1 montgomery multiplication david harris and kyle kelley harvey mudd college claremont, ca 91711...
Post on 22-Dec-2015
221 views
TRANSCRIPT

1
MontgomeryMontgomeryMultiplicationMultiplication
David Harris and Kyle KelleyHarvey Mudd College
Claremont, CA 91711
{David_Harris, Kyle_Kelley}@hmc.edu

2
OutlineOutline
• Cryptography Overview
• Finite Field Mathematics
• Montgomery Multiplication
• Tenca-Koç Montgomery Multiplier
• Improved Montgomery Multiplier
• Very High Radix
• Implementation Results
• Summary

3
Cryptography OverviewCryptography Overview
• Encryption has become essential– E-commerce (SSL)– Communications / network processors– Smart cards / digital cash– Military
• Two major classes of algorithms– Symmetric cryptosystems (e.g. DES)– Public key cryptosystems (e.g. RSA)

4
Cryptographic ProtocolsCryptographic Protocols
• Alice and Bob would like to communicate securely. Eve wants to listen in.– Symmetric key:
• Alice and Bob must share a key for encryption and decryption.
• If Eve hears it, she can read the messages.
– Public key:• Alice publishes her public key to the world.• Bob encrypts with Alice’s public key.• Alice can decrypt only with her private key.• Eve can’t decrypt with the public key.

5
Digital SignaturesDigital Signatures
• Alice wants to sign a contract in a way that only she can do.– Alice publishes her public key and
keeps the private key secret.– Encrypt the document with her secret
key.– Anyone can decrypt the document with
her public key– But nobody can forge her signature.

6
Key ExchangeKey Exchange
• Public key encryption is slow
• Use it to share a symmetric key– Use symmetric key to encrypt large
blocks of data

7
RSA EncryptionRSA Encryption
• Most widely used public key system.– Good for encryption and signatures.– Invented by Rivest, Shamir, Adleman (1978)
• Public e and private d keys are long #s– n = 256-2048+ bits– Satisfy xde mod M = 1 for all x– Finding d from e is as hard as factoring M
• Encryption: B = Ae mod M• Decryption: C = Bd mod M = Aed = A

8
Modular ExponentiationModular Exponentiation
• Critical operation in RSA and for– Digital signature algorithm– Diffie-Hellman key exchange– Elliptic curve cryptosystems
• Done with 2n modular multiplications– Ex: A27 = ((((((A2) * A)2)2) * A)2) * A– Division required after each
multiplication to compute modulo

9
Finite Field MathematicsFinite Field Mathematics
• +, * modulo prime p form a finite field– p elements– Additive identity: 0– Multiplicitive identity: 1– Each nonzero number has a unique
inverse x-1
– Named GF(p)• For Evariste Galois, a 19th century number
theorist killed in a duel at age 20

10
Binary Extension FieldsBinary Extension Fields
• Building blocks are polynomials in x– Operations performed modulo some
irreducible polynomial f(x) of degree n– Arithmetic done modulo 2– Called GF(2n)
• Example: GF(23)
• Computation is the same as GF(p)– Except that no carries are propagated
Element Code
0 000
1 001
x 010
x+1 011
x2 100
x2 +1 101
x2+x 110
x2+x+1 111

11
Montgomery MultiplicationMontgomery Multiplication
• Faster way to do modular exponentation– Operate on Montgomery residues– Division becomes a simple shift– Requires conversion to and from
residues only once per exponentiation

12
Montgomery ResiduesMontgomery Residues
• Let the modulus M be an odd n-bit integer
• Define r = 2n
• Define the M-residue of an integer a < M as
• There is a one-to-one correspondence between integers and M-residues for
0 < a < M-1
nn M 22 1
Mara mod

13
MM-Residue Examples-Residue Examples
• M = 11, r = 16
611 mod 16*1010
111 mod 16*99
711 mod 16*88
211 mod 16*77
811 mod 16*66
311 mod 16*55
911 mod 16*44
411 mod 16*33
1011 mod 16*22
511 mod 16*11
011 mod 16*00

14
Montgomery MultiplicatonMontgomery Multiplicaton
• Define
• Where r-1 is the inverse of r mod M: – r-1r = 1 (mod M)
• This gives the Montgomery residue of – z = xy mod M
MryxyxMMz mod),( 1
Mzr
Mxyr
Mryrxr
Mryxz
mod
mod
mod))((
mod1
1

15
Mont. Multiplication ExampleMont. Multiplication Example
711 mod 9*7*5)7,5(
)111 mod 9*16( 91
MM
r
• It may not be obvious that this is easier to do than regular modular multiplication.

