1 the compressor: concurrent, incremental and parallel compaction. haim kermany and erez petrank...
Post on 19-Dec-2015
240 views
TRANSCRIPT

1
The Compressor: Concurrent, Incremental and Parallel Compaction.
Haim Kermany and Erez Petrank
Technion – Israel Institute of Technology

2
The Compressor
The first compactor with one heap pass. Fully compacts all the objects in the heap. Preserves the order of the objects. Low space overhead. A parallel version and a concurrent version.

3
Garbage collection
Automatic memory management. User allocates objects Memory manager reclaims objects which “are not
needed anymore”. In practice: unreachable from roots.

4
Modern Platforms and Requirements
High performance and low pauses. SMP and Multicore platforms:
Use parallel collectors for highest efficiency Use concurrent collectors for short pauses.
Parallel (STW)High throughput
Concurrent &Parallel
short Pauses
t
t

5
Main Streams in GC Mark and Sweep
Trace objects. Go over the heap and reclaim the unmarked objects.
Reference Counting Keep the number of pointers to each object. When an object counter reaches zero, reclaim the object.
Copying Divide the heap into two spaces. Copy all the objects from one space to the other.

6
Compaction - Motivation
M&S and RC face the problem of fragmentation. Fragmentation – unused space between live objects
due to repeated allocation and reclaiming. Allocation efficiency decreases. May fail to allocate large objects. Cache behavior may be harmed.
Compaction – move all the live objects to one place in the heap. Best practice: keep order of objects for best locality.

7
Traditional Compaction Go over the heap and write the new location of
every object in its header (install a forwarding pointer).
Update all the pointers in the roots and the heap. Move the objects
Stack
Three Heap Passes

8
Agenda
Introduction: garbage collection, servers, compaction.
The Compressor: Basic technique
Obtain compaction with a single heap pass. The parallel version. The concurrent version.
Measurements Related Work. Conclusion

9
Compressor - Overview
Compute new locations of objects Fix root pointers Move objects + fix their pointers
Stack
One Heap Passplus one pass over the (small) mark-bits table.

10
Compute new locations
Computing new locations and saving this info succinctly: Heap partitioned to blocks (typically, 512 bytes). Start by computing and saving for each block the total
size of objects preceding that block (the offset vector).
10 2 3 4 5 6 7 8 9
1000 1100 1200 1300 1400 1500 1600 1700
0 50 90 125 200 275 325 350Offset vector
The Heap
Addresses

11
10 2 3 4 5 6 7 8 9
0 50 90 125 200 275 325 350
1000 1100 1200 1300 1400 1500 1600 1700
The Heap
Addresses
Offset vectorMarkbit vector
Computing A New Address
Assume a markbit vector which reflect the heap: First and the last bits of each object are set.
A new location of an object is computed from the markbit and the offset vectors: for object 5, at the 4th block the new location is:
1000 + 125 +50 = 1175.

12
Computing Offset Vector
Computed from the markbit vector. Does not require a heap pass
10 2 3 4 5 6 7 8 9
0 50 90 125 200 275 325 350
1000 1100 1200 1300 1400 1500 1600 1700
The Heap
Addresses
Offset vectorMarkbit vector

13
Properties
Single heap pass.Plus one pass over the markbit vector.
Small space overhead. Does not need a forwarding pointer.
Single threaded.
Stop-the-world.
Next: A parallel stop-the-world (STW) version. A concurrent version.

14
Parallelization – First Try
Had we divided the heap to two spaces… The application uses only one space. The Compressor compacts the objects from
one space (from-space) to the other (to-Space). Advantage: objects can be moved independently. Problem: space overhead.

15
Eliminating Space Overhead
Initially, to-space is not mapped to physical pages. It is a virtual address space.
For every (virtual) page in to-space: (a parallel loop) Map the virtual page to physical memory. Move the corresponding from-space objects and fix the
pointers. Unmap the relevant pages in from-space.
0 1 2 3 4 6 7 8 95 4 6 7 8 95
roots
0 2 31
0 1 2 3 4 5 6 7 8 9

16
Properties
All virtues of basic Compressor: Single heap pass, small space overhead.
Easy parallelization: each to-space page can be handled independently.
Stop-The-World.

17
What about Concurrency?
Problem: two copies appear when moving objects during application run.
Sync. problems between compaction and application.
Solution (Baker style): Application can only access moved objects (in to-space).

18
Concurrent Version Stop application Fix roots to new locations in to-space. Read-protect to-space and let application resume. When application touches a to-space page a trap is sprung. Trap handler moves relevant objects into the page and
unprotect the page.
0 1 2 3 4 6 7 8 95 4 6 7 8 95
roots

19
Implementation & Measurements
Implementation on the Jikes RVM. Compressor added to a simple modification of the Jikes
mark-sweep collector (main modification: allocation via local-caches). Compressor invoked once every 10 collections.
Benchmarks: SPECjbb, Dacapo, SPECjvm98. In the talk we concentrate on SPECjbb
Compared collectors: no compaction algorithms on the Jikes RVM. Some comparison to mark-sweep (MS) and an Appel
Generational collector (GenMS).

