3장 데이터 수집, 정제에서 분석까지
TRANSCRIPT

데이터 수집 , 정제에서 분석까지3 조 20912327 김승훈 21110561 윤아영 21110581 현지연 21210639 김지은 21321865 이유정

기본개념 • 데이터 마인드란 ?
• 구분자 이해하기• 데이터 및 자료 수집• 데이터 수집 방법
3.1~3.4

이해 데이터 마인드란 ?
뉴스와 데이터를 연결 지어 생각해 보고 , 취재와 제작에 데이터의 정량 분석과 시각화의 힘을 적극적이고 효과적으로 활용하려는 자세
데이터 마인드가 갖춰진 기자
• 유용한 데이터가 어디엔가 존재할 것이라는 전제하에 일을 시작 • 정부의 공공기관의 정책 정보와 마찬가지로 공공 데이터 역시 국민의 알 권리
차원에서 당당하게 요구하고 활용할 권리가 있다는 점을 분명히 인지하고 있어야 한다 .• 취재처에 무슨 데이터가 존재하고 어떻게 구할 수 있는지 파악하는 한편
자신만의 취재 데이터베이스를 구축해 부가가치를 높이려고 한다 .• 보조적 수단의 통계자료 차원이 아닌 데이터를 기반한 기사를 쓴다 .

이해 데이터 마인드란 ?
『자료 입수의 기술 (The Art of Access 』( 미국의 정보공개 전문가인 미주리 대학교의 찰스 데이비드 교수 , 아리조나 대학교의 데이비드 컬리어 교수 )
탐사 보도 전문 기자들의 문서 추적 기법 ( 문서 마인드 ) 의 데이터 취재에 접목해도 효과를 배가 할 수 있다 ,
자료 추적 하기 전 취재하는 기관의 성격 , 업무에 관해 자문자답 ! 1. 무슨 일을 하는 기관인가 ?2. 어느 사업에 어떤 예산을 지출하나 ?3. 이 기관이 감독하고 규제하는 영역은 ?4. 누가 자료를 생산하나 ?5. 기관에서 정기적으로 발표하는 통계자료는 ?6. 이 기관에서 문서를 공유하는 다른 기관은 어디인가 ?

이해 데이터 마인드란 ?
탐사 보도 전문 기자 돈 레이의 문서 체크리스트 !
1. 부모님은 누구인가 ? ( 누가 만든 자료인가 ?)2. 언재 태어났나 ? ( 언제 만들어졌고 자료 갱신 주가는 ?)3. 사용하는 언어는 ? ( 데이터에 쓰인 용어의 의미는 >)4. 결혼 했나 ? 형제는 없나 ? ( 연계된 다른 데이터는 없는가 ?)5. 어떻게 여기에 오게 됐나 ? ( 자료 생성의 흐름은 ?)6. 숨기고 있는 건 없는가 ? ( 자료 한 켠에 숨겨진 작은 글씨나 코드는 없나 ?
그 의미는 ?)
『자료 입수의 기술 (The Art of Access 』( 미국의 정보공개 전문가인 ( 저널리즘 ) 미주리 대학교 -한국언론재단 연수의 찰스 데이비드 교수 , 아리조나 대학교의 데이비드 컬리어 교수 )
탐사 보도 전문 기자들의 문서 추적 기법의 데이터 취재에 접목해도 효과를 배가 할 수 있다 ,

이해 데이터 마인드란 ?
문서는 만든 사람의 의도성에 따라 그 성격이 달라진다 .
1. 누가 무슨 목적으로 작성한 것인지를 파악2. 언제 만들어졌고 , 어느 정도 주기로 갱신되는 자료인지도 정확히 숙지3. 데이터베이스의 각 항목이 뜻하는 의미는 무엇인지도 정확히 숙지
이와 같은 ‘데이터에 관한 데이터’을 메타데이터라고 한다 .∴ 데이터 마인드는 분석도구에 익숙할수록 더 깊어진다 .

이해 데이터 파일 형식의 기본 : 구분자 (delimiter) 이해하기
가장 널리 사용되는 엑셀오피스 2007 년 버전 이후에서 사용하는 .xlxs( 엑셀 통합문서 )2003 년 이전 구 버전에서 사용하던 .xls 가 있다 .
엑셀의 대용인 무료 ‘ Open Office Calc’.ods 확장자의 ODF 파일을 생성한다 .
CSV 다음으로 많이 사용되는 파일은 탭 (tab)(TAB-Delimited Text File) 이다 .

