10 critical mistakes in data analysis
TRANSCRIPT

10 основных ошибок,которые нельзя допускать
в анализе данных
Константин ОбуховData Scientist в компании CleverDATA
Презентация для ИТ-лекторияНИУ ВШЭ
02.03.2015

Немного о CleverDATA
Развитие бизнеса на международном рынке с 2012 года
Входит в тройку
лидеров российских ИТ компаний
43 подразделения в России и за
рубежом
Более 5500 сотрудников
100 тыс.проектов для 10 тыс.заказчиков
Инновационная платформа
управления данными
«Биржа» данных
Облачный сервис
Открытые технологии
Создана в 2014 г.
Фокус на работе с «Big Data»
Собственные центры разработки
Партнерство с мировыми лидерами
и научными институтами
Центр экспертизы по
технологиям Big Data и
Digital Marketing

Мы знаем все о больших данных и их обработке
ВЫСОКАЯ СКОРОСТЬБОЛЬШОЙ ОБЪЕМЗНАЧИТЕЛЬНАЯ ВАРИАТИВНОСТЬ
Web логи
Финансовые транзакции
Социальные сети
Web контент
Машинные данные
Открытые данные
Hadoop
MPP (Vertica, Exadata, Greenplum,
Teradata)
NoSQL (Key-Value, Document-
oriented, Column-based, Graph-
oriented)
In-memory Data Grids, Calculation
Grids
Data Mining
Machine Learning / Statistics / Natural
Language Processing
Event-Stream Processing
Ценность данных в том, как вы их
анализируете и применяете для развития
своего бизнеса
Понимание клиента и его поведения
Информационная безопасность
Управление рисками
Повышение операционной эффективности
“Потенциал Big Data раскрывается в полной мере при взаимодействии с другими данными корпорации.” Билл Фрэнкс.

Задача
• В городе проживает миллион человек• 200 из них заболели неизвестным вирусом• Изобретен тест на наличие болезни с точностью 97%
Вопрос:
Какая вероятность, что вы заболели, если тест дал положительный результат?
3) 0.64%
0.64%1) 97%2) 32.14%

Решение
1 000 000
200
999 800
194
6
29 994
969 806
Больные
Здоровые
Тест положительный
Тест отрицательный
Тест отрицательный
Тест положительный
0.64%

Теорема Байеса

Ошибки I и II рода
Наличие болезни
Ре
зул
ьтат
тест
а
Больной Здоровый
По
ло
жи
тел
ьны
й 194
TruePositives
29 994
False Positives
Отр
иц
ател
ьны
й 6
FalseNegatives
969 806
TrueNegatives
Ошибка I рода
Ошибка II рода


Априорные и апостериорные вероятности
Prior PosteriorТест

Снова теорема Байеса
Необходимо делать поправку на априорные вероятности
Результат наблюденийправдоподобие

Пример с Amazon
Likelihood
Prior

10 основных ошибок, которые нельзя допускать в анализе данных
1. Опускать поправку на априорные распределения

Богатый район

Где логика?
1. У бедных нет телефона2. У бедных нет машины
Фактически нет данных из района для
бедных
Данные по богатым
Данные по бедным

Трумэн

Вот это поворот
1. У бедных нет телефона2. Бедные голосуют за Трумэна
Фактически нет данных по бедным
избирателям
Голоса за Дьюипо обзвону
Голоса за Трумэнапо обзвону

10 основных ошибок, которые нельзя допускать в анализе данных
2. Использовать для анализа неслучайную выборку

Bias Sample
Выборка 1 Выборка
2
Выборка 3
Все данные
• Данные для анализа нужно выбирать случайно из генеральной совокупности
• Проверять гипотезу нужно на контрольных данных – тоже выбранных случайно из всего множества

Как убедиться в том, что выборка случайная?
Dataset 1: { f1 ; f2 ; f3 ;…; fn } R(M x N)
Dataset 2: { f1 ; f2 ; f3 ;…; fn } R(M x N)
Признаки в обоих выборках должны принадлежать одному распределению
хорошо плохо

Как посчитать функцию распределения
Закон Больших Чисел:
X = rnorm(100,10,1)Y = rnorm(100,10,2)
X = rnorm(100,10,1)Y = rnorm(100,9.9,1.1)

