a framework for global optimization of aggregate …people.inf.elte.hu/kiss/cikkek/018 optimization...
TRANSCRIPT

,- !
‘: 1
'.._ . ..' ,"I.,'
I , I
,. ,
I,
I
.* -,.-I ,.
.~ , i ::
.;
I_, 5 : '; i;' (
~ -, 5 : i
~:. ,f :' i
~.,- 1 _
,_ I ? '.., ! I ;s ., .;
: I, '_
r*. ,::,:
"! j ,.,-. "<.,z (
.-. :',; 4 ',- <_ L
~
-'; j _ *;
.,,>,' J$ ;; 1 ~- ;1: f 1, 1
. ,J '
;, r I
,: : I,
I' .', ,
~ 1: . . '> ;;
~: cc<. ,
.:. 1 ~ ~ '.
: ,. kz:
i; +, : .h'
,,_ I " !
i- ; 1 ,,-.-,.
.'I .I :-. +
. ,.,,. ., ;:':. . J>,
.“i 7' ..;: ,- . ..' .*
A Framework for Global Optimization of Aggregate Queries
Chengwen Liu and Andrei Ursu School of Computer Science,, Telecommunications and Information Systems
DePaul University, Chicago, Illinois [email protected], [email protected]
Abstract
With recent emphasis placed by data warehouse applications on aggregate queries with vatious grouping criteria, it is natural to expect muhiple aggregate queries on the same set of tables. In this paper, we provide a fmmework for global optimization of aggregate queries under the concept of aggregate query blocks. We propose an extension to SQL to allow users to define explicit query blocks. The paper coveys the integration of the gZobaZ aggregate optimization with the oprimization of individual queries. We present easy-to-implement optimization algolithms applicable to aggregate query blocks. We show that these algorirhms add minimum overhead to the fofai optimization cost, whiie dramatically reducing the overall execution cost.
1. Introduction
With the recent developments in data warehouse applications and tools, more emphasis is pIaced on decision support type of database queries. These queries can be quite complex and expensive, and they often aggregate the same detaiI-level data according to different criteria. For example, in a commercial iusurance database, one query may request the average claim expense by customer, while another query may extract the average claim expense by injury type. Both queries will probably require a tabIe scan on a huge’ table containing all &ims.
There is a potential for dramatically reducing repetitive table scans for different aggregate queries, if we could execute multiple independent aggregations in only one table scan, while accumulating the results iu temporary storage. Such an optimization is gIobal in nature, since it spans across multiple independent queries.
Global optimization is practical only when a block of multipIe queries (SQL block) is submitted at the same time, as a program unit, to the server. This requirement comes from the fact that parallel execution of two queries is only possible when the user does not need to receive the results of the fust query, before submitting the next one. This requirement can very often be satisfied. The client-server model of computing for database applications has generated the concepts of SQL Batches and Stored Procedures to support it. These SQL programs are usually being compiled as a unit.
Pemhsimr to mnkr digitalflwd qics uiall ur p:u~ ohhis nl;lthl !iw pS%Onal of cl~f00~11 use is granted without f&2 prouidal lht Ilic wpis are not nwdt: or disWihnt4 (br pmlit tw cxmmmercinl ad~t~tngz. Uu copy- rigId notice Uw IiUu ollhc pclbliuh~i and its dnle appear. and noti~v is given that copyright ix hy p37nisiurl oflhe ACM. Inc. To copy ell~~nvisc to republish. to post on servers or IO rrrlistributu IO lists rquirti spxitic pcnnkion .w&or kc.
Once we are in the context of au SQL black, each query is compiled and optimized. After the optimization of the individual queries, we can utilii the set of individual plans to determine the queries that could participate in global execution plans,
In this paper we focus on aggregate queries. We call a group of aggregate queries that can be executed in parallel, nccordiig lo n global aggregate query plan, an aggregate query block. Such a model requires special language constructs to delimit the beginning and the end of an aggregate query block, unless nn efficient method can be devised for automatically determining the queries eligible to participate in the block. Each aggregutc query block is clustered around a ‘gpivoP’ relation, whose ncccss (either by table or index scan) will be shared by all queries in the aggregate query block.
The global execution plan must take into consideration the need to temporarily store (in cache or on disk) the relevant data values @arkI aggregate function results for each query) as it accesses the pivot table. Dependiig on the queries involved, either during the access to the pivot table, or after the computation of all aggregate values, we will join the temporary result table with the remaining relations from the original individual quq plMS. It remains to determine whether for each aggregate query block, tbc global algorithm yields a faster total query plan !hnn the sum of the estimated cost of each individual query plan, If the global plan is faster, we substitute it for the original query plans, At the end, we need to make sure that we return each result set in lhc order iu which the original queries were apecitied in ihc SQL block.
