1 a survey on text classification december 10, 2003 20033077 dongho kim kaist
TRANSCRIPT

1
A Survey on Text Classification
December 10, 200320033077 Dongho KimKAIST

2
Contents
Introduction Statistical Properties of Text Feature Selection Feature Space Reduction Classification Methods Using SVM and TSVM Hierarchical Text Classification Summary

3
Introduction
Text classification Assign text to predefined categories based on content Types of text
Documents (typical) Paragraphs Sentences WWW-Sites
Different types of categories By topic By function By author By style

4
Text Classification Example

5
Computer-Based Text Classification Technologies Naive word-matching (Chute, Yang, & Buntrock 1994)
Finding shared words between the text and names of categories
Weakest method Cannot capture any conceptually relation
Thesaurus-based matching (Lindberg & Humphreys 1990) Using lexical links Insensitive to the context High cost and low adaptivity across domains

6
Computer-Based Text Classification Technologies Empirical learning of term-category associations
Learning from a training set Fundamentally different from word-matching
Statistically capturing the semantic association between terms and categories
Context sensitive mapping from terms to categories For example,
Decision tree methods Bayesian belief networks Neural networks Nearest neighbor classification methods Least-squares regression techiniques

7
Statistical Properties of Text
There are stable, language-independent patterns in how people use natural language A few words occur very frequently;
most occur rarely In general
Top 2 words : 10~15% of all word occurrences
Top 6 words : 20% of all word occurrences
Top 50 words : 50% of all word occurrences
The 3332
And 2972
A 1775
To 1725
Of 1440
…
Tom 679
Most common words from Tom Sawyer
1
14

8
Statistical Properties of Text
The most frequent words in one corpus may be rare words in another corpus Example : ‘computer’ in CACM vs. National
Geographic Each corpus has a different, fairly small
“working vocabulary”
These properties hold in a wide range of languages

9
Statistical Properties of Text
Summary : Term usage is highly skewed, but in a
predictable pattern Why is it important to know the
characteristics of text? Optimization of data structures Statistical retrieval algorithms depend on them

10
Statistical Profiles
Can act as a summarization device Indicate what a document is about Indicate what a collection is about
1987 WSJ (132MB) 1991 Patent (254MB)
1989 AP (267MB)
stobb (1)stochast (1)stock (46704)stockad (5)stockard (3)stockbridg (2)stockbrok (351)stockbrokag (1)stockbrokerag (101)
sto (1)stochast (21)stochiometr (1)stociometr (1)stock (1910)stockbarg (30)stocker (211)stockholm (1)stockigt (4)
sto (7)sto1 (4)sto3 (1)stoaker (1)stoand (1)stober (6)stocholm (1)stock (28505)stock’ (6)

11
Zipf’s Law relates a term’s frequency to its rank Frequency 1/rank There is a constant such that Rank the terms in a vocabulary by frequency, in descending order
Empirical observation : Hence :
for English
Zipf’s Law
krankfrequency k
V
rrrr
r
pNfp
N
rf
1
1 and /
soccurrence wordofnumber total:
rank at termoffrequency :
1.0 ,/ ArApr
ANrfr
A
N
fp r
rr
10/Nk

12
Precision and Recall
Recall Percentage of all relevant
documents that are found by a search
Precision Percentage of retrieved
documents that are relevant
collectionin itemsrelevant of #
retrived itemsrelevant of #R
retrived items of #
retrived itemsrelevant of #P
retrieved
+-++-++-
%5.628/5
%5010/5
P
R
Evaluation Metrics

13
F-measure
Rewards results that keep recall and precision close together R=40, P=60. R/P average=50. F-measure=48 R=45, P=55. R/P average=50. F-measure=49.5
)(
)(2
RECALLPRESICION
RECALLPRECISIONF
Harmonic average of precision and
recall
Evaluation Metrics

14
Break Even Point
The point at which recall equals precision
Evaluation Metrics
Evaluation metric : The value of this
point

15
Term Weights: A Brief Introduction The words of a text are not equally indicative of its
meaning
Important: butterflies, monarchs, scientists, direction, compass
Unimportant : most, think, kind, sky, determine, cues, learn
Term weights reflect the (estimated) importance of each term
“Most scientists think that butterflies use the position of the sun in the sky as a kind of compass that allows them to determine which way is north. Scientists think that butterflies may use other cues, such as the
earth’s magnetic field, but we have a lot to learn about monarchs’ sense of direction.”
Feature Selection

