1/24 exploring the design space of a parallel object recognition system bor-yiing su,...
TRANSCRIPT

1/24
Exploring the Design Space of a Parallel Object Recognition
SystemBor-Yiing Su, [email protected] Keutzer, [email protected]
and the PALLAS grouphttp://parlab.eecs.berkeley.edu/wiki/pallas
Parallel Computing Lab,University of California, Berkeley
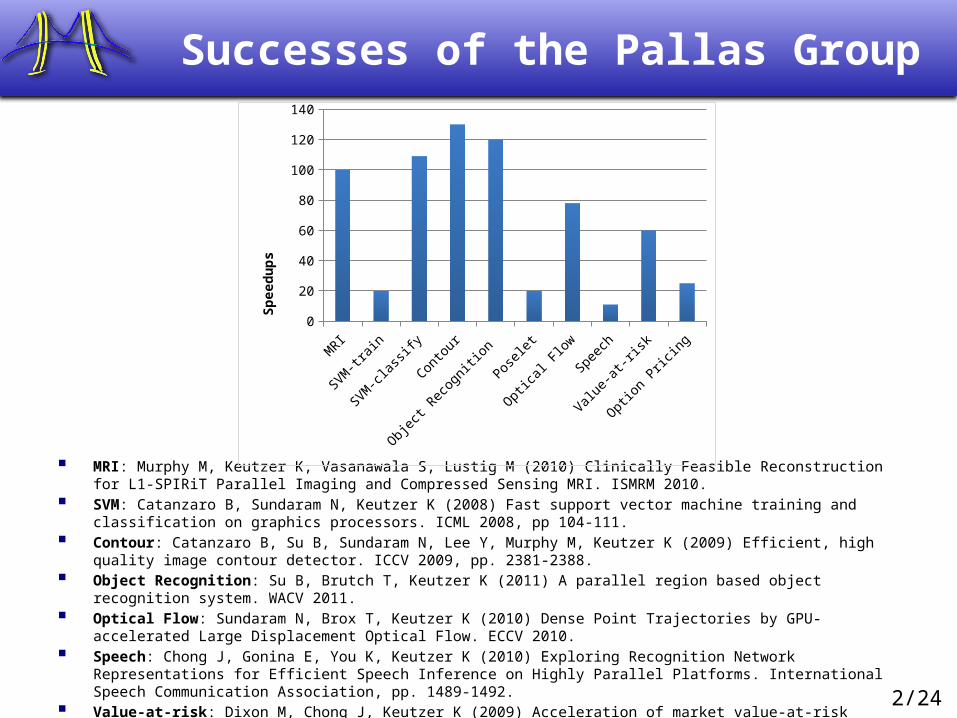
2/24
Successes of the Pallas Group
MRI: Murphy M, Keutzer K, Vasanawala S, Lustig M (2010) Clinically Feasible Reconstruction for L1-SPIRiT Parallel Imaging and Compressed Sensing MRI. ISMRM 2010.
SVM: Catanzaro B, Sundaram N, Keutzer K (2008) Fast support vector machine training and classification on graphics processors. ICML 2008, pp 104-111.
Contour: Catanzaro B, Su B, Sundaram N, Lee Y, Murphy M, Keutzer K (2009) Efficient, high quality image contour detector. ICCV 2009, pp. 2381-2388.
Object Recognition: Su B, Brutch T, Keutzer K (2011) A parallel region based object recognition system. WACV 2011. Optical Flow: Sundaram N, Brox T, Keutzer K (2010) Dense Point Trajectories by GPU-accelerated Large Displacement
Optical Flow. ECCV 2010. Speech: Chong J, Gonina E, You K, Keutzer K (2010) Exploring Recognition Network Representations for Efficient Speech
Inference on Highly Parallel Platforms. International Speech Communication Association, pp. 1489-1492. Value-at-risk: Dixon M, Chong J, Keutzer K (2009) Acceleration of market value-at-risk estimation. Workshop on High
Performance Computing in Finance at Super Computing.
MRI
SVM-tr
ain
SVM-cl
assify
Contour
Object R
ecogn
ition
Poselet
Optical Fl
owSp
eech
Value-a
t-risk
Option Pricing
0
20
40
60
80
100
120
140
Spee
dups

3/24
Outline
Design Space An Object Recognition System Exploring the Design Space of the Object Recognition system Conclusion

4/24
Three Layers of Design Space
The design space of parallel applications is composed of three layers
Design Space Explanation Example
Algorithm Layer
Using different ways to transform same inputs into same or similar outputs
Parallelization Strategy Layer
Using different strategies to parallelize the same algorithm
Platform Layer
Using specific hardware features to optimize the same parallelization strategy
LanczosSolver
BFS Graph Traversal
Blocking Dimensions
Full
Selective
No with CW test
Graph Partition
Parallel Task Queue
2 x 8
4 x 4
8 x 2
?
?
?