이해 데이터 파일 형식의 기본 : 구분자 (delimiter) 이해하기
스프레드 시트 만큼 사용되는 CSV(Comma-Separated Value)글자와 숫자 단락마다 쉼표 (Comma) 가 들어가 있다 .CSV 에서는 쉼표가 데이터와 데이터를 구분한다 .이와 같은 쉼표의 역할을 구분자 혹은 분리자 (Delimiter, Separator) 라고 한다 .

이해 데이터 파일 형식의 기본 : 구분자 (delimiter) 이해하기
CSV 파일 불러오기• 엑셀의 ‘열기’ 메뉴에서 쉽게 불러올 수 있는 경우• 상단 메뉴의 ‘데이터’→’텍스트’ 메뉴를 통해야 한다 .

이해 데이터 및 자료 수집
1. 기획2. 데이터 수집3. 데이터 정리 및 정제 ( 가장 많은 시간과 노력이 필요한 부분 ) →
올바른 분석과 시각화를 위해서는 반드시 거쳐야 하는 작업4. 데이터 분석과 시각화5. 현장 취재 병행6. 방송 , 신문 혹은 웹 콘텐츠 제작
( 순서는 고정 불변한 것은 아님 . 상황에 맞춰 작업 순서가 바뀌거나 여러 가지 작업이 동시에 진행되기도 한다 .)
아무리 비싼 도구와 좋은 소재로 분석한다고 하더라도 , 부정확한 데이터로 작업을 하면 아무 소용이 없다 . 오류를 안고 있는 데이터를 투입하면 , 오류 투성이의 결과를 낳을 수 밖에 없다 .

이해 데이터 수집의 6 가지 방법
1. 현장 취재 데이터 직접 입수2. 인터넷상에서 검색으로 자료 취득3. 정보공개 청구4. 공개 API 활용 별 4 개짜리5. 웹스크레이핑 (Web Scraping, Web Crawlng)6. 데이터베이스 자체 구축
< 극히 예외적인 한 가지 사례>웹스크레핑 사례 “미국 언론인이 웹스크레이핑으로 인해서 법정 논란”미국의 ‘스크립스 하워드 뉴스 (Scripps Howaed News Service)’ 의 취제 기자 아이작 울프 (Issac Wolf) http://www.niemanlab.org/tag/isaac-wolf/
법적 윤리적으로 갈등의 소지가 없는지는 좀 더 사회적 논의와 합의가 필요한 부분이지만 , 우리나라의 데이터 분석가와 기업 , 연구기관들도 이미 웹스크레이핑을 폭넓게 활용하고 있다 . 대부분의 웹스크레이핑은 특정 사이트의 공식적인 허락을 받지 않고 , 통상적인 방법과는 다른 경로로 데이터를 수집하게 된다 . 이 때문에 원칙적으로는 해당 기관에 데이터 파일 제공을 직접 요청하는 등 가능한 모든 수집방법을 시도해 본 다음 마지막 대안으로 사용 or 미리 해당 기관에 통지하는 것이 바람직하다 .

이해 데이터 수집의 6 가지 방법
또 하나의 방법 , 구글 고급검색
“F-35A”범위를 좁혀줌 filetype:pdf 피디에프파일만 site:gov 정부기관 사이트
인터넷상에는 검색엔진의 레이더망에는 포착되지 않는 숨겨진 고급 정보도 무수히 많다 . “ 보이지 않는 웹 (Invisible Web)” 이 그것이다 .
프리즘 : 국내 각종 정부 용역 보고서제인스 연감 : 해외 사이트에서 무기에 대한 상세한 정보Lexisnexis : 기업 간의 소송에 대한 정보 , 법률정보* 유료와 무료가 섞여 있으니 선별해서 사용 !
언론진흥재단 등 탐사 보도 혹은 데이터 저널리즘 교육 프로그램의 강좌를 통해 검색 노하우와 관련된 정보를 얻을 수 도 있다 .

