1 exercise 1 bioinformatics databases. 2 what’s in a database? sequences – genes, proteins,...
Post on 21-Dec-2015
222 views
TRANSCRIPT

11
Exercise 1Exercise 1Bioinformatics DatabasesBioinformatics Databases

22
What’s in a databaseWhat’s in a database?? Sequences – genes, proteins, etc.Sequences – genes, proteins, etc.
Full genomesFull genomes
Annotation – information about the gene/protein:Annotation – information about the gene/protein:- function- function- cellular location- cellular location- chromosomal location- chromosomal location- introns/exons- introns/exons- protein structure- protein structure- phenotypes, diseases- phenotypes, diseases
PublicationsPublications

33
NCBI and EntrezNCBI and Entrez
One of the largest and most comprehensive One of the largest and most comprehensive databases belonging to the NIH – national databases belonging to the NIH – national institute of health (USA)institute of health (USA)
Entrez is the search engine of NCBIEntrez is the search engine of NCBI Search for :Search for :
genes, proteins, genomes, structures, diseases, genes, proteins, genomes, structures, diseases, publications and morepublications and more..
httphttp://://wwwwww..ncbincbi..nlmnlm..nihnih..govgov//

44
Searching for published papersSearching for published papers Yang X, Kurteva S, Ren X, Lee S,Yang X, Kurteva S, Ren X, Lee S,
Sodroski JSodroski J.. “Subunit stoichiometry of human “Subunit stoichiometry of human immunodeficiency virus type 1 envelope glycoprotein trimers immunodeficiency virus type 1 envelope glycoprotein trimers during virus entry into host cells “, J Virolduring virus entry into host cells “, J Virol.. 2006 2006 May;80(9):4388-95. May;80(9):4388-95.

55
Use fieldsUse fields!!Yang[AU] AND glycoprotein[TI] AND 2006[DP] AND J virol[TA]
For the full list of field tags: go to help -> Search Field Descriptions and Tags

66
ExerciseExercise
Retrieve all publications in which the Retrieve all publications in which the first first author is:author is: Pe'er I Pe'er I and the and the last author is:last author is: Shamir RShamir R
77
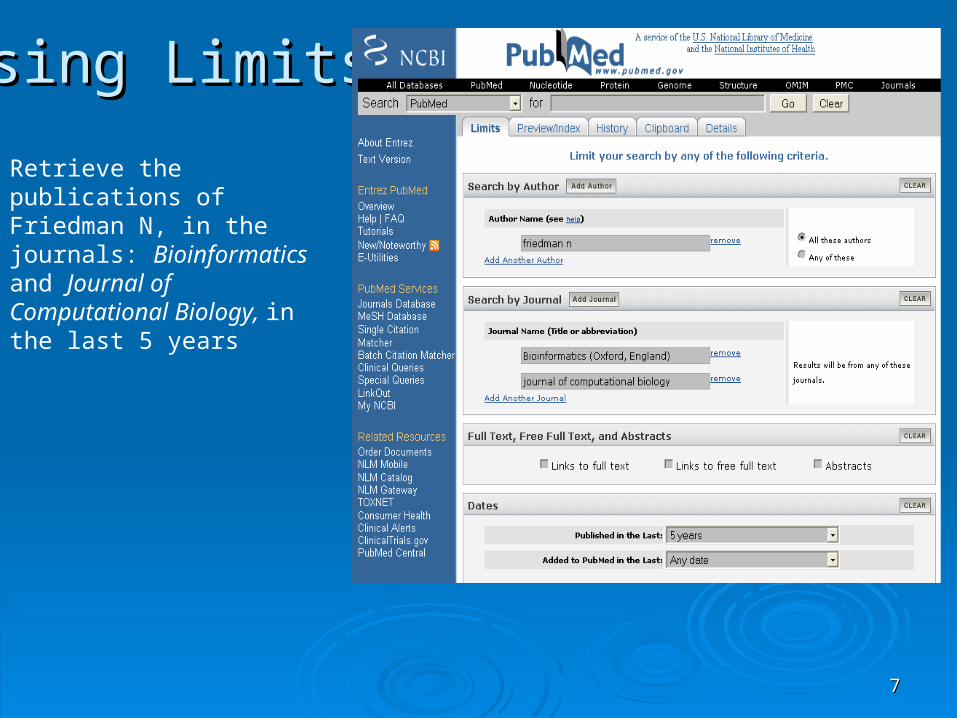
Using LimitsUsing Limits
Retrieve the publications of Friedman N, in the journals: Bioinformatics and Journal of Computational Biology, in the last 5 years

