1 a scalable information management middleware for large distributed systems praveen yalagandula hp...
TRANSCRIPT

1
A Scalable Information Management Middleware for Large Distributed Systems
Praveen Yalagandula
HP Labs, Palo Alto
Mike Dahlin, The University of Texas at Austin

2
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

3
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

4
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

5
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

6
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

7
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

8
Trends Large wide-area networked systems
Enterprise networks IBM
170 countries > 330000 employees
Computational Grids NCSA Teragrid
10 partners and growing 100-1000 nodes per site
Sensor networks Navy Automated Maintenance Environment
About 300 ships in US Navy 200,000 sensors in a destroyer [3eti.com]

9
Research Vision
Security
Wide-area Distributed Operating System
Goals:
Ease building
applications
Utilize resources efficiently
MonitoringData
Management
Scheduling ......Information Management
Information Management

10
Information Management Most large-scale distributed applications
Monitor, query, and react to changes in the system Examples:
A general information management middleware Eases design and development Avoids repetition of same task by different applications Provides a framework to explore tradeoffs Optimizes system performance
Job Scheduling System administration and management Service location Sensor monitoring and control
File location service Multicast service Naming and request routing ……

11
Contributions – SDIMS
Meets key requirements Scalability
Scale with both nodes and information to be managed
Flexibility Enable applications to control the aggregation
Autonomy Enable administrators to control flow of
information Robustness
Handle failures gracefully
Scalable Distributed Information Management System

12
SDIMS in Brief Scalability
Hierarchical aggregation Multiple aggregation trees
Flexibility Separate mechanism from policy
API for applications to choose a policy A self-tuning aggregation mechanism
Autonomy Preserve organizational structure in all aggregation
trees
Robustness Default lazy re-aggregation upon failures On demand fast reaggregation

13
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

14
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

15
Attributes Information at machines
Machine status information File information Multicast subscription information ……
Attribute ValuenumUsers 5
cpuLoad 0.5
freeMem 567MB
totMem 2GB
fileFoo yes
mcastSess1 yes

16
Aggregation Function Defined for an attribute Given values for a set of nodes
Computes aggregate value
Examples Total users logged in the system
Attribute – numUsers Aggregation function – summation

17
Aggregation Trees Aggregation tree
Physical machines are leaves Each virtual node represents a logical group of machines
Administrative domains Groups within domains
Aggregation function, f, for attribute A Computes the aggregated value Ai for level-i subtree
A0 = locally stored value at the physical node or NULL Ai = f(Ai-1
0, Ai-11, …, Ai-1
k) for virtual node with k children
Each virtual node is simulated by some machines
a b c dA0
A1
A2
f(a,b) f(c,d)
f(f(a,b), f(c,d))

18
Example Queries
Job scheduling system Find the least loaded machine Find a (nearby) machine with load < 0.5
File location system Locate a (nearby) machine with file “foo”