The rest of the paper is organized as follows. In Section 2, wo discuss related work. Section 3 introduces our optimization framework, a proposed syntax for delimiting aggregate qucty blocks and an example. The optimization nlgorithms arc presented in Section 4. In Section 5, we propose a cost model and estimate the cost of the algorithms as well as the potcntinl execution time savings. Finally, in Section 6 we provide conclusions and f&ure research directions.
2. Related Work
Most of the research in query optimization has been focusing on single query optimization, including parallel query optimization algorithms. Aggregate query optimization for single queries has become a focus since 1994, given the recent emphasis on data warehousing and data mining type of queries (YP94, CSW, CS96, BGI96]. Global or multiple query optimization (MQO) has been studied for a longer time p82, S86, RC88] mostly from the point of view of common subexpression exploitation,
CIKM 97 ,k,‘S~~@7.~ ~kV,ch i.t%‘i Copy+~[ 1997 K’AZ U-X9791-97U-xi973 1..~3..s~l 262

., 6’ ,, _ -. “12..
-F ..F: I L
According to our knowledge, no paper to date takes into consideration aggregate queries within the context of MQO.
In PC881 we fmd a good summary of the work to that date in MQO, and a proposal for an architecture for multiple query processing (MQP) that is modular and aliows new algorithms for various stages of the optimization process to be added easily. The glue of the proposed architecture is au AND-OR graph for both levels of query abstraction: the logical level - selection, projection, join - and physical level: scans, sorting, nested loops. The multiple strategies for query execution, including the multiple query strategies (‘multi-strategy”) are alternate sub- trees rooted in the original queries. The multi-strategy trees share at least one operator node.
[Al2941 provides an analysis of various common sub-expressions exploitation in MQP algorithms. The focus is on sub-expressions that are not necessarily equivalent, but are related by intersection (which means their results’ intersection in a non-null set).
In the area of group-by optimizations, both [CS94] and ryL94] introduced the idea of computing group-by before join at about the same time. Proof of necessary and sufficient conditions for deciding to push the groupby operation past one or more joins is given in ryL94]. The resulting algorithm would be too expensive for practical implementation, therefore the authors present a simpler and faster algorithm to teat a sufficient condition, for a large subclass of transformable queries. [CS94] generalizes the prior work, allowing for more subtle transformations that can push the group-by before joins even when the original groupby is on a higher cardinal@ set of attributes than the join keys.
All papers dealing with groupby optimizations only consider the single query case, and are orthogonal to the probIem of MQO.
A recent paper generalii the groupby operator into a onestep multidimensional aggregation operator called Data Cube [G+96]. This proposal includes a few power&l operators such as histograms (aggregation over computed grouping criteria), rollup (cumulative aggregations on left-to-right sub-sets of the base grouping columns), and the cube itself, or cross-tabulation (the symmetric super-aggregation or roll-up by all sub-sets of the base grouping columns). These operators are proposed as syntactical extensions of SQL. The implicit assumption is that the optimizer would easily utilize a single scan on the base table for computing all multi-dimensional aggregates. No explicit mention is made about applying the cube to join operations, except for the simple loohup case (where the group-by and join attribute sets are disjoint, and do not need to be intertwined). Actually the group by optimizations described in [CS94] will not work with the cube operator, since the proposed coalescing transformations of group by may generate new group-by operations with lower cardinatity columns (foreign keys of the join), while the original columns are used by the cube operator for all possible grouping combinations. The cost of reconstructing all of cube’s multidimensional aggregations after such transformations would be prohibitively costly.
Another approach for multidimensional aggregation is the Compute-By constructs implemented in the Sybase RDBMS product as au addition to the order-by clause. In the following, we use an example to illustrate the two constructs.
263
Given the data set
The following proposed rollup syntax:
select model, year, color, sum(volume) from sales group by model, year, color with rdup
.
would produce the following result set:
Chevy 94 Chevy 94 Chevy ALL Ford 94 Ford 94 Ford 95 Ford 95 Ford 95 Ford ALL ALL ALL
Blue Red
100 100 100 50 50 100 120 220 270 370
As cau be seen, the mllup construct produces nested uggregaea for all proper leff-to-right subsets of the groupby list. On the other hand, the following Sybase syntax:
select model, year, color, volume horn sales order by model, year, color compute TI =sum(volume) by model, year, color compute T2=sum(volume) by model, year compute T3=sum(volume) by model compute T4=sum(volume)
Would produce the following report:

,- <
:
. ,
I 1 .
,‘A
j
-1
,I
1)
.I
I’ -;
,;: ’ , “ 1
I --- #
I_ .,
‘. I
::-i
. . .
1’ _
1
-.
