1 more on indexes secondary indexes b-trees source: our textbook, slides by hector garcia-molina
Post on 19-Dec-2015
219 views
TRANSCRIPT

1
More on Indexes
Secondary IndexesB-Trees
Source: our textbook, slides by Hector Garcia-Molina

2
Secondary Indexes Sometimes we want multiple indexes on a
relation. Ex: search Candies(name,manf) both by name and
by manufacturer Typically the file would be sorted using the
key (ex: name) and the primary index would be on that field.
The secondary index is on any other attribute (ex: manf).
Secondary index also facilitates finding records, but cannot rely on them being sorted

3
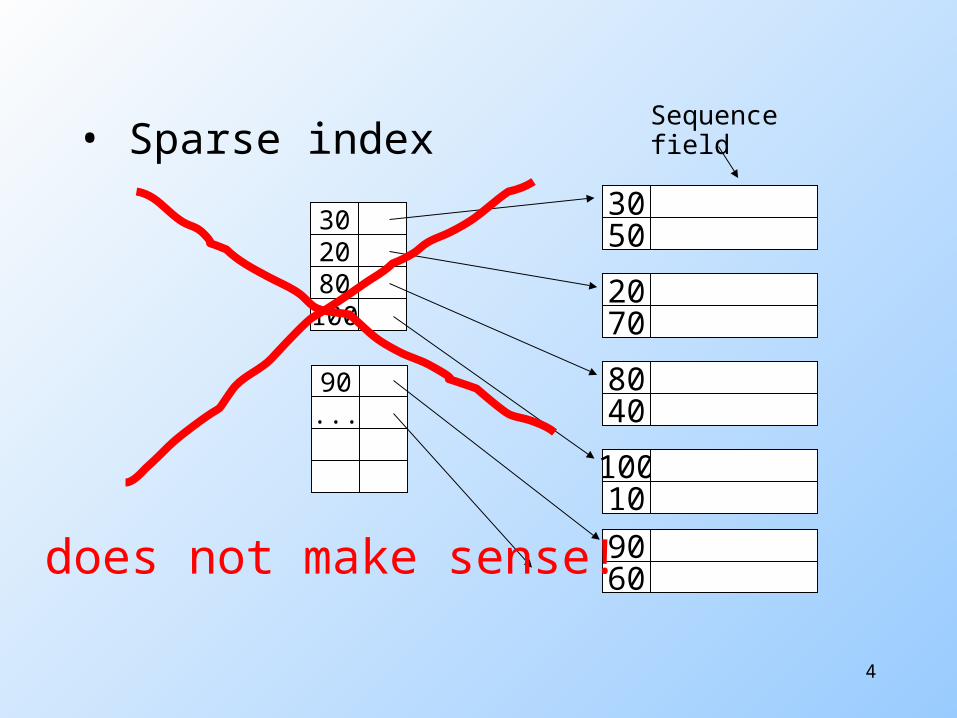
Sparse Secondary Index?
No! Since records are not sorted on
that key, cannot predict the location of a record from the location of any other record.
Thus secondary indexes are always dense.
4
Sequencefield
5030
7020
4080
10100
6090
• Sparse index
302080
100
90...
does not make sense!

5
Design of Secondary Indexes
Always dense, usually with duplicates Consists of key-pointer pairs ("key"
means search key, not relation key) Entries in index file are sorted by key Therefore second-level index is
sparse

6
Secondary indexesSequencefield
5030
7020
4080
10100
6090
10203040
506070...
105090...
sparsesecond-
leveldensefirst-level

7
Secondary Index and Duplicate Keys
Scheme in previous diagram wastes space in the present of duplicate keys
If a search key value appears n times in the data file, then there are n entries for it in the index.

