11. vorlesung - rückblick und...
TRANSCRIPT

Textdatenbanken
Sommersemester 200911. Vorlesung
- Rückblick und Zusammenfassung -
Uwe Quasthoff
Universität LeipzigInstitut für Informatik

U. Quasthoff Textdatenbanken 2
Inhalt
• Archiv – Korpus – Textdatenbank• Korpuserstellung: Texte sammeln• Korpuserstellung: Texte aufbereiten• Textdatenbank erstellen• Korpora vergleichen und abfragen• Paralleler Text

U. Quasthoff Textdatenbanken 3
Wünsche beim Arbeiten mit viel Text
• Sehr viel Text, Größenordnung 109 laufende Wörter, 10 GB.• Ständige Erweiterung der Ressourcen• Auswahl nach verschiedenen Kriterien, z.B.
– Sprache– Sachgebiet– Entstehungszeit
• Gute Qualität (d.h. wenig Datenmüll, siehe später).• Schneller Zugriff (kein sequenzielles Suchen auf der Datei)• Intelligente Suchmöglichkeiten (d.h. wie Suchmaschine oder besser)• Vorverarbeitung, Bereitstellung von vorberechneten Daten• Einheitliches Format der Texte• Viele nützliche Tools, die auf diesem Format arbeiten

U. Quasthoff Textdatenbanken 4
Archiv – Korpus – Textdatenbank
In dieser Reihenfolge:• Material einheitlicher aufbereitet.• Material besser erschlossen:
– Einfacher abzufragen– Komfortabler vorbereitet
• Trotzdem universell verwendbar
Vergleichbar:• Große Mengen an Material wünschenswert

U. Quasthoff Textdatenbanken 5
What is a corpus?
• A collection of naturally occurring language text, chosen to characterise a state or variety of language (Sinclair)
• A collection of linguistic data, either written text or a transcription of recorded data, which can be used as starting-point of linguistic description or as a means of verifying hypotheses about a language (Dictionary of linguistics and phonetics)

U. Quasthoff Textdatenbanken 6
What is not a corpus
• Lists of words • Lists of sentences produced with the purpose of creating a
corpus• Archive = “a repository of readable electronic texts not
linked in any coordinated way” (http://www.archive.org)
“The Internet Archive is building a digital library of Internet sites and other cultural artifacts in digital form. Like a paper library, we provide free access to researchers, historians, scholars, and the general public.“

U. Quasthoff Textdatenbanken 7
Corpus vs. archive
Text archive• Collection of texts in their original format
(Oxford Text Archive: http://ota.ox.ac.uk/)
Corpus• texts collected and processed in a unified,
systematic mannerBritish National Corpus: http://www.natcorp.ox.ac.uk/

U. Quasthoff Textdatenbanken 8
Web as a corpus
• The Web can be very useful source of texts• The Web is very helpful for languages other than English• Quite often there is not control on the language which is
investigated therefore filtering (if possible) is necessary

U. Quasthoff Textdatenbanken 9
Corpus annotation
• Enrichment of a corpus with various types of information• It can be done at every level:
– Word: part of speech, sense– Sentence: sentence boundaries, syntactic tree– Discourse: coreferential chains, discourse segments– Certain expressions: named entities

U. Quasthoff Textdatenbanken 10
Examples (I)
• <P><S><W POS="PRON" NUM="PL“ LEMMA="we">We</W><W POS="V" LEMMA="have">have</W><W POS="EN" LEMMA="develop">developed</W><NP><W POS="DET" LEMMA="a">a</W><W POS="A“ LEMMA="computational"> computational</W><W POS="N" NUM="SG" LEMMA="paradigm"> paradigm</W><W POS="PUNCT">,</W> ...</NP> ... </S></P>

U. Quasthoff Textdatenbanken 11
Beispiel: SGML-Dokument von TREC
<DOC> <DOCNO> WSJ870324-0001 </DOCNO> <HL> John Blair Is Near Accord To Sell Unit, Sources Say </HL> <DD> 03/24/87</DD> <SO> WALL STREET JOURNAL (J) </SO><IN> REL TENDER OFFERS, MERGERS, ACQUISITIONS (TNM) MARKETING, ADVERTISING
(MKT) TELECOMMUNICATIONS, BROADCASTING, TELEPHONE, TELEGRAPH (TEL) </IN> <DATELINE> NEW YORK </DATELINE> <TEXT> John Blair & Co. is close to an agreement to sell its TV station advertising representation operation
and program production unit to an investor group led by James H. Rosenfield, a former CBS Inc. executive, industry sources said. Industry sources put the value of the proposed acquisition at more than $100 million. ...
</TEXT> </DOC>

U. Quasthoff Textdatenbanken 12
What are the advantages of corpus annotation?• Ease of exploitation• Reusability• Multi-functionality• Explicit analyses• Once a corpus is annotated it can be used in further
research

U. Quasthoff Textdatenbanken 13
Annotation of a corpus
• Can be done: automatically, semi-automatically and manually
• Sometimes the method is automatic and then the results postprocessed
• Usually special tools are used to minimise the human error

U. Quasthoff Textdatenbanken 14
Inhalt
• Archiv – Korpus – Textdatenbank
• Korpuserstellung: Texte sammeln• Korpuserstellung: Texte aufbereiten• Textdatenbank erstellen• Korpora vergleichen und abfragen• Paralleler Text

