05 mining frequent patterns assoc and data correlations hh
TRANSCRIPT

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 1/110
January 18, 2012 Data Mining: Concepts and Techniques 1
Data Mining:Concepts and Techniques
Chapter 5
Hazem HajjSource: ©2006 Jiawei Han and Micheline Kamber, All rights reserved

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 2/110
January 18, 2012 Data Mining: Concepts and Techniques 2
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining methods
Simple case (Single level, single dimension, Boolean) rules
from transactional DBs Mining various kinds of association rules
Extension to: Multilevel, multi-dimensional, and quantitative
rules.
From association mining to correlation analysis
Studying strong correlations
Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 3/110
January 18, 2012 Data Mining: Concepts and Techniques 3
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods Mining various kinds of association rules
From association mining to correlation
analysis Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 4/110
January 18, 2012 Data Mining: Concepts and Techniques 4
What Is Frequent Pattern Analysis?
Frequent pattern: a pattern (a set of items, subsequences, substructures,
etc.) that occurs frequently in a data set
First proposed by Agrawal, Imielinski, and Swami [AIS93] in the context
of frequent itemsets and association rule mining
Motivation: Finding inherent regularities in data
What products were often purchased together? Beer and diapers?!
What are the subsequent purchases after buying a PC?
What kinds of DNA are sensitive to this new drug?
Can we automatically classify web documents?
Applications
Basket data analysis, catalog design, sale campaign analysis, Web log
(click stream) analysis, and DNA sequence analysis.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 5/110
January 18, 2012 Data Mining: Concepts and Techniques 5
Why Is Freq. Pattern Mining Important?
Discloses an intrinsic and important property of data sets
Forms the foundation for many essential data mining tasks
Association, correlation, and causality analysis
Sequential, structural (e.g., sub-graph) patterns Pattern analysis in spatiotemporal, multimedia, time-
series, and stream data
Helps in making strategic decisions

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 6/110
January 18, 2012 6
Basic Concepts: Frequent Patterns and Association Rules
Itemset X = {x1, , xk}
Find all the rules X Y with minimumsupport and confidence
support , s, probability that atransaction contains X Y
confidence, c, conditionalprobability that a transactionhaving X also contains Y
Let supmin = 50%, conf min = 50%
Freq. Pat.: {A:3, B:3, D:4, E:3, AD:3}
Association rules:
A D (60%, 100%)
D A (60%, 75%)
Customer
buys diaper
Customer
buys both
Customer
buys beer
Transaction-id Items bought
10 A, B, D
20 A, C, D
30 A, D, E
40 B, E, F
50 B, C, D, E, F
3/3
3/5
3/4

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 7/110
January 18, 2012 Data Mining: Concepts and Techniques 7
Closed Patterns and Max-Patterns
Finding all the possible patterns can be costly: A long pattern contains a combinatorial number of sub-patterns, e.g.,
{a1, , a100} contains (1001) + (100
2) + + (110000) = 2100 1 = 1.27*1030
sub-patterns!
Solution: Mine closed patterns and max-patterns instead
Idea: Closed Patterns and Max-Patterns can be sufficient to mine for all frequent patterns and get the important rules.
An itemset X is closed if X is frequent and there exists no super-
pattern Y X, with the same support as X (proposed by Pasquier, et
al. @ ICDT99) (Intuitively a closed pattern is like the biggest pattern before the
support count starts going down.)
An itemset X is a max-pattern if X is frequent and there exists no
frequent super-pattern Y X (proposed by Bayardo @ SIGMOD98)(Intuitively a max-pattern is the biggest pattern that remains frequent.)
Closed pattern is a lossless compression of freq. patterns
Reducing the # of patterns and rules

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 8/110
January 18, 2012 Data Mining: Concepts and Techniques 8
Example: Closed Patterns and Max-Patterns
Exercise. DB = {<a1, , a100>, < a1, , a50>}
Min_sup = 1.
What is the set of closed itemset ?
<a1, , a100>: 1
< a1, , a50>: 2
What is the set of max-pattern?
<a1, , a100>: 1
What is the set of all patterns?
!!
Note: From the maximal frequent item set, we can only assert that sub-sets are
frequent, but we can not assert their actual support counts. (e.g.
Consider {a3, a9})
From the set of closed frequent item sets, we have complete information
about the count of the sub-sets.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 9/110
Roadmap
Frequent Pattern Mining can be classified in various ways, which leads todifferent methods/research based on the:
Completeness of patterns to be mined (e.g. all frequent patterns,closed, max, top-k frequent)
Levels of abstractions (e.g. yield rule based on litho tool versus Lithoarea). Single level versus multi-level association rules.
Number of data dimensions in the rule (e.g. buying computer basedon age versus based on age, income, student)
Types of values in the rule. Boolean versus quantitative (e.g.Buying yes/no versus age range).
Kinds of rules. Association versus Correlation.
Kinds of patterns to be mined. Itemset versus Sequences versusStructures (graphs, trees,..)
The last one will be considered in the Advanced data mining class.January 18, 2012 Data Mining: Concepts and Techniques 9

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 10/110
January 18, 2012 Data Mining: Concepts and Techniques 10
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods:
Simple case (Single level, single dimension,
Boolean) rules from transactional DBs
Mining various kinds of association rules
From association mining to correlation analysis
Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 11/110
January 18, 2012 Data Mining: Concepts and Techniques 11
Scalable Methods for Mining Frequent Patterns
The downward closure property of frequent patterns
Any subset of a frequent itemset must be frequent
If {beer, diaper, nuts} is frequent, so is {beer,diaper} (similar to the iceberg condition of descendents: If
{beer, diaper not frequent then {beer, diaper, nuts} not frequent.)
i.e., every transaction having {beer, diaper, nuts} alsocontains {beer, diaper}
Scalable mining methods: Three major approaches
Apriori (Agrawal & Srikant@VLDB94) (5.2.1) Improvements to Apriori (5.2.3)
Freq. pattern growth (FPgrowthHan, Pei & Yin@SIGMOD00) (5.2.4)
Vertical data format approach (CharmZaki & Hsiao

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 12/110
Apriori
January 18, 2012Data Mining: Concepts and
Techniques 12

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 13/110
January 18, 2012 Data Mining: Concepts and Techniques 13
Apriori: A Candidate Generation-and-Test Approach
Apriori pruning principle: If there is any itemset which is
infrequent, its superset should not be generated/tested!
( Agrawal & Srikant @VLDB94, Mannila, et al. @ KDD 94)
Method: Initially, scan DB once to get frequent 1-itemset
Generate length (k+1) candidate itemsets from length k
frequent itemsets (This step includes the a-priori
pruning)
Test the candidates against DB
Terminate when no frequent or candidate set can be
generated

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 14/110
January 18, 2012 Data Mining: Concepts and Techniques 14
The Apriori AlgorithmAn Example
Database TDB
1st scan
C 1 L1
L2
C 2 C 22nd scan
C 3 L33rd scan
Tid Items
10 A, C, D
20 B, C, E
30 A, B, C, E
40 B, E
Itemset sup{A} 2
{B} 3
{C} 3
{D} 1
{E} 3
Itemset sup
{A} 2
{B} 3
{C} 3
{E} 3
Itemset
{A, B}
{A, C}
{A, E}
{B, C}
{B, E}
{C, E}
Itemset sup
{A, B} 1
{A, C} 2
{A, E} 1
{B, C} 2{B, E} 3
{C, E} 2
Itemset sup
{A, C} 2
{B, C} 2
{B, E} 3{C, E} 2
Itemset
{B, C, E}
Itemset sup
{B, C, E} 2
Supmin = 2
What about {A,B,C}?
JoinPrune

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 15/110
January 18, 2012 Data Mining: Concepts and Techniques 15
The Apriori Algorithm
Pseudo-code:Ck: Candidate itemset of size kLk : frequent itemset of size k
L1 = {frequent items}; //Keep going until no more candidates to generatefor (k = 1; Lk !=; k++) do begin
Ck+1 = candidates generated from Lk;for each transaction t in database do
increment the count of all candidates in Ck+1
that are contained in t Lk+1 = candidates in Ck+1 with min_support end
return k Lk;
Join & Prune
DB Scans
Iceberg

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 16/110
January 18, 2012 Data Mining: Concepts and Techniques 16
Important Details of Apriori: Join and Prune
How to generate candidates?
Step 1: self-joining Lk
Step 2: pruning
How to count supports of candidates?
Example of Candidate-generation
L3={abc, abd, acd, ace, bcd}
Self-joining: L3*L3
abcd from abc and abd
acde from acd and ace Pruning:
acde is removed because ade is not in L3
C4={abcd}

