26. cloud-scale computing abstractions
TRANSCRIPT

26. Cloud-scale computing abstractions

1
Computer Science
Azer Bestavros
Computer Science DepartmentBoston University
Introduction to Distributed SystemsIntroduction to Distributed Systems
© Copyright Azer Bestavros / All rights reserved.
Computer Science
Distributed Systems
Typical characteristics: Entities in a Distributed System are “Autonomous” No Inherent Synchronization (e.g. global clock) No Shared Resources (e.g. memory) Heterogeneous Platforms (e.g. Unix, Windows, etc.) Communication via MessagesWires have state (e.g. packets in transit) Unreliability is Inherent “Byzantine” Failures are possible …
Computer Science
Distributed Systems
Client-Server Systems Distributed File systems (e.g., NFS, AFS, etc.)Web Applications (e.g. HTTP server/browser, etc.)
Peer-Peer Systems Distributed Apps (e.g., DDBMS, DHT, Caching, etc.) Internet Infrastructure (e.g. routing, DNS, etc.)
Computer Science
Distributed SystemsDistributed Systems
To be able to get anything useful, we need to rely on some basic abstractions Communication is reliable; no messages are lost Message delivery delays can be arbitrary, but not infinite Messages are delivered in order
And often, we need to build/rely on some key capabilities (typically related to synchronization) Nodes in a distributed system can elect a leader Nodes in a distributed system can agree on event ordering Nodes in a distributed system can agree on time
Computer Science
Abstractions vs ExpressivenessAbstractions vs Expressiveness
How much should we expose to programmers? The more we expose, the more efficient we could be The less we expose, the more programmers we serve
We need a “spectrum” of paradigms Distributed Systems for Dummies Distributed Systems for CS-552
Computer Science
Distributed Computing ParadigmsDistributed Computing Paradigms
Remote Procedure Calls (RPC)Most natural progression – from threads on a single
CPU to threads on multiple CPUs Allow function calls to cross the boundaries of a single
host, with possibility of no shared memory…Must deal with all the synchronization and
management overhead

2
Computer Science
Distributed Computing ParadigmsDistributed Computing Paradigms
Client-Server ComputingApplication specific paradigm (e.g., HTTP, SMTP, …)Blurred client and server roles gave rise to the P2P
paradigm (e.g., Gnutella, Bittorrent, …)
Computer Science
Distributed Computing ParadigmsDistributed Computing Paradigms
MapReduceDesigned (reinvented) by Google for making a subset
of distributed problems easier to codeAutomates data distribution & result aggregation Restricts the ways data can interact to eliminate locks
(no shared state = no locks!)
Computer Science
A Spectrum of ParadigmsA Spectrum of Paradigms
Paradigms differ in what they abstract Less granular abstractions (e.g., RPC) are more expressive but
not for consumption by amateurs Granular abstractions (e.g., client-server) are less expressive,
but safe for consumption by amateurs The “right” granularity (e.g., MapReduce) is somewhere in the
middle and depends on targeted application
Easier if paradigm does not have to worry about the communication infrastructure – how messages between threads are exchanged? Need an abstraction for that too!
Computer Science
Sockets and PortsSockets and Ports
A socket is the basic network interface Provides a two-way “pipe” abstraction
between two applications
On server, a port identifies a “listening” program Allows multiple clients to connect to a server at once
Computer Science
Example: Web ServerExample: Web Server
80 Server
(1) Server creates a socket attached to port 80 and listens in on that port for client requests
Computer Science
Example: Web ServerExample: Web Server
80 ServerClient anon
(2) Client creates a local socket and connects to port 80 of the server