‘I ,.- .,. 1
!
.,. ,.
..,‘. ’ .J
,. II
‘, -,>- , .r, I
:.,, : .
_. ,!. ._I
-/ r .’ ;
. ‘. , ‘LI 1
-2 ->: ‘: 3,. ,
,, IA ,‘. f 1
‘<:*-‘, .,L’. ., ,,15 ‘7 i
,-. I i ,“,.. ,.I
‘- c. .,.C’ ! ;’ -*j
’ ‘:,<; ., .,~., ‘.\.::: . :
~- ‘:‘-. II
: .. .., ;
I >’ .,’ 1 .
‘. :
-; j
..i
‘<. 1. ,I
As can be seen, the two result sets are essentially the same, with more detailed information reported by the second form. The compute-by constrnct is an SQL extension that allows the calculation of several aggregates within au order-by query, with the aggregate results being interspersed with the actual result data rows. The aggregations can be viewed as running cumulative summary values for nested buckets of the result set. Simkly to the proposed rollup, these nested buckets are defined based on the values of the proper lef&-right sub-sets of the base order-by cohnnns.
algorithms such as those in [CS94] and uses a global optimization fiamework similar to the one introduced in [RC88]. The fi-amework is sketched as the following:
1. Optimize each query in the SQL block individually
2. Utilize the resulting set of individual query plans to determine the set of uggregute query bloch.
3. For each aggregate query block generate the nn&,~lc aggregate query executionplan (MAQE?P).
To our knowledge, the cube and the compu&by constructs are the only approaches of multiple dimension aggregations during the same scan of a base relation. The work presented in this paper is related to these constructs in that it also allows the caMafion of multiple dimension aggregations in the same scan. The difference is that we are proposing an optimization fiumework for muhipie queries, with arbitray aggregations, which was not provided in previous work. The queries do not necessarily have to be related via a cube, rollup, or computeby. In fact, these constructs can be gIobalIy optimized together with other standard aggregate queries by our algorithm. For example, both the rollup and the compute-by shown above could be optimized together to produce a single table scan.
4. Return the results to the user in the order in which tic original queries were specified
3.2. Proposed Extension to SQL
Since our framework is based on the concept of Query Blocks (QB), it is important for the optimizer to identify query blocks, These query blocks cau be either implicit or explicit, Implicit query blocks are contained in SQL batches or stored procedures that can be identified by the optimizer, while explicit qncry blocks are specified by the user with the following SQL synlnx:
Mhough OUT approach does contain a proposal for an optional SQL extension, its main advantage is in the optimization bework, which is lransparent IO the user. This means that the optimization can occur even without a specific syntactic construct. From a migration point of view, optimizer extensions are easier to impIement, since existing applications would not need to change (syntax transparency).
Begin Que y-3lock; <quelyl>; ww)?>; . . . +P=Y=-;
End Quey-Block;
Our method aiows for any number of aggregate queries on the same table or set of tables, on any number of group-by cohunns, to be optimized, as opposed to just the groupby set specified in the cube or compute-by clause.
Each query in the query block can be any type of SQL query. WC specificaUy consider the foliowing syntax similar to that assumed in [CS94]:
select All ~columnlisE-, AGGl@I),..,AGGn@n) from <tablelisP where wndl and cond2 . ..and condk group by toll,..., colj
3. The Framework and an Extension to SQL
3.1. MAQO Framework
We propose a new strategy for global optimization of kegate queries: the Multiple Aggregate Query Opfimizntion &12@0)
framework The tiamework is based on the concept of SQL blocks. We define an SQL block as a sequence of queries that are part of a batch or stored procedure which are executed sequentially, with no control of flow statements between them, and no variables passed between them. The user does not need to receive the results of the iirst query, before submitting the second one. This means the queries’ results are independent, thus making the order of execution irrelevant. It also means a parallel (or YnterhvimP) execution plan is possible. An aggregate quety block (AQB) is a group of aggregate queries v&ich are part of the same SQL block and can be executed according to a global aggregate query plan.
Columns (bl,...,bn} are called aggregating coltmnttts. The functions (AGGl,...,AGGn} are calicd the aggregate jitttctlott~ of the query. They can be sum, uvg, max, min, or cottnf.
The SQL92 syntax requires that ~columnlist, must be part of &ho grouping columns of the query toll,..., colj, although it can bc easily shown that <columnlist> may also contain columns which arefunctionally deptdenf on the set toll,..., colj.
We say that an expression is functionally dependent on a column listwll,..., corj ifits value can be inferred via a join.(or string of joins) to a fable in which a subset of toll,..., colj acts as ptimnry key. [G+96] uses the term decoratim column for SUCK expressions, and recommends them to be included in the sclcct list ccolumnlist>. Such an addition would not impact the global optimizations proposed in this paper.