16
Montgomery MultiplierMontgomery Multiplier
• MM is an easier operation that requires no hard division, just shifting
• In radix 2,
Z = 0for i = 0 to n-1
Z = Z + xi•Yif Z is odd then Z = Z + MZ = Z/2
if Z ≥ M then Z = Z – M

17
ExampleExample
• X = 7 = 0111• Y = 5 = 0101• M = 11 = 1011
• Z initially 0– Z = (0 + 5 + 11) / 2 = 8– Z = (8 + 5 + 11) / 2 = 12– Z = (12 + 5 + 11) / 2 = 14– Z = (14 + 0) / 2 = 7 (final result)
Z = 0for i = 0 to n-1
Z = Z + xi•Yif Z is odd then Z
= Z + MZ = Z/2
if Z ≥ M then Z = Z – M

18
ConversionConversion
• Conversion of integers to/from Montgomery residues takes one MM operation (if r2 mod M is precomputed and saved):
• Modular exponentiation takes two conversion steps and 2n multiplication steps.
xMrxrMrxxMMx
MxrMrxrrxMMx
mod 1 mod1)1,(
mod mod),(11
122

19
Cryptography AcceleratorsCryptography Accelerators
• Hardware accelerators offer more speed at less power than software– Via announced x86 C5J core
Montgomery Multiply opcode (May 04)
3COM Router 5000 Series Encryption Accelerator
IBM PCI SSL Cryptography Accelerator

20
BreakBreak

21
BreakBreak
22
BreakBreak

23
Reconfigurable HardwareReconfigurable Hardware
• Building hardwired n-bit unit is limiting– Slow for large n– Not scalable to different n
• Better to design for w-bit words– Break n-bit operand into e w-bit words– This is called scalable
• Also handle both GF(p) and GF(2n)– Requires conditionally killing carries– Called unified
24
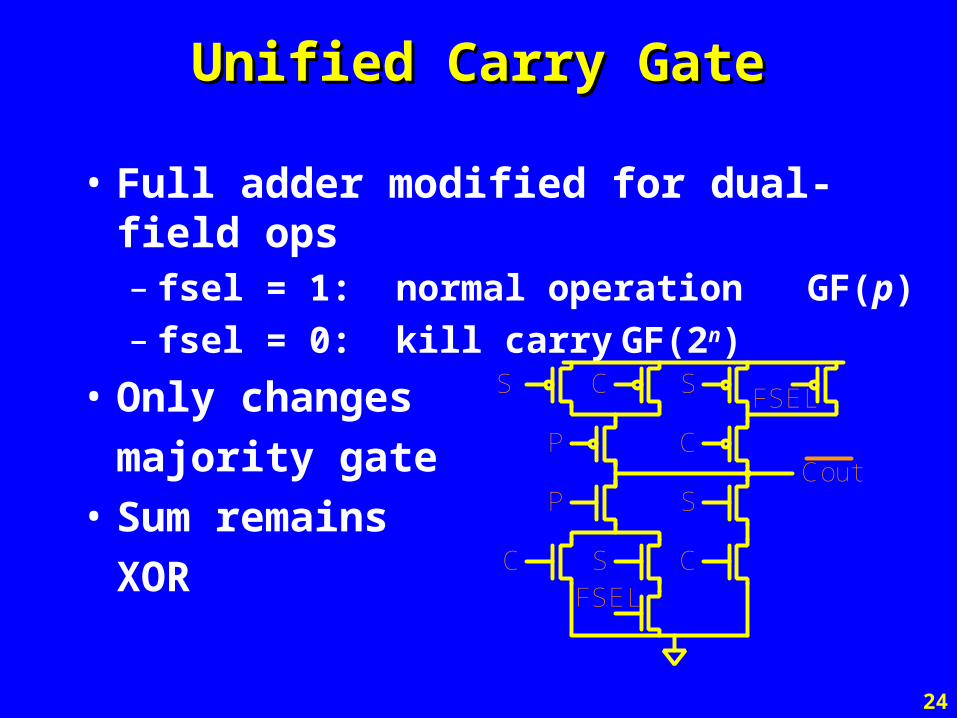
Unified Carry GateUnified Carry Gate
• Full adder modified for dual-field ops– fsel = 1: normal operation GF(p)– fsel = 0: kill carry GF(2n)
• Only changes
majority gate
• Sum remains
XORFSEL
FSEL
C S
P S
C
S
C
S C
PCout