U. Quasthoff Textdatenbanken 15
Text Collection 1
Method 1: Newspaper Text using AlltheWeb• Predefined List of Newspapers• Ordered by language• Allows search „within pages indexed last 2 hours“• Works fine for approx. 10 languagesCollection Results of Tuesday, 2006-09-12 (Raw text with noise of all kind)• DE: 21.6 MB 23.000 sentences• EN: 43.1 MB• ES: 17.1 MB• FR: 12.1 MB• IT: 8.2 MB• NL: 1.6 MB • PT: 1.1 MB
U. Quasthoff Textdatenbanken 16
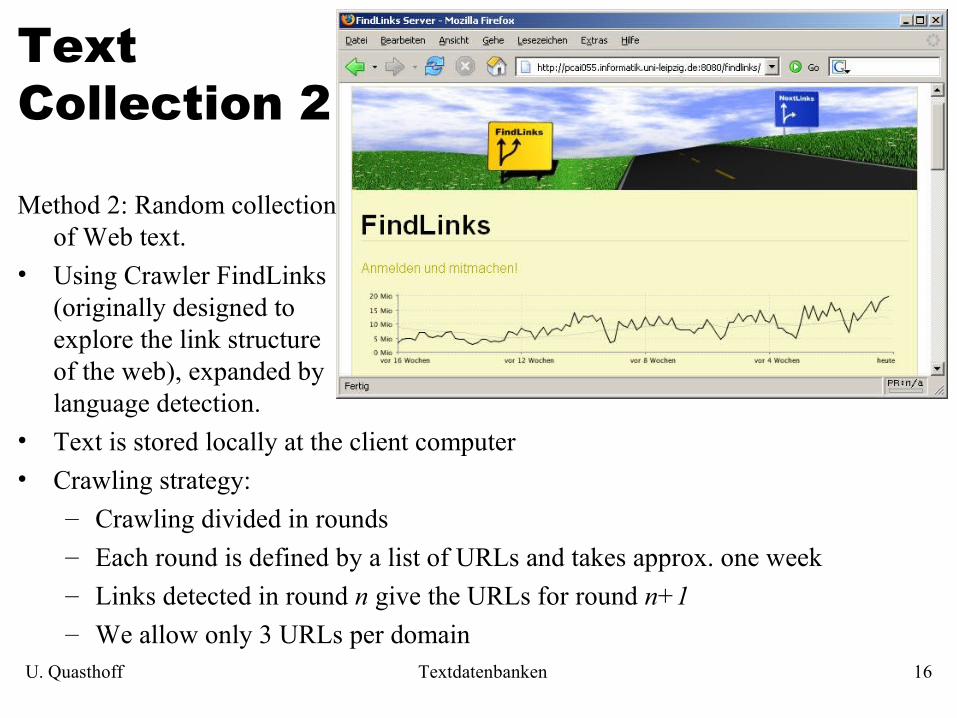
Text Collection 2
Method 2: Random collection of Web text.
• Using Crawler FindLinks (originally designed to explore the link structure of the web), expanded by language detection.
• Text is stored locally at the client computer• Crawling strategy:
– Crawling divided in rounds– Each round is defined by a list of URLs and takes approx. one week– Links detected in round n give the URLs for round n+1– We allow only 3 URLs per domain

U. Quasthoff Textdatenbanken 17
Text Collection 3http://newsisfree.com/sources/bylang• Für DE und EN etwa halb so viele
Daten wie von AlltheWeb.• Aber: Mehr Sprachen, keinerlei
Konfiguration nötig• Täglich einmal komplett (ohne
Wiederholungen von gestern) gecrawlt

U. Quasthoff Textdatenbanken 18
Wikipedias• In vielen Sprachen• Manche recht umfangreich• Einheitliches Format• Zum Download als fertige HTML-Seiten erhältlich

U. Quasthoff Textdatenbanken 19
Die größten Wikipedias IWikipedias mit mehr als 1.000.000 Artikeln (1) Englisch (English) Wikipedias mit mehr als 500.000 Artikeln(2) Deutsch - Französisch (Français) Wikipedias mit mehr als 250.000 Artikeln(5) Italienisch (Italiano) - Japanisch ( 日本語 ) - Niederländisch (Nederlands) -
Polnisch (Polski) - Portugiesisch (Português)Wikipedias mit mehr als 100.000 Artikeln(6) Chinesisch ( 中文 ) - Finnisch (Suomi) - Norwegisch (Bokmål) - Russisch
(Русский) - Schwedisch (Svenska) - Spanisch (Español)Wikipedias mit mehr als 50.000 Artikeln(12) Dänisch (Dansk) - Esperanto (Esperanto) - Hebräisch (עברית) - Indonesisch
(Bahasa Indonesia) - Katalanisch (Català) - Lombardisch (Lumbaart) - Rumänisch (Română) - Slowakisch (Slovenčina) - Tschechisch (Česky) - Türkisch (Türkçe) - Ukrainisch (Українська) - Ungarisch (Magyar)

