cedzodulieu.tailieuhoctap.vn/.../file_goc_770786.docx · web viewsmoking.dta thuốc lá và ung th...
TRANSCRIPT

T-TEST & ANOVA
T – TEST t-test1 (kiểm định t) được sử dụng trong kiểm định sự khác biệt về giá trị trung bình của
tổng thể (μ) với một giá trị (μ0) cho trước, hoặc kiểm định sự khác biệt về giá trị trung
bình giữa hai tổng thể (μ1 và μ2).
Khi sử dụng phần mềm thống kê, chúng ta sử dụng cách tiếp cận p – value2 để quyết định
chấp nhận hay bác bỏ giả thuyết không H0 (null hypothesis).
Có 2 trường hợp: t-test một mẫu và t-test 2 mẫu (2 mẫu độc lập và mẫu phối hợp từng
cặp)
t-test m t m u (one-sample t-test)ộ ẫH0: μ – μ0 = 0
H1: μ – μ0 < 0 H1: μ – μ0 ≠ 0 H1: μ – μ0 > 0Pr(T < t)3 Pr(|T| > |t|) Pr(T > t)
Kiểm định bên trái Kiểm định hai bên Kiểm định bên phải
μ là trung bình của tổng thể.
μ0 giá trị để so sánh.
Quy tắc bác bỏ /chấp nhận giả thuyết H0 như sau:
Nếu Pr ≥ α không bác bỏ H0 (chấp nhận H0).
Nếu Pr < α bác bỏ H0.
Mức ý nghĩa α =5% được mặc định ở các phần mềm thống kê.
Thực hiện kiểm định t-test trong Stata với cú pháp: ttest varname = μ0 , level(1- α)
smoking.dta thuốc lá và ung thư4.
. d
Contains data from C:\Users\TRUONGTHANHVU\Desktop\BaiGiang2011\Bai 2 ttest\smoking_vn.dta obs: 44 vars: 9 27 Sep 2011 21:26
1 Trong thực tiễn, kiểm định t được dùng thay cho kiểm định z vì chúng ta thường không biết trước phương sai tổng thể. Và khi kích thước mẫu lớn thì hai phép kiểm định t và z là như nhau.2 p-value là mức ý nghĩa quan sát (observed significance level). Với các phần mềm thống kê, dùng cách tiếp cận p-value trong quy tắc bác bỏ hay chấp nhận giả thuyết không H0 (Null Hypothesis), giả thuyết luôn chứa dấu “=”. 3 Trong phần mềm Stata, p-value là Pr hay Prob. Trong phần mềm SPSS, p-value là sig. 4 Literature: Fraumeni, J. F. 1968. "Cigarette Smoking and Cancers of the Urinary Tract: Geographic Variations in the United States," Journal of the National Cancer Institute, 41(5): 1205-1211.

size: 3,344 (99.9% of memory free)----------------------------------------------------------------------------------------------------- storage display valuevariable name type format label variable label-----------------------------------------------------------------------------------------------------state str8 %8s cigar double %10.0g number of cigarettes smoked (hds per capita)bladder double %10.0g deaths per 100k people from bladder cancer [bang quang]lung double %10.0g deaths per 100k people from lung cancer [phoi]kidney double %10.0g deaths per 100k people from kidney cancer [than]leukemia double %10.0g deaths per 100k people from leukemia [bach cau]area double %10.0g smoke double %10.0g 1 for those whose cigarette consumption is larger than the median and 0 otherwiswest double %10.0g 1 for states in the South or West and 0 for those in the North, East or Midwest-----------------------------------------------------------------------------------------------------Sorted by:
. su cigar bladder lung kidney leukemia
Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- cigar | 44 24.91409 5.573286 14 42.4 bladder | 44 4.121136 .9649249 2.86 6.54 lung | 44 19.65318 4.228122 12.01 27.27 kidney | 44 2.794545 .5190799 1.59 4.32 leukemia | 44 6.829773 .6382589 4.9 8.28
Chúng ta muốn kiểm định phát biểu tỷ lệ chết (trung bình) do ung thư phổi là 20 – 18 –
21 ở mức ý nghĩa α?. ttest lung = 20, level(99)
One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [99% Conf. Interval]---------+-------------------------------------------------------------------- lung | 44 19.65318 .6374133 4.228122 17.93529 21.37108------------------------------------------------------------------------------ mean = mean(lung) t = -0.5441Ho: mean = 20 degrees of freedom = 43
Ha: mean < 20 Ha: mean != 20 Ha: mean > 20 Pr(T < t) = 0.2946 Pr(|T| > |t|) = 0.5892 Pr(T > t) = 0.7054
Một số chú ý: SE=SD/sqrt(n) 0.6374 = 4.2281/sqrt(44) Khoảng tin cậy 99% của giá trị trung bình = (a,b) =
(ybar ± tn-1α/2*SE) = (19.653 ± 2.695*0.6374)
Lệnh tra bảng t: ttable (download findit probtabl)5 . ttest lung = 20, level(90)
One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [90% Conf. Interval]---------+--------------------------------------------------------------------
5 Để tra bảng chi-bình phương, bảng f, bảng t, bảng z sử dụng các lệnh sau chitable ftablettable ztable. Xác định tại 1 df cụ thể thì đánh số df vào sau lệnh. Thêm obtion alpha(#) để chỉ đến mức ý nghĩa α cho tra bảng f. Không sử dụng option này cho lệnh ztable.

lung | 44 19.65318 .6374133 4.228122 18.58164 20.72472------------------------------------------------------------------------------ mean = mean(lung) t = -0.5441Ho: mean = 20 degrees of freedom = 43
Ha: mean < 20 Ha: mean != 20 Ha: mean > 20 Pr(T < t) = 0.2946 Pr(|T| > |t|) = 0.5892 Pr(T > t) = 0.7054
. ttest lung = 20, level(95)
One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- lung | 44 19.65318 .6374133 4.228122 18.36772 20.93865------------------------------------------------------------------------------ mean = mean(lung) t = -0.5441Ho: mean = 20 degrees of freedom = 43
Ha: mean < 20 Ha: mean != 20 Ha: mean > 20 Pr(T < t) = 0.2946 Pr(|T| > |t|) = 0.5892 Pr(T > t) = 0.7054
. ttest lung = 18, level(95)
One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- lung | 44 19.65318 .6374133 4.228122 18.36772 20.93865------------------------------------------------------------------------------ mean = mean(lung) t = 2.5936Ho: mean = 18 degrees of freedom = 43
Ha: mean < 18 Ha: mean != 18 Ha: mean > 18 Pr(T < t) = 0.9935 Pr(|T| > |t|) = 0.0129 Pr(T > t) = 0.0065
. ttest lung = 21, level(95)
One-sample t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- lung | 44 19.65318 .6374133 4.228122 18.36772 20.93865------------------------------------------------------------------------------ mean = mean(lung) t = -2.1129Ho: mean = 21 degrees of freedom = 43
Ha: mean < 21 Ha: mean != 21 Ha: mean > 21 Pr(T < t) = 0.0202 Pr(|T| > |t|) = 0.0404 Pr(T > t) = 0.9798
Ki m đ nh 2 m uể ị ẫ
t-test hai m u đ c l p (independent-samples t-test)ẫ ộ ậo Ví dụ về hai mẫu độc lập:
Quan tâm về mức chi tiêu học ngoại ngữ ở độ tuổi 10 – 30 giữa Tp. HCM và Tp. Cần Thơ.
Quan tâm kết quả học môn kinh tế chính trị giữa trường ĐH Kinh tế và Học viện Chính trị quốc
gia.