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 17/110
January 18, 2012 Data Mining: Concepts and Techniques 17
How to Generate Candidates? Join & Prune(Algorithm illustrated on previous slide)
Suppose the items in Lk-1 are listed in an order
Step 1: self-joining Lk-1
insert into Ck
select p.item1, p.item2, , p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q.item1, , p.itemk-2=q.itemk-2, p.itemk-1 <
q.itemk-1
Step 2: pruningforall itemsets c in Ck do
forall (k-1)-subsets s of c do
if (s is not in Lk-1) then delete c from Ck

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 18/110
Generating Association Rules
Assume we got the following frequent sets: {I1,I2, I5}: 2,
Generate its subsets: {I1, I2}: 4, {I1, I5}: 2,
{I2,I5}:2, {I1}:6. Decide on strong association rules: What is the
confidence level in:
I1 and I2 I5?
I1 I2 and I5 ?
I2 and I5 I1?
.
January 18, 2012 Data Mining: Concepts and Techniques 18

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 19/110
January 18, 2012 Data Mining: Concepts and Techniques 19
Challenges of Frequent Pattern Mining
Challenges
Multiple scans of transaction database
Huge number of candidates
Tedious workload of support counting for candidates
Improving Apriori: general ideas
Reduce passes of transaction database scans
Methods: Partition, Hashing w pruning, Dynamic itemset counting
Shrink number of candidates
Methods: Sampling, Hashing w pruning, or use rule if transaction w/
no frequent items then remove
Facilitate support counting of candidates
Inverted index

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 20/110
January 18, 2012 Data Mining: Concepts and Techniques 20
Improving A-priori Methods
Paritioning: Into local frequent then global of the local
candidates
Hash-Based Technique: As 1-itemset s are being counted,
generate two itemset counts by hashing into bucket hash and
count increment bucket with every 2-itemset insertion. Thenbucket without min-support is removed.
Sampling : Tradeoff between accuracy and efficiency
Dynamic Itemset Counting: Divide DB into blocks. At start of
every block, add candidates instead before full DB scan.
Transaction reduction: If it does not contain k-frequent itemset,
then it can not have k+1-frequent itemset

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 21/110
January 18, 2012 Data Mining: Concepts and Techniques 21
Partition: Scan Database Only Twice
Any itemset that is potentially frequent in DB must be
frequent in at least one of the partitions of DB
Scan 1: partition database and find local frequent
patterns
Scan 2: consolidate global frequent patterns
A. Savasere, E. Omiecinski, and S. Navathe. An efficient
algorithm for mining association in large databases. In
VLDB95

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 22/110
January 18, 2012 Data Mining: Concepts and Techniques 22
DHP: Reduce the Number of Candidates
A k-itemset whose corresponding hashing bucket count is
below the threshold cannot be frequent
Candidates: a, b, c, d, e
Hash entries: {ab, ad, ae} {bd, be, de}
Frequent 1-itemset: a, b, d, e
ab is not a candidate 2-itemset if the sum of count of
{ab, ad, ae} is below support threshold
J. Park, M. Chen, and P. Yu. An effective hash-based
algorithm for mining association rules. In SIGMOD95

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 23/110
January 18, 2012 Data Mining: Concepts and Techniques 23
Sampling for Frequent Patterns
Select a sample of original database, mine frequent
patterns within sample using Apriori
Scan database once to verify frequent itemsets found in
sample, only borders of closure of frequent patterns arechecked
Example: check abcd instead of ab, ac, , etc.
Scan database again to find missed frequent patterns H. Toivonen. Sampling large databases for association
rules. In VLDB96
8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 24/110
January 18, 2012 Data Mining: Concepts and Techniques 24
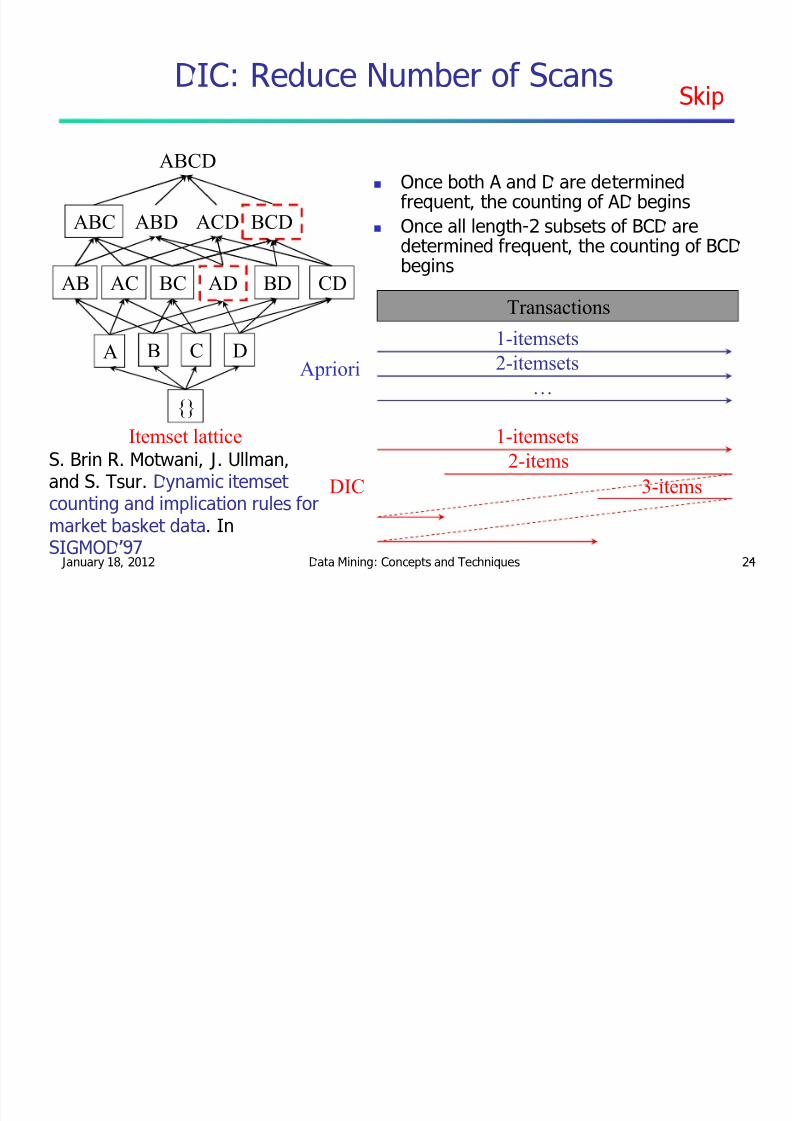
DIC: Reduce Number of Scans
ABCD
ABC ABD ACD BCD
AB AC BC AD BD CD
A B C D
{}Itemset lattice
Once both A and D are determinedfrequent, the counting of AD begins
Once all length-2 subsets of BCD aredetermined frequent, the counting of BCD
begins
Transactions
1-itemsets
2-itemsets
«Apriori
1-itemsets
2-items
3-itemsDIC
S. Brin R. Motwani, J. Ullman,and S. Tsur. Dynamic itemset counting and implication rules formarket basket data. In
SIGMOD97
Skip

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 25/110
January 18, 2012 Data Mining: Concepts and Techniques 25
Bottleneck of Frequent-pattern Mining
Multiple database scans are costly
Mining long patterns needs many passes of
scanning and generates lots of candidates
To find frequent itemset i1i2i100
# of scans: 100
# of Candidates: (1001) + (100
2) + + (110000) = 2100-
1 = 1.27*1030
! Bottleneck: candidate-generation-and-test
Can we avoid candidate generation?