16
Term Weights
Term frequency (TF) The more often a word occurs in a document,
the better that term is in describing what the document is about
Often normalized, e.g. by the length of the document
Sometimes biased to range [0.4..1.0] to represent the fact that even a single occurrence of a term is a significant event
lengthdocavglengthdoc
tf
tfTF
tf
tfTF
lengthdoc
tfTF
d
___
5.15.0
max
_
Feature Selection

17
Term Weights
Inverse document frequency (IDF) Terms that occur in many documents in the collection are less us
eful for discriminating among documents Document frequency (df) : number of documents containing the t
erm IDF often calculated as
TF and IDF are used in combination as product
1log
df
NIDF
IDFTFxi
Feature Selection

18
Vector Space Similarity
Similarity is inversely related to the angle between the vectors
Cosine of the angle between the two vectors
22ii
ii
yx
yx
Feature Selection

19
Feature Space Reduction
Main reasons Improve accuracy of the algorithm Decrease the size of data set Control the computation time Avoid overfitting
Feature space reduction technique Stopword removal, stemming Information gain Natural language processing

20
Stopword Removal
Stopwords : words that are discarded from a document representation Function words : a, an, and, as, for, in, of, the, to, … About 400 words in English Other frequent words : ‘Lotus’ in a Lotus Support
Feature Space Reduction

21
Stemming
Group morphological variants Plural : ‘streets’ ‘street’ Adverbs : ‘fully’ ‘full’ Other inflected word forms : ‘goes’ ‘go’ Grouping process is called “conflation”
Current stemming algorithms make mistakes Conflating terms manually is difficult, time-consuming Automatic conflation using rules
Porter Stemmer Porter stemming example : ‘police’, ‘policy’ ‘polic’
Feature Space Reduction

22
Information Gain
Measuring information obtained by presence or absence of a term in a document
Feature space reduction by thresholding Biased to common term large reduction in size of data
set cannot be achieved
term:
)1(category th :
t
miici
m
i
m
i
m
iiiiiii
iii
tcptcptptcptcptpcpcp
tcptptcptpcptIG
1 1 1
))|(log()|()())|(log()|()())(log()(
))|( of(entropy )())|( of(entropy )())( ofentropy ()(
Feature Space Reduction

23
Natural Language Processing
Pick out the important words from a document For example, nouns, proper nouns, or verbs Ignoring all other parts Not biased to common terms reduction in
bath feature space and size of data Named entities
The subset of proper nouns consisting of people, locations, and organization
Effective in cases of news story classification
Feature Space Reduction

24
Experimental Results
Data set From six news media sources
Two print sources (New York Times and Associated Press Wire)
Two television sources (ABC World News Tonight and CNN Headline News)
Two radio sources (Public Radio International and Voice of America)
Robert Cooley, Classification of News Stories Using Support Vector Machines,Proceedings of the 16th International Joint Conference on Artificial Intelligence Text Mining Workshop, 1999

25
Experimental Results
Results
NLP significant loss in recall and precision SVM >> kNN (using full text or information gain) Binary weighting significant loss in recall
Robert Cooley, Classification of News Stories Using Support Vector Machines,Proceedings of the 16th International Joint Conference on Artificial Intelligence Text Mining Workshop, 1999

26
kNN
Stands for k-nearest neighbor classification Algorithms
Given a test document,1. Find k nearest neighbors among training documents2. Calculate and sort score of candidate categories3. Thresholding on these scores
Decision rule
jjii
kNNdi bcdydxsimsigncxy
i
),(),(),(
thresholdspecific-category :
document training theand document test ebetween th similarity the: ),(
}1,0{),(
j
ii
ji
b
dxdxsim
cdy
Classification Methods

27
LLSF
Stands for Linear Least Squares Fit Obtain matrix of word-category regression coeffici
ents by LLSF FLS : arbitrary document vector of weighted cat
egories By thresholding like kNN, assign categories
2minarg BFAFF
LS
matrixsolution :
)ut vectorsinput/outp ofpair a is columns ding(correspon data training: ,
LSF
BA
Classification Methods

28
Naïve Bayes
Assumption Words are drawn randomly from class
dependent lexicons (with replacement) Word independence
Result
xl
ii
i
x
YwWPYxXP
iw
xl
1
)|()|(
document in the th word- the:
document in the wordsofnumber total:
1- classpredict else,-
)1|()1()1|()1(
if 1 classpredict -
11
xx l
ii
l
ii YwWPYPYwWPYP
Classification Methods
Classification rule
Word independence