Quan tâm về chất lượng phục vụ khách hàng giữa Mobifone và S-fone.
H0: μ1 – μ2 = 0H1: μ1 – μ2 < 0 H1: μ1 – μ2 ≠ 0 H1: μ1 – μ2 > 0Pr(T < t) Pr(|T| > |t|) Pr(T > t)
μ1, μ2 là trung bình của tổng thể thứ nhất và thứ hai.
Trong thực tiễn, chúng ta thường không biết phương sai của hai tổng thể. Khi thực hiện t-
test trường hợp hai mẫu độc lập (independent-samples t-test) chúng ta cần tiến hành kiểm
định cả 2 trường hợp: (1) phương sai của hai tổng thể bằng nhau và (2) phương sai của
hai tổng thể không bằng nhau.
Ví dụ: Khảo sát doanh nghiệp dn243.dta. d
Contains data from C:\Users\TRUONGTHANHVU\Desktop\BaiGiang2011\Bai 2 ttest\dn243.dta obs: 243 vars: 6 27 Sep 2011 21:06 size: 3,888 (99.9% of memory free)------------------------------------------------------------------------------- storage display valuevariable name type format label variable label-------------------------------------------------------------------------------mdn float %9.0g Ma doanh nghiepthitruong byte %10.0g thitruong Thi truongthoigian byte %8.0g Thoi gian hoat dong (thang)khuvuc byte %9.0g Thanhthi Thanh thi (thanh thi=1)baohanh byte %8.0g baohanh Co tram bao hanh (co=1)doanhthu float %9.0g doanh thu nam 2010 (trieu VND)-------------------------------------------------------------------------------Sorted by:
Chúng ta kiểm định sự khác biệt về doanh thu (biến doanhthu) trung bình theo thị trường
(biến khuvuc: thanhthi = 1, nongthon = 0).. table khuvuc, c(mean doanhthu)
--------------------------Thanh thi |(thanh |thi=1) | mean(doanhthu)----------+---------------Nong thon | 173134.3Thanh thi | 213119.3--------------------------
. tab khuvuc, su(doanhthu) mean
| Summary of | doanh thu Thanh thi | nam 2010 (thanh | (trieu VND) thi=1) | Mean------------+------------ Nong thon | 173134.33 Thanh thi | 213119.27------------+------------ Total | 191069.96

. tabstat doanhthu, stat(mean sd var) by(khuvuc)
Summary for variables: doanhthu by categories of: khuvuc (Thanh thi (thanh thi=1))
khuvuc | mean sd variance----------+------------------------------Nong thon | 173134.3 63357.42 4.01e+09Thanh thi | 213119.3 65513.6 4.29e+09----------+------------------------------ Total | 191070 67221.17 4.52e+09-----------------------------------------
. oneway doanhthu khuvuc
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 9.6099e+10 1 9.6099e+10 23.22 0.0000 Within groups 9.9742e+11 241 4.1387e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
Bartlett's test for equal variances6: chi2(1) = 0.1332 Prob>chi2 = 0.715
Thống kê chi bình phương chi2(1) = 0.1332 có Prob>chi2 = 0.715 > 0.05 chấp nhận
giả thuyết Ho: phương sai hai tổng thể bằng nhau. Trường hợp, phương sai của 2 tổng thể
khác nhau có ý nghĩa thống kê tại mức α, trong Stata – thêm unequal vào câu lệnh thực
hiện ttest; ngược lại thì không.
. ttest doanhthu, by(khuvuc)
Two-sample t test with equal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------Nong tho | 134 173134.3 5473.247 63357.42 162308.5 183960.2Thanh th | 109 213119.3 6275.065 65513.6 200681 225557.5---------+--------------------------------------------------------------------combined | 243 191070 4312.24 67221.17 182575.6 199564.3---------+-------------------------------------------------------------------- diff | -39984.94 8297.909 -56330.63 -23639.25------------------------------------------------------------------------------ diff = mean(Nong tho) - mean(Thanh th) t = -4.8187Ho: diff = 0 degrees of freedom = 241
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
Ta thấy Pr(|T| > |t|) = 0.0000 < 0.05 (5%), nên bác bỏ giả thuyết H0: hai giá trị trung bình
của hai tổng thể là bằng nhau. Như vậy, giá trị trung bình của hai tổng thể là khác nhau ở
mức ý nghĩa kiểm định 5%. Hơn nữa, Pr(T < t) = 0.0000 ứng với giả thuyết Ha: diff < 0
6 In Stata, the . oneway command performs the Bartlett’s chi-squared test for equal variances.

