a data-driven framework for archiving and exploring social media data
TRANSCRIPT

A data-driven framework for archiving and exploring social
media data
Qunying Huang University of Wisconsin,Madison Chen Xu University of Wyoming
by Sahithi Thandra
Fall 2015 Regular Paper Presentation 1

• Introduction
• Methodology
• System Architecture • Workflow
• Experiments & Results
• Prototype
• Conclusion
• Future work
• Strengths & Weaknesses
Outline
Introduction
3

• Marketing
• ‘Geo-sensor’ networks
• Detection of Events
4
Usages of Social media data

• Volume: For Twitter, number of tweets per day is nearly 400 million in March 2013 as per Twitter statistics 2014
• Variety: Text, images, videos etc
• Velocity: For Twitter, 9100 tweets are posted every second, according to Statistics Brain 2014
• Veracity: Social media data are assertive and create the trustworthiness question
Challenges in four dimensions

• We address the demands on high performance computing framework for processing social media data in an efficient way.
Our Goal
6

We use three primary strategies in order to query and process the massive data sets efficiently
• Data sets are archived as different collections in the data base.
• Parallel computing is applied to harvest,query and analyze tweets to or from dif ferent collections simultaneously.
• Data are duplicated across multiple servers to support massive concurrent access of the data sets.
Methodology
7
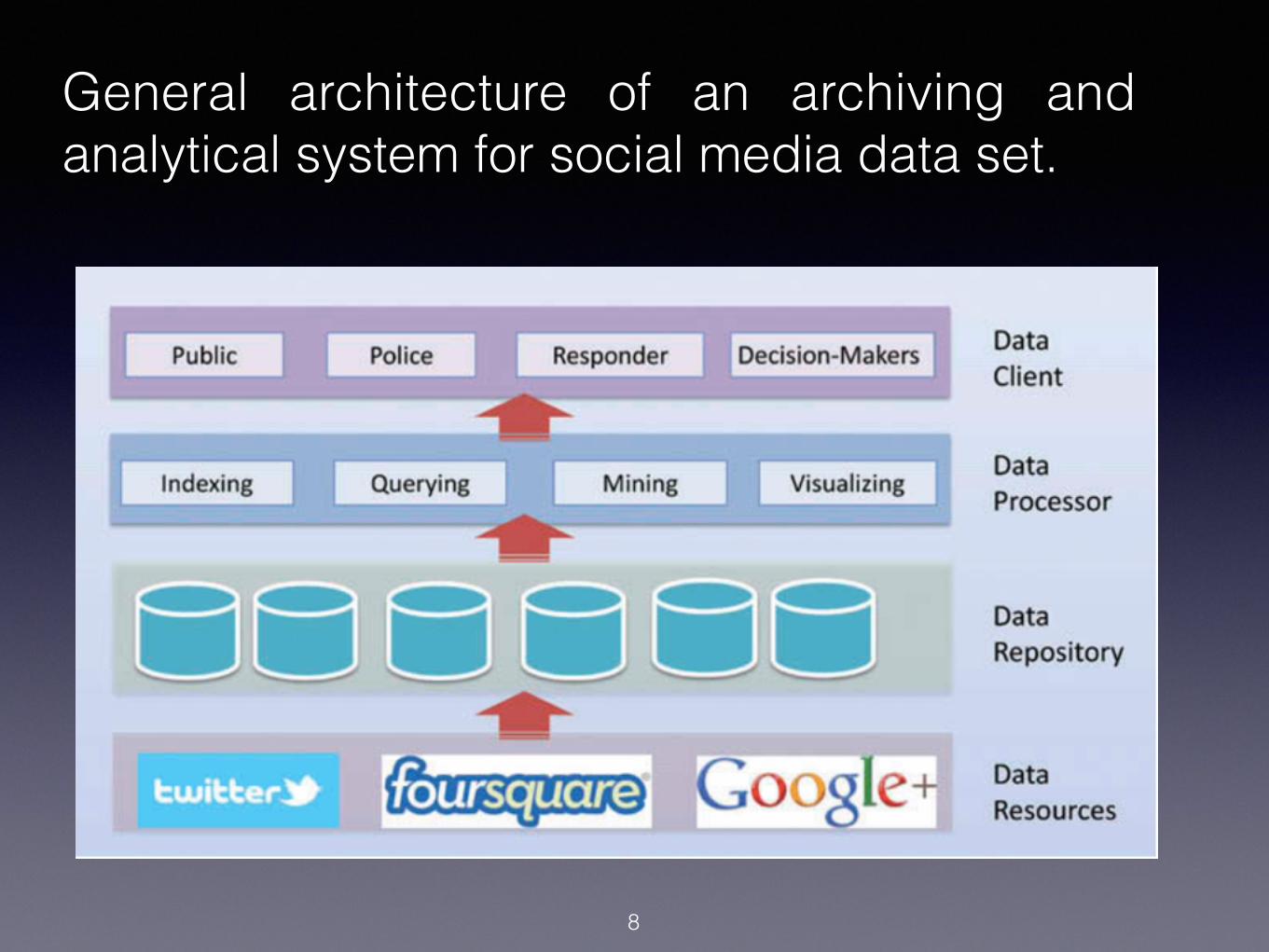
8
General architecture of an archiving and analytical system for social media data set.