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 26/110
Frequent Pattern Growth
January 18, 2012
Data Mining: Concepts and
Techniques 26

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 27/110
January 18, 2012 Data Mining: Concepts and Techniques 27
Mining Frequent Patterns Without Candidate Generation
Grow long patterns from short ones using local
frequent items
abc is a frequent pattern
Get all transactions having abc: DB|abc
d is a local frequent item in DB|abc
abcd is afrequent pattern

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 28/110
January 18, 2012 Data Mining: Concepts and Techniques 28
The idea behind Mining Frequent Patterns Without Candidate
Generation
1. Generate the set of frequent items (1-itemsets)
2. Sort the list. Note (obviously) the least frequent has the least combinations with others in the
original DB and vice-versa.
3. For each item (starting with the least frequent), call it z we identify all
frequent (we prune out those that are not frequent) itemsets that could
combine with it.
4. We combine these itemsets with the item z to form the combined frequent
itemsets having that item (z) in it.
5. We move to the next least frequent item, call it y, and repeat the same. But
exclude all those that had z in them since already captured.
6. And so on..until we hit the most frequent.
7. So How do we do this?....FP Algorithm

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 29/110
Approach
Build a tree to represent DB
Mine the tree (instead of the DB) more efficiently
To Facilitate scan of tree, use (index) header
table
January 18, 2012 Data Mining: Concepts and Techniques 29

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 30/110
January 18, 2012 Data Mining: Concepts and Techniques 30
Construct FP-tree from a Transaction Database
{}
f:4 c:1
b:1
p:1
b:1c:3
a:3
b:1m:2
p:2 m:1
Header Table
Item frequency head f 4c 4
a 3b 3m 3
p 3
min_support = 3
TID Items bought (ordered) frequent items100 { f, a, c, d, g, i, m, p} { f, c, a, m, p}200 {a, b, c, f, l, m, o} { f, c, a, b, m}300 {b, f, h, j, o, w} { f, b}400 {b, c, k, s, p} {c, b, p}
500 {a, f, c, e, l, p, m, n} { f, c, a, m, p}1. Scan DB once, find
frequent 1-itemset (single item pattern)
2. Sort frequent items in
frequency descendingorder, f-list
3. Scan DB again,construct FP-tree
Add pointers from
header table F-list =f-c-a-b-m-p
2
3
1

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 31/110
January 18, 2012 31
Find Patterns Having P From P-conditional Database(Identifying the frequent items that could combine together- step 3 for all items)
Step 4: Starting at the frequent item header table in the FP-tree Traverse the FP-tree by following the link of each frequent item p Accumulate all of transformed prefix paths of item p to form ps
conditional pattern base
C onditional pattern bases
item cond. pattern base
c f:3
a fc:3
b fca:1, f:1, c:1
m fca:2, fcab:1
p fcam:2, cb:1
{}
f:4 c:1
b:1
p:1
b:1c:3
a:3
b:1m:2
p:2 m:1
Header Table
Item frequency head f 4c 4
a 3b 3m 3
p 3We then re-organize the potential combinations toreflect commonality through the creation of an FPtree for each cond pattern base. Will prune out nodes that does not satisfy min_sup
4

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 32/110
January 18, 2012 Data Mining: Concepts and Techniques 32
From Conditional Pattern-bases to Conditional FP-trees(combining frequent items together step 4)
For each pattern-base
Accumulate the count for each item in the base
Construct the FP-tree for the frequent items of thepattern base
m-conditional pattern base:
fca:2, fcab:1
{}
f:3
c:3
a:3
m-conditional FP-tree
All frequentpatterns relate to m
m, fm, cm, am,
fcm, fam, cam,
fcam
¼ ¼
{}
f:4 c:1
b:1
p:1
b:1c:3
a:3
b:1m:2
p:2 m:1
Header Table Item frequency head f 4
c 4a 3b 3m 3
p 3
For example, consider the case for item ³m´ below
All have 3 counts

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 33/110
January 18, 2012 Data Mining: Concepts and Techniques 33
Recursion: Mining Each Conditional FP-tree
{}
f:3
c:3
a:3m-conditional FP-tree
Cond. pattern base of am: (fc:3)
{}
f:3
c:3
am-conditional FP-
tree
Cond. pattern base of cm: (f:3){}
f:3
cm-conditional FP-tree
Cond. pattern base of cam: (f:3)
{}
f:3
cam-conditional FP-tree

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 34/110
Recursion details
Need to include details on how recursion works.
January 18, 2012 Data Mining: Concepts and Techniques 34

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 35/110
Now Associations
Now we can compute from the FP-tree strongassociations Similar to candidate generation.
January 18, 2012 Data Mining: Concepts and Techniques 35

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 36/110
January 18, 2012 Data Mining: Concepts and Techniques 36
Mining Frequent Patterns With FP-trees
Idea: Frequent pattern growth
Recursively grow frequent patterns by pattern anddatabase partition
Method
For each frequent item, construct its conditionalpattern-base, and then its conditional FP-tree
Repeat the process on each newly created conditionalFP-tree
Until the resulting FP-tree is empty, or it contains onlyone pathsingle path will generate all thecombinations of its sub-paths, each of which is afrequent pattern

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 37/110
January 18, 2012 Data Mining: Concepts and Techniques 37
FP-Growth vs. Apriori: Scalability With the Support Threshold
0
10
2030
40
50
60
70
80
90
100
0 0.5 1 1.5 2 2.5 3
Support threshold(%)
R u n t i m e ( s e c . )
D1 FP-grow th runtime
D1 Apriori runtime
Data set T25I20D10K
Skip
When too many patterns tosearch, FP-Growth muchbetter

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 38/110
January 18, 2012 Data Mining: Concepts and Techniques 38
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods
Mining various kinds of association rules
From association mining to correlation
analysis Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 39/110
January 18, 2012 Data Mining: Concepts and Techniques 39
Mining Various Kinds of Association Rules
Mining multilevel association
Mining multidimensional association
Mining quantitative association

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 40/110
Multi-level Association
January 18, 2012
Data Mining: Concepts and
Techniques 40
A h Mi i M l i l L l

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 41/110
January 18, 2012 Data Mining: Concepts and Techniques 41
Approach to Mining Multiple-Level Association
I. Apply concpet hierachies to find counts of patterns atrdifferent levels. Goal is to Generate Associations at different levels.
II. Use Apriori (or other) optimization for mining at each
level (just like before) and generate associations at eachlevel.
III. Remove redundant Associations

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 42/110
January 18, 2012 Data Mining: Concepts and Techniques 42
I. Mining Multiple-Level Association Rules
Data Items at low primitive levels may be sparse (e.g.buying a particular type & model of laptop) versus dataitems at higher levels of abstraction (e.g. buyingcomputers)
As a result, may not be possible to extract strongassociations for low primitives due to sparsity
Use concept hierarchies to identify interesting (frequent patterns.
Note:
Categorical attributes may have a natural concept hierarchy (e.g. city state country)
Numerical attributes can be discretized

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 43/110
January 18, 2012 Data Mining: Concepts and Techniques 43
II. Mining Multiple-Level Association Rules
Top-down approach for mining multi-level associations using1) Uniform support for all levels
2) Flexible support settings - Items at the lower level are expected tohave lower support
Depending on the approach, different rules may be pruned
Exploration of shared multi-level mining (Agrawal & Srikant@VLB95,Han & Fu@VLDB95)
1) uniform support
Milk
[support = 10%]
2% Milk
[support = 6%]
SkimMilk
[support = 4%]
At Level 1
min_sup = 5%
At Level 2
min_sup = 5%
At Level 1
min_sup = 5%
At Level 2
min_sup = 3%
2) Flexible reduced support
Note with approach 1) Skim Milk would be pruned.
III M lti l l A i ti R d d

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 44/110
January 18, 2012 Data Mining: Concepts and Techniques 44
III. Multi-level Association: RedundancyFiltering
Some rules may be redundant due to ancestor relationships
between items.
Example
milk wheat bread [support = 8%, confidence = 70%]
2% milk wheat bread [support = 2%, confidence = 72%]
We say the first rule is an ancestor of the second rule.
A rule is redundant if its support is close to the expected value,
based on the rules ancestor.
Remove the less general rule.
In the above example, remove the rule 2% milk wheat bread
Assumption: count of 2% milk is ~ ¼ milk transactions. In that
case, expected support is ¼ of milk, and confidence is the same
(since 2% milk is also milk)

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 45/110

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 46/110
January 18, 2012 Data Mining: Concepts and Techniques 46
Mining Multi-Dimensional Association
Single-dimensional rules:
buys(X, milk) buys(X, bread)
Multi-dimensional rules: u 2 dimensions or predicates
Inter-dimension assoc. rules (no repeated predicates)
age(X,19-25) occupation(X,student) buys(X, coke)
hybrid-dimension assoc. rules (repeated predicates)
age(X,19-25) buys(X, popcorn) buys(X, coke)
Categorical Attributes: finite number of possible values, noordering among valuesdata cube approach
Quantitative Attributes: numeric, implicit ordering among
valuesdiscretization, and clustering approaches