bác bỏ giả thuyết Ho (Ho: diff = mean(Nong tho) - mean(Thanh th) ≥ 0) ở mức ý
nghĩa α, hay mean(Nong tho) < mean(Thanh th).. ttest doanhthu, by(khuvuc) unequal
Two-sample t test with unequal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------Nong tho | 134 173134.3 5473.247 63357.42 162308.5 183960.2Thanh th | 109 213119.3 6275.065 65513.6 200681 225557.5---------+--------------------------------------------------------------------combined | 243 191070 4312.24 67221.17 182575.6 199564.3---------+-------------------------------------------------------------------- diff | -39984.94 8326.636 -56392.02 -23577.86------------------------------------------------------------------------------ diff = mean(Nong tho) - mean(Thanh th) t = -4.8021Ho: diff = 0 Satterthwaite's degrees of freedom = 227.781
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
Quay lại file smoking_vn.dta.
. oneway cigar smoke
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 767.615645 1 767.615645 56.76 0.0000 Within groups 568.029618 42 13.5245147------------------------------------------------------------------------ Total 1335.64526 43 31.0615178
Bartlett's test for equal variances: chi2(1) = 6.8325 Prob>chi2 = 0.009
. ttest cigar, by(smoke) unequal
Two-sample t test with unequal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- 0 | 22 20.73727 .5362291 2.515137 19.62212 21.85242 1 | 22 29.09091 .9705461 4.552265 27.07255 31.10927---------+--------------------------------------------------------------------combined | 44 24.91409 .8402045 5.573286 23.21966 26.60852---------+-------------------------------------------------------------------- diff | -8.353636 1.108829 -10.61028 -6.096995------------------------------------------------------------------------------ diff = mean(0) - mean(1) t = -7.5337Ho: diff = 0 Satterthwaite's degrees of freedom = 32.728
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
. ttest cigar, by(smoke)
Two-sample t test with equal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------

0 | 22 20.73727 .5362291 2.515137 19.62212 21.85242 1 | 22 29.09091 .9705461 4.552265 27.07255 31.10927---------+--------------------------------------------------------------------combined | 44 24.91409 .8402045 5.573286 23.21966 26.60852---------+-------------------------------------------------------------------- diff | -8.353636 1.108829 -10.59134 -6.115929------------------------------------------------------------------------------ diff = mean(0) - mean(1) t = -7.5337Ho: diff = 0 degrees of freedom = 42
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
. oneway cigar west
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 8.7465928 1 8.7465928 0.28 0.6015 Within groups 1326.89867 42 31.5928255------------------------------------------------------------------------ Total 1335.64526 43 31.0615178
Bartlett's test for equal variances: chi2(1) = 10.0249 Prob>chi2 = 0.002
. ttest cigar, by(west)
Two-sample t test with equal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- 0 | 20 25.4025 .7383812 3.302141 23.85705 26.94795 1 | 24 24.50708 1.424247 6.977355 21.5608 27.45336---------+--------------------------------------------------------------------combined | 44 24.91409 .8402045 5.573286 23.21966 26.60852---------+-------------------------------------------------------------------- diff | .8954167 1.701766 -2.538887 4.32972------------------------------------------------------------------------------ diff = mean(0) - mean(1) t = 0.5262Ho: diff = 0 degrees of freedom = 42
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.6992 Pr(|T| > |t|) = 0.6015 Pr(T > t) = 0.3008
. ttest cigar, by(west) unequal
Two-sample t test with unequal variances------------------------------------------------------------------------------ Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- 0 | 20 25.4025 .7383812 3.302141 23.85705 26.94795 1 | 24 24.50708 1.424247 6.977355 21.5608 27.45336---------+--------------------------------------------------------------------combined | 44 24.91409 .8402045 5.573286 23.21966 26.60852---------+-------------------------------------------------------------------- diff | .8954167 1.604271 -2.364686 4.155519------------------------------------------------------------------------------ diff = mean(0) - mean(1) t = 0.5581Ho: diff = 0 Satterthwaite's degrees of freedom = 34.0478
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0 Pr(T < t) = 0.7098 Pr(|T| > |t|) = 0.5804 Pr(T > t) = 0.2902

t-test hai m u ph thu c hay ph i h p t ng c p (paired samplesẫ ụ ộ ố ợ ừ ặ t-test)
H0: μ1 – μ2 = 0
H1: μ1 – μ2 < 0 H1: μ1 – μ2 ≠ 0 H1: μ1 – μ2 > 0
Pr(T < t) Pr(|T| > |t|) Pr(T > t)
μ1, μ2 là trung bình của tổng thể thứ nhất và thứ hai.
o Ví dụ về hai mẫu phối hợp từng cặp:
Cải tiến phương pháp dạy ngoại ngữ.
Hiệu quả trước và sau có chương trình khuyến mãi.
Khác biệt trong chất lượng sản phẩm trước và sau cải tiến.. d
Contains data from C:\Users\TRUONGTHANHVU\Desktop\BaiGiang2011\Bai 2 ttest\caitien.dta obs: 24 Nash and Schwartz (1987) vars: 7 27 Sep 2011 22:36 size: 552 (99.9% of memory free)-------------------------------------------------------------------------------------------- storage display valuevariable name type format label variable label--------------------------------------------------------------------------------------------kh byte %8.0g slbl ma khach hanghailong1 byte %8.0g diem danh gia (truoc)hailong2 byte %8.0g diem danh gia (sau)logo1 float %9.0g logo2 float %9.0g chatluong1 float %9.0g chatluong2 float %9.0g --------------------------------------------------------------------------------------------Sorted by:
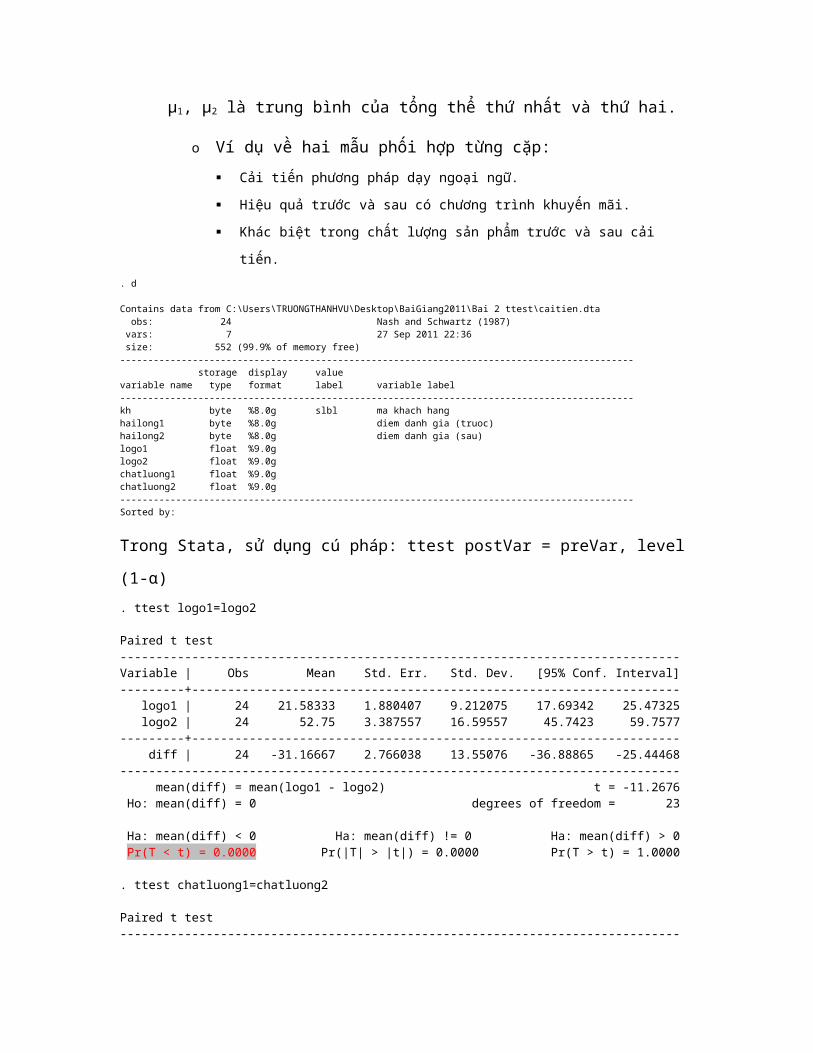
Trong Stata, sử dụng cú pháp: ttest postVar = preVar, level (1-α). ttest logo1=logo2
Paired t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+-------------------------------------------------------------------- logo1 | 24 21.58333 1.880407 9.212075 17.69342 25.47325 logo2 | 24 52.75 3.387557 16.59557 45.7423 59.7577---------+-------------------------------------------------------------------- diff | 24 -31.16667 2.766038 13.55076 -36.88865 -25.44468------------------------------------------------------------------------------ mean(diff) = mean(logo1 - logo2) t = -11.2676 Ho: mean(diff) = 0 degrees of freedom = 23
Ha: mean(diff) < 0 Ha: mean(diff) != 0 Ha: mean(diff) > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
. ttest chatluong1=chatluong2
Paired t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------chatlu~1 | 24 22.91667 3.038352 14.88482 16.63136 29.20198chatlu~2 | 24 54.16667 3.122886 15.29895 47.70649 60.62685

