20140528 aws meister blackbelt - amazon kinesis (korean)
TRANSCRIPT

Amazon Kinesis
[AWS Meister - Black Belt] 웨비나 시리즈 발표자료 번역: 정윤진 솔루션스 아키텍트
이 자료의 내용은 웨비나가 진행된 시기에 맞춰져 있어 현재의 내용과는 다를 수 있습니다. 내용에 대한 문의사항이 있으신 경우 [email protected]으로 연락 주시기 바랍니다.

Agenda
• Kinesis 를 둘러싼 환경
• Kinesis 개요
• 데이터 입력
• 데이터 수집 및 처리
• Kinesis 의 운용
• 샘플 아키텍처
• 사례
• 정리

Kinesis 를 둘러싼 환경

다량의 다양한 데이터 분석에 대한 비지니스 요구가 증가
M2M
센서 데이터 오픈 데이터
IoT
Web Logs
실시간으로 데이터를 처리하고자 하는 요구가 증가
POS Data

예컨데, 다음과 같은 케이스
서비스 및 시스템의
실시간 분석
•마케팅 이벤트 상황
파악
•게임내 이벤트의
상황 파악
•POS 데이터를 통한
매출 상황 파악
상태 분석/감시
•센서 이상 감지
•무단 침입 감지
서비스 품질 향상
•소설 데이터를
이용한 실시간
서비스
•사용자 최근 행동에
기반한 권고 사항

AWS의 예:신속 정확한 사용량 정보 분석
초당 수천만건의 레코드
수십만개의 데이터 소스
시간당 테라바이트의 데이터
매일 100개 이상의 ETL job
시간당 100건 이상의 SQL query
• 실시간 알람이 요구 • 스케일 가능한 구조로 변경
Kinesis

Kinesis 요약

Amazon Kinesis?
• 대량의 연속된 데이터를 실시간으로 처리 가능한 풀 매니지드 서비스
• Kinesis는, 수십만 곳의 데이터 소스에서 테라 바이트 수준의 데이터를 처리 할 수 있으며, 저장된 데이터는 다수의 AZ에 저장하여 신뢰성과 높은 내구성을 보유한 서비스

Kinesis 요약
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library + Connector Library
Apache Storm
Amazon Elastic MapReduce
PUT GET + Processing

Kinesis 내부 구조 및 용어
Data Sources
App.4
[Machine Learning]
App.1
[Aggregate & De-Duplicate]
Data Sources
Data Sources
Data Sources
App.2
[Metric Extraction]
S3
DynamoDB
Redshift
App.3
[Real-time Dashboard]
Data Sources
Availability Zone
Shard 1
Shard 2
Shard N
Availability Zone
Availability Zone
Kinesis
AW
S E
nd
poin
t
•데이터 용도 별 Stream을 생성, Stream은 1개 이상의 Shard로 구성됨
• Shard는 데이터 입력측에서 1MB/sec, 1000 TPS, 데이터 처리측에서는 2 MB/sec, 5TPS 의 처리량을 가짐
•입력 데이터를 Data Record라 하며, 입력 된 Data Record는 24시간 동안 다수의 AZ에 저장
• Shard의 증가 및 축소에 따라 스케일 아웃-인이 가능
Stream

설치 및 모니터링
• Management Console/API
Stream 이름과 Shard의 수량을 입력 Stream을 생성
용량 및 대기 시간을 모니터링, Cloud Watch모니터링 가능

비용
• 가격
과금
Shard 요금 $0.015/shard/시간
Put request $0.028/1,000,000PUT
예를 들어 1개월 (30일), 10Shard, 월 100,000,000PUT, 약 $110/월
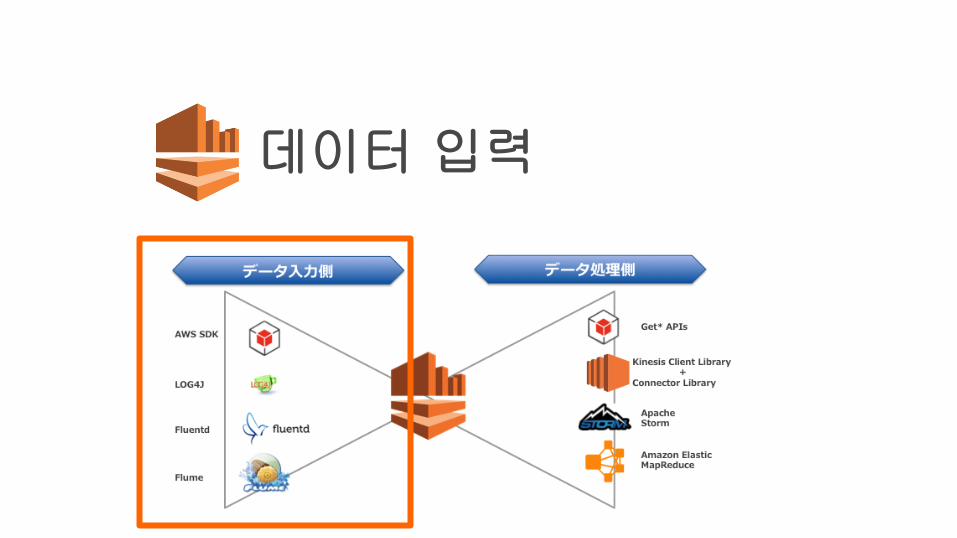
데이터 입력