19
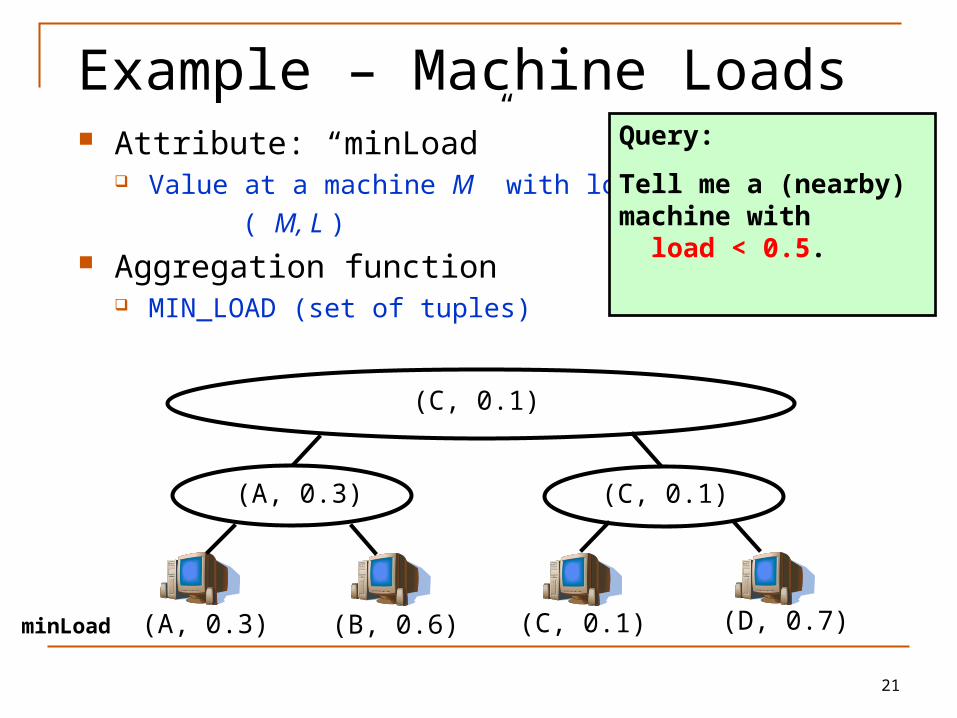
Example – Machine Loads Attribute: “minLoad”
Value at a machine M with load L is ( M, L )
Aggregation function MIN_LOAD (set of tuples)
(C, 0.1)
(A, 0.3) (C, 0.1)
(A, 0.3) (B, 0.6) (C, 0.1) (D, 0.7)minLoad

20
Example – Machine Loads Attribute: “minLoad”
Value at a machine M with load L is ( M, L )
Aggregation function MIN_LOAD (set of tuples)
(C, 0.1)
(A, 0.3) (C, 0.1)
(A, 0.3) (B, 0.6) (C, 0.1) (D, 0.7)minLoad
Query:
Tell me the least loaded machine.
21
Example – Machine Loads Attribute: “minLoad”
Value at a machine M with load L is ( M, L )
Aggregation function MIN_LOAD (set of tuples)
(C, 0.1)
(A, 0.3) (C, 0.1)
(A, 0.3) (B, 0.6) (C, 0.1) (D, 0.7)minLoad
Query:
Tell me a (nearby) machine with load < 0.5.

22
Example – File Location Attribute: “fileFoo”
Value at a machine with id machineId machineId if file “Foo” exists on the machine null otherwise
Aggregation function SELECT_ONE(set of machine ids)
B
B C
null B C nullfileFoo

23
Example – File Location Attribute: “fileFoo”
Value at a machine with id machineId machineId if file “Foo” exists on the machine null otherwise
Aggregation function SELECT_ONE(set of machine ids)
B
B C
null B C nullfileFoo
Query:
Tell me a (nearby) machine with file “Foo”.

24
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

25
Scalability To be a basic building block, SDIMS should
support
Large number of machines (> 104) Enterprise and global-scale services
Applications with a large number of attributes (> 106) File location system
Each file is an attribute Large number of attributes

26
Scalability Challenge Single tree for aggregation
Astrolabe, SOMO, Ganglia, etc. Limited scalability with attributes Example: File Location
f1, f2
f2, f3
f4, f5
f6, f7
f1, f2, f3 f4,f5,f6,f7
f1,f2,…,f7

27
Scalability Challenge Single tree for aggregation
Astrolabe, SOMO, Ganglia, etc. Limited scalability with attributes Example: File Location
f1, f2
f2, f3
f4, f5
f6, f7
f1, f2, f3 f4,f5,f6,f7
f1,f2,…,f7Automatically build multiple trees for aggregationAggregate different attributes along different trees

28
Building Aggregation Trees Leverage Distributed Hash Tables
A DHT can be viewed as multiple aggregation trees
Distributed Hash Tables (DHT) Supports hash table interfaces
put (key, value): inserts value for key get (key): returns values associated with key
Buckets for keys distributed among machines Several algorithms with different properties
PRR, Pastry, Tapestry, CAN, CHORD, SkipNet, etc. Load-balancing, robustness, etc.