야후파이프 • 활용하기3.5

이해 야후 파이프 이용하기
야후파이브 작업창

이해 야후 파이프 이용하기
야후 파이프 모듈 구성화면
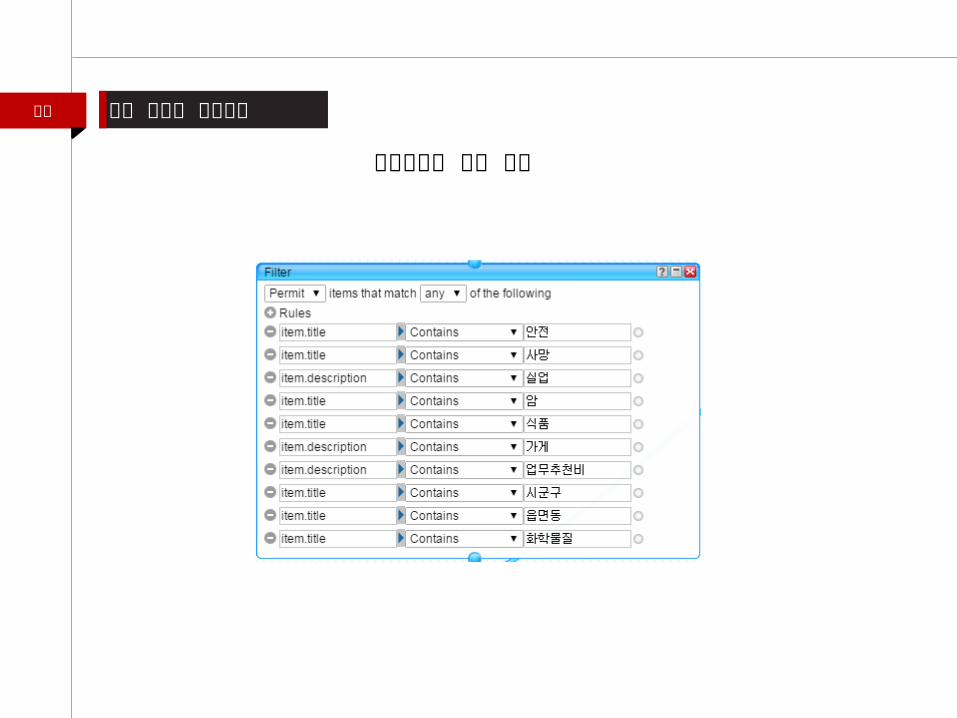
이해 야후 파이프 이용하기
야후파이프 필터 모튤

이해 야후 파이프 이용하기
RSS 피드 필터링정렬용 야후 파이프 모듈 구성

이해 야후 파이프 이용하기
모듈 실행 결과 RSS 피드 불러온 모습

refine• 데이터 오류 바로잡기• 빈 셀 (blank) 골라내기• 일관성 없는 표기 바로잡기• GREL 과 정규표현식 활용하기
3.7~3.10

1. 홈페이지 (openrefine.org) 접속
2. 다운로드
3. Window kit 다운로드
4. ( 자바 프로그램이 깔려 있지 않으면 자바 프로그램 다운 )
Refine 오픈 리파인 실행법

5. ( 다운로드 후 ) 알집 풀기
6. 다이아 모양 google-refine 클릭
오픈 리파인 실행법Refine

7. 파일 선택 클릭
8. 제 3 장 中
“ 서울시도로시설물” 클릭
Refine 오픈 리파인 실행법

9. NEXT 클릭 .
10. Project name 설정 후 Create project 클릭
Refine 오픈 리파인 실행법

Refine 오픈 리파인 메인 화면 : Record -> rows 바꾸기

시설물명 -> Facet -> Text facet 클릭Refine 빈 셀 (blank) 골라내기
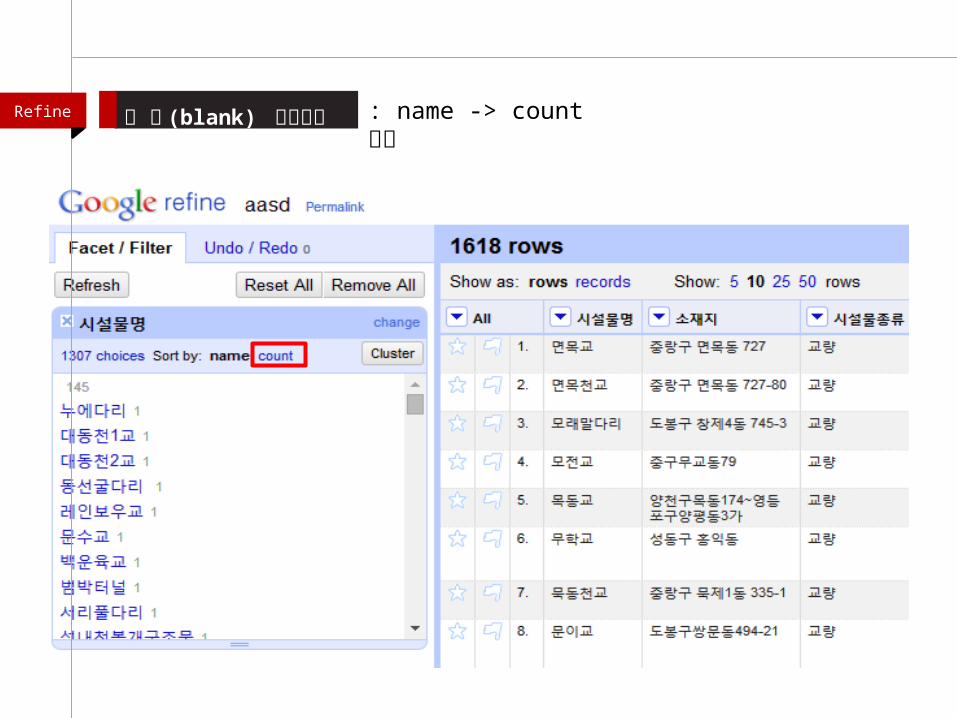
Refine 빈 셀 (blank) 골라내기 : name -> count 클릭