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 47/110
Multi-Dimensional Association approach
Find frequent patterns with the multi-dimensionalvalues similar to frequent itemsets.
Then Generate associations.
January 18, 2012 Data Mining: Concepts and Techniques 47

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 48/110
January 18, 2012 Data Mining: Concepts and Techniques 48
Mining Quantitative Associations
Techniques can be categorized by how numericalattributes, such as age or salary are treated
1. Static discretization based on predefined concept
hierarchies (data cube methods)
2. Dynamic discretization based on data distribution
(quantitative rules, e.g., Agrawal & Srikant@SIGMOD96)

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 49/110
January 18, 2012 Data Mining: Concepts and Techniques 49
Static Discretization of Quantitative Attributes
Discretized prior to mining using concept hierarchy. Numeric values are replaced by ranges.
Data cube is well suited for mining. It may already contain the
dimensions of interest.
The cells of an n-dimensionalcuboid correspond to the
predicate sets.
Mining from data cubes
can be much faster. A set of values that occur frequently in an n-dimensional cell can be
mined for associations.
The counts of the sub-items can be found in the cube.
Use rule generation algorithm to derive the associations
(income)
(age)
()
( buys)
(age, income) (age,buys)(income,buys)
(age,income,buys)

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 50/110

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 51/110
January 18, 2012 Data Mining: Concepts and Techniques 51
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods
Mining various kinds of association rules
From association mining to correlation analysis
Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 52/110
Misleading Example
Consider 10,000 sales transactions: 6000included computer games, 7500 included videos,4000 included both.
We can conclude: Buys (X, computer games ) buys (X,
videos) [40%, 66.7%] , but is misleading
Since 75% buy videos
In this case, we actually have a negativecorrelation.
So, we may want to add correlation measure.
January 18, 2012 Data Mining: Concepts and Techniques 52

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 53/110
Correlation Measure Options
Possible correlation measures:
Lift
Chi-square
All confidence Cosine
Coherence
Idea is to use correlation measure in conjunctionwith support/confidence to decide whether tokeep or drop the association.
January 18, 2012 Data Mining: Concepts and Techniques 53

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 54/110
January 18, 2012 Data Mining: Concepts and Techniques 54
Interestingness Measure: Correlations (Lift)
Measure of dependent/correlated events: lift
)()(
)(
B P A P
B A P li ft
!
If Lift > 1 then positively correlated.If Lift < 1 then negatively correlated
If Lift = 1 independent.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 55/110
January 18, 2012 Data Mining: Concepts and Techniques 55
Interestingness Measure: Correlations (Lift)
play basketball eat cereal [40%, 66.7%] is misleading
The overall % of students eating cereal is 75% > 66.7%.
play basketball not eat cereal [20%, 33.3%] is more accurate (because
they are negatively correlated), although with lower support and confidence
Measure of dependent/correlated events: lift
89.05000/3750*5000/3000
5000/2000),( !!C Bli ft
Basketball Not basketball Sum (row)
Cereal 2000 1750 3750
Not cereal 1000 250 1250
Sum(col.) 3000 2000 5000)()(
)(
B P A P
B A P li ft
!
33.15000/1250*5000/3000
5000/1000),( !!C Bli ft

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 56/110
January 18, 2012 Data Mining: Concepts and Techniques 56
Other Measures Definition
)()(
)(
B P A P
B A P li ft
!
)su p( _ max _
)su p( _
X item
X conf all !
|)(|
)su p(
X universe
X coh !
|)su p()su p(
)su p(),(cos
B A
AUB B Aine !

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 57/110
Null-Invariant measures
A null transaction is a transaction that does not contain any of the itemsets being examined.
A measure is null-invariant if its value is free from
the influence of null-transactions. Note that Lift and Chi-square can be influenced
by null transactions
All-confidence, Coherence, and Cosine are null-
inavriant
January 18, 2012 Data Mining: Concepts and Techniques 57

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 58/110
January 18, 2012 Data Mining: Concepts and Techniques 58
Are lift and G2 Good Measures of Correlation?
Buy walnuts buy milk [1%, 80%] is misleading
if 85% of customers buy milk
Support and confidence are not good to represent correlations
So many interestingness measures? (Tan, Kumar, Sritastava @KDD02)
Milk No Milk Sum (row)
Coffee m, c ~m, c c
No Coffee m, ~c ~m, ~c ~c
Sum(col.) m ~m 7
)()(
)(
B P A P
B A P li ft
!
DB m, c ~m, c m~c ~m~c lift all-conf coh G2
A1 1000 100 100 10,000 9.26 0.91 0.83 9055
A2 100 1000 1000 100,000 8.44 0.09 0.05 670
A3 1000 100 10000 100,000 9.18 0.09 0.09 8172
A4 1000 1000 1000 1000 1 0.5 0.33 0
)su p( _ max _
)su p( _
X item
X conf all !
|)(|
)su p(
X universe
X coh !

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 59/110
January 18, 2012 Data Mining: Concepts and Techniques 59
Are lift and G2 Good Measures of Correlation?
In A1 m and c are positively correlated
In A2 and A3 they are negatively correlated
In A4, they are independent
Note that Chi-square are not good measures of negative correlations
All provide good indicators of independence
DB m, c ~m, c m~c ~m~c lift all-conf coh G2
A1 1000 100 100 10,000 9.26 0.91 0.83 9055
A2 100 1000 1000 100,000 8.44 0.09 0.05 670
A3 1000 100 10000 100,000 9.18 0.09 0.09 8172
A4 1000 1000 1000 1000 1 0.5 0.33 0

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 60/110
Proposed Approach
Use All confidence and Coherence to start with,then zoom in with Lift or Chi-square whennumbers are close to independence (ieambiguous)
January 18, 2012 Data Mining: Concepts and Techniques 60

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 61/110
January 18, 2012 Data Mining: Concepts and Techniques 61
Which Measures Should Be Used?
lift and G2 are not good measures forcorrelations in largetransactional DBs
all-conf orcoherence could begood measures(Omiecinski@TKDE03)
Both all-conf andcoherence have thedownward closureproperty
Efficient algorithmscan be derived formining (Lee et al.@ICDM03sub)
Ch t 5 Mi i F t P tt

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 62/110
January 18, 2012 Data Mining: Concepts and Techniques 62
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods
Mining various kinds of association rules
From association mining to correlation analysis
Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 63/110
January 18, 2012 Data Mining: Concepts and Techniques 63
Constraint-based (Query-Directed) Mining
Finding all the patterns in a database autonomously?
unrealistic!
The patterns could be too many but not focused!
Data mining should be an interactive process User directs what to be mined using a data mining
query language (or a graphical user interface)
Constraint-based mining
User flexibility: provides constraints on what to be
mined
System optimization: explores such constraints for
efficient miningconstraint-based mining

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 64/110
January 18, 2012 Data Mining: Concepts and Techniques 64
Constraints in Data Mining
Knowledge type constraint :
classification, association, etc.
Data constraint using SQL-like queries
find product pairs sold together in stores in Chicago in
Dec.02 Dimension/level constraint
in relevance to region, price, brand, customer category
Rule (or pattern) constraint
small sales (price < $10) triggers big sales (sum >$200)
Interestingness constraint
strong rules: min_support u 3%, min_confidence u60%

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 65/110
January 18, 2012 Data Mining: Concepts and Techniques 65
Constrained Mining vs. Constraint-Based Search
Constrained mining vs. constraint-based search/reasoning
Both are aimed at reducing search space
Finding all patterns satisfying constraints vs. finding
some (or one) answer in constraint-based search in AI Constraint-pushing vs. heuristic search
It is an interesting research problem on how to integratethem
Constrained mining vs. query processing in DBMS Database query processing requires to find all
Constrained pattern mining shares a similar philosophyas pushing selections deeply in query processing

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 66/110
January 18, 2012 Data Mining: Concepts and Techniques 66
Anti-Monotonicity in Constraint Pushing
Anti-monotonicity
When an intemset S violates the
constraint, so does any of its superset
sum(S.Price) e v is anti-monotone sum(S.Price) u v is not anti-monotone
Example. C: range(S.profit) e 15 is anti-
monotone
Itemset ab violates C
So does every superset of ab
TID Transaction
10 a, b, c, d, f
20 b, c, d, f, g, h
30 a, c, d, e, f
40 c, e, f, g
TDB (min _ su p=2)
Item Profit
a 40
b 0
c -20
d 10
e -30
f 30
g 20
h -10