8
Duplicate values & secondary indexes
1020
4020
4010
4010
4030
10101020
20304040
4040...
one option...
Problem:excess overhead!
• disk space• search time

9
Buckets
To avoid repeating values, use a level of indirection
Put buckets between the secondary index file and the data file
One entry in index for each search key K; its pointer goes to a location in a "bucket file", called the bucket for K
Bucket holds pointers to all records with search key K

10
Duplicate values & secondary indexes
1020
4020
4010
4010
4030
10203040
5060...
buckets
saves space as long as search-keys are larger than pointers and average key appears at least twice

11
Why “bucket” idea is useful
Indexes Recordsname: primary Emp
(name,dept,floor,...)
dept: secondaryfloor: secondary

12
Query: SELECT name FROM Emp WHERE dept = 'Toy' AND floor = 2dept index Emp floor index
Toy 2
Intersect Toy dept bucket and floor 2
bucket to get set of matching Emp’sSaves disk I/O's

13
Summary of Indexes So Far
Advantages: simple index is sequential file, good for scans
Disadvantages either inserts are expensive or lose sequentiality (cf. next slide)
Instead use B-tree data structure to implement index

14
Example Index (sequential)
continuous
free space
102030
405060
708090
39313536
323834
33
overflow area(not sequential)

15
B-Trees
Several related data structures Key features are:
automatically adjust number of levels of indexes as size of data file changes
storage on blocks is managed to keep every block between half full and full => no overflow blocks needed
We'll actually study B+ trees

16
B-Tree Structure
an example of a balanced search tree: every root-to-leaf path has same length
each node (vertex) in the tree is a block, which contains search keys and pointers
parameter n, which is largest value so that n+1 pointers and n keys fit in one block Ex: If block size is 4096 bytes, keys are 4 bytes,
and pointers are 8 bytes, then n = 340.

17
Constraints on B-Tree Nodes
Keys in leaf nodes are copies of keys from data file, in sorted order
Root contains between 2 and n+1 index node pointers
Each internal node contains between (n+1)/2 and n+1 index node pointers Each non-leaf node consists of
ptr1,key1,ptr2,key2,…,keym-1,ptrm
where ptri points to index node with keys between keyi-1 and keyi

18
Constraints (cont'd)
Each leaf contains between (n+1)/2 and n data record pointers, plus a "next leaf" pointer
Associated with each data record pointer is a key, and the pointer points to the data record with that key

19
Example B-tree nodes with n = 3
30
35
30
30 35
30
textbook notationmore concise notation
Leaf:
Non-leaf:
to recordwith key 30
to record with key 35
to part of tree with keys < 30
to part of tree with keys ≥ 30
20
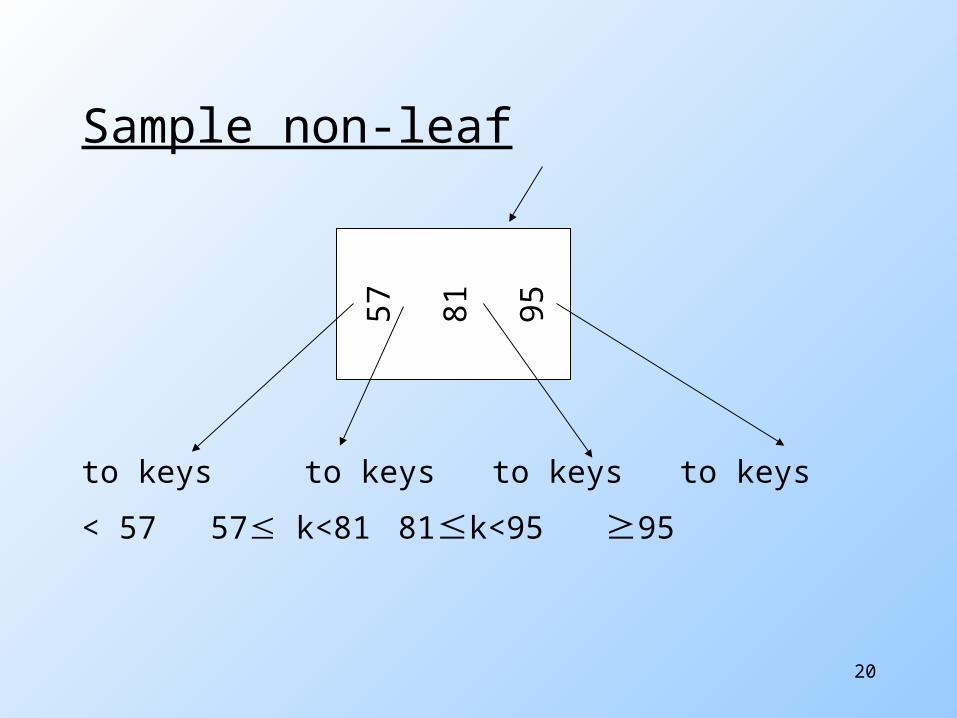
Sample non-leaf
to keys to keys to keys to keys
< 57 57 k<81 81k<95 95
57
81
95