: blank 위에 마우스 올리면 “ edit” , “include” 뜸Refine 빈 셀 (blank) 골라내기

: (좌 ) “include” 클릭
: ( 우 ) “edit” 클릭 후 -> “이름없는 시설물” 작성 후 -> apply 클릭
Refine 빈 셀 (blank) 골라내기

: (좌 ) exclude 클릭
: ( 우 ) 무명교 -> “edit” -> 이름없는 시설물로 변경
Refine 빈 셀 (blank) 골라내기

: 이름없는 시설물 없애는 법 이름없는 시설물 -> edit -> (띄워쓰기 한번 )
Refine 빈 셀 (blank) 골라내기

: 이름없는 시설물 없애는 법Refine 빈 셀 (blank) 골라내기
(좌 ) 빈칸 우측의 “ include” 클릭 ( 우 ) 시설물명 -> edit cells -> common transforms -> blank out cells

: (좌 ) 소유자 -> facet -> text facel
: ( 우 ) 같은 곳이지만 (“강북구청”=“강북구청장” ) 다른 표기 발견
Refine 일관성 없는 표기 바로잡기

: (좌 ) 강북구청에 마우스 커서 올린 뒤 -> edit 클릭
: ( 우 ) 강북구청 -> 강북구청장으로 변경 (apply)
Refine 일관성 없는 표기 바로잡기

: 준공일 ( 일반 데이터의 유형은 TEXT, 준공일의 유형은 시간 (DATA))
: 우선 준공일 -> Edit cells -> common transforms -> to date 선택
Refine 일관성 없는 표기 바로잡기

: (좌 ) 준공일 -> Facet -> Timeline facet
: ( 우 ) (좌 ) 의 결과
Refine 일관성 없는 표기 바로잡기

: (좌 ) 1900 년대 지어진 건물들이 많음 ( 이상함 ) : ( 우 ) 그 이유를 알아보기 위해 범위를 줄임
Refine 일관성 없는 표기 바로잡기

: 477 개나 되는 건물이 1900 년대 지어짐 ? -> 그 원인은 그 시대에 지어진 것이 아니라 준공 시점을 모르기 때문
Refine 일관성 없는 표기 바로잡기
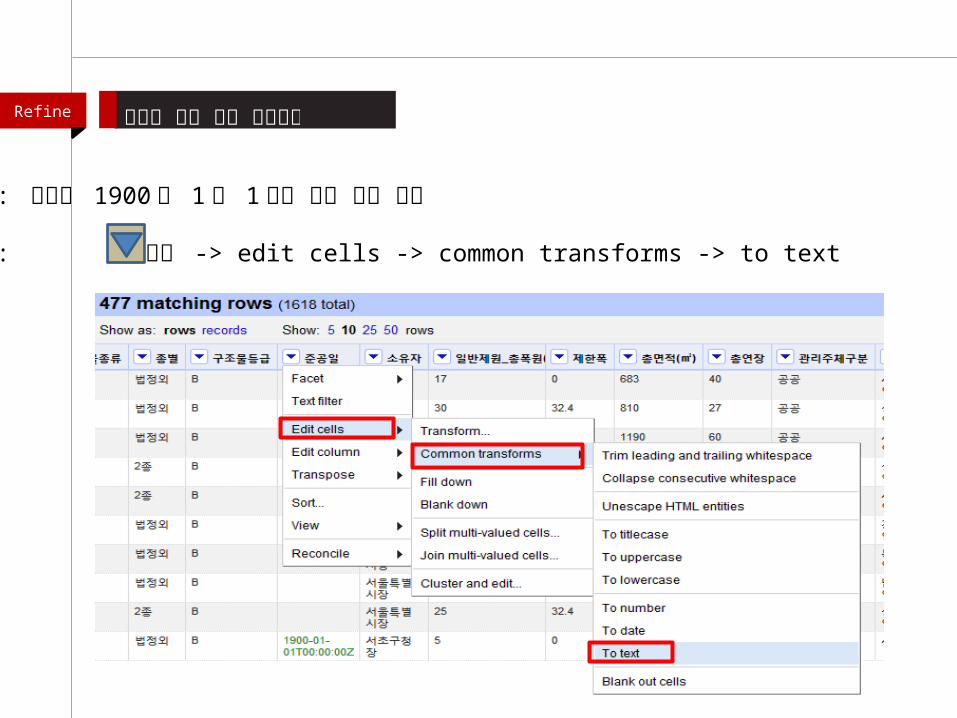
: 문제의 1900 년 1월 1 일의 표기 문제 해결
: 준공일 -> edit cells -> common transforms -> to text
Refine 일관성 없는 표기 바로잡기