88
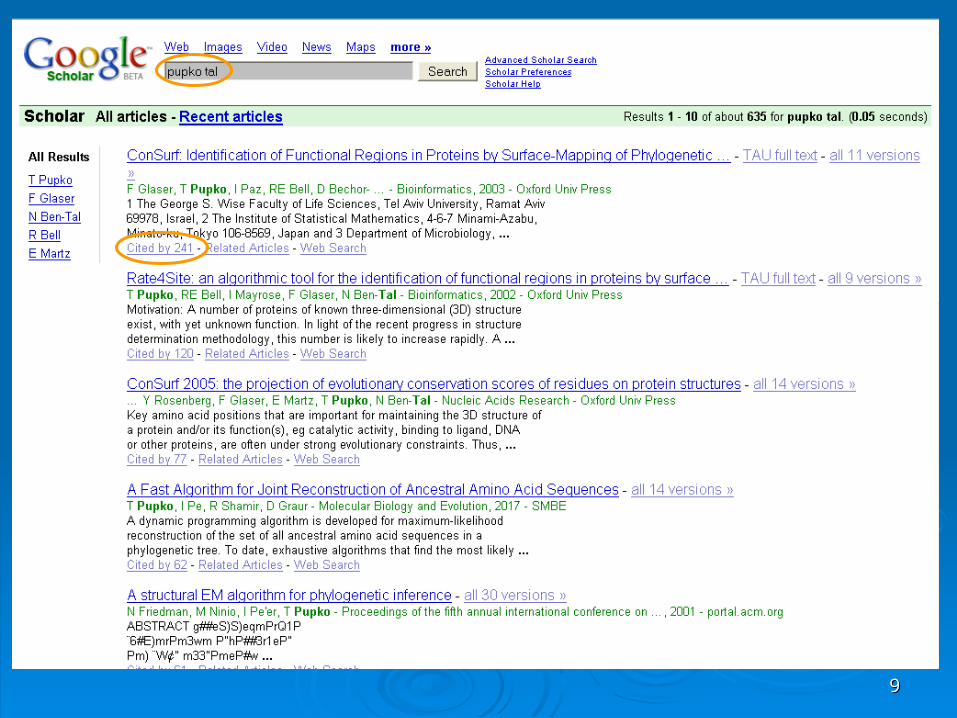
Google scholarGoogle scholarhttp://scholar.google.com/
99

1010
NCBI gene & protein databases: NCBI gene & protein databases: GenBankGenBank
GenBankGenBank is an annotated collection of all is an annotated collection of all publicly available DNA sequencespublicly available DNA sequences
Holds Holds 65 billion65 billion bases (Oct. 2007)bases (Oct. 2007)
GenPeptGenPept is a database of translated is a database of translated coding sequences from GenBankcoding sequences from GenBank