As can be seen, having and order-by is not taken into account nt this time.
The MAQO tiework assumes the optimizations of the individual groupby operations by previously proposed
The purpose of this construct is to allow users to tell the system whether to apply global optimization. A QB can include cube,
264
.: I

;.; .~ -; : r;;,: , 9 :
rollup and compute-by queries, and it has the following additional advantages:
l The impact on the user code is minimaI. .
l Only the desired aggregates are computed
l Allows for the generalized coalescing grouping [GCG] transformation of each individual query before attempting global optimization, therefore increasing the chances for global optimizations.
where productpid = sale-orderpid and customercid = sale_order.cid group by division, state;
Note that in 42, none of the grouping attributes (division, state) are part of tbe &e-order table, although the aggregation attribute (amt) does belong to it.
The syntax-based delimitation of the query block may seem redundant since SQL BUSC~W.V and Stored Procedures can be treated as query blocks by default. Nevertheless, it is useful for several reasons:
l It gives experienced users the power and flexibility to infhrence the behavior of the query optimizer for better performauce.
The standard (original) execution plans for Ql and Q2 can be expressed as the annotated leftdeep join trees in Figure 1. An annotated join tree is a representation of the query execution plan where the root is a groupby operation, and each leaf node is a scan operation (on dati pages or index search) on a table. Each internal node represents a join operation. Annotations of a join node may include the join method, selection conditions and the list of projection attributes. For execution efficiency, the execution space is often restricted to be the class of left-deep join trees, where the right child of every internal node is a leaf.
l It gives the DBA the power to choose whether to treat SQL compute avg(price) batches and stored procedures as default query blocks for group by pid the purpose of gIoba1 optimization. I
l Depending on the implementation, for very large batches or stored procedures, the global optimizing engine may simply give up on some combinations of queries. The syntax-based delimitation ensures that certain aggregate query blocks will always be 0pGmized.
I sale-order.
3.3. An Example
As an example, we consider the database of a company that takes orders from customers for a variety of its products. A sale order has an order identifier, a product, a customer, an amount ordered and a price. A product has its own identitier and a name, is produced by a division, and has a certain color. A customer is defmed by its own identifier, a name, an address with zip code and state. The following is a simplified version of the resulting schema:
Figure 1. Execution Plans for Ql and 42
sale-order (oid, pid, cid, amt, price), where: oid = order identifier pid = product identifier cid = customer identifier amt = amount ordered, etc.
It is obvious that the uxmnon sub-expression (CSE) substitution techniques (such as those described in [AR94]) can not be applied in this case, since the grouping columns, aggregating columns and the aggregating fanctions are different between Ql and Q2. It can also be seen that the cube operator would not apply in this case. First, the application does not need all possible combinations of aggregations among cid, pid, division and state, but onIy one aggregate by pid and another by division and state. Second, the original grouping cohmms for the second query (division and state) are not part of the sale-order table, a situation that is not covered by the proposed syntax t%om [W96].
product (pid, name, division, color), where pid = product identifier name = product name, etc.
However, our proposed approach allows the programmer to tell the optimizer that these queries are related and a global aggregate optimization is applied within the quev block (QB):
customer (cid, name, zipcode, state) cid = customer identifier name = customer name, etc.
Begin Query-Block;
select pid avg(price) from sale order group by&
Consider the following queries that report the average price by product (Ql) and the total sales by division and state (42) respectively:
Ql: select pid, avg(price) from sale order group by&k
select division, state, sun@@ horn product sale-order, customer where productpid = sale-orderpid and customercid = sale-ordercid group by division, state-,
End Query~Bfock;
Qz: select division, state, sum(amt) Gem product, sale-order, customer
compute (amolmt)
T
/\ sale-order product
265

,
’
* ;
,I
‘.:: ]
I
‘. i
., I
/
1
.’ ‘._
,) -. .;,-
’ .i ’ -:.. ,, .< .-i ~<_, .:. ..:-; .) :
.*: :&. ;, .j ;‘;
-i 1 , . :c‘: :: ; c -‘:j~4 : ,
‘-..?-,;r, / 1. ,, , .,.--:ds2, !+;y;: ,z p5; +L’- ‘ .*..,,“:~,~~~ ”
,, *..:;..*rr.t + ~;~;SL!~tf$2 -i .,-?..&+I I ( ;y$@g
: ,i:.:,‘r 5 P-p. *.j .g+.+‘-*.s.~ ‘; , lcT -, ‘?~L#>Z.2 i
‘fu;$$j&~~
~‘~~.%~:,~*,$ ! . . s;. :-,. ,; ,y/; 1 “AT :: ; ‘-t;, :: ,. { ‘~:‘:.“~:~>~~r I
-2;;: :$+.:. 8, /,c ; -““.Q :’ ‘:.a ’ i ,‘.