U. Quasthoff Textdatenbanken 20
Die größten Wikipedias II
Wikipedias mit mehr als 25.000 Artikeln(10) Arabisch (العربية) - Bulgarisch (Български) - Cebuano (Cebuano) - Estnisch
(Eesti) - Koreanisch ( 한국어 ) - Kroatisch (Hrvatski) - Litauisch (Lietuvių) - Serbisch (Српски / Srpski) - Slowenisch (Slovenščina) - Telugu (తతతతతత)
Wikipedias mit mehr als 10.000 Artikeln(25) Albanisch (Shqip) - Baskisch (Euskara) - Bengali (తతతతత) - Bishnupriya
Manipuri (తతతత తతత/తతతతతతతతతతతతత తతతతతతత) - Bosnisch (Bosanski) - Bretonisch (Brezhoneg) - Einfaches Englisch (Simple English) - Galicisch (Galego) - Georgisch ( ) - Griechisch (Ελληνικά) - ქართულიHindi (ह�न��) - Ido (Ido) - Isländisch (Íslenska) - Javanisch (Basa Jawa) - Lateinisch (Latina) - Luxemburgisch (Lëtzebuergesch) - Malaiisch (Bahasa Melayu) - Neapolitanisch (Nnapulitano) - Nepal Bhasa (न�प�ल भ�ष�) - Norwegisch (Nynorsk) - Persisch (فارسی) - Serbokroatisch (Srpskohrvatski / Српскохрватски) - Sundanesisch (Basa Sunda) - Tamilisch (தம�ழ) - Thailändisch (ไทย) - Vietnamesisch (Tiếng Việt)

U. Quasthoff Textdatenbanken 21
Wikipedia Eigenschaften• Wenig Redundanz• Fachlich breit gefächert• Es existieren Richtlinien für Autoren• Fast keine 1./2. Person

U. Quasthoff Textdatenbanken 22
Projekt Gutenberg und Verwandte
Gutenberg in Zahlen • mehr als 3.000 Bücher, (über 1.000.000 Buchseiten) • ca. 20.000 Gedichte• 1.800 Märchen• 1.200 Fabeln• 3.500 Sagen• ca. 3,3 Millionen Seitenabrufe (Pageimpressions) / MonatStand: Juni 2007

U. Quasthoff Textdatenbanken 23
Dimension Zeit
Wann sind Zeitscheiben sinnvoll?• Beobachtung von zeitlichen Veränderungen• Neuheiten• Trends

U. Quasthoff Textdatenbanken 24
Inhalt
• Archiv – Korpus – Textdatenbank• Korpuserstellung: Texte sammeln
• Korpuserstellung: Texte aufbereiten• Textdatenbank erstellen• Korpora vergleichen und abfragen• Paralleler Text

U. Quasthoff Textdatenbanken 25
Sprache ermitteln I• Die Sprache eines Textes muss ermittelt bzw. verifiziert werden.• Die Aufgabe ist um so einfacher, je länger ein Text ist.• Sehr leicht für Texte mit N=200 Wörtern oder mehr:
– Benutze für jede der zu untersuchenden Sprachen die Liste der häufigsten L=50 Wörter.
– Stelle fest, welche Liste die meisten Vertreter im Text hat.– Falls es einen deutlichen Sieger gibt, ist dies die Sprache des Textes.
• Der Algorithmus funktioniert auch für kleinere N (z.B. N=10, ein Satz), wenn L entsprechend größer gewählt wird. Faustregel: N*L=10.000
Voraussetzung für diesen Algorithmus: Sprache bekannt, denn Stoppwörter müssen bereitgestellt werden.

U. Quasthoff Textdatenbanken 26
Rohtext
Unstrukturierter AS C I I -Text wird als Grundlage für die statistischen und clusterbasierten Verfahren des Text Mining benötigt.
Quellen:• Meist: HTML-Text aus dem Web (unproblematisch wegen einheitlicher und
bekannter Struktur).• Seltener: pdf-Dokumente, XML aus Satzsystemen (problematisch, da pdf-
Konverter unzuverlässig und XML-Struktur uneinheitlich).

U. Quasthoff Textdatenbanken 27
Dokumente
Text liegt in folgender Form vor:<quelle> <name>http://...</quelle>Die beiden englischen Vereine FC Chelsea ...
Dies ist nicht das ganze Originaldokument, sollte aber den Text (nicht aber die Bilder, Tabellen, Links, ...) des Originaldokuments im wesentlichen vollständig enthalten.
Nächster Schritt: Wir zerlegen den Text in die nächstkleineren Teile: Sätze. Dabei verlieren eventuelle Unvollständigkeiten auf der Dokumentebene an
Bedeutung.

U. Quasthoff Textdatenbanken 28
Korrekte Konvertierung
<quelle><name>http://www.stock-world.de/sports/Sport__425/2262889-
Chelsea_und_ManU_im_Halbfinale.html</name><name_lang>http://www.stock-world.de/sports/Sport__425/2262889-
Chelsea_und_ManU_im_Halbfinale.html</name_lang></quelle>Die beiden englischen Vereine FC Chelsea und Manchester United sind in das
Halbfinale der Champions League eingezogen. Der Londoner Club setzte sich beim FC Valencia mit 2:1 (0:1) durch und zog nach dem 1:1 aus dem Hinspiel in die Runde der letzten vier ein. ManU qualifizierte sich nach einer Gala-Vorstellung gegen den AS Rom für das Halbfinale. Der Tabellenführer der englischen Premier League feierte im Stadion Old Trafford einen 7:1 (4:0) Kantersieg gegen die Italiener.

U. Quasthoff Textdatenbanken 29
Zerlegung des Textes in Teile
0. Schritt: Entfernen von HTML-Markup o.ä.1. Schritt: Zerlegung des Textes in Sätze (s. letzte Vorlesung)2. Schritt: Zerlegung des Textes in Wörter (heute)

U. Quasthoff Textdatenbanken 30
Regeln zur Satzsegmentierung I
Zunächst einige einfache Regeln für den Satzanfang:• Sätze beginnen niemals mit Kleinbuchstaben. • Nach einer Überschrift beginnt ein neuer Satz.• Am Anfang eines Absatzes beginnt ein neuer Satz.• Groß geschriebene Artikel (wie Der, Die, Den, ...) sprechen für einen Satzanfang.• Beginnt kein neuer Absatz, so steht vor dem neuen Satz ein Satzendezeichen.