1111
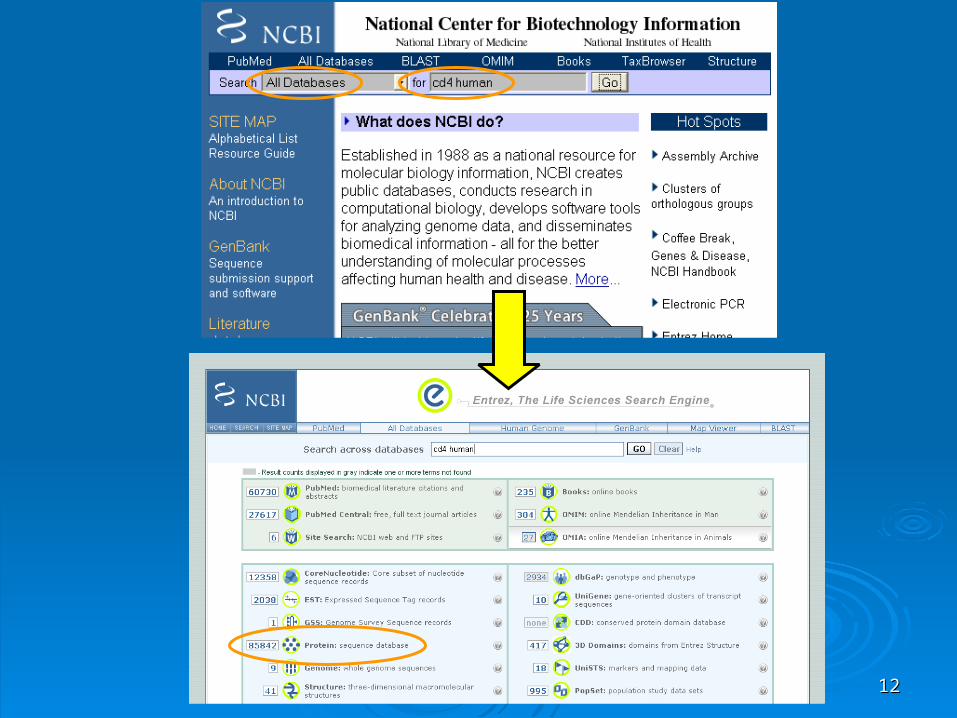
Searching for CD4 human using Searching for CD4 human using EntrezEntrez
Search demonstrationSearch demonstration
1212
1313
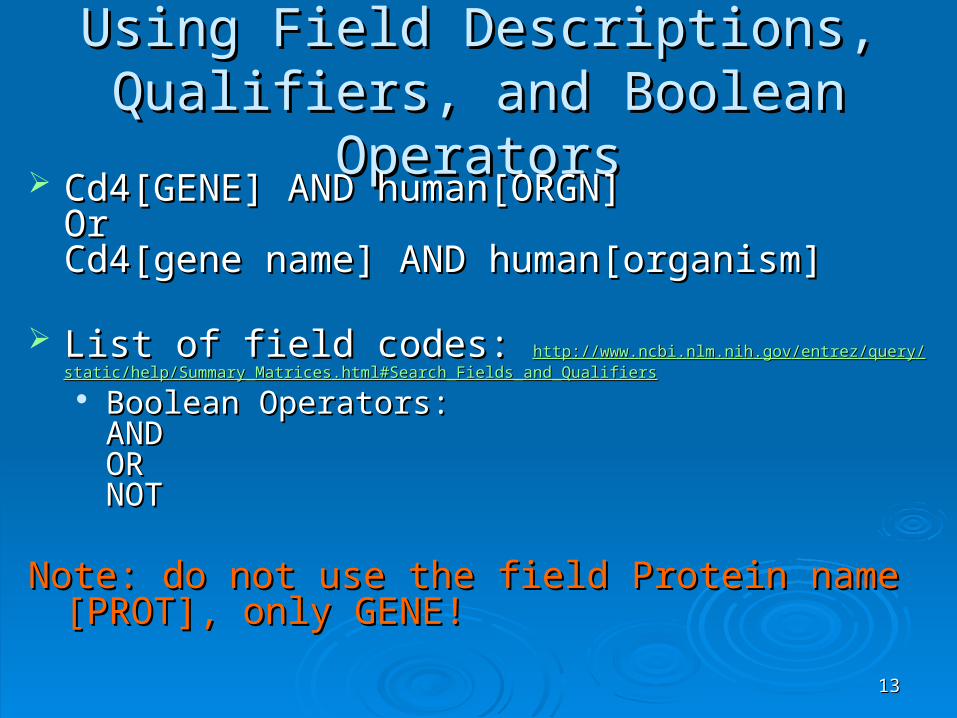
Using Field Descriptions, Qualifiers, Using Field Descriptions, Qualifiers, and Boolean Operatorsand Boolean Operators
Cd4[GENE] AND human[ORGN] Cd4[GENE] AND human[ORGN] Or Or Cd4[gene name] AND human[organism]Cd4[gene name] AND human[organism]
List of field codes: List of field codes: httphttp://://wwwwww..ncbincbi..nlmnlm..nihnih..govgov//entrezentrez//queryquery//staticstatic//helphelp//Summary_MatricesSummary_Matrices..html#Search_Fields_and_Qualifiershtml#Search_Fields_and_Qualifiers
Boolean Operators:Boolean Operators:ANDANDORORNOTNOT
Note: do not use the field Protein name [PROT], only Note: do not use the field Protein name [PROT], only GENE!GENE!