21
Sample leaf node:
From non-leaf node
to next leafin
sequence5
7
81
95
To r
eco
rd
wit
h k
ey 5
7
To r
eco
rd
wit
h k
ey 8
1
To r
eco
rd
wit
h k
ey 8
5

22
Full nodemin. node
Non-leaf
Leaf
n=3
12
01
50
18
0
30
3 5 11
30
35
counts
even if
null
23
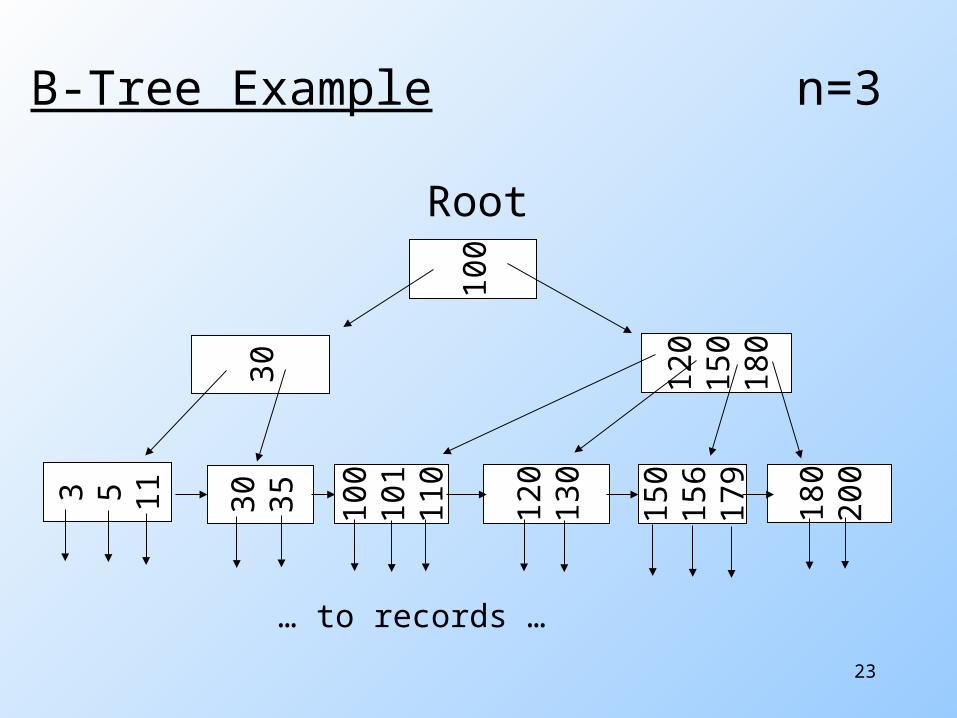
Root
B-Tree Example n=3
100
120
150
180
30
3 5 11
30
35
100
101
110
120
130
150
156
179
180
200
… to records …

24
Insert into B+tree
(a) simple case space available in leaf
(b) leaf overflow(c) non-leaf overflow(d) new root

25
(a) Insert key = 32 n=33 5 11
30
31
30
100
32

26
(a) Insert key = 7 n=3
3 5 11
30
31
30
100
3 5
7
7

27
(c) Insert key = 160 n=3
10
0
120
150
180
150
156
179
180
200
160
18
0
160
179