: 문제의 1900 년 1월 1 일의 표기 문제 해결
: (좌 ) 준공일 -> facet-> text facet
: ( 우 ) 그 결과 , 1990 년 1월 1 일 준공된 시설물 (408 개 ) + 빈 셀 (69 개 )
Refine 일관성 없는 표기 바로잡기

: 문제의 1900 년 1월 1 일의 표기 문제 해결
: 1990 년 1월 1 일 준공된 시설물 (408 개 ) + 빈 셀 (69 개 ) -> edit -> “ 준공일 미확인” 으로 적용
Refine 일관성 없는 표기 바로잡기

: 준공일 미확인 (477 개 ) 이 정해지면 , 준공일 -> edit cells -> common transforms -> to number 선택
Refine 일관성 없는 표기 바로잡기
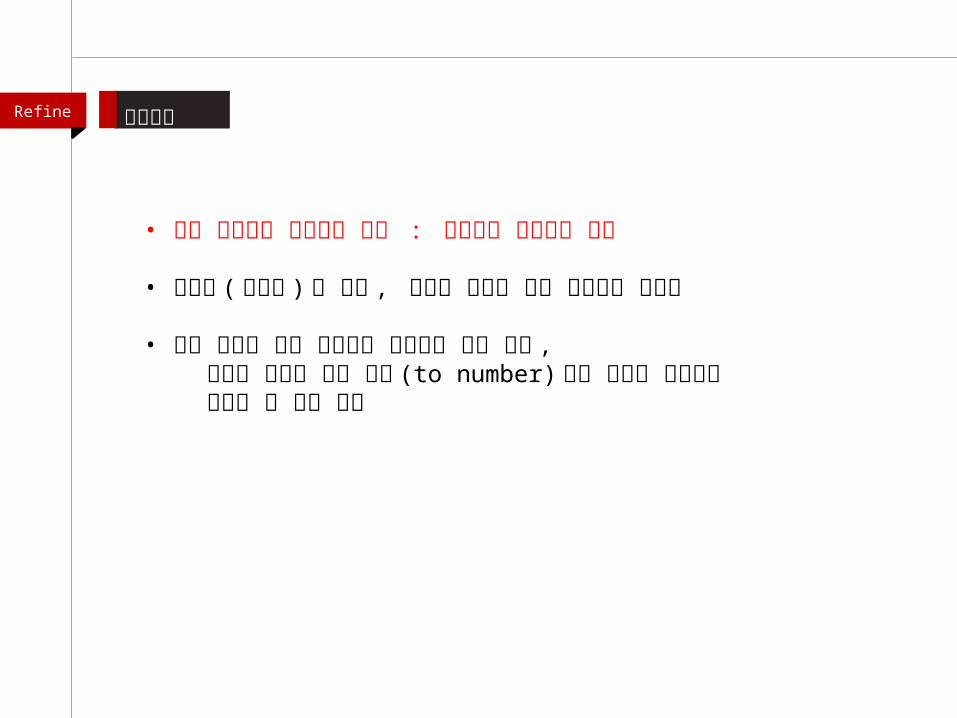
• 오픈 리파인을 사용하는 이유 : 데이터를 정제하기 위해
• 파란색 (검은색 ) 은 문자 , 녹색은 숫자나 시간 데이터를 나타냄
• 셀의 왼쪽에 붙어 표시되는 데이터는 문자 형태 , 수치는 반드시 숫자 유형 (to number) 으로 형식을 바꿔줘야 제대로 된 계산 가능
Refine 참고사항