20
SPECjbb Throughput
7000
9000
11000
13000
15000
17000
1 2 3 4 5 6 7 8
Number of WareHouses
Thro
ugh
pu
t (o
ps)
CON
STW
GenMS
MS
CON = Concurrent Compressor,
STW = Parallel Compressor
21
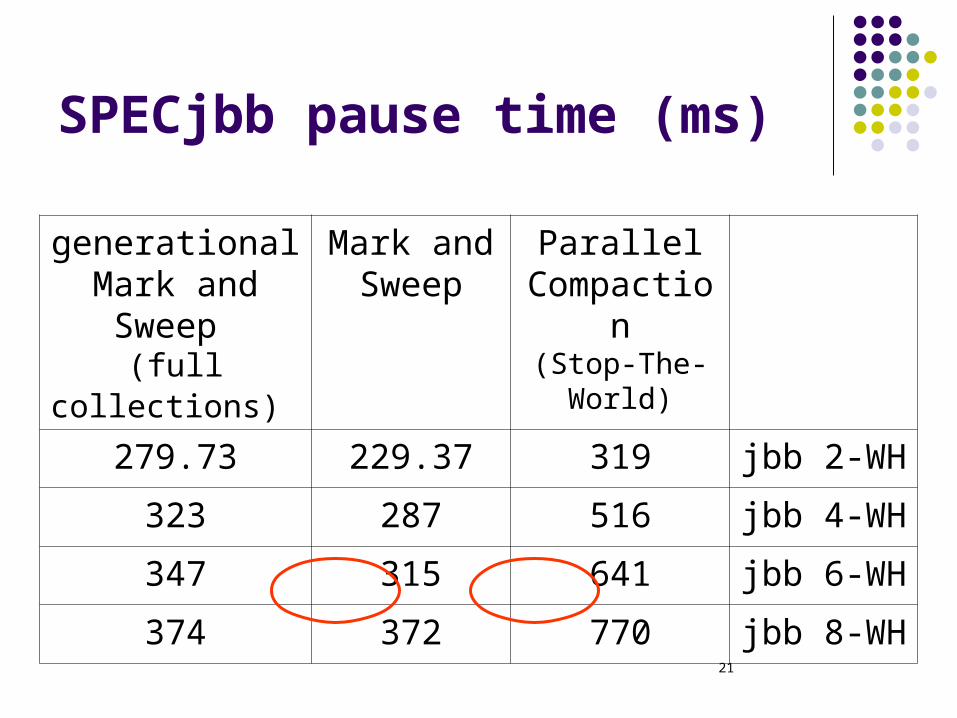
SPECjbb pause time (ms)
Parallel Compaction
(Stop-The-World)
Mark and Sweep
generational Mark and Sweep
(full collections)
jbb 2-WH319229.37279.73
jbb 4-WH516287323
jbb 6-WH641315347
jbb 8-WH770372374
22
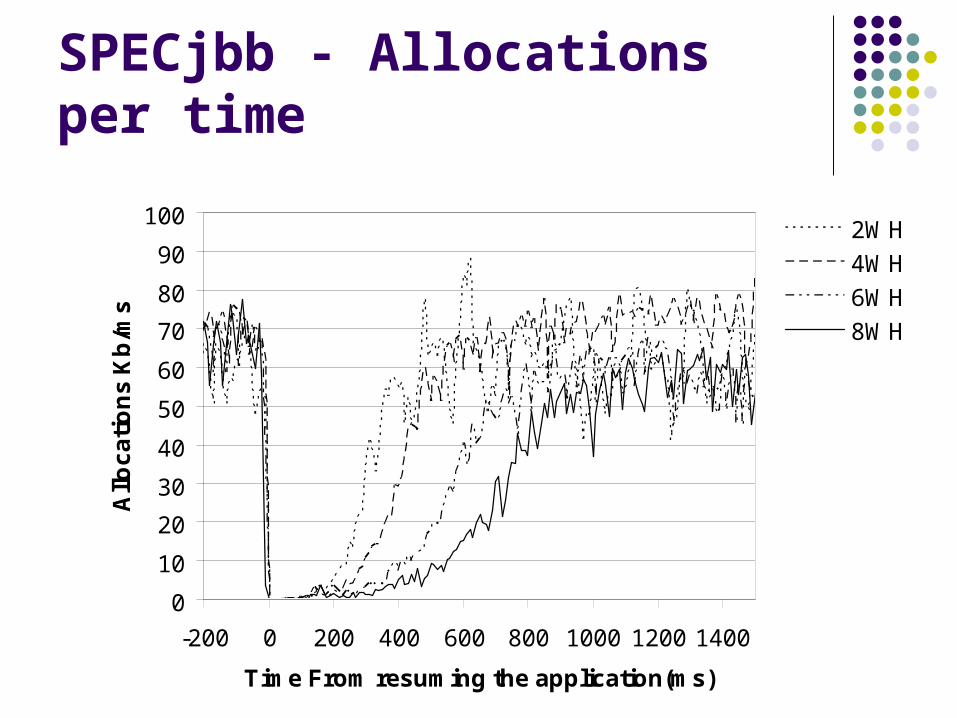
SPECjbb - Allocations per time
0
10
20
30
40
50
60
70
80
90
100
-200 0 200 400 600 800 1000 1200 1400
Time From resuming the application(ms)
Allo
ca
tio
ns
Kb
/ms
2WH
4WH
6WH
8WH