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 67/110
January 18, 2012 Data Mining: Concepts and Techniques 67
Monotonicity for Constraint Pushing
Monotonicity
When an intemset S satisfies the
constraint, so does any of its
superset
sum(S.Price) u v is monotone
min(S.Price) e v is monotone
Example. C: range(S.profit) u 15 Itemset ab satisfies C
So does every superset of ab
TID Transaction
10 a, b, c, d, f
20 b, c, d, f, g, h
30 a, c, d, e, f
40 c, e, f, g
TDB (min _ su p=2)
Item Profit
a 40
b 0
c -20
d 10
e -30
f 30
g 20
h -10

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 68/110
January 18, 2012 Data Mining: Concepts and Techniques 68
Succinctness
Succinctness:
Given A1, the set of items satisfying a succinctness
constraint C, then any set S satisfying C is based on
A1 , i.e., S contains a subset belonging to A1
Idea: Without looking at the transaction database,
whether an itemset S satisfies constraint C can be
determined based on the selection of items
min(S.Price) e v is succinct
sum(S.Price) u v is not succinct
Optimization: If C is succinct, C is pre-counting pushable

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 69/110
January 18, 2012 Data Mining: Concepts and Techniques 69
The Apriori Algorithm Example
TID Items
100 1 3 4
200 2 3 5
300 1 2 3 5
400 2 5
Database D itemset sup.
{1} 2
{2} 3
{3} 3
{4} 1
{5} 3
itemset sup.
{1} 2
{2} 3
{3} 3
{5} 3
Scan D
C 1 L1
itemset
{1 2}
{1 3}
{1 5}
{2 3}{2 5}
{3 5}
itemset sup
{1 2} 1
{1 3} 2
{1 5} 1
{2 3} 2{2 5} 3
{3 5} 2
itemset sup
{1 3} 2
{2 3} 2
{2 5} 3
{3 5} 2
L2
C 2 C 2Scan D
C 3 L3itemset
{2 3 5}Scan D itemset sup
{2 3 5} 2

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 70/110
January 18, 2012 Data Mining: Concepts and Techniques 70
Naïve Algorithm: Apriori + Constraint
TID Items
100 1 3 4
200 2 3 5
300 1 2 3 5
400 2 5
Database D itemset sup.
{1} 2
{2} 3
{3} 3
{4} 1
{5} 3
itemset sup.
{1} 2
{2} 3
{3} 3
{5} 3
Scan D
C 1 L1
itemset
{1 2}
{1 3}
{1 5}
{2 3}{2 5}
{3 5}
itemset sup
{1 2} 1
{1 3} 2
{1 5} 1
{2 3} 2{2 5} 3
{3 5} 2
itemset sup
{1 3} 2
{2 3} 2
{2 5} 3
{3 5} 2
L2
C 2 C 2Scan D
C 3 L3itemset
{2 3 5}Scan D itemset sup
{2 3 5} 2
Constraint:
Sum{
S.price} < 5
The Constrained Apriori Algorithm: Push

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 71/110
January 18, 2012 Data Mining: Concepts and Techniques 71
The Constrained Apriori Algorithm: Push
an Anti-monotone Constraint Deep
TID Items
100 1 3 4
200 2 3 5
300 1 2 3 5
400 2 5
Database D itemset sup.
{1} 2
{2} 3
{3} 3
{4} 1
{5} 3
itemset sup.
{1} 2
{2} 3
{3} 3
{5} 3
Scan D
C 1 L1
itemset
{1 2}
{1 3}
{1 5}
{2 3}{2 5}
{3 5}
itemset sup
{1 2} 1
{1 3} 2
{1 5} 1
{2 3} 2{2 5} 3
{3 5} 2
itemset sup
{1 3} 2
{2 3} 2
{2 5} 3
{3 5} 2
L2
C 2 C 2Scan D
C 3 L3itemset
{2 3 5}Scan D itemset sup
{2 3 5} 2
Constraint:
Sum{S.price} < 5
The Constrained Apriori Algorithm: Push a

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 72/110
January 18, 2012 Data Mining: Concepts and Techniques 72
The Constrained Apriori Algorithm: Push a
Succinct Constraint Deep
TID Items
100 1 3 4
200 2 3 5
300 1 2 3 5
400 2 5
Database D itemset sup.
{1} 2
{2} 3
{3} 3
{4} 1
{5} 3
itemset sup.
{1} 2
{2} 3
{3} 3
{5} 3
Scan D
C 1 L1
itemset
{1 2}
{1 3}
{1 5}
{2 3}{2 5}
{3 5}
itemset sup
{1 2} 1
{1 3} 2
{1 5} 1
{2 3} 2{2 5} 3
{3 5} 2
itemset sup
{1 3} 2
{2 3} 2
{2 5} 3
{3 5} 2
L2
C 2 C 2Scan D
C 3 L3itemset
{2 3 5}Scan D itemset sup
{2 3 5} 2
Constraint:
min{S.price } <= 1
not immediately to be used

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 73/110
January 18, 2012 Data Mining: Concepts and Techniques 73
Converting Tough Constraints
Convert tough constraints into anti-
monotone or monotone by properly
ordering items
Examine C: avg(S.profit) u 25 Order items in value-descending
order
<a, f, g, d, b, h, c, e>
If an itemset afb violates C So does afbh, afb*
It becomes anti-monotone!
TID Transaction
10 a, b, c, d, f
20 b, c, d, f, g, h
30 a, c, d, e, f
40 c, e, f, g
TDB (min _ su p=2)
Item Profit
a 40
b 0
c -20
d 10
e -30
f 30
g 20
h -10

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 74/110
January 18, 2012 Data Mining: Concepts and Techniques 74
Strongly Convertible Constraints
avg(X) u 25 is convertible anti-monotone w.r.t.item value descending order R: <a, f, g, d, b,h, c, e>
If an itemset af violates a constraint C, so
does every itemset with af as prefix, such asafd
avg(X) u 25 is convertible monotone w.r.t. itemvalue ascending order R-1: <e, c, h, b, d, g, f,a>
If an itemset d satisfies a constraint C, sodoes itemsets df and dfa, which having d asa prefix
Thus, avg(X) u 25 is strongly convertible
Item Profit
a 40
b 0
c -20
d 10
e -30
f 30
g 20
h -10

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 75/110
January 18, 2012 Data Mining: Concepts and Techniques 75
Can Apriori Handle Convertible Constraint?
A convertible, not monotone nor anti-monotonenor succinct constraint cannot be pushed deepinto the an Apriori mining algorithm
Within the level wise framework, no direct pruning based on the constraint can be made
Itemset df violates constraint C: avg(X)>=25
Since adf satisfies C, Apriori needs df to
assemble adf, df cannot be pruned But it can be pushed into frequent-pattern
growth framework!
Item Value
a 40
b 0
c -20
d 10
e -30
f 30
g 20
h -10

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 76/110
January 18, 2012 Data Mining: Concepts and Techniques 76
Mining With Convertible Constraints
C: avg(X) >= 25, min_sup=2
List items in every transaction in value descending
order R: <a, f, g, d, b, h, c, e>
C is convertible anti-monotone w.r.t. R
Scan TDB once remove infrequent items
Item h is dropped
Itemsets a and f are good,
Projection-based mining Imposing an appropriate order on item projection
Many tough constraints can be converted into
(anti)-monotone
TID Transaction
10 a, f, d, b, c
20 f, g, d, b, c
30 a, f, d, c, e
40 f, g, h, c, e
TDB (min _ su p=2)
Item Value
a 40
f 30
g 20
d 10
b 0
h -10
c -20
e -30