데이터 입력 방법
• PutRecord API 로 데이터 입력이 가능 http://docs.aws.amazon.com/kinesis/latest/APIReference/API_PutRecord.html
• AWS SDK for Java, Javascript, Python, Ruby, PHP, .Net
예)boto를 이용하여 put_record
http://docs.pythonboto.org/en/latest/ref/kinesis.html#module-boto.kinesis.layer1

데이터 입력
Stream
Shard-0
Shard-1
Data Record
Data Record
Data Record
Kinesis는 받은 데이터를 Shard 에 분배
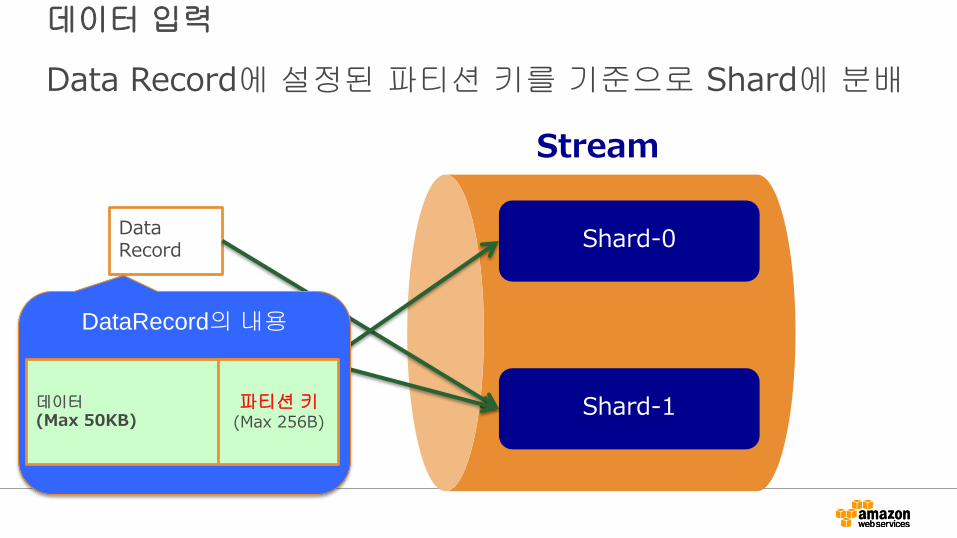
데이터 입력
Stream
Shard-0
Shard-1
Data Record
Data Record
Data Record
Data Record에 설정된 파티션 키를 기준으로 Shard에 분배
DataRecord의 내용
데이터 (Max 50KB)
파티션 키 (Max 256B)

Shard 분배 로직
Shard는 각 담당하는 범위를 기준으로 파티션 키와 MD5 값이 일치하는 범위의 Shard 에 분배
예 0 MD5의 범위
2128
Shard-1 (2128/2 - 2128)
MD5(파티션 키)
Shard-0 (0 - 2128/2)
데이터 파티션 키
값은 둘중 하나에 분배

파티션 키에 대한 Tips
TIPS
• Shard는 Partition Key를 기반으로 분배 • Shard의 용량은
Partition key 를 잘 설계하여 좋은 분산을 구현할 필요가 있다