U. Quasthoff Textdatenbanken 31
Regeln zur Satzsegmentierung II
Analog gibt es einige einfache Regeln für das Satzende:• Sätze enden mit einem Satzendezeichen. Solche Satzendezeichen sind Punkt,
Fragezeichen und Ausrufezeichen. Nach dem Satzendezeichen muss zusätzlich ein white space (meist ein Leerzeichen, s.u.) stehen. Achtung, Punkte können auch an anderer Stelle stehen, z.B. nach Abkürzungen oder Zahlen.
• Vor einer Überschrift endet ein Satz.• Am Ende eines Absatzes endet ein Satz.• Überschriften sollten wie Sätze behandelt werden.

U. Quasthoff Textdatenbanken 32
Segmentierung in Wörter I
Naiver Ansatz:• Im Deutschen sind die Wörter eines Textes durch Leerzeichen getrennt (anders als
z.B. im Chinesischen). • Also zerlegen wir einfach einen Satz an den Leerzeichen (und harten
Zeilenumbrüchen) und erhalten die Wörter dieses Satzes. • Eventuell müssen wir nach der Trennung bei den Leerzeichen noch Satzzeichen
wie Punkt, Komma und Anführungszeichen entfernen.
Die Zwischenräume zwischen Wörtern werden auch als white space bezeichnet.

U. Quasthoff Textdatenbanken 33
Inhalt
• Archiv – Korpus – Textdatenbank• Korpuserstellung: Texte sammeln• Korpuserstellung: Texte aufbereiten
• Textdatenbank erstellen• Korpora vergleichen und abfragen• Paralleler Text

U. Quasthoff Textdatenbanken 34
Speicherung in einer Datenbank
In einer relationalen Datenbank sollen die anfallenden Daten gespeichert werden:
• Sätze• Wörter (mit Anzahl im Korpus)• Inverse Liste zum Nachschlagen der Wörter• Angaben zu Einzelwörtern: Grammatik, Sachgebiet, ...• Wortpaare mit Angaben, z.B. Synonyme und Kookkurenzen

U. Quasthoff Textdatenbanken 35
Speicherung der Sätze
Tabelle sentences mit s_id, sentence, source
s_id: Id des Satzes, fortlaufend nummeriertsentence: Der Volltext des Satzes als String.source: (Verweis auf) die Quelle (URL) des Satzes
Index auf: s_id
Evtl. weitere Angaben wie z.B. Sprache

U. Quasthoff Textdatenbanken 36
Angaben zu Sätzen: Tabelle sentencesTabelle sentences mit Spalten s_id und sentence Index auf s_id +------+-------------------------------------------------------------+| s_id | sentence |+------+-------------------------------------------------------------+| 3 | Leder: Vielleicht ringt Normann nur um Anerkennung. || 6 | Das können die Fachleute beraten. || 10 | Rose sei Realist, einer, der erst denkt und dann handelt. || 12 | Ich liege im Bett, im Krankenhaus, träume tief und dunkel. || 17 | Das von Seoul finanzierte Projekt ist in der Anfangsphase. || 18 | Auf dem Bus steht in kursiven Lettern: Die Wölfe kommen. || 29 | Jeder westliche Soldat wird im Irak als Besatzer angesehen. || 31 | Damit ist sie aber hoffnungslos überfordert. || 32 | Vogts Konzept trug schnell Früchte. || 36 | Erich Mielke ist an allem Schuld. || 38 | Wir haben den Willen zur aktiven Zusammenarbeit. || 49 | Die beiden Insassen blieben jedoch unverletzt. || 59 | "Das hätte uns gut getan." || 60 | Demnächst will er auf die Auer Dult. |+------+-------------------------------------------------------------+

U. Quasthoff Textdatenbanken 37
Angaben zu Sätzen: QuellenTabelle sources mit Spalten so_id, source und dateIndex auf so_id+-------+------------------------------------+------------+| so_id | source | date |+-------+------------------------------------+------------+| 1 | Berliner Zeitung vom 30.11.2001 | 2001-11-30 || 2 | Süddeutsche Zeitung vom 15.03.2002 | 2002-03-15 || 3 | Süddeutsche Zeitung vom 27.09.2001 | 2001-09-27 |+-------+------------------------------------+------------+Tabelle inv_s mit Spalten so_id und s_idIndex auf s_id+--------+------+| so_id | s_id |+--------+------+| 118823 | 1 || 118823 | 2 || 1527 | 3 |+--------+------+

U. Quasthoff Textdatenbanken 38
Angaben zu Sätzen: QuellenTabelle sources mit Spalten so_id, source und dateIndex auf so_id+-------+------------------------------------+------------+| so_id | source | date |+-------+------------------------------------+------------+| 1 | Berliner Zeitung vom 30.11.2001 | 2001-11-30 || 2 | Süddeutsche Zeitung vom 15.03.2002 | 2002-03-15 || 3 | Süddeutsche Zeitung vom 27.09.2001 | 2001-09-27 |+-------+------------------------------------+------------+Tabelle inv_s mit Spalten so_id und s_idIndex auf s_id+--------+------+| so_id | s_id |+--------+------+| 118823 | 1 || 118823 | 2 || 1527 | 3 |+--------+------+