(Y,” . . ‘,. ‘1 ;., :
I. :;
‘, ;
1 ‘, -. </,
I’ ., ’ I. I._ ,.
r
We first apply the generalized coalescing grouping {GCG) tmnsfonnations proposed in [CS94] to Q2. The resulting query plan can be expressed as the following set of three queries with temporary result tab& where 421 reduces the cardiiality of the sale-order table for subsequent joins.
Q21: select cid, Rid, tl=surn{antt) into #U fkm sale order group by %I, pid;
Q22: select division, cid, t2=sum(tl) into #t2 from product, #tl where pmduct.pid = #tl .pid group by division, cid
Q&: select division, state, sum(t.2) fmin customer, #t2 where customerpid = #t2.pid group by division, state;
By usiug the notion of extended annotated join trees introduced in [CS94], we represent the MAQO execution plan for Ql and 42 as shown in Figure 2. An extended annotutedjoin tree is an annotated join tree where a group-by operation may occur in au internal node. That is the group-by has been pushed lower than one or more joins. Extended Zeft-deep join trees are defined similarly. A group-by node in an extended join tree is annotated by the grouping columns and by the uggregati?zg columns. One can easily see that we are able to re-use the scan operation on sale_order which is the most co& one.
compute sum(amt)
join
At omer compute sum(amt) group by division, pid
Figure 2. MAQO Execution Plan
266
4. The Optimization Algorithm
Our optimization strategy is cost-based, meaning it estimates the cost of the individual execution plans, as well as the cost of the global plan, and it selects the cheapest.
4.1. Optimization of individual queries
For the optimization of individual queries, we recommend, besides the traditional join ordering algorithms, the usage of group-by push-down strategies, such as the geizeruilzed coalescing grouping (GCG), which allows for computing the aggregates at the lowest possible level and re~nclinn in subsequent join costs.
4.1.1. Traditional and Current Algorithms
Traditionally, the execution space has been limited to left-deep join trees, which correspond to linear orderings of joins, The scl of relations ~RI...Rn} in the query are sequenced during optimization to yield a join order. The optimization algorithm proceeds stagewise, pmducing optimal plans for subqueries in each stage. At stage i, all possible join plans between the currently optimal subquery Q’ on i tables and nny new table ate enumerated. The best plan will be chosen for the Ned set of i+l tables. Let us refer to this a!goritiun (originally described in [S*79]) as Enumerute.
In practice, varions implementations enumerate al1 pcnutations of table orderings, but place limits on the number of tables considered for permutation, for example four. This is due to the factorial growth of the number of possibilities. The underlying assumption is that it is worth considering all possibilities m order to obtain an optimal plan for the great majority of queries, which contain up to four tables, while accepting less thM optimal plans for the more rare cases of queries with more than four tables.
The current cost-based optimization algorithms take into account statistical distribution tables maintained for each index. The rating of an access method (index or table scan) depends on the estimated number of I/OS, based on the distribution tables and the given search arguments. A sear&r argnmerrt is defined as a search condition on an indexed cohrmn that is compared to a constant, If the constant is known at optimization lime, the actual distribution table can be utilized to estimate the number of pages to be scanned while using this index. If the constant is not known at optimization time, but will evaluate to a constant at run-time, a default distribution is used to rate the index.
According to the structure of the left-deep join trees, the group- by is performed at the root, affer all joins. The group-by is cumntly resolved by almost always using a temporary table to hold intermediate results. This table is usually maintained in cache, where it is often organized as a hashed array. The hash function is chosen to minimize the number of entries per hash bucket. Only in cases of insufficient memory the intcrmedintc result table is saved to disk, in an arca reserved for tcrnporary results. For example, in Sybase, this area is the tcmpomry database rempdb. When storage in tempdb is necessary, the intermediate result table is sorted by the grouping columns, and saved with an additional chskv~dindex on the snmc cohmns.

4.1.2. Pushing Group-by past Joins
In order to improve query processing for aggregate queries, a heuristic algorithm for pushing groupby as far down in the left- deep tree as possible is proposed in [CS94]. The result of applying this algorithm is a generalized coalescing grouping transformation of the original left-deep tree. This heuristic extends the Enumerute algorithm mentioned above. At each step of this algorithm, prior to considering an application of the cnrrent join, an application of a groupby operator is considered on either of the tables considered for join. The cost is computed for the query Q’ at the ith step for each of the cases:
4.3. Multiple Aggregate Query Optimization . (MAQO) Algorithm
. applying the group-by to either one of the tables considered before the join
l just applying the join as in Enumerate
At each step, the partial minimal cost for Q’ is computed and this subquery (and corresponding extended ieftaeep tree) is utilized in the next iteration.