25
Tenca-Koç Montgomery MultiplierTenca-Koç Montgomery Multiplier
Z = 0
for i = 0 to n-1
(CA, Zw-1:0) = Zw-1:0 + Xi × Yw-1:0
reduce = Z0
(CB, Zw-1:0) = Zw-1:0 + reduce × Mw-1:0
for j = 1 to e+1
(CA, Z(j+1)w-1:jw) = Z(j+1)w-1:jw + Xi × Y(j+1)w-1:jw + CA
(CB, Z(j+1)w-1:jw) = Z(j+1)w-1:jw + reduce × M(j+1)w-1:jw + CB
Zjw-1:(j-1)w = (Zjw, Zjw-1:(j-1)w+1)
IEEE Transactions on Computers, Sept. 2003

26
Processing ElementsProcessing Elements
• Keep Z in carry-save redundant form
• Simple processing element (PE)
3:2
CS
A
3:2
CS
A
(w)
Cin
Cb
x i
Zw-1:0
Yw-1:0
Mw-1:0
Ca
Cout
Cin
Cout
reset
(w)
Z0
Zw-1
Z0
Zw-1:0
Mw-1:0
Yw-1:0
reduce

27
ParallelismParallelism
• Two dimensions of parallelism:– Width of processing element w– Number of pipelined PEs p
• Multiply takes k = n/p kernel cycles
FIFO
0YM
Mem
X Mem
PE1 PE2 PE3 PE p
SequenceControl
Result
Z
MY
xKernel
Z’

28
Pipeline TimingPipeline Timing
Ker
nel
Cyc
le 1
Case I: e > 2p-1e = 4, p = 2
Case II: e < 2p-1e = 4, p = 4
tim
e
spacePE1 PE2
1 x0
x1
x0
x1
x0
x1
x0
x1
x3
x3
x3
x3
x2
x2
x2
x2
2
3
4
5
6
7
8
9
10
11
12
13
Ker
nel
Cyc
le 2
PE1 PE2 PE3 PE4
KernelStall
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
x1
MY5w-1:4wZ5w-2:4w-1
x0
MY5w-1:4wZ5w-2:4w-1
x3
MY5w-1:4wZ5w-2:4w-1
x2
MY5w-1:4wZ5w-2:4w-1
x0
x0
x0
x0
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
x0
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
x0
x0
x0
x0
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
x0
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
MYw-1:0Zw-2:-1
MY2w-1:wZ2w-2:w-1
MY3w-1:2wZ3w-2:2w-1
MY4w-1:3wZ4w-2:3w-1
MY5w-1:4wZ5w-2:4w-1
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
Ker
nel
Cyc
le 1
Ker
nel
Cyc
le 2
14
15
16
17
18
19
20

29
QueueQueue
• If full PEs cause stall, queue results
• Convert back to nonredundant form– Saves queue space– CPA needed for final result anyway
Z’ Z
Result
FIFO(0 or more words)
firstcycle
byp
ass
1x0
0100w w
sum
carry CP
A