1414
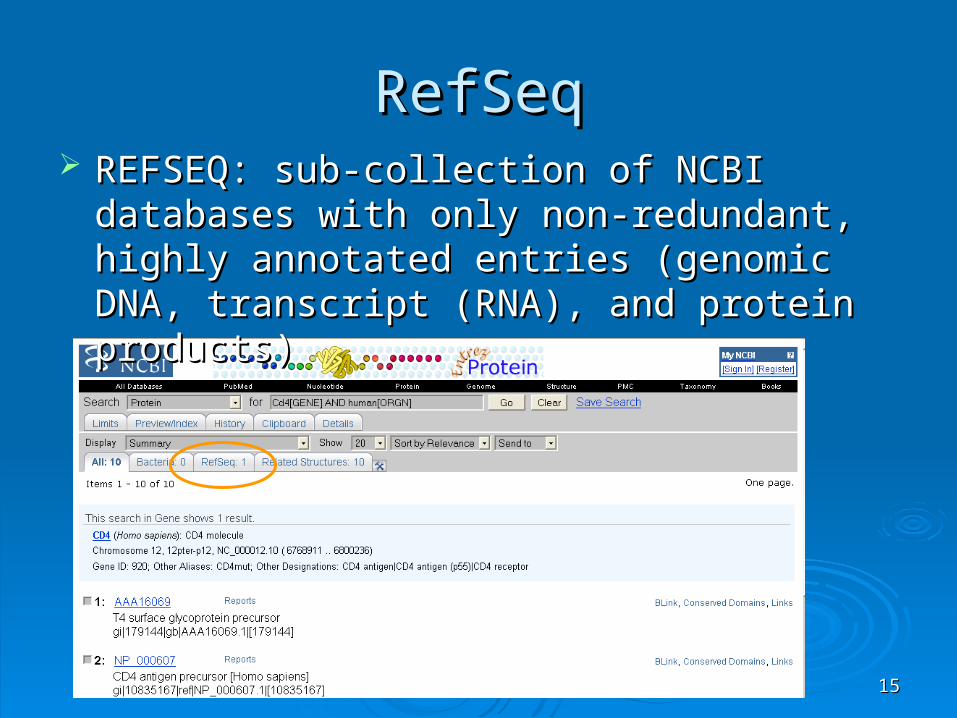
1515
RefSeqRefSeq REFSEQ: sub-collection of NCBI databases with REFSEQ: sub-collection of NCBI databases with
only non-redundant, highly annotated entries only non-redundant, highly annotated entries (genomic DNA, transcript (RNA), and protein (genomic DNA, transcript (RNA), and protein products)products)

1616

1717An explanation on GenBank records

1818
Accession NumbersAccession NumbersGenBankGenBank
EMBLEMBL
Two letters followed by six digits, e.g.:Two letters followed by six digits, e.g.:AY123456AY123456
One letter followed by five digits, eOne letter followed by five digits, e..gg.:.:U12345U12345
GenPept (a.a. GenPept (a.a. translations of translations of GenBank)GenBank)
Three letters and five digits, e.g.:Three letters and five digits, e.g.:AAA12345AAA12345
RefseqRefseqRefSeq accession numbers can be distinguished from RefSeq accession numbers can be distinguished from GenBank accessions by their prefix distinct format of GenBank accessions by their prefix distinct format of [[2 2 characters+underscorecharacters+underscore]], e.g.: , e.g.: NP_015325NP_015325..NM_: nucleotide, NP_: proteinNM_: nucleotide, NP_: protein
SWISSSWISS--PROTPROT
(another protein (another protein database)database)
All are six charactersAll are six characters::Character/FormatCharacter/Format1 [O,P,Q] 2 [0-9] 3 [A-Z,0-9] 4 [A-Z,0-9]1 [O,P,Q] 2 [0-9] 3 [A-Z,0-9] 4 [A-Z,0-9]5 [A-Z,0-9] 6 [0-9] 5 [A-Z,0-9] 6 [0-9] e.g.:e.g.:P12345P12345 and and Q9JJS7Q9JJS7
PDB (Protein Data PDB (Protein Data Bank – structure Bank – structure database)database)
one digit followed by three letters, eone digit followed by three letters, e..gg.:.:1hxw1hxw

1919
Swiss-ProtSwiss-Prot
A protein sequence database which A protein sequence database which strives to provide a high level of strives to provide a high level of annotation:annotation:* the function of a protein* the function of a protein* domains structure* domains structure* post* post--translational modificationstranslational modifications* variants* variants
One entry for each proteinOne entry for each protein

2020

2121
GenBank Vs. Swiss-ProtGenBank Vs. Swiss-Prot
GenBank results Swiss-Prot results

2222
Downloading a sequence & Fasta formatDownloading a sequence & Fasta format
Fasta formatFasta format
> gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLTKGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLTLTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSIVYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
Save Accession Numbers for future use (makes searching quicker):Refseq: NP_000607.1Swiss-Prot: P01730

