1 statistics for the behavioral sciences (5 th ed.) gravetter & wallnau chapter 10 the t test...
TRANSCRIPT

1
Statistics for the Behavioral Sciences (5 th ed.) Gravetter & Wallnau
Chapter 10
The t Test for Two Independent Samples
University of GuelphPsychology 3320 — Dr. K. Hennig
Winter 2003 Term

2
Once or Twice?Within Subjects Design
• If the subjects are used more than once or matched, this design is called aWithin Subjects Design or a Repeated Measures Design.
Advantages of Repeated Measures Designs:• They take fewer participants. • They typically have more statistical power (like a matched t-test). • Disadvantages of Repeated Measures Designs:• You have to worry about practice effects and carryover effects. We
will return to this.

3

4
Between vs. within designs
• Between-subjects– comparison of separate groups (men cf. women;
ethnicity1 cf. ethnicity2; married cf. unmarried); or matched groups
• between-subjects/repeated measures – two data sets from the same sample (patients before
therapy cf. after; drug use Grade 9 cf. grade 11; time1 cf. time2)

5
Figure 10-2 (p. 310)Do the achievement scores for children taught by method A differ from the scores for children taught by method B? In statistical terms, are the two population means the same or different? Because neither of the two population means is known, it will be necessary to take two samples, one from each population. The first sample will provide information about the mean for the first population, and the second sample will provide information about the second population.

7
Logic and procedure:t statistic for independent-measure design
• H0: 1 - 2 = 0
• H1: 1 - 2 <> 0
• overall t formula:
• the independent-measures t uses the difference
Ms
Mt
errorstandardestimated
meanpopulationmeansample
)(
)()(
errorstandardestimated
differencemeanpopulationdifferencemeansample
21
2121
MMs
MM
t

8
Reminder• The means of two groups are compared relative
to a sample distribution of:– means (“is M1 different from the population ?”)
– sample variances (proved mean all s2 = 2)
– mean differences (“is the difference between two sample means, ΔM1-M2, different?”)
Sample 1 (M= ?)
Sample n (M = ?)..
1 2 3 4 5
2
4
6
8
12
n
SSs

9

10
t-statistic (contd.)
• (Review) standard error: measures how accurately the sample statistic represents the population parameter– single sample = the amount of error expected for a sample
mean– independent measures formula = amount of error expected
when you use the mean difference (M1-M2)
• Recall:
• now we want to know the total error, but…2
22
1
21
21 n
s
n
ss MM )(
n
ssM
2