U. Quasthoff Textdatenbanken 39
Speicherung der Wörter
Tabelle words mit w_id, word, freq
w_id: Id des Wortes, Nummerierung s. nächste Folieword: Das Wort als String.freq: Häufigkeit des Wortes, absolute Frequenz im Korpus
Index auf: w_id, word

U. Quasthoff Textdatenbanken 40
Wortgruppen
In die Wortliste aufgenommen werden auch Wortgruppen bestehend aus zwei oder mehr Wörtern, die dann in dieser Reihenfolge vorkommen müssen.
Wie werden die Anzahlen der Wörter aus Wortgruppen gezählt? Wir zählen zunächst die Einzelwörter ohne Berücksichtigung der Wortgruppen, danach noch einmal nur die Wortgruppen. Wörter in Wortgruppen werden also mehrfach gezählt.Vorteil: Das Hinzufügen oder Weglassen von Wortgruppen ändert die Anzahlen der Einzelwörter nicht!
Die häufigsten Wortgruppen+------+------------------+------+| w_id | word | freq |+------+------------------+------+| 290 | vor allem | 8017 || 604 | zum Beispiel | 2644 || 650 | unter anderem | 2544 || 668 | immer wieder | 2405 || 853 | Vor allem | 1849 || 890 | am Ende | 1753 || 923 | New York | 1681 || 1157 | Ende des | 1323 || 1182 | Gerhard Schröder | 1306 || 1205 | am Wochenende | 1275 || 1245 | DIE WELT | 1240 || 1326 | Jahre alt | 1200 || 1371 | in H÷he von | 1071 || 1399 | nach wie vor | 1068 || 1430 | immer mehr | 1066 || 1596 | ersten Mal | 981 || 1524 | in der Nacht | 957 || 1622 | kurz vor | 950 || 1640 | im Vergleich | 937 || 1627 | zu Hause | 922 || 1617 | so viel | 919 || 1669 | zwei Wochen | 896 || 1751 | dieses Jahres | 885 || 1725 | im Osten | 880 || 1752 | im Sommer | 842 || ... | ... | ... |+------+------------------+------+

U. Quasthoff Textdatenbanken 41
WortgruppenFrage: Wie findet man sinnvolle Wortgruppen? Wir brauchen statistische
Auffälligkeit und sinnvolle Grenzen.
Vorgehen zur Erzeugung sinnvoller Wortgruppen: Zu einem Korpus werden all die NB-Kollokationen als Wörter
hinzugenommen, die sowohl eine gewisse Mindestsignifikanz wie auch eine gewisse Mindestfrequenz haben. Der Vorgang wird iteriert, solange sinnvolle Dinge entstehen.
Hier: Korpus aus 2 Mill. Sätzen, Mindestanzahl und Mindestsignifikanz für die Erzeugung sind jeweils 10.

U. Quasthoff Textdatenbanken 42
Angaben zu Sätzen: Inverse Liste
Tabelle inv_w mit Spalten w_id, s_id und pos (wievieltes Wort im Satz)Index auf s_id und w_id.
+------+------+-----+| w_id | s_id | pos |+------+------+-----+| 1 | 92 | 26 || 1 | 104 | 21 || 1 | 527 | 15 || 1 | 647 | 8 || 1 | 728 | 18 |+------+------+-----+

U. Quasthoff Textdatenbanken 43
Angaben zu Wörtern: Sachgebiet
Tabelle subject_area mit Spalten w_id und subject_area Index auf w_id
+--------------------+---------+----------------+| (word) | w_is | subject_area |+--------------------+---------+----------------+| Abfangjäger | 141400 | Luftfahrt || Balustrade | 113484 | Architektur || Beinfreiheit | 131029 | Auto || Blinker | 107209 | Auto || Bodenplatte | 104364 | Bauwesen || wägen | 102481 | Technik || Windstoß | 113556 | Meteorologie || Wölbung | 126466 | Technik || Xenon | 103457 | Chemie || Ziegelstein | 111300 | Bauwesen |+--------------------+---------+----------------+Sachgebietsangaben zu Wortnummern: Die Datenbank enthält nur Wortnummern und Sachgebiete, die dünn gesetzten Wörter dienen hier nur zur Information

U. Quasthoff Textdatenbanken 44
Angaben zu Wortgruppen: SynonymeRelationen: Tabelle rel mit Spalten w1_id, group_id und type Index auf w1_id, group_id
+---------------------+---------+------------+-----+| word | w_id | group_id | type|+---------------------+---------+------------+-----+| Abstammung | 12488 | 37989 | V || Abkunft | 105235 | 37989 | v || Geblüt | 216266 | 37989 | v || Herkunft | 3223 | 37989 | v || Herkommen | 147265 | 37989 | v || Deszendenz | 1822552 | 37989 | v || Herleitung | 154039 | 37989 | v || Provenienz | 36948 | 37989 | v || Abstammungslehre | 382861 | 37990 | V || Darwinismus | 117034 | 37990 | v |Synonymgruppen: Wörter mit gleicher group_id gehören zu einer Gruppe, type gibt den Typ an (hier: „vergleiche“, Daten aus Wörterbuch) . Ein Eintrag jeder Gruppe (mit type in Großbuchstaben) dient der Benennung der Gruppe.