Given au aggregate query block AQB consisting of (QI, 42, . . ., Qn]. Let GEG be the global execution graph that represents the multiple aggregate query execution plan (MAQEP) for AQB and LDTj be the extended leftdeep tree representing the execution plan for Qj. (Note: this is a graph, and not a tree, since it has multiple root nodes, corresponding to each of the results sets, and some nodes have multiple parents; it can also be viewed as a forest, since loom each “Yoot” we can reconstruct a leftdeep tree.) Assume Cost0 is a function which takes a fully annotated LDT as input and retnrns an estimate of the cost for the execution plan represented by the LDT- We also define that LDTl supersedes LJH2 if the result data set of LDTl contains tllat of IDE?.
Sketch of algorithm MAO0
For each Qj in (Ql. Q2, ---, Qn} The application of the transformations described above are not a precondition for the application of the global optimimtion algorithm. It just makes it more efficient, since by applying the group-by early we minim& the size of the intermediate resnlts and thus the storage requirements for the global plan.
4.2. Identification of Aggregate Query Blocks.
An important step in MAQO is to identity aggregate query blocks (AQB). We assume each AQB is chrstered around a pivot relation, whose access (either by table or index scan) will be shared by all queries in the aggregate query block It is possible that multiple relations can be shared, as has been shown in previous work on common sub-expression substitution. For simplicity of our exposition, we focus on the case of single pivot table, although the algorithm can easily be extended to cover multiple relations. We consider for convenience that the pivot table is the leltmost leaf in each of the [extended] leftdeep trees of the queries in the aggregate query block.
1. Identify the common snbtree between GEG and LDTj by ignoring detailed annotations like access methods and join methods. Let CST be the firlly annotated common subtree in GEG and CSTj be the Erlly amrotated snbtree in LDTj. Note that this is a generaIi&ion of the common sub-expression exploitation model @vng factoring, described in [AR94].
2. Calculate the benefit for including Qj in MAQEP Beneft = min( Cost(CSlJ, Cost(CSlj]]
When Qj is included in MAQEP, the common sub-tree needs to be evaluated only once. If CST supersedes CSTj, the benefit would be Cost(csT); otherwise, the benefit is Cost(LDTj).
Given the above assumption, in order to automatically determine the components of an aggregate query block all we need to do is to partition the SQL block by the left-most leaf of the trees, while maintaining the original order of the queries in the SQL block. The partition algorithm is very simple: .
3. Estimatethe temp0mystomgepenaKycawed byaddingQj toMAQEP
Penalty = Pen@(LDTj, j) .
4. IfBenefit is greater than Penalty, THEN merge LDTj to GEG by eliminating the superseded common snbtree
5. Else Add LDTj to GEG as a disconnected tree
Partition (OB)
For each aggregate query AQi in the SQL block QB
1. Find its pivot table by walking depth-fmt the leftdeep tree to its left-most leac let PT be this table.
3. Else, add AQi to the AQBk whose pivot table is PT.
The penalty t%nctio& Penalty(LL)q,n), estimates the penalty incurred to temporarily store the result set produced by a query thou& the end of the AQB execution. The parameter LDT is the leftdeep tree of the query and the parameter n is the number of queries in hJAQEP. A good implementation of Pemdtyo should use distribution statistics maintained by the server at each table and index level in order to estimate the size of the result set of the query. Given today’s server cache sizes (from 16MB for a “small footprint” to gigabytes for parallel machines) it is safe to assume that the results of aggregate queries fit largely in cache. This is also the prefaed strategy for most cost-based optimizers, given the usually high t?equency of access to the aggregate buckets during aggregate calculations.
2. If this is the first query with this pivot table, create a new entry AQBj in the list of aggregate query blocks, and add AQi to AQBj.
The penalty function captures the fact that when occu#ug more space in cache we potentially force another user’s query to go to
267 I
; .7’ .- -::. .
disk. This is due to the fact that, when using MAQEP, the temporary storage must be held through the end if the execution of alI queries in the AQB. &I the worst case, the &%&-set of Qi could force an equal number of pages needed by another query out of cache. In practice, the actual penalty on other users’ queries varies widely with the type of system activity, number of concurrent users, memory size, etc. Named Caches - a recent
feature implemented in Sybase System 1 I- actually reduces the penalty by allowing dedicated cache bufYers to user-specified tables and indices. Given these variations, it would be difEcult tb provide a general function for the tota storage penalty for n queries in an AQB. For our purposes, we want to model two intuitive facts: 1. When ~1, Penalty = 0 (since one query is cached anyway) 2. The longer we occupy the space iu cache, the higher the
chance that space to become needed by another query.