3
Computer Science
ServerThread
Example: Web ServerExample: Web Server
80 Server
anonClient anon
(3) Server accepts connection, creates a dedicated socket, and spawns a service thread. Server continues to listen in on port 80…
Computer Science
Example: Web ServerExample: Web Server
80 Server
ServerThreadanonClient anon
ServerThreadanonClient anon
ServerThreadanonClient anon
........
Computer Science
Client-Server InteractionsClient-Server Interactions
Regular client-server protocols involve sending data back and forth according to a shared state
Client: Server:
HTTP/1.0 index.html GET
200 OK
Length: 2400
(file data)
HTTP/1.0 hello.gif GET
200 OK
Length: 81494
…
Computer Science
Client-Server InteractionClient-Server Interaction
In the example of a Web server, client could not just start arbitrary services or code
For that, we need to call a procedure on a remote computer…
Computer Science
Remote Procedure CallRemote Procedure Call
RPC to servers will call arbitrary functions in dll, exe, with arguments passed over the network, and return values back over network
Client: Server:
foo.dll,bar(4, 10, “hello”)
“returned_string”
foo.dll,baz(42)
err: no such function
…
Computer Science
Possible Interfaces Possible Interfaces
RPC can be used with two basic interfaces: synchronous and asynchronous
Synchronous RPC is a “remote function call” – client blocks and waits for return value
Asynchronous RPC is a “remote thread spawn” – client does not need to block

4
Computer Science
Synchronous RPCSynchronous RPCComputer Science
Asynchronous RPCAsynchronous RPC
Computer Science
Asynchronous RPC: CallbacksAsynchronous RPC: CallbacksComputer Science
More Design ConsiderationsMore Design Considerations
Numerous protocols: DCOM, CORBA, JRMI…Who can call RPC functions? Anybody? How to handle multiple versions of a function? Need to marshal objects How do you handle error conditions?
Oh! And, then there is safety and security…
And, what about these “sockets”?
Computer Science
What makes “sockets” work?What makes “sockets” work?
Underneath the socket layer are several more protocols Most important are TCP and IP (which are used hand-in-
hand so often, they’re often spoken of as one protocol: TCP/IP)
Even more low-level protocols handle how data is sent over Ethernet wires, or how bits are sent through the air using 802.11 wireless…
Computer Science
IP: The Internet ProtocolIP: The Internet Protocol
Defines the addressing scheme for computers Encapsulates internal data in a “packet”
Does not provide reliability Just includes enough information for the data to
tell routers where to send it

5
Computer Science
TCP: Transmission Control ProtocolTCP: Transmission Control Protocol
Built on top of IP Introduces concept of “connection” Provides reliability and ordering
Computer Science
Why is This Necessary?Why is This Necessary?
Not actually tube-like “underneath the hood”
Unlike the phone system (circuit switched), the packet switched Internet uses many routes at once
Computer Science
Layering: In Networking Layering: In Networking
The set of protocols at the various layers constitute the protocol “stack”.
Software written for layer i on C1 “believes” that it is interacting with software at layer i on C2.
The software at layer n at the destination receives exactly the same protocol message sent by layer n at the sender.
Computer Science
Layering: In Networking (IP Stack)Layering: In Networking (IP Stack)
Computer Science
LayeringLayering
Layering is an approach for managing complexity
Systems are designed at one layer with a model of the functionality of the underlying layer
Details of the implementation details of a lower layer functionality are hidden from the upper layer
Layering allows compatibility with multiple and/or new implementations
Any disadvantages?
Computer Science
Layering: In Networking Layering: In Networking Layering allows for services to be shared and/or
combined at higher layers. Example: TCP/IP Stack

1
Hadoop / Map Reduce
1
Azer Bestavros
Slides (with minor adjustments) are courtesy of Andreas Haeberlen
Application: National census
Suppose we have 10,000 employees, whose job is to collate census forms and to determine how many people are ina given profession
How would you organize this task?
3
http
://w
ww
.cen
sus.
gov/
2010
cens
us/p
df/2
010_
Ques
tionn
aire
_Inf
o.pd
f
Abstracting the data flow
4
Filter+StackWorker
Filter+StackWorker
Filter+StackWorker
Filter+StackWorker
CountStackWorker
CountStackWorker
CountStackWorker
CountStackWorker
CountStackWorker
blue: 4k
green: 4k
cyan: 3k
gray: 1k
orange: 4k
Making things more complicated
Employees take vacations, get sick, work at different rates
Some forms are incorrectly filled and require corrections or need to be thrown away
What if the supervisor gets sick? How big should the stacks be? How do we monitor progress? ...
5
Application: Indexing the web
Suppose we have 10,000 computers, used to scrape the webdaily to compute an index of medical termsfor WebMD
How would you organize this task?
6
Abstracting the data flow
7
Filter+StackWorker
Filter+StackWorker
Filter+StackWorker
Filter+StackWorker
Check+FileWorker
Check+FileWorker
Check+FileWorker
Check+FileWorker
Check+FileWorker
cancer links
diabetes links
flu links
mono links
zika links