U. Quasthoff Textdatenbanken 45
Angaben zu Wortpaaren: KookkurrenzenNachbarschaftskookkurrenzen: Tabelle co_n mit Spalten w1_id, w2_id und sig Index auf w1_id, w2_id
+---------------+----------+----------+----------+-------------+| (word_1) | (word_2) | w1_id | w2_id | sig |+---------------+----------+----------+----------+-------------+| geschmolzenes | Blei | 202641 | 13296 | 25 || gehacktem | Blei | 848257 | 13296 | 30 || Mikrogramm | Blei | 10975 | 13296 | 36 || flüssiges | Blei | 55179 | 13296 | 36 || ... | ... | ... | ... | ... |+---------------+----------+----------+----------+-------------+Nachbarschaftskookkurrenzen. Linke Nachbarn zum Wort Nummer 13296 Blei. Dabei enthält die Datenbank nur die Wortnummern, die dünn gesetzten Wörter dienen hier nur zur Information

U. Quasthoff Textdatenbanken 46
Inhalt
• Archiv – Korpus – Textdatenbank• Korpuserstellung: Texte sammeln• Korpuserstellung: Texte aufbereiten• Textdatenbank erstellen
• Korpora vergleichen und abfragen• Paralleler Text

U. Quasthoff Textdatenbanken 47
Vorhaben: Normgrößenkorpora
Korpora• Verfügbarmachen der Korpora (in verschiedenen Normgrößen) für Nutzer
weltweit.• Wir können mit Daten und Austauschformaten Standards setzen. • Es besteht dringender Bedarf an solchen Korpora.
Größen• Anzahl von Sätzen: 100.000, 300.000, 1, 3, 10, 30 Millionen• Für jede Sprache bis zum jeweiligen Maximum• „Reinigen“ von fremdsprachlichen und nicht wohlgeformten Sätzen.• Sprachvergleich durch völlig gleiche Verarbeitung• Bereitstellung von Kookkurrenzen zur Weiterverarbeitung

U. Quasthoff Textdatenbanken 48
Normgrößenkorpora
Das geplante Vorhaben zeichnet sich aus • durch die größere Anzahl von Sprachen und den großen Umfang pro Sprache• durch das einheitliche Format der Daten für alle Sprachen und• durch die Vergleichbarkeit der Korpora auf Grund der Normgrößen• durch die zusätzliche Lieferung statistischer Daten. Kookkurrenzdaten werden
nirgendwo angeboten und sind für viele Anwender nützlich.

U. Quasthoff Textdatenbanken 49
Verfügbare Sprachen

U. Quasthoff Textdatenbanken 50
Rohtext sammeln
Rohtext zur Bearbeitung
auswählen
Satzsegmentieren
Erstes Putzen(Dubletten, LanI, Muster)
Verlustrate?
Datenbankteilw. erstellen
Zweites Putzen(SatzSim)
Verlustrate?
Sätze aus DBexportieren
SatzSim-Dateneinfügen
Normgrößen-Korpora erstellen
Abkürzungslisteerzeugen / wählen
Wortgruppenerzeugen
Rohtext DatenbankRohdatenbank Zusatz-Datenfür Korpus
POS-Taggingoder UnsuPOS
Zusatz-Datenfür Wörter
POS-Datenbankerstellen
Wörterbuch-daten, Cognates
WortSim-DatenKook. 2. Ord.
UnsuPos-TagFlexion,
MorphologieSilbentrennung
Komposita, WSI
Plausibilitäts-tests (statist.)
StatistischeAuswertung
Plausibilitätstests (Menge, Zeichen)
LaufendeFunktions-kontrolle
Datenbankenverknüpfen
Konvertieren,ArchivierenVerlustrate?
Test imBrowser
Wortliste fürLanI exportieren
StatistischesParsen
Beschreibungenaus Wikipedia
Datenbankvollst. erstellen
Eigennamen-Erkennung
Geo-Dateneinfügen
Sachgebiete usw.für Sätze
DokumentationTeil 1
DokumentationTeil 3
DokumentationTeil 2
Mengenstatistiknach Quellen
Wortnetze,Anno-Daten

U. Quasthoff Textdatenbanken 51
Elementare Abfragemöglichkeiten Abfragen für WörterStatistisch• Häufigkeit eines Wortes (im Korpus)
Analog zum Wörterbuch• Grammatikangaben, Silbentrennung,• Sachgebiet• Bedeutungsbeschreibung, evtl. mehrere Bedeutungen• Synonyme, Ober- und Unterbegriffe
Korpusbasierte Abfragen• Gesucht sind Belegsätze für ein gegebenes Wort.• Typisches gemeinsames Auftreten: Nachbarschafts- und Satzkookkurrenzen zu
einem Wort

U. Quasthoff Textdatenbanken 52
Mehr Abfragemöglichkeiten
Abfragen für WörterAnalog zum Wörterbuch• Wörter ähnlicher Bedeutung• Sachgebiet• Synonyme, Ober- und Unterbegriffe• Wörter mit ähnlicher Schreibweise (kleiner Levinshtein-Abstand)
Korpusbasierte Abfragen• Belegsätze für Kookkurrenzen• Gesucht sind Belegsätze für die verschiedenen Bedeutungen eines Wortes.• Kookkurrenzen sortiert nach den Bedeutungen des Stichwortes• Kookkurrenzen sortiert nach Wortart

U. Quasthoff Textdatenbanken 53
Abfragen für Sätze• Satz mit POS-Tags• Satz mit Syntaxbaum• Ähnliche Sätze
– nach Inhalt– nach Struktur