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 77/110
January 18, 2012 Data Mining: Concepts and Techniques 77
Handling Multiple Constraints
Different constraints may require different or even
conflicting item-ordering
If there exists an order R s.t. both C1 and C2 are
convertible w.r.t. R, then there is no conflict betweenthe two convertible constraints
If there exists conflict on order of items
Try to satisfy one constraint first
Then using the order for the other constraint to
mine frequent itemsets in the corresponding
projected database
8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 78/110
January 18, 2012 Data Mining: Concepts and Techniques 78
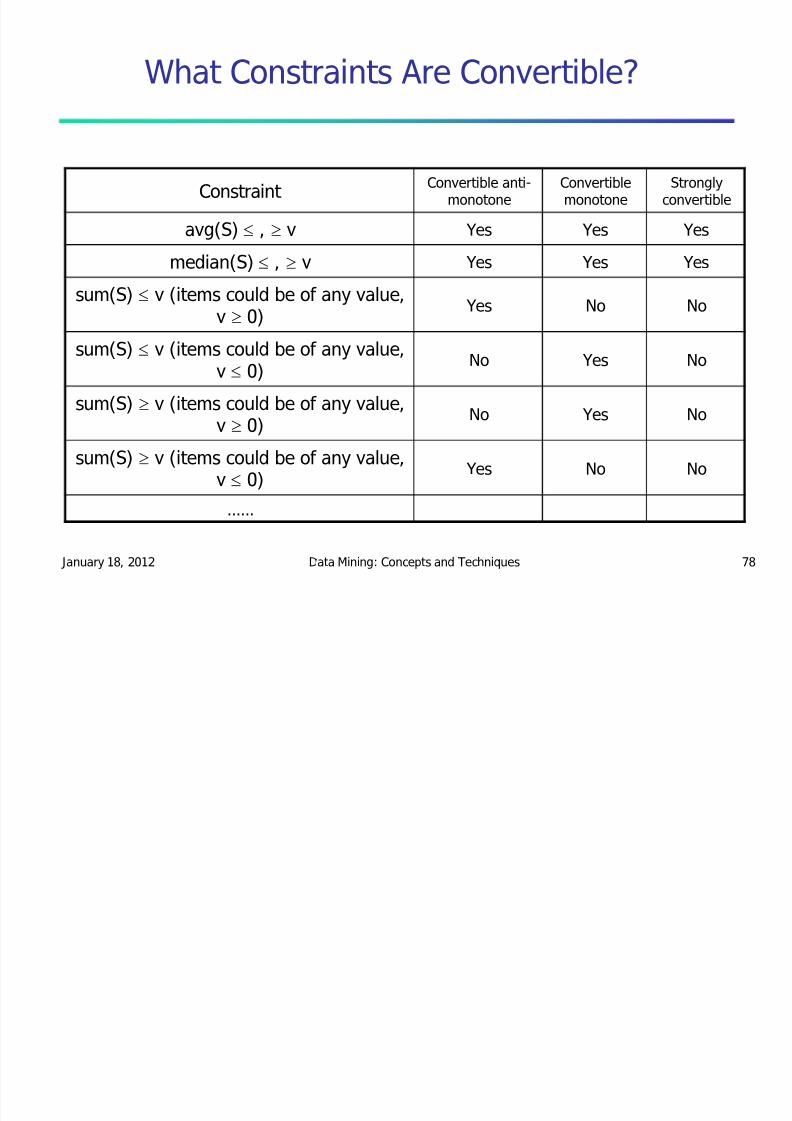
What Constraints Are Convertible?
Constraint Convertible anti-
monotoneConvertiblemonotone
Stronglyconvertible
avg(S) e , u v Yes Yes Yes
median(S) e , u v Yes Yes Yes
sum(S) e v (items could be of any value,v u 0)
Yes No No
sum(S) e v (items could be of any value,v e 0)
No Yes No
sum(S) u v (items could be of any value,v u 0) No Yes No
sum(S) u v (items could be of any value,v e 0)
Yes No No

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 79/110
January 18, 2012 Data Mining: Concepts and Techniques 79
Constraint-Based MiningA General Picture
Constraint Antimonotone Monotone Succinctv S no yes yes
S V no yes yes
S V yes no yes
min(S) e v no yes yes
min(S) u v yes no yes
max(S) e v yes no yes
max(S) u v no yes yes
count(S) e v yes no weakly
count(S) u v no yes weakly
sum(S) e v ( a S, a u 0 ) yes no no
sum(S) u v ( a S, a u 0 ) no yes no
range(S) e v yes no no
range(S) u v no yes no
avg(S) U v, U { !, e, u } convertible convertible no
support(S) u \ yes no no
support(S)e \ no yes no

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 80/110
January 18, 2012 Data Mining: Concepts and Techniques 80
A Classification of Constraints
Convertibleanti-monotone
Convertiblemonotone
Stronglyconvertible
Inconvertible
Succinct
AntimonotoneMonotone
Chapter 5: Mining Frequent Patterns

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 81/110
January 18, 2012 Data Mining: Concepts and Techniques 81
Chapter 5: Mining Frequent Patterns, Association and Correlations
Basic concepts and a road map
Efficient and scalable frequent itemset mining
methods
Mining various kinds of association rules
From association mining to correlation analysis
Constraint-based association mining
Summary

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 82/110
January 18, 2012 Data Mining: Concepts and Techniques 82
Frequent-Pattern Mining: Summary
Frequent pattern miningan important task in data mining
Scalable frequent pattern mining methods
Apriori (Candidate generation & test)
Projection-based (FPgrowth, CLOSET+, ...)
Vertical format approach (CHARM, ...)
Mining a variety of rules and interesting patterns
Constraint-based mining
Mining sequential and structured patterns
Extensions and applications

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 83/110
January 18, 2012 Data Mining: Concepts and Techniques 83
Frequent-Pattern Mining: Research Problems
Mining fault-tolerant frequent, sequential and structured
patterns
Patterns allows limited faults (insertion, deletion,
mutation)
Mining truly interesting patterns
Surprising, novel, concise,
Application exploration
E.g., DNA sequence analysis and bio-patternclassification
Invisible data mining

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 84/110
January 18, 2012 Data Mining: Concepts and Techniques 84
Ref: Basic Concepts of Frequent Pattern Mining
( Association Rules) R. Agrawal, T. Imielinski, and A. Swami. Miningassociation rules between sets of items in large databases.
SIGMOD'93.
(Max-pattern) R. J. Bayardo. Efficiently mining long patterns from
databases. SIGMOD'98. (Closed-pattern) N. Pasquier, Y. Bastide, R. Taouil, and L. Lakhal.
Discovering frequent closed itemsets for association rules. ICDT'99.
(Sequential pattern) R. Agrawal and R. Srikant. Mining sequential
patterns. ICDE'95

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 85/110
January 18, 2012 Data Mining: Concepts and Techniques 85
Ref: Apriori and Its Improvements
R. Agrawal and R. Srikant. Fast algorithms for mining association rules. VLDB'94.
H. Mannila, H. Toivonen, and A. I. Verkamo. Efficient algorithms for
discovering association rules. KDD'94.
A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for
mining association rules in large databases. VLDB'95.
J. S. Park, M. S. Chen, and P. S. Yu. An effective hash-based algorithm
for mining association rules. SIGMOD'95.
H. Toivonen. Sampling large databases for association rules. VLDB'96.
S. Brin, R. Motwani, J. D. Ullman, and S. Tsur. Dynamic itemset counting and implication rules for market basket analysis. SIGMOD'97.
S. Sarawagi, S. Thomas, and R. Agrawal. Integrating association rule
mining with relational database systems: Alternatives and implications.
SIGMOD'98.
R f D th Fi t P j ti B d FP Mi i

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 86/110
January 18, 2012 Data Mining: Concepts and Techniques 86
Ref: Depth-First, Projection-Based FP Mining
R. Agarwal, C. Aggarwal, and V. V. V. Prasad. A tree projectionalgorithm for generation of frequent itemsets. J. Parallel andDistributed Computing:02.
J. Han, J. Pei, and Y. Yin. Mining frequent patterns without candidategeneration. SIGMOD 00.
J. Pei, J. Han, and R. Mao. CLOSET: An Efficient Algorithm for MiningFrequent Closed Itemsets. DMKD'00.
J. Liu, Y. Pan, K. Wang, and J. Han. Mining Frequent Item Sets byOpportunistic Projection. KDD'02.
J. Han, J. Wang, Y. Lu, and P. Tzvetkov. Mining Top-K Frequent Closed
Patterns without Minimum Support. ICDM'02. J. Wang, J. Han, and J. Pei. CLOSET+: Searching for the Best
Strategies for Mining Frequent Closed Itemsets. KDD'03.
G. Liu, H. Lu, W. Lou, J. X. Yu. On Computing, Storing and QueryingFrequent Patterns. KDD'03.
R f V ti l F t d R E ti M th d