정규표현식은 문자열의 배열에서 일정한 패턴을 찾아내
데이터 처리를 쉽게 만드는 수단
Refine GREL 과 정규표현식 활용하기

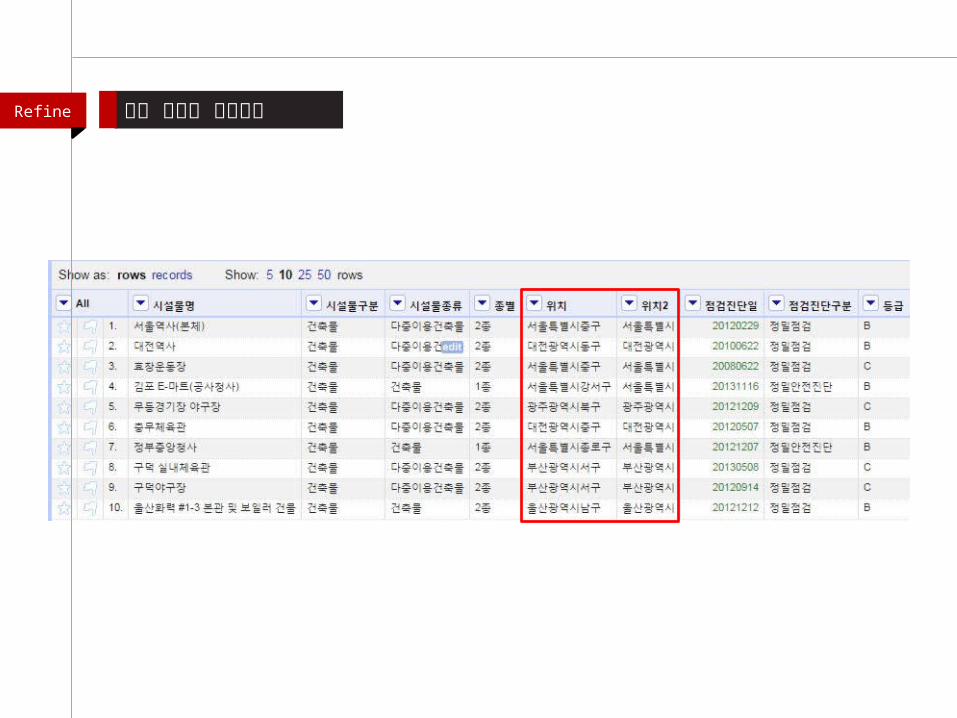
Refine 문자열 사이의 공백을 기준으로 ‘위치’ 칼럼을 두개의 칼럼으로 분리하기

“시” , “ 구”가 분리되어 있지 않음
Refine 문자열 사이의 공백을 기준으로 ‘위치’ 칼럼을 두개의 칼럼으로 분리하기

value.replace("특별시 ","특별시 ").replace("광역시 ","광역시
").replace(" 도 "," 도 ").replace(" 영도 구 "," 영도구 ")
Refine 문자열 사이의 공백을 기준으로 ‘위치’ 칼럼을 두개의 칼럼으로 분리하기

“시” ,” 구”가 분리되었음
Refine 문자열 사이의 공백을 기준으로 ‘위치’ 칼럼을 두개의 칼럼으로 분리하기

Refine 특정 문자만 추출하기

value.replace("특별시 ","특별시 ").replace("광역시 ","광역시
").replace(" 도 "," 도 ").replace(" 영도 구 ","영도구 ").split(" ")[0]
컴퓨터 언어는 순서를 셀 때 1 부터 세는 것이 아니라 0 부터 센다 .
나는 학생입니다나는 =0
Refine 특정 문자만 추출하기

value.partiton(/^.{4} 시 |^.{2,} 도 /)[1]을 입력했을때도 똑같이
첫번째 문자열인 ‘시’를 기준으로 나눠진다 .
Refine 특정 문자만 추출하기

• / : 정규표현식의 시작을 알리는 기호• ^: 첫 번째 나오는 문자열 서울특별시• . : 아무 글자나 한 글자• {4}: 앞 문자열이 4번 나타날 때 서울특별• | : 영어의 OR 와 같은 이른바 blooean 연산자• ^ : 첫 번째 나오는 문자• {2,}: 앞 문자열이 2번 이상 나타날 때 충청북도• / : 정규표현식 마무리를 알리는 기호
Refine 특정 문자만 추출하기

Refine 특정 문자만 추출하기

value.replace("특별시 ","특별시 ").replace("광역시 ","광역시
").replace(" 도 "," 도 ").replace(" 영도 구 ","영도구 ").split(" ")[0]
Refine 특정 문자만 추출하기
Refine 특정 문자만 추출하기

value.replace(/\d+-\d+/,"")
Refine 특정 문자만 추출하기

• / : 정규 표현의 시작• \d : 숫자 (digit) 한 개 혹은 여러 개• - : 1-010 처럼 숫자 사이에 위치한 – 기호• \d+ : 숫자가 한 개 혹은 여러 개• / : 정규표현식 마무리
Refine 특정 문자만 추출하기