30
Improved DesignImproved Design
• Don’t wait two cycles for MSB
• Kick off dependent operation right away on the available bits
• Take extra cycle(s) at the end to handle the extra bits
• For p processing elements, cycle count reduces from 2p to p + (p/w)

31
Improved PEImproved PE
• Left-shift M and Y rather than right-shifting Z
• Same amount of hardware
3:2 CS
A
3:2 CS
A
(w)Cin
Cb
x i
reduce
Zw-1:0
Mw-1:0Yw-1:0
M-1
Zw-2:-1
Yw-2:-1
Mw-2:-1
Mw-1
Ca
Cout
Cin
Cout
reset
(w)
Yw-1
Y-1
Z0
32
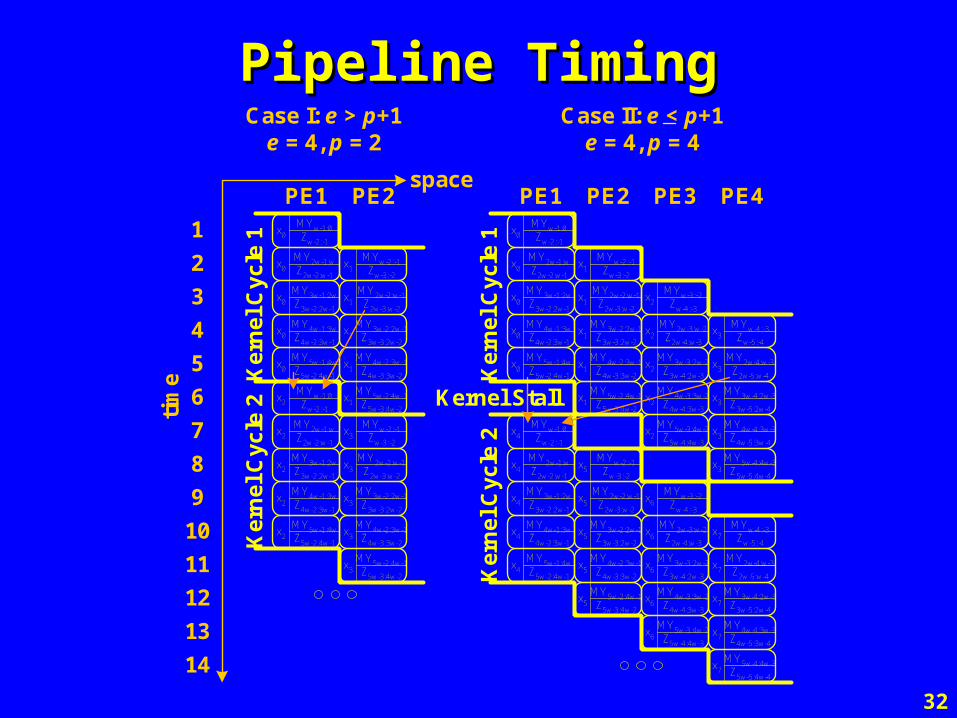
Pipeline TimingPipeline Timing
Ker
nel
Cyc
le 1
Case I: e > p+1e = 4, p = 2
Case II: e < p+1e = 4, p = 4
tim
espace
PE1 PE2
1 MYw-1:0Zw-2:-1
x0
MYw-2:-1Zw-3:-2
x1MY2w-1:wZ2w-2:w-1
x0
MY2w-2:w-1Z2w-3:w-2
x1MY3w-1:2wZ3w-2:2w-1
x0
MY3w-2:2w-1Z3w-3:2w-2
x1MY4w-1:3wZ4w-2:3w-1
x0
MY4w-2:3w-1Z4w-3:3w-2
x1
x3
x3
x3
x3
x2
x2
x2
x2
2
3
4
5
6
7
8
9
10
11
12
13
Ker
nel
Cyc
le 2
Ker
nel
Cyc
le 1
PE1 PE2x0
x1x0
x1x0
x1x0
x1
MYw-3:-2Zw-4:-3
x2
MY2w-3:w-2Z2w-4:w-3
x2
MY3w-3:2w-2Z3w-4:2w-3
x2
MY4w-3:3w-2Z4w-4:3w-3
x2
MYw-4:-3Zw-5:-4
x3
MY2w-4:w-3Z2w-5:w-4
x3
MY3w-4:2w-3Z3w-5:2w-4
x3
MY4w-4:3w-3Z4w-5:3w-4
x3
PE3 PE4
Ker
nel
Cyc
le 2 x4
x5x4
x4
x4
x6
x7
Kernel StallMYw-1:0Zw-2:-1
MYw-2:-1Zw-3:-2
MY2w-1:wZ2w-2:w-1
MY2w-2:w-1Z2w-3:w-2
MY3w-1:2wZ3w-2:2w-1
MY3w-2:2w-1Z3w-3:2w-2
MY4w-1:3wZ4w-2:3w-1
MY4w-2:3w-1Z4w-3:3w-2
MYw-1:0Zw-2:-1
MYw-2:-1Zw-3:-2
MY2w-1:wZ2w-2:w-1
MY2w-2:w-1Z2w-3:w-2
MY3w-1:2wZ3w-2:2w-1
MY3w-2:2w-1Z3w-3:2w-2
MY4w-1:3wZ4w-2:3w-1
MY4w-2:3w-1Z4w-3:3w-2
MYw-1:0Zw-2:-1
MYw-2:-1Zw-3:-2
MY2w-1:wZ2w-2:w-1
MY2w-2:w-1Z2w-3:w-2
MY3w-1:2wZ3w-2:2w-1
MY3w-2:2w-1Z3w-3:2w-2
MY4w-1:3wZ4w-2:3w-1
MY4w-2:3w-1Z4w-3:3w-2
MYw-3:-2Zw-4:-3
MY2w-3:w-2Z2w-4:w-3
MY3w-3:2w-2Z3w-4:2w-3
MY4w-3:3w-2Z4w-4:3w-3
MYw-4:-3Zw-5:-4
MY3w-4:2w-3Z3w-5:2w-4
MY4w-4:3w-3Z4w-5:3w-4
MY2w-4:w-3Z2w-5:w-4
x5
x6
x7
x5
x6
x7
x5
x6
x7
MY5w-1:4wZ5w-2:4w-1
x0
MY5w-2:4w-1Z5w-3:4w-2
x1
14
MY5w-1:4wZ5w-2:4w-1
x2
MY5w-2:4w-1Z5w-3:4w-2
x3
x0
MY5w-3:4w-2Z5w-4:4w-3
x2
MY5w-4:4w-3Z5w-5:4w-4
x3
MY5w-1:4wZ5w-2:4w-1
x1MY5w-2:4w-1Z5w-3:4w-2
x4
MY5w-3:4w-2Z5w-4:4w-3
x6
MY5w-4:4w-3Z5w-5:4w-4
x7
MY5w-1:4wZ5w-2:4w-1
MY5w-2:4w-1Z5w-3:4w-2
x5