29
Estimating the Parameters
Count frequencies in training data
Estimating P(Y) Fraction of positive / negative examples in training data
Estimating P(W|Y) Smoothing with Laplace estimate
Naïve Bayes
yl
ywywTF
negpos
n
y classin documentsin occuring wordsofnumber : -
classin occurs word timesofnumber : ),( -
examples trainingegativepositive/n ofnumber : / -
examples trainingofnumber : -
n
negYP
n
posYP )1(ˆ )1(ˆ
2
1),()|(ˆ
yl
ywTFyYwWP

30
Experiment ResultsYiming Yang and Xin Liu, A re-examination of text categorization methods,Proceedings of ACM SIGIR Conference on Research and Development in Information Retrieval, 1999.

31
Text Classification using SVM
A statistical learning model of text classification with SVMs:
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.
0 if linearly separable

32
Properties 1+2: Sparse Examples in High Dimension High dimensional feature vectors (30,000 features) Sparse document vectors : only a few words of the whole language
occur in each document SVMs use overfitting protection which does not depend on the dim
ension of feature
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.

33
Property 3: Heterogeneous Use of Words
No pair of documents shares any words, but ‘it’, ‘the’, ‘and’, ‘of’, ‘for’, ‘an’, ‘a’, ‘not’, ‘that’, ‘in’.
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.

34
Property 4: High Level of Redundancy
Few features are irrelevant!: Feature space reduction causes loss of information
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.

35
Property 5: ‘Zipf’s Law’
Most words occur very infrequently!
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.

36
TCat ConceptsT. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.
occurences contains example negative -
occurences contains example positive -
features includesset th -
])::[],...,::([ 111
i
i
i
sss
n
p
fi
fnpfnpTCat
TCat([20:20:100], # high freq. [4:1:200],[1:4:200],[5:5:600]. # medium freq. [9:1:3000],[1:9:3000],[10:10:4000] # low freq. )
Modeling real text-classification tasksUsed for previous proof

37
Margin of Tcat-Concepts
By Zipf’s law, we can bound R2
Intuitively, many words with low frequency relatively short document vectors
TCat ConceptsT. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.
cba
bac
2
22
s
i i
i
s
i i
ii
s
i i
i
f
nc
f
npb
f
pa
1
2
1
1
2
margin : with
0 0 0
,|),(| Inequality Schwarz-Cauchyby 2
ibac
yxyx
Linearly separable

38
TCat ConceptsT. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines,Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.
sphere enclosing of radius the: R
otherwise 1'
)/(1 if '
1
'
))((
2
22
1
12
2
CRC
RCCRC
n
ECR
E
hErrE
n
ii
SVMn
Bound on Expected Error of SVM

39
Text Classification using TSVM
How would you classify the test set?
Training set {D1, D6} Test set {D2, D3, D4, D5}
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines,Proceedings of the International Conference on Machine Learning (ICML), 1999.
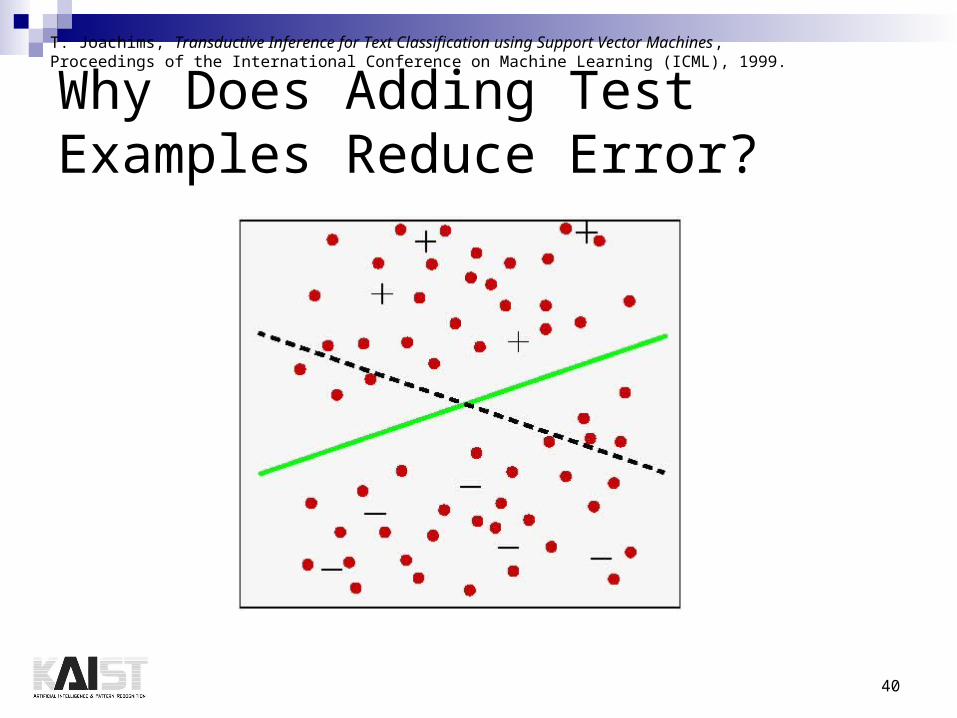
40
Why Does Adding Test Examples Reduce Error?
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines,Proceedings of the International Conference on Machine Learning (ICML), 1999.