2
Making things more complicated
Computers may go offline, crash, or operate at different speeds
Some web pages contain misspelled terms and/or are used for spamming/advertisement
Network or data center control may fail How big should the batches per server be? How do we monitor progress? ...
8
I don't want to deal with all this!!!
Wouldn't it be nice if there were some system that took care of all these details for you?
Ideally, you'd just tell the system what needs to be done…
That's the Hadoop/MapReduce framework.
9
What is MapReduce? A distributed programming model In many circles, considered the key building block for
much of Google’s data analysis A programming language built on it: Sawzall,
http://labs.google.com/papers/sawzall.html… Sawzall has become one of the most widely used programming languages at Google. … [O]n one dedicated Workqueue cluster with 1500 Xeon CPUs, there were 32,580 Sawzall jobs launched, using an average of 220 machines each. While running those jobs, 18,636 failures occurred (application failure, network outage, system crash, etc.) that triggered rerunning some portion of the job. The jobs read a total of 3.2x1015 bytes of data (2.8PB) and wrote 9.9x1012 bytes (9.3TB).
Other similar languages: Yahoo’s Pig Latin and Pig; Microsoft’s Dryad
Cloned in open source: Hadoop,http://hadoop.apache.org/
10
Why MapReduce? Scenario:
You have a huge amount of data, e.g., all the Google searches of the last three years
You would like to perform a computation on the data, e.g., find out which search terms were the most popular
How would you do it? The computation isn't necessarily difficult, but parallelizing
and distributing it, as well as handling faults, is challenging
Idea: A programming language! Write a simple program to express the (simple) computation,
and let the language runtime do all the hard work
11
Underlying Abstraction…
There are two kinds of workers: Those that take input data items and organize them into
“stacks” of items for later processing Those that take the stacks and aggregate the results to
produce outputs on a per-stack basis
We’ll call these: mapper: takes (item_key, value), produces one or more
(stack_key, value’) pairs reducer: takes (stack_key, {set of value’}), produces one or
more output results – typically (stack_key, agg_value)
12
We will refer to this keyas the reduce key
The MapReduce programming model Simple distributed functional programming primitives
modeled after Lisp primitives: map (apply function to all items in a collection) and reduce (apply function to set of items with a common key)
We start with: A user-defined function to be applied to all data,map: (data key, data value) (key, value)
Another user-specified operation reduce: (key, {set of values}) result
A set of n nodes, each with data All nodes run map on all of their data, producing new
data with keys This data is collected by key, then shuffled, and sent to
nodes and reduced13
3
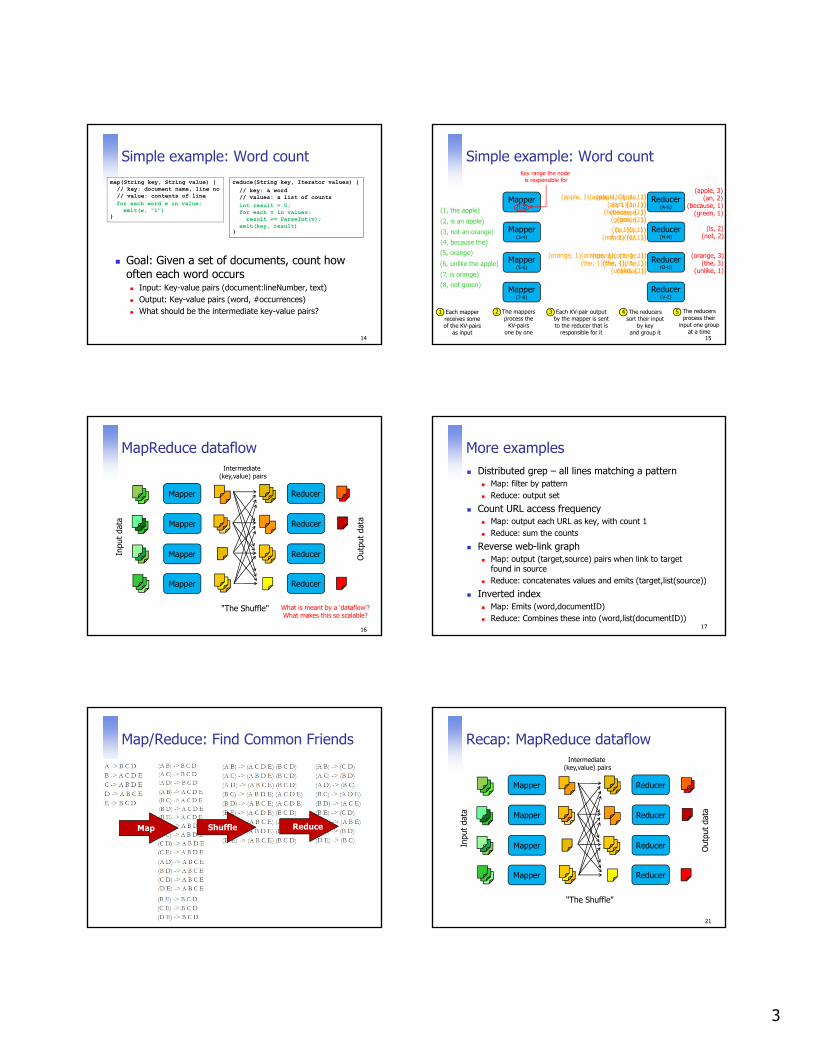
Simple example: Word count
Goal: Given a set of documents, count how often each word occurs Input: Key-value pairs (document:lineNumber, text) Output: Key-value pairs (word, #occurrences) What should be the intermediate key-value pairs?
map(String key, String value) {// key: document name, line no// value: contents of line
}
reduce(String key, Iterator values) {
// key: a word// values: a list of counts
}
for each word w in value:emit(w, "1")
int result = 0;for each v in values:result += ParseInt(v);
emit(key, result)
14
Simple example: Word count
15
Mapper(1-2)
Mapper(3-4)
Mapper(5-6)
Mapper(7-8)
Reducer(A-G)
Reducer(H-N)
Reducer(O-U)
Reducer(V-Z)
(1, the apple)(2, is an apple)(3, not an orange)(4, because the)(5, orange)(6, unlike the apple)(7, is orange)(8, not green)
(the, 1)
(apple, 1)
(is, 1)
(apple, 1)(an, 1)
(not, 1)
(orange, 1)
(an, 1)(because, 1)
(the, 1)(orange, 1)
(unlike, 1)
(apple, 1)
(the, 1)
(is, 1)
(orange, 1)
(not, 1)
(green, 1)
(apple, 3)(an, 2)
(because, 1)(green, 1)
(is, 2)(not, 2)
(orange, 3)(the, 3)
(unlike, 1)
(apple, {1, 1, 1})(an, {1, 1})
(because, {1})(green, {1})
(is, {1, 1})(not, {1, 1})
(orange, {1, 1, 1})(the, {1, 1, 1})
(unlike, {1})
Each mapper receives some of the KV-pairs
as input
The mappersprocess the
KV-pairs one by one
Each KV-pair outputby the mapper is sent to the reducer that is
responsible for it
The reducers sort their input
by key and group it
The reducers process their
input one groupat a time
1 2 3 4 5
Key range the node is responsible for
MapReduce dataflow
16
Mapper
Mapper
Mapper
Mapper
Reducer
Reducer
Reducer
Reducer
Inpu
t dat
a
Outp
ut d
ata
"The Shuffle"
Intermediate (key,value) pairs
What is meant by a 'dataflow'?What makes this so scalable?
More examples Distributed grep – all lines matching a pattern
Map: filter by pattern Reduce: output set
Count URL access frequency Map: output each URL as key, with count 1 Reduce: sum the counts
Reverse web-link graph Map: output (target,source) pairs when link to target
found in source Reduce: concatenates values and emits (target,list(source))
Inverted index Map: Emits (word,documentID) Reduce: Combines these into (word,list(documentID))
17
Map/Reduce: Find Common Friends
Map Shuffle Reduce
Recap: MapReduce dataflow
21
Mapper
Mapper
Mapper
Mapper
Reducer
Reducer
Reducer
Reducer
Inpu
t dat
a
Outp
ut d
ata
"The Shuffle"
Intermediate (key,value) pairs