33
LatencyLatency
• Tenca-Koç
• Improved Design
II) (Case1221
I) (Case111
peepk
pepek
II) (Case12212
I) (Case12)1(2)1(
peepk
pepek

34
Very High RadixVery High Radix
• These designs are Radix-2– 1 bit of x per PE
• Higher radix designs reduce latency– Process more bits of x per PE– Require integer multiplication instead of
AND gates

35
Montgomery’s AlgorithmMontgomery’s Algorithm
Multiply: Z = X × Y
Reduce: reduce = Z × M’ mod R
Z = [Z + reduce × M] / R
Normalize: if Z ≥ M then Z = Z – M
• M’ satisfies RR-1 – MM’ = 1– Drives LSBs to 0

36
Scalable Very High Radix AlgorithmScalable Very High Radix Algorithm
w-bit words of M and Y e = n/w
v-bit digits of X f = n/v radix = 2v
Z = 0
for i = 0 to f-1
(CA, Zw-1:0) = Zw-1:0 + X(i+1)v-1:iv × Yw-1:0
reduce = (M'v-1:0 × Zw-1:0)v-1:0
(CB, Zw-1:0) = Zw-1:0 + reduce × Mw-1:0
for j = 1 to e+1
(CA, Z(j+1)w-1:jw) = Z(j+1)w-1:jw + X(i+1)v-1:iv × Y(j+1)w-1:jw + CA
(CB, Z(j+1)w-1:jw) = Z(j+1)w-1:jw + reduce × M(j+1)w-1:jw + CB