---------+-------------------------------------------------------------------- diff | 24 -31.25 3.028398 14.83606 -37.51472 -24.98528------------------------------------------------------------------------------ mean(diff) = mean(chatluong1 - chatluong2) t = -10.3190 Ho: mean(diff) = 0 degrees of freedom = 23
Ha: mean(diff) < 0 Ha: mean(diff) != 0 Ha: mean(diff) > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
. ttest hailong1=hailong2
Paired t test------------------------------------------------------------------------------Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------hailong1 | 24 1.666667 .1772032 .8681147 1.300094 2.033239hailong2 | 24 3.916667 .1583047 .7755316 3.589188 4.244145---------+-------------------------------------------------------------------- diff | 24 -2.25 .2272233 1.113162 -2.720047 -1.779953------------------------------------------------------------------------------ mean(diff) = mean(hailong1 - hailong2) t = -9.9022 Ho: mean(diff) = 0 degrees of freedom = 23
Ha: mean(diff) < 0 Ha: mean(diff) != 0 Ha: mean(diff) > 0 Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000
ANOVAMục tiêu của phân tích phương sai (ANOVA - Analysis of Variance) là so sánh trung
bình của nhiều tổng thể dựa trên các trị trung bình của các mẫu quan sát từ các tổng thể
này, và thông qua kiểm định giả thuyết để kết luận về sự bằng nhau giữa các trung bình
tổng thể.
Trong thực tiễn, chúng ta dùng ANOVA như là một công cụ để phân tích ảnh hưởng của
một yếu tố nguyên nhân đến một kết quả nào đó (phân tích phương sai một yếu tố -
One-way ANOVA); hay ảnh hưởng của hai yếu tố nguyên nhân đến một yếu tố kết quả
gọi là phân tích phương sai 2 yếu tố - Two-way ANOVA.
Khi thực hiện ANOVA, yếu tố nguyên nhân phải là biến định tính (biến phân loại), ký
hiệu là biến xi, yếu tố kết quả thường là biến định lượng, ký hiệu là biến y.
Với giả thuyết H0 là các nhóm (tổng thể) có trung bình bằng nhau: H0: µ1 = µ2 =… = µi =
µk; trong đó, µi là trung bình của nhóm thứ i.
Giả thuyết đối H1 : có ít nhất hai trung bình là khác nhau.
Các bước tiến hành kiểm định:
Bước 1: Tổng các biến thiên giữa các nhóm SSG (between-group sums of squares) là:
Bước 2: Tổng các biến thiên trong nội bộ nhóm SSW (within-group sums of squares) là:
Bước 3: Tổng biến thiên trong nhóm và giữa các nhóm SST (total sum of squares):
Loại biến
thiên
Tổng biến
thiênBậc tự do Trung bình biến thiên F
Giữa các nhóm SSG df1=k – 1 MSG = SSG/(k – 1) MSG/MSW
Nội bộ nhóm SSW df2=n – k MSW = SSW/(n – k)
Tổng SST n – 1
Quy tắc bác bỏ H0 là nếu giá trị thống kê F lớn hơn giá trị tới hạn Fα,k-1,n-k (Ftra bảng7). Khi
sử dụng SPSS, quy tắc bác bỏ H0 là giá trị p-value (sig.) nhỏ hơn mức ý nghĩa kiểm định
α.
Các lệnh thực hiện trong Stata:
oneway y x
thực hiện phân tích phương sai một yếu tố, kiểm định sự khác nhau giữa các
giá trị trung bình y phân theo các nhóm (phân loại hay thuộc tính) khác nhau của
biến x.
anova y x
thực hiện phân tích phương sai một yếu tố như oneway y x, nhưng thể hiện
bảng kết quả dưới hình thức khác.
oneway y x, tab
thực hiện phân tích phương sai một yếu tố, có thể hiện bảng giá trị trung bình
của các nhóm.
7 Hàm tra bảng F trong Excel: FINV(pr,df1,df2)