Shard
시퀀스 넘버
Stream에 입력된 Data Record에 Kinesis의 Stream에서 유니크한 시퀀스 번호를 부여 (시간경과에 따라 함께 증가하는 구조) 연속된 PutRecord API를 호출하는 경우 순서가 달라질 수 있다. 동일한 파티션 키에서 순서가 매우 중요한 경우, PutRecord API의 호출에 주의 SequenceNumberForOrdering 매개 변수를 설정한다 시퀀스 번호는 PutRecord API 응답으로 확인 가능
데이터 레코드 (14)
데이터 레코드 (15)
데이터 레코드 (17)
데이터 레코드 (19)
데이터 레코드 (20)
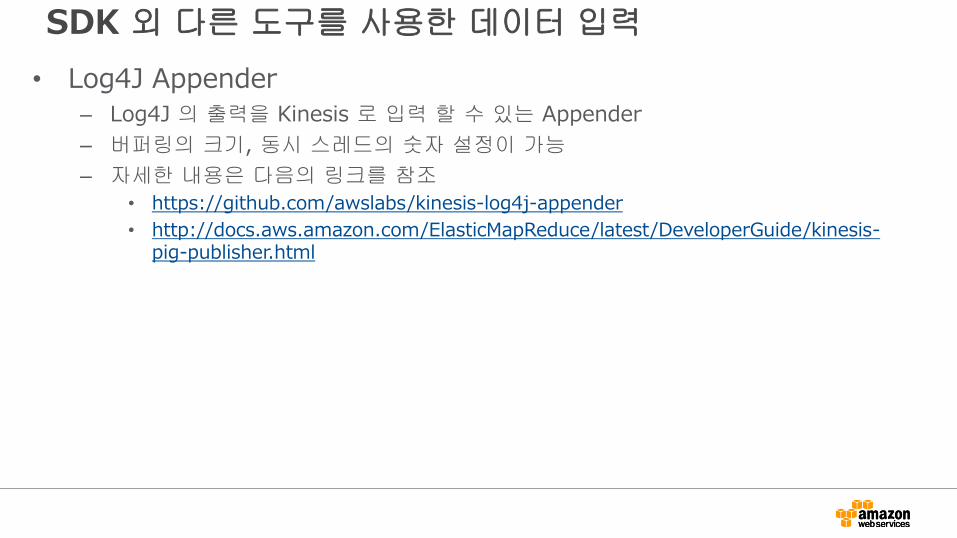
SDK 외 다른 도구를 사용한 데이터 입력
• Log4J Appender
– Log4J 의 출력을 Kinesis 로 입력 할 수 있는 Appender
– 버퍼링의 크기, 동시 스레드의 숫자 설정이 가능
– 자세한 내용은 다음의 링크를 참조
• https://github.com/awslabs/kinesis-log4j-appender
• http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/kinesis-pig-publisher.html

데이터의 수집 및 처리

데이터 취득 방법
• GetShardIterator API에서 Shard의 위치를 검색, GetRecords API를 사용하여 Kinesis 에 저장된 데이터를 가져올 수 있음 – http://docs.aws.amazon.com/kinesis/latest/APIReference/API_GetShardIterator.html
– http://docs.aws.amazon.com/kinesis/latest/APIReference/API_GetRecords.html
• AWS SDK for Java, Javascript, Python, Ruby, PHP, .Net
예)boto를 사용하여 get_shard_iterator, get_records
http://docs.pythonboto.org/en/latest/ref/kinesis.html#module-boto.kinesis.layer1

GetShardIterator의 검색 지정 방법
• GetShardIterator API는 ShardIteratorType을 지정하고 포지션을 얻을 수 있음
• ShardIteratorType 은 다음과 같음 – AT_SEQUENCE_NUMBER ( 지정된 시퀀스 넘버에서 데이터를 가져옴 )
– AFTER_SEQUENCE_NUMBER ( 지정된 시퀀스 넘버 이후부터 데이터를 가져옴 )
– TRIM_HORIZON ( Shard에 존재하는 가장 오래된 데이터부터 가져옴 )
– LATEST ( 최신 데이터부터 가져옴 )
Seq: xxx
LATEST
AT_SEQUENCE_NUMBER AFTER_SEQUENCE_NUMBER
TRIM_HORIZON
GetShardIterator의 동작

Kinesis Client Library
• GetShardIterator API 및 GetRecords API를 이용하여 데이터의 검색 및 데이터 처리를 할 수 있지만, 데이터를 처리하는 인스턴스에 대한 고가용성과 Shard 의 분할, 병합등의 복잡한 처리를 구현할 필요가 있다.
• Kinesis Client Library를 이용하면 이러한 복잡한 과정을 따로 구현하지 않고 비지니스 로직에 집중 할 수 있다.
• Kinesis Client Library는 Java 를 지원
• Github에서 소스를 확인 할 수 있음 – https://github.com/awslabs/amazon-kinesis-client
• Kinesis Client Library는 체크 포인트의 관리에 DynamoDB를 이용하고 있으며 처음 시작할때 DynamoDB 테이블을 생성한다. – 기본적으로 Read Provisioned Throughput, Write Provisioned Throughput은 10으로 설정됨

