1 chapter 10 query processing: the basics. 2 external sorting sorting is used in implementing many...
TRANSCRIPT

1
Chapter 10
Query Processing: The Basics

2
External Sorting
• Sorting is used in implementing many relational operations
• Problem: – Relations are typically large, do not fit in main memory
– So cannot use traditional in-memory sorting algorithms
• Approach used:– Combine in-memory sorting with clever techniques aimed at
minimizing I/O
– I/O costs dominate => cost of sorting algorithm is measured in the number of page transfers

3
External Sorting (cont’d)
• External sorting has two main components:– Computation involved in sorting records in
buffers in main memory– I/O necessary to move records between mass
store and main memory

4
Simple Sort Algorithm• M = number of main memory page buffers• F = number of pages in file to be sorted• Typical algorithm has two phases:
– Partial sort phase: sort M pages at a time; create F/M sorted runsruns on mass store, cost = 2F
Example: M = 2, F = 7run
Original file
Partially sorted file
5 3 2 6 1 10 15 7 20 11 8 4 7 5
2 3 5 6 1 7 10 15 4 8 11 20 5 7
5
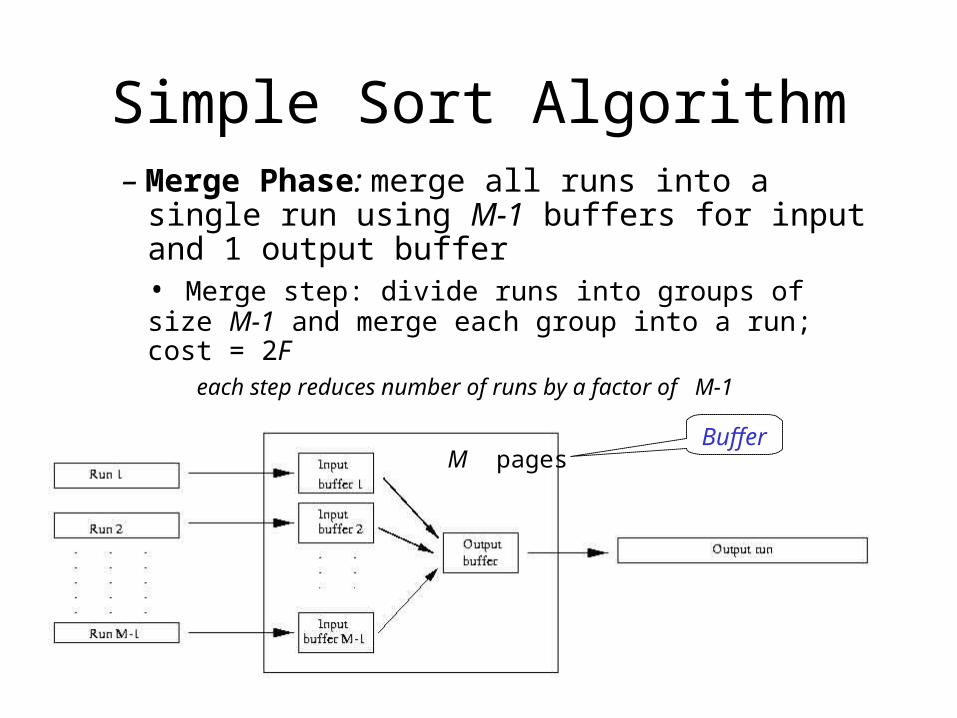
Simple Sort Algorithm– Merge Phase: merge all runs into a single run
using M-1 buffers for input and 1 output buffer• Merge step: divide runs into groups of size M-1 and merge each group into a run; cost = 2F
each step reduces number of runs by a factor of M-1
M pagesBuffer

6
Merge: An Example
2 3 5 6
1 7 10 15
Input buffersOutput buffer
1 2 3 5 6 7 10 15
2 3
1 7
5 6
10 15
1 23 56 710 15
Output runInput runs

7
Simple Sort Algorithm
• Cost of merge phase: – (F/M)/(M-1)k runs after k merge steps Log M-1(F/M) merge steps needed to merge an
initial set of F/M sorted runs
– cost = 2F Log M-1(F/M) 2F(Log M-1F -1)
• Total cost = cost of partial sort phase + cost of merge phase 2F Log M-1F

8
Duplicate Elimination
• A major step in computing projection, union, and difference relational operators
• Algorithm:– Sort– At the last stage of the merge step eliminate
duplicates on the fly– No additional cost (with respect to sorting) in
terms of I/O