Refine 특정 문자만 추출하기

value.split("|")[0]+"."+value.split("|")[1]+value.split("|")[2]
Refine 특정 문자만 추출하기

Split :괄호안의 문자를 “ .” 로 처리 하라는 의미
value.split("|")[0]+"."+value.split("|")[1]+value.split("|")[2]
Refine 특정 문자만 추출하기

cells[" 위도 "].value+" "+cells[" 경도 "].value
Refine 칼럼과 칼럼을 합치는 기능

엑셀• 스프레드시트• 피벗테이블• 필수 엑셀기능 & 고급함수• SQL 쿼리
3.11~3.15

엑셀
스프레드 시트
Ctrl + end : 커서 위치를 데이터값이 입력된 영역의 오른편 아래쪽 끝단으로 이동한다 .
Ctrl + shift + end : 특정 셀을 기준으로 오른쪽 아래 방향으로 데이터 값이 입력된 영역의 끝단까지를 모두 선택한다 .
Ctrl + 화살표키 : 데이터 값이 입력된 영역의 끝단으로 커서를 옮긴다 .
Ctrl + shift + 화살표 키 : 데이터 값이 입력된 영역의 끝단으로 선택 범위를 확대 .

엑셀
스프레드 시트
연간 상승률 : ( 올해 연봉 – 지난해 연봉 )/ 지난해 연봉 *100반올림 함수 round 수식 앞에 추가= round( 숫자값 , 표시할 소수점 이하 자릿수 )=round(( 셀 - 셀 2))/ 셀 2*100,0)
SUM : 합산AVERAGE : 평균MAX, MIN : 최대 , 최소치총합이 1372368107 으로 계산됬을때 , 3 자리 단위로 쉼표 표시 : 전체범위 지정 – 표시형식 – 우하단 X
특정 공기관의 부채를 전체 공기관 부채 총합으로 나누기 위해분모를 고정하려면 $붙여야 한다 . – 절대참조를 하지 않고 셀 자동 채움을 할 경우 분모 값에서 연속으로 오류 발생 .

엑셀
스프레드 시트
필터링 : 내가 원하는 조건의 데이터만 뽑아내는 것 일정 조건에 해당하는 데이터만 걸러낼 수 있다 .
원하는 셀 선택 후 데이터 – 필터로 가서 화살표 표시 클릭 – 걸러낼 셀 클릭 – ‘모두 선택’ – 걸러낼 셀 체크해서 필터링 .
칼럼 여러 개를 선택하면 복수 필터 동시 사용 가능
입력된 칼럼 - =,>,< 와 같은 등호와 부등호를 사용해 일정 값을 기준으로 초과 , 미만 , 이상 , 이하의 데이터만 추출 가능 .

엑셀
피벗테이블
피벗 테이블 – 특정 범주 데이터를 기준으로 다른 수치 데이터를 합산하고 평균을 내거나 비율을 계산하고 정렬해 일목요연한 표로 정리한 것 .
차트상 아무 셀이나 한 곳 클릭 – 상단메뉴의 삽입 – 핍업테이블 – 확인 – 오른편에는 피벗 테이블 필드 , 왼편에는 표 만들어짐 – drag and darg 방식 사용 – 원하는 데이터 칼럼의 네모난 빈 상자를 클릭하거나 칼럼 명을 클릭한 뒤 원하는 곳으로 끌어다놈 – 평균값으로 변환하기 위해 셀을 아무 곳이나 클릭한 뒤 마우스 우 클릭 – 값요약 기준 – 평균으로 조정 – 총합계는 제거한 뒤 마우스 우클릭해 필드 표시형식 메뉴에서 연봉 평균값을 소수점 1 자리로 표시 .

엑셀
피벗테이블
몇 개씩 분포했는지 개수세기‘ 행’에 범주 데이터를 옮기고 ‘값’에도 동일한 범주 데이터를 넣으면 , 각 항목별로 개수 세어준다 .
퍼센트 비율로 나타내기 – 개수 칼럼에서 마우스 우클릭 뒤 값 요약 기준 – 기타 옵션 – 값 표시형식 – 설정
피벗테이블 셀 위에서 마우스 우클릭해 정렬 메뉴를 선택하면 내림차순 혹은 올림차순으로 정렬 가능
피벗테이블은 데이터의 분포를 요약하는데 탁월한 기능