4
Designing MapReduce algorithms Key decision: What should be done by map,
and what by reduce? map can do something to each individual key-value pair, but
it can't look at other key-value pairs Example: Filtering out key-value pairs we don't need
map can emit more than one intermediate key-value pair for each incoming key-value pair Example: Incoming data is text, map produces (word,1) for each word
reduce can aggregate data; it can look at multiple values, as long as map has mapped them to the same (intermediate) key Example: Count the number of words, add up the total cost, ...
Need to get the intermediate format right! If reduce needs to look at several values together, map
must emit them using the same key!22
Map Reduce on Movie Ratings
Movie ratings are provided as [uID::mID::R::T] Need to provide MapReduce code to histogram
ratings for each movie on a scale from 1 to 10uID mID R Time
1::0068646::10::13816200271::0113277::10::13794666692::0422720::08::1412178746 2::0454876::08::1394818630 2::0790636::07::1389963947 2::0816711::08::1379963769 2::1091191::07::1391173869 2::1103275::07::1408192129 2::1322269::07::1391529691 2::1390411::08::1451374513 2::1398426::08::1456160307 2::1431045::07::1457733508 2::1433811::08::1380453043 2::1454468::08::1387016442 2::1535109::08::1386350135 2::1675434::08::1396688981 2::1798709::10::1389948338 2::2017038::07::1390570895 2::2024544::10::1389355949 ......
Map Reduce on Movie Ratings
Map: input [key=(mID,R); value=1]
Reduce: [key=(mID,R); {v}] [key=(mID,R); value = sum({v})]
Can we make the histogram for all movies in database?
Map Reduce on Movie Ratings
Map: input [key=(mID,R); value=1]
Reduce: [key=(mID,R); {v}] [key=(mID,R); value = sum({v})]
Map: [key=(mID,R); sum] [key=R; value=sum]
Reduce: [key=R; {s}] [key=R; value = sum({s})]
Can we make the histogram from 1 to 5 stars (instead of an integer from 1-10)?
Map Reduce on Movie Ratings Map:
input [key=(mID,R); value=1] Reduce:
[key=(mID,R); {v}] [key=(mID,R); value = sum({v})] Map:
[key=(mID,R); sum] [key=R; value=sum] Reduce:
[key=R; {s}] [key=R; value = sum({s})] Map:
[key=R; sum] [key=S (=int(R/2)); value=sum] Reduce:
[key=S; {s}] [key=S; value = sum({s})]
Hadoop and friends
27
Azer Bestavros