Количественная оценка степени различия
Критерий Колмогорова - Смирнова

Чем отличаются эти данные?x y
1 -1.0 0.02 -0.8 0.63 -0.6 0.84 -0.4 0.95 -0.2 1.06 0.0 1.07 0.2 1.08 0.4 0.99 0.6 0.810 0.8 0.611 1.0 0.012 -1.0 0.013 -0.8 -0.614 -0.6 -0.815 -0.4 -0.916 -0.2 -1.017 0.0 -1.018 0.2 -1.019 0.4 -0.920 0.6 -0.821 0.8 -0.622 1.0 0.0
x y
1 -1.0 -1.02 -0.8 -0.83 -0.6 -0.64 -0.4 -0.45 -0.2 -0.26 0.0 0.07 0.2 0.28 0.4 0.49 0.6 0.610 0.8 0.811 1.0 1.012 -1.0 1.013 -0.8 0.814 -0.6 0.615 -0.4 0.416 -0.2 0.217 0.0 0.018 0.2 -0.219 0.4 -0.420 0.6 -0.621 0.8 -0.822 1.0 -1.0
x y
1 -3.1 0.02 -2.8 -0.33 -2.5 -0.54 -2.1 -0.85 -1.8 -1.06 -1.5 -1.07 -1.2 -0.98 -0.9 -0.89 -0.6 -0.610 -0.3 -0.311 0.0 0.012 0.3 0.313 0.6 0.614 0.9 0.815 1.2 1.016 1.5 1.017 1.8 0.918 2.1 0.819 2.5 0.620 2.8 0.321 3.1 0.022 1.0 -1.0

Вот чем
Графики наилучшим образом представляют данные

10 основных ошибок, которые нельзя допускать в анализе данных
3. Неверная визуализация




Как не следует строить графики

Как вообще не следует строить графики

Выборы представителей Великобритании в Европарламент 2009 г.

Почему круговые диаграммы это зло
Невозможно сравнивать абсолютные значения

Восприимчивость к размеру
Почему круговые диаграммы это зло

Невозможно анализировать комбинированные значения
Почему круговые диаграммы это зло

10 основных ошибок, которые нельзя допускать в анализе данных
4. Считать корреляцию причинной связью
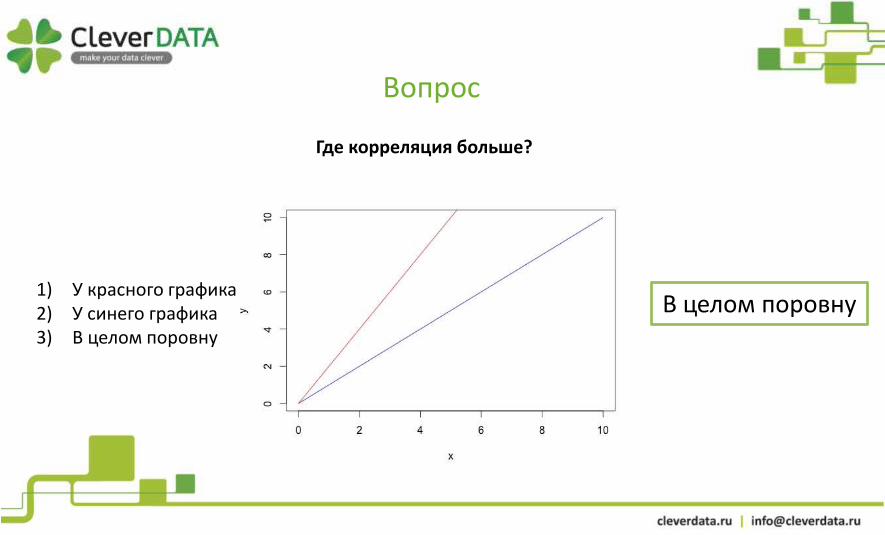
Вопрос
Где корреляция больше?
1) У красного графика2) У синего графика3) В целом поровну
В целом поровну