23
Dacapo - Allocations per time
0
5
10
15
20
25
30
-20 -10 0 10 20 30 40 50 60 70
Time from resuming the application (ms)
Allo
catio
n r
ate
jython
pmd
ps
xalan

24
Previous Work on Compaction
Early works: Two-finger, Lisp2, and the threaded algorithm [Jonkers and Morris] are single threaded and therefore create a large pause time.
[Flood et al. 2001] first parallel compaction algorithms. But has 3 heap passes and creates several dense areas.
[Abuaiadh et al. 2004] Parallel with two heap passes, not concurrent.
[Ossia et al. 2004] execute the pointer fix-up part concurrently.

25
Related Work
Numerous concurrent and parallel garbage collectors. Copying collectors [Cheney 70] compact objects
during the collection but require a large space overhead and do not retain objects order.
Savings in space overhead for copying collectors [Sachindran and Moss 2004]
[Bacon et al. 2003, Click et al. 2005] propose an incremental compaction. But it uses a read barrier, and does not keep the order of objects.
26
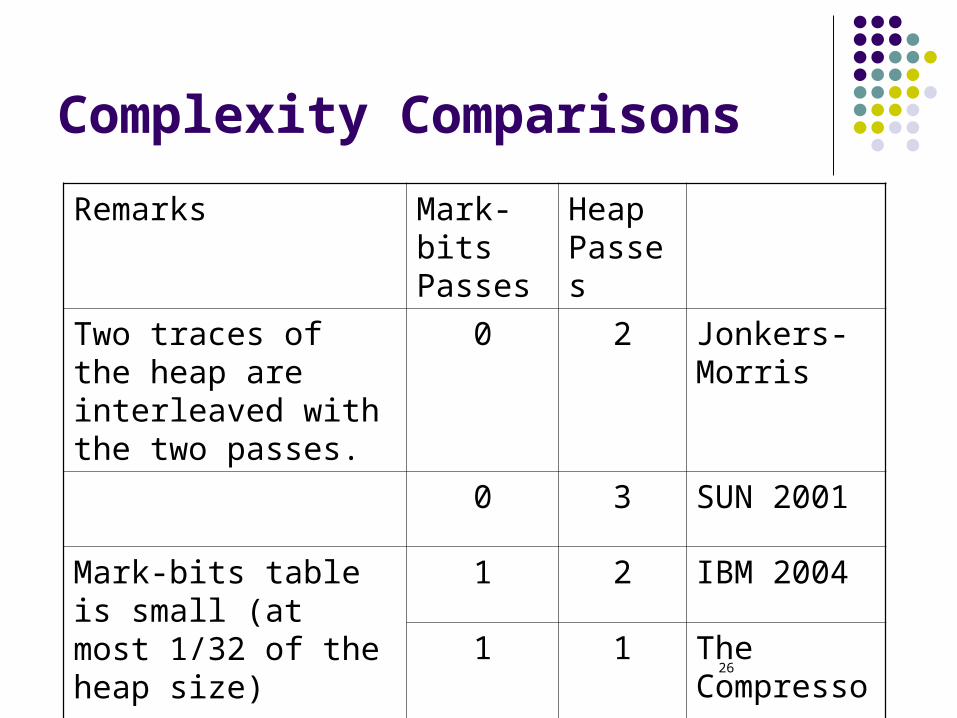
Complexity Comparisons
Heap Passes
Mark-bits Passes
Remarks
Jonkers-Morris
20Two traces of the heap are interleaved with the two passes.
SUN 200130
IBM 200421Mark-bits table is small (at most 1/32 of the heap size) The
Compressor11

27
Conclusion
The Compressor: The first compactor that passes over the
heap only once. Plus one pass over the mark-bits vector.
Fully compacts all the objects in the heap. Preserves the order of the objects. Low space overhead. Uses memory services to obtain parallelism. Uses traps to obtain concurrency.

28
Questions