5
Who uses (or used) Hadoop? Hadoop is (was) running search on some of
the Internet's largest sites: Amazon Web Services: Elastic MapReduce AOL: Variety of uses, e.g., behavioral analysis & targeting EBay: Search optimization Facebook: Reporting/analytics, machine learning Fox Interactive Media: MySpace, Photobucket, Rotten T. Last.fm: Track statistics and charts IBM: Blue Cloud Computing Clusters LinkedIn: People You May Know Rackspace: Log processing Twitter: Store + process tweets, log files, other data Yahoo: >40,000 nodes; biggest cluster is 4,500 nodes/455PB
28
What do MR programmers write? A mapper
Accepts (key,value) pairs from the input Produces intermediate (key,value) pairs to be shuffled
A reducer Accepts intermediate (key,value) pairs Produces final (key,value) pairs for the output
A driver Specifies which inputs to use, where to put the outputs
Hadoop takes care of the rest!! Storage, scheduling, synchronization, fault tolerance, …
29
Hadoop
File system to feed huge amounts of data into a MapReduce dataflow efficiently
Hadoop Distributed File System (HDFS)
Runtime platform for distributing map/reduce tasks across nodes, coordination, fault tolerance...
Fully Distributed Mode
30
What is HDFS? HDFS is a distributed file system
Makes some unique tradeoffs that are good for MapReduce
What HDFS does well: Very large read-only or append-only files (individual files may
contain Gigabytes/Terabytes of data) Sequential access patterns
What HDFS does not do well: Storing lots of small files Low-latency access Multiple writers Writing to arbitrary offsets in the file
31
HDFS versus NFS
Single machine makes part of its file system available to other machines
Sequential or random access PRO: Simplicity, generality,
transparency CON: Storage capacity and
throughput limited by single server
32
Single virtual file system spread over many machines
Optimized for sequential read and local accesses
PRO: High throughput, high capacity
"CON": Specialized for particular types of applications
Network File System (NFS) Hadoop Distributed File System (HDFS)
How data is stored in HDFS
Files are stored as sets of (large) blocks Default block size: 64 MB (ext4 default is 4kB!) Blocks are replicated for durability and availability What are the advantages of this design?
Namespace is managed by a single name node Actual data transfer is directly between client & data node Pros and cons of this decision?
33
foo.txt: 3,9,6bar.data: 2,4
block #2 of foo.txt?
9Read block 9
9
9
9 93
33
22
24
4
46
6Name node
Data nodesClient