11
t-statistic (contd.)
• But, what if the size of the two samples is not the same (n1<>n2)?
• Recall:
• we now have two SS and df values, thus:
df
SS
n
SSs
12
2
11
21
222
2112
21
212
nn
snsns
ordfdf
SSSSs
p
p
)()(
12
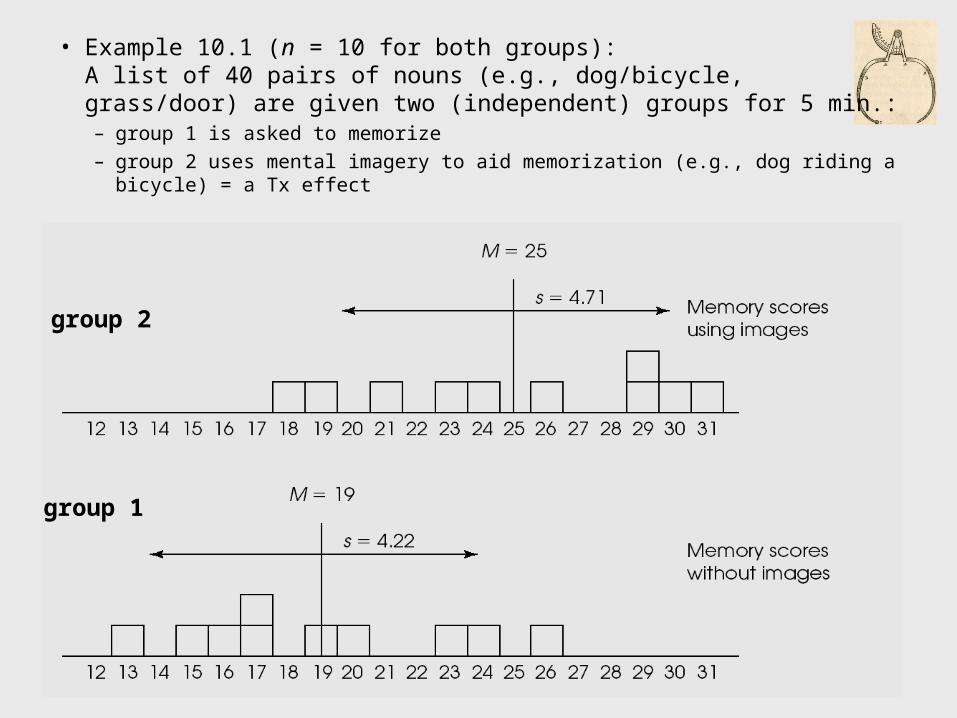
• Example 10.1 (n = 10 for both groups): A list of 40 pairs of nouns (e.g., dog/bicycle, grass/door) are given two (independent) groups for 5 min.:– group 1 is asked to memorize– group 2 uses mental imagery to aid memorization (e.g., dog riding a bicycle)
= a Tx effect
group 2
group 1
13
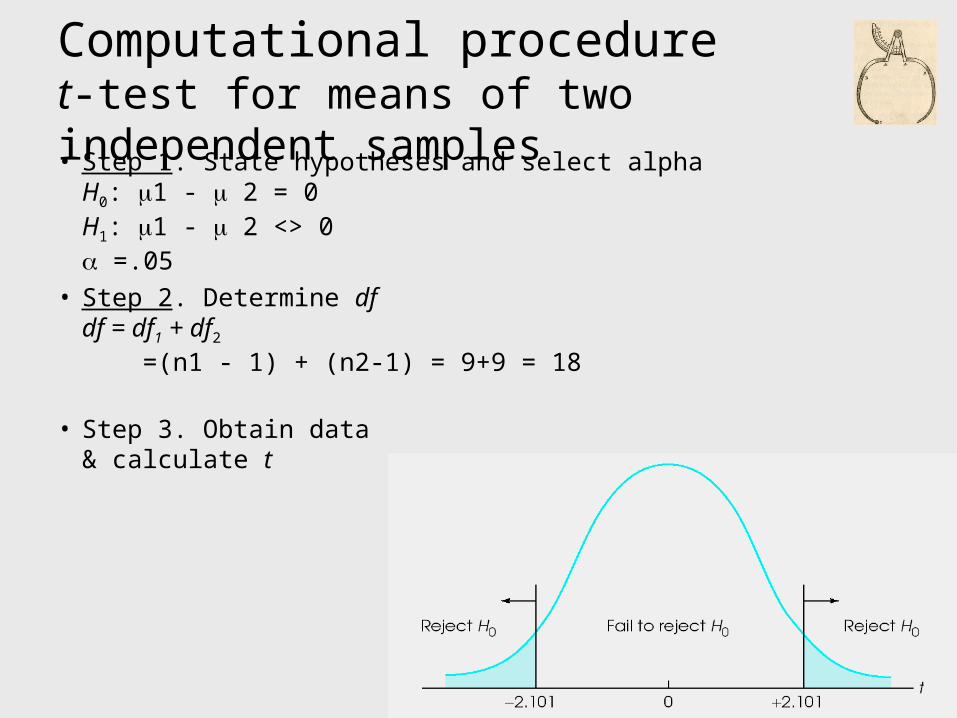
Computational proceduret-test for means of two independent samples• Step 1. State hypotheses and select alpha
H0: 1 - 2 = 0H1: 1 - 2 <> 0 =.05
• Step 2. Determine dfdf = df1 + df2
=(n1 - 1) + (n2-1) = 9+9 = 18
• Step 3. Obtain data& calculate t