5/24
Statements
1. Exploring the design space is necessary to achieve high performance on a hardware platform of choice
2. Take advantage of domain knowledge is necessary to understand trade-offs among different parallelization methods and achieve peak performance
Algorithm Layer
Parallelization Strategy Layer
Platform Layer
Design Space

6/24
Outline
Design Space An Object Recognition System Exploring the Design Space of the Object Recognition system Future Work

7/24
Object Recognition System
ObjectRecognition
System
Image Queries Outputs
BottlesSwans
Trained Categories
MugsGiraffes
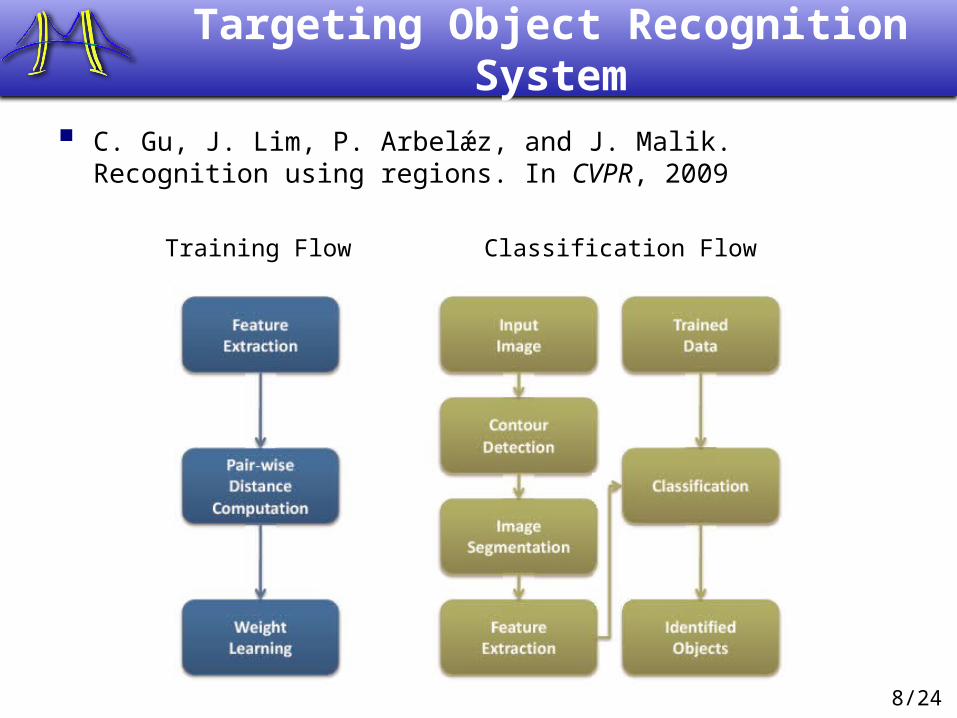
8/24
Targeting Object Recognition System
C. Gu, J. Lim, P. Arbelǽz, and J. Malik. Recognition using regions. In CVPR, 2009
Training Flow Classification Flow

9/24
Outline
Design Space An Object Recognition System Exploring the Design Space of the Object Recognition system
Lanczos Eigensolver Breadth First Search (BFS) Graph Traversal Kernel Pair-wise Distance Kernel Overall Performance Demo
Conclusion

10/24
Lanczos Eigensolver
The Lanczos Eigensolver is the most time consuming part in the contour detection computation
By linking pixels to its neighbors, we can construct an affinity matrix among the pixels
We can find good contours by performing the normalized cut spectral graph partitioning algorithm on the graph
The normalized cut can be solved by finding the eigenvectors of the affinity matrix