Kinesis Client Library
• Kinesis Client Library를 사용한 응용 프로그램(Kinesis응용 프로그램)을 실행하면 Worker 가 생성되어 Kinesis 에서 데이터를 검색한다.
• Kinesis 응용 프로그램 측면에서는 구성 설정 및 데이터 처리를 위한 IRecordProcessor 를 사용
• 개발 관련 내용은 다음의 링크를 참조 – http://docs.aws.amazon.com/kinesis/latest/dev/kinesis-record-processor-
app.html

Kinesis Client Library 샘플 코드
public class SampleRecordProcessor implements IRecordProcessor { @Override public void initialize(String shardId) { LOG.info("Initializing record processor for shard: " + shardId); this.kinesisShardId = shardId; } @Override public void processRecords(List<Record> records, IRecordProcessorCheckpointer checkpointer) { LOG.info("Processing " + records.size() + " records for kinesisShardId " + kinesisShardId); // Process records and perform all exception handling. processRecordsWithRetries(records); // Checkpoint once every checkpoint interval. if (System.currentTimeMillis() > nextCheckpointTimeInMillis) { checkpoint(checkpointer); nextCheckpointTimeInMillis = System.currentTimeMillis() + CHECKPOINT_INTERVAL_MILLIS;
} } }
[Sample RecordProcessor ]

Kinesis Client Library 샘플 코드
IRecordProcessorFactory recordProcessorFactory = new SampleRecordProcessorFactory(); Worker worker = new Worker(recordProcessorFactory, kinesisClientLibConfiguration); int exitCode = 0; try { worker.run(); } catch (Throwable t) {
LOG.error("Caught throwable while processing data.", t); exitCode = 1; }
[Sample Worker]
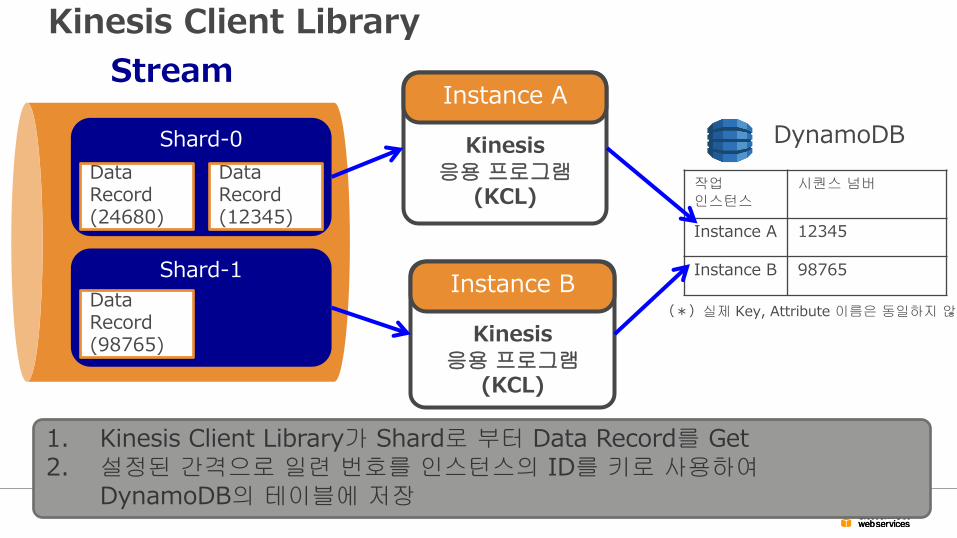
Kinesis Client Library
Stream
Shard-0
Shard-1
Kinesis 응용 프로그램
(KCL) 작업 인스턴스
시퀀스 넘버
Instance A 12345
Instance B 98765
Data Record (12345)
Data Record (24680)
Data Record (98765)
DynamoDB
Instance A
Kinesis 응용 프로그램
(KCL)
Instance B
1. Kinesis Client Library가 Shard로 부터 Data Record를 Get 2. 설정된 간격으로 일련 번호를 인스턴스의 ID를 키로 사용하여
DynamoDB의 테이블에 저장
(*)실제 Key, Attribute 이름은 동일하지 않음
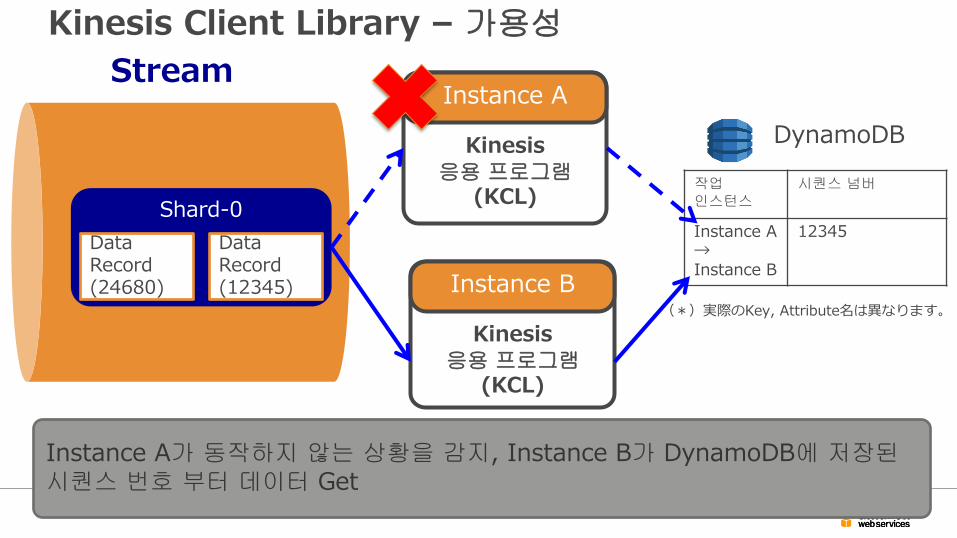
Kinesis Client Library – 가용성
Stream
Shard-0
Kinesis 응용 프로그램
(KCL) 작업 인스턴스
시퀀스 넘버
Instance A → Instance B
12345 Data Record (12345)
Data Record (24680)
DynamoDB
Instance A
Kinesis 응용 프로그램
(KCL)
Instance B
Instance A가 동작하지 않는 상황을 감지, Instance B가 DynamoDB에 저장된 시퀀스 번호 부터 데이터 Get
(*)実際のKey, Attribute名は異なります。