6
The Secondary Namenode What if the state of the namenode is lost?
Data in the file system can no longer be read!
Solution #1: Metadata backups Namenode can write its metadata to a local disk, and/or to
a remote NFS mount
Solution #2: Secondary Namenode Purpose: Periodically merge the edit log with the fsimage
to prevent the log from growing too large Has a copy of the metadata, which can be used to
reconstruct the state of the namenode But: State lags behind somewhat, so data loss is likely if
the namenode fails35
Hadoop (HDFS) was built for MR
Could this be useful for other paradigms?
Apache Spark Instead of just “map” and “reduce”, defines a large
set of operations Transformations to “set things up” if and when needed Actions to “do computation” if needed
Operations can be arbitrarily combined in any order Supports Java, Scala and Python Adds persistent (intermediate) storage
55
Spark: Example (Python)# Estimate Pi (compute-intensive task).# Pick random points in the unit square ((0, 0) to (1,1)),# See how many fall in unit circle. The fraction = 0.25 Pi# Note that “parallelize” method creates an RDD
def sample(p):x, y = random(), random()return 1 if x*x + y*y < 1 else 0
count = spark.parallelize(xrange(0, NUM_SAMPLES)).map(sample)\.reduce(lambda a, b: a + b)
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)
Source: https://spark.apache.org/docs/latest/quick-start.html
60
Spark: Libraries
Spark SQL Queries over structured data
Spark Streaming Stream processing of live data streams
Mllib Machine learning
GraphX graph manipulation extends Spark RDD with Graph abstraction: a directed
multigraph with properties attached to vertices/edges
61

6
Computer Science
Networking IssuesNetworking Issues
If a party to a socket disconnects, how much data did they receive?
Did they crash? Or did a machine in the middle crash?
Can someone in the middle intercept/modify the data?
What is the cheapest, most efficient way to route data? Traffic congestion makes routing topology important for efficient throughput!
Computer Science
ConclusionConclusion
Distributed systems: Building layered abstractions to facilitate Internet-scale applications
Designing a large distributed system involves trade-offs at each of these levels
Appreciating subtle concerns at each level requires diving past the abstractions, but abstractions are still useful