2323

2424
PDBPDB:: Protein Data Bank Protein Data Bank
Main database of 3D structuresMain database of 3D structures Includes ~47,000 entries (Includes ~47,000 entries (proteinsproteins, ,
nucleic acids, others)nucleic acids, others) Proteins organized in groups, families etc.Proteins organized in groups, families etc. Is highly redundantIs highly redundant http://www.rcsb.orghttp://www.rcsb.org

2525
CD4 in complex with gp120CD4 in complex with gp120
gp120
CD4
PDB ID 1G9M

2626
Model organisms have independent database:Model organisms have independent database:
Organism specific databasesOrganism specific databases
HIV database http://hiv-web.lanl.gov/content/index

2727
GenecardsGenecards
All in one database of human genes (a All in one database of human genes (a project by Weizmann institute) project by Weizmann institute)
Attempts to integrate as many as possible Attempts to integrate as many as possible databases, publications and all available databases, publications and all available knowledgeknowledge
httphttp://://wwwwww..genecardsgenecards..orgorg

2828

2929
SummarySummary
General and comprehensive databases:General and comprehensive databases: NCBI, EMBL, DDBJNCBI, EMBL, DDBJ
Genome specific databases:Genome specific databases: ENSEMBL, UCSC genome browserENSEMBL, UCSC genome browser
Highly annotated databases:Highly annotated databases: Human genesHuman genes
• Genecards Genecards Proteins:Proteins:
• Swiss-Prot, RefseqSwiss-Prot, Refseq Structures:Structures:
• PDBPDB

3030
The MOST important of allThe MOST important of all
1.1.GoogleGoogle (or any search engine) (or any search engine)

3131
And always rememberAnd always remember::
2.2.RT(F)MRT(F)M – –
Read the manual!!Read the manual!!

3232
HelpHelp!!
Read the Help sectionRead the Help section Read the FAQ sectionRead the FAQ section Google the question!Google the question!

3333
|| || ||||| ||| || || |||||||||||||||||||MVHLTPEEKTAVNALWGKVNVDAVGGEALGRLLVVYPWTQRFFE…
ATGGTGAACCTGACCTCTGACGAGAAGACTGCCGTCCTTGCCCTGTGGAACAAGGTGGACGTGGAAGACTGTGGTGGTGAGGCCCTGGGCAGGTTTGTATGGAGGTTACAAGGCTGCTTAAGGAGGGAGGATGGAAGCTGGGCATGTGGAGACAGACCACCTCCTGGATTTATGACAGGAACTGATTGCTGTCTCCTGTGCTGCTTTCACCCCTCAGGCTGCTGGTCGTGTATCCCTGGACCCAGAGGTTCTTTGAAAGCTTTGGGGACTTGTCCACTCCTGCTGCTGTGTTCGCAAATGCTAAGGTAAAAGCCCATGGCAAGAAGGTGCTAACTTCCTTTGGTGAAGGTATGAATCACCTGGACAACCTCAAGGGCACCTTTGCTAAACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAATTTCAAGGTGAGTCAATATTCTTCTTCTTCCTTCTTTCTATGGTCAAGCTCATGTCATGGGAAAAGGACATAAGAGTCAGTTTCCAGTTCTCAATAGAAAAAAAAATTCTGTTTGCATCACTGTGGACTCCTTGGGACCATTCATTTCTTTCACCTGCTTTGCTTATAGTTATTGTTTCCTCTTTTTCCTTTTTCTCTTCTTCTTCATAAGTTTTTCTCTCTGTATTTTTTTAACACAATCTTTTAATTTTGTGCCTTTAAATTATTTTTAAGCTTTCTTCTTTTAATTACTACTCGTTTCCTTTCATTTCTATACTTTCTATCTAATCTTCTCCTTTCAAGAGAAGGAGTGGTTCACTACTACTTTGCTTGGGTGTAAAGAATAACAGCAATAGCTTAAATTCTGGCATAATGTGAATAGGGAGGACAATTTCTCATATAAGTTGAGGCTGATATTGGAGGATTTGCATTAGTAGTAGAGGTTACATCCAGTTACCGTCTTGCTCATAATTTGTGGGCACAACACAGGGCATATCTTGGAACAAGGCTAGAATATTCTGAATGCAAACTGGGGACCTGTGTTAACTATGTTCATGCCTGTTGTCTCTTCCTCTTCAGCTCCTGGGCAATATGCTGGTGGTTGTGCTGGCTCGCCACTTTGGCAAGGAATTCGACTGGCACATGCACGCTTGTTTTCAGAAGGTGGTGGCTGGTGTGGCTAATGCCCTGGCTCACAAGTACCATTGA
MVNLTSDEKTAVLALWNKVDVEDCGGEALGRLLVVYPWTQRFFE…
Alignment teaserAlignment teaser……