29
DHT - Overview Machine IDs and keys: Long bit vectors Owner of a key = Machine with ID closest to the
key Bit correction for routing Each machine keeps O(log n) neighbors
10010 10111
11000
11101
0110001001
0011000001
Key = 11111
get(11111)

30
DHT Trees as Aggregation Trees
010 001100 101110 111011000
1xx
11x
111
Key = 11111

31
DHT Trees as Aggregation Trees
010 001100 101110 111011000
1xx
11x
111
Mapping from virtual nodes to real machines
Key = 11111

32
DHT Trees as Aggregation Trees
010 001100 101110 111011000
1xx
11x
111
010 001100 101110 111011000
0xx
00x
000
Key = 11111
Key = 00010 010 001100 101110 111011000
1xx
11x
111

33
DHT Trees as Aggregation Trees
010 001100 101110 111011000
0xx
00x
000
Key = 11111
Key = 00010 010 001100 101110 111011000
1xx
11x
111
Aggregate different attributes along different trees
hash(“minLoad”) = 00010 aggregate minLoad along tree for key
00010

34
Scalability
Challenge: Scale with both machines and attributes
Our approach Build multiple aggregation trees
Leverage well-studied DHT algorithms Load-balancing Self-organizing Locality
Aggregate different attributes along different trees Aggregate attribute A along the tree for key = hash(A)

35
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

36
Flexibility Challenge When to aggregate?
On reads? or on writes? Attributes with different read-write ratios
read-write ratio
#writes >> #reads
#reads >> #writes
CPU Load Total Mem
{File Location
Astrolabe Ganglia
Sophia MDS-2
DHT based systems
Best Policy
Aggregate on reads
Aggregate on writes
Partial Aggregation on writes

37
Flexibility Challenge When to aggregate?
On reads? or on writes? Attributes with different read-write ratios
read-write ratio
CPU Load Total Mem
{File Location
Astrolabe Ganglia
Sophia MDS
DHT based systems
Best Policy
Aggregate on reads
Aggregate on writes
Partial Aggregation on writesSingle framework – separate mechanism from
policy
Allow applications to choose any policy
Provide self-tuning mechanism
#writes >> #reads
#reads >> #writes

38
Install: an aggregation function for an attribute Function is propagated to all nodes Arguments up and down specify an aggregation policy
Update: the value of a particular attribute Aggregation performed according to the chosen policy
Probe: for an aggregated value at some level If required, aggregation is done Two modes: one-shot and continuous
Install
Update
Probe
API Exposed to Applications

39
Flexibility
Update-Local
Up=0 Down=0
Policy
Setting
Update-All
Up=all Down=all
Update-Up
Up=all Down=0

40
Flexibility
Update-Local
Up=0 Down=0
Policy
Setting
Update-All
Up=all Down=all
Update-Up
Up=all Down=0

41
Flexibility
Update-Local
Up=0 Down=0
Policy
Setting
Update-All
Up=all Down=all
Update-Up
Up=all Down=0

42
Flexibility
Update-Local
Up=0 Down=0
Policy
Setting
Update-All
Up=all Down=all
Update-Up
Up=all Down=0

43
Self-tuning Aggregation
Some apps can forecast their read-write rates
What about others? Can not or do not want to specify Spatial heterogeneity Temporal heterogeneity
Shruti: Dynamically tunes aggregation Keeps track of read and write patterns

44
Shruti – Dynamic Adaptation
Update-Up
Up=all Down=0
R
A

45
Shruti – Dynamic Adaptation
Update-Up
Up=all Down=0
A Lease based mechanism
Any updates are forwarded until lease is relinquished
R
A

46
Shruti – In Brief On each node
Tracks updates and probes Both local and from neighbors
Sets and removes leases
Grants leases to a neighbor A When gets k probes from A while no updates happen
Relinquishes leases from a neighbor A When gets m updates from A while no probes happen

47
Flexibility
Challenge Support applications with different read-write
behavior
Our approach Separate mechanism from policy Let applications specify an aggregation policy
Up and Down knobs in Install interface Provide a lease based self-tuning aggregation
strategy