Kinesis Client Library – 확장성
Stream
Shard-0
Kinesis 응용 프로그램
(KCL)
Shard 작업 인스턴스
시퀀스 넘버
Shard-0 Instance A 12345
Shard-1 Instance A 98765
Data Record (12345)
Data Record (24680)
DynamoDB
Instance A
Shard-1 이 증설된 것을 감지하여 데이터 수집을 시작하고 Shard-1 의 체크포인트 정보를 DynamoDB 에 추가
Shard-1
Data Record (98765)
New
(*)実際のKey, Attribute名は異なります。

목적에 따라 Kinesis 응용 프로그램 추가가 가능
Stream
シャード
Shard
データ レコード (12345)
データ レコード (98765)
データ レコード (24680)
데이터 레코드 (12345)
데이터 레코드 (98765)
데이터 레코드 (24680)
응용 프로그램 (KCL)
DynamoDB
Instance A Shard 작업
인스턴스 시퀀스 넘버
Shard-0 Instance A 12345
Shard-1 Instance A 98765
응용 프로그램 (KCL)
Instance A Shard 작업
인스턴스 시퀀스 넘버
Shard-0 Instance A 24680
Shard-1 Instance A 98765
각 응용 프로그램마다 서로 다른 테이블에서 관리
Archive Table
Calc Table

Kinesis Connector Library
• Kinesis Connector Library를 이용하면 S3, DynamoDB、Redshift와 같은 다른 서비스와 연동이 매우 용이함
• Kinesis Connector Library는 Java를 지원 • Github 링크
– https://github.com/awslabs/amazon-kinesis-connectors
RedShift
DynamoDB
S3
다른 데이터 분석을 위해 저장
실시간 대시 보드 및 순위
축적된 데이터를 다각도로 분석
Kinesis

• Data Record의 검색, 변환, 필터, 버퍼 및 저장등을 매우 쉽게 구현 가능
ITransformer
•Kinesis
에서
사용자가
원하는
모델로
변환
IFilter
•데이터를
필터링,
필터링을 거친
데이터가
버퍼로 이동
IBuffer
•지정된
레코드 또는
바이트까지
버퍼
IEmitter
•다른 AWS
서비스
접근
S3
DynamoDB
Redshift
Kinesis
Kinesis Connector Library