11/24
Exploring the Algorithm Layer
Three different re-orthogonalization methods Full re-orthogonalization Selective re-orthogonalization No re-orthogonalization with Cullum - Willoughby test
500 550 600 650 700 750 800 850 900 950 10000
1
2
3
4
5
6
7x 10
-3
# of iteratoin
Ritz
Val
ue
500 550 600 650 700 750 800 850 900 950 10000
1
2
3
4
5
6
7x 10
-3
# of iteratoin
Ritz
Val
ue
500 550 600 650 700 750 800 850 900 950 10000
1
2
3
4
5
6
7x 10
-3
# of iteratoin
Ritz
Val
ue
Full ReorthogonalizationSelective ReorthogonalizationNo Reorthogonalization

12/24
Experimental Results
Matlab Trlan ParaMat Full Selective No0
50
100
150
200
250Ru
n tim
e (s
)
Method Runtime(s)Matlab 227Trlan 170
ParaMat 151.2Full 15.83
Selective 3.6No 0.81
Explored Design Space Three different re-orthogonalization methods
Conclusion: • Use the no re-orthogonalization with Cullum- Willoughby test
method on a GPU in our system

13/24
BFS Graph Traversal Kernel
The image segmentation component heavily relies on the BFS graph traversal kernel
Image Graph: Nodes represent image pixels Edges represent neighboring relationships
BFS graph traversal kernel: propagate information from some pixels to other pixels

14/24
Exploring the Algorithm Layer
Direct algorithm: Each source node propagates information to its neighbors Traditional BFS graph traversal algorithm
Reverse algorithm: Each node checks whether it can be updated by one or more neighboring nodes Structured grid computation

15/24
Exploring the Parallelization Strategy Layer
Two strategies can be used to parallelize the traditional BFS graph traversal algorithm Graph partition Parallel task queue
...
Graph Partition Task Queue

16/24
Associating Design Space Exploration with Input Data Properties
Explored Design Space Parallel Task queue on Intel
Core i7 using OpenMP with 8 threads
Graph partition on Intel Core i7 using OpenMP with 8 threads
Structured grid on Nvidia GTX 480
Maximum Traversal Distance
Com
puta
tion
Tim
e (s
)
Conclusion: • Use the structured grid
method on a GPU in our system

17/24
Pair-wise χ2 Distance Kernel
In both the training stage and the classification stage, we need to compute the pair-wise distance between two region sets Similar regions have shorter distance Different regions have longer distance
It is a matrix matrix multiplication computation Replacing dot product into χ2 distance
Definition of the χ2 distance:

18/24
Exploring the Design Space
Algorithm Layer Inner χ2 distance
Outer χ2 distance
Platform Layer Cache Mechanisms
No Cache Hardware Controlled
Cache (Texture memory on GPU)
Software Controlled Cache (Shared memory on GPU)

19/24
Associating Design Space Exploration with Input Data Properties
Explored Design Space The combination of two
algorithms and three cache mechanisms on Nvidia GTX 480
Conclusion: • Use the outer χ2 distance
method with software controlled cache in the training stage
• Use the inner χ2 distance method with software controlled cache in the classification stage

20/24
Overall Performance: Speedups
Training Classification
Computation
Computation time (s) Speedup
Serial Parallel
Contour 236.7 1.58 150x
Segmentation
2.27 0.357 6.36x
Feature 7.97 0.065 123x
Hough Voting
84.13 0.779 108x
Total 331.07 2.781 119x
Computation
Computation time (s) Speedup
Serial Parallel
Feature 543 15.97 34x
Distance 1732 2.9 597x
Weight 57 1.41 40x
Total 2332 20.28 115x

21/24
Overall Performance: Detection Accuracy
Serial Parallel
FPPI
Det
ectio
n R
ate
FPPI
Det
ectio
n R
ate

22/24
Demo

23/24
Conclusion
Exploring the design space is necessary to achieve high performance on a hardware platform of choice
Take advantage of domain knowledge is necessary to understand trade-offs among different parallelization methods and achieve peak performance
We have developed a parallel object recognition system with comparable detection accuracy while achieving 110x-120x times speedup
Work presented at ICCV 2009 and WACV 2011
Bor-Yiing Su, Tasneem Brutch, Kurt Keutzer, "A Parallel Region Based Object Recognition System," in IEEE Workshop on Applications of Computer Vision (WACV 2011), Hawaii, January 2011Bryan Catanzaro, Bor-Yiing Su, Narayanan Sundaram, Yunsup Lee, Mark Murphy, and Kurt Keutzer, "Efficient, High-Quality Image Contour Detection," in International Conference on Computer Vision (ICCV-2009), pp. 2381-2388, Kyoto Japan, September 2009.

24/24
Thank You