3434
Pairwise Pairwise Sequence Sequence AlignmentAlignment

3535
What is sequence alignmentWhat is sequence alignment??
Alignment: Alignment: Comparing two (pairwise) or Comparing two (pairwise) or more (multiple) sequences. Searching for more (multiple) sequences. Searching for a series of identical or similar characters in a series of identical or similar characters in the sequences.the sequences.
MVNLTSDEKTAVLALWNKVDVEDCGGE|| || ||||| ||| || || ||MVHLTPEEKTAVNALWGKVNVDAVGGE

3636
Why sequence alignment?Why sequence alignment?
Predict characteristics of a protein – Predict characteristics of a protein –
use the structure or function information on use the structure or function information on known proteins with similar sequences available known proteins with similar sequences available in databases in order to predict the structure or in databases in order to predict the structure or function of an unknown proteinfunction of an unknown protein
Assumptions: similar sequences Assumptions: similar sequences produce similar proteinsproduce similar proteins

3737
Local vs. GlobalLocal vs. Global Global alignmentGlobal alignment – finds the best – finds the best
alignment across the alignment across the wholewhole two two sequences.sequences.
Local alignmentLocal alignment – finds regions of – finds regions of high similarity in high similarity in partsparts of the of the sequences.sequences.
ADLGAVFALCDRYFQ|||| |||| |ADLGRTQN-CDRYYQ
ADLG CDRYFQ|||| |||| |ADLG CDRYYQ

3838
In the course of evolution, the sequences changed In the course of evolution, the sequences changed from the ancestral sequence by random mutationsfrom the ancestral sequence by random mutations
Three types of changes:Three types of changes:1.1. InsertionInsertion - AAGA - AAGA AAG AAGTTAA
Sequence evolutionSequence evolution
AAGAAGAA
InsertionInsertion

3939
In the course of evolution, the sequences changed In the course of evolution, the sequences changed from the ancestral sequence by random mutationsfrom the ancestral sequence by random mutations
Three types of Three types of changeschanges : :1.1. InsertionInsertion - AAGA - AAGA AAG AAGTTAA
2.2. DeletionDeletion - - AAAAGAGA AGA AGA
Sequence evolutionSequence evolution
AA AGAG
DeletionDeletion
AA

4040
In the course of evolution, the sequences In the course of evolution, the sequences changed from the ancestral sequence by changed from the ancestral sequence by random mutationsrandom mutations
Three types of mutations:Three types of mutations:
1.1. InsertionInsertion - AAGA - AAGA AAG AAGTTAA
2.2. DeletionDeletion - A - AAAGAGA AGA AGA
3.3. SubstitutionSubstitution -- AA AAGGAA AA AACCAA
Evolutionary changes in sequencesEvolutionary changes in sequences
AAAA AA
SubstitutionSubstitution
GGCC
InsertionInsertion + + DeletionDeletion IndelIndel

4141
Sequence alignmentSequence alignment
AAGCTGAATTCGAAAGGCTCATTTCTGA
AAGCTGAATT-C-GAAAGGCT-CATTTCTGA-

4242
Scoring schemeScoring scheme
Match/mismatch scores: substitution matricesMatch/mismatch scores: substitution matrices Nucleic acids:Nucleic acids:
• Transition-transversionTransition-transversion Amino acids:Amino acids:
• Evolution (empirical data) based: (PAM, BLOSUM)Evolution (empirical data) based: (PAM, BLOSUM)• Physico-chemical properties based (Grantham, Physico-chemical properties based (Grantham,
McLachlan)McLachlan)
Gap penaltyGap penalty

4343
Amino Acid Scoring MatricesAmino Acid Scoring Matrices PAM matrices: PAM80, PAM120, PAM250PAM matrices: PAM80, PAM120, PAM250
The number with PAM matrices represent The number with PAM matrices represent evolutionary distance evolutionary distance
Greater numbers denote greater distancesGreater numbers denote greater distances Low PAM: strong similaritiesLow PAM: strong similarities High PAM: weak similaritiesHigh PAM: weak similarities
PAM120 for general use (40% identity)PAM120 for general use (40% identity) PAM60 for close relations (60% identity)PAM60 for close relations (60% identity) PAM250 for distant relations (20% identity)PAM250 for distant relations (20% identity)
If uncertain, try several different If uncertain, try several different matricesmatrices