14
(contd.)
• Step 3a. For the two samples, A and B, of sizes n1 and n2 respectively, calculate
• Step 3b. Estimate the variance of the source population
• Step 3c. Estimate the sd of the sampling distribution of sample-mean differences
• Step 3d. Calculate t as
1
212
112
11 n
XXSSandXX
)(
)()( 11 21
212
nn
SSSSsp
2
2
1
2
21 n
s
n
ss pp
MM )(
)(
)()(
21
2121
MMs
MMt

15
Example (contd.)
• Step 3a.• Step 3b.
• Step 3c.
• Step 3d.
• Step 4. Make a decision. Table lookup df = 18
2099
160200
11 21
212
)()( nn
SSSSsp
2410
20
10
20
2
2
1
2
21 n
s
n
ss pp
MM )(
0032
6
2
01925
21
2121 .)()()(
)(
MMs
MMt
16
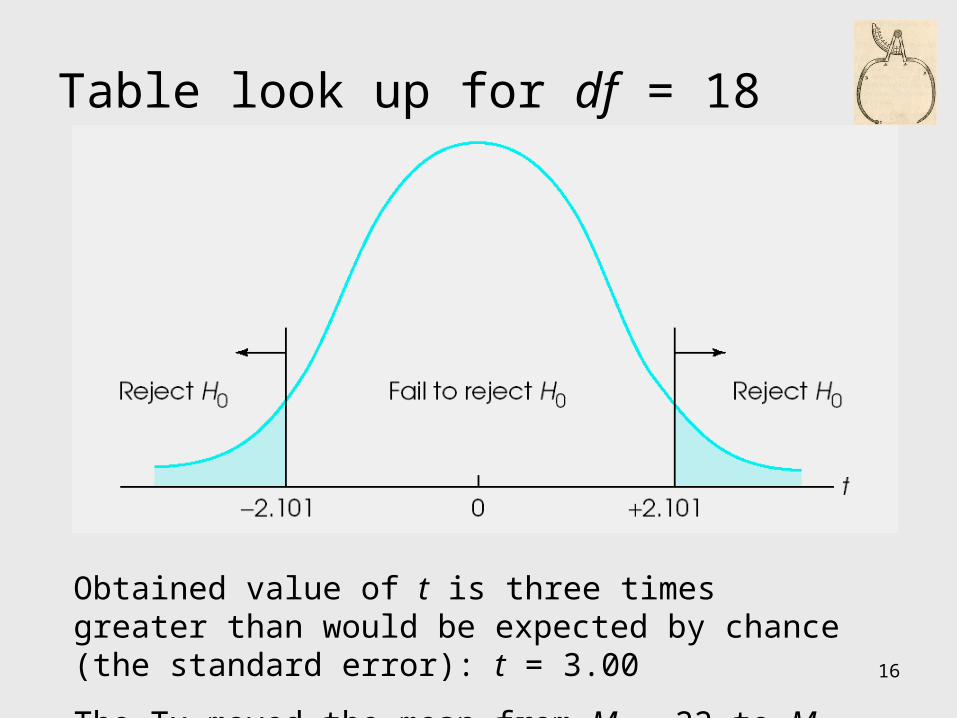
Table look up for df = 18
Obtained value of t is three times greater than would be expected by chance (the standard error): t = 3.00
The Tx moved the mean from M = 22 to M = 25

17
Figure 10-4 (p. 318)The t distribution with df = 18. The critical region for = .05 is shown.Two things are important: significance and effect size

18
Calculating effect sizeTwo methods (Cohen’s d or r2)
• Cohen’s d = mean difference/sd
• the distance between the two means is slightly more than 1 sd, thus d should be slightly larger than 1.00
• Can also calculate variance accounted for by Tx
341474
6
20
19252
21 ..
ps
MM
333027
9
183
32
2
2
22 .
dft
tr

19
Calculating r2 directly:
Tx contribution to variability=Tx variability/ total variability=180/540 = .333 = 33.3%