9
Duplicate elimination During Merge
2 3 5 6
1 3 5 15
Input buffersOutput buffer
1 2 3 5 6 15
2 3
1 3
5 6
5 15
1 23 56 15
Output runInput runs Last key used
1215356
Key 3 ignored: duplicate
Key 5 ignored: duplicate

10
Sort-Based Projection
• Algorithm:– Sort rows of relation at cost of 2F Log M-1F
– Eliminate unwanted columns in partial sort phase (no additional cost)
– Eliminate duplicates on completion of last merge step (no additional cost)
• Cost: the cost of sorting

11
Hash-Based Projection• Phase 1:
– Input rows– Project out columns– Hash remaining columns using a hash function with range 1…M-1
creating M-1 buckets on disk– Cost = 2F
• Phase 2: – Sort each bucket to eliminate duplicates– Cost (assuming a bucket fits in M-1 buffer pages) = 2F
• Total cost = 4F
M pages
Buffer

12
Computing Selection (attr op value)
• No index on attr:– If rows are not sorted on attr:
• Scan all data pages to find rows satisfying selection condition
• Cost = F
– If rows are sorted on attr and op is =, >, < then: • Use binary search (at log2 F ) to locate first data
page containing row in which (attr = value)
• Scan further to get all rows satisfying (attr op value)
• Cost = log2 F + (cost of scan)

13
Computing Selection (attr op value)
• Clustered B+ tree index on attr (for “=” or range search):
– Locate first index entry corresponding to a row in which (attr = value). CostCost = depth of tree
– Rows satisfying condition packed in sequence in successive data pages; scan those pages.
CostCost: number of pages occupied by qualifying rows
B+ treeindex entries(containing rows)that satisfycondition

14
Computing Selection (attr op value)
• Unclustered B+ tree index on attr (for “=” or range search):
– Locate first index entry corresponding to a row in which (attr = value).
CostCost = depth of tree
– Index entries with pointers to rows satisfying condition are packed in sequence in successive index pages
• Scan entries and sort record Ids to identify table data pages with qualifying rows
Any page that has at least one such row must be fetched once.
• CostCost: number of rows that satisfy selection condition

15
Unclustered B+ Tree Index
index entries (containingrow Ids) that satisfycondition
data page
Data file
B+ Tree

16
Computing Selection (attr = value)
• Hash index on attr (for “=” search only):– Hash on value. CostCost 1.2
• 1.2 – typical average cost of hashing (> 1 due to possible overflow chains)
• Finds the (unique) bucket containing all index entries satisfying selection condition
• Clustered index – all qualifying rows packed in the bucket (a few pages)
CostCost: number of pages occupies by the bucket
• Unclustered index – sort row Ids in the index entries to identify data pages with qualifying rows
Each page containing at least one such row must be fetched once
CostCost: min(number of qualifying rows in bucket, number of pages in file)

17
Computing Selection (attr = value)
• Unclustered hash index on attr (for equality search)
buckets
data pages

18
Access Path• Access pathAccess path is the notion that denotes algorithm +
data structure used to locate rows satisfying some condition
• Examples:– File scan: can be used for any condition– Hash: equality search; all search key attributes of hash
index are specified in condition– B+ tree: equality or range search; a prefix of the search
key attributes are specified in condition• B+ tree supports a variety of access paths
– Binary search: Relation sorted on a sequence of attributes and some prefix of that sequence is specified in condition

19
Access Paths Supported by B+ tree
• Example: Given a B+ tree whose search key is the sequence of attributes a2, a1, a3, a4
– Access path for search a1>5 AND a2=3 AND a3=‘x’ (R): find first entry having a2=3 AND a1>5 AND a3=‘x’ and scan leaves from there until entry having a2>3 or a3 ‘x’. Select satisfying entries
– Access path for search a2=3 AND a3 >‘x’ (R): locate first entry having a2=3 and scan leaves until entry having a2>3. Select satisfying entries
– Access path for search a1>5 AND a3 =‘x’ (R): Scan of R

20
Choosing an Access Path• SelectivitySelectivity of an access path = number of pages
retrieved using that path• If several access paths support a query, DBMS
chooses the one with lowest selectivity• Size of domain of attribute is an indicator of the
selectivity of search conditions that involve that attribute
• Example: CrsCode=‘CS305’ AND Grade=‘B’ (TranscriptTranscript)
– a B+ tree with search key CrsCode has lower selectivity than a B+ tree with search key Grade

21
Computing Joins• The cost of joining two relations makes the
choice of a join algorithm crucial• SimpleSimple block-nested loops block-nested loops join algorithm
for computing r A=B s
foreach page pr in r do foreach page ps in s do output pr A=B ps