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 87/110
January 18, 2012 Data Mining: Concepts and Techniques 87
Ref: Vertical Format and Row Enumeration Methods
M. J. Zaki, S. Parthasarathy, M. Ogihara, and W. Li. Parallel algorithmfor discovery of association rules. DAMI:97.
Zaki and Hsiao. CHARM: An Efficient Algorithm for Closed Itemset
Mining, SDM'02.
C. Bucila, J. Gehrke, D. Kifer, and W. White. DualMiner: A Dual-Pruning Algorithm for Itemsets with Constraints. KDD02.
F. Pan, G. Cong, A. K. H. Tung, J. Yang, and M. Zaki , CARPENTER:
Finding Closed Patterns in Long Biological Datasets. KDD'03.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 88/110
January 18, 2012 Data Mining: Concepts and Techniques 88
Ref: Mining Multi-Level and Quantitative Rules
R. Srikant and R. Agrawal. Mining generalized association rules. VLDB'95.
J. Han and Y. Fu. Discovery of multiple-level association rules fromlarge databases. VLDB'95.
R. Srikant and R. Agrawal. Mining quantitative association rules in
large relational tables. SIGMOD'96. T. Fukuda, Y. Morimoto, S. Morishita, and T. Tokuyama. Data mining
using two-dimensional optimized association rules: Scheme,algorithms, and visualization. SIGMOD'96.
K. Yoda, T. Fukuda, Y. Morimoto, S. Morishita, and T. Tokuyama.
Computing optimized rectilinear regions for association rules. KDD'97. R.J. Miller and Y. Yang. Association rules over interval data.
SIGMOD'97.
Y. Aumann and Y. Lindell. A Statistical Theory for Quantitative Association Rules KDD'99.
f i i C l i d i l

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 89/110
January 18, 2012 Data Mining: Concepts and Techniques 89
Ref: Mining Correlations and Interesting Rules
M. Klemettinen, H. Mannila, P. Ronkainen, H. Toivonen, and A. I. Verkamo. Finding interesting rules from large sets of discovered
association rules. CIKM'94.
S. Brin, R. Motwani, and C. Silverstein. Beyond market basket:
Generalizing association rules to correlations. SIGMOD'97. C. Silverstein, S. Brin, R. Motwani, and J. Ullman. Scalable
techniques for mining causal structures. VLDB'98.
P.-N. Tan, V. Kumar, and J. Srivastava. Selecting the Right
Interestingness Measure for Association Patterns. KDD'02.
E. Omiecinski. Alternative Interest Measures for Mining
Associations. TKDE03.
Y. K. Lee, W.Y. Kim, Y. D. Cai, and J. Han. CoMine: Efficient Mining
of Correlated Patterns. ICDM03.
R f Mi i O h Ki d f R l

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 90/110
January 18, 2012 Data Mining: Concepts and Techniques 90
Ref: Mining Other Kinds of Rules
R. Meo, G. Psaila, and S. Ceri. A new SQL-like operator for miningassociation rules. VLDB'96.
B. Lent, A. Swami, and J. Widom. Clustering association rules.
ICDE'97.
A. Savasere, E. Omiecinski, and S. Navathe. Mining for strong
negative associations in a large database of customer transactions.ICDE'98.
D. Tsur, J. D. Ullman, S. Abitboul, C. Clifton, R. Motwani, and S.
Nestorov. Query flocks: A generalization of association-rule mining.
SIGMOD'98.
F. Korn, A. Labrinidis, Y. Kotidis, and C. Faloutsos. Ratio rules: A new
paradigm for fast, quantifiable data mining. VLDB'98.
K. Wang, S. Zhou, J. Han. Profit Mining: From Patterns to Actions.
EDBT02.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 91/110
January 18, 2012 Data Mining: Concepts and Techniques 91
Ref: Constraint-Based Pattern Mining
R. Srikant, Q. Vu, and R. Agrawal. Mining association rules with itemconstraints. KDD'97.
R. Ng, L.V.S. Lakshmanan, J. Han & A. Pang. Exploratory mining and
pruning optimizations of constrained association rules. SIGMOD98.
M.N. Garofalakis, R. Rastogi, K. Shim: SPIRIT: Sequential PatternMining with Regular Expression Constraints. VLDB99.
G. Grahne, L. Lakshmanan, and X. Wang. Efficient mining of
constrained correlated sets. ICDE'00.
J. Pei, J. Han, and L. V. S. Lakshmanan. Mining Frequent Itemsetswith Convertible Constraints. ICDE'01.
J. Pei, J. Han, and W. Wang, Mining Sequential Patterns with
Constraints in Large Databases, CIKM'02.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 92/110
January 18, 2012 Data Mining: Concepts and Techniques 92
Ref: Mining Sequential and Structured Patterns
R. Srikant and R. Agrawal. Mining sequential patterns: Generalizationsand performance improvements. EDBT96.
H. Mannila, H Toivonen, and A. I. Verkamo. Discovery of frequent
episodes in event sequences. DAMI:97.
M. Zaki. SPADE: An Efficient Algorithm for Mining Frequent Sequences.
Machine Learning:01.
J. Pei, J. Han, H. Pinto, Q. Chen, U. Dayal, and M.-C. Hsu. PrefixSpan:
Mining Sequential Patterns Efficiently by Prefix-Projected Pattern
Growth. ICDE'01.
M. Kuramochi and G. Karypis. Frequent Subgraph Discovery. ICDM'01. X. Yan, J. Han, and R. Afshar. CloSpan: Mining Closed Sequential
Patterns in Large Datasets. SDM'03.
X. Yan and J. Han. CloseGraph: Mining Closed Frequent Graph
Patterns. KDD'03.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 93/110
January 18, 2012 Data Mining: Concepts and Techniques 93
Ref: Mining Spatial, Multimedia, and Web Data
K. Koperski and J. Han, Discovery of Spatial Association Rules inGeographic Information Databases, SSD95.
O. R. Zaiane, M. Xin, J. Han, Discovering Web Access Patterns and
Trends by Applying OLAP and Data Mining Technology on Web Logs.
ADL'98.
O. R. Zaiane, J. Han, and H. Zhu, Mining Recurrent Items in
Multimedia with Progressive Resolution Refinement. ICDE'00.
D. Gunopulos and I. Tsoukatos. Efficient Mining of Spatiotemporal
Patterns. SSTD'01.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 94/110
January 18, 2012 Data Mining: Concepts and Techniques 94
Ref: Mining Frequent Patterns in Time-Series Data
B. Ozden, S. Ramaswamy, and A. Silberschatz. Cyclic association rules.ICDE'98.
J. Han, G. Dong and Y. Yin, Efficient Mining of Partial Periodic Patterns
in Time Series Database, ICDE'99.
H. Lu, L. Feng, and J. Han. Beyond Intra-Transaction Association Analysis: Mining Multi-Dimensional Inter-Transaction Association Rules.
TOIS:00.
B.-K. Yi, N. Sidiropoulos, T. Johnson, H. V. Jagadish, C. Faloutsos, and
A. Biliris. Online Data Mining for Co-Evolving Time Sequences. ICDE'00.
W. Wang, J. Yang, R. Muntz. TAR: Temporal Association Rules on
Evolving Numerical Attributes. ICDE01.
J. Yang, W. Wang, P. S. Yu. Mining Asynchronous Periodic Patterns in
Time Series Data. TKDE03.
R f I b C b d C b C t ti

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 95/110
January 18, 2012 Data Mining: Concepts and Techniques 95
Ref: Iceberg Cube and Cube Computation
S. Agarwal, R. Agrawal, P. M. Deshpande, A. Gupta, J. F. Naughton,R. Ramakrishnan, and S. Sarawagi. On the computation of
multidimensional aggregates. VLDB'96.
Y. Zhao, P. M. Deshpande, and J. F. Naughton. An array-based
algorithm for simultaneous multidi-mensional aggregates.
SIGMOD'97. J. Gray, et al. Data cube: A relational aggregation operator
generalizing group-by, cross-tab and sub-totals. DAMI: 97.
M. Fang, N. Shivakumar, H. Garcia-Molina, R. Motwani, and J. D.
Ullman. Computing iceberg queries efficiently. VLDB'98.
S. Sarawagi, R. Agrawal, and N. Megiddo. Discovery-driven
exploration of OLAP data cubes. EDBT'98.
K. Beyer and R. Ramakrishnan. Bottom-up computation of sparse
and iceberg cubes. SIGMOD'99.
Ref: Iceberg Cube and Cube Exploration