48
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

49
Administrative Autonomy Systems spanning multiple administrative
domains
Allow a domain administrator control information flow Prevent external observer from observing the
information Prevent external failures from affecting the operations
Challenge DHT trees might not conform
A B C D

50
Administrative Autonomy
A B C D
Our approach: Autonomous DHTs Two properties
Path locality Path convergence
Ensure that virtual nodes aggregating data of a domain are hosted on machines in the domain
}

53
Robustness Large scale system failures are common
Handle failures gracefully Enable applications to tradeoff
Cost of adaptation, Response latency, and Consistency
Techniques Tree repair
Leverage DHT self-organizing properties Aggregated information repair
Default lazy re-aggregation on failures On-demand fast re-aggregation

54
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

55
Evaluation
SDIMS prototype Built using FreePastry DHT framework [Rice Univ.] Three layers
Methodology Simulation
Scalability and Flexibility Micro-benchmarks on real networks
PlanetLab and CS Department
Aggregation Mgmt.
Tree Topology Mgmt.
Autonomous DHT

56
Small multicast sessions with size 8 Node Stress = Amt. of incoming and outgoing
info
1
10
100
1000
10000
100000
1e+06
1e+07
1 10 100 1000 10000 100000
Nod
e S
tres
s
Number of sessions
MAX node stress with participant size 8
Simulation Results - Scalability
AS 256
AS 4096AS 65536
SDIMS 256
SDIMS 4096
SDIMS 65536
#machines
Max

57
Small multicast sessions with size 8 Node Stress = Amt. of incoming and outgoing
info
1
10
100
1000
10000
100000
1e+06
1e+07
1 10 100 1000 10000 100000
Nod
e S
tres
s
Number of sessions
MAX node stress with participant size 8
Simulation Results - Scalability
AS 256
AS 4096AS 65536
SDIMS 256
SDIMS 4096
SDIMS 65536
Max
Orders of magnitude difference in maximum node stress better load balance

58
Small multicast sessions with size 8 Node Stress = Amt. of incoming and outgoing
info
1
10
100
1000
10000
100000
1e+06
1e+07
1 10 100 1000 10000 100000
Nod
e S
tres
s
Number of sessions
MAX node stress with participant size 8
Simulation Results - Scalability
AS 256
AS 4096AS 65536
SDIMS 256
SDIMS 4096
SDIMS 65536
Decreasing max load
Increasing max load
Max

60
Simulation Results - Flexibility Simulation with 4096 nodes Attributes with different up and down
strategies
0.1
1
10
100
1000
10000
0.0001 0.01 1 100 10000
Num
ber
of m
essa
ges
per
oper
atio
n
Read to Write ratio
Update-Local
Update-Up
Update-All
Up=5, Down=0
Up=all, Down=5

61
Simulation Results - Flexibility Simulation with 4096 nodes Attributes with different up and down
strategies
0.1
1
10
100
1000
10000
0.0001 0.01 1 100 10000
Num
ber
of m
essa
ges
per
oper
atio
n
Read to Write ratio
Update-Local
Update-Up
Update-All
Up=5, Down=0
Up=all, Down=5
AstrolabeGanglia
DHT Based Systems
Sophia MDS-2