U. Quasthoff Textdatenbanken 54
Abfragen für ein Korpus

U. Quasthoff Textdatenbanken 55
Abfragen über mehrere Korpora
Welche Wörter kommen in Korpora verschiedener Sprachen gemeinsam vor?• Eigennamen (George W. Bush, IBM)• Internationalismen: Video, Computer• Einige Stoppwörter: in, an, ja• Falsche Freunde: war (de/en)
Welche Wörter sind verblüffend ähnlich: Cognates• Große Mindestlänge und kleiner Levinshtein-Abstand, • z.B. Präsident / presidente / president, Universtität / universidad / university

U. Quasthoff Textdatenbanken 56
Inhalt
• Archiv – Korpus – Textdatenbank• Korpuserstellung: Texte sammeln• Korpuserstellung: Texte aufbereiten• Textdatenbank erstellen• Korpora vergleichen und abfragen
• Paralleler Text

U. Quasthoff Textdatenbanken 57
Aufgabenstellung
Es gibt für viele Texte Übersetzungen, in einigen günstigen Fällen ist alles frei verfügbar.
Frage: Wie lässt sich daraus ein zweisprachiges Wörterbuch konstruieren?Oder: Wie lässt sich daraus das Wissen des Übersetzers „rekonstruieren“?
Arbeitsschritte:Gegeben ist ein (möglicherweise großes) Dokument mit seiner Übersetzung.Finde immer kleinere zusammengehörige Textteile:• Absätze• Sätze• Wörter

U. Quasthoff Textdatenbanken 58
Beispiel für Paralleltext: Vorher
EnglishAccording to our survey, 1988 sales of mineral water and soft drinks were muchhigher than in 1987, reflecting the growingpopularity of these products. Cola drinkmanufacturers in particular achieved aboveaveragegrowth rates. The higher turnoverwas largely due to an increase in the salesvolume. Employment and investment levelsalso climbed. Following a two-year transitionalperiod, the new Foodstuffs Ordinancefor Mineral Water came into effect on April1, 1988. Specifically, it contains more stringentrequirements regarding quality consistencyand purity guarantees.
FrenchQuant aux eaux minérales et aux limonades,elles rencontrent toujours plus d'adeptes. Eneffet, notre sondage fait ressortir des ventesnettement supérieures a celles de 1987, pourles boissons ~ base de cola notamment. Laprogression des chiffres d'affaires résulte engrande partie de l'accroissement du volumedes ventes. Uemploi et les investissementsont également augmenté. La nouvelle ordonnancefédérale sur les denrées alimentairesconcernant entre autres les eaux minérales,entrée en vigueur le ler avril 1988 aprés unepériode transitoire de deux ans, exige surtoutune plus grande constance dans la qualité etune garantie de la pureté.

U. Quasthoff Textdatenbanken 59
Parallel Resources• Newswire: DE-News (German-English), Hong-Kong News, Xinhua News
(Chinese-English),• Government: Canadian-Hansards (French-English), Europarl (Danish, Dutch,
English, Finnish, French, German, Greek, Italian, Portugese, Spanish, Swedish), UN Treaties (Russian, English, Arabic, . . . )
• Manuals: PHP, KDE, OpenOffice (all from OPUS, many languages)• Web pages: STRAND project (Philip Resnik)

U. Quasthoff Textdatenbanken 60
Word-Level Alignments• Given a parallel sentence pair we can link (align) words or phrases that are
translations of each other:

U. Quasthoff Textdatenbanken 61
Sentence Alignment
• If document De is translation of document Df how do we find the translation for each sentence?
• The n-th sentence in De is not necessarily the translation of the n-th sentence in document Df
• In addition to 1:1 alignments, there are also 1:0, 0:1, 1:n, and n:1 alignments
• Approximately 90% of the sentence alignments are 1:1

U. Quasthoff Textdatenbanken 62
Sentence Alignment (c’ntd)
• There are several sentence alignment algorithms:– Align (Gale & Church): Aligns sentences based on their character
length (shorter sentences tend to have shorter translations then longer sentences). Works astonishingly well
– Char-align: (Church): Aligns based on shared character sequences. Works fine for similar languages or technical domains
– K-Vec (Fung & Church): Induces a translation lexicon from the parallel texts based on the distribution of foreign-English word pairs.

U. Quasthoff Textdatenbanken 63
Cognates
Definitions of cognates on the Web:• Words from two languages that are similar in spelling and
meaning or sound and meaning • Words that are similar in two or more languages as a result
of common descent. • Cognates are words from different languages which are
related historically, eg English bath - German bad or English yoke - Hindi yoga. Beware FalseFriends however.

U. Quasthoff Textdatenbanken 64
Extraction of cognates
• string comparison on the level of types in two parallel segments: Perl module String::Approx (Hietanainen 2002)
• high precision → cognates override bilingual lexicon
informatika informaticsinfrastrukture infrastructureinstrumentacija instrumentationintegracija integratingintegrala integraliterativen iterativekarakteristik characteristicskaskade cascadekoeficient coefficientkomponenta componentkoncentracijo concentrationkoncept conceptkonstanta constantkonvergenca convergencekoordinat coordinateslinearne linearlogisticxna logisticmateriali materialsmatrika Matrix

U. Quasthoff Textdatenbanken 65
Soundex: Ähnlich klingende WörterKodierungsschema für Buchstaben1: B P F V2: C S K G J Q X Z3: D T 4: L 5: M N 6: RRegeln:1. Ersten Buchstaben übernehmen2. A E I O U W Y H löschen3. Restliche Buchstaben entsprechend Kodierungsschema ersetzen4. Dopplungen löschen5. Auf 4 Zeichen kürzen, ggf. mit Nullen auffüllen.Varianten: Reihenfolge 1,3,4,2,5
Schritt 5 weglassen (z.B. bei MySQL)