Kinesis Connector Library 샘플 코드
public class S3Pipeline implements IKinesisConnectorPipeline<KinesisMessageModel, byte[]> { @Override public ITransformer<KinesisMessageModel, byte[]> getTransformer(KinesisConnectorConfiguration configuration) { return new JsonToByteArrayTransformer<KinesisMessageModel>(KinesisMessageModel.class); } @Override public IFilter<KinesisMessageModel> getFilter(KinesisConnectorConfiguration configuration) { return new AllPassFilter<KinesisMessageModel>(); } @Override public IBuffer<KinesisMessageModel> getBuffer(KinesisConnectorConfiguration configuration) { return new BasicMemoryBuffer<KinesisMessageModel>(configuration); } @Override public IEmitter<byte[]> getEmitter(KinesisConnectorConfiguration configuration) { return new S3Emitter(configuration); } }
[Sample S3 pipeline]
JSON을 ByteArray로 변환
모든 패스 필터
메모리 버퍼
S3에 데이터 저장
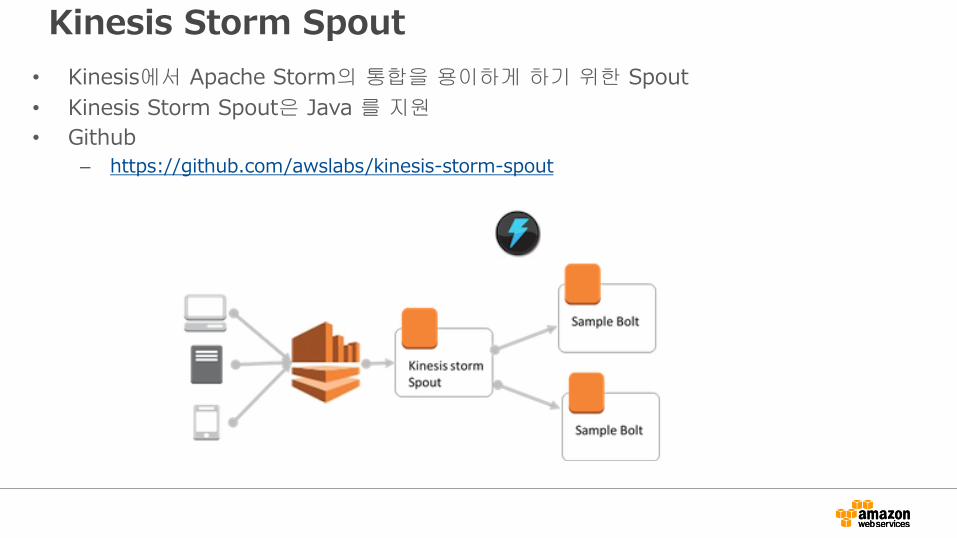
Kinesis Storm Spout
• Kinesis에서 Apache Storm의 통합을 용이하게 하기 위한 Spout
• Kinesis Storm Spout은 Java 를 지원
• Github
– https://github.com/awslabs/kinesis-storm-spout

EMR Connector
• Hive、Pig、Cascading、Hadoop Streaming등 친숙한 Hadoop 관련 도구를 사용하여 Kinesis Stream의 데이터를 검색, Map Reduce 처리가 가능
• ETL 처리와 다른 Kinesis Stream, S3, DynamoDB, HDFS의 Hive Table등의 다른 데이터 소스의 테이블과 JOIN 하는것도 가능
– (예) Clickstream (Kinesis) JOIN Ad campaign data (DynamoDB)
Kinesis Stream EMR Hive
Table
Data Storage
Table Mapping
(Hive 사용의 경우)
http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-kinesis.html

EMR Connector : Hive 사용 사례
Hive 테이블 생성
Kinesis Stream 정의
HQL 실행 (예)
HQL을 실행하면 내부적으로는 Kinesis 에서 데이터를 검색, 처리

• 먼저 처리된 데이터의 중복 처리를 피하기 위해 DynamoDB 를 사용하여 체크포인트를 참조
• Data pipeline / Crontab 을 주기적으로 실행하여 Kinesis에서 주기적으로 데이터를 수신, 처리가 가능
EMR Connector : Hive 사용 사례

Kinesis의 운용

CloudWatch를 통한 모니터링
• CloudWatch를 통해 아래의 메트릭을 확인 가능
• Shard의 운용에 사용 할 수 있음
메트릭
GetRecords.Bytes GetRecords 로 얻은 바이트 수
GetRecords.IteratorAge GetShardIterator 사용 시간
GetRecords.Latency GetRecords 지연시간
GetRecords.Success GetRecords API 정상 처리 카운트
PutRecord.Bytes PutRecord 로 입력된 바이트 수
PutRecord.Latency PutRecord 지연시간
PutRecord.Success PutRecord API 정상 처리 카운트

Shard의 분산 및 병합
• Shard의 용량과 실제 사용에 따라 Shard 를 분할 또는 병합하여 처리량의 확장과 비용의 최적화가 가능
• SpritShard API로 분할, MergeShards API로 병합 가능 – (SpritShard) http://docs.aws.amazon.com/kinesis/latest/APIReference/API_SplitShard.html
– (MergeShards) http://docs.aws.amazon.com/kinesis/latest/APIReference/API_MergeShards.html
AW
S En
dp
oin
t
Availability
Zone
Shard 1
Shard 2 Shard N
Availability
Zone Availability
Zone Shard-
1
Shard-
2
Shard-
1
Shard-
2
Shard-
3
Shard-
4 분할