Data repository
9

• Social media data sets are unstructured with non-uniform fields, so traditional RDMS is not appropriate.
• MongoDB uses Javascript Object Notation(JSON) documents to store records.
• Traditional relational DBs are not designed to deal with the scale and agility of social media applications
• MongoDB supports utilization of multiple servers to improve performance.
Two Primary Reasons
10

• This layer receives and parses a specific data request.
• Interactions between Data processor and DB are time consuming
• We empower data processor with parallel computing by using it at two levels
• Process level
• Client level
Data processor
11
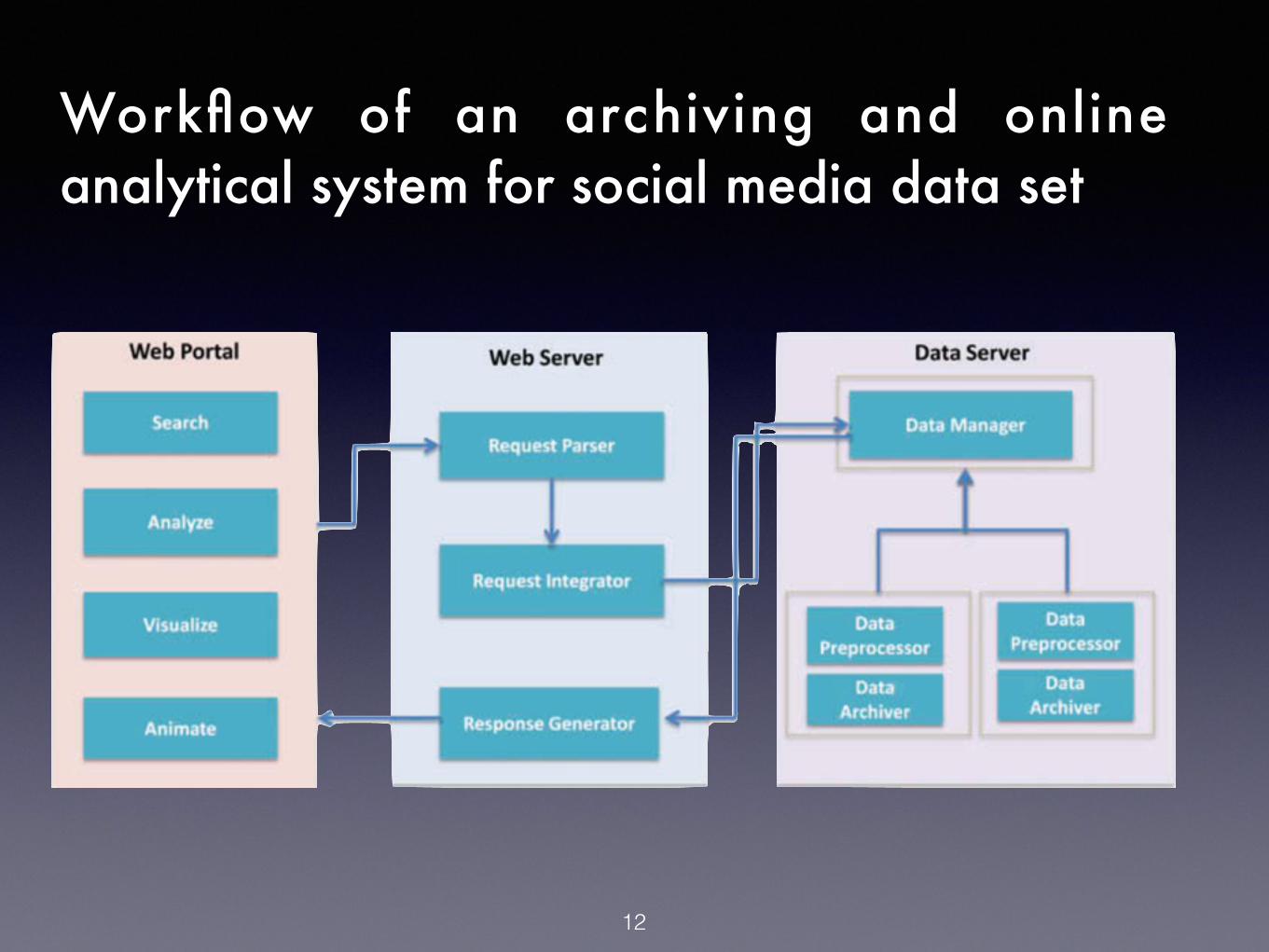
12
Workflow of an archiving and online analytical system for social media data set