41
Experiment Results
Data set Reuter-21578 dataset-ModApte
Training : 9,603 test : 3,299 WebKB collection of WWW pages
Only the class ‘course’, ‘faculty’, ‘project’, ‘student’ are used Stemming and stopword removal are not used
Ohsumed corpus compiled by William Hersh Training : 10,000 test : 10,000
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines,Proceedings of the International Conference on Machine Learning (ICML), 1999.

42
Experiment Results
Results
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines,Proceedings of the International Conference on Machine Learning (ICML), 1999.
P/R-breakeven point for Reuters categories

43
Experiment Results
Results
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines,Proceedings of the International Conference on Machine Learning (ICML), 1999.
Average P/R-breakeven point on WebKB Average P/R-breakeven point on Ohsumed

44
documents
documents
Hierarchical Text Classification
Real world classification complex hierarchical structure
Due to difficulties of training for many classes or features
Class 1Class 1
Class 2Class 2
Class 3Class 3
Level 1
…
Level 2
Class 1-1Class 1-1
Class 1-2Class 1-2
Class 1-3Class 1-3
Class 2-1Class 2-1
…
…

45
Hierarchical Text Classification
More accurate specialized classifiers
documents
documents
ComputersComputers
SportsSports
Hardware
Hardware
SoftwareSoftware
ChatChat
SoccerSoccer
FootballFootball‘computer’ :
discriminating
‘computer’ : not discriminating

46
Experiment Setting
Data set : LookSmart’s web directory Using short summary from
search engine 370597 unique pages 17173 categories 7-level hierarchy Focus on 13 top-level and 1
50 second-level categories
S. Dumais and H. Chen, Hierarchical classification of Web content. Proceedings of SIGIR'00, August 2000, pp. 256-263.

47
Experiment Setting
Using SVM Posterior probabilities by regularized
maximum likelihood fitting Combining probabilities from the first and
second level Boolean scoring function, P(L1) && P(L2) or, Multiplicative scoring function, P(L1) * P(L2)
S. Dumais and H. Chen, Hierarchical classification of Web content. Proceedings of SIGIR'00, August 2000, pp. 256-263.

48
Experiment Results
Non-hierarchical (baseline) : F1 = 0.476 Hierarchical
Top-level Training set : F1 = 0.649 Test set : F1 = 0.572
Second-level Multiplicative : F1 = 0.495 Boolean : F1 = 0.497
Assuming top-level classification is correct, F1 = 0.711
S. Dumais and H. Chen, Hierarchical classification of Web content. Proceedings of SIGIR'00, August 2000, pp. 256-263.

49
Summary
Feature space reduction Performance of SVM and TSVM is better
than others TSVM has merits in text classification Hierarchical classification is helpful Other issues
Sampling strategies Other kinds of feature selection

50
Reference T. Joachims, Text Categorization with Support Vector Machines: Learning
with Many Relevant Features. Proceedings of the European Conference on Machine Learning (ECML), Springer, 1998.
T. Joachims, Transductive Inference for Text Classification using Support Vector Machines. Proceedings of the International Conference on Machine Learning (ICML), 1999.
T. Joachims, A Statistical Learning Model of Text Classification with Support Vector Machines. Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR), ACM, 2001.
Robert Cooley, Classification of News Stories Using Support Vector Machines (1999). Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence Text Mining Workshop, August 1999.
Yiming Yang and Xin Liu, A re-examination of text categorization methods. Proceedings of ACM SIGIR Conference on Research and Development in Information Retrieval, (SIGIR), 1999.
S. Dumais and H. Chen, Hierarchical classification of Web content. Proceedings of SIGIR'00, August 2000, pp. 256-263.