• Dobra, A. & Fienberg, S.E. (2004). How Large is the World Wide Web? In
Web Dynamics (pp. 23– 43). Berlin: Springer.
• Gulli, A. & Signorini, A. (2005). The Indexable Web is More than 11.5 Billion
Pages. In Proceedings of WWW ’05 (pp. 902–903). New York, NY, USA:
ACM Press.
24

References• Lawrence, S. & Giles, C.L. (1998). Searching the World Wide Web. Science,
280, pp. 98–100.
• Lawrence, S. & Giles, C.L. (1999). Accessibility of Information on the Web.
Nature, 400, pp. 107–109.
• Payne, N. & Thelwall, M. (2008). Longitudinal Trends in Academic Web
Links. Journal of Information Science, 34, pp. 3–14.
• Rousseau, R. (1999). Daily Time Series of Common Single Word Searches in
AltaVista and NorthernLight. Cybermetrics, 2, 1.
25

References• Thelwall, M. (2008). Quantitative Comparisons of Search Engine Results.
Journal of the American Society for Information Science and Technology,
59, pp. 1702–1710.
• Thelwall, M. (2009). Introduction to Webometrics: Quantitative Web
Research for the Social Sciences. Synthesis Lectures on Information
Concepts, Retrieval, and Services, 1, pp. 1–116.
• Thelwall, M. & Sud, P. (2012). Webometric Research with the Bing Search
API 2.0. Journal of Informetrics, 6, pp. 44–52.
26