Thus we propose the following formula for the total storage penalty for n queries in MAQEP:
1 n-l n TotPenaBy (n) = - * - * &pages (LDTJ’ ) * APD
2 n
where pages(LDTjl is the mnnber of temporary pages for the result-set of @ and APED is the average page load time from disk to memory. This formula states that about burf of fhe tempormy pages occupied in cache by UaQO will force other users ‘pages to disk.
Therefore, the penalty caused by Qi is PenuI@(LDTj, j) = TotPenal~liJ - TofPena&v&I)
5. Performance Discussion
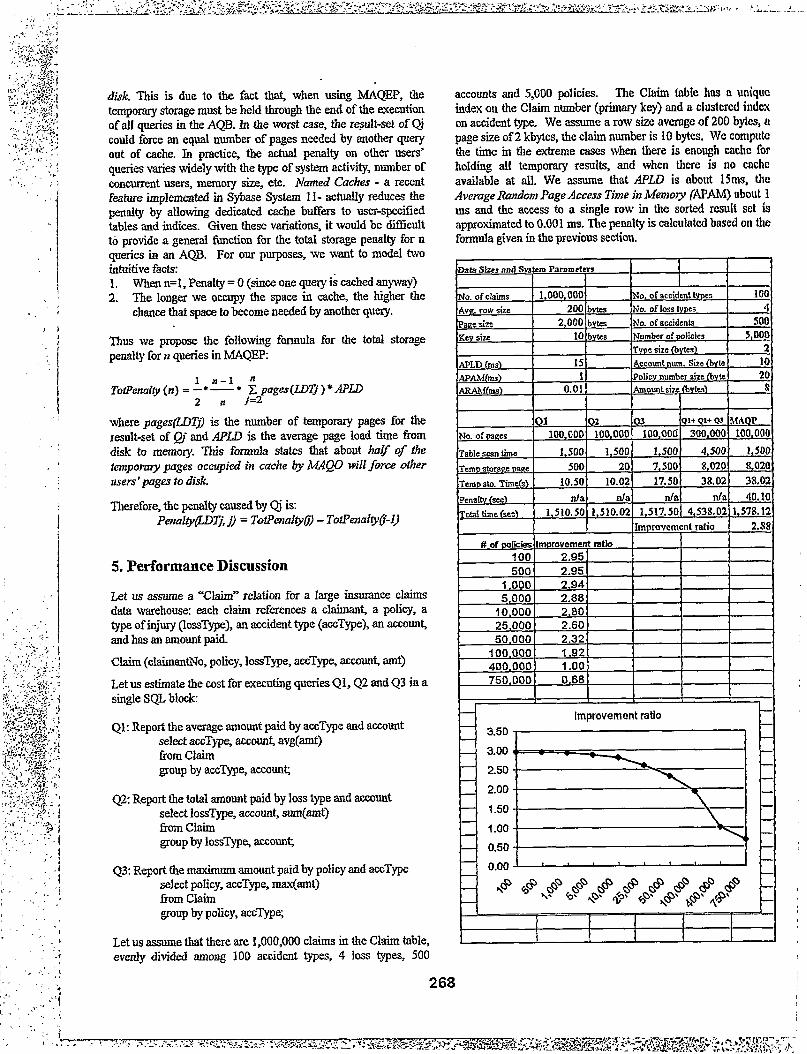
Let us assume a ‘%laiS relation for a large insumnce claims data warehouse: each claim references a claimant, a policy, a type of injury (lossType), an accident type (accType), an account, and has an amount paid.
Claim (&imantNo, policy, lossType, accType, account, amt)
Let us estimate the cost for executing queries Ql, Q2 and Q3 in a single SQL block:
Ql: Report the average amount paid by accType and account select accType, accounf avg(amt) from Claim group by accType, account;
42: Report the total amount paid by Ioss type and account select lossType, account, snm(amt) from Claim group by lossType, account;
Q3: Report the maximum amount paid by policy and accType select policy, accType, max@mt) from Claim group by policy, accType;
Let us assume that there are 1 ,OOO,OOO claims in the Claim table, evenly divided among 100 accident types, 4 loss types, 500
268
accounts and 5,000 policies. The CIaim tnbIe hns a unique index on the Claim number (primary key) and a clustered index on accident type. We assume a row size average of 200 bytes, a page size of 2 kbytes, the claim number is 10 bytes. We compute the time in the extreme cases when there is enough cache for holding all temporary results, and when there is no cache available at all. We assume that APLD is about 15ms, tic Averuge Random Page Access Time in Memov (APAM) about 1 ms and the access to a single row in the sorted result set is approximated to 0.00 1 ms. The penalty is calculated based on the formula given in the previous section.