Что такое корреляция

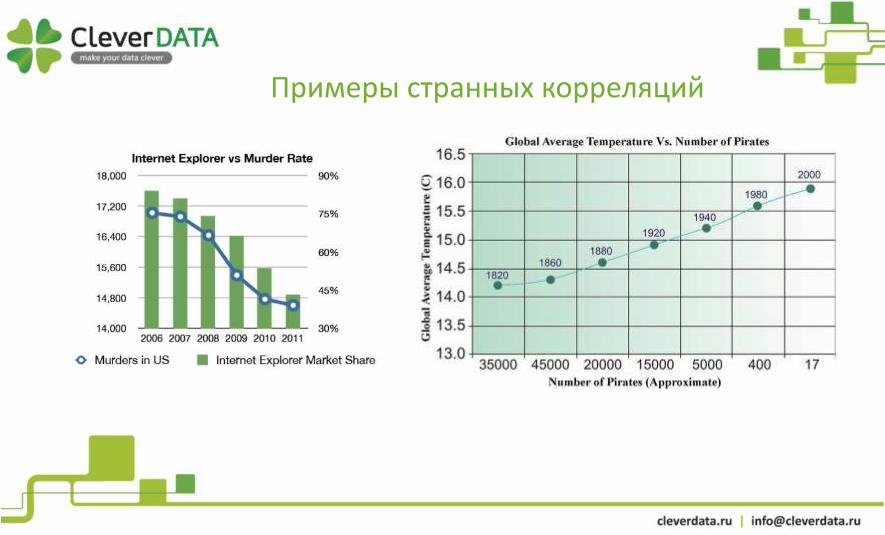
Примеры странных корреляций

Корреляция как следствие третьего фактора
Корреляция не подразумевает причинной связи

Яйцо

Как узнать, где причина, а где следствие?
Тест Грэнджера на причинностьКоличество куриц в момент t
Количество яиц в момент времени t
Гипотеза 1: x не является причиной y
Гипотеза 2: y не является причиной x

Проверка на данных
Яйцо появилось раньше

Машинное обучение
Машинное обучение изучает методы построения моделей
и алгоритмов, способных обучаться на данных
Данные Алгоритм Модель

Supervised Learning
• Необходимо задать обучающую выборку –набор данных признаки : результат
• Алгоритм применяется для распознавания неизвестных объектов
Классификация Регрессия

Unsupervised Learning
• Для обучения нужна выборка только признаков
• Алгоритм применяется для обнаружения взаимосвязей и закономерностей между объектами
Кластеризация Поиск ассоциативных правил

10 основных ошибок, которые нельзя допускать в анализе данных
5. Неверно выбранная целевая переменная

Прогнозирование оттока клиентов
• Необходимо выявить клиентов, которые с большой вероятностью прекратят взаимодействие с компанией
• Предиктивная модель обучается на уже ушедших клиентах, ищет признаки оттока
• Каждому клиенту сопоставляется вероятность уйти в отток через какой-то промежуток времени

«Идеальная» модель оттока
Точность прогнозирования составляет 98.2%
Экономическая эффективность отсутствует

Моделирование отклика на предложение
Подход «от продукта» Подход «от клиента»

Матрица отклика
Клиент ID
Продукт А Продукт B Продукт C Продукт D
SMS Звонок E-mail SMS Звонок E-mail SMS Звонок E-mail
1626 60% 80% 45% 20% 30% 10% 15% 25% 70%
2832 50% 60% 35% 80% 90% 85% 55% 60% 60%
2515 75% 80% 50% 10% 15% 5% 60% 70% 50%
9010 20% 25% 25% 10% 30% 10% 85% 90% 40%
7812 30% 35% 30% 50% 60% 55% 90% 95% 20%
3511 60% 50% 60% 10% 30% 20% 40% 60% 80%
6266 55% 65% 35% 25% 25% 15% 60% 75% 25%
1842 25% 35% 20% 50% 50% 45% 55% 50% 85%

Отклик и прибыль
Клиент ID
Кампании
Кампания 1 Кампания 2 Кампания 3
1626 100р.60%
120р.35%
80р.40%
2832 50р.60%
30р.50%
35р.60%
2515 80р.60%
130р.70%
100р.20%
9010 60р.35%
25р.90%
40р.60%
7812 80р.55%
110р.60%
115р.40%
3511 125р.65%
50р.50%
140р.70%
При построении модели необходимо учитывать условия, в которых ей
придется работать
Высокая вероятность откликане гарантирует высокую эффективность

10 основных ошибок, которые нельзя допускать в анализе данных
6. Допускать переобучение модели

Регрессионная задача
Аппроксимация полиномом степени М
Минимизация среднеквадратичной ошибки

Точность растет при увеличении М
Переобучение
У переобученной модели очень низкая точность на тестовой выборке

Задача – минимизация ошибки на тесте
Переобучение

Переобучение уменьшается при увеличении объема выборки
Чем больше данных, тем сложнее модель можно построить