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 96/110
January 18, 2012 Data Mining: Concepts and Techniques 96
Ref: Iceberg Cube and Cube Exploration
J. Han, J. Pei, G. Dong, and K. Wang, Computing Iceberg DataCubes with Complex Measures. SIGMOD 01.
W. Wang, H. Lu, J. Feng, and J. X. Yu. Condensed Cube: An
Effective Approach to Reducing Data Cube Size. ICDE'02.
G. Dong, J. Han, J. Lam, J. Pei, and K. Wang. Mining Multi-Dimensional Constrained Gradients in Data Cubes. VLDB'01.
T. Imielinski, L. Khachiyan, and A. Abdulghani. Cubegrades:
Generalizing association rules. DAMI:02.
L. V. S. Lakshmanan, J. Pei, and J. Han. Quotient Cube: How to
Summarize the Semantics of a Data Cube. VLDB'02.
D. Xin, J. Han, X. Li, B. W. Wah. Star-Cubing: Computing Iceberg
Cubes by Top-Down and Bottom-Up Integration. VLDB'03.
R f FP f Cl ifi ti d Cl t i

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 97/110
January 18, 2012 Data Mining: Concepts and Techniques 97
Ref: FP for Classification and Clustering
G. Dong and J. Li. Efficient mining of emerging patterns:Discovering trends and differences. KDD'99.
B. Liu, W. Hsu, Y. Ma. Integrating Classification and Association
Rule Mining. KDD98.
W. Li, J. Han, and J. Pei. CMAR: Accurate and Efficient
Classification Based on Multiple Class-Association Rules. ICDM'01.
H. Wang, W. Wang, J. Yang, and P.S. Yu. Clustering by pattern
similarity in large data sets. SIGMOD 02.
J. Yang and W. Wang. CLUSEQ: efficient and effective sequence
clustering. ICDE03. B. Fung, K. Wang, and M. Ester. Large Hierarchical Document
Clustering Using Frequent Itemset. SDM03.
X. Yin and J. Han. CPAR: Classification based on Predictive
Association Rules. SDM'03.
R f St d P i P i FP Mi i

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 98/110
January 18, 2012 Data Mining: Concepts and Techniques 98
Ref: Stream and Privacy-Preserving FP Mining
A. Evfimievski, R. Srikant, R. Agrawal, J. Gehrke. Privacy PreservingMining of Association Rules. KDD02.
J. Vaidya and C. Clifton. Privacy Preserving Association Rule Mining
in Vertically Partitioned Data. KDD02.
G. Manku and R. Motwani. Approximate Frequency Counts over
Data Streams. VLDB02.
Y. Chen, G. Dong, J. Han, B. W. Wah, and J. Wang. Multi-
Dimensional Regression Analysis of Time-Series Data Streams.
VLDB'02.
C. Giannella, J. Han, J. Pei, X. Yan and P. S. Yu. Mining Frequent Patterns in Data Streams at Multiple Time Granularities, Next
Generation Data Mining:03.
A. Evfimievski, J. Gehrke, and R. Srikant. Limiting Privacy Breaches
in Privacy Preserving Data Mining. PODS03.
R f Oth F P tt Mi i A li ti

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 99/110
January 18, 2012 Data Mining: Concepts and Techniques 99
Ref: Other Freq. Pattern Mining Applications
Y. Huhtala, J. Kärkkäinen, P. Porkka, H. Toivonen. Efficient Discovery of Functional and Approximate Dependencies Using
Partitions. ICDE98.
H. V. Jagadish, J. Madar, and R. Ng. Semantic Compression and
Pattern Extraction with Fascicles. VLDB'99.
T. Dasu, T. Johnson, S. Muthukrishnan, and V. Shkapenyuk.
Mining Database Structure; or How to Build a Data Quality
Browser. SIGMOD'02.

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 100/110
January 18, 2012 Data Mining: Concepts and Techniques 100
Implications of the Methodology

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 101/110
January 18, 2012 Data Mining: Concepts and Techniques 101
Implications of the Methodology
Mining closed frequent itemsets and max-patterns
CLOSET (DMKD00)
Mining sequential patterns
FreeSpan (KDD00), PrefixSpan (ICDE01)
Constraint-based mining of frequent patterns
Convertible constraints (KDD00, ICDE01)
Computing iceberg data cubes with complex measures
H-tree and H-cubing algorithm (SIGMOD01)
Skip
MaxMiner: Mining Max patterns

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 102/110
January 18, 2012 Data Mining: Concepts and Techniques 102
MaxMiner: Mining Max-patterns
1st scan: find frequent items
A, B, C, D, E
2nd scan: find support for
AB, AC, AD, AE, ABCDE BC, BD, BE, BCDE
CD, CE, CDE, DE,
Since BCDE is a max-pattern, no need to check BCD, BDE,
CDE in later scan
R. Bayardo. Efficiently mining long patterns from
databases. In SIGMOD98
Tid Items
10 A,B,C,D,E
20 B,C,D,E,
30 A,C,D,F
Potentialmax-patterns
Skip
Mi i F t Cl d P tt CLOSET

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 103/110
January 18, 2012 Data Mining: Concepts and Techniques 103
Mining Frequent Closed Patterns: CLOSET
Flist: list of all frequent items in support ascending order
Flist: d-a-f-e-c
Divide search space
Patterns having d Patterns having d but no a, etc.
Find frequent closed pattern recursively
Every transaction having d also has cfa cfad is a
frequent closed pattern
J. Pei, J. Han & R. Mao. CLOSET: An Efficient Algorithm for
Mining Frequent Closed Itemsets", DMKD'00.
TID Items
10 a, c, d, e, f
20 a, b, e30 c, e, f
40 a, c, d, f
50 c, e, f
Min_sup=2
Skip
CLOSET+: Mining Closed Itemsets by

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 104/110
January 18, 2012 Data Mining: Concepts and Techniques 104
g yPattern-Growth
Itemset merging: if Y appears in every occurrence of X, then Y is merged with X
Sub-itemset pruning: if Y X, and sup(X) = sup(Y), X and all of
Xs descendants in the set enumeration tree can be pruned
Hybrid tree projection
Bottom-up physical tree-projection
Top-down pseudo tree-projection
Item skipping: if a local frequent item has the same support in
several header tables at different levels, one can prune it from
the header table at higher levels
Efficient subset checking
Skip
CHARM: Mining by Exploring Vertical Data Format

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 105/110
January 18, 2012 Data Mining: Concepts and Techniques 105
CHARM: Mining by Exploring Vertical Data Format
Vertical format: t(AB) = {T11, T25, } tid-list: list of trans.-ids containing an itemset
Deriving closed patterns based on vertical intersections
t(X) = t(Y): X and Y always happen together
t(X) t(Y): transaction having X always has Y
Using diffset to accelerate mining
Only keep track of differences of tids
t(X) = {T1, T2, T3}, t(XY) = {T1, T3} Diffset (XY, X) = {T2}
Eclat/MaxEclat (Zaki et al. @KDD97), VIPER(P. Shenoy et
al.@SIGMOD00), CHARM (Zaki & Hsiao@SDM02)
Further Improvements of Mining Methods

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 106/110
January 18, 2012 Data Mining: Concepts and Techniques 106
Further Improvements of Mining Methods
AFOPT (Liu, et al. @ KDD03) A push-right method for mining condensed frequent
pattern (CFP) tree
Carpenter (Pan, et al. @ KDD03)
Mine data sets with small rows but numerous columns Construct a row-enumeration tree for efficient mining
Skip
Visualization of Association Rules: Plane Graph

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 107/110
January 18, 2012 Data Mining: Concepts and Techniques 107
Visualization of Association Rules: Plane Graph
Visualization of Association Rules: Rule Graph

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 108/110
January 18, 2012 Data Mining: Concepts and Techniques 108
Visualization of Association Rules: Rule Graph
Visualization of Association Rules

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 109/110
January 18, 2012 Data Mining: Concepts and Techniques 109
(SGI/MineSet 3.0)
Mining Other Interesting Patterns

8/3/2019 05 Mining Frequent Patterns Assoc and Data Correlations HH
http://slidepdf.com/reader/full/05-mining-frequent-patterns-assoc-and-data-correlations-hh 110/110
Mining Other Interesting Patterns
Flexible support constraints (Wang et al. @ VLDB02)
Some items (e.g., diamond) may occur rarely but are
valuable
Customized supmin specification and application
Top-K closed frequent patterns (Han, et al. @ ICDM02)
Hard to specify supmin, but top-k with lengthmin is more
desirable
Dynamically raise supmin in FP-tree construction andmining, and select most promising path to mine
Skip