• Request Parser : receives the request, extracts parameters, creates a new service task.
• Request Integrator : schedules and dispatches the query tasks to data server, determines the number of processes to be invoked.
• Response Generator : integrates results, performs analytical functions such as Sentiment Analysis.
Modules of web server
13

• Data Archiver : receives and stores the real-time data
• Data Preprocessor : facilitates data querying process
• Data Manager : maintains over all picture of data, disseminates the requests to related data collections
Modules of data server
14

• Performance Analysis
• Spatiotemporal query
• Concurrent query
• Sentiment analysis
• Prototype
Experiments
15

• We’ve taken 3 servers,each having 16GB memory and 3.4GHz dual quad-core CPU
• 2 are data servers
• 1 is web client
• Experiments are performed on 160 million tweets
• We tested 10,20,40,80, and 160 million tweet collection with 1,2 and 4 threads for 1 and 2 data servers.
16
Specifications

Performance of different number of threads for spatiotemporal query of different number of tweets on one and two DB servers
17

18
Performance improvement compared to the serial computing(one thread) with one db server

19
Response performance comparisons by one and two DB servers with different concurrent request numbers

20
Performance of different number of threads for sentiment analysis of different number of tweets on one and two DB servers

• Java, JSP for front end
• Twitter 4j (2014), an official java library for the Twitter API for accessing streaming tweets