Zjw-1:(j-1)w = (Zjw+v-1:jw, Zjw-1:(j-1)w+v)
37
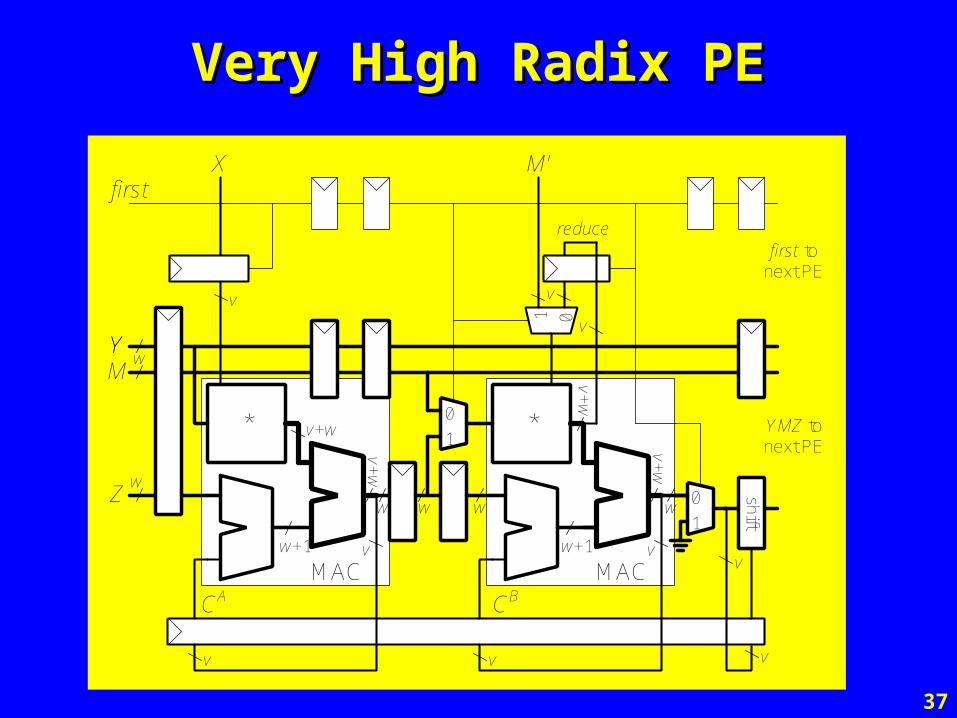
Very High Radix PEVery High Radix PE
Z
*
X
Y
reduce
M
M'
v
v+w0
1*
1 0
CA CB
w
w
v
v v
w+1
w w
v+w
w+1
v+w
YMZ to next PE
Y
first
first to next PE
v+w
w w
vv
v
0
1
v
v
shift
MAC MAC
38
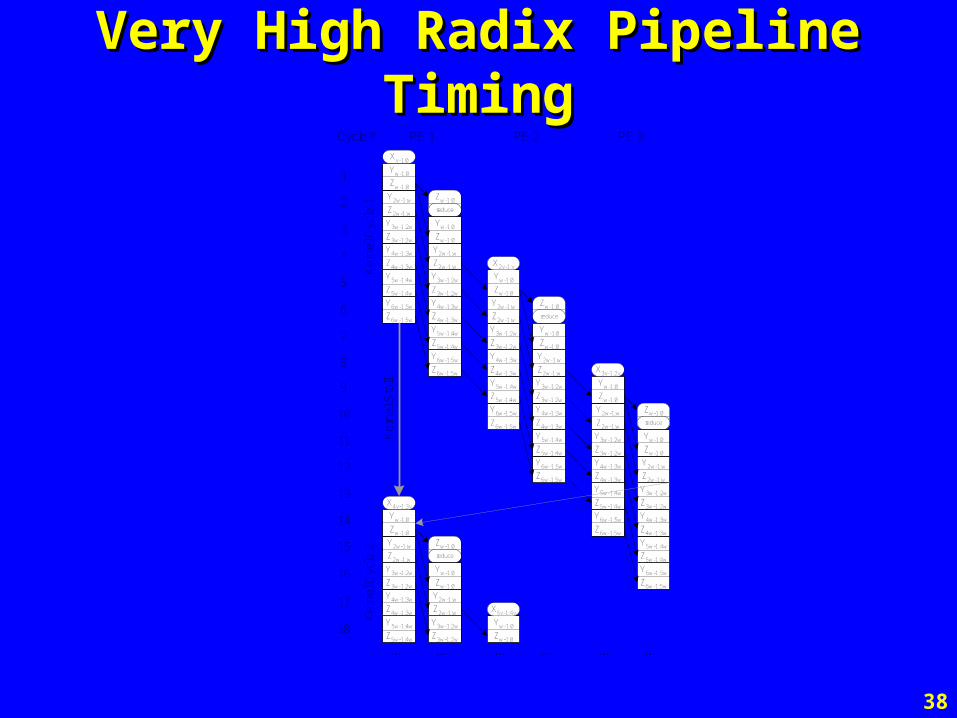
Very High Radix Pipeline TimingVery High Radix Pipeline Timing
Zw-1:0
reduce
Xv-1:0
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
Zw-1:0
reduce
X2v-1:v
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
Zw-1:0
reduce
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Y6w-1:5w
Z6w-1:5w
X3v-1:2v
Zw-1:0
reduce
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Y4w-1:3w
Z4w-1:3w
Y5w-1:4w
Z5w-1:4w
Yw-1:0
Zw-1:0
Y2w-1:w
Z2w-1:w
Y3w-1:2w
Z3w-1:2w
Yw-1:0
Zw-1:0
Ke
rne
l Sta
ll
PE 1 PE 2 PE 3
Ke
rne
l Cyc
le 1
Ke
rne
l Cyc
le 2
X4v-1:3v
X5v-1:4v
… … … … … …
1
Cycle #
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