oneway y x, bonferroni8 scheffe
thực hiện phân tích phương sai một yếu tố, có thể hiện bảng giá trị trung bình
theo các thuộc tính của biến x và bảng kiểm định về sự khác biệt giữa giá trị trung
bình đó.
anova y x1 x2
thực hiện phân tích phương sai hai yếu tố, kiểm định sự khác nhau giữa các trị
trung bình y phân theo các thuộc tính khác nhau của hai biến x1 và x2.
anova y x1 x2 x1*x2
phân tích phương sai hai yếu tố bao gồm cả ảnh hưởng độc lập của từng yếu tố
x1 , x2 và ảnh hưởng do tương tác giữa hai yếu tố x1 & x2 gây nên.
Ph ng sai m t y u t (One-way ANOVA)ươ ộ ế ố
Một số giả định đối với phân tích phương sai một yếu tố:
o Các nhóm so sánh phải độc lập và được chọn một cách ngẫu nhiên.
o Các nhóm so sánh phải có phân phối chuẩn hoặc cỡ mẫu phải đủ lớn.
o Phương sai của các nhóm phải bằng nhau.. d
Contains data from C:\Users\TRUONGTHANHVU\Desktop\BaiGiang2011\Bai 2 ttest\dn243.dta obs: 243 vars: 6 27 Sep 2011 21:06 size: 3,888 (99.9% of memory free)------------------------------------------------------------------------------- storage display valuevariable name type format label variable label-------------------------------------------------------------------------------mdn float %9.0g Ma doanh nghiepthitruong byte %10.0g thitruong Thi truongthoigian byte %8.0g Thoi gian hoat dong (thang)khuvuc byte %9.0g Thanhthi Thanh thi (thanh thi=1)baohanh byte %8.0g baohanh Co tram bao hanh (co=1)doanhthu float %9.0g doanh thu nam 2010 (trieu VND)-------------------------------------------------------------------------------Sorted by:
Chúng ta phân tích “yếu tố nguyên nhân” khu vực bán hàng là thành thị/ nông thôn (biến
khuvuc) có ảnh hưởng đến doanh thu (biến doanhthu) của các doanh nghiệp hay không?
Để trả lời câu hỏi này, chúng ta cần so sánh giá trị trung bình của biến doanhthu theo hai
thị trường: thành thi và nông thôn và kiểm định rằng có hay không có sự khác biệt một
cách có ý nghĩa thống kê giữa hai thị trường này.
8 Bonferroni hay Scheffe là 2 trong nhiều phương pháp kiểm định thống kê sau để so sánh các trị trung bình của các nhóm (post hoc multiple comparisons).

. oneway doanhthu khuvuc
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 9.6099e+10 1 9.6099e+10 23.22 0.0000 Within groups 9.9742e+11 241 4.1387e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
Bartlett's test for equal variances: chi2(1) = 0.1332 Prob>chi2 = 0.715
. oneway doanhthu khuvuc, tab
Thanh thi | Summary of doanh thu nam 2010 (thanh | (trieu VND) thi=1) | Mean Std. Dev. Freq.------------+------------------------------------ Nong thon | 173134.33 63357.417 134 Thanh thi | 213119.27 65513.601 109------------+------------------------------------ Total | 191069.96 67221.166 243
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 9.6099e+10 1 9.6099e+10 23.22 0.0000 Within groups 9.9742e+11 241 4.1387e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
Bartlett's test for equal variances: chi2(1) = 0.1332 Prob>chi2 = 0.715
Lưu ý: thực hiện One-way ANOVA với biến phân loại x có 2 thuộc tính thì giống với
thực hiện ttest9.
Prob > F = 0.0000 khá nhỏ (nhỏ hơn 0.01) bác bỏ giả thuyết H0: trung bình của hai
tổng thể là bằng nhau nghĩa là, có sự khác biệt có ý nghĩa thống kê giữa khu vực
thành thị và nông thôn về doanh thu bán hàng.
Bây giờ, chúng ta phân tích “yếu tố nguyên nhân” thị trường (bắc-trung-tây nguyên-nam)
doanh thu hay không? Như vậy, chúng ta cần so sánh giá trị trung bình của biến
doanhthu theo 4 nhóm thị trường và kiểm định rằng có hay không có sự khác biệt có ý
nghĩa thống kê giữa các nhóm này.
. oneway doanhthu thitruong
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 6.6620e+10 3 2.2207e+10 5.17 0.0018 Within groups 1.0269e+12 239 4.2967e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
9 Có thể nói ANOVA là sự mở rộng của t-test.

Bartlett's test for equal variances: chi2(3) = 0.5103 Prob>chi2 = 0.917
. oneway doanhthu thitruong, tab
| Summary of doanh thu nam 2010 | (trieu VND) Thi truong | Mean Std. Dev. Freq.------------+------------------------------------ Phia Bac | 189750 69226.033 40 Mien Trun | 211692.31 65444.853 65 Tay Nguye | 194533.33 62866.081 75 Phia Nam | 166507.94 66409.257 63------------+------------------------------------ Total | 191069.96 67221.166 243
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 6.6620e+10 3 2.2207e+10 5.17 0.0018 Within groups 1.0269e+12 239 4.2967e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
Bartlett's test for equal variances: chi2(3) = 0.5103 Prob>chi2 = 0.917
Chúng ta bác bỏ giả thuyết: trung bình của các nhóm là bằng nhau vì p-value Prob>F=
0.0018 < mức ý nghĩa α. Nghĩa là có sự khác biệt có ý nghĩa thống kê về doanh thu bán
hàng giữa 4 nhóm thị trường. Giá trị Prob>chi2 = 0.917 > 0.05, có thể nói phương sai về
doanh thu giữa 4 nhóm thị trường là không khác nhau Kết quả phân tích ANOVA như
trên có thể sử dụng tốt. Tuy nhiên, bảng trên chưa cho biết sự khác biệt giữa các thị
trường với nhau. Chúng ta cần thực hiện kiểm định hậu ANOVA, với 2 phương pháp
kiểm định bonferroni và scheffe.. oneway doanhthu thitruong, bonferroni scheffe
Analysis of Variance Source SS df MS F Prob > F------------------------------------------------------------------------Between groups 6.6620e+10 3 2.2207e+10 5.17 0.0018 Within groups 1.0269e+12 239 4.2967e+09------------------------------------------------------------------------ Total 1.0935e+12 242 4.5187e+09
Bartlett's test for equal variances: chi2(3) = 0.5103 Prob>chi2 = 0.917
Comparison of doanh thu nam 2010 (trieu VND) by Thi truong (Bonferroni)Row Mean-|Col Mean | Phia Bac Mien Tru Tay Nguy---------+---------------------------------Mien Tru | 21942.3 | 0.582 |Tay Nguy | 4783.33 -17159 | 1.000 0.742 |