U. Quasthoff Textdatenbanken 66
Trans-co-occurrencesTranslingual co-occurrences
‘normal‘ co-occurrences:• Calculaton performed on sentence basis• Co-occurrents can be found frequently together in sentences
Trans-co-occurrences:• Calculaton performed on bilingual sentence pairs• Co-occurrents can be found frequently together in bilingual sentence pairs• Hypothesis: significant co-occurrences between words of different languages (=
trans-co-occurrences) are translation equivalents

U. Quasthoff Textdatenbanken 67
Example: Gesellschaft@de society@enDie@de drogenfreie@de Gesellschaft@de wird@de es@de aber@de nie@de geben@de .@de But@en
there@en never@en will@en be@en a@en drug-free@en society@en .@en Unsere@de Gesellschaft@de neigt@de leider@de dazu@de ,@de Gesetze@de zu@de umgehen@de .@de
Unfortunately@en ,@en our@en society@en is@en inclined@en to@en skirt@en round@en the@en law@en .@en
Zum@de Glück@de kommt@de das@de in@de einer@de demokratischen@de Gesellschaft@de selten@de vor@de .@de Fortunately@en ,@en in@en a@en democratic@en society@en this@en is@en rare@en .@en
Herr@de Präsident@de !@de Wir@de leben@de in@de einer@de paradoxen@de Gesellschaft@de .@de Mr@en President@en ,@en we@en live@en in@en a@en paradoxical@en society@en .@en
Ich@de sprach@de vom@de Paradoxon@de unserer@de Gesellschaft@de .@de I@en mentioned@en what@en is@en paradoxical@en in@en society@en .@en
Zeit@de ist@de Macht@de in@de unserer@de Gesellschaft@de .@de Time@en is@en power@en in@en our@en society@en .@en .
In all sentence pairs, Gesellschaft@de and society@en occur together.

U. Quasthoff Textdatenbanken 68
Example: top-ranked trans-co-occurrences Gesellschaft: society@en (12082), social@en (342), our@en (274), in@en (237), societies@en (226),
Society@en (187), women@en (183), as@en a@en whole@en (182), of@en our@en (168), open@en society@en (165), democratic@en (159), company@en (137), modern@en (134), children@en (120), values@en (120), economy@en (119), of@en a@en (111), knowledge-based@en (110), European@en (105), civil@en society@en (102)
society: Gesellschaft@de (12082), unserer@de (466), einer@de (379), gesellschaftlichen@de (328), Wissensgesellschaft@de (312), Menschen@de (233), gesellschaftliche@de (219), Frauen@de (213), Zivilgesellschaft@de (179), Gesellschaften@de (173), Informationsgesellschaft@de (161), modernen@de (157), sozialen@de (155), Wirtschaft@de (132), Leben@de (119), Familie@de (118), Gesellschaftsmodell@de (108), demokratischen@de (108), soziale@de (98), Schichten@de (97)
kaum: hardly@en (825), scarcely@en (470), little@en (362), barely@en (278), hardly@en any@en (254), very@en little@en (186), almost@en (88), difficult@en (68), unlikely@en (63), virtually@en (53), scarcely@en any@en (51), impossible@en (47), or@en no@en (40), there@en is@en (38), hardly@en ever@en (37), any@en (32), hardly@en anything@en (32), surprising@en (31), hardly@en a@en (29), hard@en (28)
hardly: kaum@de (825), wohl@de kaum@de (138), schwerlich@de (64), nicht@de (51), verwunderlich@de (43), kann@de (37), wenig@de (37), wundern@de (25), man@de (21), dürfte@de (17), gar@de nicht@de (17), auch@de nicht@de (16), gerade@de (16), überrascht@de (15), fast@de (14), überraschen@de (14), praktisch@de (13), ist@de (12), schlecht@de (12), verwundern@de (12)

U. Quasthoff Textdatenbanken 69
Alignment: Example 1
Red Words: No alignmentBlue Arrows: ErrorsArrow Index: rank in trans-co-occurrences
Die Landwirtschaft stellt nur 5,5 % der Arbeitsplätze der Union .
Agriculture only provides 5.5 % of employment in (the Union) .
1 21113 13 3
2
Die Landwirtschaft stellt nur 5,5 % der Arbeitsplätze der Union .
Agriculture only provides 5.5 % of employment in (the Union) .
1 1 15 4 2 1

U. Quasthoff Textdatenbanken 70
Alignment: Example 2
Grey Arrows: Multiple alignments for frequent words.
Indem wir den Mitgliedstaaten für die Umsetzung der Richtlinie kein spezifisches Datum setzen ,
By not setting a specific date (for the) Member States (to implement) the directive
sondern ihnen einen Zeitraum von drei Monaten nach Inkrafttreten der Richtlinie zugestehen ,
and instead giving them a period of three months after its (entry into force) ,
führen wir eine Flexibilitätsklausel ein ,
we are introducing a flexibility clause
die eine unverzügliche Umsetzung gewährleistet .
which ensures that the directive will be implemented without delay .
1 1 12
1 7 14
1 1 15
1 1
1
1
1 1 1 1 1 1,2,3
1
1
4
1 1
11
121
1 1
1 1 1
4 445