62
Simulation Results - Flexibility Simulation with 4096 nodes Attributes with different up and down
strategies
0.1
1
10
100
1000
10000
0.0001 0.01 1 100 10000
Num
ber
of m
essa
ges
per
oper
atio
n
Read to Write ratio
Update-Local
Update-Up
Update-All
Up=5, down=0
Up=all, Down=5
Writes dominate reads:
Update-local best
Reads dominate writes:
Update-All best
63
0.1
1
10
100
1000
10000
1e-04 0.001 0.01 0.1 1 10 100 1000
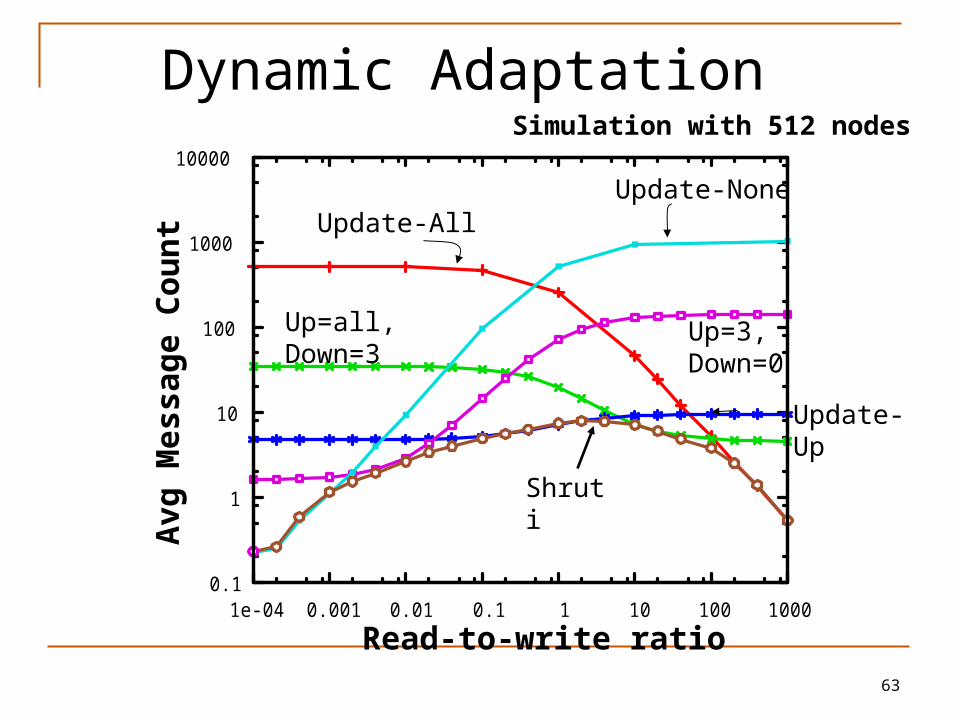
Dynamic Adaptation
Avg
Mes
sag
e C
ou
nt
Read-to-write ratio
Simulation with 512 nodes
Update-AllUpdate-None
Up=3, Down=0
Up=all, Down=3
Update-Up
Shruti

64
Prototype Results
CS department: 180 machines PlanetLab: 70 machines
Department Network
0
100
200
300
400
500
600
700
800
Update - All Update - Up Update - Local
Lat
ency
(m
s)
Planet Lab
0
500
1000
1500
2000
2500
3000
3500
Update - All Update - Up Update - Local

65
Outline SDIMS: a general information management middleware
Aggregation abstraction
SDIMS Design Scalability with machines and attributes Flexibility to accommodate various applications Autonomy to respect administrative structure Robustness to failures
Experimental results
SDIMS in other projects
Conclusions and future research directions