28
(d) New root, insert 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
40
45
40
30new root

29
(a) Simple case - no example
(b) Coalesce with neighbor (sibling)
(c) Re-distribute keys(d) Cases (b) or (c) at non-leaf
Deletion from B-tree

30
(b) Coalesce with sibling Delete 50
10
40
100
10
20
30
40
50
n=4
40

31
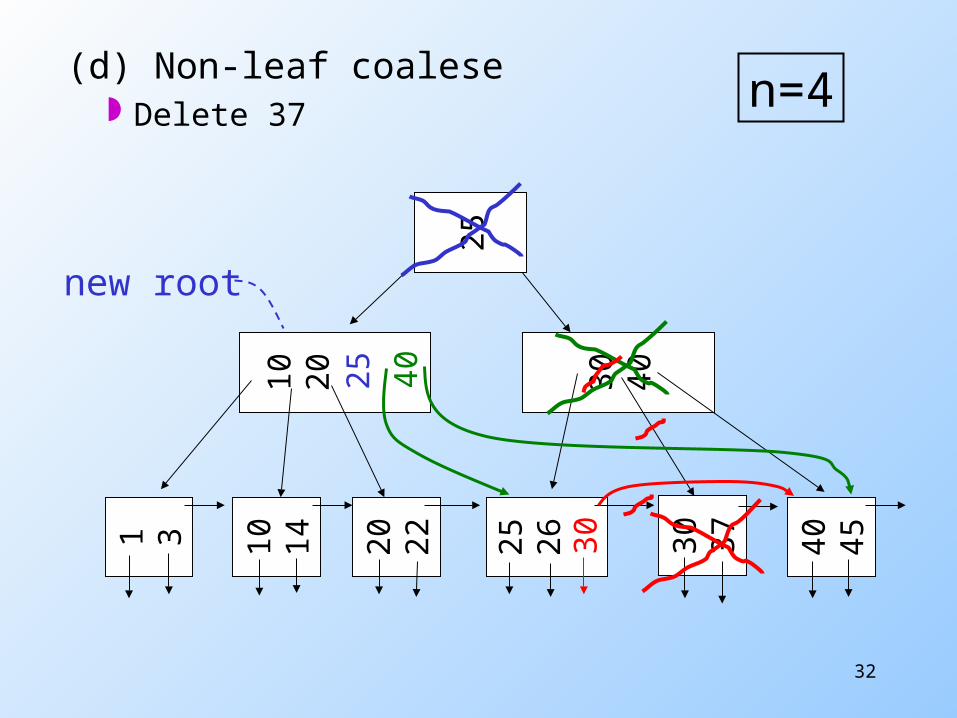
(c) Redistribute keys Delete 50
10
40
100
10
20
30
35
40
50
n=4
35
35
32
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
(d) Non-leaf coalese Delete 37
n=4
40
30
25
25
new root

33
B-tree deletions in practice
– Often, coalescing is not implemented Too hard and not worth it!

34
Applications of B-Trees B-tree is used to implement indexes The data record pointers in the leaves
correspond to the data record pointers in sequential indexes
Some example uses: B-tree search key is primary key for data file,
leaf pointers form a dense index on the file B-tree search key is primary key for data file,
leaf pointers form a sparse index on the file B-tree search key is not primary key, leaf
pointers form a dense index on the file