Improvement ratio
3.5D
3.00 qc ; : ;
2.50 -
2.00 -.
1.50 -
1.00 -
0.50 0.00 I 4

-- --_ >> < -.- -
As CM be seen f?om the above worksheet, the improvement ratio is nearly three-fold for result sets that are reasonably small, compared with the size of the pivot table. That is, aggregations are performed over relatively high cardinality groupings. We expect the great majority of typical decision support queries across various industries to follow this pattern.
When the number of aggregate rows grows dramatically, the penalty of the temporary storage starts to reduce the benefit of the MAQO algorithm. In our case, at 400,000 policies by 100 accident types (a very improbable scenaiio for an ad-hoc query!) the cost of the MAQO algorithm is equal to the cost of the sum of the individual queries (the break-even point). After this point, the MAQO algorithm becomes slower than executing the individual queries independently.
Evidently, the larger the number of participating queries, the greater the improvement ratio. For most usual cases, in general, we will see close to an N-fold improvement for an AQB with N participating queries.
6. Conclusions and Future Work
We introduce an algorithm for grobar uggregure query optinzization in the context of aggregate qtmy blocks. We propose a syntax for defining, as well as an algorithm for automatic identification of aggregate query blocks. We showed that such an optimization takes advantage of the concepts of SQL Batch and Stored Procedure, which are very common in toda.y’s relational database servers. Our algorithm is relatively easy to implement in existing RDBMS products and adds minimum overhesd to the total optimization cost. We proposed an intuitive model for estimating the penalty incurred for storing the result sets through the end of the execution of the aggregate query block. We verified through a theoretical performance analysis that for most aggregate queries the penalty is negligible as compared to the overall cost saving. We showed that MAQO could save in general N-l table/index scans, where N is the number of queries in the aggregate query bIock. That means an N-fold reduction in execution cost for blocks of aggregate queries that are based on the same pivot table or sub-expression.
Our estimates could be further validated on a standard benchmark such as the TPC-D, which provides many group-by queries. It may be interesting to study in greater detail the factors affecting the Penalty function in multi-user enviromnent in order to improve its estimation formula.
Further, it would be interesting to pursue the application of a data mining technique, such as decision tree classifiers, to query optimization. The nature of the decision tree classifiers in data mining is very much linked to the concept of multi-dbnensional aggregate queries. Such classifiers can allow the automatic generation of multiple goal-seeking aggregate queries on various criteria, which would directly benefit Tom the global aggregate query optimization described in this paper.
References
[AR941 J. Alsabbagh, V. Raghavan, “‘Analysis of Common Subexpression Exploitation Models in Multiple-Query Processing”, IEEE Conference on Data Engineering, 1994
pGI96] .G. Bhargava, P. Goel and B. Iyer, “Efficient Processing of Outer Joins and Aggregate Functions”, Proc. IEEE 12th Intl Conference on Data Engineering, Feb. 1996, pp441-449.
[CKPSM] S. Chaudhuri, RKrishnamurthy, S.Potamianos and K. Shim, ‘cOptimizing Queries with Materialized Views”, lEEE 1995.
[CS94] S. Chaudhuri and K. Shim, “Including Group-by in Qnery Optimization”, Proc. of 20th VLDB, 1994, ~~354-366.
p82] S. Finkelstein, “Common expression Analysis in Database Applications”, Proc. of the 1982 ACM-SIGMOD Conference, Orlando (June 1982)
[G+96] Jim Gray et al, “Data Cube: A Relational Aggregation Operator: Genemlizing GroupBy, Cross-Tab, and Sub-Totals”, Proc. IEEE 12th I&l Conference on Data Engineering~ Feb. 1996, pp152-159.
FM961 A. Levy, LS.Mmnick “Reasoning with Aggregate constraints”, IFEE 1996
@)2] M MmaIikrishna, ‘Improved Umresting Algorithms for Join Aggregate SQL Queries”, Proc. of the 18th VLDB Conference, 1992, pg. 91-102.
FCSS] A. Rosenthal, and U.S. Chakravarthy, “Anatomy of a Modular Multiple Query optimizer”, 14th Int. Conf. on VLDB (1988)
[S*79] P.G.Selinger et al , ‘Access Path Selection in a Relational Database Management”, Proc. of the 1986 ACM-SIGMOD Confiice on Management of Data, 1979
[SLSS] T. Sellis, C. Lin , “‘Multiple Qnery optimization”, ACM- TODS 1988
ryL94] Weipend P. Yan and Per-Ake Larson, “‘Performing GroupBy before Join”, Int’l Conference on Data Engineering, 1994 .
[n95] Weipend P. Yan and Per-Ake Larson, ‘Eager Aggregation and Lazy Aggregation”, Proceedings of VLDB, 1995
269