66
SDIMS in Other Projects
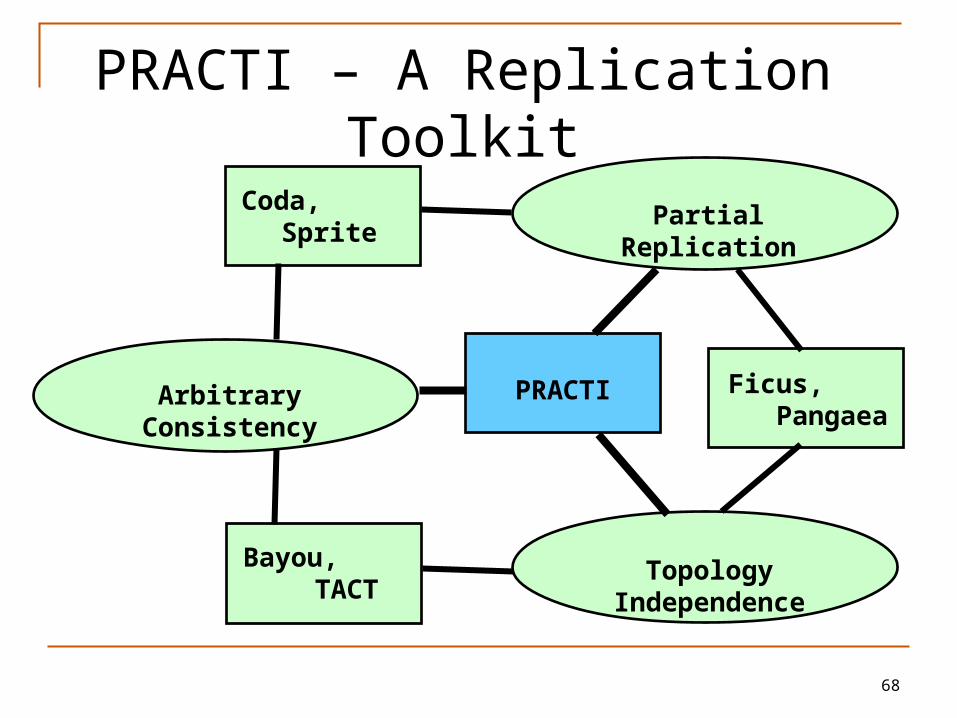
PRACTI – a replication toolkit (Dahlin et al)
Grid Services (TACC) Resource Scheduling Data management
INSIGHT: Network Monitoring (Jain and Zhang)
File location Service (IBM)
Scalable Sensing Service (HP Labs)
68
PRACTI – A Replication Toolkit
Partial Replication
Arbitrary Consistency
Topology Independence
Coda, Sprite
Bayou, TACT
Ficus, Pangaea
PRACTI

69
PRACTI Design
Core: Mechanism Controller: Policy
Notified of key events Read Miss, update arrival, invalidation arrival, …
Directs communication across cores
Controller Core
Inform
Mgmt.
read() write() delete()
Invals & Updates from/to other nodes

70
SDIMS Controller in PRACTI
Read Miss: For locating a replica Similar to “File Location System” example But handles flash crowds
Dissemination tree among requesting clients
For Writes: Spanning trees among replicas Multicast tree for spreading invalidations Different trees for different objects

71
0
5
10
15
20
25
30
35
Hand Tuned SDIMS
Phase IPhase IIPhase IIITotal
PRACTI – Grid Benchmark Three phases
Read input and programs Compute (some pairwise reads) Results back to server
Performance improvement: 21% reduction in
total time
Home
Grid at school

72
PRACTI Experience Aggregation abstraction and API generality
Construct multicast trees for pushing invalidations Locate a replica on a local read miss
Construct a tree in the case of flash crowds
Performance benefits Grid micro-benchmark: 21% improvement over
manual tree construction
Ease of implementation Less than two weeks

73
Conclusions
Research Vision Ease design and development of distributed
services
SDIMS – an information management middleware Scalability with both machines and attributes
An order of magnitude lower maximum node stress Flexibility in aggregation strategies
Support for a wide range of applications Autonomy Robustness to failures

74
Future Directions
Core SDIMS research Composite queries Resilience to temporary reconfigurations Probe functions
Other components of wide-area distributed OS Scheduling Data management Monitoring …
Security MonitoringData
Management
Scheduling ......Information Management

75
For more information:
http://www.cs.utexas.edu/users/ypraveen/sdims

76
SkipNet and Autonomy Constrained load balancing in Skipnet
Also single level administrative domains One solution: Maintain separate rings in
different domains
ece.utexas.edu
cs.utexas.edu phy.utexas.edu
Does not form trees because of revisits

77
Load Balance
Let f = fraction of attributes a node is interested in N = number of nodes in the system
In DHT -- node will have O(log (N)) indegree whp

78
Related Work Other aggregation systems
Astrolabe, SOMO, Dasis, IrisNet Single tree
Cone Aggregation tree changes with new updates
Ganglia, TAG, Sophia, and IBM Tivoli Monitoring System Database abstraction on DHTs
PIER and Gribble et al 2001 Support for “join” operation
Can be leveraged for answering composite queries