22
Block-Nested Loops Join
• If r and s are the number of pages in r and s, the cost of algorithm is
r + r s + cost of outputting final result
– If r and s have 103 pages each,
cost is 103 + 103 * 103
– Choose smaller relation for the outer loop:• If r < s then r + r s < s + r s
Number of scans of relation s

23
Block-Nested Loops Join• Cost can be reduced to
r + (r/(M-2)) s + cost of outputting final result
by using M buffer pages instead of 1.
Number of scans of relation s

24
Block-Nested Loop Illustrated
Output buffer
s
r
Input buffer for s
Input buffer for r
… and so on
r s

25
Index-Nested Loop Join r A=B s
• Use an index on s with search key B (instead of scanning s) to find rows of s that match tr
– Cost Cost = r + r + cost of outputting final result
– Effective if number of rows of s that match tuples in r is small (i.e., is small) and index is clustered
foreach tuple tr in r do { use index to find all tuples ts in s satisfying tr.A=ts.B; output (tr, ts) }
Number of rows in r
avg cost of retrieving all rows in s that match tr

26
Sort-Merge Join r A=B s
sort r on A;sort s on B;while !eof(r) and !eof(s) do { Scan r and s concurrently until tr.A=ts.B=c; Output A=c(r)B=c (s) }
r
s
B=c (s)
A=c(r)

27
Join During Merge Illustrated
1 3p p
r
s
DA
BE
p p4 0
0 9q q
r9
8 7 3s s s
s7
t t2 5
u u u2 5 0
5 7u u
1 1v v
x0
1 3 1 3p p p pp p p p4 0 0 4
8 7 3s s ss s s7 7 7
5 7 5 7 5 7u u u u u uu u u u u u2 2 5 5 0 0
r A=B s

28
Cost of Sort-Merge Join• CostCost of sorting assuming M buffers: 2 r log M-1 r + 2 s log M-1 s
• CostCost of merging:– Scanning A=c(r) and B=c (s) can be combined with the last step of
sorting of r and s --- costs nothing– Cost of A=c(r)B=c (s) depends on whether A=c(r) can fit in the
buffer• If yes, this step costs 0 • In no, each A=c(r)B=c (s) is computed using block-nested join, so the
cost is the cost of the join. (Think why indexed methods or sort-merge are inapplicable to Cartesian product.)
• Cost of outputting the final result depends on the size of the result

29
Hash-Join r A=B s
• Step 1: Hash r on A and s on B into the same set of buckets
• Step 2: Since matching tuples must be in same bucket, read each bucket in turn and output the result of the join
• CostCost:: 3 (r + s ) + cost of output of final result– assuming each bucket fits in memory

30
Hash Join

31
Star Joins
• r cond1 r1 cond2
… condn rn
– Each cond i involves only the attributes of ri and r
r
r1
r2
r3
r4
r5
cond1 cond2
cond3
cond4
cond5
Star relationSatellite
relations

32
Star Join

33
Computing Star Joins
• Use join index join index (Chapter 11)– Scan r and the join index {<r,r1,…,rn>} (which is
a set of tuples of rids) in one scan
– Retrieve matching tuples in r1,…,rn
– Output result

34
Computing Star Joins• Use bitmap indicesbitmap indices (Chapter 11)
– Use one bitmapped join index, Ji , per each partial join
r condi ri
– Recall: Ji is a set of <v, bitmap>, where v is an rid of a tuple in ri and bitmap has 1 in k-th position iff k-th tuple of r joins with the tuple pointed to by v
1. Scan Ji and logically OR all bitmaps. We get all rids in r that join with ri
2. Now logically AND the resulting bitmaps for J1, …, Jn.3. Result: a subset of r, which contains all tuples that can
possibly be in the star join • Rationale: only a few such tuples survive, so can use indexed loops

35
Choosing Indices
• DBMSs may allow user to specify – Type (hash, B+ tree) and search key of index– Whether or not it should be clustered
• Using information about the frequency and type of queries and size of tables, designer can use cost estimates to choose appropriate indices
• Several commercial systems have tools that suggest indices– Simplifies job, but index suggestions must be verified

36
Choosing Indices – Example
• If a frequently executed query that involves selection or a join and has a large result set, use a clustered B+ tree index
Example: Retrieve all rows of TranscriptTranscript for StudId
• If a frequently executed query is an equality search and has a small result set, an unclustered hash index is best– Since only one clustered index on a table is possible,
choosing unclustered allows a different index to be clustered
Example: Retrieve all rows of TranscriptTranscript for (StudId, CrsCode)