Phia Nam | -23242.1 -45184.4 -28025.4 | 0.484 0.001 0.078
Comparison of doanh thu nam 2010 (trieu VND) by Thi truong (Scheffe)Row Mean-|Col Mean | Phia Bac Mien Tru Tay Nguy---------+---------------------------------Mien Tru | 21942.3 | 0.429 |Tay Nguy | 4783.33 -17159 | 0.987 0.498 |Phia Nam | -23242.1 -45184.4 -28025.4 | 0.382 0.002 0.103
Cả 2 phương pháp bonferroni và scheffe đều cho thấy sự khác biệt có ý nghĩa trong trị
trung bình giữa thị trường miền Trung và phía Nam, trong khi các cặp thị trường khác thì
không.
Ph ng sai hai y u t (Two-way ANOVA)ươ ế ố
Chúng ta phân tích xem 2 “yếu tố nguyên nhân”: khu vực (thành thị/nông thôn) và có
trạm bảo hành sản phẩm (biến baohanh, có trạm = 1) có ảnh hưởng đến doanh thu hay
không? Nghĩa là, chúng ta cần so sánh giá trị trung bình của doanh thu bán hàng theo
nhóm có/ không có trạm bảo hành theo khu vực thành thị/nông thôn và kiểm định rằng có
hay không có sự khác biệt có ý nghĩa thống kê giữa các phân nhóm. Thêm vào đó, biến
tương tác khuvuc*baohanh có ảnh hưởng đến doanh thu không?
Trước hết, ta xem trị trung bình của biến doanh thu theo biến khuvuc và biến baohanh.. tab khuvuc baohanh, su( doanhthu) mean
Means of doanh thu nam 2010 (trieu VND)
Thanh thi | Co tram bao hanh (thanh | (co=1) thi=1) | khong co | Total-----------+----------------------+---------- Nong thon | 165172.41 224444.44 | 173134.33 Thanh thi | 95625.00 261379.31 | 213119.27-----------+----------------------+---------- Total | 177602.04 247234.04 | 191069.96
. anova doanhthu baohanh khuvuc baohanh#khuvuc
Number of obs = 243 R-squared = 0.2221 Root MSE = 59659.2 Adj R-squared = 0.2123
Source | Partial SS df MS F Prob > F ---------------+---------------------------------------------------- Model | 2.4287e+11 3 8.0956e+10 22.75 0.0000

| baohanh | 1.4062e+11 1 1.4062e+11 39.51 0.0000 khuvuc | 4.0852e+10 1 4.0852e+10 11.48 0.0008 baohanh#khuvuc | 378016612 1 378016612 0.11 0.7448 | Residual | 8.5065e+11 239 3.5592e+09 ---------------+---------------------------------------------------- Total | 1.0935e+12 242 4.5187e+09
Yếu tố baohanh và yếu tố khuvuc ảnh hưởng có ý nghĩa thống kê đến doanh thu vì các p-
value của chúng khá nhỏ (nhỏ hơn mức ý nghĩa α), nhưng biến tương tác
baohanh#khuvuc không có ý nghĩa thống kê. . anova doanhthu baohanh##khuvuc
Number of obs = 243 R-squared = 0.2221 Root MSE = 59659.2 Adj R-squared = 0.2123
Source | Partial SS df MS F Prob > F ---------------+---------------------------------------------------- Model | 2.4287e+11 3 8.0956e+10 22.75 0.0000 | baohanh | 1.4062e+11 1 1.4062e+11 39.51 0.0000 khuvuc | 4.0852e+10 1 4.0852e+10 11.48 0.0008 baohanh#khuvuc | 378016612 1 378016612 0.11 0.7448 | Residual | 8.5065e+11 239 3.5592e+09 ---------------+---------------------------------------------------- Total | 1.0935e+12 242 4.5187e+09
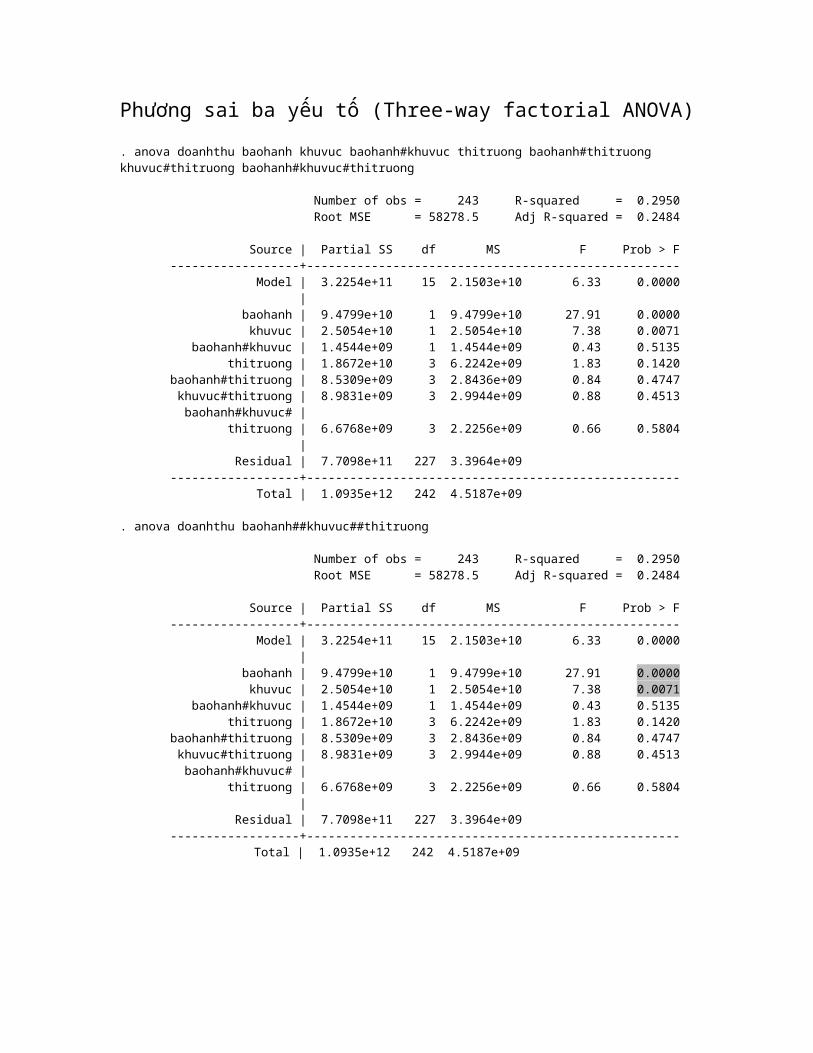
Ph ng sai ba y u t (Three-way factorial ANOVA)ươ ế ố. anova doanhthu baohanh khuvuc baohanh#khuvuc thitruong baohanh#thitruong khuvuc#thitruong baohanh#khuvuc#thitruong
Number of obs = 243 R-squared = 0.2950 Root MSE = 58278.5 Adj R-squared = 0.2484
Source | Partial SS df MS F Prob > F ------------------+---------------------------------------------------- Model | 3.2254e+11 15 2.1503e+10 6.33 0.0000 | baohanh | 9.4799e+10 1 9.4799e+10 27.91 0.0000 khuvuc | 2.5054e+10 1 2.5054e+10 7.38 0.0071 baohanh#khuvuc | 1.4544e+09 1 1.4544e+09 0.43 0.5135 thitruong | 1.8672e+10 3 6.2242e+09 1.83 0.1420 baohanh#thitruong | 8.5309e+09 3 2.8436e+09 0.84 0.4747 khuvuc#thitruong | 8.9831e+09 3 2.9944e+09 0.88 0.4513 baohanh#khuvuc# | thitruong | 6.6768e+09 3 2.2256e+09 0.66 0.5804 | Residual | 7.7098e+11 227 3.3964e+09 ------------------+---------------------------------------------------- Total | 1.0935e+12 242 4.5187e+09
. anova doanhthu baohanh##khuvuc##thitruong