4444
Amino Acid Scoring MatricesAmino Acid Scoring Matrices BLOSUM matrices: BLOSUM45, BLOSUM62, BLOSUM matrices: BLOSUM45, BLOSUM62,
BLOSUM80BLOSUM80 The number with BLOSUM matrices represent The number with BLOSUM matrices represent
average % identity average % identity Greater numbers denote greater identityGreater numbers denote greater identity Low BLOSUM: weak similaritiesLow BLOSUM: weak similarities High BLOSUM: strong similaritiesHigh BLOSUM: strong similarities
BLOSUM62 for general use BLOSUM62 for general use BLOSUM80 for close relations BLOSUM80 for close relations BLOSUM45 for distant relationsBLOSUM45 for distant relations
If uncertain, try several different matricesIf uncertain, try several different matrices

4545
Web servers for pairwise alignmentWeb servers for pairwise alignment

4646
BLAST 2 sequences (bl2Seq) at BLAST 2 sequences (bl2Seq) at NCBI NCBI
Produces the Produces the locallocal alignment of two given alignment of two given sequences using sequences using BLASTBLAST (Basic Local (Basic Local Alignment Search Tool)Alignment Search Tool) engine for local engine for local alignmentalignment
Does not use an optimal algorithm but a Does not use an optimal algorithm but a heuristicheuristic

4747
Back to NCBIBack to NCBI

4848
BLAST – bl2seqBLAST – bl2seq

4949
blastnblastn – nucleotide – nucleotide
blastpblastp – protein – protein
Bl2Seq - queryBl2Seq - query

5050
Bl2seq resultsBl2seq results

5151
Bl2seq resultsBl2seq results
MatchMatch DissimilarityDissimilarity GapsGaps SimilaritySimilarity Low Low
complexitycomplexity

5252
Bl2seq resultsBl2seq results::
Bits scoreBits score – A score for the alignment according – A score for the alignment according to the number of identities, similarities, etc.to the number of identities, similarities, etc.
Expected-score (E-value)Expected-score (E-value) –The number of –The number of alignments with the same score one can alignments with the same score one can “expect” to observe by chance when searching a “expect” to observe by chance when searching a database of a particular size. The closer the e-database of a particular size. The closer the e-value approaches zero, the greater the value approaches zero, the greater the confidence that the hit is realconfidence that the hit is real
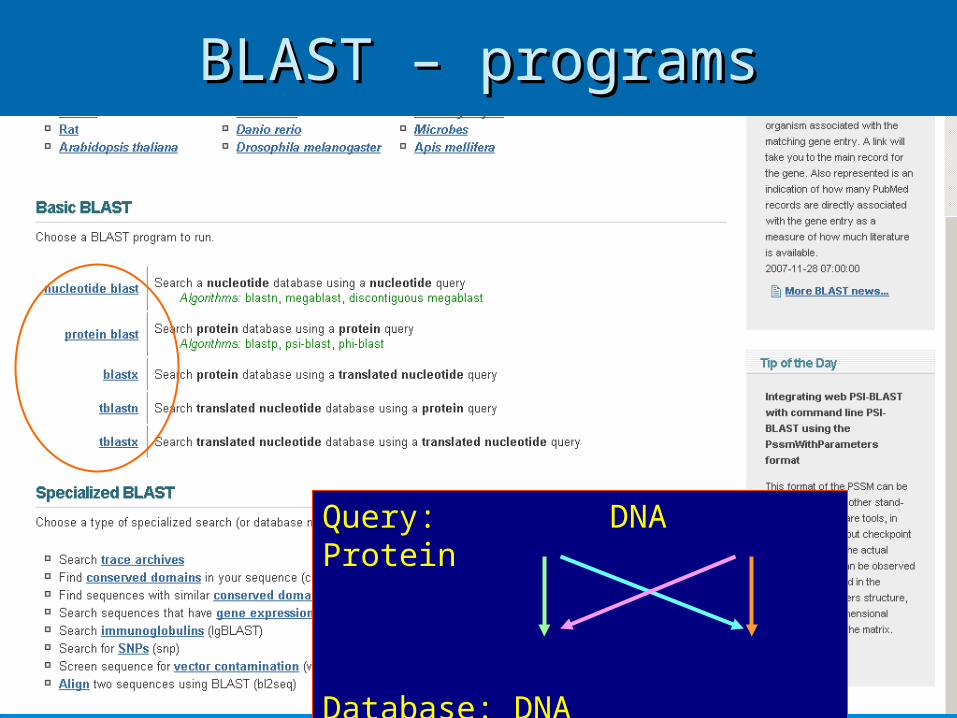
5353
BLAST – programsBLAST – programs
Query: DNA Protein
Database: DNA Protein