엑셀
필수 엑셀기능 & 고급함수
텍스트 분리 기능 : 메뉴 데이터 – 텍스트 분리바꾸기 기능 : 홈 – 찾기 및 선택 – 바꾸기Ex) ‘ 서울시 강북구 번동’ 셀이 있을 경우 ‘시’를 ‘특별시’로 변동 가능Concatenate( 문자열 , 문자열 , …, 문자열 ) 문자가 입력된 셀 합쳐주는 함수Ex) A2 셀에 서울시 , B2 셀에 강북구라고 입력돼 있을 때 , =con-catenate(A2,””,B2) 은 ‘서울시 강북구’라는 셀을 발생
Concatenate함수와 같이 함수명이 긴 경우 con 만 입력해도 con으로 시작하는 여러 함수가 뜨기 때문에 선택 가능 , & 로 문자열을 연결시켜도 concatenate 와 동일한 효과 낼 수 있다 . 가령 =A2&””&B2 라고 입력해도 =concatenate(A2,””,B2) 과 같은 결과를 낸다 .

엑셀
필수 엑셀기능 & 고급함수
Datevalue – 시간 데이터를 숫자로 변환Today - 오늘의 연월일 날짜를 산출하는 함수Leet(A2,5) 는 셀 A2 의 문자열에서 왼쪽에서 다섯글자를 추출Mid(A2,7,3) 은 A2 의 왼편에서 7번째 자리부터 시작해 세 글자를 뺌Right(A2.3) A2 의 오른쪽에서 세 글자를 추출If( 조건문 , 결과값이 참인경우 , 결과값이 거짓인 경우 )Ex) if(A2>70, “ 합격” , “ 불합격” )

엑셀
SQL 쿼리
쿼리 – sol 을 사용해 원본데이터를 검색 , 추가 , 수정 , 삭제하는 질의문으로 dbms 를 사용하여 데이터베이스를 조작하는 것
이미 구축되어 있는 테이블로부터 데이터베이스를 분석하여 필요한 정보를 찾는 도구
폼이나 보고서의 원본데이터가 됨

엑셀
SQL 쿼리
Secect - 필요한 칼럼 선택해 불러옴Where - 조건에 맞는 행을 불러옴Group by – 특정 칼럼을 기준으로 다른 칼럼 데이터를 집게해 보여준다 . 피벗 테이블의 ‘행’에 끌어 넣어주는 칼럼명이 바로 이기준 칼럼Pivot – 피벗 테이블의 ‘열’ 만듬Order by – 올림차순 혹은 내림차순으로 정렬Limit – 표시할 행수 설정Label – 표시할 칼럼 이름 새로 지정

마무리 • 통계 기본 상식• 데이터 저널리즘에 대해3.16~3.17

마무리 통계에 관한 몇 가지 기본 상식
통계학• 기술 통계 : 자료의 특징을 간단히 설명 하는 통계• 추리 통계 : 표본집단을 설정해 가설을 만든 후 , 참과 거짓을 결정

마무리 통계에 관한 몇 가지 기본 상식
평균 = 자료 분포의 특성을 보여주는 대푯값
산술평균 : 전체 값을 모두 더한 뒤 , 개수로 나눈 값 (outlier 발생 가능 )
중앙값 : 표본 수치를 나열 했을 때 중앙값(홀수면 정중앙 수치 , 짝수면 중앙의 나란히 위치한 두 수의 평균값 )
최빈값 : 표본 수치 중 가장 많이 등장하는 값
일반적으로는 산술평균을 사용하지만 분포가 쏠릴 경우 , 중앙값 사용

마무리 통계에 관한 몇 가지 기본 상식
우리가 주목해야 하는 것 , 데이터 간의 차이
범위 : 최댓값과 최솟값을 구한 차이편차 : 각 데이터와 평균의 차이 ( 편차를 모두 더하면 0)
분산 : 각 편자의 제곱의 평균표준편차 : 수치와 중심값과 거리를 가늠할 수 있는 수치
이러한 수치를 통해 정규 분포를 만들어 시각적으로 데이터를 볼 수 있다 .

마무리 데이터에 대한 과신을 버려야 데이터 저널리즘이 산다 .
데이터에 근처한 취재는 “객관적이고 입체적인 보도"가 목적이다 .따라서 , 데이터 저널리즘은 데이터의 객관성과 정확성이 중요하다 .
숫자는 의견이고 , 요약이고 , 추정치에 불과하다 .
뉴욕타임즈 컴퓨터 활용보도 (CAR) 에디터사라코헨
수치 자료에서 가치와 효용성을 끌어내는 것은 전적으로데이터를 적극 사용하는 사람의 몫인 것이다 .

감사합니다 .