Number of obs = 243 R-squared = 0.2950 Root MSE = 58278.5 Adj R-squared = 0.2484
Source | Partial SS df MS F Prob > F ------------------+---------------------------------------------------- Model | 3.2254e+11 15 2.1503e+10 6.33 0.0000 | baohanh | 9.4799e+10 1 9.4799e+10 27.91 0.0000 khuvuc | 2.5054e+10 1 2.5054e+10 7.38 0.0071 baohanh#khuvuc | 1.4544e+09 1 1.4544e+09 0.43 0.5135 thitruong | 1.8672e+10 3 6.2242e+09 1.83 0.1420 baohanh#thitruong | 8.5309e+09 3 2.8436e+09 0.84 0.4747 khuvuc#thitruong | 8.9831e+09 3 2.9944e+09 0.88 0.4513 baohanh#khuvuc# | thitruong | 6.6768e+09 3 2.2256e+09 0.66 0.5804 | Residual | 7.7098e+11 227 3.3964e+09 ------------------+---------------------------------------------------- Total | 1.0935e+12 242 4.5187e+09

Phụ lục:

Phụ lụcNguyên tắc của kiểm định các giả thuyết của tổng thể là : đưa ra các giả thuyết về các
tham số (trung bình, phương sai, tỷ lệ), tiến hành thu thập thông tin từ mẫu để kiểm định
giả thuyết đưa ra.
Các bước tiến hành kiểm định giả thuyết (5 bước):
1. Bước 1: Đặt giả thuyết: gồm cặp giả thuyết H0 (null hypothesis) và giả thuyết đối
H1; trong đó, H0 (giả thuyết không là giả thuyết mà chúng ta muốn kiểm định).
2. Bước 2: Chọn mức ý nghĩa kiểm định α (thường là 1%, 5% hay 10%); α là mức
độ chấp nhận sai lầm của nhà nghiên cứu.
3. Bước 3: Chọn phép kiểm định thích hợp (kiểm định t hay z) và tính giá trị thống
kê đó (gọi là giá trị tính toán10).
4. Bước 4: Xác định giá trị tới hạn của phép kiểm định.
5. Bước 5: So sánh giá trị tới hạn với giá trị kiểm định để quyết định chấp nhận hay
bác bỏ giả thuyết H0.
Tùy thuộc vào cách đặt giả thuyết mà chúng ta có kiểm định hai bên (two – tailed test)
hay kiểm định một bên (one-tailed test).
H0: μ – μ0 = 0H1: μ – μ0 < 0 H1: μ – μ0 ≠ 0 H1: μ – μ0 > 0
Kiểm định bên trái Kiểm định hai bên Kiểm định bên phải
μ là trung bình của tổng thể.
μ0 giá trị so sánh.
Khi sử dụng phần mềm thống kê, chúng ta sử dụng cách tiếp cận p – value 11 để quyết
định chấp nhận hay bác bỏ giả thuyết không (H0, null hypothesis). P-value là mức ý nghĩa
quan sát12 (observed significance level) tương ứng với giá trị thống kê kiểm định. Ví dụ,
10 t(tính toán) 11 Với các phần mềm thống kê, dùng cách tiếp cận p-value trong quy tắc bác bỏ hay chấp nhận giả thuyết không H0 (Null Hypothesis), giả thuyết luôn chứa dấu “=”. 12 Ví dụ: nếu p-value = 20% mà chúng ta vẫn bác bỏ H0 thì chuyện gì sẽ xảy ra? Khi thực hiện kiểm định, chúng ta chọn mức ý nghĩa kiểm định 5% (có thể 1% hay 10%), nghĩa là chúng ta chấp nhận phạm sai lầm “bác bỏ H0 trong khi thực sự H0 đúng” (gọi là sai lầm loại I) tối đa chỉ 5%. Nếu ta bác bỏ giả thuyết H 0 tại mức ý nghĩa quan sát 20% (lớn hơn nhiều so với 5%) tức là khả năng phạm sai lầm “bác bỏ H0 trong khi thực sự H0 đúng” tới 20%, lớn hơn nhiều so với ngưỡng cho phép tối đa mà chúng ta đã chọn. Vì vậy,