SpritShard와 MergeShards의 적용예
• 처리하고자 하는 데이터의 특성에 맞게 Shard를 운용 – Shard는 시간단위로 비용이 청구되므로 낭비 없이 사용 할 수 있도록 Split /Merge 를 적용
• 처리량이 많아지는 시간에 Shard 를 분할하고 적어지면 병합하는 방법

SpritShard API
• SpritShard에서 담당하는 Hash key 의 시작값을 지정
conn = KinesisConnection()
descStream = conn.describe_stream(stream_name)
for shard in descStream['StreamDescription']['Shards']:
StartHashKey = shard['HashKeyRange']['StartingHashKey']
EndHashKey = shard['HashKeyRange']['EndingHashKey’]
NewHashKey = (long(EndHashKey) - long(StartHashKey))/2
print "StartHashKey : ", StartHashKey
print "EndHashKey : ", EndHashKey
print "NewHashKey : ", str(NewHashKey)
ret = conn.split_shard(stream_name,targetShard,str(NewHashKey))
Boto를 사용한 예:1Stream1Shard를 절반으로 분할
StartHashKey : 0
EndHashKey : 340282366920938463463374607431768211455
NewHashKey : 170141183460469231731687303715884105727
위의 코드로 출력되는 내용: 0-34의 shard가 0-17xx , 17xx-34xx 로 분할 )

MergeShards API
• MergeShards API는 기존 Shard 와 병합하려는 Shard 를 지정
conn = KinesisConnection()
conn.merge_shards(stream_name,targetShard, mergedShard)
Boto 사용 예
샘플 아키텍처

Digital Ad. Tech Metering with Kinesis
Incremental Ad.
Statistics
Computation
Metering Record Archive
Ad Analytics Dashboard
Continuous Ad
Metrics Extraction

Stream을 연속으로 파이프라인과 같이 연결
Data Sources
Data Sources
Data Sources
Kinesis App
Kinesis App
Kinesis App
Data Sources
Data Sources
Data Sources
Kinesis App
Kinesis App
Kinesis App
Kinesis App
Data Source 그룹 A
Data Source 그룹 B
Data Source 그룹A용 ETL (클렌징)
Data Source 그룹B용 ETL (클렌징)
집계

다른 AWS 서비스와 연동
AW
S E
ndpoin
t
Kinesis App.1
Kinesis App.2
Redshift
DynamoDB
Kinesis App.3
Availability Zone
Shard 1
Shard 2
Shard N
Availability Zone
Availability Zone
RDS
데이터 분석가
BI도구, 통계 분석
Data as a Service를 제공
서비스 제공
S3
기업 데이터의 저장
최종 사용자에게 push
Kinesis에 의한 스트림 저장

사용 사례

導入事例
게임 엔진 서버에서 보내는 수백의 게임 데이터를 실시간으로 Amazon Kinesis 로 보내고 비지니스에 필수적인 분석 및 대시 보드 어플리케이션을 지연없이 운용
기존 배치 기반의 데이터 수집 및 분석 메커니즘을 Amazon Kinesis 로 대체하여 실시간 분석으로 변경, 시스템 운용 자원 및 비용을 절감

Gaming Analytics with Amazon Kinesis

Kinesisの使いドコロ

SQS와 Kinesis의 구분
• Kinesis는 Pub-Sub 메세지 모델을 구축 가능하며, Stream에서 유일한 시퀀스 넘버가 DataRecord에 부여되기 때문에 순차적인 처리가 가능하다
SQS 데이터 소스 Worker
Worker
단일 메세지 타입에 대해 여러 Worker 가 처리
Kinesis 데이터소스
Worker A
Worker B
목적에 따라 Kinesis 응용 프로그램을 구현하여 동일한 소스 데이터를 동시에 사용 가능