Еще раз теорема Байеса
Априорная вероятность(до наблюдения)
Эффект наблюдаемых данных
Апостериорная вероятность(после наблюдения)
Функция правдоподобия описывает насколько вероятны наблюдаемые данные при различных значениях весов w

Регуляризация для предотвращения переобучения модели

Как подобрать нужные параметры модели
Тюнинг модели заключается в подборе таких параметров λ и M, при которых ошибка на тестовой выборке
минимальная – кросс-валидация

7. Оставить выбросы и шумы в данных
10 основных ошибок, которые нельзя допускать в анализе данных

X16,2426,7212,7634,6717,8223,7323,4672,1521,2393,2410,123,16
26,7225,5127,1124,1744,2427,8851,2380,221,41
17,13
Какая величина наилучшим образом описывает эти данные?
Среднее 30,95
Медиана 24,84
X93,2480,2272,1551,2344,2434,6727,8827,1126,7226,7225,5124,1723,7323,4621,2317,8217,1316,2412,7610,123,161,41
3QR
MED
1QR

Задача поиска аномалий
Аномалии – это те события или наблюдения, которые не соответствуютожидаемому паттерну других событий в данных
• Intrusion detection• Fraud detection• Fault detection• System monitoring• Event detection• Data preprocessing
Очистка от шумов позволяет значительно увеличить точность предиктивной модели

Задача прогнозирования сбоев в работе различных систем

4 этапа построения модели
1. Необходимо правильно обработать данные• Модель структурирования потоковых данных позволяет извлечь из
машинных данных важные признаки• Без обработки данных увеличивается погрешность прогнозирования
Паттерн сбоя
До обработки После обработки

4 этапа построения модели
2. Необходимо найти сбои в исторических данных
• Для того, чтобы прогнозировать сбои в будущем, необходимо «обучиться» на прошлых ошибках.
• Вероятностная модель определяет сбои как значимые отклонения от нормального состояния работы систем (one class SVM)
Детектирование значимых отклонений от нормы

Подход к решению3. Выявление значимых признаков сбоев
• Выявив сбои, необходимо автоматически найти причины их возникновения
• Методы корреляционного анализа позволяют найти причины прошедших сбоев
Корреляционная матица признаков сбоев

Подход к решению4. Построение предиктивной модели
Прошлые наблюдения Будущая вероятность сбоя
Триггеры (предикторы) ошибок
• Модель обучается на исторических данных, сопоставляя прошлым наблюдениям будущую вероятность сбоя в различных временных интервалах
• В реальном времени модель отслеживает показатели систем и триггеры ошибок, рассчитывая будущую вероятность сбоя

8. Неверно разделить исследование и оптимизацию
10 основных ошибок, которые нельзя допускать в анализе данных


Снова ошибки I и II рода
Реальность
Гип
оте
за
Верная Неверная
Вер
на True
PositivesFalse
Positives
Не
вер
на
FalseNegatives
TrueNegatives
Exploration Error
Exploitation Error

Где же грань?
Exploration
Exploitation
t
Исследование
Оптимизация

9. Делать поспешные выводы
10 основных ошибок, которые нельзя допускать в анализе данных

Insight не означает конец исследования
Exploration
Exploitation
t
Исследование
Оптимизация
Insight

Почему нельзя делать поспешные выводы

Основные этапы построения предиктивных моделей
Data Preprocessing
Feature Engineering
FeatureSelection
Machine Learning
Back Testing
• Необходимая обработка данных: очистка шумов, выбросов. Приведение данных к нормальному виду
• Генерация факторов и признаков в модели. Поиск скрытых паттернов
• Выбор предикторов, выявление значимых закономерностей
• Построение модели алгоритмами машинного обучения, тюнинг модели
• Тестирование модели на реальных данных

10. Выбор неправильного инструмента для анализа
10 основных ошибок, которые нельзя допускать в анализе данных

Какой инструмент лучше?
Сл
ож
но
сть
исп
ол
ьзо
ван
ия
Возможности в анализе данных

10 основных ошибок, которые нельзя допускать в анализе данных
1. Опускать поправку на априорные распределения
2. Использовать для анализа неслучайную выборку
3. Неверная визуализация
4. Считать корреляцию причинной связью
5. Неверно выбранная целевая переменная
6. Допускать переобучение модели
7. Оставить выбросы и шумы в данных
8. Неверно разделить исследование и оптимизацию
9. Делать поспешные выводы
10. Выбор неправильного инструмента для анализа
Вопросы?

Спасибо за внимание!