39
LatencyLatency
• Tenca-Koç: k = n/p
• Very High Radix: k = n/pv
3 4 1 2 4 2 (Case I)
4 1 1 4 2 (Case II)
k e p e p
k p e e p
II) (Case12212
I) (Case12)1(2)1(
peepk
pepek

40
ImplementationImplementation
• C and Verilog reference models– Parameterized by w, p, and v– Extensive testing up to n = 1024
• Synthesized Verilog onto FPGA– Xilinx Virtex II Pro XC2V2000-6

41
ResultsResults
Description Technology Hardware Clock Speed (MHz)
Scalable 256-bit time (ms)
1024-bit time (ms)
T-K p = 40 w=8 0.5 m CMOS synthesized
28 Kgates 80 Yes 3.8 88
Improved p = 16 w = 16 Xilinx Virtex II 1514 LUTs
+ ~5n RAM
144 Yes 1.1 59
Improved p = 64 w = 16 Xilinx Virtex II 5598 LUTs
+ ~5n RAM
144 Yes 1.0 16
p = 4 w = 16 v = 16
very high radix
Xilinx Virtex II 780 LUTs
+ 8 mults
+ ~5n RAM
102 Yes 0.45 22
p = 16 w = 16 v = 16
very high radix
Xilinx Virtex II 2847 LUTs
+ 32 mults
+ ~5n RAM
102 Yes 0.40 6.6

42
SummarySummary
• Modular exponentiation is key operation in cryptography
• Hardware accelerators getting popular– Reconfigurable in key length & field
• Developed improved MM– Half the latency for n ≤ w*p– Half the queue size
• Higher radix looks even better– Well-suited to FPGAs