실시간 대시 보드
• Web로그, 센서 데이터 등 실시간 정보의 시각화 용도
• 단기적인 데이터의 시각화 뿐만 아니라 장기적인 분석을 위한 저장도 가능
센서
센서
센서 Kinesis App [보관]
Dashboard Kinesis App [요약, 이상 감지]
Redshift
DynamoDB
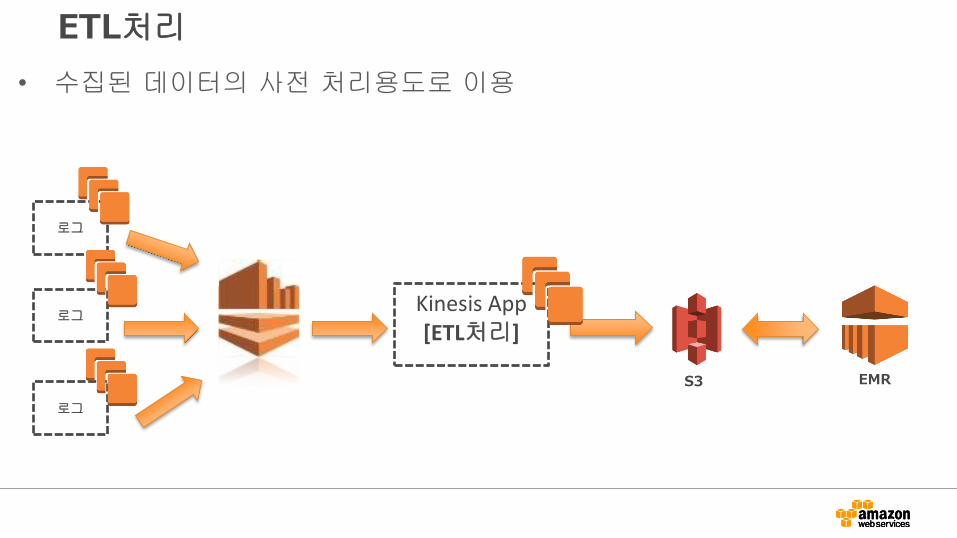
ETL처리
로그
로그
로그
• 수집된 데이터의 사전 처리용도로 이용
Kinesis App [ETL처리]
S3 EMR
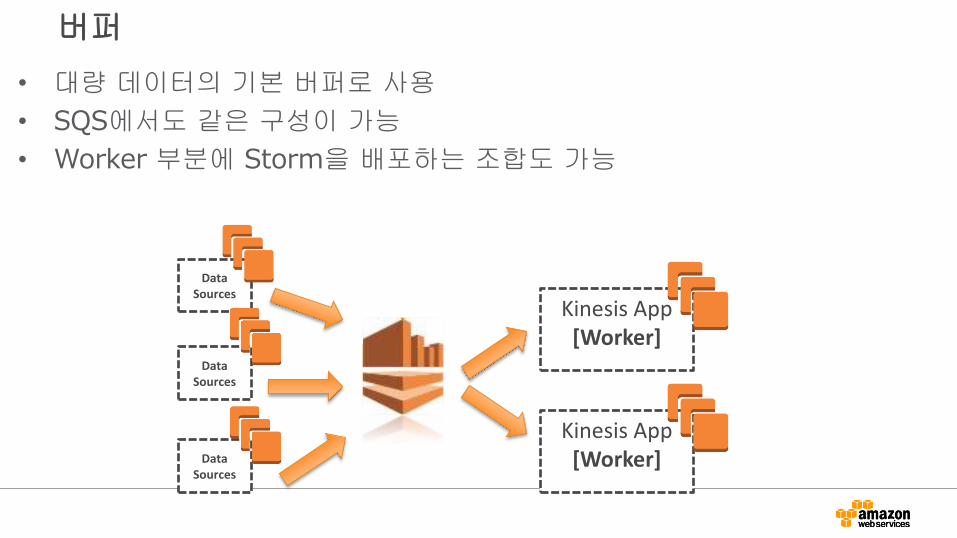
버퍼
Data Sources
Data Sources
Data Sources
Kinesis App [Worker]
• 대량 데이터의 기본 버퍼로 사용
• SQS에서도 같은 구성이 가능
• Worker 부분에 Storm을 배포하는 조합도 가능
Kinesis App [Worker]

결론

쉬운 관리
실시간 스트리밍 데이터 수집
및 처리를 위한 매니지드
서비스. Stream 구축이 매우
쉬움
실시간
스트리밍 유형의 빅데이터
처리가 가능. 몇분, 몇시간의
배치성 처리와 비교하여 몇초
이내로 데이터 처리가 가능
신축성
처리 속도와 볼륨을 원하는
대로 변경 가능하여 비지니스
요구에 맞는 스케일 업/다운이
가능
S3, Redshift, &
DynamoDB
통합
데이터의 수집, 변환, 처리 후
S3및 Redshift, DynamoDB에
저장하는것이 가능
실시간 처리
응용 프로그램
Kinesis Client Library를
이용하여 쉽게 실시간
스트리밍 데이터 처리의
구현이 가능
Low Cost
모든 규모의 워크로드를 비용
효율적으로 수용 가능
Amazon Kinesis

참고 자료
• Amazon Kinesis API Reference – http://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html
• Amazon Kinesis Developer Guide http://docs.aws.amazon.com/kinesis/latest/dev/introduction.html
• Amazon Kinesis Forum https://forums.aws.amazon.com/forum.jspa?forumID=169#

Q&A