35
B-Trees with Duplicate Keys
Change definition of B-tree: If key K appears in an internal node,
then K is the smallest "new" key in the subtree S rooted at the pointer that follows K in the node
"New" means K does not appear in the part of the B-tree to the left of S but it does appear in S
Allow null key in certain situations
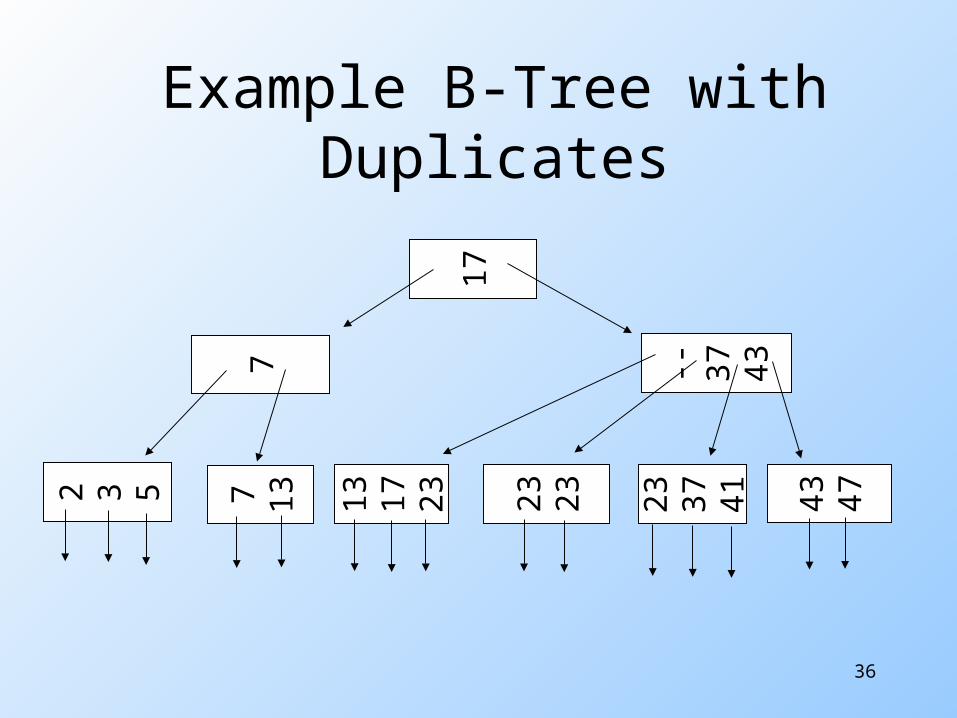
36
Example B-Tree with Duplicates
17
-- 37
437
2 3 5 7 13
13
17
23
23
23
23
37
41
43
47

37
Lookup in B-Trees Assume no duplicate keys. Assume B-tree is a dense index. To find the record with key K, search starting
at the root and ending at a leaf: if current node is not a leaf and has keys K1,
K2, …, Kn, find the smallest key, Ki, in the sequence that is ≤ K.
follow the (i+1)-st pointer to a node at the next level and repeat
when a leaf node is reached, find the key with value K and follow the associated pointer to the data record

38
Range Queries with B-Trees
Range query: a query in which a range of values is sought. Examples: SELECT * FROM R WHERE R.k > 40; SELECT * FROM R WHERE R.k >= 10 AND R.k
<= 25; To find all keys in the range [a,b]:
Do a lookup on a: leads to leaf where a could be Search the leaf for all keys ≥ a If we find a key > b, we are done Else follow next-leaf pointer and continue
searching in the next leaf Continue until finding a key > b or no more
leaves

39
Efficiency of B-Trees B-trees allow lookup, insertion and deletion of
records with very few disk I/Os Number of disk I/Os is number of levels in the
B-tree plus cost of any reorganization If n is at least 10, then splitting/merging blocks
will be rare and usually limited to the leaves For typical sizes of keys, pointers, blocks and
files, 3 levels suffice (see next slide) Also can keep root block of B-tree in memory

40
Size of B-Tree Assume
4096 bytes per block 4 bytes per key (e.g., integer) 8 bytes per pointer no header info in the block
Then n = 340 (can keep n keys and n+1 pointers in a block)
Assume on average a block has 255 pointers Count:
one node at level 1 (the root) 255 nodes at level 2 255*255 = 65,025 nodes at level 3 (leaves) each leaf has 255 pointers, so total number of records
is more than 16 million