• Google Maps API (2014) for mapping the geo-tags tweets
• LingPipe (2014) tool for performing sentimental analysis
Prototype
21
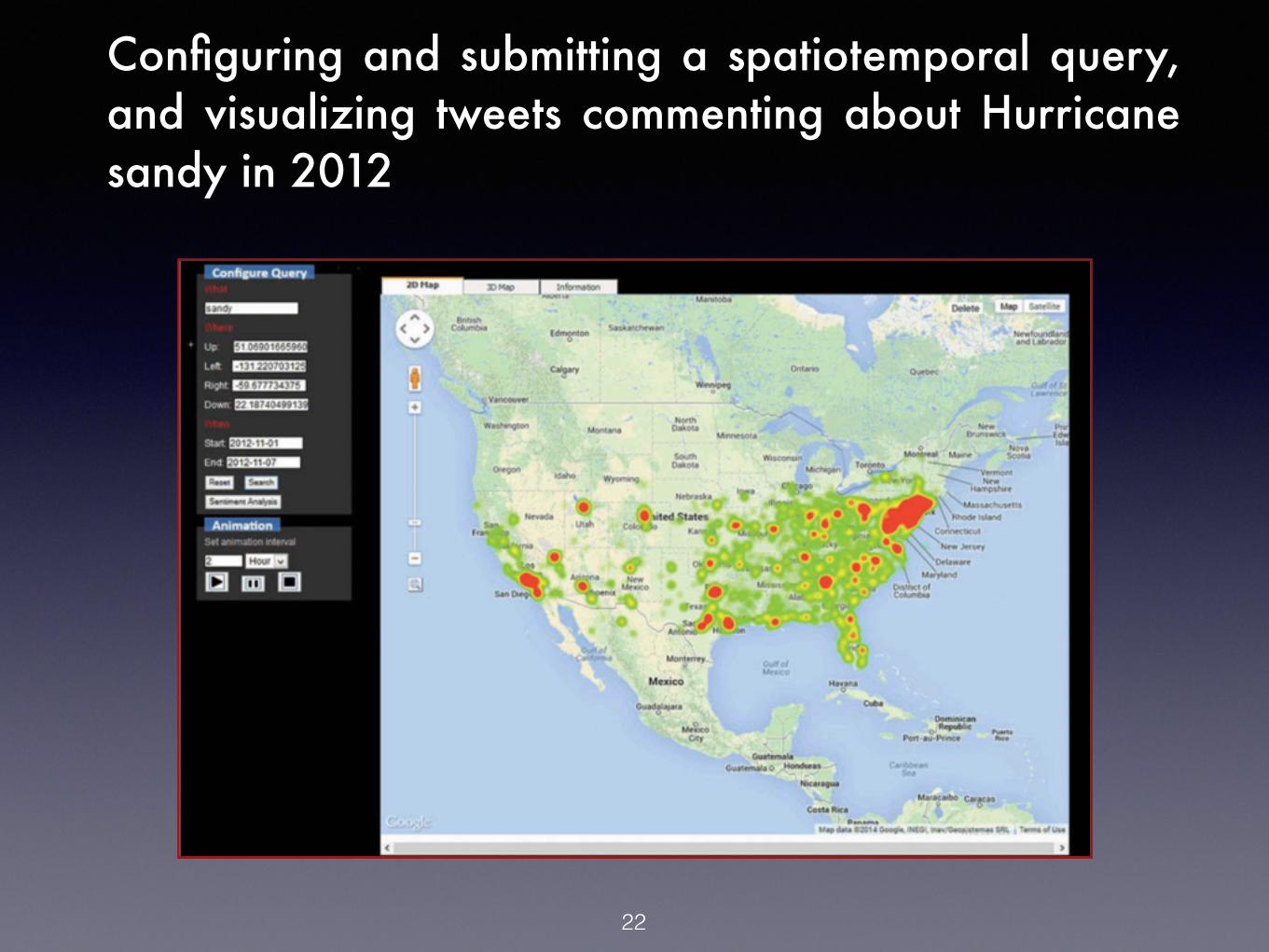
22
Configuring and submitting a spatiotemporal query, and visualizing tweets commenting about Hurricane sandy in 2012

23
Sentiment analysis results: a) negative tweets, b) positive tweets, c) negative and positive tweets overlay

Conclusion
• we proposed and prototyped a data-driven framework to address big data archiving, retrieving and computing challenges for social media data exploration.
• We experimentally studied the performance of parallel computing for querying the DB under various test conditions
• Our preliminary results show that proposed framework can improve the performance of more than 40%
24

1. Michel Kramer, Ivo Senner. 2015. “A modular software architecture for processing Big Geospatial data in the cloud” (Regular paper 3)
2. Sui, D., and M. F. Goodchild. 2011. “The Convergence of GIS and Social Media: Challenges for GIScience.” International Journal of Geographical Information Science 25 (11): 1737–1748.
3. Goodchild, M. F. 2007. “Citizens as Sensors: The World of Volunteered Geography.” GeoJournal 69 (4): 211–221.
Related work
25

• Cloud computing is a promising computing infrastructure to accelerate geoscience research.
• We can leverage cloud storage for data archiving.
Future work
26

Strengths
1.Implementation
2. Easy to under- stand
3.Results are positive
27
Weaknesses
1.Effective dataset is not too large
2.Only one type of data is used

Thank you for your attention!
28