79
Load Balance How many attributes?
O(log N) levels Few children at each level Each node interested in few attributes Level 0: d Level 1: 2 x d / 2 = d Level 2: 2 * (d) / 2 = c^2 * d/4 … Total = d * [ 1+ c/2+c^2/4+……] = O(d * log
N)

82
SDIMS not yet another DHT system
Typical DHT applications Use put and get interfaces in hashtable
Aggregation as a general abstraction

83
0
2
4
6
8
10
12
14
16
10 100 1000 10000 100000
Per
cent
age
of v
iola
tions
Number of Nodes
Autonomy
Increase in path length Path Convergence violations
None in autonomous DHT
0
1
2
3
4
5
6
7
10 100 1000 10000 100000
Pat
h Le
ngth
Number of Nodes
bf=4bf=16bf=64
Pastry
bf=4
bf=16
bf=64
Pastry
ADHT
bf = branching factor or nodes per domain

84
0
2
4
6
8
10
12
14
16
10 100 1000 10000 100000
Per
cent
age
of v
iola
tions
Number of Nodes
Autonomy
Increase in path length Path Convergence violations
None in autonomous DHT
0
1
2
3
4
5
6
7
10 100 1000 10000 100000
Pat
h Le
ngth
Number of Nodes
bf=4bf=16bf=64
Pastry
bf=4
bf=16
bf=64
Pastry
ADHT
bf = branching factor or nodes per domain
bf tree height
bf #violations

85
Robustness Planet-Lab with 67 nodes
Aggregation function: summation; Strategy: Update-Up
Each node updates the attribute with value 10
10
100
1000
10000
100000
0 50 100 150 200 250 300 350 400 450 500 500
550
600
650
700
La
ten
cy
(in
ms
)
Va
lue
s O
bs
erv
ed
Time(in sec)
Valueslatency
Node Killed

86
Sparse attributes Attributes of interest to only few nodes
Example: A file “foo” in file location application Key for scalability
Challenge: Aggregation abstraction – one function per
attribute Dilemma
Separate aggregation function with each attribute Unnecessary storage and communication overheads
A vector of values with one aggregation function Defeats DHT advantage

87
Sparse attributes Attributes of interest to only few nodes
Example: A file “foo” in file location application Key for scalability
Challenge: Aggregation abstraction – one function per attribute Dilemma
Separate aggregation function with each attribute Unnecessary storage and communication overheads
A vector of values with one aggregation function Defeats DHT advantage
Attribute
Function Value
fileFooAggrFuncFileFoo
macID
fileBarAggrFuncFileBar
macID
…… ……… ……

88
Sparse attributes Attributes of interest to only few nodes
Example: A file “foo” in file location application Key for scalability
Challenge: Aggregation abstraction – one function per attribute Dilemma
Separate aggregation function with each attribute Unnecessary storage and communication overheads
A vector of values with one aggregation function Defeats DHT advantage
Attribute
Function Value
fileAggrFuncFileLoc
(“foo”, “bar”, ……)

89
Novel Aggregation Abstraction Separate attribute type from attribute
name Attribute = (attribute type, attribute name) Example: type=“fileLocation”, name=“fileFoo”
Define aggregation function for a typeAttr. Type Attr. Name ValuefileLocation fileFoo 1.1.1.1
fileLocation fileBar 1.1.1.1
MIN cpuLoad (macA, 0.3)
multicast mcastSess1 yes
IP addr: 1.1.1.1
Name: macA
Attr. TypeAggr Function
fileLocation SELECT_ONE
MIN MIN
multicast MULTICAST

90
Example – File Location Attribute: “fileFoo”
Value at a machine with id machineId machineId if file “Foo” exists on the machine null otherwise
Aggregation function SELECT_TWO (set of machine ids)
B, C
B C
null B C nullfileFoo
Query:
Tell me two machines with file “Foo”.

92
CS Department Micro-benchmark Experiment
10
100
1000
0 5 10 15 20 25 30 35 40 45 1500
1550
1600
1650
1700
1750
1800
1850
1900
Late
ncy
(in m
s)
Valu
es O
bser
ved
Time(in sec)
Failures and read performance (latencies and staleness)
Valueslatency
Node Killed