t0
Chấp nhận H0t = (0; tα)
Bác bỏ H0t = (tα; +∞)
α
tα
p1
t1
p2
t2
tα
t1 hay t2 chính là t tính toánứng với t1 có P1; t2 có P2tα chính là giá trị t tra bảng
khi chúng ta dùng kiểm định t (hình dưới) thì giá trị p đúng bằng diện tích phía dưới của
đường cong tính từ giá trị thống kê t (đường thẳng t=tα) đến vô cùng (∞).
t(tính toán) trong kiểm định 2 mẫu độc lập:
t(tính toán)
bậc tự do df=n1+n2-2 = n – 2 (n = n1 +n2).
Kiểm định tỷ lệ - prtestTrường hợp so sánh tỷ lệ với 1 tỷ lệ giả thuyết (một số chọn trước):
Sử dụng thống kê z, với z-tính-toán theo công thức:
chúng ta không nên bác bỏ H0 (vì đối mặt với nguy cơ phạm sai lầm quá lớn). Nhớ là, khi bác bỏ hay không bác bỏ gỉa thuyết H0 chúng ta đều có nguy cơ mắc phải sai lầm. α là xác suất tối đa mắc phải sai lầm bác bỏ H0 trong khi H0 thực sự đúng. β là xác suất tối đa mắc phải sai lầm không bác bỏ H0 trong khi H0 thực sự sai.
Và khoảng tin cậy (1-alpha)*100 là:
Trường hợp so sánh 2 tỷ lệ:
Sử dụng thống kê z, với z-tính-toán theo công thức:
Và khoảng tin (1-alpha)*100 của p1 – p2 là:
Sủ dụng file: vote.dta để thực hành.. use "F:\Bai giang2012\data\vote.dta"
. d
Contains data from F:\Bai giang2012\data\vote.dta
obs: 208
vars: 2 29 Dec 2011 14:01
size: 2,496 (99.9% of memory free)
-----------------------------------------------------------------------------------------
storage display value
variable name type format label variable label
-----------------------------------------------------------------------------------------
dang float %9.0g dang Dang phai
gioitinh long %8.0g sex Gioi tinh
-----------------------------------------------------------------------------------------
Sorted by:
Một nhà nghiên cứu muốn biết liệu người đàn ông và phụ nữ trong một cộng đồng cụ thể
có sự khác biệt trong lá phiếu (bầu cử) chọn lựa đảng phái chính trị của họ. Anh ta thu
thập dữ liệu từ một mẫu ngẫu nhiên của 208 cử tri.
Trường hợp 1:
Tỷ lệ bầu chọn cho Đảng Cộng hòa là 90% (ở mức ý nghĩa alpha = 5%)?. prtest dang=0.9
One-sample test of proportion dang: Number of obs = 208
------------------------------------------------------------------------------
Variable | Mean Std. Err. [95% Conf. Interval]
-------------+----------------------------------------------------------------

dang | .6538462 .0329868 .5891931 .7184992
------------------------------------------------------------------------------
p = proportion(dang) z = -11.8336
Ho: p = 0.9
Ha: p < 0.9 Ha: p != 0.9 Ha: p > 0.9
Pr(Z < z) = 0.0000 Pr(|Z| > |z|) = 0.0000 Pr(Z > z) = 1.0000
Chú ý: z-tính-toán. dis (.6538462-0.9)/sqrt(0.9*0.1/208)
-11.833602
. z-tra-bảng = 1.96 (alpha=0.05)
Bác bỏ H0, chấp nhận Ha: p < 0.9.. prtest dang=0.7
One-sample test of proportion dang: Number of obs = 208
------------------------------------------------------------------------------
Variable | Mean Std. Err. [95% Conf. Interval]
-------------+----------------------------------------------------------------
dang | .6538462 .0329868 .5891931 .7184992
------------------------------------------------------------------------------
p = proportion(dang) z = -1.4525
Ho: p = 0.7
Ha: p < 0.7 Ha: p != 0.7 Ha: p > 0.7
Pr(Z < z) = 0.0732 Pr(|Z| > |z|) = 0.1463 Pr(Z > z) = 0.9268
. prtest dang=0.5
One-sample test of proportion dang: Number of obs = 208
------------------------------------------------------------------------------
Variable | Mean Std. Err. [95% Conf. Interval]
-------------+----------------------------------------------------------------
dang | .6538462 .0329868 .5891931 .7184992
------------------------------------------------------------------------------
p = proportion(dang) z = 4.4376
Ho: p = 0.5
Ha: p < 0.5 Ha: p != 0.5 Ha: p > 0.5
Pr(Z < z) = 1.0000 Pr(|Z| > |z|) = 0.0000 Pr(Z > z) = 0.0000
Trường hợp 2:
Tỷ lệ bầu chọn cho Đảng Cộng hòa là ngang nhau giữa phái nam và phái nữa (không có
sự khác biệt theo giới tính trong lựa chọn đảng phái chính trị) ở mức ý nghĩa alpha = 5%?. tab gioitinh dang, nolabel row
+----------------+

| Key |
|----------------|
| frequency |
| row percentage |
+----------------+
| Dang phai
Gioi tinh | 0 1 | Total
-----------+----------------------+----------
0 | 20 60 | 80
| 25.00 75.00 | 100.00
-----------+----------------------+----------
1 | 52 76 | 128
| 40.63 59.38 | 100.00
-----------+----------------------+----------
Total | 72 136 | 208
| 34.62 65.38 | 100.00
. tab gioitinh dang, row
+----------------+
| Key |
|----------------|
| frequency |
| row percentage |
+----------------+
| Dang phai
Gioi tinh | danchu conghoa | Total
-----------+----------------------+----------
nam | 20 60 | 80
| 25.00 75.00 | 100.00
-----------+----------------------+----------
nu | 52 76 | 128
| 40.63 59.38 | 100.00
-----------+----------------------+----------
Total | 72 136 | 208
| 34.62 65.38 | 100.00
. prtest dang, by(gioitinh)
Two-sample test of proportion nam: Number of obs = 80
nu: Number of obs = 128
------------------------------------------------------------------------------
Variable | Mean Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
nam | .75 .0484123 .6551137 .8448863
nu | .59375 .0434104 .5086672 .6788328
-------------+----------------------------------------------------------------

diff | .15625 .0650247 .0288039 .2836961
| under Ho: .0678038 2.30 0.021
------------------------------------------------------------------------------
diff = prop(nam) - prop(nu) z = 2.3044
Ho: diff = 0
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(Z < z) = 0.9894 Pr(|Z| < |z|) = 0.0212 Pr(Z > z) = 0.0106
Tham khảo thêm tại: http://www.stata.com/help.cgi?prtest

Ví dụ: bảng t

Vào trang http://www.tutor-homework.com/statistics_tables/statistics_tables.html để tra các giá trị thống kê t, z, chi2 và F

Tham khảo ttest bằng SPSS: (file dữ liệu đi kèm: 216data.sav)http://academic.udayton.edu/gregelvers/psy216/spss/ttests.htm
* Obtaining Stata Programsnet from http://www.ats.ucla.edu/stat/stata/ado/analysis/net install ???findit ???

Tài liệu tham khảo:1. Long, J. Scott. and Jeremy Freese (2003). Regression Models for categorical Outcomes Using
Stata , revised edition. College Station, TX: Stata Press.2. Nicholas Minot (2002). 3. Woolbridge, J.M. (2005) Introductory Econometrics – A Modern Approach, South-Western
College Pub.
4. James H. Stock & Mark W. Watson (2006) Introduction to Econometrics (second edition),
Addison-Wesley Pub.
5. Christopher Dougherty (2007), Introduction to Econometrics (third edition), Oxford Pub.
6. Cameron, A. C., and P. K. Trivedi (2009), Microeconometrics Using Stata. College Station,
Texas.