5454
BLAST – BlastpBLAST – Blastp

5555
Blastp - resultsBlastp - results

5656
Blastp – results (cont’)Blastp – results (cont’)

5757
Blastp – acquiring sequencesBlastp – acquiring sequences

5858
Blastp – acquiring sequences Blastp – acquiring sequences (cont’)(cont’)

5959
Fasta format – multiple sequencesFasta format – multiple sequences>gi|4504351|ref|NP_000510.1| delta globin [Homo sapiens] MVHLTPEEKTAVNALWGKVNVDAVGGEALGRLLVVYPWTQRFFESFGDLSSPDAVMGNPKVKAHGKKVLG AFSDGLAHLDNLKGTFSQLSELHCDKLHVDPENFRLLGNVLVCVLARNFGKEFTPQMQAAYQKVVAGVAN ALAHKYH
>gi|4504349|ref|NP_000509.1| beta globin [Homo sapiens] MVHLTPEEKSAVTALWGKVNVDEVGGEALGRLLVVYPWTQRFFESFGDLSTPDAVMGNPKVKAHGKKVLG AFSDGLAHLDNLKGTFATLSELHCDKLHVDPENFRLLGNVLVCVLAHHFGKEFTPPVQAAYQKVVAGVAN ALAHKYH
>gi|4885393|ref|NP_005321.1| epsilon globin [Homo sapiens] MVHFTAEEKAAVTSLWSKMNVEEAGGEALGRLLVVYPWTQRFFDSFGNLSSPSAILGNPKVKAHGKKVLT SFGDAIKNMDNLKPAFAKLSELHCDKLHVDPENFKLLGNVMVIILATHFGKEFTPEVQAAWQKLVSAVAI ALAHKYH
>gi|6715607|ref|NP_000175.1| G-gamma globin [Homo sapiens] MGHFTEEDKATITSLWGKVNVEDAGGETLGRLLVVYPWTQRFFDSFGNLSSASAIMGNPKVKAHGKKVLT SLGDAIKHLDDLKGTFAQLSELHCDKLHVDPENFKLLGNVLVTVLAIHFGKEFTPEVQASWQKMVTGVAS ALSSRYH
>gi|28302131|ref|NP_000550.2| A-gamma globin [Homo sapiens] MGHFTEEDKATITSLWGKVNVEDAGGETLGRLLVVYPWTQRFFDSFGNLSSASAIMGNPKVKAHGKKVLT SLGDATKHLDDLKGTFAQLSELHCDKLHVDPENFKLLGNVLVTVLAIHFGKEFTPEVQASWQKMVTAVAS ALSSRYH

6060
Searching for remote homologsSearching for remote homologs
Sometimes BLAST isn’t enoughSometimes BLAST isn’t enough Large protein family, and BLAST only finds Large protein family, and BLAST only finds
close members. We want more distant close members. We want more distant members members
PSI-BLASTPSI-BLAST Profile HMMs (not discussed)Profile HMMs (not discussed)

6161
PSI-BLASTPSI-BLAST
PPosition osition SSpecific pecific IIterated BLASTterated BLAST
Regular blast
Construct profile from blast results
Blast profile search
Final results

6262
PSI-BLASTPSI-BLAST
Advantage:Advantage: PSI-BLAST looks for seq’s PSI-BLAST looks for seq’s that are close to the query, and learns that are close to the query, and learns from them to extend the circle of friendsfrom them to extend the circle of friends
Disadvantage:Disadvantage: if we obtained a WRONG if we obtained a WRONG hit, we will get to unrelated sequences hit, we will get to unrelated sequences (contamination). This gets worse and (contamination). This gets worse and worse each iterationworse each iteration

6363
BLAST – PSI-BlastBLAST – PSI-Blast

6464
PSI-Blast - resultsPSI-Blast - results